
- 1手写 UE4中的 TArray
- 2AI智能客服的开发流程
- 3linux基础总结_mv 带属性和权限
- 4梅科尔工作室-Joe-鸿蒙笔记1_module.json5配置文件中,包含了以下哪些信息?
- 5Linux课程四课---Linux第一个小程序(进度条)
- 6C--树的常见案例
- 7Linux基础命令实例操作_linux 实例命令操作
- 8Qt 之QWebEngineView 触摸屏联动_qwebengineview 触屏事件
- 9utf8mb4_general_ci 和utf8mb4_unicode_ci有什么异同,有什么优劣_utf8mb4_unicode_ci utf8mb4_general_ci
- 10office插件开发_OneKeyTools:强大PPT插件
注意力与自注意力概念以及自注意机制的实现步骤、代码_自注意力机制代码
赞
踩
1、概念
注意力机制模仿了生物观察行为的内部过程,即一种将内部经验和外部感觉对齐从而增加部分区域的观察精细度的机制。注意力机制可以快速提取稀疏数据的重要特征,因而被广泛用于自然语言处理任务。
当过载信息映入眼帘时,我们的大脑会把注意力放在主要的信息上,这就是大脑的注意力机制。
同样,当我们读一句话时,大脑也会首先记住重要的词汇,这样就可以把注意力机制应用到自然语言处理任务中,于是人们就通过借助人脑处理信息过载的方式,提出了Attention机制。
Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。
而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理。
在第一个阶段,可以引入不同的函数和计算机制,根据Query和某个 Keyi ,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性(即 求两个向量的夹角的余弦)或者通过再引入额外的神经网络(如MLP)来求值。
第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。SoftMax函数如下所示:
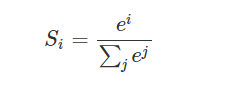
然后将对每个输入用softmax计算后的scores与values值点乘,并相加得到Attention数值。
自注意机制:主要是根据两两之间的关系来引入权重,在通道、空间两个层面,通过计算每个单元通道与通道之间、像素点与像素点之间的值,来加强两两之间的联系,进而提高精确度语义分割。
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
自注意力机制在文本中的应用,主要是通过计算单词间的互相影响,来解决长距离依赖问题。
2 自注意力机制计算过程:
1). 准备输入:输入3个4维数据。
2).初始化权重:
 3). 推导键(key)、查询(query)和值(value):input×相应权重。
3). 推导键(key)、查询(query)和值(value):input×相应权重。
4). 计算输入1的注意力分数:query·key
(ps:在transformer中使用时,为了梯度稳定,使用score归一化,即除以√(dk))
5). 计算 softmax:使用上述提到的softmax函数进行计算score的值,得到新的score。
6). 将分数与值相乘:score·value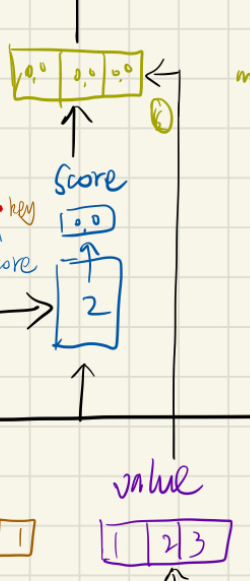
7). 对加权的值求和,得到输入1的输出:
8). 为输入 2 和 3 重复 4-7 步骤

3.pytorch实现自注意机制
import torch from torch.nn.functional import softmax import numpy #1、 input x=[[1,0,1,0], [0,2,0,2], [1,1,1,1] ] x=torch.tensor(x,dtype=torch.float32) #2、 weight w_key=[[0,0,1], [1,1,0], [0,1,0], [1,1,0] ] w_query=[[1,0,1], [1,0,0], [0,0,1], [0,1,1] ] w_value=[[0,2,0], [0,3,0], [1,0,3], [1,1,0] ] w_key=torch.tensor(w_key,dtype=torch.float32) w_query=torch.tensor(w_query,dtype=torch.float32) w_value=torch.tensor(w_value,dtype=torch.float32) #3、 key keys = x @ w_key #keys = numpy.matmul(x,w_key) querys = x @ w_query values = x @ w_value # print(keys) # print(querys) # print(values) #4、 attention score attn_scores = querys @ keys.T #5、 softmax attn_scores_softmax = softmax(attn_scores,dim=-1)#求每一行的softmax # print(attn_scores_softmax) #approxmate 估值 attn_scores_softmax=[[0.0,0.5,0.5], [0.0,1.0,0.0], [0.0,0.9,0.1] ] attn_scores_softmax=torch.tensor(attn_scores_softmax) #6、 multiplication:score_soft*values print(values[:,None,:]) # print(attn_scores_softmax.T[:,:,None]) weighted_values = values[:,None] * attn_scores_softmax.T[:,:,None] #None,即将维度(3,3)变为(3,1,3)。将维度(3,3)变为(3,3,1) print(weighted_values)#(3,3,3) #7、output outputs = weighted_values.sum(dim=0) #按第一维度相加 print(outputs)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
参考:
https://zhuanlan.zhihu.com/p/25723112
https://zhuanlan.zhihu.com/p/265108616?utm_source=qq
https://baike.baidu.com/item/%E5%BD%92%E4%B8%80%E5%8C%96%E6%8C%87%E6%95%B0%E5%87%BD%E6%95%B0/22660782?fromtitle=Softmax%E5%87%BD%E6%95%B0&fromid=22772270&fr=aladdin

