
- 1【C++】类与对象(三)—运算符重载|const成员函数|取地址及const取地址操作符重载_c++运算符重载的const
- 2《云原生安全攻防》-- 容器攻击案例:Docker容器逃逸
- 3【Ai应用】Springboot集成通义千问api开发一个对话应用_springboot 对接通义千问
- 4ES(ElasticSearch)搜索_es获取每个索引当天搜索词
- 5Linux 入门教程 by 程序员鱼皮
- 6放弃 RNN/LSTM 吧,因为真的不好用!望周知~_lstm文本分类准确率不高的原因
- 7PyQt5 事件处理机制_pyqt5 按钮事件
- 8网络工程专业的毕业生现在都在干什么,后悔当时的选择吗?_选网络工程后悔
- 9Bert解析,state of the art的语言模型
- 10详解QPropertyAnimation的使用--实现Qt动画效果_qpropertyanimation 起到
Python-完整笔记(基础知识点+面向对象+正则表达式)_python学习笔记
赞
踩
标识符命名规范
标识符:变量、常量、函数名称、模块名称、类名称、对象名称。。。
1.标识符的有效符号:数字、大小写字母、_下划线三种有效符号组件(注意:$符号在python中是特殊字符)
2.不能以数字开头
3.不能用关键字或者保留字(eg:for ,if,保留字:现在没有使用未来可能使用的字)
4.不建议使用全局已经定义过去标识符(eg:print,float......)
5.建议变量命名或者标识符命名尽量有意义
6.多个单词组成时,建议使用驼峰法和下划线法分割单词
7.类名称建议使用大驼峰,常量所有单词全部大写
python关键字
import keyword dir() 展示
数据类型
基本数据类型:
数值型(number):整型--int、浮点型--float、复数--complex
布尔类型(bool):True、False
字符串(str):'字符串'、"字符串"、"""字符串"""、'''字符串'''
None:没有
复合数据类型:
万物皆对象
list set dict tuple object ......
类型转换问题:
自动类型转换
int <--> float
bool <--> int (eg:a=10 b=3.14 c=True---->a+c=11)
bool <--> float (注意a=0.1,b=0.2,a+b!=0.3)
强制类型转换
int <--->str
float <--->str
eg:
num1 = float(input("请输入第一个数"))
num2 = float(input("请输入第一个数"))
print(str(num1)+"+"+str(num2)+"="+str(num1+num2))
print(str(num1)+"-"+str(num2)+"="+str(num1-num2))
print(str(num1)+"*"+str(num2)+"="+str(num1*num2))
print(str(num1)+"/"+str(num2)+"="+str(num1/num2))
运行结果:请输入第一个数10
请输入第一个数5
10.0+5.0=15.0
10.0-5.0=5.0
10.0*5.0=50.0
10.0/5.0=2.0
常见的运算符
算术运算符:
+
-
*
/ 在python里面是除而非整除
// 整除,地板除法
%
** 幂次方
关系运算符:
>
<
>=
<=
==
!=
逻辑运算符:
与 && and(一假则假)
或 || or(全假则假)
非 ! not
所属运算符:
in eg:user=["nsdjkfn"、"fnjdn"、"dkfn"]
"fnjdn" in user
True
not in
is运算符:
is python中==判断是两个变量的值,is判断是两个变量的地址
赋值运算符
=
+= #a +=3
-=
*=
/=
//=
**=
python没有自加和自减
i++
++i
--i
i--
三目运算符
变量 = 值1 if 表达式 else 值2 (eg:c=1000 if 3>4 else 100,结果为100))
(在C中:变量 = 表达式 ? 值1:值2;
如果表达式成立,结果为值1;反之结果为值2)
位运算符
在电子计算机中,数据但是以2进制保存,所以数据的运算但是基于二进制位运算。
& 与运算符(一假则假,全真则真)
| 或运算符(一真则真,全假则假), 二进制数据的各个位进行或运算
10 1010
11 1011 |
1011 11
^ 异或运算符,相反为真!
~ 按位取反,二进制数据全部取反!
<< 左移运算符,右边补0,移n位就结果乘2的n次方!
>> 右移运算符,前面补0,后面多出一位删除,移n位就除2的n次方!
eg:1、判断一个数是2的n次方数
n 10000000 N
n-1 01111111 N
2、判断一个数是偶数或者奇数
n & 1== 0 偶数
n & 1== 1 奇数
计算机底层知识:
计算机底层记录数据的本质是使用半导体,进行二进制数据的记录
一个二极管: 0/1 位(bit) b
字节(Byte) B
原码:十进制转换后的二进制
反码:除符号位不变,其余各位统统取反
补码:反码加一(为了解决负数的计算而产生的三个码)
计算机底层数字都是通过补码来计算,计算完成后还原为原码。(为了适应负数的兼容性)
程序控制流程(三大流程)
1.顺序:
从左到右,自上而下执行代码
2.选择:(有冒号的以下内容就有缩进)
(1)单分支
if条件:
if第二行缩进4个,用tab也行,但必须保持空格和空格相同,tab和tab一样对齐,否则报错。必须缩进保持一致!!!
eg:if age>=18:
print(".......")
print(".......")
(2)双分支
if conditon:
#如果条件成立,则执行if中的语言
else:
#如果条件不成立,则执行else中的语言
(3)多分支(三分支)
if condition1:
#如果条件成立,就执行
elif condition2:
#.....
......
elif conditionN:
#......
else:
#......
python的switch语法是近期才出现的。
3.循环:
while循环
while condition:
#循环体
for循环
1.range(num) #从0到num的区间所有整数
2.range(strat,end)#从start到end但是不包括strat和end
3.range(start,end,step) #从30到0的打印
for i in a:
......
else:
循环正常结束后要执行的代码(如果时break终止循环的情况,else下方缩进的代码将不执行)
break 和continue关键字
break:终止当前循环
continue:跳出本次循环,进入下次循环
字符串的拼接方法:
1.全部转换为字符串,在拼接+;
2.通过多个逗号,利用print函数的方式完成拼接;
3.通过%s %d %f 利用C语言的printf函数;
4.
print("jio"+name+"jio\n")
print("jio",name,"jio\n")
print("jio %s"%name)
print("jio {}" .format(name))
注意:
1.将choice转化为大写(.upper)或者小写(.lower)
choice.upper() == "Y" or choice.lower == "y"
2.else中的代码只有正常结束才会执行其中的代码
容器:
数据结构主要学习知识:
线性表、哈希、树、图
| 线性表(line table) | 顺序表 |
| 数组(array) | 类型一致、大小固定、连续的内存结构 |
| 链表(linkedlist) | 不一定连续内存、大小不固定;查询效率偏差,但是增加和删除比较方便。双向链表(查询效率高,耗内存高)、单向链表(与双向链表相反) |
| 队列(queue) | 先进先出(FIFO),后进后出(LILO) |
| 栈(stack) | 先进后出(FILO),后进先出(LIFO),不能乱存东西 |
python提供了四个内置容器:
列表(list):双向链表,无序可以重复
集合(set):哈希表,无序不能重复
元组(tuple):固定不变
字典(dict):哈希表,本质二维表
注:像python、javascript、PHP、ruby这些弱数据语言类型的编程语言,他们统统不存在数组!!
列表(list):
底层采用双向链表
如何获取定义list:
a = [ ]
a = [1、2、3、4]
全局函数list函数:
b = list()
b = list([1、2、3、4])
b = list({1、2、3、4})
列表具有迭代性
如何获取列表的元素(element):
下标或者角标
a[0] #第一个元素
a[列表长度-1] #最后一个元素
a[len(d)-1] #最后一个元素
如何遍历列表:
way1:for 一个临时变量 in 一个列表:
print(临时变量)
way2:
i = 0
while i <len(列表):
print(列表[i])
i +=1
增加、删改列表元素:
dir(a)#打印查看存在的属性和方法
1.|--append(新的元素) #将新的元素追加到尾部
eg:a.append("jio")
2.|--insert(index,新的元素) #将新的元素插入到index位置
eg:a.insert(2,"ok") #插在第三个位置
3.|--extend(列表) #合并
eg:a.extend(b) or a=a+b
4.|--remove(元素) #根据元素移除第一个匹配的元素
eg:a.remove(100)
5.|--pop([-1]) #默认移除最后一个元素,pop([0]):移除第一个;列表为空抛出异常
eg:a.pop()
6.|--clear() #清空列表
b.clear()
7.|--index(值) #通过获取某个值的第一个下标(从左向右)
8.|--count(值) #统计某个元素出现的次数
9.|--reverse() #翻转列表中元素的顺序,注意和全局函数reversed(返回一个迭代值)的区别
eg:reverse(a)
10.|--sort() #排序,d.sort(reverse=True)降序排序;d.sort(reverse=False)升序排序
eg:d.sort()
11.|--copy() #浅拷贝对象
堆(heap)~对象存在堆里面,对应的地址放在栈里面
引用传递、浅拷贝、深拷贝
引用传递:复制的是栈的地址
浅拷贝:拷贝的是堆内存,会产生新的内存空间,只是仅仅拷贝第一层对象
(将堆里面的内容复制一个放在堆里面,地址发生变化,然后复制的是堆的地址)
深拷贝:拷贝完整(递归多次)
集合(set):
底层采用的hash table(哈希表)实现的!!!
哈希表的特点:无序的、不能重复
创建set:
s= {1,2,3,4,5,6}
ssf = set() #空set
无法通过下标获取元素、可以使用len函数获取元素个数;可以通过for循环
元组(tuple):
表示一组固定不变的值
元组是不可变数据类型,基本数据类型都是不可变的
eg:t = (1,2,3,4,5)
dir(reason)
|--index(值) #通过获取某个值的第一个下标(从左向右)
|--count(值) #统计某个元素出现的次数
注意:构建一个元素的元组,加一个逗号-->t = (3,)
字典(dict):
本质还是一个哈希表,类似于map结构,本质就是一个二维表,只有唯一一个key与之对应
key(不重复,哈希特性;只能是字符串或者数字) | value
1.字典的创建和定义:
d = {} or d = dict()
d = {key:value,key:value,......}
2.获取value:
d["key"] #获取key对应值,如果key不存在则异常
d[key] = 新的值 #修改key的值,如果key不存在,则添加一组
3.获取字典的键值对数量:len(字典对象)
4.字典的常见方法:
dir(dict)
| d.get(key,default(默认值)) | 获取key对应的值,如果key不存在,返回空 |
| d.setdefault(key,value) | 新增一组,不能修改;如果value则默认为空 |
| d.keys() | 查看所有key |
| d.items() | 以组键的形式查看 |
| d.values() | 查看所有value |
| dict.fromkeys(Iterable,none) | 依照Iterable的内容自动生成几组 |
| d.pop(key) | 移除key对应的键值对 |
| d.popitem() | 从后进的地方逐队移除,也就是从左到右的移除 |
| d.update(dd) | 合并并且实时更新 |
函数篇
具有名称的功能代码集合
python定义函数:def关键字 #defined function
1.def 函数名称:
#函数体
#[return 返回值]
2.调用函数:函数不会自己执行,需要调用才会执行
(函数调用本质:函数在执行时,首先会被加载到执行栈中,等函数执行完成之后,会立刻弹出栈,保证执行栈中没有内存的消耗和占用)
函数名称()
eg:def print_msg(x):
#参数x定义要打印几次
for i in range(x):
print("hello world")
print_msg(3)
3.函数的分类:
根据函数是否存在参数:有参的函数 | 无参的函数
根据函数是否返回值:有返回值的函数 | 无返回值的函数
根据函数的定义者:系统函数 | 自定义函数 | 第三方函数
函数的本质就是功能代码的集合:
就是将完成某一功能的代码放在一起,取个名字,等 其他人(包括我)实现这个功能时,我们就可以直接调用这个函数,而不用再次实现。
4.局部变量(本地变量 )(local variable)和全局变量(global variable)
注意:1.在函数内部可以正常访问全局变量不允许修改全部变量(基于安全考虑,python禁止函数内部修改全局变量)实在是需要在函数内部修改全局变量,须在里面加一个global 需要修改的全局变量名(不提倡)
2.形参也是局部变量
3.局部变量只能在函数内部有效!!!
4.局部变量是函数内部的变量
5.引用传递和值传递
值传递:在函数调用的时候,传递的是值,函数内部的修改不会影响外界的值,也就是实参
引用传递:在函数调用时,传递的时内存地址(C语言指针),因此函数内部得到同一个对象
6.函数的参数
def bsa(一般参数:八种类型,默认值参数,可变参数,关键字参数)->八种返回类型:
eg:def bsa(r:float,pi=3.14,*args,**kwargs)->int 返回或者传递的类型
默认值参数:如果我们的某些参数在大多数情况下是固定值,可以将这个固定值设置成默认值,简化调用(没有默认值参数必须写在默认值参数前面)
注意:函数中位置参数必须放在默认值参数前面
可变参数:如果函数中需要传递一批参数(大量)为了方便可以使用可变参数。可变参数是使用的元组
关键字参数:使用字典
7.函数作为参数
函数作为参数传递到另外一个函数中去
匿名函数:lambda表达式(少量)
lambda[参数......]:函数体
eg:def test02(func):
res = func(2,10)
return res
test02(lambda x,y:x*y)
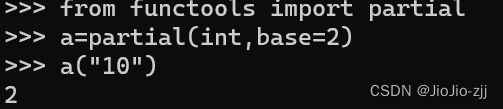
8.偏函数
特殊的函数使用:将默认值进行修改
functools库 ~ 函数工具库
from functools import partial ~ 导入一个/少数函数,进行定义修改默认值
eg:#将原本int的二进制的默认值转化为十进制
递归(recursion)和排序查找
在计算机科学中是指通过城府将问题分解为同类的子问题而解决问题的方法
代码中,函数自身调用自身
递归一定要有终止条件,如果没有及那个形成死循环
递归本质通过空间换时间,栈内存被疯狂占有,因此递归一定要慎用,特别是递归的层数,一般不建议超过1000次
斐波那契而数列:从第三个元素开始,每一个元素的值=前两个元素之和

1.字符串对象:
基本数据类型:字符串在python中是基本数据类型。
python是面向对象,在面向对象的编程语言看来,万物皆对象!!!
字符串定义:'字符串',"字符串","""字符串""",'''字符串''',str()
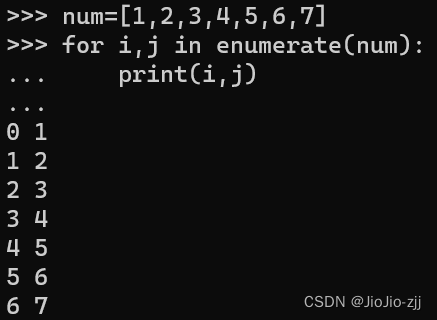
遍历字符串,enumerate函数,i为索引下标
常见的方法:
| capitalize() | 首字母大写 |
| center(n)#n的值要大于字符串本身长度 | 居中对齐 |
| ljist(n) | 左对齐 |
| rjust(n) | 右对齐 |
| count() | 统计子元素的个数 |
| index(值) | 通过获取某个值的第一个下标(从左向右) |
| rindex() | 通过获取某个值的最后一个下标(从右向左) |
| find() | 与index用法一样,稍有区别 |
| rfind() | |
| endswith() | 以什么结束 |
| startswith() | 以什么开始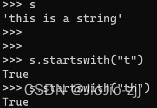 |
| format() | 格式化字符串 |
| isalnum()#判断字符串由是否数字字母组成,是则返回True;isalpha()#判断是否由字母组成;isascii()#判断字符串是否由ASCII码表内的组成;isdecimal()#判断数字;isdigit()#判读数字;isidentifier()#判断是否符合标识符组成原理;islower()#判断是否由小写开头;isupper()#大写 | 做判断 |
| istitle() |  |
| 大小写转换 | 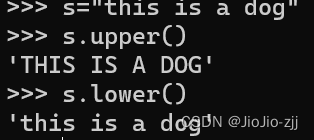 |
| 转化为文本格式title() | 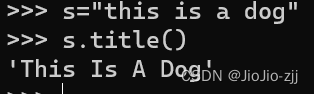 |
| strip() | 清除空格 |
| lstrip() | 清除左边空格 |
| rstrip() | 清除右边空格 |
| removesuffix("...") | 移除后缀 |
| removeprefix("...") | 移除前缀 |
| replace("将要替换的的值","替换成什么值") | 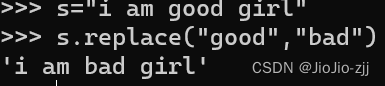 |
| partition() | 以某个值分割(值分割一次) |
| split() | 按照特定的符号分割(所有都分割,参照物丢弃)
|
| join() |  |
| maketrans() |  |
| translate() | |
| encode() | 将字符串转换为字节,默认编码utf-8 |
| decode() | 将字节转化为字符串 |

2.切片
python提供的用来分割或者分割有序序列()的一种技术
(1)有序序列[start:]#从下标位置开始,到结束[)的区间(前开后闭)
(2)有序序列[start:end]
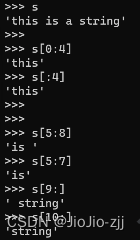
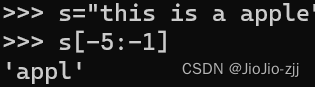
(3)有序序列[start:end:step]
注意:python支持负索引!!!只能从左到右切片,唯一改变方向就是把step设为负数
3.排序与查找:
冒泡排序:(较稳定)
相邻的两个数两两比较,从而找到需要的值(最大or最小值)
- #冒泡排序
- def bubble_sort(num:list)->None:
- for i in range(len(num)-1):
- for j in range(len(num)-1-i):
- if num[j]>num[j+1]:
- num[j],num[j+1]=num[j+1],num[j]
- num=[1,4,2,5,3,24,7,12,82,1,9]
- bubble_sort(num)
选择排序:(不稳定)
每一轮找到一个最大值/最小值,假设“第一个值”为最小值,每一轮会找到正真的最小值(每一轮“第一个值”和剩下的值进行比较找到最小值与之交换)。
- #选择排序1,每一轮只交换一次
- def select_sort(nums:list[int])->None:
- for i in range(len(nums)-1):
- min_index=i
- for j in range(i+1,len(nums)):
- if nums[j]<nums[min_index]:
- min_index=j
- if i!=min_index:
- nums[i],nums[min_index]=nums[min_index],nums[i]
- nums=[4,2,1,-2,4,2,9,10]
- print(select_sort(nums))
-
- #选择排序2,每一轮存在多次交换
- def select_sort(nums:list[int])->None:
- for i in range(len(nums)-1):
- for j in range(i+1,len(nums)):
- if nums[j]<nums[i]:
- nums[i],nums[j]=nums[j],nums[i]
- nums=[4,2,1,-2,4,2,8,10]
- print(select_sort(nums))

插入排序:
将无序数挨个插入到有序数中,第一轮第一个数不变,第二个数开始插入比较
- #插入排序
- def insert_sort(nums:list[int])->None:
- for i in range(len(nums)-1):
- for j in range(i+1,-1,-1):
- if nums[j+1]<nums[j]:
- nums[j],nums[j+1]=nums[j+1],nums[j]
- return nums
- nums=[4,2,31,-2,4,2,89,10]
- print(insert_sort(nums))
二分查找:
折半查找,非常优秀的查找方法,值要查询的数是有序的,二分查找则平均时间复杂度
- #二分查找常用方式
- def binary_search(nums:list[int],target:int)->int:
- left=0
- right=len(nums)-1
- while left<=right:
- middle = (left+right)>>1
- if nums[middle]>target:
- right=middle-1
- elif nums[middle]<target:
- left = middle+1
- else:
- return middle
- return -1
-
- #二分查找的递归方式
- def binary_search(nums:list[int],left:int,target:int)->int:
- if left > right:
- return -1
- middle=(left+right)//2
- if nums[middle]>target:
- return binary_search(nums,left,middle-1,target)
- elif nums[middle]<target:
- return binary_search(nums,middle+1,left,target)
- else:
- return middle
模块和包的基本概念~项目化的管理文件
模块(module):一个.py文件就是一个模块
包(package):类似于一个文件夹,可以管理和保持很多模块;正真的标准的包存在一个__init__.py
python中模块(包)的导入问题
import ***** #直接导入需要的模块和包
import ***.****.*** #如果存在多层,可以层层导入
import ***** as np #通过别名,简化导入的模块名称
from ***(包) import ****(模块) #python提供的一种导入
注意:在python中如果遇到比较复杂的命名可以使用别名法将其简化
main函数的作用和使用
模块根据创建者存在三种分类:
官方内置模块:python
自定义模块:存在模块下
第三方:需要下载;使用pip工具,python主目录下/pip/site-packages
pip install 模块名称 | pip uninstall 模块名称
main函数的使用和作用:JavaScript,python,PHP等弱数据编程语言是脚本语言,解释性语言,所有没有main,即使有也不知道程序的入口,有特殊作用。
python其实有main函数,但是作用不是此程序的入口,用来测试代码,该代码无法导入到其他代码中去。魔法属性:if __name__=='__main__':******
常见的内置模块的使用
random,math,os,sys,os.path,uuid,hashlib.....
1.随机数模块random:
random.random()#0~1
random.random()*10#0~10小数
int(random.random()*10)#整数
random.choices()#从中随机取出一个值
random.choice()
random.randint(n1,n2)#前闭后闭
random.randrange(n1,n2,step)
random.uniform()
random.shuffle()#传入有序列表进去,传出打乱的列表,洗牌
还有很多方法,通过--help和help(方法)和dir(方法)自行查找测试和学习!!!
2.数学模块math:
math.ceil(n)#向上取整
math.floor(n)#向下取整
round(n,保留的小数位数)#四舍五入,全局
abs(n)#绝对值,全局
math.degrees()#弧度转角度
math.radians()#角度转弧度
math.factorial()#求阶乘
3.os模块:pathlib(现在基本使用这个只不过是基于面向对象)
os.path.abspath(os.curdir)#查看当前绝对路径
os.getcwd()#获取当前路径
os.getpid()#获取当前进程编号
os.getppid()#获取父进程编号
os.listdir()#返回当前工作目录下的子项目
os.sep#查看分割符
open
查找过滤和遍历文件目录:
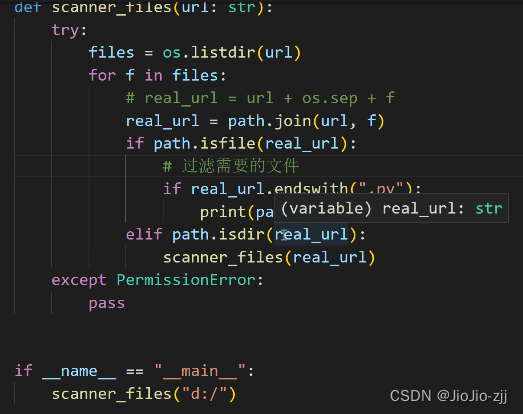
4.sys模块
python解释器系统
sys.argv #迭代器!!!
sys.getcursionlimit #递归最大次数,范围
sys.setcursionlimit #设置递归次数限值
sys.getrefcount #引用次数,方便进行垃圾回收栈堆
5.时间和日期模块
time
表现形式:字符串、数字、
time.asctime#获取当前时间
time.sctime#获取当前时间
time.gmtime#时间对象(其格式自行查找)
time.localtime#当前本地时间9个参数
time.mktime((2023,11,24,19,46,41......#通过查找时间对象里面的参数需要确定))#时间数字,从1970年到现在经过了多少秒
time.sleep(2)#程序停留2秒钟
time.time()#拿到当前时间的秒数
time.strftime("%Y/%m/%d %H:%M:%S")#时间输出格式化,这是当前时间的格式化;也可以在后加上需要格式化的其他时间
time.strptime("1980-12-3 12:32:33","%Y/%m/%d %H:%M:%S")#转化成时间对象,前面和后面必须对应
datatime
datatime.now()#当前时间7个参数
.......自己查,很多重要的进行方便的时间转换
calendar
calender.calender(2023)#2023年的日历
......打印其中几个月。。。自己查找学习
uuid
分布式解决方案
uuid.uuid4().hex#128位2进制,转化成了16进制。永不重复,每次获取的不同
6.加密模块:
不可逆加密(明文-->密文,单向):hash加密
可逆加密:(1)对称加密
加密和解密使用同一个密钥
DES算法
(2)非对称加密
加密和解密使用不同的密钥,该密钥是一对(公钥和私钥)
RSA
hashlib模块
t=hashlib.md5("661118".encode())#用md5/sha1...加密
t.hexdigest()#加密之后的密文
#如果是为了加密防止他人访问和查看数据,一定要添加盐值,否则可以通过第三方工具(cmd5)解密;
t.update("hfisddnvoksaj'pd=.dkoopjdiow".encode())#本质是在原数据上添加内容,所以盐值需要尽量复杂
hmac模块
h=hmac.new("123456".encode(),"hdjksan".encode,"MD5")#(需要加密的数据,盐值混淆,任何加密算法)
h.hexdigest()
pandas
openpyx1
xlswriter
xlrd
xlwt(python操作excel,pdf,word选修!!!)
IO流相关知识和对象序列化
IO流(Input Output Stream,广义上就是指计算机中数据的流动;但是我们一般说的IO流是狭义上的指的是数据在内存(CPU)和磁盘之间的数据流动)
IO流分类:输入流;输出流
根据流的数据格式:字符流;字节流
python如何处理IO流:
全局函数open函数,用来处理IO流
(文件名,mode(默认为tr:字符读),。。。)
字符流(效率高但是有局限性)
输入流:
f=open("a,txt")
f.read()#读取字符文件内容默认读到末尾,第二次读取为空因为光标已经到末尾
f.readline()#按行读
f.readline()#把所有行包装成一个列表输出
f.seek(0)#光标回到文件首
f=open("a.txt","rt",encoding="utf-8")#正确读取到数据
f.close()#io流一定要关闭!!!
输出流:
msg="i hate you !!!"
f=open("a.dat","wt",encoding="utf-8")#在os的本地地址上自动生成一个命名为a.dat的文件
f.write(msg)#写入数据
f.flush()#强制刷新,IO流有缓冲,写入不能马上看到数据的写入。
在IO流关闭时会自动强制刷新一次,使用tw关闭io流时会删除内容

字节流:(效率差但是没有局限性)
mode(br:字节读)

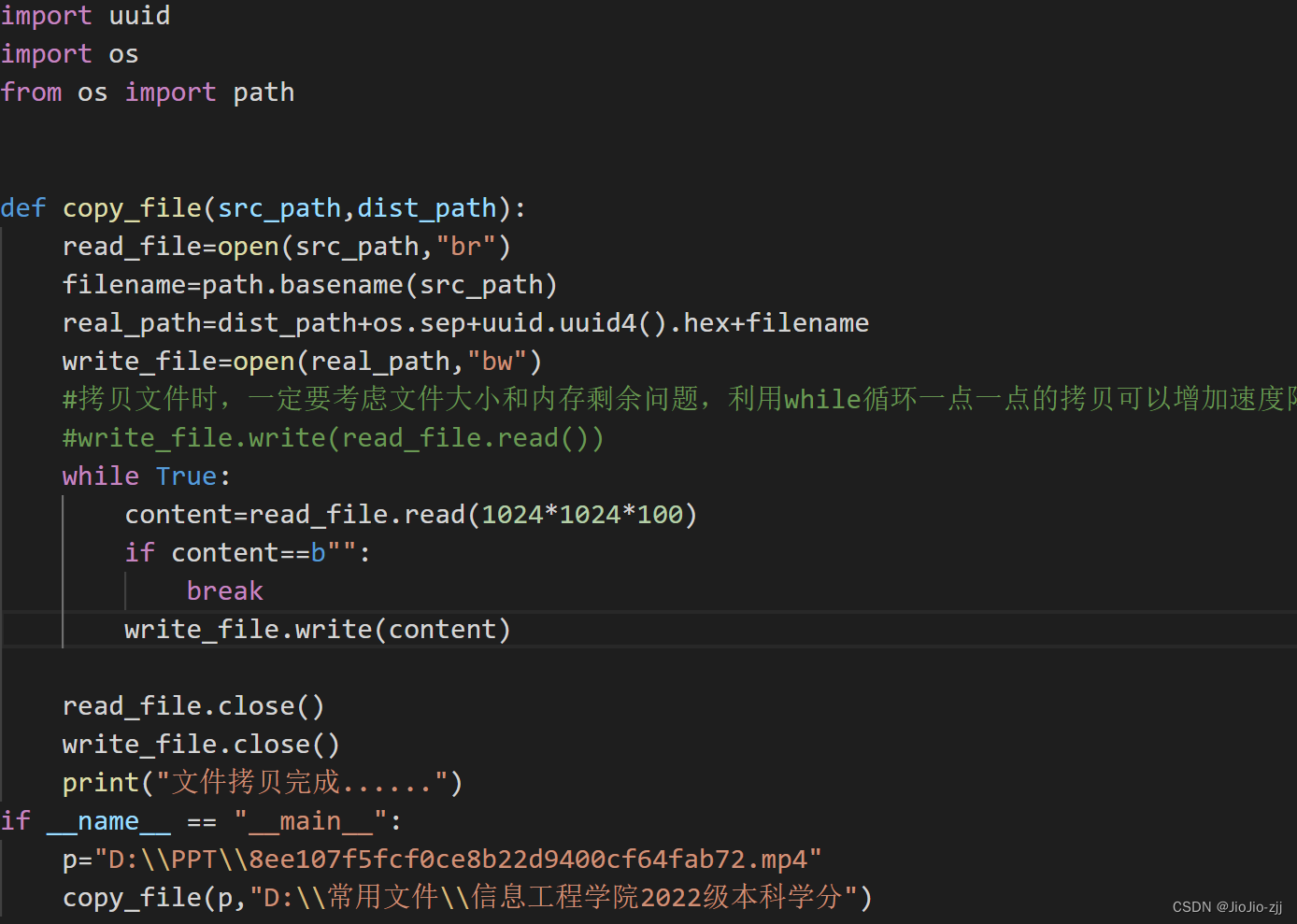
对象序列化和持久化:
对象序列化:将对象(抽象概念)转化为字节或者字符串的过程
对象反序列化:将对象序列化后的字节或者字符串重新还原成对应的对象
对象持久化:就对象序列化后再通过IO保存到永久存储的设备上的过程
对象反持久化:对象持久化后的数据重新读取到内存中变成对象的过程
python提供的序列化和持久化的模块:
pickle模块
该模块会将数据序列化成字节数据
(1)pickle.dumps()#序列化
两者加上IO就实现了持久化
(2)pickle.loads()#反序列化
(3)pickle.dump(ls,open("a.txt","bw"))#一步到位实现序列化和反持久化
(4)pickle.load(open("a.txt","bw"))#实现反持久化
json模块
该模块会将数据序列化成字符串数据
因为不是所有的对象都有特定的字符串表示格式,所以json模块只能处理一些常见的类型(list,set,tuple,dict)
(1)与pickle的四个模块用法一样(因为不是所有的对象但是特定的字符串表示格式,所有json只能处理一些常见的类型,json本质上就是用来处理dict类型的。与JavaScript交互)
(2)shelve模块
python面向对象
C语言是面向过程(将大问题分解为n个小问题,小问题分装成函数,面向函数)的编程
C++、java这些是面向对象(分类:抽取事物的共性,将相似事物归纳为一个类别)的编程
面向对象的核心概念:
类:就是一个事物的类别
对象:某一个类别中的具体案例
python进行面向对象(oop)编程:
面向对象的专业术语:
OO:面向对象
OOP:面向对象的编程
OOA:面向对象的分析
OOD:面向对象的设计
OOT:面向对象的测试
面向对象的三大特征:
(1)封装
在面向对象中,封装有两层含义:
1.类封装属性和方法
2.基于安全性考虑,面向对象会将属性私有化,提供合法的渠道进行访问的方式
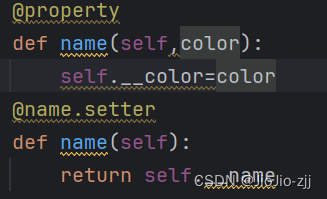
封装的三种写法:
(1)在属性或者方法前面加__,方法私有化只可以在类里面调用
(2)
(3)
python的标识符命名的特殊规范:
1.所有都是大写的,表示常量
2.大驼峰一般表示类
3._....
from ...... import * #模块的封装
4.__.... #魔法属性或者魔法方法
5.__.... #封装属性或者方法
(2)继承
类与类之间,目的:复用代码
class class_name(父类(super class基类或者超类)#默认继承object)
- class RichWeman(object):
-
- def __init__(self):
- self.money=100000000000
- self.company="强盛集团"
- self.__secretary="小红秘书"
- def speak(self):
- print("我看不清楚,我眼瞎!!!")
- def __show_self(self):
- print("悄悄话不能告诉你!")
-
- class Son(RichWeman):
- pass
- """
- class Son(RichWeman):
- def __init__(self):
- #super()是一个指针,指向父类!!!
- super().__init__()
- #如果字类初始化函数不存在,则会根据继承去初始化父类的初始化函数
- #如果字类初始化,要在字类的初始化函数的第一行调用父类初始化函数
- self.name="儿子"
- #方法重写,会继承自己的speak()函数的内容
- def speak(self):
- print("我看的清楚,我眼睛清亮!!!")
- """
- if __name__=="__main__":
- s=Son()
- print(s.money)
- print(s.company)
- s.speak()
python通过装饰器解决重载问题
(3)多态(面向对象的核心)
多态是在继承的基础上,父类引用指向子类实例的现象:List list=new ArrayList()
像python这种弱数据类型编程语言天生就支持多态
使用面向对象实现去重:
- class ListNode:
- def __init__(self, val, next = None):
- self.val = val
- self.next = next
- class Solution:
- def deduplication(self, head: ListNode) -> ListNode:
- if head is None:
- return head
- temp=head
- while temp.next is None:
- while temp.val == temp.next.val:
- temp.next = temp.next.next
- temp=temp.next
- return head
- if __name__=="__main__":
- pass
(1)定义类
分析类的共性--->静态特征:属性
--->动态行为特征:函数(方法)
class 类名称(父类#or什么都不写,代表有一个共同的父类object):
#定义类的成员
(2)创建对象
(3)调用对象的属性或者方法,完成具体案例
异常(Exception)处理
异常,非正常现象:一般指的是软件运行时出现一些可控或者可处理的错误
注意:异常是一种错误,但是错误不一定时异常。致命性的错误只能通过修改代码;异常是可以控制或者忽略
针对异常,进行的处理被称为异常处理;目的:保证软件的稳定性、增强软件的容错能力
(1)try catch #进行异常抓捕的处理
try:
except<异常名称>:
else:
没有异常时执行的代码
finally:
无论是否有异常都会执行的代码
- def divide(x,y):
- result=0
- try:
- result=x/y
- num = int(input(">>>"))
- print(num+100)
- except ZeroDivisionError as e:
- print(e)#打印错误信息
- print("对不起,除数不为0!")
- except ValueError:
- num=int(input("int函数只能接受数字字符串,不能转换其他类型"))
- print(num + 100)
- #所有异常的父类都是Exception,使用多态捕获其他异常的处理方案
- except Exception:
- print("其他异常处理方案")
- #根据需要书写
- else:
- print("没有任何异常被捕获时,才会有else中代码;只要进入except,就不会输出 else中的代码")
- return result
- finally:
- print("无论是否有异常都执行")#放一些必须执行和重要的代码,像关闭IO、回收资源、是否内存等等核心必须要执行的代码
- if __name__ == "__main__":
- a=float(input("第一个数:"))
- b=float(input("第二个数:"))
- divide(a,b)
- #为了利用finally的特点可能存在如下语法结构
- try:
- pass
- finally:
- .......
- #return先发生,finally执行不会影响return值
- return ...
- finally:
- ...
- #return先发生,finally执行会影响return值
- return ...
- finally:
- return ...
- ...
(2)断言处理(一般不使用,主要使用到软件测试上)
正则表达式
匹配模式(regular expression),独立于编程语言存在的技术。正则表达式使用一个模块re。
re.compile #编译
eg:re.compile(r"a",re.I).findall() #re.I修改正则的规则,忽略a的大小写
re.findall #re.findall("\d+",ss),返回匹配ss中的数字
re.finditer #与findall作用基本一样,只不过返回迭代器
re.match("...",s) #变量s是否以"..."开始
re.split #以什么分割
eg:re.split("\.","www.baidu.com") #以.作为分割输出
re.sub #替换
re.search #re.search("\d+",s).group() 懒惰匹配,查询s中一个数字,search返回的是迭代器,加上.group(),返回数值
元字符:
. #匹配除换行符以外的任意单位符号
\w #匹配有效符号(有的中文也是有效符号,有的编程语言规则略有不同),不匹配特殊符号
\d #匹配数字
\s #匹配空白位(空格,制表符\t)
^ #匹配字符串的开始
$ #匹配字符串的结束
\b #匹配单词的开始或者结束
eg:re.findall("^g.*d$",s) #匹配s以g开头d结尾的词;
re.findall("g.*d",s) #匹配s中以g开头d结尾的词
[] #匹配一个位,列举,只能是中括号中的某一个符号充当
[0-9] or [0123456789] #表示的是数字0到9
[a-z] #匹配小写字母(是按照ASCII码表来的)
[A-Z] #匹配大写字母
[A-Za-z] #匹配大小写字母
[_0-9a-zA-Z] #匹配有效符号,适用于所有编程语言
[\u4e00-\u9fa5] #匹配的是所有中文
eg:re.match("t[abcdef]",s) #匹配s中是否以t开头然后必须是[]里面的某一个位
反义符:
\D #匹配非数字
\W #匹配非有效符号,匹配特殊符号
\S #匹配非空白位
[^ansna] #不能以[]中的某一个字符组成,与^[ansna]相反
转义符:
斜杠在python中是转义字符,以及正则表达式里面也有意义,所以使用四个斜杠或者用r去除斜杠在python字符串中的意义,排除python对它的影响!!!
p="c:\\a\\b"
re.match("c:\\\\a\\\\\b",p)
re.match(r"c:\\a\\b",p)
re.match("\w+@qq\.com","271978@qq.com")
重复、位数问题:
* #0~多位
+ #1~多位
? #表示0或者1
eg:/? #/要么有要么没有
{n} #n位
{n,} #至少n位
{m,n} #在m到n区间范围内,最多n位最少m位
分组:
正则的二次筛选
re.findall(r"<div>(.*)</div>",s)
#返回(.*)里面的内容
re.match(r"<(\w+)>.*</\w+>",s).group(1)#求标签的内容,1就是第一个括号
re.findall(r"<(\w+)>(.*)</\w+>",s)[0][0]#得到第一个括号里面的值
re.findall(r"<(\w+)>(.*)</\w+>",s)[0][1]#得到第二个括号里面的内容
re.sub(r"\n|\r|\s+","",ss)#sub是替换,将转义字符转化为空并输出

正则表达式的表达模式:
(1)贪婪模式:尽可能多的去匹配结果
(2)非贪婪模式(懒惰模式):只要匹配到结果,会立刻返回
贪婪模式--------->懒惰模式 #以下符号就是贪婪模式,在原本的以下符号后加上一个?,就可以转换为懒惰模式,就可以在重复的去除某个东西时,精准匹配
eg:
*
+
?
{n,}
{m,n}
is和等于符号的区别
is和==都是用来判断变量的
is判断的是两个变量的内存地址
==判断的是两个变量的值
python 内存中有一个数据区,数据区存的是常量,固定不变的值,缓存数据等;python中有一个小整型缓存区(-5 ----256 ),当在这个范围内就不开辟新空间存储数字了;除了小整型缓存区还有字符串缓存区,但是字符串不能包含特殊的符号。
eg: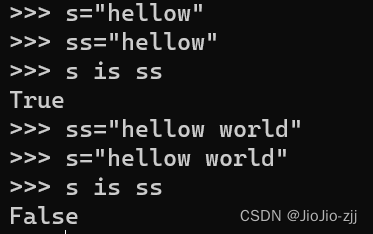
列表推导式的使用
想生成一个0~100的列表:ls1 = [x for x in range(101)]
打印0~100内所有偶数的列表:ls2 = [i for i in range(101) if i % 2 ==0]
生成一个0~9的任意两个数相乘的列表:ls3 = [i*j for i in range(10) for j in range(10)]
列表推导式所占空间比较大,所以选择列表生成器进行列表生成
列表生成器
在列表推导式基础上只要把[]换成()
生成器是一个算法,通过next()计算值,所以占内存小,没调用一次next(),返回下一个值,直到抛出异常
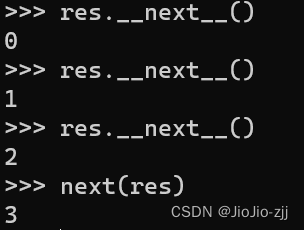
yield关键字和函数转换为生成器对象
数据一直存储在列表里,也是会造成内存占用过大的问题,函数转换为列表生成器,通过yield关键字(类似于return),整个函数的返回值是一个生成器
当一个函数出现yield,那么这个函数被调用执行,而且返回值是一个生成器next它的返回值,不断地返回被调用yield的值
yield值之后,会记住当前位置,下一次next函数调用生成器的时候,会在记住的位置继续执行
- ls=[]
- def fibonacci(num):
- first, second = 1, 1
- index = 0
- while index < num:
- first, second = second, first+second
- yield first #和return相似 会返回值
- index += 1
- if __name__ == '__main__':
- #fibonacci(10)
- #fibonacci(1000) #占用内存
- # print(ls)
- res = fibonacci(10) #没有任何输出结果
- print(res) #打印生成器对象
- print(next(res))
- print(next(res))
- print(next(res))


