
- 1Mac环境下Parallels Desktop 19的安装和使用_parallels desktop 19 for mac
- 2react apollo_使用GraphQL和Apollo React Hooks构建餐票应用程序
- 3Android 使用 Gson 解析 json 数据及生成_gradle 导入gson
- 4Jeecg | 如何解决 ERR Client sent AUTH, but no password is set 问题_jeecg err client sent auth, but no password is set
- 5KUKA机器人EthernetKRL通讯客户端(ASCII码格式)_ethernetkrl2.8
- 6无情的独裁者-特斯拉的马斯克_space x 马斯克 没有人情味的老板
- 7Python常用方法_python方法
- 8python微信PC端自动化-获取聊天记录_wxauto实时获取微信群聊记录
- 9nginx配置证书和私钥进行SSL通信验证_nginx 证书
- 10网络安全概论——TCP/IP协议族的安全性_tcp通讯安全
【目标检测】23、Generalized Focal Loss V2
赞
踩

代码:https://github.com/implus/GFocalV2
出处:CVPR2021
效果:
- GFLV2 非常轻量级,可以嵌入很多检测器中,提高约 2AP,带来的额外计算很少
- GFLV2 (Res2Net-101-DCN) 在 COCO 上获得了 53.3 AP
- 通过可视化,可以看出在 NMS 过程中能起到很好的作用,能够更好的保留位置更准的框
一、背景
Localization Quality Estimation(LQE)位置质量估计,在密集预测的中很有用,可以用来在 NMS 中辅助框排序。
早期的很多目标检测器(如 Faster RCNN、Mask RCNN、Cascade RCNN 等)都是用分类得分来作为 LQE score。这就造成了一些不公平性,因为分类得分高的,不一定位置准确。
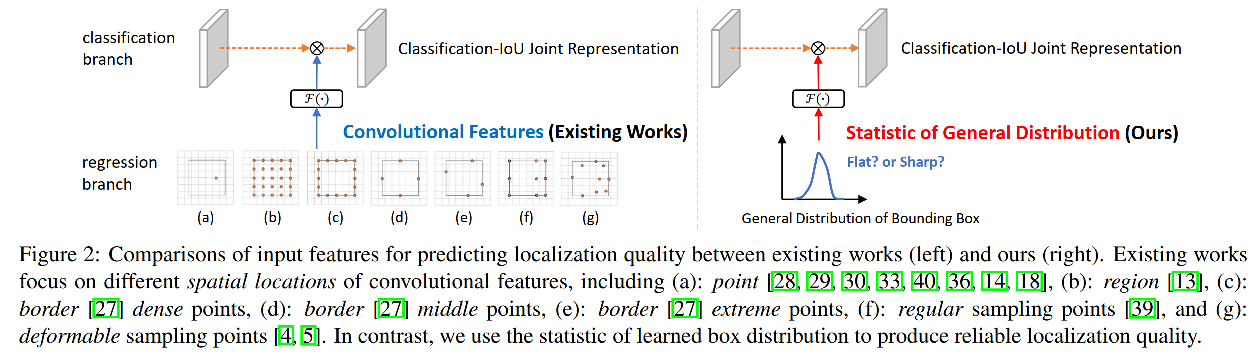
然后就出现了一些方法,会额外衡量位置特征的质量,早期很多方法直接通过卷积特征来预测 LQE score,如点、边缘、区域等(如图2a-2g)
- YOLO 中提出了 objectness,使用真值和预测框的 IoU 来描述位置质量。随后,又有很多网络进一步使用了 IoU,如 IoU-Net、IoU-aware、PAA、GFLV1、VFNet等
- FCOS 和 ATSS 中提出了 centerness,来衡量目标 center 的距离,来抑制 low-quality 的检测结果
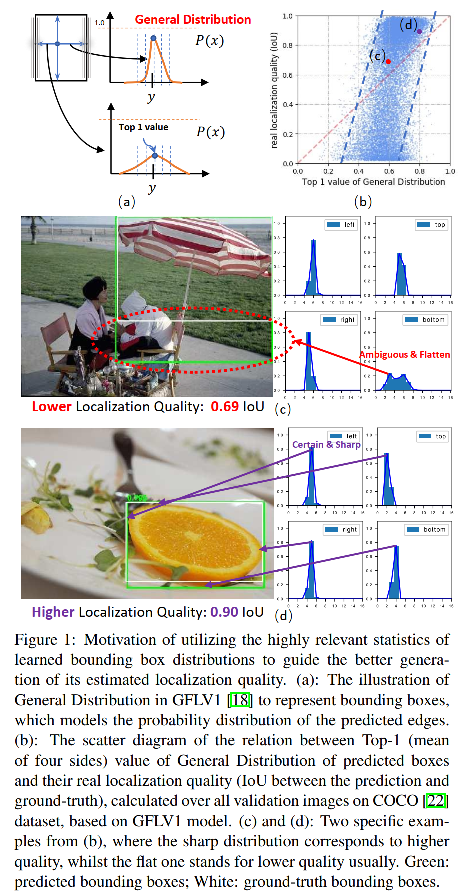
GFLV1 中提出了 generalize distribution,来定义更一般化的位置分布,且发现了边界模糊与否和分布的关系(越模糊,分布越平缓,甚至双峰),但没有好好的用这个分布。
GFLV2 就利用了分布的统计信息,来提取位置的 score,来指导模型的训练。
从图 1b 可以看出,把预测框分布的 Top-1 和 IoU 做了一个分布展示,可以看出有很强的相关性(这里的 Top-k 是指分类得分)。
如图 1a 中,General Focal loss 建立的分布其实是 anchor point 到左上右下四个边的位置,如果某个边模糊性大一些,则 anchor point 到该边的距离就会是一个比较缓的分布,甚至会有多个峰值。
如图 1c 中,右侧为遮阳伞的四个边的分布,其中横轴为 0-16,这个范围是 GFV1 中,作者对所有 gt bbox 映射到特征图维度,并计算所有 coco 数据集中正样本的回归范围,发现最大值大概可以设置为 16,也就是说分布长度可以设置为 16+1,而且需要特别指出不同的数据集由于分布不一致,你可以需要针对你的数据特点重新确定这个超参。
二、方法
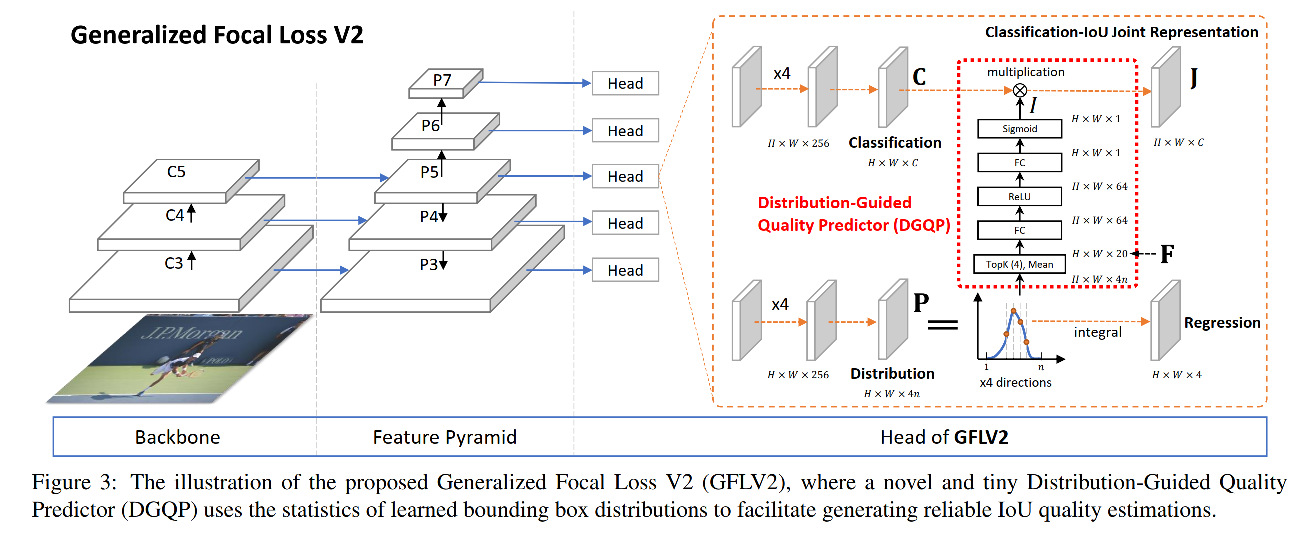
GFLv2 的结构(主要是比 V1 多了 DGQP 来衡量定位质量,V1 中使用的 IoU,其他的训练 loss 都是一样的):
- 分类分支:使用 QFL loss 来训练分类分支,学习的目标 J = I × C J = I \times C J=I×C,也就是回归分支的分布经过 DGQP 后的输出 I I I 和分类分支的分类得分 C C C 相乘,其中 I I I 也就是定位质量衡量指标 LQE
- 回归分支:同时使用 DFL(权重 0.25) 和 GIoU loss(权重 2)
GFLV1 中提出的 generalized 分布,用于将位置分布建模为一个更通用的分布,且发现了边界模糊与否和位置分布的关系(越模糊,分布越平缓),但没有好好用这个分布。GFLV2 使用了这个分布的统计信息,来提取位置得分,指导模型训练。
2.1 概况
本文作者提出了一种新的思考方向来计算 LQE:bbox 分布的统计信息,而非卷积特征,这里的 bbox 的分布是指 GFLV1 中提出的 General Distribution,也就是对每个边求其离散概率分布,该分布描述的是其位置的不确定性(图1a)。
为什么使用 bbox 分布的统计信息?
作者认为 the statistic of General Distribution 和其 localization quality (LQE)有很强的相关性,如图 1b 所示。
为什么有很强的相关性?
如图 1c 和 1d, bbox 分布的形状可以反应其预测结果的 localization quality
- 分布越尖锐,预测的框越准确
- 分布越平缓,预测的框越不准
本文核心点:提出 Distribution-Guided Quality Predictor (DGQP),来学习统计信息和 LQE score 的关系
由于发现了 bbox 分布的统计信息和 LQE score 的相关性,作者提出了一个轻量级子网络(只有很少的 hidden units),输入统计信息,输出 LQE score。
GFLV2 和 GFLV1 的不同:
- GFLV2 分解了 GFLV1 的联合特征表达
- GFLV2 引入了 DGQP,对 GFLV1 提出的的 general 分布统计信息提取,得到 LQE score 作为框位置的得分,指导训练。
2.2 Generalized Focal Loss V1
1、Classification-IoU Joint Representation
GFLV1 中的联合表示,是为了缓解训练和测试的不一致性(训练分开训练,测试合并使用)
联合表示的方式:当预测类别是真实类别时,联合表示特征 J = I o U J=IoU J=IoU,否则为 0
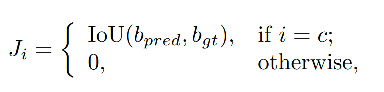
2、General Distribution of Bounding Box Representation
GFV1 中,提出了使用 general distribution P ( x ) P(x) P(x) 来表示预测框的四个边的分布(而非简单的狄拉克分布)
每个边的预测 y ^ \hat{y} y^ 为:
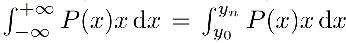
离散化为 [ y 0 , y 1 , . . . , y n ] [y_0, y_1, ..., y_n] [y0,y1,...,yn]
该离散分布有一个特性: Σ i = 0 n P ( y i ) = 1 \Sigma_{i=0}^nP(y_i)=1 Σi=0nP(yi)=1(因为所有概率之和为 1)
所以估计的 y ^ \hat{y} y^ 可以表示如下:
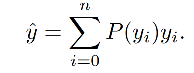
相比于 delta 分布,general distribution 可以更准确的反应预测的质量(图1c和图1d)。
2.3 Generalized Focal Loss V2
1、Decomposed Classification-IoU Representation
尽管 V1 中的联合表达能够解决训练和测试过程中的不一致问题,但只使用分类得分来控制联合表达还是有些局限性的。
所以在 V2 中,作者同时使用分类分支(C)和回归分支(I)的特征(经过DGQP的输出得到的),来作为联合表达,虽然 J J J 是由两个因子构成的,但作者会将其同时用于训练和测试阶段,来避免不一致性。
J = C × I J=C \times I J=C×I
- C = [ C 1 , C 2 , . . . , C m ] , C i ∈ [ 0 , 1 ] C=[C_1, C_2, ..., C_m], C_i\in[0, 1] C=[C1,C2,...,Cm],Ci∈[0,1]
- I ∈ [ 0 , 1 ] I\in[0,1] I∈[0,1],表示 IoU 特征的信息,也就是 IoU 的质量估计。(下面有介绍 I I I 是如何得到的,如图 3 右半部分所示,是通过对回归分支的分布提取统计信息,经过 FC+ReLU+sigmoid 得到的特征)
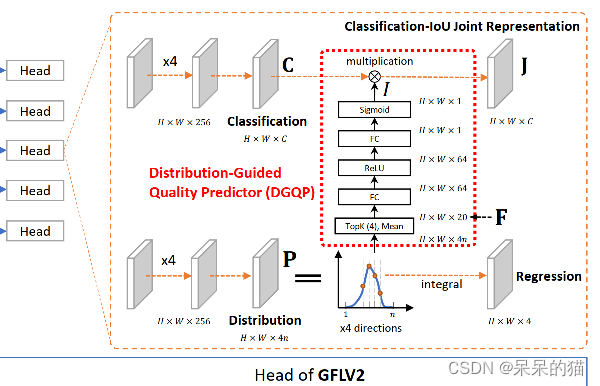
2、Distribution-Guided Quality Predictor
DGQP 是 V2 的核心(图 3 红框中),该模块将分布的统计信息作为输入,IoU 特征 I I I 作为输出。
方便起见,将框的左、右、上、下共四个边定义为 l , r , t , b {l, r, t, b} l,r,t,b,其离散概率定义为:
P w = [ P w ( y 0 ) , P w ( y 1 ) , . . . , P w ( y n ) ] , w ∈ l , r , t , b P^w=[P^w(y_0), P^w(y_1),..., P^w(y_n)], w\in{l, r, t, b} Pw=[Pw(y0),Pw(y1),...,Pw(yn)],w∈l,r,t,b
经过实验,作者选择 P w P^w Pw 的前 Top-k 值和均值,并且将两者 concat 起来,得到统计特征 F ∈ R 4 ( k + 1 ) F\in R^{4(k+1)} F∈R4(k+1)
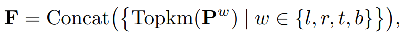
- Topkm:前 Top-k 值和均值
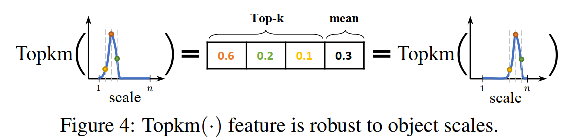
为什么要同时选择前 Top-k 值和均值?
- P w P^w Pw 的和是固定的( Σ i = 0 n P w ( y i ) = 1 \Sigma_{i=0}^n P^w(y_i)=1 Σi=0nPw(yi)=1),前 Top-k 值和均值可以很好的反应分布的形态,如:大、小、缓、陡等
- 前 Top-k 值和均值对分布的偏移不敏感,可以对目标的尺度保持更好的鲁棒性,如图 4
得到统计特征 F 后,如何得到 IoU 质量估计?
构建网络 F ( . ) F(.) F(.):只有两个全连接层,后面接 Relu 和 Sigmoid
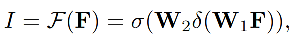
- δ \delta δ:Relu
- σ \sigma σ:Sigmoid
- W 1 ∈ R p × 4 k + 1 W_1\in R^{p\times4{k+1}} W1∈Rp×4k+1, k k k 是 Top-k 个参数(k=4)
- W 2 ∈ R 1 × p W_2\in R^{1\times p} W2∈R1×p, p p p 是 hidden layer 的通道(p=64)
三、效果
3.1 消融实验
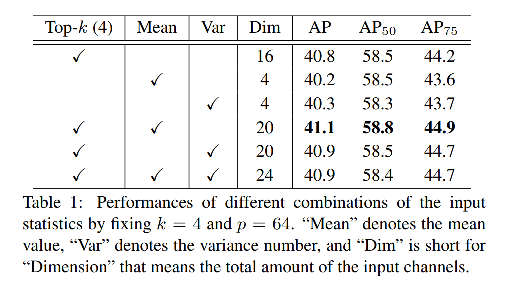
1、Top-k 和 mean 结合方式
对于 generaliz distribution 的统计信息,有 Top-k,mean,var 等多种形式,如表 1 所示,使用 Top-k,mean,表现最好,且 k=4,p=64。
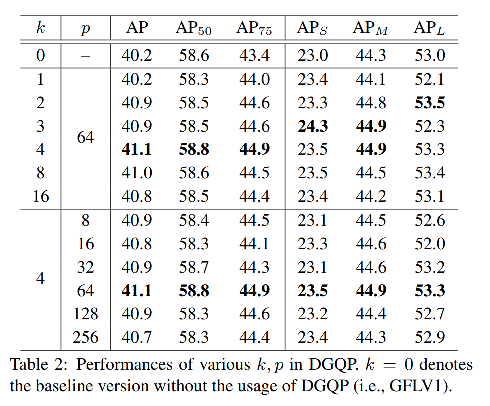
2、DGQP 的结构
固定一个参数,调节另外一个参数,结果见表 2,k=4,p=64 表现最优
3、DGQP 输入的形式
GFLV2 在提出的时候是第一个使用统计信息来生成 LQE 的方法,由于分布的统计信息和 LQE score 有很强的相关性。
作者为了验证实验不同卷积特征作为输入,对输出的影响,使用了如图 2 所示的 7 种不同特征作为输入来生成 LQE,对 AP 的影响,结果见表 3。

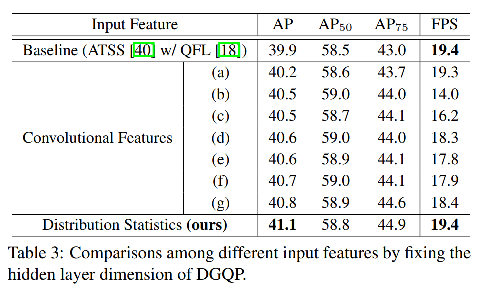
4、Usage of the Decomposed Form
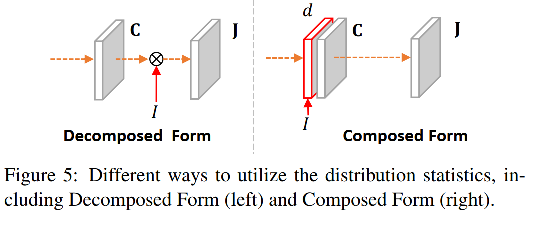
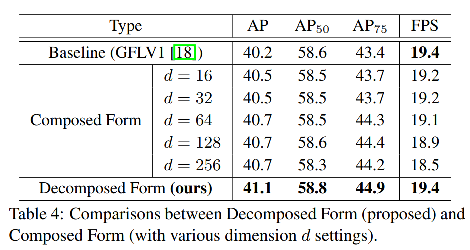
为了探索 Classification-IoU 联合表达的最优方式,作者对比了“组合”和“非组合”两种方式
非组合: 如图 5 左侧, J = C × I J=C \times I J=C×I
组合: 如图 5 右侧, J J J 仅由 C 决定,类别正确的保留 IoU,类别错误的直接剔除
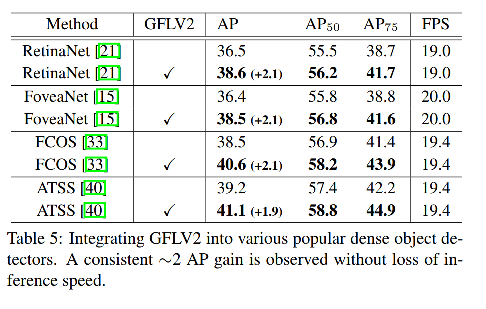
5、和密集检测器的结合
GFLV2 非常轻量,并且可以用于很多检测器,如表 5 所示,基本上可以带来 2 AP 的提升,且速度基本没降低。
3.2 和 SOTA 对比
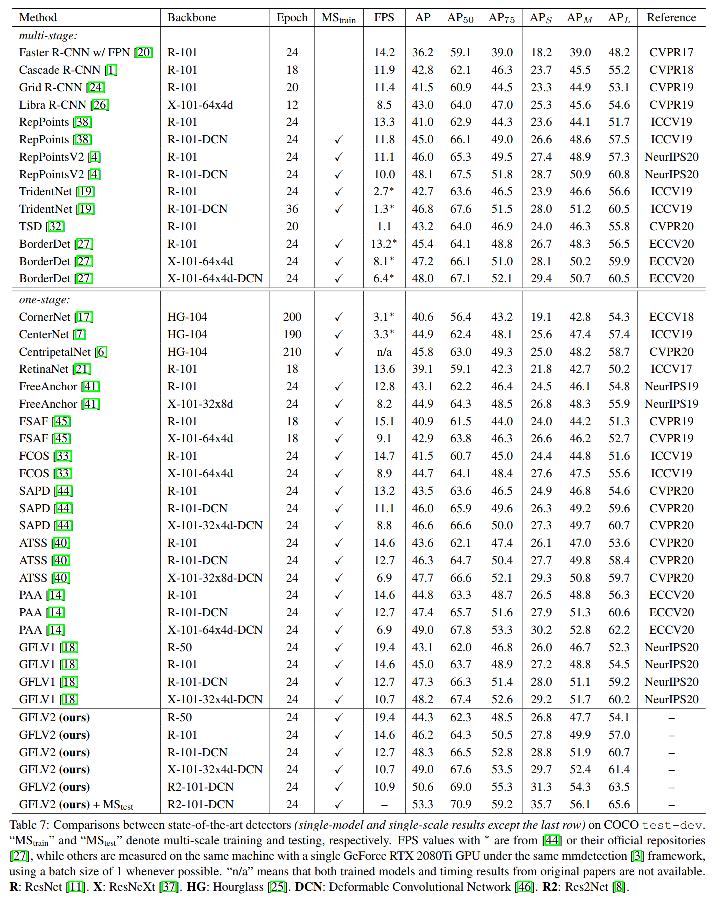
3.3 分析
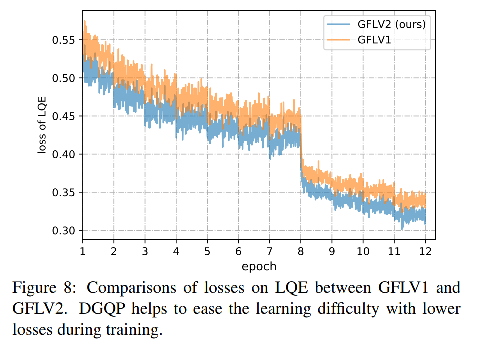
1、DGQP 能够降低网络学习难度,如图 8 所示
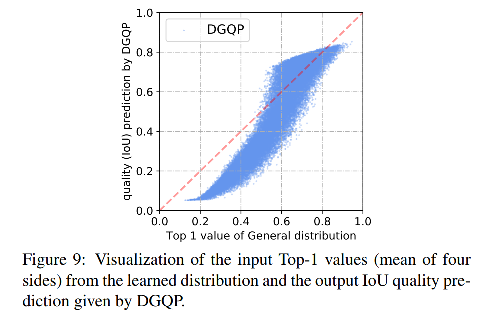
2、DGQP 的输入输出有很强的联系,如图 9 所示
3、GFLV2 能够在 NMS 的时候使用更可靠的 IoU quality 来提升预测效果,如图 7 所示


