
热门标签
热门文章
- 1css实现两列布局,一列固定宽度,一列宽度自适应方法_css表格宽度怎么自动适应
- 2安装torch-geometric_torch-geometric 2.1.0.post1安装
- 33102. 最小化曼哈顿距离——leetcode
- 4【微信小程序】小程序群分享获取分享信息_小程序分享聊天群获取信息
- 5《基于 Kafka + Flink + ES 实现危急值处理措施推荐和范围校准》_基于 kafka + flink+es 实现危急值处理措施推荐和范围校准
- 6java前端开发jquery_web前端开发JQuery常用实例代码片段(50个)
- 7在vue中webSocket通信_vue websocket header
- 8为什么不建议在 MySQL 中使用 UTF-8?_mysql问什么不建议使用utf8
- 9深度学习:自然语言处理与Finetuning
- 10德州仪器2024届校招 FAE&;AE&;TSE_芯片tse fae ae
当前位置: article > 正文
无监督学习和强化学习
作者:Guff_9hys | 2024-07-18 17:35:48
赞
踩
无监督学习和强化学习
无监督学习:
不含有“目标”的机器学习问题通常被为无监督学习。
无监督学习回答下列问题:

环境
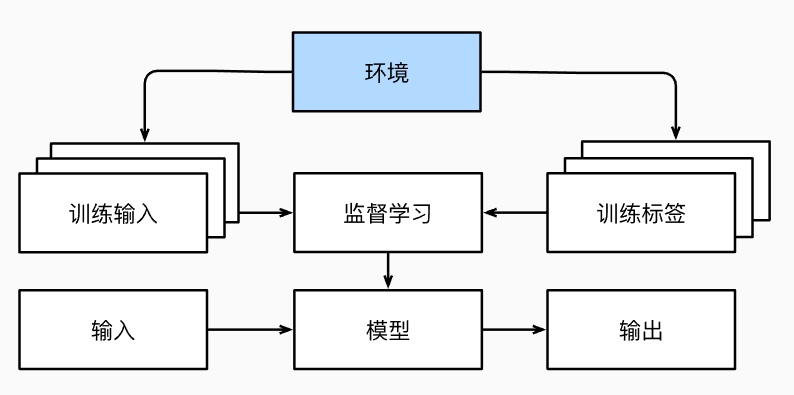
优点:我们可以孤立地进行模式识别,而不必分心于其他问题。
缺点:解决的问题相当有限。
强化学习
在强化学习问题中,智能体(agent)在一系列的时间步骤上与环境交互。 在每个特定时间点,智能体从环境接收一些观察(observation),并且必须选择一个动作(action),然后通过某种机制(有时称为执行器)将其传输回环境,最后智能体从环境中获得奖励(reward)。 此后新一轮循环开始,智能体接收后续观察,并选择后续操作,依此类推。 强化学习的过程在图中进行了说明。 请注意,强化学习的目标是产生一个好的策略(policy)。 强化学习智能体选择的“动作”受策略控制,即一个从环境观察映射到行动的功能。
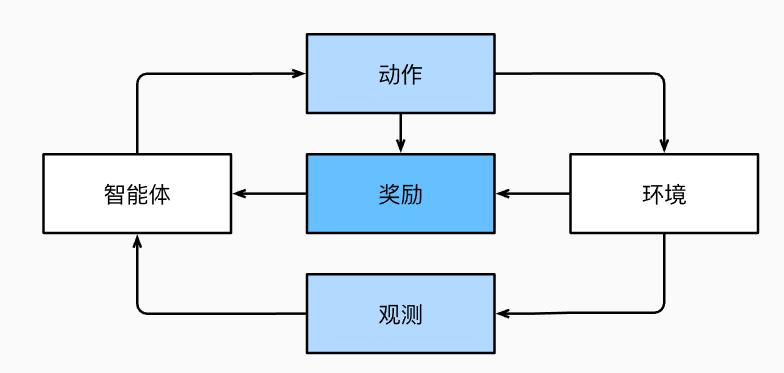
强化学习框架的通用性十分强大。例如,我们可以将任何监督学习问题转化为强化学习问题。 当然,强化学习还可以解决许多监督学习无法解决的问题。
强化学习可能还必须处理部分可观测性问题。
强化学习智能体必须不断地做出选择:是应该利用当前最好的策略,还是探索新的策略空间(放弃一些短期回报来换取知识)。
当环境可被完全观察到时,强化学习问题被称为马尔可夫决策过程(markov decision process)。 当状态不依赖于之前的操作时,我们称该问题为上下文赌博机(contextual bandit problem)。 当没有状态,只有一组最初未知回报的可用动作时,这个问题就是经典的多臂赌博机(multi-armed bandit problem)。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Guff_9hys/article/detail/846904
推荐阅读
相关标签

