
- 1举例详细学习和分析后端业务逻辑代码开发思路(二)
- 2Linux驱动开发—平台总线模型详解
- 3Duilib的简单使用(一、duilib demo)
- 4喜大普奔!VMware Workstation Pro 17.5 官宣免费!_vmware-workstation-full-17.5.2-23775571.exe
- 5群晖修改php文件系统,群晖6.2版本修改eSATA挂载NTFS硬盘设置方法
- 6BurpSuite安装教程以及环境配置(附安装包)_burp环境配置
- 7微软 Win11 Dev 预览版 Build 23570 发布,修复文件资源管理器卡顿问题_windows feature experience pack 1000.23570.1001
- 8JAVA中最基本最常用的功能_Java最常见的208道面试题 _Java基础
- 9太逼真了!Gen-3 Alpha重磅发布,Sora最强竞争对手!
- 10undetected_chromedriver的介绍|在Python中的应用_undetected-chromedriver
如何训练一个大模型:LoRA篇_lora训练
赞
踩
目录
写在前面
现在有很多开源的大模型,他们一般都是通用的,这就意味着这些开源大模型在特定任务上可能力不从心。为了适应我们的下游任务,就需要对预训练模型进行微调。
全参数微调有两个问题:在新的数据集上训练,会破坏大模型原来的能力,使其泛化能力急剧下降;而且现在的模型参数动辄几十亿上百亿,要执行全参数微调的话,他贵啊!!

于是LoRA出现了, LoRA(Low-Rank Adaptation)是微软提出的一种参数有效的微调方法,可以降低微调占用的显存以及更轻量化的迁移。同时解决了上述两个问题,那它凭什么这么厉害?往下看吧。
一、LoRA算法原理
1.设计思想
论文地址:https://arxiv.org/pdf/2106.09685
模型是过参数化的,它们有更小的内在维度,模型主要依赖于这个低的内在维度(low intrinsic dimension)去做任务适配。假设模型在适配任务时参数的改变量是低秩的,由此引出低秩自适应方法lora,通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
上面那段话也许有点难以理解。简单来讲,LoRA是大模型的低秩适配器,或者就简单的理解为适配器,在图像生成中可以将lora理解为某种图像风格(比如SD社区中的各种漂亮妹子的lora,可插拔式应用,甚至组合式应用实现风格的融合)的适配器,在NLP中可以将其理解为某个任务的适配器(比如基于通用大模型训练的各个领域的专家大模型)。
2.具体实现
LoRA的实现方式是在基础模型的线性变换模块(全连接、Embedding、卷积)旁边增加一个旁路,这个旁路是由两个小矩阵做内积得来的,两个小矩阵的中间维度,就是秩!!
通过低秩分解(先降维再升维)来模拟参数的更新量。
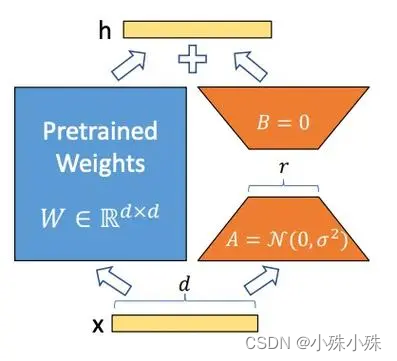
下面是LoRA的公式:
上面公式中x是这一层的输入,h是这一层的输出,是基础模型的权重参数;A和B是两个小矩阵,A的输入和B的输出形状跟
一样,A的输出和B的输入一样,称为秩,秩一般很小,微调的所有“新知识”都保存在A和B里面;
是一个缩放系数,这个数越大,LoRA权重的影响就越大。
下面就是经典的LoRA运算流程图:
我们以ChatGLM的attention模块的query_key_value(是一个linear(4096, 12288))为例,描述一下流程,其中输入4096、输出12288,LoRA的秩是8:
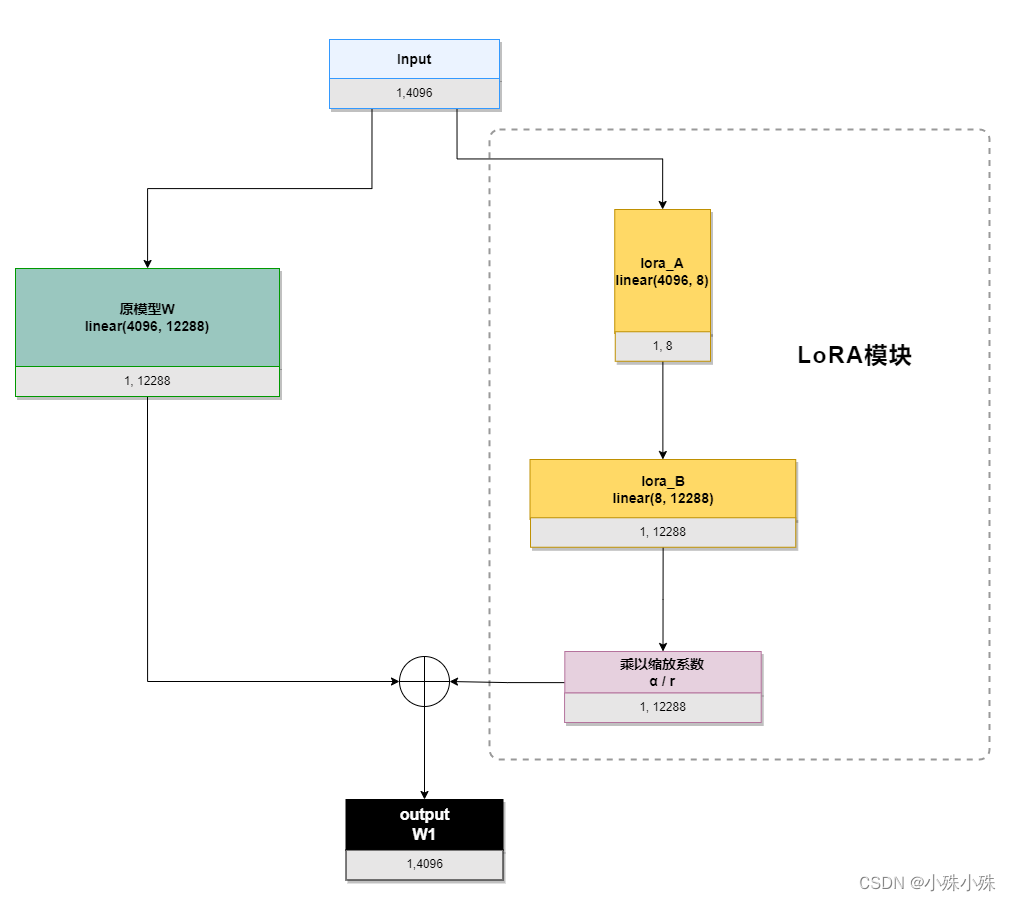
初始化时,lora_A采用高斯分布初始化,lora_B初始化为全0,保证训练开始时旁路为0矩阵;
训练时,原模型固定,只训练降维矩阵A和升维矩阵B;
推理时需要做参数合并,就是将AB的内积(一个与基础模型形状一样的低秩矩阵)加到原参数上,这样不引入额外的推理延迟。对于上图的例子,lora_A与lora_B做内积,得到4096x1228的参数矩阵,然后与基础模型W相加就可以了。
我们来算算需要训练多少参数,如果是全参数需要训练4096*12288=50331648个参数,LoRA需要训练4096*8+8*12288=131072,参数可是数量级的减少啊。
二、peft库
Pytorch中peft库实现了LoRA算法,而且使用非常方便,我们以ChatGLM代码为例,看一下LoRA对ChatGLM模型做了什么,直接上代码:
- from peft import LoraConfig, TaskType, get_peft_model
- from transformers import AutoModel, HfArgumentParser, TrainingArguments
-
- from finetune import CastOutputToFloat, FinetuneArguments
-
-
- def count_params(model):
- for name, param in model.named_parameters():
- print(name, param.shape)
-
-
-
- def make_peft_model():
- # 初始化原模型
- model = AutoModel.from_pretrained(
- "THUDM/chatglm-6b", load_in_8bit=False, trust_remote_code=True, device_map="auto", local_files_only=True
- ).float()
-
-
- # 给原模型施加LoRA
- peft_config = LoraConfig(
- task_type=TaskType.CAUSAL_LM,
- inference_mode=True,
- r=8,
- lora_alpha=32,
- lora_dropout=0.1,
- target_modules=['query_key_value'],
- )
- model = get_peft_model(model, peft_config).float()
- count_params(model)
-
-
-
- if __name__ == '__main__':
- make_peft_model()

输出如下:
base_model.model.transformer.word_embeddings.weight torch.Size([130528, 4096])
base_model.model.transformer.layers.0.input_layernorm.weight torch.Size([4096])
base_model.model.transformer.layers.0.input_layernorm.bias torch.Size([4096])
base_model.model.transformer.layers.0.attention.query_key_value.base_layer.weight torch.Size([12288, 4096])
base_model.model.transformer.layers.0.attention.query_key_value.base_layer.bias torch.Size([12288])
base_model.model.transformer.layers.0.attention.query_key_value.lora_A.default.weight torch.Size([8, 4096])
base_model.model.transformer.layers.0.attention.query_key_value.lora_B.default.weight torch.Size([12288, 8])
base_model.model.transformer.layers.0.attention.dense.weight torch.Size([4096, 4096])
base_model.model.transformer.layers.0.attention.dense.bias torch.Size([4096])
base_model.model.transformer.layers.0.post_attention_layernorm.weight torch.Size([4096])
base_model.model.transformer.layers.0.post_attention_layernorm.bias torch.Size([4096])
base_model.model.transformer.layers.0.mlp.dense_h_to_4h.weight torch.Size([16384, 4096])
base_model.model.transformer.layers.0.mlp.dense_h_to_4h.bias torch.Size([16384])
base_model.model.transformer.layers.0.mlp.dense_4h_to_h.weight torch.Size([4096, 16384])
base_model.model.transformer.layers.0.mlp.dense_4h_to_h.bias torch.Size([4096])
base_model.model.transformer.layers.1.input_layernorm.weight torch.Size([4096])
base_model.model.transformer.layers.1.input_layernorm.bias torch.Size([4096])......
可以看到模型中被添加了LoRA模块(红色部分),是根据全连接“query_key_value”生成的。因为query_key_value层输入是4096,输出是12288,而配置中LoRA的秩是8,所以两个LoRA块是(8,4096)和(12288, 8)
代码也很好理解,get_peft_model方法将原模型参数冻结并且根据配置向模型中添加LoRA模块。
解释一下配置LoraConfig,下面是这个对象的主要参数:
1.task_type:
SEQ_CLS:序列分类(Sequence Classification)任务。这种任务涉及对输入序列整体进行分类,例如情感分析、文本分类等。
SEQ_2_SEQ_LM:序列到序列语言建模(Sequence-to-Sequence Language Modeling)任务。这种任务能够将一个输入序列映射到另一个输出序列,例如机器翻译、文本摘要等。
CAUSAL_LM:因果语言建模(Causal Language Modeling)任务。这种任务涉及训练一个模型,使其能够预测给定先前上下文的下一个标记,例如自动补全、语言生成等。
TOKEN_CLS:标记分类(Token Classification)任务。这种任务涉及对输入序列中的每个标记进行分类,例如命名实体识别、词性标注等。
QUESTION_ANS:问答(Question Answering)任务。这种任务涉及根据给定的问题和相关的上下文文本来预测答案。输入是Prompt+问题。
FEATURE_EXTRACTION:特征提取(Feature Extraction)任务。这种任务涉及从文本或序列中提取有用的特征,以供其他任务或模型使用。
2.r:LoRA秩的维度,这数越大,微调带来的“影响”越强,但是需要训练的参数量会增加。
3.lora_alpha:LoRA在前向传播的过程中引入一个额外的扩展系数(scaling coefficient),用于将LoRA权重应用于预训练权重。这个数越大,LoRA权重的影响就越大。
4.target_modules:要施加LoRA的模块名称,需要注意的是,参数是字符串数组,模块类型必须是`torch.nn.Linear`, `torch.nn.Embedding`, `torch.nn.Conv2d`, `transformers.pytorch_utils.Conv1D`中的一个。比如这个例子中还可以填写"word_embeddings"和"dense"。
三、完整的训练代码
现在给出一个完整的基于LoRA的ChatGLM训练代码,peft库在原模型基础上添加LoRA非常方便,对代码的侵入也很小。下面的代码我添加了注释,流程还是很清楚的:
- from transformers.integrations import TensorBoardCallback
- from torch.utils.tensorboard import SummaryWriter
- from transformers import TrainingArguments
- from transformers import Trainer, HfArgumentParser
- from transformers import AutoTokenizer, AutoModel
- import torch
- import torch.nn as nn
- from peft import get_peft_model, LoraConfig, TaskType
- from dataclasses import dataclass, field
- import datasets
- import os
-
-
- tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
-
-
- @dataclass
- class FinetuneArguments:
- dataset_path: str = field(default="data/alpaca")
- model_path: str = field(default="output")
- lora_rank: int = field(default=8)
-
-
- class CastOutputToFloat(nn.Sequential):
- def forward(self, x):
- return super().forward(x).to(torch.float32)
-
-
- def data_collator(features: list) -> dict:
- len_ids = [len(feature["input_ids"]) for feature in features]
- longest = max(len_ids)
- input_ids = []
- labels_list = []
- for ids_l, feature in sorted(zip(len_ids, features), key=lambda x: -x[0]):
- ids = feature["input_ids"]
- seq_len = feature["seq_len"]
- labels = (
- [-100] * (seq_len - 1) + ids[(seq_len - 1) :] + [-100] * (longest - ids_l)
- )
- ids = ids + [tokenizer.pad_token_id] * (longest - ids_l)
- _ids = torch.LongTensor(ids)
- labels_list.append(torch.LongTensor(labels))
- input_ids.append(_ids)
- input_ids = torch.stack(input_ids)
- labels = torch.stack(labels_list)
- return {
- "input_ids": input_ids,
- "labels": labels,
- }
-
-
-
- class ModifiedTrainer(Trainer):
- def compute_loss(self, model, inputs, return_outputs=False):
- return model(
- input_ids=inputs["input_ids"],
- labels=inputs["labels"],
- ).loss
-
- def save_model(self, output_dir=None, _internal_call=False):
- self.model.save_pretrained(output_dir)
-
-
- def main():
- writer = SummaryWriter()
- # 组织训练参数
- finetune_args, training_args = HfArgumentParser(
- (FinetuneArguments, TrainingArguments)
- ).parse_args_into_dataclasses()
-
- # init model
- model = AutoModel.from_pretrained(
- "THUDM/chatglm-6b", load_in_8bit=False, trust_remote_code=True, device_map="auto", local_files_only=True
- ).float()
- model.gradient_checkpointing_enable()
- model.enable_input_require_grads()
- # 模型是可以并行化的。
- model.is_parallelizable = True
- # 启用模型的并行化。
- model.model_parallel = True
- # 将模型的 lm_head(语言模型头)的输出转换为浮点数类型。
- model.lm_head = CastOutputToFloat(model.lm_head)
- # 禁用模型配置中的缓存,用于禁止缓存中间结果,可以减少显存占用,但是训练时间会变长
- model.config.use_cache = (
- False # silence the warnings. Please re-enable for inference!
- )
-
- # LoRA配置
- peft_config = LoraConfig(
- task_type=TaskType.CAUSAL_LM,
- inference_mode=False,
- r=finetune_args.lora_rank,
- lora_alpha=32,
- lora_dropout=0.1,
- )
- # 对模型使用LoRA
- model = get_peft_model(model, peft_config).float()
-
- # 使用alpaca数据集
- dataset = datasets.load_from_disk(finetune_args.dataset_path)
- print(f"\n{len(dataset)=}\n")
-
- # for d in dataset.iter(batch_size=1):
- # print("d:", d)
-
- # start train
- trainer = ModifiedTrainer(
- model=model,
- train_dataset=dataset,
- args=training_args,
- callbacks=[TensorBoardCallback(writer)],
- data_collator=data_collator,
- )
- trainer.train()
- writer.close()
- # 存训练后的参数
- model.save_pretrained(training_args.output_dir)
-
-
- if __name__ == "__main__":
- main()
训练之后模型文件会保存在output_dir目录中。到这里我们发现一个问题,毕竟LoRA在原模型的基础上加了分支,这会带来推理效率的降低,其实我们调用merge_and_unload方法就能将LoRA的分支模块合并到基础模型,推理代码如下:
- from peft import LoraConfig, TaskType, get_peft_model
- from transformers import AutoModel, AutoModelForSeq2SeqLM
- import torch
- from transformers import AutoTokenizer
-
- # 加载基础模型
- model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True, device_map='auto')
- tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
-
- # 配置LoRA
- peft_config = LoraConfig(
- task_type=TaskType.CAUSAL_LM, inference_mode=True,
- target_modules=['query_key_value'],
- r=8, lora_alpha=32, lora_dropout=0.1
- )
- # 对模型使用LoRA
- model = get_peft_model(model, peft_config).half()
- # 加载LoRA参数
- model.load_state_dict(torch.load("output/checkpoint-1000/adapter_model.bin", map_location=torch.device("cuda")), strict=False)
- # 将LoRA的分支模块合并到基础模型
- model.merge_and_unload()
-
- while True:
- prompt = input("Prompt: ")
- inputs = tokenizer(prompt, return_tensors="pt")
- model.params_dtype = torch.float32
- response = model.generate(input_ids=inputs["input_ids"],
- max_length=inputs["input_ids"].shape[-1] + 128)
- response = response[0, inputs["input_ids"].shape[-1]:]
- print("responseL", response)
- for r in response:
- print(r, ":", tokenizer.decode([r], skip_special_tokens=False))
- print("Response:", tokenizer.decode(response, skip_special_tokens=True))
四、总结
1.LoRA的实现方式是在原模型的线性变换模块(全连接、Embedding、卷积)旁边增加一个旁路,通过低秩分解(先降维再升维)来模拟参数的更新量。
2.LoRA模块由两个小矩阵组成,这两个矩阵内积的输入输出形状与原模型一致,大模型需要的“新知识”就存在这个模块中;
3.秩可以很小,有实验表明,就算秩=1,效果也不是很差;
4.尽量多的对模型中的线性变换模块使用秩很小LoRA;而不是对一个模块使用秩很大的LoRA;
5.推理时需要做参数合并,就是将AB的内积加到原参数上,从而不引入额外的推理延迟;
5.LoRA智能一定程度提升模型在某个领域的能力,并不能使模型发生根本性的能力提升。
LoRA就介绍到这里,关注不迷路(#^.^#)
关注订阅号了解更多精品文章

交流探讨、商务合作请加微信


