
- 18个华为设备常用的Python脚本,你都会配置使用吗? -HCIE HCIP HCIA_python netmiko 登录华为认证
- 2华为手机有哪些功能关掉比较好?_自动管理全部关掉可以吗
- 3首次安装Android Studio,gradle7.x下载慢的问题_still waiting for package manifests to be fetched
- 4python爬虫菜鸟教程-Python数据分析,学习路径拆解及资源推荐_菜鸟教程可以爬虫吗
- 5【Scikit-Learn 中文文档】特征提取 - 数据集转换 - 用户指南 | ApacheCN_sklearn alternate_sign
- 6基本的WEB渗透测试_如何做渗透测试获取flag
- 7自然语言处理实战——卷积神经网络(CNN)_cnn 自然语言处理
- 8【BERT】从零解读笔记_bert encoder
- 9MySQL锁分类_mysql锁的分类
- 10部署 KVM 虚拟化平台
【学习】Deep Learning for Deepfakes Creation and Detection_uadfv
赞
踩
论文题目:Deep Learning for Deepfakes Creation and Detection
翻译:基于深度学习的Deepfake创建与检测
作者:
Thanh Thi Nguyen*1, Cuong M. Nguyen2, Dung Tien Nguyen1,
Duc Thanh Nguyen1 and Saeid Nahavandi3
1School of Information Technology, Deakin University, Victoria, Australia(澳大利亚维多利亚州迪肯大学信息技术学院)
2School of Engineering, Deakin University, Victoria, Australia(澳大利亚维多利亚州迪肯大学工程学院)
3Institute for Intelligent Systems Research and Innovation, Deakin University, Australia(澳大利亚迪肯大学智能系统研究与创新研究所)
*Corresponding author’s e-mail: thanh.nguyen@deakin.edu.au.
【Abstract】
深度学习已成功应用于解决各种复杂问题,从大数据分析到计算机视觉和人为控制。然而,深度学习的进步也已被用于创建可以对隐私,民主和国家安全造成威胁的软件。 “ deepfake”是最近出现的具有深度学习功能的应用程序之一。Deepfake算法可以创建人类无法将其与真实图像区分开来的伪造图像和视频,因此提出了能够自动检测和评估数字视觉媒体完整性的技术提案。本文介绍了用于创建深造假的算法的调查,更重要的是,迄今为止,文献中提出了检测深造假的方法,我们对深造假技术的挑战,研究趋势和方向进行了广泛的讨论,并回顾了深造假的背景。以及最先进的深层虚假检测方法,本研究对深度造假技术进行了全面概述,并促进了开发新的,更强大的方法来应对日益严峻的Deepfakes。
【1 - Introduction】
Deepfake(源自“深度学习”和“ fake”)是一种可以将目标人的面部图像叠加到源人的视频上,以创建目标人做或说源人的事情的视频的技术。诸如自动编码器和生成对抗网络之类的深度学习模型已广泛应用于计算机视觉领域,以解决各种问题[1 {7]。 Deepfake算法也使用这些模型来检查一个人的面部表情和动作,并合成另一个进行类似表情和动作的人的面部图像[8]。 Deepfake算法通常需要大量的图像和视频数据来训练模型以创建逼真的图像和视频。由于名人和政客等公众人物可能在线上有大量视频和图像,因此它们是伪造品的最初目标。 Deepfake被用来将名人或政客的面孔换成色情图片和视频中的人物。 Deepfake的第一个视频出现在2017年,名人的面孔被换成了色情演员的面孔。当采用伪造的方法为伪造的目的制作带有假演讲的世界领导人的视频时,这将会威胁世界的安全与稳定[9,10]。因此,Deepfakes可能会被滥用,以达到引起国家之间的政治或宗教紧张局势,愚弄公众并影响选举活动的结果,或者通过制造虚假新闻在金融市场造成混乱。它甚至可以用于生成伪造的地球卫星图像,以包含实际上不存在的物体,来使军事分析家感到困惑。例如,尽管实际上没有这架桥梁,但在通过deepfakes在河上建造了伪造的桥梁。这可能会误导一个在战斗中被引导着过桥的部队[11,12]。
Deepfakes也有积极的用途,例如为迷路者创建声音或在不重新拍摄电影的情况下更新电影[13]。但是,恶意软件对deepfake的恶意使用在很大程度上超越了积极的一面。先进的深层网络的发展以及大量数据的可用性,使得伪造的图像和视频几乎无法被人类甚至精密的计算机算法区分开。如今,创建那些被修改过的图像和视频的过程也变得更加简单,因为它只需要目标个人的身份照片或简短视频即可。制作令人惊叹的令人振奋的镜头也只需要越来越少的精力。最新的进展甚至可以仅用静止图像创建deepfakes[14]。因此,深造假不仅会威胁到公众人物,而且还会影响普通百姓。例如,用一个欺骗性的语音欺骗了一个公司的CEO243,000美元[15]。刚刚发布的称为DeepNude的软件显示出更多令人不安的威胁,因为它可以使一个非自愿的人转变为的色情片中的人物[16]。同样,中国的应用软件Zao最近也变得病毒式传播,因为技术水平较低的用户可以将自己的面孔交换到电影明星的身体上,然后将自己插入著名的电影和电视剪辑中[17]。这些形式的伪造对隐私的侵犯和对公民的身份构成巨大威胁,影响人类生活的许多方面。
因此,在数字领域寻找真相变得越来越重要。在处理Deepfake时,这更具挑战性,因为它们主要用于恶意目的,并且如今几乎任何人都可以使用现有的Deepfake工具来创建Deepfake。迄今为止,已经提出了许多检测深度伪造的方法。它们中的大多数也基于深度学习,因此,恶意和积极使用深度学习方法之间的斗争已经开始。为了应对面部信息交换技术或伪造品的威胁,美国国防高级研究计划局(DARPA)发起了一项针对媒体取证的研究计划(名为Media Forensics或MediFor),以加速假数字视觉媒体检测方法的开发[18]。 最近,Facebook Inc.与Microsoft Corp以及AI联盟合作伙伴合作发起了Deepfake检测挑战赛,以促进更多的研究和开发,以检测和防止Deepfake误用于误导民众[19]。
本文对创建和检测深层造假的方法进行了概述。 在第2节中,我们介绍了Deepfake算法的原理以及如何使用深度学习来启用这种分布式技术。 第3节回顾了检测Deepfake的不同方法,以及它们的优缺点。 我们将在第4节中讨论有关深度欺诈检测以及多媒体取证问题的挑战,研究趋势和方向。
【2 - Deepfake Creation】
由于伪造视频的质量以及应用程序使用的容易性,使Deepfake变得流行起来,这些应用程序对于具有从专业到新手的计算机技能的各种用户来说,都是如此。这些应用程序大多数是基于深度学习技术开发的。深度学习以其表示复杂和高维数据的能力而闻名。具有这种能力的深层网络的一种变体是深层自动编码器,它已广泛应用于降维和图像压缩[20 {22]。 Deepfake创建的第一个尝试是FakeApp,它是由Reddit用户使用自动编码器-解码器配对结构开发的[23,24]。在该方法中,自动编码器提取面部图像的潜在特征,然后使用解码器重建面部图像。为了在源图像和目标图像之间交换面部,需要两个编码器/解码器对,其中每对用于在图像集上进行训练,并且编码器的参数在两个网络对之间共享。换句话说,两对具有相同构造的编码器网络。这种策略使通用编码器能够找到并学习两组面部图像之间的相似性,因为面部通常具有相似的特征(例如,眼睛,鼻子,嘴巴的位置),因此这是较为不具挑战性的。图1显示了Deepfake创建过程,其中人脸A的特征集与解码器B相连,以从原始人脸A重建人脸B。这种方法已经应用于DeepFaceLab [25],DFaker [26], DeepFake-tf(基于TensorFlow的Deepfake)[27]等。


图1:使用两个编码器/解码器对的Deepfake创建模型。 两个网络使用相同的编码器进行编码但使用不同的解码器进行训练过程(顶部)。 人脸A的图像使用通用编码器进行编码,并使用解码器B进行解码,以创建一个Deepfake(底部)。
通过将在VGGFace [28]中实现的对抗损失和感知损失添加到编码器-解码器体系结构,在[30]中提出了一种基于生成对抗网络(GAN)[29]的改进版本的Deepfake,即Faceswap-GAN。 添加了VGGFace知觉损失,使眼睛运动更加逼真并与输入面部保持一致,并有助于消除分割蒙版中的伪像,从而获得更高质量的输出视频。 该模型有助于创建分辨率为64x64、128x128和256x256的输出。 另外,引入了FaceNet实现中的多任务卷积神经网络(CNN)[31],以使人脸检测更加稳定,人脸对齐更加可靠。 CycleGAN [32]用于生成网络的实现。 总之,表1列出了流行的deepfake工具及其功能。
【3 - Deepfake Detection(检测)】
Deepfakes对隐私,社会安全和民主的危害越来越大[35]。 这种威胁刚出现时,就已经提出了检测deepfakes的方法。 早期的尝试是基于从伪造的视频和伪造的视频合成过程的不一致性中获得的手工特征。 另一方面,最近的方法将深度学习应用于自动提取突出特征和判别特征以检测deepfakes。
Deepfake检测通常被认为是二进制分类问题,其中分类器用于在真实视频和篡改视频之间进行分类。这种方法需要大量的真实和虚假视频数据库来训练分类模型。假冒视频的数量越来越多,但在设置验证各种检测方法的基准方面仍然受到限制。为了解决这个问题,Korshunov和Marcel [36]使用开放源代码Faceswap-GAN [30],基于GAN模型生成了一个值得关注的Deepfake数据集,其中包含620个视频。来自公开可用的VidTIMIT数据库的视频[37]用于生成低质量和高质量的Deepfake视频,这些视频可以有效地模仿面部表情,嘴巴运动和眨眼。然后将这些视频用于测试各种Deepfake检测方法。测试结果表明,基于VGG [38]和Facenet [31,39]的流行的人脸识别系统无法有效地检测出deepfakes。其他方法,如嘴唇同步方法[40 {42]和支持向量机(SVM)[43、44]的图像质量指标,在应用于从此新产生的数据集中检测Deepfake视频时,会产生很高的错误率。这引起了人们对未来开发更健壮的方法(这些方法可以检测更加真实的deepfakes)的迫切需求。

图2:与Deepfake检测方法相关的评论论文类别,其中我们将论文分为两大类,即伪造图像检测和面部视频检测。
本节介绍了Deepfake检测方法的调查,将其分为两大类:伪图像检测方法和伪视频检测方法(图2)。 后者分为两类:基于视频帧的方法中的视觉伪像和跨帧方法中的时间特征。 尽管大多数基于时间特征的方法都使用深度学习递归分类模型,但这些方法使用视频帧内的视觉伪像可以由深度或浅层分类器实现。
【3.1 - Fake Image Detection】
人脸交换在视频合成,人像变形,尤其是身份保护方面具有许多引人注目的应用,因为它可以用图片库中的人脸替换照片中的人脸。但是,它也是网络攻击者用来渗透识别或身份验证系统以获取非法访问的技术之一。诸如CNN和GAN之类的深度学习的使用,使交换的面部图像对于取证模型更具挑战性,因为它可以保留照片的姿势,面部表情和光线[45],Zhang等。 [46]使用“词袋法”提取一组紧凑特征并将其输入到各种分类器中,例如SVM [47],随机森林(RF)[48]和多层感知器(MLP)[49]以进行区分从正品交换了面部图像。在深度学习生成的图像中,由GAN模型合成的图像可能最难检测,因为基于GAN学习复杂输入数据的分布并生成具有相似输入分布的新输出的能力,它们是逼真的且质量很高。
尽管GAN的开发仍在进行中,但大多数有关GAN生成图像检测的工作并未考虑检测模型的泛化能力,并且经常引入GAN的许多新扩展,Xuan等。 [50]使用了图像预处理步骤,例如高斯模糊和高斯噪声,可去除GAN图像的低频高频线索。 这增加了真实图像和伪图像之间的像素级统计相似度,并要求取证分类器学习更多的内在和有意义的特征,比以前的图像取证方法[51,52]或图像隐写分析网络[53]具有更好的泛化能力。
另一方面,Agarwal和Varshney [54]将基于GAN的深层伪造检测作为假设检验问题,其中使用认证的信息理论研究引入了统计框架[55]。 定义合法图像的分布与特定GAN生成的图像之间的最小距离,即预测误差。 分析结果表明,当GAN精度较差时,此距离会增加,在这种情况下,较容易检测到deepfakes。 在高分辨率图像输入的情况下,需要极其精确的GAN来生成难以检测的伪图像。
最近,Hsu等人 [56]介绍了一种两阶段的深度学习方法来检测Deepfake图像。第一阶段是基于通用伪特征网络(CFFN)的特征提取器,其中使用了[57]中介绍的Siamese 4网络体系结构。 CFFN包含几个密集单元,每个单元包含不同数量的密集块[58],以提高伪造图像的代表性能力。密集单元的数量为三或五个,具体取决于验证数据是人脸图像还是普通图像,并且每个单元中的通道数最多可变化数百个。伪图像和真实图像之间的区别特征(即成对信息)是通过CFFN学习过程提取的。这些特征然后被馈入第二阶段,第二阶段是一个小的CNN,连接到CFFN的最后一个卷积层,以将欺骗性图像与真实图像区分开。所提出的方法已被验证用于假脸和假普通图像检测。一方面,面部数据集是从CelebA [59]获得的,其中包含10177个身份和202599个对齐的各种姿势和背景杂乱的面部图像。五个GAN变体用于生成大小为64x64的伪图像,包括深度卷积GAN(DCGAN)[60],Wasserstein GAN(WGAN)[61],具有梯度罚分的WGAN(WGAN-GP)[62],最小平方GAN [63]和GAN(PGGAN)的逐步发展[64]。总共获得了385,198张训练图像和10,000张真实和伪造的测试图像,以验证所提出的方法。另一方面,一般数据集是从ILSVRC12中提取的[65]。用于高保真自然图像合成的大型GAN训练模型(BIGGAN)[66],自注意GAN [67]和频谱归一化GAN [68]用于生成大小为128x128的伪图像。训练集包含600,000张伪造和真实图像,而测试集包含10,000种两种类型的图像。实验结果表明,所提出的方法优于其竞争方法,例如[69 - 72]中引入的方法。
【3.2 - Fake Video Detection】
大多数图像检测方法不能用于视频,因为视频压缩后帧数据会严重退化[73]。 此外,视频具有在帧组之间变化的时间特性,因此对于设计为仅检测静态图像的方法具有挑战性。 本小节重点介绍Deepfake视频检测方法,并将其分为两类:采用时间特征的方法和探索帧内视觉伪像的方法
3.2.1 Temporal Features across Video Frames
Sabir等人基于观察到,在伪造品的合成过程中不能有效地增强时间连贯性。 [74]利用视频流的时空特征来检测深度伪造。 视频操作是在逐帧的基础上执行的,因此,可以认为由面部操作产生的低级伪像会进一步表现为跨帧不一致的时间伪像。 基于卷积网络DenseNet [58]和门控循环单位单元[75]的集成,提出了循环卷积模型(RCN),以利用帧之间的时间差异(见图3)。 所提出的方法在FaceForensics ++数据集上进行了测试,该数据集包含1,000个视频[76],并显示出令人激动的结果。

图3:用于面部操纵检测的两步过程,其中预处理步骤旨在检测,裁剪和对齐一系列帧上的面部,第二步通过结合卷积神经网络(CNN)和循环神经网络(RNN)来区分已操纵和真实的面部图像 [74]。
同样,Guera和Delp [77]强调深层视频包含帧内不一致和帧之间的时间不一致。 然后,他们提出了使用时间感知管线方法,该方法使用CNN和长期短期记忆(LSTM)来检测Deepfake视频。 CNN用于提取帧级特征,然后将其馈入LSTM以创建时间序列描述符。 之后,使用一个完全连接的网络根据序列描述符对真实视频中的篡改视频进行分类(图4)。
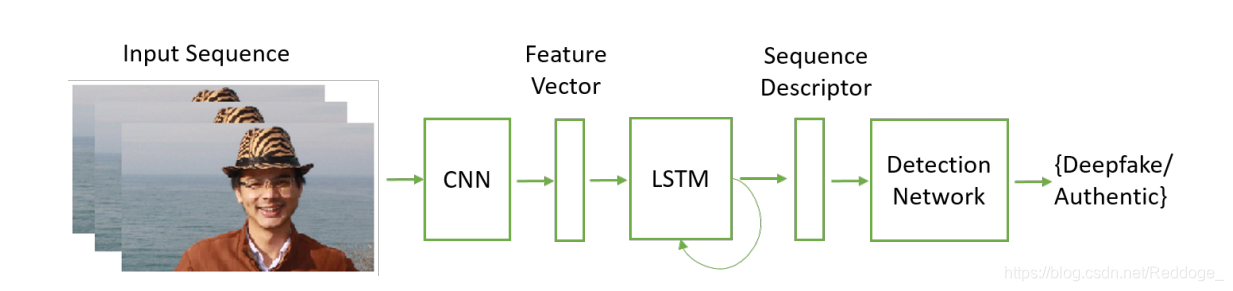
图4:使用卷积神经网络(CNN)和长期短期记忆(LSTM)来提取给定视频序列的时间特征(通过序列描述符表示)的深度检测方法。 由全连接层组成的检测网络被用来作为序列描述符的输入,并计算属于真实或deepfakes的帧序列的概率[77]。
另一方面,在[78]中提出了一种生理信号,即眨眼来检测深层假货,其基础是观察到deepfakes中人的眨眼频率要比不受干扰的视频少得多。一个健康的成年人通常眨眼2到10秒之间,每次眨眼需要0.1到0.4秒。然而,Deepfake算法经常使用在线提供的面部图像进行训练,这些图像通常显示睁开眼睛的人,即在互联网上发布的图像很少显示闭着眼睛的人。因此,在无法获取眨眼的人的图像的情况下,deepfake算法无法生成可以正常眨眼的假脸。换句话说,deepfake中的眨眼频率远低于普通视频中的眨眼速度。为了区分真假视频,Li等人 [78],首先将视频分解为帧,然后根据六个眼睛界标提取出面部区域和眼睛区域。经过几步预处理,例如对齐人脸,提取和缩放眼睛界标点的边界框以创建新的帧序列后,这些裁剪的眼睛区域序列将分配到长期递归卷积网络(LRCN)中[79]动态状态预测。 LRCN由基于CNN的特征提取器,基于长期短期记忆(LSTM)的序列学习和基于完全连接层的状态预测组成,以预测睁眼和闭眼状态的可能性。眨眼表明强烈的时间依赖性,因此LSTM的实施有助于有效捕获这些时间模式。基于预测结果来计算眨眼率,其中眨眼被定义为0.5阈值以上且持续时间少于7帧的峰值。该方法在从网络收集的数据集上进行评估,该数据集由49个采访和演示视频以及由Deepfake算法生成的相应假视频组成。实验结果表明,提出的方法在检测假视频方面具有良好的性能,可以通过考虑动态的眨眼模式来进一步改善对视频的检测,同时,频繁眨眼也可能是篡改的迹象。
3.2.2 Visual Artifacts within Video Frame
如前面小节所述,使用跨视频帧的时间模式的方法主要基于深度递归网络模型来检测Deepfake视频。 本小节研究通常将视频分解为帧并探索单个帧内的视觉伪像以获得判别特征的另一种方法。 然后,将这些功能分配到深层或浅层分类器中,以区分假视频和真实视频。 因此,我们在本小节中根据分类器的类型(即深层或浅层)对方法进行分组。
3.2.2.1 Deep classifiers
Deepfake视频通常以有限的分辨率创建,因此需要仿射人脸变形方法(即缩放,旋转和剪切)来匹配原始视频的配置。由于扭曲的面部区域和周围环境之间的分辨率不一致,因此此过程留下了可以由CNN模型(例如VGG16 [80],ResNet50,ResNet101和ResNet152 [81])检测到的伪像。文献[82]中提出了一种基于深度伪造算法的面部变形步骤中观察到deepfakes的方法。在两个Deepfake数据集UADFV和DeepfakeTIMIT上评估了所提出的方法。 UADFV数据集[83]包含49个真实视频和49个假视频,总共32752帧。 DeepfakeTIMIT数据集[42]包括一组64 x 64大小的低质量视频和另一组128 x 128的高质量视频,其中包含从每个质量集的320个视频中提取的总共10537个原始图像和34,023个虚构图像。将该方法的性能与其他流行方法进行了比较,例如面部篡改检测方法两流NN [84],HeadPose [83]和两种深层伪造检测MesoNet方法,即Meso-4和MesoInception-4 [73]。该方法的优点在于,在训练检测模型之前,无需生成Deepfake视频作为负面示例。取而代之的是,通过提取原始图像的面部区域并将其对齐为多个比例,然后在对随机拾取的缩放图像应用高斯模糊并将其扭曲回原始图像之前,动态生成负面示例。与其他方法相比,这减少了大量时间和计算资源,而其他方法则需要事先生成deepfakes。
最近,Nguyen等。 [85]提出使用胶囊网络来检测操纵的图像和视频。胶囊网络最初是为解决CNN在逆图形任务中的局限性而提出的,其目的是寻找用于产生世界图像的物理过程[86]。基于动态路由算法的胶囊网络的最新发展[87]证明了其描述对象部分之间的分层姿势关系的能力。如图5所示,此开发被用作检测伪造图像和视频的管道中的组件。部署了动态路由算法,以通过多次迭代将三个胶囊的输出路由到输出胶囊,以在伪造之间进行分离。和真实的图像。该方法通过涵盖广泛伪造图像和视频攻击的四个数据集进行评估。它们包括著名的Idiap研究所重播攻击数据集[88],由Afchar等人创建的Deepfake人脸交换数据集。 [73],通过Face2Face方法[90]生成的面部重现FaceForensics数据集[89]和由Rahmouni等人生成的完全计算机生成的图像数据集。 [91]。在所有这些数据集中,与竞争方法相比,该方法产生的性能最佳。这表明了胶囊网络在构建通用检测系统方面的潜力,该系统可以有效地应对各种伪造的图像和视频攻击。

图5:胶囊网络采用从VGG-19网络[80]获得的功能,以区分假图片或视频与真实图片或视频(顶部)。 预处理步骤会检测面部区域并将其缩放为128x128的大小,然后再使用VGG-19提取胶囊网络的潜在特征,该网络包括三个主要胶囊和两个输出胶囊,一个用于真实图像,一个用于虚假图像( 底部)。 统计池是构成伪造检测的胶囊网络的重要组成部分[85]。
3.2.2.2 Shallow classifiers
Deepfake检测方法主要依赖于伪造图像与真实图像或视频之间的固有特征的伪影或不一致。Yang等 [83],提出了一种通过观察3D头部姿势之间的差异(包括头部方向和位置)来确定检测的方法,该方法基于中央面部区域的68个面部界标进行估算。检查3D头部姿势,因为在Deepfake人脸生成管道中存在缺陷。提取的特征被馈送到SVM分类器中以获得检测结果。在两个数据集上进行的实验表明,该方法相对于其竞争方法具有出色的性能。第一个数据集,即UADFV,由49个深层假视频及其各自的真实视频组成[83]。第二个数据集包括241个真实图像和252个深度假图像,这是DARPA MediFor GAN图像/视频挑战[92]中使用的数据的子集。同样,在[93]中,研究了一种基于眼睛,牙齿和面部轮廓的视觉特征来利用伪造品和面部操纵伪影的方法。视觉伪影是由于缺乏整体一致性,入射照明的错误或不精确估计或底层几何结构的不精确估计而引起的。对于deepfakes检测,将利用眼睛和牙齿区域中缺失的反射和缺失的细节,以及基于面部标志从面部区域提取的纹理特征。因此,使用眼睛特征向量,牙齿特征向量和从全脸作物提取的特征。提取特征后,采用逻辑回归和小型神经网络这两个分类器对真实视频中的伪造品进行分类。在从YouTube下载的视频数据集上进行的实验显示,在接收器工作特性曲线下方的面积方面,最佳结果为0.851。然而,所提出的方法的缺点是需要满足某些先决条件的图像,例如睁开眼睛或可见的牙齿。
在[94]中提出了使用光响应非均匀性(PRNU)分析来检测来自真实的伪造品。 PRNU是一种噪声模式,源于数码相机的感光传感器的出厂缺陷。每个数字相机的PRNU都不相同,通常被视为数字图像的指纹[95,96]。该分析在图像取证中被广泛使用,因为交换的面部被认为会改变视频帧面部区域中的局部PRNU模式。视频被转换为帧,并被裁剪到有问题的面部区域。然后将裁剪的帧顺序分为八个组,在其中为每个组计算平均PRNU模式。计算归一化的互相关函数,以比较这些组之间的PRNU模式。作者创建了一个包含10个真实视频和16个操纵视频的测试数据集,其中DeepFaceLab工具从真实视频中制作了假视频[25]。分析显示,在深层假货和货真价实的平均归一化互相关分数方面,存在显着的统计差异。因此,尽管需要测试更大的数据集,但这种分析在深度伪造检测方面具有潜力。
当观看带有疑问的视频或图像时,用户通常希望搜索其来源。但是,目前尚无这种工具的可行性。 Hasan和Salah [97]提出使用区块链和智能合约来帮助用户检测Deepfake视频的假设是,前提是视频只有在其来源可追溯时才是真实的。每个视频都与一个智能合约相关联,该智能合约链接到其父视频,并且每个父视频在其层次结构中都有一个指向其子代的链接。通过该链,即使视频已被多次复制,用户也可以可靠地追溯到与原始视频关联的原始智能合约。智能合约的一个重要属性是星际文件系统(IPFS)的独特哈希值,该哈希值用于以分散和内容可寻址的方式存储视频及其元数据[98]。对智能合约的关键特性和功能进行了测试,以应对几种常见的安全挑战,例如分布式拒绝服务,重放和中间人攻击,以确保建议的解决方案满足安全要求。这种方法是通用的,可以扩展到其他类型的数字内容,例如图像,音频和手稿。
【4 - Discussions, Conclusions and Future Research Directions】
伪造品已经开始削弱人们对媒体内容的信任,因为看到他们不再与相信他们相称。它们可能对目标人群造成困扰和负面影响,加剧虚假信息和仇恨言论,甚至可能激起政治紧张局势,激怒公众,暴力或战争。如今,这尤其重要,因为用于创建深层伪造的技术越来越容易获得,并且社交媒体平台可以迅速传播这些假冒内容。有时,deepfakes不需要传播给大量受众,就会造成有害影响。出于恶意目的制造深造假品的人只需将其作为破坏策略的一部分,即可将其分发给目标受众,而无需使用社交媒体。例如,情报部门可以利用这种方法来试图影响重要人物(例如政客)做出的决定,从而导致国家和国际安全威胁[99]。为捕捉Deepfake警报问题,研究界致力于开发Deepfake检测算法,并已报告了许多结果。本文回顾了最先进的方法,表2中提供了典型方法的摘要。值得注意的是,使用高级机器学习创建深度仿造的人们与努力检测深度仿造的人们之间的斗争是生长。
Deepfake的质量一直在提高,检测方法的性能也需要相应提高。灵感来自于AI破坏也可以来自AI修复[101]。检测方法仍处于早期阶段,已提出并评估了各种方法,但使用的是零散的数据集。一种提高检测方法性能的方法是创建一个不断增长的更新的伪造基准数据集,以验证检测方法的不断发展。这将有助于检测模型的训练过程,特别是基于深度学习的检测模型,这需要大量的训练集。另一方面,当前的检测方法主要集中在深层伪造管线的缺点上,即发现竞争者的弱点来攻击它们。在攻击者通常试图不公开这种深造技术的对抗环境中,此类信息和知识并不总是可用的。这对于检测方法的发展是一个真正的挑战,未来的研究需要着重于引入更健壮,可扩展和可推广的方法。
另一个研究方向是将检测方法集成到诸如社交媒体之类的分发平台中,以提高其在处理深层仿冒的广泛影响方面的有效性。可以在这些平台上实施使用有效检测方法的筛选或过滤机制,以简化Deepfake检测[99]。拥有这些平台的技术公司可以制定法律要求,以快速删除深度欺诈,以减少其影响。另外,水印工具也可以集成到人们用来制作数字内容的设备中,以创建不可变的元数据,以存储原创性细节,例如多媒体内容的时间和位置以及其未经篡改的证明[99]。这种集成很难实现,但是解决方案可以是使用破坏性的区块链技术。区块链已在许多领域得到有效使用,到目前为止,针对基于该技术的深度检测问题的研究很少。由于它可以创建一系列唯一的不可更改的元数据块,因此它是用于数字来源解决方案的出色工具。区块链技术与该问题的整合已显示出一定的结果[97],但这一研究方向还远远没有成熟。
另一方面,使用检测方法来发现Deepfakes至关重要,但是了解人们发布Deepfakes的真实意图更为重要。 这需要基于发现Deepfake的社交环境(例如,社交网络)对用户进行判断。 谁分发了它以及他们对此发表了什么看法[102]。 随着Deepfake越来越逼真,这是至关重要的,并且高度期望检测软件将落后于Deepfake创作技术。 因此,有必要进行有关深度欺诈的社会背景研究以帮助用户做出这样的判断。
录像和摄影已被广泛用作警察调查和司法案件的证据。可以由具有计算机或法律执行背景,并且具有收集,检查和分析数字信息的经验的数字媒体取证专家将它们作为法院的证据。机器学习和AI技术的发展可能已经被用来修改这些数字内容,因此专家的意见可能不足以验证这些证据,因为即使专家也无法辨别出操纵的内容。如今,由于存在广泛的数字操作方法,当图像和视频被用作定罪者的证据时,这方面需要在法庭上加以考虑。因此,在将数字媒体取证结果用于法院之前,必须证明它们是有效和可靠的。这要求对取证过程的每个步骤以及如何获得结果进行仔细的记录。机器学习和AI算法可用于支持确定数字媒体的真实性,并已获得准确可靠的结果,例如[104 - 106],但其中大多数算法无法解释。这为AI在取证问题中的应用创造了巨大的障碍,因为不仅取证专家通常不具备计算机算法方面的专业知识,而且计算机专业人员也无法正确解释结果,因为这些算法大多数都是黑盒模型。这一点尤为重要,因为最新的具有最准确结果的模型是基于由许多神经网络参数组成的深度学习方法的。因此,计算机视觉中可解释的AI是在数字媒体取证中促进和利用AI和机器学习的进步与优势所需要的研究方向。

【Reference】
[1] Badrinarayanan, V., Kendall, A., and Cipolla, R. (2017). Segnet: A deep convolutional encoder-decoderarchitecture for image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(12), 2481-2495.
[2] Guo, Y., Jiao, L., Wang, S., Wang, S., and Liu, F. (2017). Fuzzy sparse autoencoder framework for single image per person face recognition. IEEE Transactions on Cybernetics, 48(8), 2402-2415.
[3] Tewari, A., Zollhoefer, M., Bernard, F., Garrido, P., Kim, H., Perez, P., and Theobalt, C. (2018). High fidelity monocular face reconstruction based on an unsupervised model-based face autoencoder. IEEE Transactions on Pattern Analysis and Machine Intelligence. DOI: 10.1109/TPAMI.2018.2876842.
[4] Yang, W., Hui, C., Chen, Z., Xue, J. H., and Liao, Q. (2019). FV-GAN: Finger vein representation using generative adversarial networks. IEEE Transactions on Information Forensics and Security, 14(9), 2512-2524.
[5] Liu, F., Jiao, L., and Tang, X. (2019). Task-oriented GAN for PolSAR image classification and clustering. IEEE transactions on Neural Networks and Learning Systems, 30(9), 2707-2719.
[6] Cao, J., Hu, Y., Yu, B., He, R., and Sun, Z. (2019). 3D aided duet GANs for multi-view face image synthesis. IEEE Transactions on Information Forensics and Security, 14(8), 2028-2042.
[7] Zhang, H., Xu, T., Li, H., Zhang, S., Wang, X., Huang, X., and Metaxas, D. N. (2019). StackGAN++: Realistic image synthesis with stacked generative adversarial networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(8), 1947-1962.
[8] Lyu, S. (2018, August 29). Detecting deepfake videos in the blink of an eye. Retrieved from http://theconversation.com/detecting-deepfake-videos-in-the-blink-of-an-eye-101072
[9] Bloomberg (2018, September 11). How faking videos became easy and why that’s so scary. Retrieved from https://fortune.com/2018/09/11/deep-fakes-obama-video/
[10] Chesney, R., and Citron, D. (2019). Deepfakes and the new disinformation war: The coming age of post-truth geopolitics. Foreign Affairs, 98, 147.
[11] Tucker, P. (2019, March 31). The newest AI-enabled weapon: Deep-Faking photos of the earth. Re trieved from https://www.defenseone.com/technology/2019/03/next-phase-ai-deep-faking-whole-world and-china-ahead/155944/
[12] Fish, T. (2019, April 4). Deep fakes: AI-manipulated media will be weaponised to trick military. Retrieved from https://www.express.co.uk/news/science/1109783/deep-fakes-ai-artificial-intelligence photos-video-weaponised-china
[13] Marr, B. (2019, July 22). The best (and scariest) examples of AI-enabled deepfakes. Re trieved from https://www.forbes.com/sites/bernardmarr/2019/07/22/the-best-and-scariest-examples of-ai-enabled-deepfakes/
[14] Zakharov, E., Shysheya, A., Burkov, E., and Lempitsky, V. (2019). Few-shot adversarial learning of realistic neural talking head models. arXiv preprint arXiv:1905.08233.
[15] Damiani, J. (2019, September 3). A voice deepfake was used to scam a CEO out of $243,000. Retrieved from https://www.forbes.com/sites/jessedamiani/2019/09/03/a-voice-deepfake-was-used-to scam-a-ceo-out-of-243000/
[16] Samuel, S. (2019, June 27). A guy made a deepfake app to turn photos of women into nudes. It didn’t go well. Retrieved from https://www.vox.com/2019/6/27/18761639/ai-deepfake-deepnude-app nude-women-porn
[17] The Guardian (2019, September 2). Chinese deepfake app Zao sparks privacy row after going vi ral. Retrieved from https://www.theguardian.com/technology/2019/sep/02/chinese-face-swap-app-zao triggers-privacy-fears-viral
[18] Turek, M. (2019). Media Forensics (MediFor). Retrieved from https://www.darpa.mil/program/media forensics
[19] Schroepfer, M. (2019, September 5). Creating a data set and a challenge for deepfakes. Retrieved from https://ai.facebook.com/blog/deepfake-detection-challenge
[20] Punnappurath, A., and Brown, M. S. (2019). Learning raw image reconstruction-aware deep image compressors. IEEE Transactions on Pattern Analysis and Machine Intelligence. DOI: 10.1109/TPAMI.2019.2903062.
[21] Cheng, Z., Sun, H., Takeuchi, M., and Katto, J. (2019). Energy compaction-based image compression using convolutional autoencoder. IEEE Transactions on Multimedia. DOI: 10.1109/TMM.2019.2938345.
[22] Chorowski, J., Weiss, R. J., Bengio, S., and Oord, A. V. D. (2019). Unsupervised speech representa tion learning using wavenet autoencoders. IEEE/ACM Transactions on Audio, Speech, and Language Processing. 27(12), pp. 2041-2053.
[23] Faceswap: Deepfakes software for all. Retrieved from https://github.com/deepfakes/faceswap
[24] FakeApp 2.2.0. Retrieved from https://www.malavida.com/en/soft/fakeapp/
[25] DeepFaceLab. Retrieved from https://github.com/iperov/DeepFaceLab
[26] DFaker. Retrieved from https://github.com/dfaker/df
[27] DeepFake-tf: Deepfake based on tensorflow. Retrieved from https://github.com/StromWine/DeepFake tf
[28] Keras-VGGFace: VGGFace implementation with Keras framework. Retrieved from https://github.com/rcmalli/keras-vggface
[29] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … and Bengio, Y. (2014). Generative adversarial nets. In Advances in Neural Information Processing Systems (pp. 2672-2680).
[30] Faceswap-GAN. Retrieved from https://github.com/shaoanlu/faceswap-GAN
[31] FaceNet. Retrieved from https://github.com/davidsandberg/facenet
[32] CycleGAN. Retrieved from https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
[33] DeepFaceLab: Explained and usage tutorial. Retrieved from https://mrdeepfakes.com/forums/thread deepfacelab-explained-and-usage-tutorial
[34] DSSIM. Retrieved from https://github.com/keras-team/keras-contrib/blob/master/keras contrib/losses/dssim.py
[35] Chesney, R., and Citron, D. K. (2018). Deep fakes: a looming challenge for privacy, democracy, and national security. https://dx.doi.org/10.2139/ssrn.3213954.
[36] Korshunov, P., and Marcel, S. (2019). Vulnerability assessment and detection of deepfake videos. In The 12th IAPR International Conference on Biometrics (ICB), pp. 1-6.
[37] VidTIMIT database. Retrieved from http://conradsanderson.id.au/vidtimit/
[38] Parkhi, O. M., Vedaldi, A., and Zisserman, A. (2015, September). Deep face recognition. In Proceedings of the British Machine Vision Conference (BMVC) (pp. 41.1-41.12).
[39] Schroff, F., Kalenichenko, D., and Philbin, J. (2015). Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 815-823).
[40] Chung, J. S., Senior, A., Vinyals, O., and Zisserman, A. (2017, July). Lip reading sentences in the wild. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 3444-3453). IEEE.
[41] Suwajanakorn, S., Seitz, S. M., and Kemelmacher-Shlizerman, I. (2017). Synthesizing Obama: learning lip sync from audio. ACM Transactions on Graphics (TOG), 36(4), 95:195:13.
[42] Korshunov, P., and Marcel, S. (2018, September). Speaker inconsistency detection in tampered video. In 2018 26th European Signal Processing Conference (EUSIPCO) (pp. 2375-2379). IEEE.
[43] Galbally, J., and Marcel, S. (2014, August). Face anti-spoofing based on general image quality assess ment. In 2014 22nd International Conference on Pattern Recognition (pp. 1173-1178). IEEE.
[44] Wen, D., Han, H., and Jain, A. K. (2015). Face spoof detection with image distortion analysis. IEEE Transactions on Information Forensics and Security, 10(4), 746-761.
[45] Korshunova, I., Shi, W., Dambre, J., and Theis, L. (2017). Fast face-swap using convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision (pp. 3677-3685).
[46] Zhang, Y., Zheng, L., and Thing, V. L. (2017, August). Automated face swapping and its detection. In 2017 IEEE 2nd International Conference on Signal and Image Processing (ICSIP) (pp. 15-19). IEEE.
[47] Wang, X., Thome, N., and Cord, M. (2017). Gaze latent support vector machine for image classification improved by weakly supervised region selection. Pattern Recognition, 72, 59-71.
[48] Bai, S. (2017). Growing random forest on deep convolutional neural networks for scene categorization. Expert Systems with Applications, 71, 279-287.
[49] Zheng, L., Duffner, S., Idrissi, K., Garcia, C., and Baskurt, A. (2016). Siamese multi-layer perceptrons for dimensionality reduction and face identification. Multimedia Tools and Applications, 75(9), 5055- 5073. [50] Xuan, X., Peng, B., Dong, J., and Wang, W. (2019). On the generalization of GAN image forensics. arXiv preprint arXiv:1902.11153.
[51] Yang, P., Ni, R., and Zhao, Y. (2016, September). Recapture image forensics based on Laplacian convo lutional neural networks. In International Workshop on Digital Watermarking (pp. 119-128). Springer, Cham.
[52] Bayar, B., and Stamm, M. C. (2016, June). A deep learning approach to universal image manipulation detection using a new convolutional layer. In Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security (pp. 5-10). ACM.
[53] Qian, Y., Dong, J., Wang, W., and Tan, T. (2015, March). Deep learning for steganalysis via convolu tional neural networks. In Media Watermarking, Security, and Forensics 2015 (Vol. 9409, p. 94090J).
[54] Agarwal, S., and Varshney, L. R. (2019). Limits of deepfake detection: A robust estimation viewpoint. arXiv preprint arXiv:1905.03493.
[55] Maurer, U. M. (2000). Authentication theory and hypothesis testing. IEEE Transactions on Information Theory, 46(4), 1350-1356.
[56] Hsu, C. C., Zhuang, Y. X., and Lee, C. Y. (2019). Deep fake image detection based on pairwise learning. Preprints, 2019050013.
[57] Chopra, S. (2005). Learning a similarity metric discriminatively, with application to face verification. In IEEE Conference on Compter Vision and Pattern Recognition (pp. 539-546).
[58] Huang, G., Liu, Z., Van Der Maaten, L., and Weinberger, K. Q. (2017). Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 4700-4708).
[59] Liu, Z., Luo, P., Wang, X., and Tang, X. (2015). Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision (pp. 3730-3738).
[60] Radford, A., Metz, L., and Chintala, S. (2015). Unsupervised representation learning with deep convo lutional generative adversarial networks. arXiv preprint arXiv:1511.06434.
[61] Arjovsky, M., Chintala, S., and Bottou, L. (2017, July). Wasserstein generative adversarial networks. In International Conference on Machine Learning (pp. 214-223).
[62] Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., and Courville, A. C. (2017). Improved training of Wasserstein GANs. In Advances in Neural Information Processing Systems (pp. 5767-5777).
[63] Mao, X., Li, Q., Xie, H., Lau, R. Y., Wang, Z., and Paul Smolley, S. (2017). Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision (pp. 2794-2802).
[64] Karras, T., Aila, T., Laine, S., and Lehtinen, J. (2017). Progressive growing of GANs for improved quality, stability, and variation. arXiv preprint arXiv:1710.10196.
[65] Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., … and Berg, A. C. (2015). ImageNet large scale visual recognition challenge. International Journal of Computer Vision, 115(3), 211-252.
[66] Brock, A., Donahue, J., and Simonyan, K. (2018). Large scale GAN training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096.
[67] Zhang, H., Goodfellow, I., Metaxas, D., and Odena, A. (2018). Self-attention generative adversarial networks. arXiv preprint arXiv:1805.08318.
[68] Miyato, T., Kataoka, T., Koyama, M., and Yoshida, Y. (2018). Spectral normalization for generative adversarial networks. arXiv preprint arXiv:1802.05957.
[69] Farid, H. (2009). Image forgery detection. IEEE Signal Processing Magazine, 26(2), 16-25.
[70] Mo, H., Chen, B., and Luo, W. (2018, June). Fake faces identification via convolutional neural network. In Proceedings of the 6th ACM Workshop on Information Hiding and Multimedia Security (pp. 43-47). ACM.
[71] Marra, F., Gragnaniello, D., Cozzolino, D., and Verdoliva, L. (2018, April). Detection of GAN-generated fake images over social networks. In 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR) (pp. 384-389). IEEE.
[72] Hsu, C. C., Lee, C. Y., and Zhuang, Y. X. (2018, December). Learning to detect fake face images in the wild. In 2018 International Symposium on Computer, Consumer and Control (IS3C) (pp. 388-391). IEEE.
[73] Afchar, D., Nozick, V., Yamagishi, J., and Echizen, I. (2018, December). MesoNet: a compact facial video forgery detection network. In 2018 IEEE International Workshop on Information Forensics and Security (WIFS) (pp. 1-7). IEEE.
[74] Sabir, E., Cheng, J., Jaiswal, A., AbdAlmageed, W., Masi, I., and Natarajan, P. (2019). Recurrent convolutional strategies for face manipulation detection in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (pp. 80-87).
[75] Cho, K., van Merrienboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., and Bengio, Y. (2014, October). Learning phrase representations using RNN encoderdecoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 1724-1734).
[76] Rossler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies, J., and Niener, M. (2019). FaceForensics++: Learning to detect manipulated facial images. arXiv preprint arXiv:1901.08971.
[77] Guera, D., and Delp, E. J. (2018, November). Deepfake video detection using recurrent neural networks. In 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS) (pp. 1-6). IEEE.
[78] Li, Y., Chang, M. C., and Lyu, S. (2018, December). In ictu oculi: Exposing AI created fake videos by detecting eye blinking. In 2018 IEEE International Workshop on Information Forensics and Security (WIFS) (pp. 1-7). IEEE.
[79] Donahue, J., Anne Hendricks, L., Guadarrama, S., Rohrbach, M., Venugopalan, S., Saenko, K., and Darrell, T. (2015). Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2625-2634).
[80] Simonyan, K., and Zisserman, A. (2014). Very deep convolutional networks for large-scale image recog nition. arXiv preprint arXiv:1409.1556.
[81] He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep residual learning for image recognition. In Pro ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 770-778).
[82] Li, Y., and Lyu, S. (2019). Exposing deepfake videos by detecting face warping artifacts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (pp. 46-52).
[83] Yang, X., Li, Y., and Lyu, S. (2019, May). Exposing deep fakes using inconsistent head poses. In 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 8261-8265). IEEE.
[84] Zhou, P., Han, X., Morariu, V. I., and Davis, L. S. (2017, July). Two-stream neural networks for tam pered face detection. In 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (pp. 1831-1839). IEEE.
[85] Nguyen, H. H., Yamagishi, J., and Echizen, I. (2019, May). Capsule-forensics: Using capsule networks to detect forged images and videos. In 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 2307-2311). IEEE.
[86] Hinton, G. E., Krizhevsky, A., and Wang, S. D. (2011, June). Transforming auto-encoders. In Interna tional Conference on Artificial Neural Networks (pp. 44-51). Springer, Berlin, Heidelberg.
[87] Sabour, S., Frosst, N., and Hinton, G. E. (2017). Dynamic routing between capsules. In Advances in Neural Information Processing Systems (pp. 3856-3866).
[88] Chingovska, I., Anjos, A., and Marcel, S. (2012, September). On the effectiveness of local binary patterns in face anti-spoofing. In Proceedings of the International Conference of Biometrics Special Interest Group (BIOSIG) (pp. 1-7). IEEE.
[89] Rossler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies, J., and Niener, M. (2018). FaceForensics: A large-scale video dataset for forgery detection in human faces. arXiv preprint arXiv:1803.09179.
[90] Thies, J., Zollhofer, M., Stamminger, M., Theobalt, C., and Niener, M. (2016). Face2Face: Real-time face capture and reenactment of RGB videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2387-2395).
[91] Rahmouni, N., Nozick, V., Yamagishi, J., and Echizen, I. (2017, December). Distinguishing computer graphics from natural images using convolution neural networks. In 2017 IEEE Workshop on Informa tion Forensics and Security (WIFS) (pp. 1-6). IEEE.
[92] Guan, H., Kozak, M., Robertson, E., Lee, Y., Yates, A. N., Delgado, A., … and Fiscus, J. (2019, January). MFC datasets: Large-scale benchmark datasets for media forensic challenge evaluation. In 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW) (pp. 63-72). IEEE.
[93] Matern, F., Riess, C., and Stamminger, M. (2019, January). Exploiting visual artifacts to expose deepfakes and face manipulations. In 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW) (pp. 83-92). IEEE.
[94] Koopman, M., Rodriguez, A. M., and Geradts, Z. (2018). Detection of deepfake video manipulation. In The 20th Irish Machine Vision and Image Processing Conference (IMVIP) (pp. 133-136).
[95] Lukas, J., Fridrich, J., and Goljan, M. (2006). Digital camera identification from sensor pattern noise. IEEE Transactions on Information Forensics and Security, 1(2), 205-214.
[96] Rosenfeld, K., and Sencar, H. T. (2009, February). A study of the robustness of PRNU-based camera identification. In Media Forensics and Security (Vol. 7254, p. 72540M). International Society for Optics and Photonics.
[97] Hasan, H. R., and Salah, K. (2019). Combating deepfake videos using blockchain and smart contracts. IEEE Access, 7, 41596-41606.
[98] IPFS powers the Distributed Web. Retrieved from https://ipfs.io/
[99] Chesney, R. and Citron, D. K. (2018, October 16). Disinformation on steroids: The threat of deep fakes. Retrieved from https://www.cfr.org/report/deep-fake-disinformation-steroids
[100] Huang, G. B., Mattar, M., Berg, T., and Learned-Miller, E. (2007, October). Labelled faces in the wild: A database for studying face recognition in unconstrained environments. Technical Report 07-49, University of Massachusetts, Amherst, http://vis-www.cs.umass.edu/lfw/.
[101] Floridi, L. (2018). Artificial intelligence, deepfakes and a future of ectypes. Philosophy and Technology, 31(3), 317-321.
[102] Read, M. (2019, June 27). Can you spot a deepfake? Does it matter? Retrieved from http://nymag.com/intelligencer/2019/06/how-do-you-spot-a-deepfake-it-might-not-matter.html
[103] Maras, M. H., and Alexandrou, A. (2019). Determining authenticity of video evidence in the age of artificial intelligence and in the wake of deepfake videos. The International Journal of Evidence and Proof, 23(3), 255-262.
[104] Fridrich, J., and Kodovsky, J. (2012). Rich models for steganalysis of digital images. IEEE Transactions on Information Forensics and Security, 7(3), 868-882.
[105] Su, L., Li, C., Lai, Y., and Yang, J. (2017). A fast forgery detection algorithm based on exponential Fourier moments for video region duplication. IEEE Transactions on Multimedia, 20(4), 825-840.
[106] Iuliani, M., Shullani, D., Fontani, M., Meucci, S., and Piva, A. (2018). A video forensic framework for the unsupervised analysis of MP4-like file container. IEEE Transactions on Information Forensics and Security, 14(3), 635-645.

