- 1统信UOS_麒麟KYLINOS上不覆盖高版本依赖包的情况下批量安装软件_kwre 统信(1)_同时安装多个kylin和uos
- 2jupyter下载tensorflow
- 3论文笔记--Llama3 report_llama3 论文
- 4Java语言程序设计考试题大全(含答案)_java题库及答案
- 5机器学习——聚类算法K-means_kmeans聚类 类别分不开
- 6使用Navicat生成ER关系图并导出_navicat生成数据库er图
- 7Apache2上部署SSL证书 提升安全等级_apache如何添加strict-transport-security
- 8软考-安全管理
- 9springboot集成 redis_springboot 集成redis 端口
- 10mysql 调用脚本_分享一个MySQL主从监控脚本—优化为钉钉告警
AI与数据库交互_vanna 千问
赞
踩
Vanna
Vanna项目是一个MIT许可的开源AI数据库交互项目,使用Python、RAG(检索增强生成)框架搭建。
⚠️MIT许可的开源项目,意味着Vanna可商用。
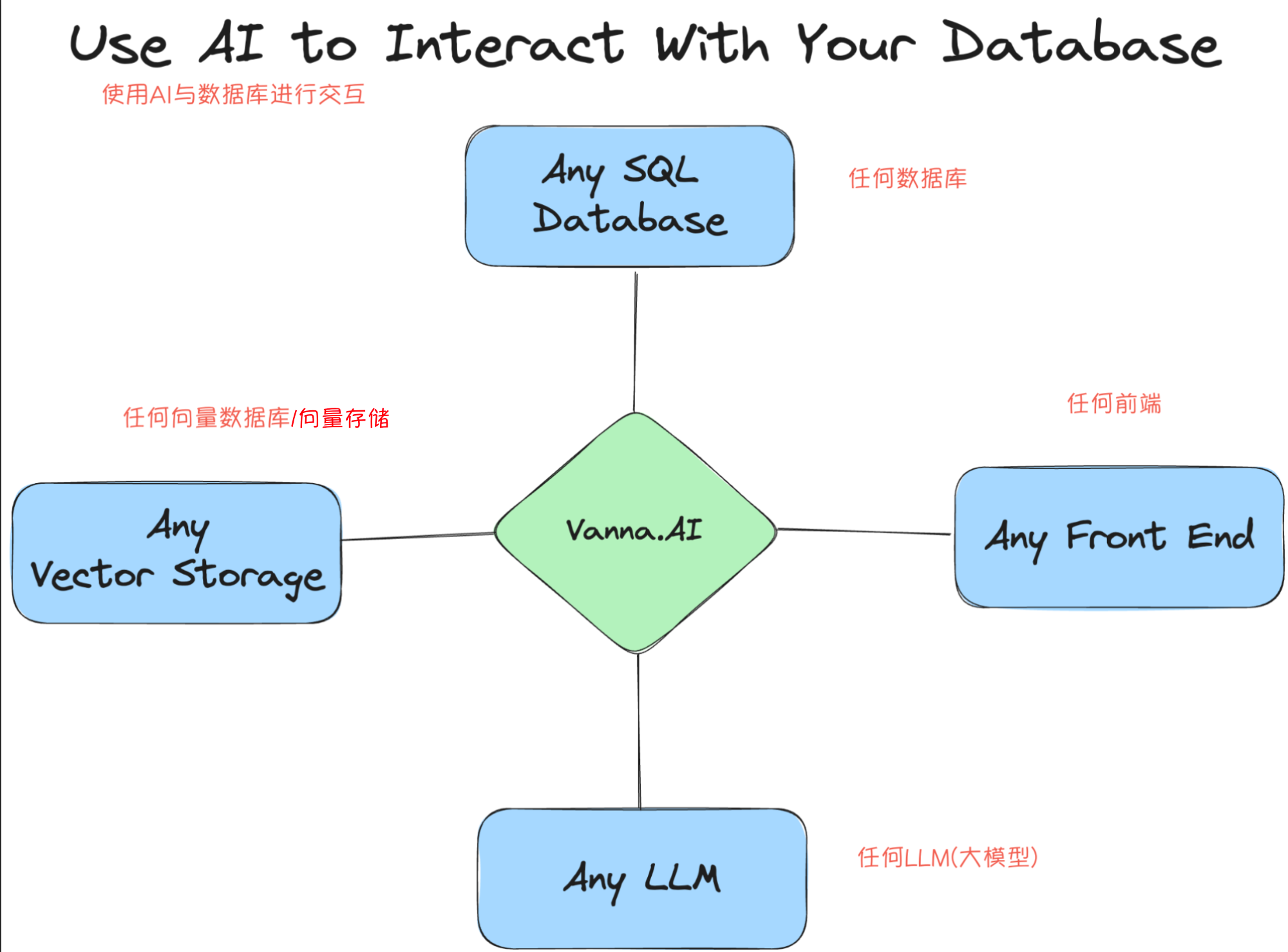
Vanna项目兼容市面上几乎所有主流数据库和向量数据库,同时支持大型模型。它还提供了丰富的接口,使得开发者能够轻松构建出卓越的前端页面,从而提升用户体验。
Vanna的工作原理
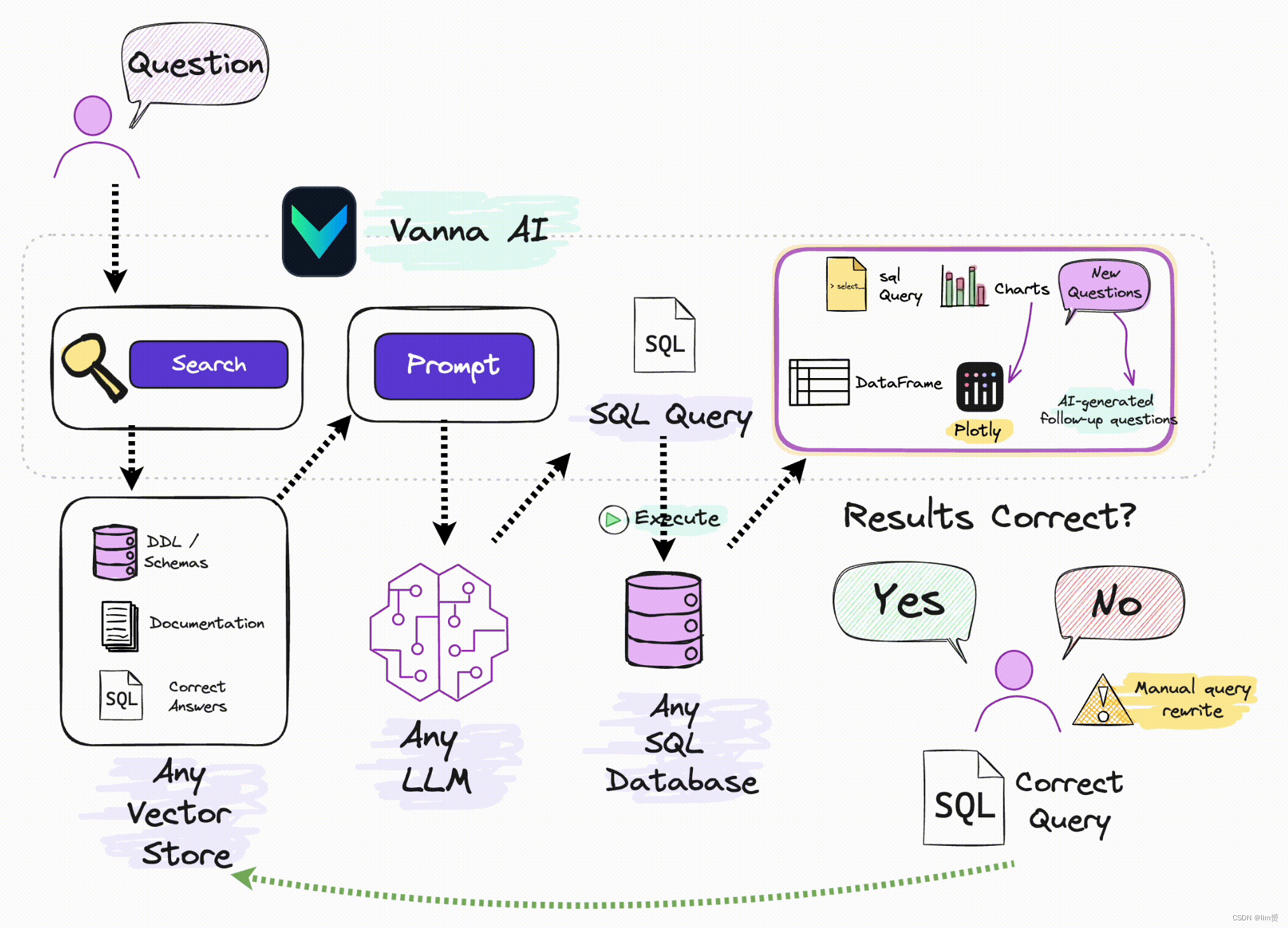
Vanna的工作分为两个简单的步骤——在你的数据上训练一个RAG“模型”,然后问一些问题,这些问题将返回SQL查询,这些查询可以设置为自动在你的数据库上运行。
- 在你的数据上训练一个RAG“模型”。
- 问问题。
如果你不知道RAG是什么,不要担心——你不需要知道它是如何工作的。你只需要知道你“训练”了一个模型,它存储了一些元数据,然后用它来“问”问题。
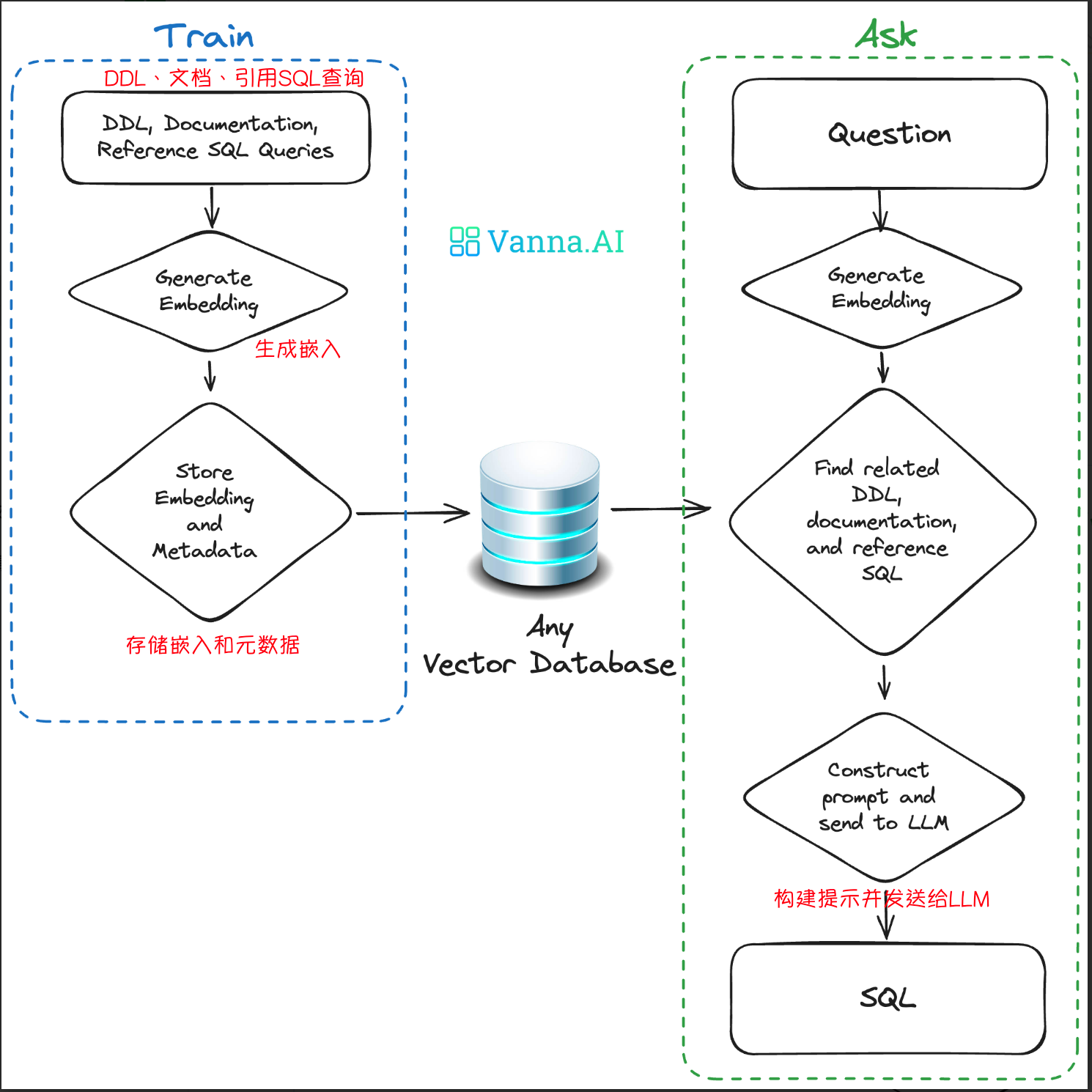
Vanna AI 允许用户将数据库定义语言(DDL)/模式(schema)语句、文本描述以及包含问题和SQL答案的数据集存储在向量数据库中用于训练。当用户提出查询时,Vanna AI 能够智能搜索向量存储,生成用于大语言模型(LLM)的Prompt(提示词)。随后,它将执行LLM返回的SQL语句,查询数据库,并根据需要以多种格式展示结果,可以选择正确的结果将它保存到向量数据库,用来提升准确率。
有关其工作原理的更多细节,请参阅base class 。
开始
构建一个基于Postgresql(DataBase)、ChromaDB(Vector)、通义千问(LLM)的Vanna项目
下载项目:
git clone git@github.com:vanna-ai/vanna.git使用Jupyter Notebook运行程序
创建demo.ipynb文件
设置
安装依赖
- #dashscope 阿里灵积服务
- %pip install 'vanna[chromadb,postgres]' dashscope -i https://mirrors.aliyun.com/pypi/simple/
- from vanna.base import VannaBase
- from vanna.chromadb import ChromaDB_VectorStore
- from dashscope import Generation
在这里查看示例实现:
https://github.com/vanna-ai/vanna/blob/main/src/vanna/mistral/mistral.py
构造Vannna客户端
- import random
- class QwenLLM(VannaBase):
- def __init__(self,config=None):
- self.model=config['model']
- self.api_key=config['api_key']
-
- def system_message(self,message: str):
- return {'role':'system','content':message}
-
- def user_message(self, message: str):
- return {'role':'user','content':message}
-
- def assistant_message(self, message: str):
- return {'role':'assistant','content':message}
-
- def submit_prompt(self,prompt,**kwargs):
- resp=Generation.call(
- model=self.model,
- messages=prompt,
- seed=random.randint(1, 10000),
- result_format='message',
- api_key=self.api_key)
- return resp.output.choices[0].message.content
-
- class MyVanna(ChromaDB_VectorStore, QwenLLM):
- def __init__(self, config=None):
- ChromaDB_VectorStore.__init__(self,config=config)
- QwenLLM.__init__(self,config=config)
-
- vn=MyVanna({'api_key':'{yours_api_key}','model':'qwen-plus'})

连接数据库
vn.connect_to_postgres(host='my-host', dbname='my-dbname', user='my-user', password='my-password', port='my-port')开始训练
DDL语句
这些语句使系统能够了解哪些表、列和数据类型可用。
- DDL="""
- CREATE TABLE students (
- id SERIAL PRIMARY KEY,
- name VARCHAR(100),
- age INT CHECK (age > 0),
- email VARCHAR(255) UNIQUE NOT NULL
- );
- COMMENT ON TABLE students IS '这是存储学生信息的表';
- COMMENT ON COLUMN students.name IS '学生的全名';
- COMMENT ON COLUMN students.age IS '学生的年龄';
- COMMENT ON COLUMN students.email IS '学生的电子邮件地址';
- """
- # 存储DDL到向量库
- vn.train(ddl=DDL)
文档
这些可以是关于你的数据库、业务或行业的任何重要文档,这些文档对于LLM来说可能是理解用户问题的上下文所必需的。
vn.train(documentation="Our business defines XYZ as ABC")sql语句
为系统提供经常使用的SQL,有助于系统理解所问问题的上下文。
vn.train(sql="SELECT col1, col2, col3 FROM my_table")Question-Sql对‼️
还可以使用 question-SQL 对来训练系统。这是训练系统最直接的方法,也是对系统理解所问问题的上下文最有帮助的方法。
- vn.train(
- question="我们顾客的平均年龄是多少?",
- sql="SELECT AVG(age) FROM customers"
- )
提问
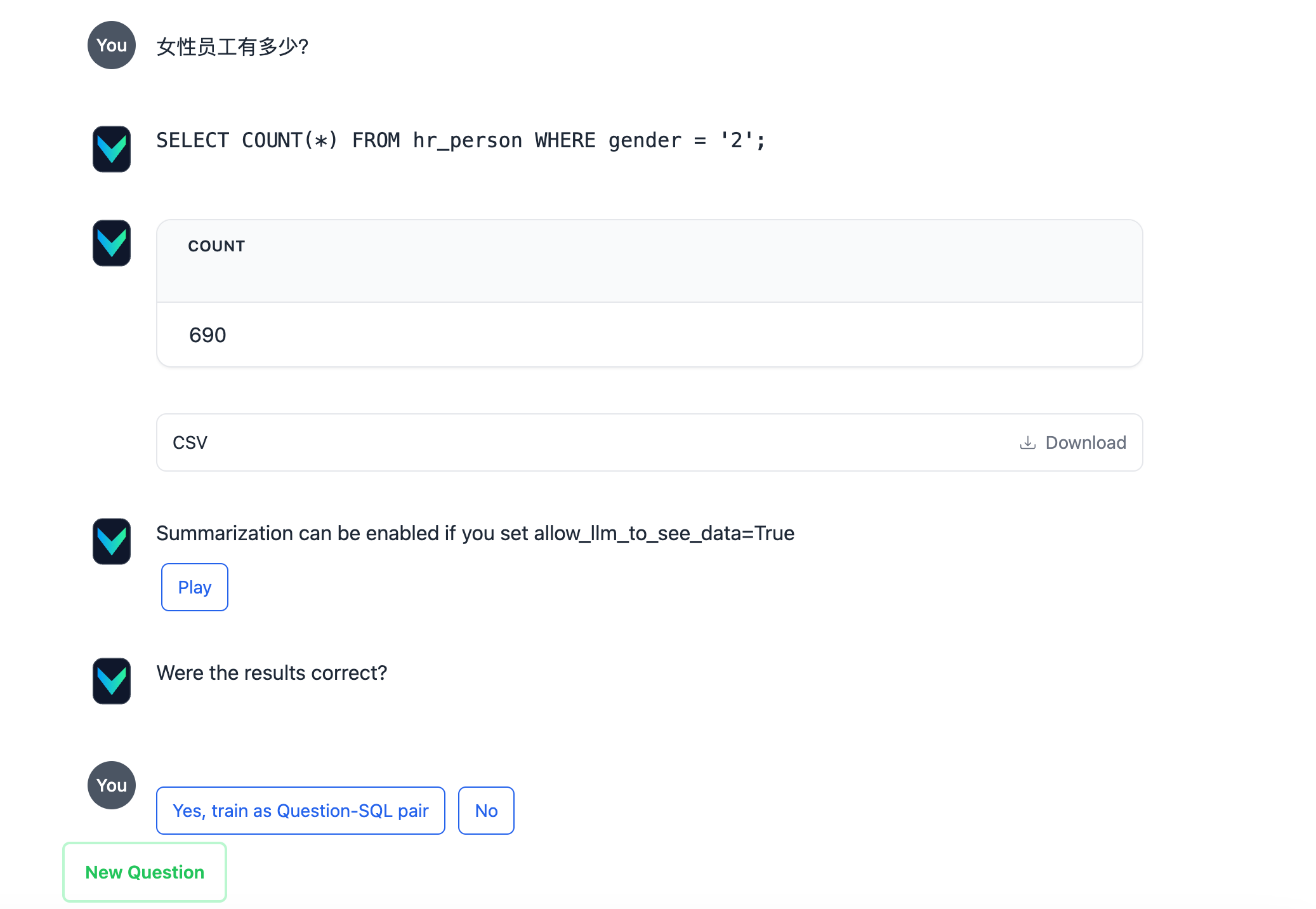
使用vn.ask函数进行提问。可以获得LLM返回的Sql语句,以及Sql语句对应的结果。
vn.ask("员工的平均年龄?")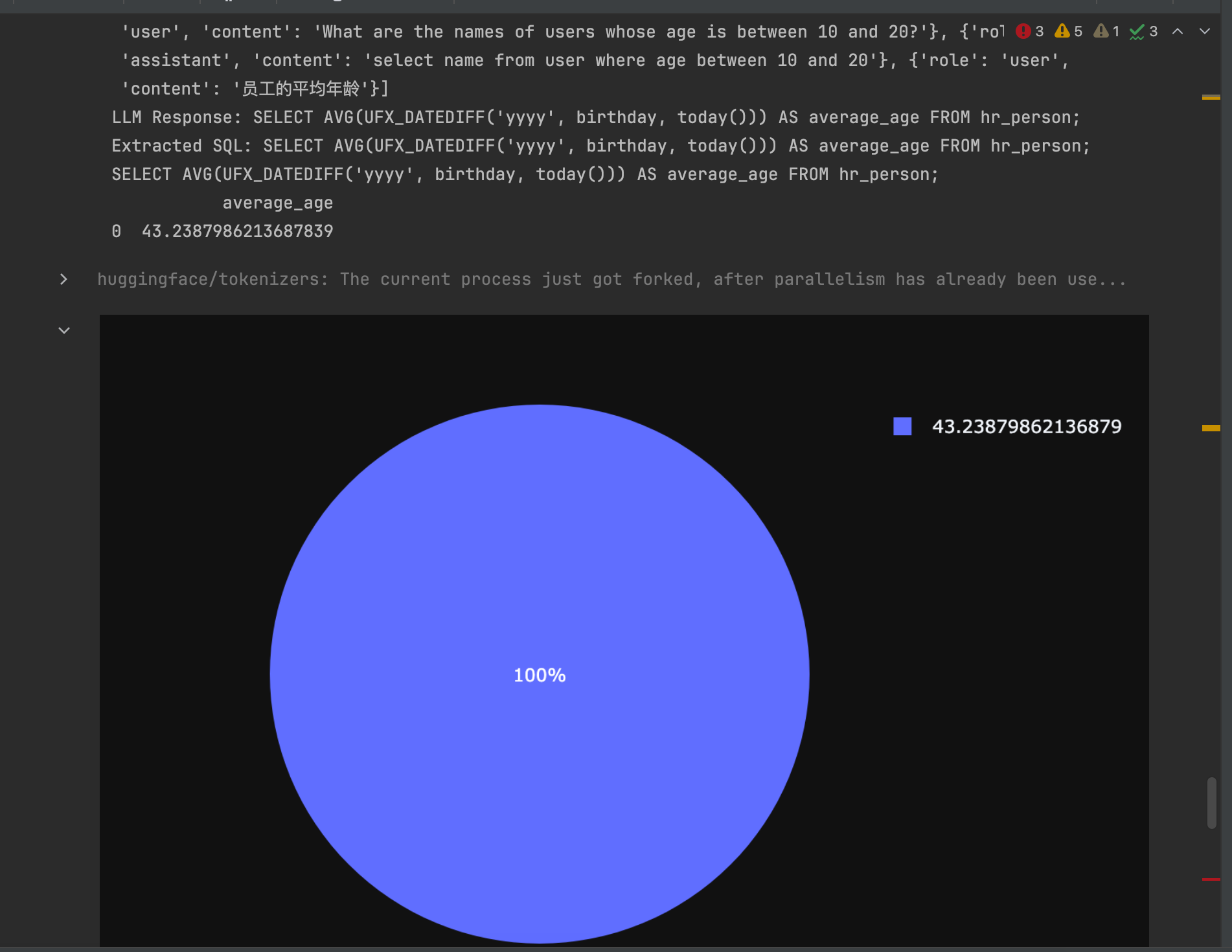
用户界面
这些是Vanna提供的一些用户界面。您可以使用这些原样或作为您自己的自定义接口的起点。
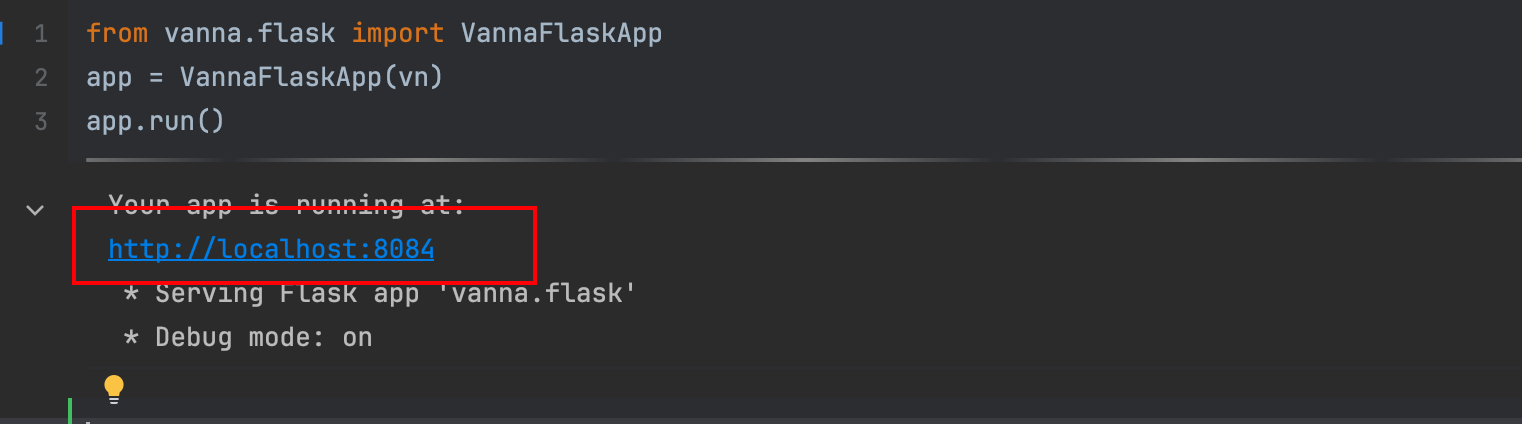
Vanna 带有一个内置的 Web 应用程序 (Flask),您可以在 Jupyter 笔记本中或独立启动。
启动Web程序
- from vanna.flask import VannaFlaskApp
- app = VannaFlaskApp(vn)
- app.run()
运行代码,点击输出台中的地址。
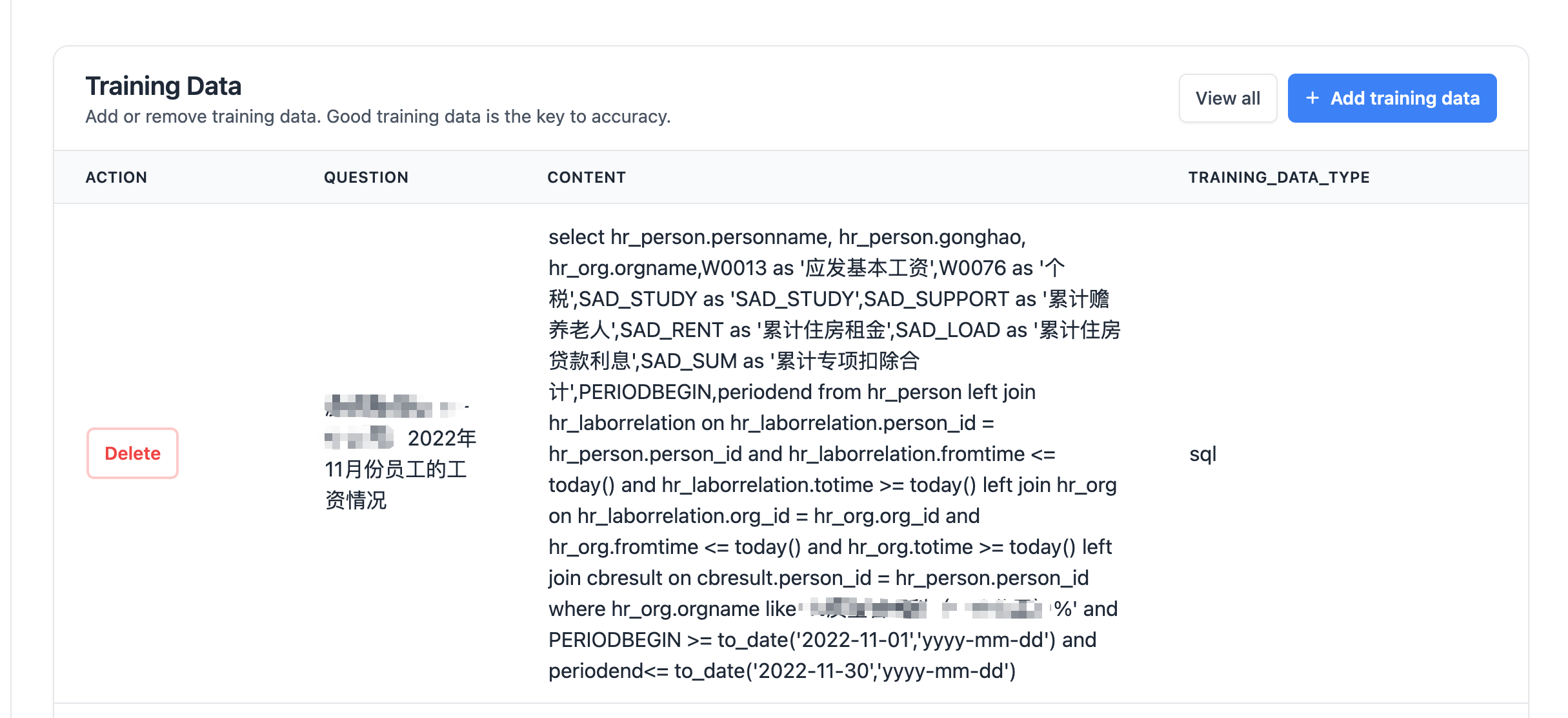
训练数据管理
点击页面左上角Training Data,进入训练数据管理页面,提供了训练数据的增删功能。
点击训练数据管理页面右上角"Add tarining data"按钮,增加DDL、document、Sql类型的巡礼数据。
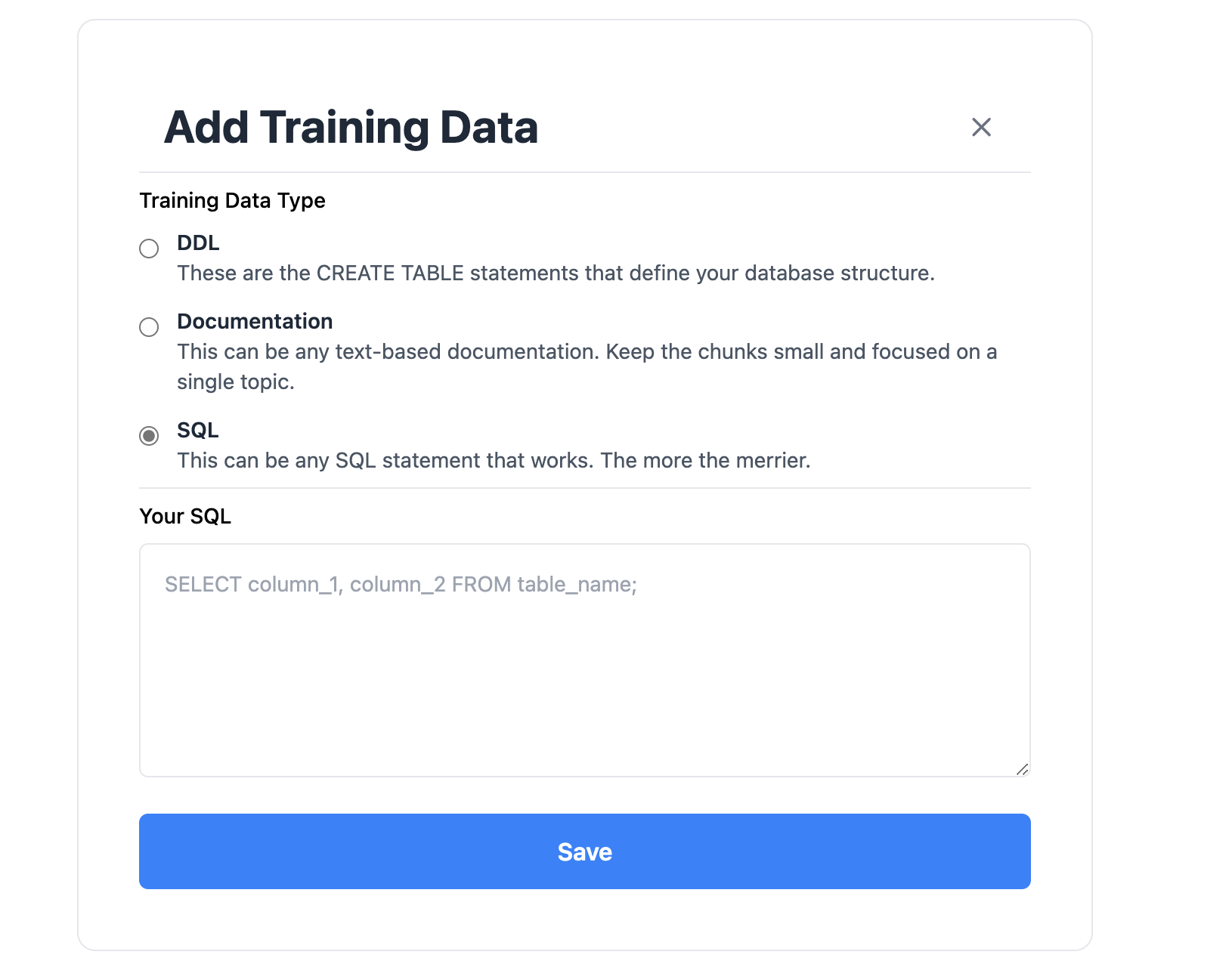
提问
Vanna AI 具备自我优化的能力,它能够将用户的问题和大模型返回的结果作为训练数据,不断学习和提升自身的性能。当大模型的输出不尽如人意时,Vanna AI 提供了一个纠正机制:用户可以对SQL语句进行调整,以确保其准确性,并将这些经过修正的Question-SQL对保存下来,作为优化模型的宝贵资源。这一过程不仅增强了系统的智能性,也为用户提供了一个参与模型训练的途径,共同推动Vanna AI 的持续进步和完善。