
- 1向量数据库:新一代的数据处理工具_向量数据库csdn
- 2C#对于文件中的文件名判断问题
- 3Android 模拟器下使用虚拟摄像头_安卓模拟器安装摄像头模块教程
- 4【ArcGIS自定义脚本工具】批量裁剪栅格(多对多)_python一个矢量文件批量裁剪多个栅格
- 5(建议收藏)OpenHarmony系统能力SystemCapability列表_systemcapability怎么打开啊
- 6request&response 使用方法_获取response 的请求路径
- 7基于springboot和微信小程序实现桥牌计分管理系统演示【项目源码】_计分小程序源码
- 8deepfacelab SAE 模型训练参数详解_saehd训练多长时间
- 9s23.基于 Kubernetes v1.25 (二进制) 和 Containerd部署高可用集群_kubernetes v1.25.11 对应containerd 版本
- 10(原创)机器学习之矩阵论(三)
【论文分享】InternVideo: General Video Foundation Models via Generative and Discriminative Learning
赞
踩
导言
今天翻译的文章是来自上海人工智能实验室的工作,在多个视频数据集上取得了SOTA的效果,翻译如下。不当之处,还请网友们不吝赐教!
InternVideo: 通过生成式和判别式学习实现通用视频基础模型
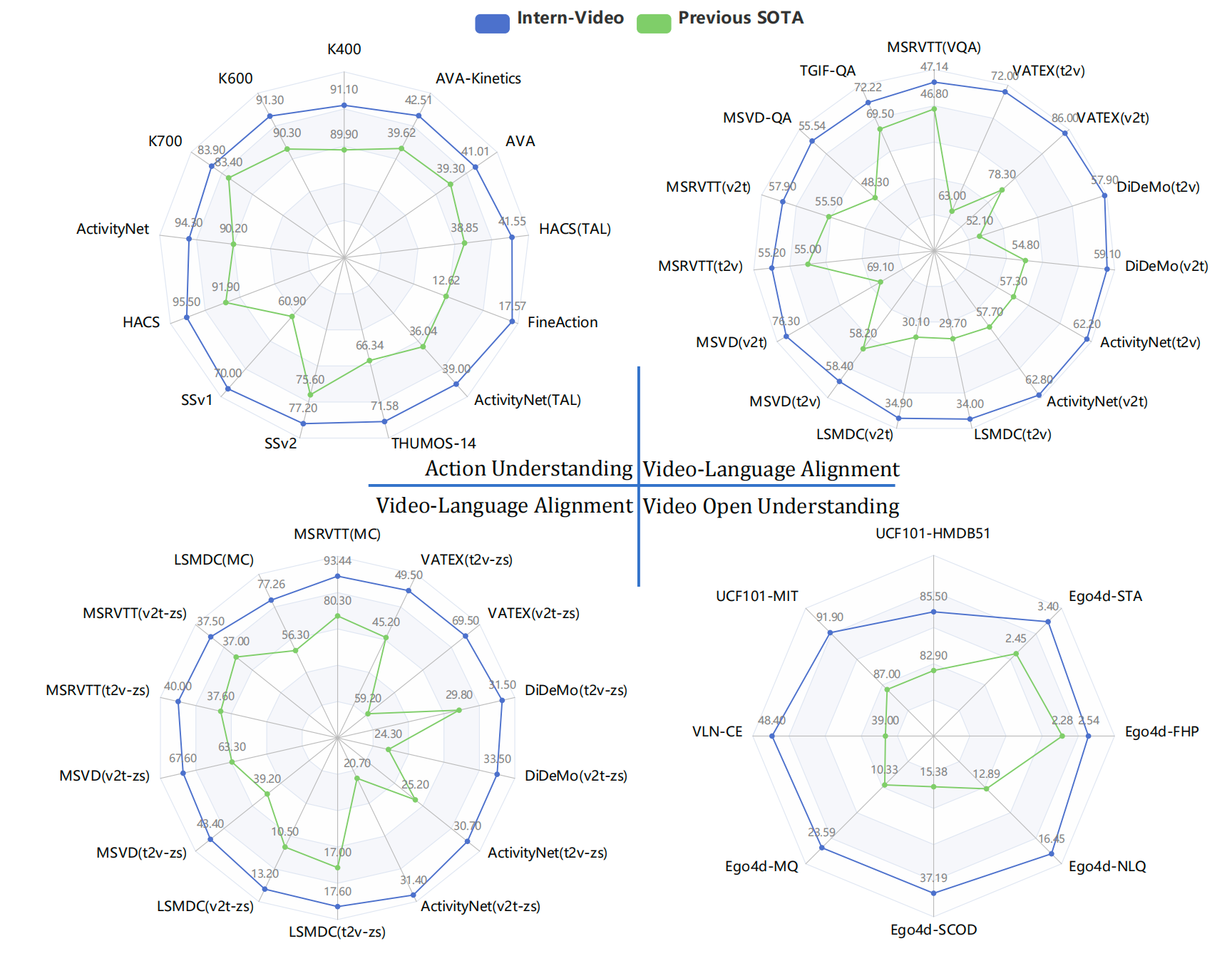
图1:与现有最先进的方法(包括专用模型[1–5]和基础模型[6–9])相比,InternVideo在广泛的视频相关任务上表现最优。比较细节见第4.3节。v2t和t2v分别表示视频到文本和文本到视频的检索。STA、FHP、NLQ、SCOD和MQ分别表示短时目标交互预测(Short-term Object Interaction Anticipation)、未来手部预测(Future Hand Prediction)、自然语言查询(Natural Language Queries)、目标状态变化检测(State Change Object Detection)和时刻查询(Moment Queries)。
Abstract 摘要
最近,基础模型在计算机视觉领域的各种下游任务上表现出色。然而,大多数现有的视觉基础模型仅关注图像层次的预训练和适应(adaption),这对于动态且复杂的视频层次理解任务来说是有限的。为了填补这一空白,我们通过利用生成式和判别式自监督视频学习的优势,提出了通用视频基础模型InternVideo。具体来说,InternVideo高效地探索了遮罩视频建模和视频-语言对比学习作为预训练目标,并以可学习的方式选择性地协调这两个互补框架的视频表示,以提升各种视频应用。在没有额外花哨功能的情况下,InternVideo在包括视频动作识别/检测、视频-语言对齐和开放世界视频应用在内的39个视频数据集上实现了最先进的性能。
Introduction 引言
基础模型在研究领域得到了越来越多的关注[10-12],因为它们为大量感知任务提供了一个实用的范例,取得了出奇好的结果。通过简单的适应或零/少量样本学习,基础模型利用从大规模网络数据中学到的通用表示大大降低了下游设计和训练成本,同时具有高容量的强大支持。人们期望基础模型能够从感知中培养认知,获得通用视觉能力。
尽管已经提出了一系列视觉基础模型[7, 13-21],但与图像任务相比,视频理解及其相关任务的研究相对较少,主要用于验证这些模型的视觉特征对时空表示的益处。我们推测学术界关注相对较少的原因是:1)视频处理带来的高计算负担;2)当前相当多的视频基准测试可以通过利用图像支撑结构的外观特征以及相应的时间建模来处理。具体而言,在空间分辨率相近且时间采样比例通常为 16 的情况下,视频处理的时间维度至少比图像处理复杂一个数量级。对于某些当前的视频数据集,仅靠图像特征或者与侧向时间模块一起,就足以取得不错的结果,特别是在多模态模型 CLIP [13] 的崛起下。其考虑时间信息的各种变体在几个核心任务中取得了竞争力或最先进的性能[5, 22]。考虑到这一点,同时进行时空学习的模型似乎并非研发成本与回报之间的最佳平衡点。
此外,考虑到视频应用的广泛范围,当前视觉基础模型的可迁移性有些局限。这些模型[6, 8, 23, 24]要么关注动作理解任务(如动作识别、时空动作定位等),要么关注视频-语言对齐任务(如视频检索、视频问答等)。我们认为这种情况源于它们的学习方案以及缺乏一个全面的基准测试来衡量视频理解能力。因此,这些研究[6, 8, 23, 24]将重点放在几个特定任务上,以展示它们的时空感知能力。社区期望一个通用的基础模型能够应用于更广泛的领域。
在本文中,我们通过一种成本效益高且通用的模型 InternVideo 来推进视频基础模型的研究。为了建立一种可行且有效的时空表示,我们研究了流行的视频遮罩建模(video masked modeling)[23, 25]和多模态对比学习[13, 26]。需要注意的是,视频遮罩建模专注于动作理解,而当前解码器所导致的有限模型规模仍值得探讨。对于多模态对比学习,它将丰富的语义嵌入到视频表示中,同时忽略了具体的时空建模。为了应对这些挑战,我们让这两种自监督方法在模块化设计中高效地进行大规模学习。
为了显著拓宽当前视频基础模型的泛化能力,我们提出了一种统一的表示学习方法,包括这两种自监督训练方式。为了验证这种通用表示,我们提出了一个系统性的视频理解基准。它涉及到动作理解、视频-语言对齐和开放世界视频应用的评估,我们认为这是通用视频感知的三个核心能力。在该系统中,我们最初选择了 39 个公共数据集中的 10 个具有代表性的视频任务,并将它们划分为这三种类型。据我们所知,InternVideo 是第一个在这三种不同类型的视频任务中表现出有前景的可迁移性并取得最先进性能的视频基础模型。
在 InternVideo 中,我们设计了一个统一的视频表示学习范式(Unified Video Representation,UVR)。它探索了使用自动编码器(Masked Autoencoders, MAE)的遮罩视频建模和两种类型的表示的多模态对比学习,通过监督动作分类加强它们,并基于它们之间的跨表示学习生成更通用的表示。UVR 不仅实证地表明视频表示在核心视频任务上显著优于具有时间捕获的图像表示,而且训练效率高。其 MAE 利用视频中的高冗余性,仅使用少量可见标记进行训练。同时,InternVideo 中的多模态学习扩展了现有的图像预训练骨干结构,用于视频对比训练。在对这两个视频编码器进行监督训练之后,我们设计了跨模型注意力来在这两个几乎冻结的编码器之间进行特征对齐。
除了统一的视频表示学习范式,我们还为大规模视频基础模型的可控和高效训练提供了实践和指导。我们的工作包括但不限于:1)使 VideoMAE 可扩展,并探讨其在模型和数据规模方面的可扩展性;2)关于如何利用现有的图像预训练骨干结构的高效且有效的多模态架构设计和训练方法;3)实证地发现 VideoMAE 和多模态模型的特征具有互补性,并研究如何通过协调不同现有模型来推导出更强大的视频表示。具体而言:
• 对于 VideoMAE 的可扩展性研究,我们证明了在训练视频中适当的多样性和规模扩大可以提高所使用的视频编码器的可扩展性。在一个遮罩自动编码器训练设置的新预训练数据集中,通过微调 ViT 在 Kinetics-400 [27] 上的动作识别性能从 base 到 large 从 81.01% 提高到 85.35%,进一步达到 86.9% 的巨大设置,超过了 [23] 报告的性能,有显著的优势。 VideoMAE 的可扩展性使其在视频基础模型开发中具有可用性。
• 对于将现有基础模型用于多模态学习,我们将图像预训练的视觉变换器 [28] 扩展到视频表示学习。这种迁移学习需要大量的结构和优化定制,或者使用局部和全局时空模块进行多模态预训练。局部模块通过连续且独立的空间和时间注意力计算来解耦时空建模。同时,全局模块计算空间和时间上的标记交互。实验表明,这种重用设计在时空表示学习中是有效的。
• 除了自监督预训练,我们还采用监督动作识别来进一步增强视频表示。结果表明,动作识别是一个很好的源任务,可以迁移到各种下游应用。
• 为了协调基础模型,我们通过跨表示学习将遮罩视频编码器与多模态编码器统一起来,而不是将它们共同训练为一个公式。关于可能相互矛盾的 MAE 和多模态学习(MML)的优化,如何在不损害它们优点的情况下将它们结合在一起仍然是一个悬而未决的问题 [29]。更重要的是,具有对比学习的 MML 需要大量批次进行更好的对比优化。将 MAE 添加到其中将不可避免地导致诸多令人头痛的实现问题。考虑到它们可能的训练对抗性,我们分别训练 MAE 和 MML。在它们的训练收敛之后,我们使用提出的跨模态注意力(Cross-Model Attention,CMA)模块动态地结合它们的表示。它在 MAE 和 MML 的中层特征之间实现跨注意力,自适应地融合它们的高层特征以进行预测。在模型级表示交互阶段,我们分别冻结由 MAE 和 MML 训练的骨干结构,只在监督学习中使用几个时代更新 CMA。实验证明,这是一种计算上可行且高效的方法来利用 MAE 和 MML 特征。
我们在 10 个任务(涵盖 39 个数据集,包括核心任务,如动作识别、时空动作定位、视频问答、视频检索等)中验证了我们提出的视频基础模型,并在每个任务中显著优于所有最先进的方法。我们认为,通过我们的方法获得的这些整体优越结果,以及观察和分析,为视频理解领域树立了一个新的基准。本文的实证证据提高了人们对视频感知任务和部分高阶任务(表述为感知形式)可以通过视频基础模型很好地解决的信心,成为跨一系列应用的性能关键方法。
总之,我们在以下方面为视频基础模型做出贡献:
• 我们探索了一个通用的视频表示范式,结合了遮罩建模和对比建模,通过监督学习中的轻量级模型交互学习统一它们的表示。我们通过实验证实,生成训练和对比训练学到的特征相互补充,并且能够比它们独立训练获得更好的结果。
• 我们发现遮罩视频编码器在模型和数据规模方面可以进行适当的调整。我们设计了可插拔的局部时态和全局时空交互模块,用于重用预训练的 ViT 图像-文本数据进行多模态学习,减轻了训练负担并获得了更好的下游性能。
• 我们在构建系统视频理解基准方面进行了初步尝试。我们的通用视频基础模型在这个基准中的几个核心任务的 39 个数据集上实现了最先进的性能,例如,在动作识别中的 Kinetics-400 和 Something-Something v2。我们实证发现,我们学到的视频表示优于竞争对手,尤其是对于一些基于图像的任务,以大幅度领先视觉-语言任务。这表明通用视频表示将在视频任务中发挥核心作用。我们相信,我们提出的方法和模型的开放性将为研究社区提供方便的基础模型和特征访问工具。
Related Work 相关工作
图像基础模型。大部分当前的视觉模型仅适用于特定任务和领域,需要手动标注的数据集进行训练。针对此问题,最近的研究提出了视觉基础模型。CLIP [13] 和 ALIGN [14] 使用大规模的带噪声的图像-文本对进行对比学习训练双编码器模型,从而为强大的零样本迁移获得鲁棒的图像-文本表示。INTERN [12] 将自监督预训练扩展到多个学习阶段,这些阶段使用大量的图像-文本对以及手动注释的图像。与 CLIP 相比,INTERN 在线性探测(linear probe)性能方面表现更好,并提高了下游图像任务的数据效率。Florence [15] 使用统一的对比学习 [16] 和精细的适应模型扩展了它们,支持不同迁移设置的各种视觉任务。SimVLM [17] 和 OFA [18] 使用生成目标训练编码器-解码器模型,并在一系列多模态任务上表现出竞争力。此外,CoCa [7] 将 CLIP 的对比学习和 SimVLM 的生成学习统一起来。最近,BeiT-3 [19] 引入了统一的 BeiT [20] 预训练的多路 Transformers,实现了多个视觉和图像-语言任务的最先进的迁移结果。
视频基础模型。以前的图像基础模型 [7, 15] 只在视频识别(尤其是 Kinetics)方面表现出有希望的性能。对于视频多模态任务,VIOLET [30] 结合了遮罩语言和遮罩视频建模,All-in-one [24] 提出了具有共享主干的统一视频-语言预训练,LAVENDER [31] 将任务统一为遮罩语言建模。尽管它们在多模态基准中表现良好,但它们使用有限的视频-文本数据进行训练,在仅视频任务(如动作识别)方面面临困难。相反,MERLOT Reserve [32] 收集了 20M 个视频-文本-音频对,通过对比跨度匹配训练联合视频表示,从而实现了最先进的视频识别和视觉常识推理。与图像基础模型相比,当前的视频基础模型仅支持有限的视频和视频-语言任务,尤其是对于那些如时态定位等细粒度时态区分任务。
自监督预训练。最近,自监督学习发展迅速。它关注为预训练设计不同的预设任务 [33-37],主要可以分为对比学习和遮罩建模。对比学习采用各种数据增强手段生成图像的不同视图,然后将正样本对靠近,将负样本对远离。为了保持足够的信息负样本,以前的方法依赖于大型记忆库或批量大小 [38-40]。BYOL [41] 和 SimSiam [42] 消除了负样本的要求,设计了精细的技巧以避免模型崩溃。对于遮罩建模,它根据可见上下文进行遮罩预测以学习丰富的视觉表示。iGPT [43] 首次提及遮罩图像建模(MIM)。BeiT[20] 提出了使用预训练的分词器 [44] 进行视觉令牌预测,MaskFeat [6] 预测手工制作的图像描述符,而 MAE [25] 直接重构原始像素。对于时空表示学习,VideoMAE [23] 和 BEVT [45] 分别将 MAE 和 BeiT 扩展到时空域。
多模态预训练。从图像-文本预训练的发展开始,大规模的视频-文本预训练与特定下游任务微调已成为视频-语言领域的标准范式 [26, 30, 32, 46-51]。开创性方法 [52, 53] 使用预训练的视觉和语言编码器提取离线视频和文本特征,而最近的方法 [9, 24, 26, 46, 54, 55] 已证明端到端训练的可行性。此外,流行的方法通常包括两个或三个预训练任务,例如遮罩语言建模 [31]、视频-文本匹配 [24]、视频-文本对比学习 [47] 和视频-文本遮罩建模 [30]。
3 InternVideo
InternVideo是一个通用视频基础模型,它的训练方式和内部合作方式如图2所示。在结构上, InternVideo采用vision transformer (ViT) [28]及其变体UniformerV2[56]。并引入额外的局部时空建模模块以实现多层表示交互。在学习过程中,InternVideo 逐步改进其表示,整合自监督(遮罩建模和多模态学习)和有监督训练。此外,我们在探索两种类型的自监督学习时,进一步整合了它们的优点。InternVideo 通过可学习的交互动态地从这两个转换器中提取新特征,从生成和对比过程中获得最佳效果。通过新整合的特征,InternVideo 在 10 个主流视频任务的 34 个基准测试中刷新了新的性能记录,并在最近的 Ego4D 比赛 [57] 的五个赛道中夺得冠军。
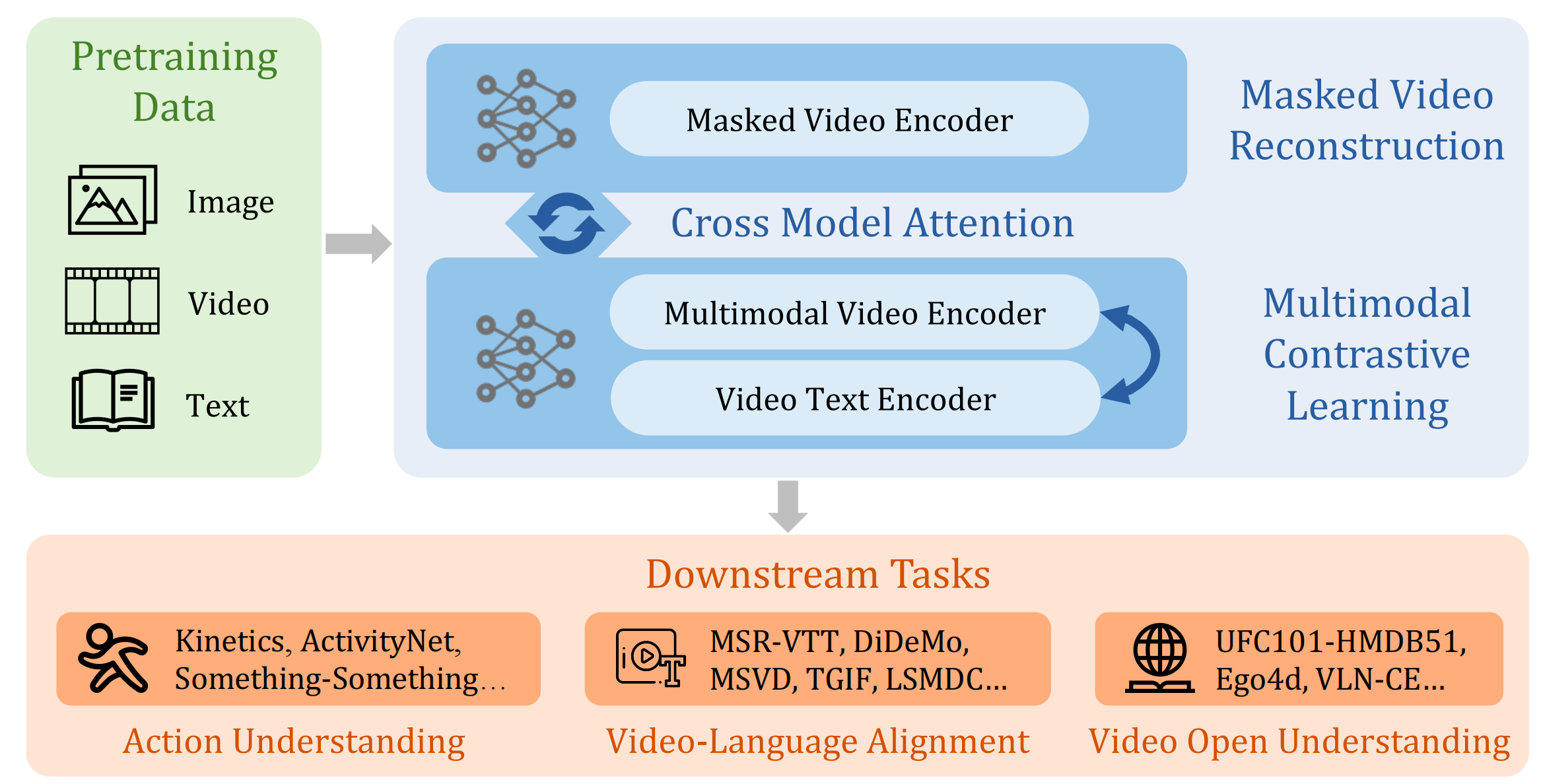
图2 InternVideo整体架构图
3.1 自监督视频预训练
InternVideo 在没有监督的情况下进行遮罩和对比训练,以进行表示学习。根据 [13, 23],视频遮罩建模产生了擅长动作区分的特征,例如动作识别和时态动作定位,视频-语言对比学习能够在没有标注的情况下理解文本中的视频语义。我们采用两个具有不同结构的转换器来更好地利用这两个优化目标。最终的表示通过自适应地聚合这两种类型的表示来构建。
3.1.1 视频遮罩建模
我们遵循我们在 VideoMAE [23] 工作中提出的大部分方法,将 Vanilla Vision Transformer(ViT)作为视频编码器进行时空建模,如图 3(a)所示。VideoMAE 使用高度遮罩的视频输入进行视频重建任务,采用非对称编码器-解码器结构。使用的编码器和解码器都是 ViT。解码器的通道数是编码器的一半,默认为 4 个块(block)。具体来说,我们将时间跨步下采样的视频输入划分为不重叠的 3D 块,并将它们线性投影到立方体嵌入中。然后,我们对这些嵌入应用管状遮罩(例如 90% 的比例),并将它们输入到非对称编码器-解码器结构中进行遮罩视频建模预训练。为了全局描述时空交互,我们在 ViT 中采用联合时空注意力 [58, 59],使所有可见令牌相互全局交互。由于只有少数令牌用于计算,因此它在计算上是可行的。
3.1.2 视频-语言对比学习
我们进行视频/图像-文本对比学习和视频字幕任务预训练,如图 3(b)所示。为了提高训练效率,我们基于预训练的 CLIP[13]构建我们的多模态结构。 而不是直接使用原始的ViT,我们使用我们提出的UniformerV2[56]作为视频编码器以实现更好更高效的时序建模。此外,我们采用额外的转换器解码器进行跨模态学习。具体来说,我们遵循 [7, 60] 给出的典型的先对齐再融合范式。首先,分别对视频和文本进行编码。然后,使用对比损失将视频和文本特征的嵌入空间对齐。在融合阶段,我们应用字幕解码器作为跨模态融合器,使用交叉注意力进行字幕预处理。这种先对齐再融合范式不仅确保了模态可以对齐到相同的单一嵌入空间,对于检索等任务是有益的,而且还赋予了模型结合不同模态的能力,对于像问题回答这样的任务是有益的。字幕解码器的引入既扩展了原始 CLIP 的潜力,也提高了多模态特征的鲁棒性。
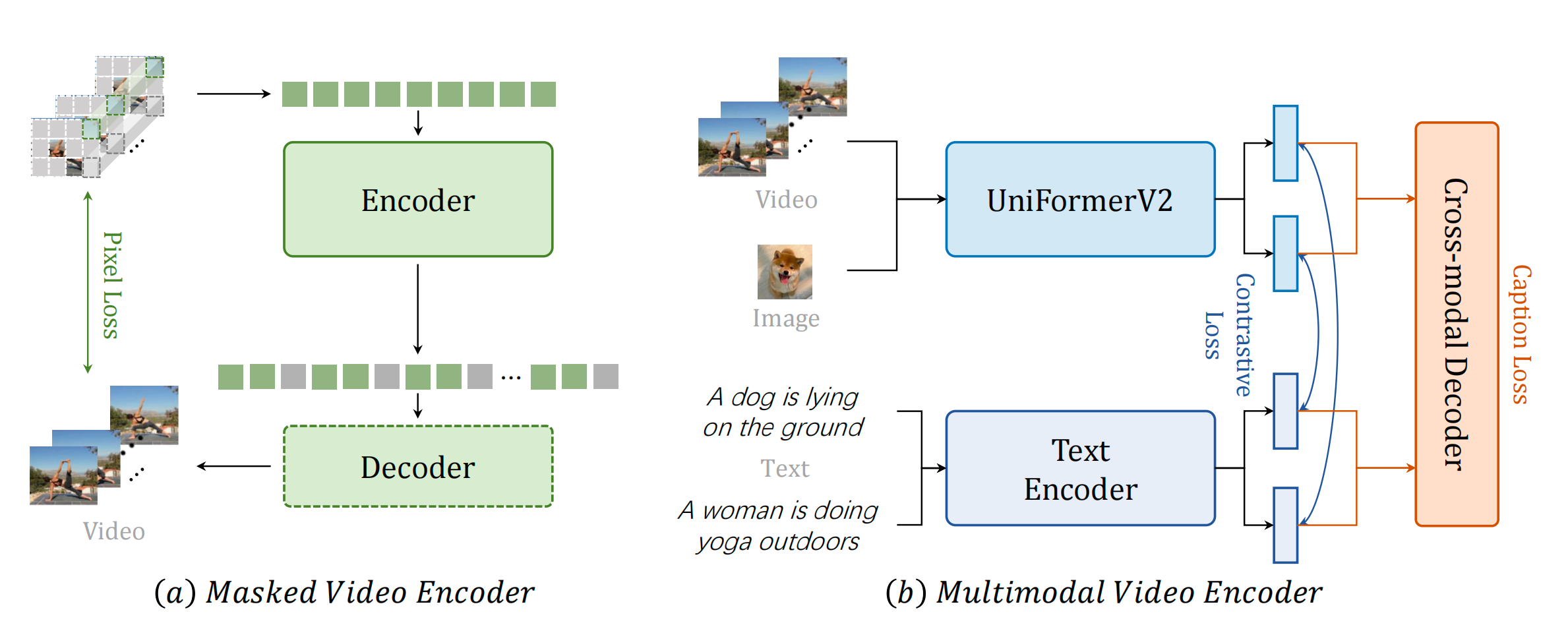
图3 预训练阶段,掩码学习和多模态学习的整体框架
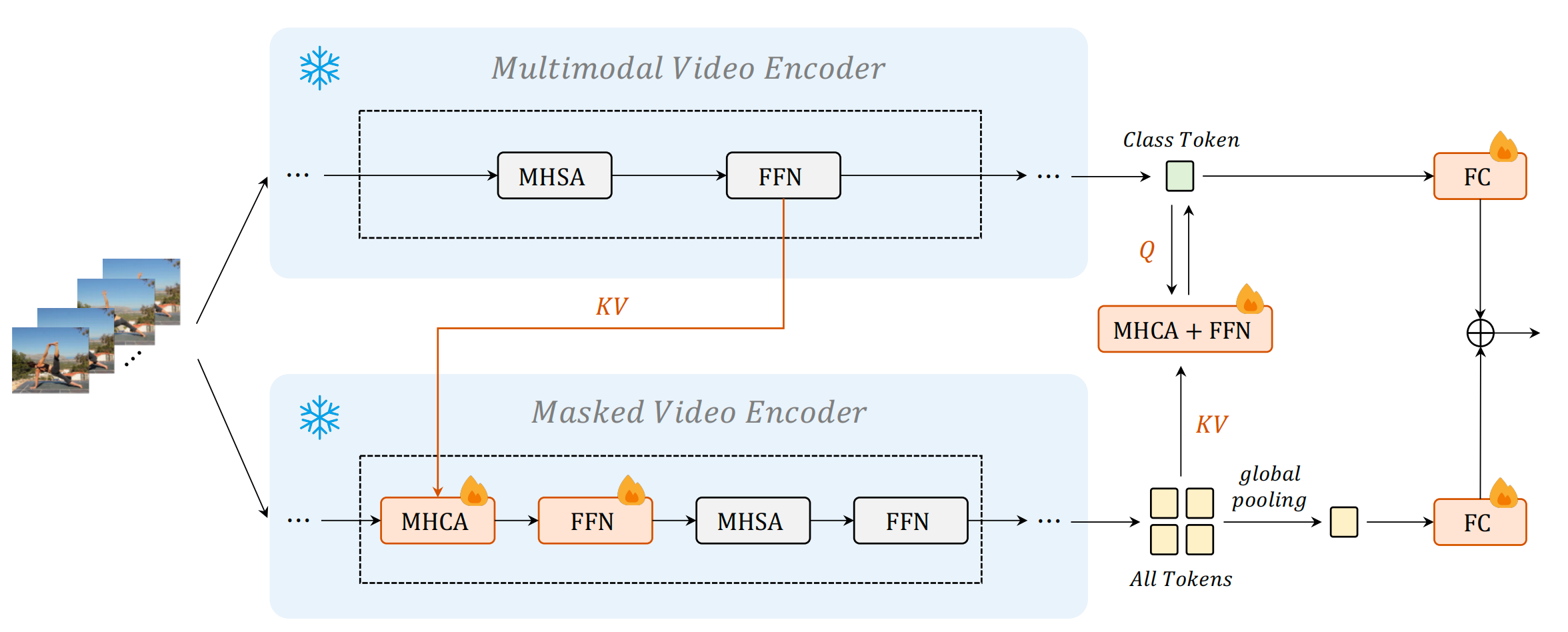
图4 利用交叉模型注意力机制图解模型交互
3.2 Supervised Video Post-Pretraining 有监督视频后预训练
经验性地来说,动作识别在视频下游应用中表现良好,作为元任务得到了广泛验证[61, 62]。因此,我们分别为遮罩视频编码器和多模态视频编码器进行有监督动作分类的后预训练,以提高在多样任务中的性能。为了提升这些编码器的学习能力,我们提出了一个统一的视频基准数据集 Kinetics-710(K710,详见第 4.1 节),用于微调我们的视频编码器。
遮罩视频编码器(Masked Video Encoder): 我们在 K710 上使用 32 个 GPU 对遮罩视频编码器进行微调。我们根据基础学习率和批量大小线性调整学习率,即 lr = 基础学习率 × 批量大小/256。我们采用 DeepSpeed框架来节省内存使用并加速训练。我们将基础学习率设置为 0.001,drop path rate 设置为 0.2,head dropout rate 设置为 0.5,重复采样[63]设置为 2,层衰减(layer decay)设置为 0.8,并训练 40 个周期。
多模态视频编码器(Multimodal Video Encoder). 我们遵循 UniFormer [64] 中的大部分训练方法。为了获得最佳效果,默认情况下,我们采用 CLIP-ViT [13] 作为骨干网络,因为它通过视觉-语言对比学习预训练了鲁棒的表示。我们在 ViT-B/L 的最后 4 层中插入全局 UniBlocks,以执行多阶段融合。我们将基础学习率设置为 1e-5,重复采样设置为 1,批量大小设置为 512,并训练 40 个周期。我们采用稀疏采样[sparse sampling][65],分辨率为 224,适用于所有数据集。在后预训练中,我们使用 UniformerV2 [56] 作为视觉编码器,并以一种使输出与原始 CLIP 模型相同的方式初始化额外的参数,这对于良好的零样本性能至关重要。视频字幕模块是一个标准的 6 层变换器解码器,其后接一个两层 MLP,c = 768。其他设置保持 CLIP Large/14 不变。
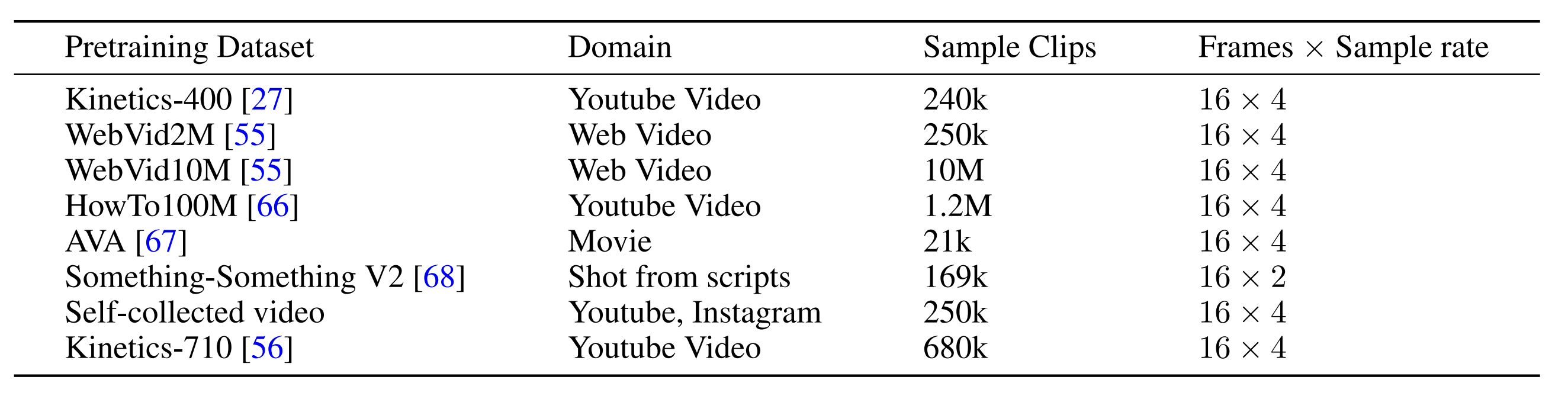
表1:InternVideo预训练过程中使用的数据集概述。
大规模的数据集对于通用视觉预训练至关重要。我们的预训练数据包含来自5个不同领域的1200万个视频片段。
3.3 跨模型交互
为了基于视频遮罩建模和视频-语言对比学习学习统一的视频表示,我们进行交叉表示学习,并添加跨模型注意力模块,如图 4 所示。由于同时优化两个模型计算密集,我们冻结两个主干,除了多模态视频编码器中的分类层和查询标记,只更新新添加的组件。我们添加一些精细的可学习模块(跨模型注意力),用于对齐不同方法中学到的表示。跨模型注意力(CMA)由标准的多头交叉注意力(MHCA)和前馈网络(FFN)组成。它使用来自多模态视频编码器的中间标记作为键和值,而使用来自遮罩视频编码器的标记作为查询。从 CMA 计算出的新标记被视为与多模态视频编码器逐渐对齐的表示。这个过程主要将多模态知识转移到遮罩视频编码器中的 CMA。一个设计例外是,对于最后一个 CMA 模块,其键和值来自遮罩视频编码器的标记,查询来自多模态视频编码器的类标记。因此,类标记根据来自遮罩编码器的标记进行更新。它将单模态知识转移到多模态视频编码器中的 CMA。从这个角度看,遮罩视频编码器所有阶段的特征和多模态视频编码器最后阶段的特征在动作识别监督下得到增强,以协调彼此。最后,我们使用可学习的线性组合动态融合两个预测分数。
4 实验
我们首先详细介绍实验配置(第 4.1 节),然后在第 4.3 节中展示 InternVideo 在所提出的视频理解基准上的下游性能,涵盖三种类型的任务(动作理解,视频-语言对齐和开放理解)。
4.1 预训练数据
通用视频基础模型预训练需要大量不同领域的数据。为了实现多样性的数据分布,我们使用 6 个公共数据集和我们自己收集的视频片段,如表 1 所示。
Kinetics-710. 我们采用新定制的 Kinetics 动作数据集 Kinetics-710 [56] 进行有监督训练,包括单独和联合训练。它包含 650K 个视频,具有 710 个独特的动作标签。它将 Kinetics 400/600/700 [27, 69, 70] 的所有独特训练数据结合在一起。为了避免训练泄漏,我们放弃了特定版本 Kinetics 测试集中存在的一些训练数据。
UnlabeledHybrid. UnlabeledHybrid 数据集用于遮罩视频预训练,包括 Kinetics-710 [56]、Something-Something V2 [68]、AVA [67]、WebVid2M [55] 和我们自己收集的视频。对于 AVA,我们将 15 分钟的训练视频按 300 帧切割,得到 21k 个视频片段。我们分别从自收集视频和 WebVid2M 中随机挑选 250k 个视频。更多细节可参见表 1。
表 2:Kinetics 和 Something-Something 上的动作识别结果。我们比较了表中方法在这些数据集上的 top-1 准确率。InternVideo-D 表示它是由遮罩视频编码器 ViT-H 和 CLIP预训练(CLIP-pretrained)的 UniFormerV2-L 两个模型集成得到的,而 InternVideo-T 表示它是由基于 InternVideo-D 和多模态预训练(multimodal-pretrained)的 UniFormerV2-L集成得到的 。
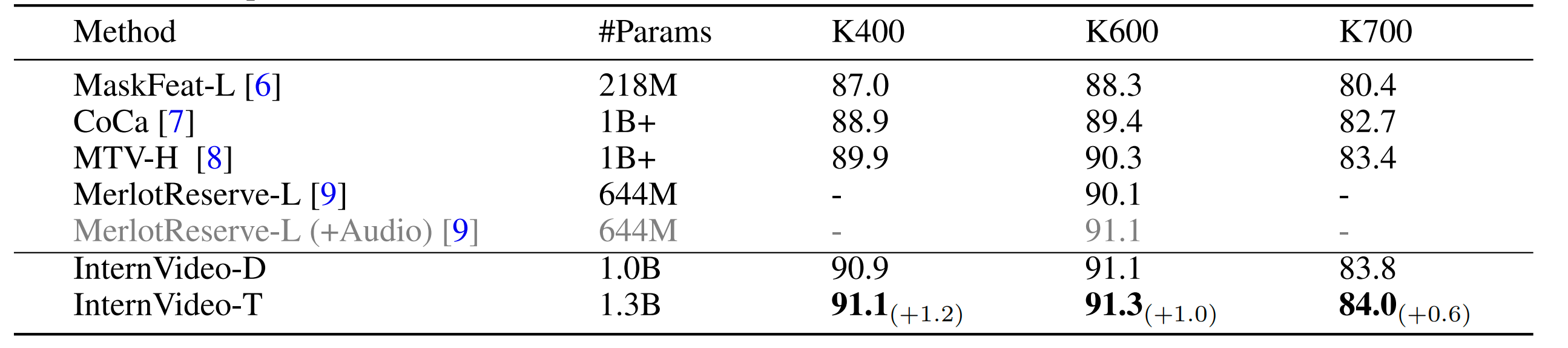
表3: Something-Something 和 ActivityNet 和 HACS 和 HMDB51上的动作识别结果. 我们比较了表中方法在这些数据集上的top-1准确率。

4.2 实现
4.2.1 多模态训练
我们将 CLIP 用作初始化,然后使用 WebVid2M、WebVid10M 和 HowTo100M 对我们的多模态模型进行后期预训练。由于视频文本数据集的训练语料库并不像 CLIP-400M [13] 那样丰富,我们与图像文本数据集共同训练该视频模型,LAION-400M [71] 的一个子集包含了100M的图像文本对。我们在每次迭代中交替使用图像和视频。视频文本的批量大小为14,336,图像文本的批量大小为86,016。我们在128台 NVIDIA A100 GPUs 上训练了400k步,耗时2周,学习率为8 × 10−5,权重衰减为0.2,采用余弦退火调度,并进行了4k的热身步骤。
4.2.2 遮蔽视频训练
我们在 UnlabeledHybrid 数据集上对 VideoMAE-Huge 进行了1200个周期的训练,使用了64台80G-A100 GPUs。该模型采用了余弦退火学习率调度,并预热了总周期数的10%。学习率设定为2.5e − 4。只用了 MultiScaleCrop 进行数据增强。
4.2.3 模型互动
如图4所示,我们冻结了多模态视频编码器中的两个主干网络,只保留分类层和查询标记。为了保持原始输出,我们在额外的 MHCA 和 FFN 中添加了类似于 Flamingo [72] 的双曲正切门控层,动态加权求和中的参数初始化为零。我们以批量大小为64,学习率为 5 × 105,权重衰减为0.001,丢弃率为0.9,EMA速率为0.9999来训练协调模型。此外,我们还使用了一个余弦退火调度,预热了1个周期。所有使用的数据增强都与 UniFormerV2 [56] 相同。
4.3 下游任务
我们在一系列的下游任务上进行了大量实验,以评估 InternVideo。所采用的任务可以分为三类,分别考虑行为理解、视频语言对齐和开放理解。由于 InternVideo 包含了专门用于描述时空变化的遮蔽视频编码器,以及融合了多模态的视频编码器,因此它可以显著提高行为理解(第4.3.1节)和视频语言对齐(第4.3.2节)任务的效果。由大规模训练数据带来的泛化性也使其在相关任务上具有令人印象深刻的零样本和开放集性能(第4.3.3节)。即使转移到以自我为中心的任务上,InternVideo 仍然在简单的头部 [57] 中表现出压倒性的优势。详细信息如下。
表4:在 THUMOS-14 和 ActivityNet-v1.3 以及 HACS 和 FineAction 上的时序动作定位(Temporal action localization)结果。我们报告了每个数据集上比较方法的平均 mAP。

表5:在 AVA2.2 和 AVA-Kinetics (AK) 上的时空动作定位(Spatiotemporal action localization)结果。我们报告了数据集上评估方法的 mAP。

4.3.1 行为理解任务
动作识别(Action Recognition)。动作产生时空模式。 InternVideo 的目标是学习适当时空特征的表示,以及动态模式的建模。我们在8个动作识别基准上评估 InternVideo,包括流行的 Kinetics 和 Something-Something。我们在 Kinetics-400 [27]、Kinetics-600 [69]、Kinetics-700 [70]、Something-in-Something-V1 [68]、Something-in-Something-V2 [68]、 ActivityNet [79]、HACS [80] 和 HMDB51 [81] 上评估 InternVideo 中的 VideoMAE 和 UniFormerV2。我们使用 top-1 准确率作为比较指标。在表2和3中,InternVideo 在所有这些动作识别基准上都展现了极其有前途的表现。我们的 InternVideo 在几乎所有基准上明显优于之前的 SOTA 方法,并在 ActivityNet 上达到了 SOTA 结果。额外融合模型(InternVideo-D vs. InternVideo-T)所带来的准确率提升显示出探索广泛技术路线图的必要性,因为不同的线路在性能上互相受益。
时序动作定位(Temporal Action Localization)。这项任务(TAL)旨在从完全观察的未修剪视频中定位动作片段的起止点。我们在四个经典的 TAL 数据集上评估我们的 InternVideo:THUMOS-14 [82]、ActivityNet-v1.3 [79]、HACS Segment [80] 和 FineAction [83]。与以前的时间动作定位任务一致,我们使用平均精确率(mAP)进行量化评估。每个动作类别都计算精确度(AP),以评估动作类别的提议。它在不同的 tIoU 阈值下进行计算。我们报告了公开可用的最新的 TAL 方法的性能,包括 THUMOS-14、ActivityNet-v1.3 和 FineAction 的 ActionFormer [4] 方法,以及 HACS Segment 的 TCANet [75] 方法。我们使用我们 InternVideo 中的 ViT-H 作为特征提取的骨干。在我们的实验中,ViT-H 模型是从 Hybrid 数据集预训练的。如表4所示,我们的 InternVideo 在这四个 TAL 数据集上的表现优于所有以前的方法。请注意,我们的 InternVideo 在时间动作定位中取得了巨大的提升,特别是在像 THUMOS-14 和 FineAction 这样的细粒度 TAL 数据集中。
时空动作定位(Spatiotemporal Action Localization)。这项任务(STAL)是预测视频关键帧中人的帧和相应的动作。我们在两个经典的 STAL 数据集 AVA2.2 [67] 和 AVA-Kinetics [84] 上评估 InternVideo。在 AVA2.2 [67] 中,每个视频持续15分钟,并每秒给出一个关键帧。注释是为关键帧提供的,而不是所有帧。这里我们使用一个经典的两阶段方法来处理这个任务。我们应用一个在 MS-COCO [85] 上训练良好的 Mask-RCNN [86] 在每个关键帧上检测人,关键帧框在 Alphaction [87] 项目中提供。在第二阶段,以关键帧为中心,提取一定数量的帧并喂入我们的视频骨干。类似地,在训练中,我们使用训练的真实框 [87],并使用第一阶段预测的框进行测试。
我们在 InternVideo 中使用 ViT-Huge 进行实验。具体结果可以在表5中看到。分类头使用一个简单的线性头,在两个数据集上都达到了 SOTA 性能。注意使用 ViT-H 模型,并且使用 AVA-Kinetics 数据集进行训练,不仅提高了整体的 mAP,而且显著提高了仅在 AVA 上测试获得的 mAP。这表明将一些 Kinetics 视频引入 AVA 将提高模型在 AVA 上的泛化能力;另一方面,观察 AVA 数据集的各种分布,我们发现 AVA 呈现出典型的长尾分布。引入 Kinetics 视频将会缓解这个问题,从而获得更好的结果。由于在 AVA-Kinetics 数据集上验证的模型数量较小,所以在表5中只选择了来自 paperswithcode 网站的结果。
表6:在MSR-VTT、MSVD、LSMDC、ActivityNet、DiDeMo和VATEX上的视频检索结果。我们报告了文本到视频(T2V)和视频到文本(V2T)检索任务的R@1结果。【译者注:R@1(Rank-1 Accuracy)是衡量模型性能的一种指标,通常用于评估基于图像的识别或检索任务。R@1 指标是指在对测试数据集进行预测时,模型预测的最高概率类别与实际标签相同的比例。换句话说,它衡量了模型在给定一个查询(query)图像时能否正确地返回与之匹配的图像。
具体来说,对于一个给定的查询图像,模型将对数据集中的所有图像进行预测,并按照预测概率进行排序。然后,R@1 指标是指模型将查询图像的最高预测概率分配给的类别与查询图像的实际类别相同的比例。
例如,如果数据集中有 100 个类别,每个类别有 100 张图像,那么在进行 R@1 计算时,模型将对每个查询图像进行预测,并将它与数据集中所有图像进行比较。然后,R@1 指标将计算出模型在所有查询图像上的平均准确率。
R@1 指标是图像识别和检索任务中常用的指标之一,但它并不能完全反映模型的性能。在某些情况下,使用其他指标如 Top-k Accuracy 或 Mean Average Precision (MAP) 可能更加合适。】

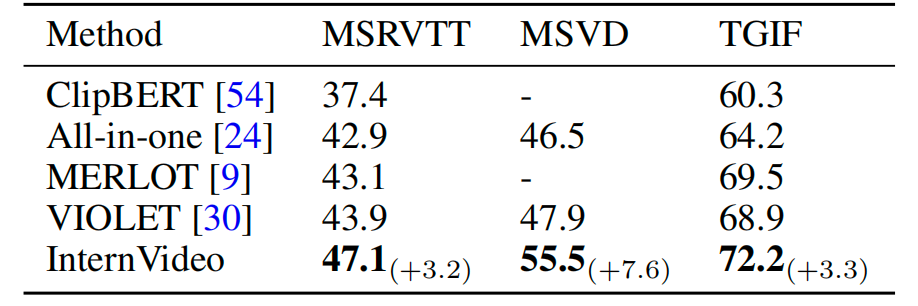
表7:在MSRVTT、MSVD和TGIF上的视频问题回答。我们报告了top-1准确率。
【译者注:在机器学习和深度学习中,Top-k准确率是评估分类模型性能的一种指标,它表示模型在前k个预测结果中,将样本正确分类的比例。而Top-1准确率是Top-k准确率的一个特例,即k=1时的情况,它表示模型在所有预测结果中,将样本正确分类的比例。
具体来说,对于一个分类模型和一个测试数据集,Top-k准确率的计算方式是:对于每个测试样本,模型会输出k个最有可能的类别,并将这k个类别按照概率从高到低排序。如果样本真实的类别在这k个类别中,那么该样本就被视为分类正确。Top-1准确率是Top-k准确率的一种特殊情况,即k=1时的情况。
Top-1准确率是最常见的分类准确率指标,因为它对于模型预测最可能的单一类别的能力进行了评估。而Top-k准确率可以更全面地评估模型的分类能力,因为它考虑了样本可能属于多个类别的情况。通常情况下,Top-k准确率中的k通常取2、3、5、10等值。
总结:Top-1准确率是Top-k准确率的一种特殊情况,它评估模型预测最可能的单一类别的能力。而Top-k准确率可以更全面地评估模型的分类能力,反应了多个可能的类别。】
4.3.2 视频-语言对齐任务
视频检索(Video Retrieval.)我们在视频检索任务上评估InternVideo。给定一组视频和相关的自然语言字幕,此任务需要从候选项中检索匹配的视频或字幕,以对应其跨模态对应项。我们遵循通用范例,通过视觉编码器fv(·)和文本编码器ft(·)来捕获视觉和文本语义,然后计算跨模态相似性矩阵作为检索指导。我们利用多模态视频编码器作为fv(·)和ft(·),预训练的ViT-L/14 [28]作为基本的CLIP [13]架构,并在每个检索数据集上微调整个模型。训练方法和大部分超参数设置遵循CLIP4Clip [5],包括训练计划,学习率,批量大小,视频帧数,最大文本长度等。为了提升模型性能,我们还采用了双softmax损失[91]作为后处理操作。
我们的模型在六个公开基准测试上进行了评估:MSR-VTT [92],MSVD [93],LSMDC [94],DiDeMo [95],ActivityNet [79]和VATEX [96],我们按照之前的工作报告了标准划分的结果。我们在文本到视频和视频到文本任务上都使用排名-1(R@1)指标来度量检索结果,这些结果显示在表6中。结果显示,我们的模型大幅度超越了所有以前的方法,显示了InternVideo在视频语言相关任务上的优越性。更详细的检索结果,包括排名-5(R@5)和排名-10(R@10),可以在补充材料中找到。
视频问答(Video Question Answering.)为了进一步展示InternVideo的视觉语言能力,我们在视频问答(VQA)上评估InternVideo。给定一个视频和问题对,VQA的任务是预测问题的答案。与没有跨模态融合的原始CLIP模型不同,我们的多模态视频编码器能够通过提出的字幕解码器捕捉模态之间的交互。有三种可能的方式来生成VQA分类器所需的特征:连接视频编码器和文本编码器的特征,只使用字幕解码器的特征,以及连接来自视频编码器,文本编码器和字幕解码器的所有特征。经过比较,我们选择使用所有三种来源的特征来提升性能。VQA分类器是一个三层MLP。
我们在三个流行的公开基准测试上进行评估:MSR-VTT [92],MSVD [97]和TGIF [98]。我们主要遵循[24]中的做法。结果显示在表7中,我们的模型超越了所有以前的SOTA,这证明了我们的跨模态学习方法的有效性。
视觉语言导航(Visual Language Navigation.)视觉语言导航[99]要求一个智能体根据其视觉感知按照自然语言指令在未知的照片真实环境中导航。导航智能体应该能够捕获时空信息,比如从导航历史中的物体相对运动,特别是当智能体在连续空间中以短步长导航时。为了验证我们模型这种能力的有效性,我们在VLN-CE benchmark[100]上进行了实验,要求智能体在连续环境中工作。
我们使用[90](CWP-HEP)提出的方法进行我们的实验。历史增强型规划智能体( history-enhanced planner)是HAMT [101]的定制变体,它使用深度嵌入和RGB嵌入的连接作为输入嵌入。请注意,我们在这里不使用试验控制器,因为VLN-CE设置允许滑动。这是一个强大的基准线,已经超越了之前的最新方法CWP-VLNBERT [89]。在每个决策循环中,我们收集最新的16帧观察结果来形成全景导航视频,然后使用InternVideo中的ViT-L对视频进行编码。视频嵌入与RGB嵌入和深度嵌入连接作为最终的图像嵌入。对于评估,我们参考[90]的详细指标。InternVideo可以将我们的基线从50.2%提高到52.9%的成功率(SR)(表8)。
表8:VLN-CE数据集的结果。

表9:在MSR-VTT、MSVD、LSMDC、ActivityNet、DiDeMo和VATEX上进行零样本视频检索的结果。我们报告了文本到视频(T2V)和视频到文本(V2T)检索任务上的R@1结果。

4.3.3 视频开放理解任务
零样本动作识别(Zero-shot Action Recognition.)。零样本识别是原始CLIP模型的出色功能之一。通过我们设计的多模态视频编码器,我们也可以实现出色的零样本动作识别性能,而无需进一步优化。我们在Kinetics-400数据集上评估我们的模型,准确率为64.25%,这大幅超过了之前的最佳成绩56.4% [102]。零样本视频检索。我们将InternVideo与CLIP进行零样本文本到视频和视频到文本检索的比较。为了公平比较,我们使用预训练权重1的CLIP的ViT-L/14模型。采用Wise-finetuning [103] 和模型集成以进一步提升零样本视频检索的模型性能。我们实证地发现零样本检索的最佳视频帧数在4和8之间,每个基准数据集上表现最佳的帧数是通过网格搜索得出的。如表9所示,InternVideo在所有六个基准数据集上都显示出优越的检索能力。此外,Florence [15] 使用了900M的图像-文本对进行预训练,它在MSR-VTT上的文本到视频检索的R@1精度达到了37.6。相比之下,我们的模型以较少的训练数据(14.35M视频+ 100M图像vs 900M图像)优于Florence 4.1%。这些结果揭示了我们方法在预训练过程中学习联合视频-文本特征空间的有效性。
零样本多选(Zero-shot Multiple Choice.)。零样本多选是另一个可以展示模型通用性的零样本任务。多选任务的目标是在给定选项中找到正确的答案,通常是一个小子集,如5个词。我们发现,与图像-文本对的联合训练,Wise-finetuning和模型集成对零样本多选的性能至关重要。我们在表10中报告了在MSR-VTT和LSMDC数据集上的零样本多选结果。我们使用零样本性能作为训练中通用性的一个方便的指标,结果表明我们的模型是稳健和有效的。
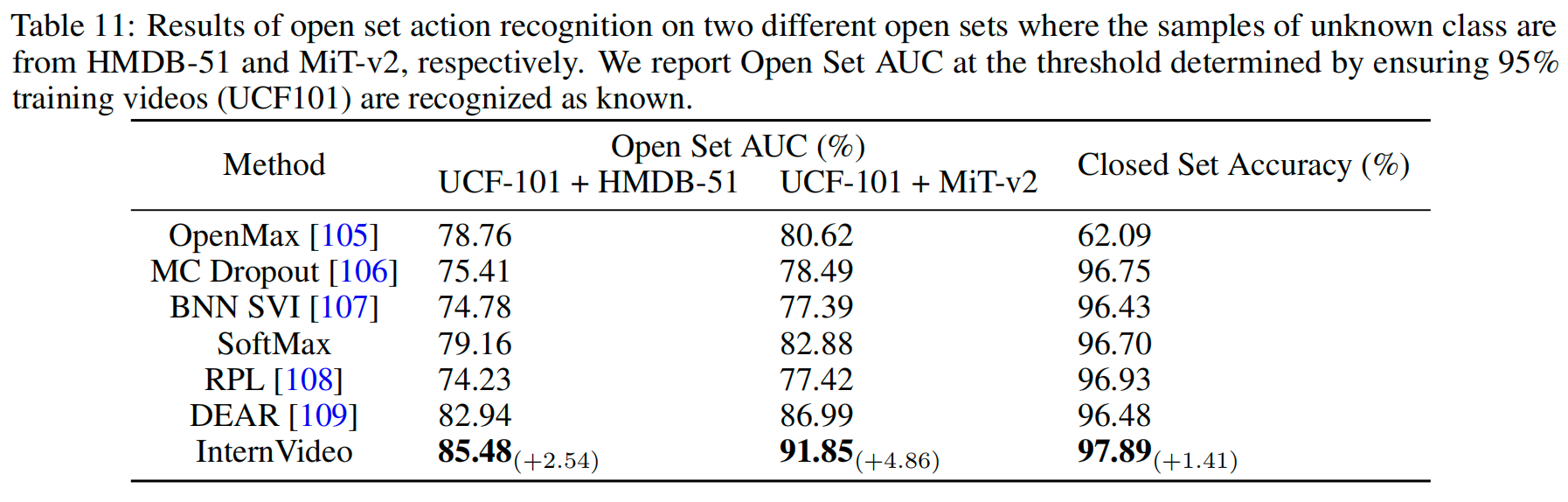
开放集动作识别。(Open-set Action Recognition.)在开放集动作识别(OSAR)中,模型需要能够识别训练类别中的已知动作样本,并拒绝那些超出训练类别的未知样本。由于人类动作的不确定的时间动态和静态偏差 [109],与图像相比,视频动作在开放集识别(OSR)设置中更具挑战性。我们的InternVideo非常适应训练类别之外的未知类别,并在没有任何模型校准的情况下超越了现有方法 [109]。
我们使用InternVideo的ViT-H/16模型作为主干,在UCF-101 [110] 训练集上对其进行微调,并使用一个简单的线性分类头。为了使InternVideo能够“知道未知”,我们遵循 [109] 中提出的DEAR方法,通过利用证据深度学习(EDL),将其形式化为一个不确定性估计问题,这为多类分类和不确定性建模提供了一种联合形式化的方法。具体来说,给定一个视频作为输入,InternVideo主干顶部的Evidential Neural Network(ENN)头预测类别的证据,形成一个Dirichlet分布,从而确定输入的多类概率和预测的不确定性。在开放集推理过程中,高不确定性的视频可以被视为未知的动作,而低不确定性的视频则由学习到的类别概率进行分类。
InternVideo不仅可以准确地识别已知的动作类别,而且还可以识别未知的类别。表11报告了InternVideo以及其他基线的封闭集(封闭集精度)和开放集(开放集AUC)性能的结果。结果显示,我们的InternVideo在两个开放集数据集中,无论已知样本来自HMDB-51 [81] 还是MiT-v2 [111],都始终显著优于其他基线。
表10:在MSR-VTT和LSMDC数据集上的零样本多选结果。灰色部分表示使用监督学习的方法。

表11:在两个不同开放集上进行开放集动作识别的结果,其中未知类别样本分别来自HMDB-51和MiT-v2。我们报告了在给定阈值下的开放集的AUC,阈值设定在确保95%的训练视频(UCF101)被识别为已知类别。
5 结论性言论
在本文中,我们提出了一个多功能且训练高效的视频基础模型InternVideo。据我们所知,InternVideo是第一个在所有动作理解、视频-语言对齐和视频开放理解任务中表现最好的研究。与以前的相关工作[6, 8, 9]相比,它通过在近40个涵盖10个不同任务的数据集上实现最先进的性能,极大地提升了视频基础模型的通用性。该模型利用了基于Mask视频学习(VideoMAE)和视频-语言对比建模以及监督训练之间的跨模型学习的统一视频表示。与以前的基础模型相比,它在训练中非常高效。使用简单的ViT及其相应的变体,我们在64.5K GPU小时(A100-80G)内实现了通用视频表示,而CoCa [7]需要245.76K TPU小时(v4)。我们在一系列应用上验证了这种通用的时空表示。通过简单的任务头(甚至是线性的)和适当的下游调整调优,我们的视频表示在所有使用的数据集中都展示了打破历史纪录的结果。即使在零样本和开放数据集中,我们的模型谱仍然提供了一致且显著的性能提升,进一步证明了其泛化和适应能力。
5.1 限制
我们的研究显示了视频基础模型的有效性和可行性,而不是提供全新的公式或模型设计。它关注当前流行的视频感知任务,并使用剪辑处理视频。它的设计几乎无法处理长期视频任务,以及高阶任务,例如从电影的已观看部分预测剧情。获取解决这些任务的能力对于进一步推动视频表示学习的通用性至关重要。
5.2 未来工作
为了进一步扩展视频基础模型的通用性,我们认为将模型协调与认知并入其研究是必要的。具体来说,如何系统地协调来自不同模态、预训练任务甚至不同架构的基础模型以获得更好的表示仍然是开放待讨论,并且具有挑战性的。有多种技术路线可以解决这个问题,例如模型蒸馏、统一不同的预训练目标、特征对齐等等。通过利用以前学到的知识,我们可以持续加速视频基础模型的开发。
从长远来看,基础模型有望超越感知能力,实现具备认知能力。从可行性的角度来看,我们认为在开放世界中从基础动态感知(foundational dynamic perception)中实现大规模时空分析(长期&大场景)是这个领域的研究趋势之一,它带来了基本的认知理解。此外,它引发了一种潮流,将基础模型与决策结合,形成智能体来探索新任务。在这种交互中,数据收集和模型训练也自动化了。整个过程进入了一个闭环,因为交互结果将调整代理策略和行为。我们的初步实验(第4.3.2节)证明了将视频基础模型集成到具身智能(Embodied AI.)的前景非常可观。
【译者注:具身智能(Embodied Artificial Intelligence,Embodied Intelligence,Embodied AI)又称“具身AI”“具身人工智能”指的是是通过创建软硬件结合的智能体。 可以简单理解为各种不同形态的机器人,让它们在真实的物理环境下执行各种各样的任务,来完成人工智能的进化过程。】
6 更广泛的影响(board impact)
我们提出了一个视频基础模型谱(model spectrum)InternVideo。它能够在大约40个数据集上提供最先进的性能,能够进行动作区别、视频-语言对齐和开放理解。除了公开数据,我们还利用了从互联网上自行收集的数据。用于收集数据的查询已经过道德和法律问题的检查,所策划的数据也是如此。训练InternVideo的功耗远低于CoCa [7],只占CoCa的23.19%。对于进一步的影响研究,我们需要探讨偏见、风险、公平性、平等以及更多的社会话题。
引用
References
[1] Boyang Xia, Wenhao Wu, Haoran Wang, Rui Su, Dongliang He, Haosen Yang, Xiaoran Fan, and Wanli Ouyang. Nsnet:
Non-saliency suppression sampler for efficient video recognition. In ECCV, 2022.
[2] Alexandros Stergiou and Ronald Poppe. Learn to cycle: Time-consistent feature discovery for action recognition. Pattern
Recognition Letters, 141:1–7, 2021.
[3] Lei Wang and Piotr Koniusz. Self-supervising action recognition by statistical moment and subspace descriptors. In ACM
International Conference on Multimedia, 2021.
[4] Chenlin Zhang, Jianxin Wu, and Yin Li. Actionformer: Localizing moments of actions with transformers. In eccv, 2022.
[5] Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, and Tianrui Li. Clip4clip: An empirical study of clip for
end to end video clip retrieval and captioning. Neurocomputing, 2022.
[6] Chen Wei, Haoqi Fan, Saining Xie, Chao-Yuan Wu, Alan Yuille, and Christoph Feichtenhofer. Masked feature prediction for
self-supervised visual pre-training. In CVPR, 2022.
[7] Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu. Coca: Contrastive captioners
are image-text foundation models. arXiv preprint arXiv:2205.01917, 2022.
[8] Shen Yan, Xuehan Xiong, Anurag Arnab, Zhichao Lu, Mi Zhang, Chen Sun, and Cordelia Schmid. Multiview transformers
for video recognition. In CVPR, 2022.
[9] Rowan Zellers, Ximing Lu, Jack Hessel, Youngjae Yu, Jae Sung Park, Jize Cao, Ali Farhadi, and Yejin Choi. Merlot:
Multimodal neural script knowledge models. NeurIPS, 2021.
[10] Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein,
Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models. arXiv preprint
arXiv:2108.07258, 2021.
[11] Hassan Akbari, Liangzhe Yuan, Rui Qian, Wei-Hong Chuang, Shih-Fu Chang, Yin Cui, and Boqing Gong. Vatt: Transformers
for multimodal self-supervised learning from raw video, audio and text. NeurIPS, 2021.
[12] Jing Shao, Siyu Chen, Yangguang Li, Kun Wang, Zhenfei Yin, Yinan He, Jianing Teng, Qinghong Sun, Mengya Gao, Jihao
Liu, et al. Intern: A new learning paradigm towards general vision. arXiv preprint arXiv:2111.08687, 2021.
[13] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda
Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML,
2021.
[14] Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom
Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In ICML, 2021.
[15] Lu Yuan, Dongdong Chen, Yi-Ling Chen, Noel Codella, Xiyang Dai, Jianfeng Gao, Houdong Hu, Xuedong Huang, Boxin Li,
Chunyuan Li, et al. Florence: A new foundation model for computer vision. arXiv preprint arXiv:2111.11432, 2021.
[16] Jianwei Yang, Chunyuan Li, Pengchuan Zhang, Bin Xiao, Ce Liu, Lu Yuan, and Jianfeng Gao. Unified contrastive learning in
image-text-label space. In CVPR, 2022.
[17] Zirui Wang, Jiahui Yu, Adams Wei Yu, Zihang Dai, Yulia Tsvetkov, and Yuan Cao. SimVLM: Simple visual language model
pretraining with weak supervision. In ICLR, 2022.
[18] Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia
Yang. Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. In
ICML, 2022.
[19] Wenhui Wang, Hangbo Bao, Li Dong, Johan Bjorck, Zhiliang Peng, Qiang Liu, Kriti Aggarwal, Owais Khan Mohammed,
Saksham Singhal, Subhojit Som, et al. Image as a foreign language: Beit pretraining for all vision and vision-language tasks.
arXiv preprint arXiv:2208.10442, 2022.
[20] Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. BEit: BERT pre-training of image transformers. In ICLR, 2022.
[21] Paul Barham, Aakanksha Chowdhery, Jeff Dean, Sanjay Ghemawat, Steven Hand, Daniel Hurt, Michael Isard, Hyeontaek Lim,
Ruoming Pang, Sudip Roy, et al. Pathways: Asynchronous distributed dataflow for ml. Proceedings of Machine Learning and
Systems, 2022.
[22] Yiwei Ma, Guohai Xu, Xiaoshuai Sun, Ming Yan, Ji Zhang, and Rongrong Ji. X-clip: End-to-end multi-grained contrastive
learning for video-text retrieval. In ACM International Conference on Multimedia, 2022.
[23] Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. VideoMAE: Masked autoencoders are data-efficient learners for
self-supervised video pre-training. In NeurIPS, 2022.
[24] Alex Jinpeng Wang, Yixiao Ge, Rui Yan, Yuying Ge, Xudong Lin, Guanyu Cai, Jianping Wu, Ying Shan, Xiaohu Qie, and
Mike Zheng Shou. All in one: Exploring unified video-language pre-training. arXiv preprint arXiv:2203.07303, 2022.
[25] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision
learners. In CVPR, 2022.
[26] Tianhao Li and Limin Wang. Learning spatiotemporal features via video and text pair discrimination. CoRR, abs/2001.05691,
2020.
[27] Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In CVPR, 2017.
[28] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa
Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16
words: Transformers for image recognition at scale. In ICLR, 2021.
[29] Roman Bachmann, David Mizrahi, Andrei Atanov, and Amir Zamir. Multimae: Multi-modal multi-task masked autoencoders.
arXiv preprint arXiv:2204.01678, 2022.
[30] Tsu-Jui Fu, Linjie Li, Zhe Gan, Kevin Lin, William Yang Wang, Lijuan Wang, and Zicheng Liu. Violet: End-to-end
video-language transformers with masked visual-token modeling. arXiv preprint arXiv:2111.12681, 2021.
[31] Linjie Li, Zhe Gan, Kevin Lin, Chung-Ching Lin, Zicheng Liu, Ce Liu, and Lijuan Wang. Lavender: Unifying video-language
understanding as masked language modeling. arXiv preprint arXiv:2206.07160, 2022.
[32] Rowan Zellers, Jiasen Lu, Ximing Lu, Youngjae Yu, Yanpeng Zhao, Mohammadreza Salehi, Aditya Kusupati, Jack Hessel,
Ali Farhadi, and Yejin Choi. Merlot reserve: Neural script knowledge through vision and language and sound. In CVPR, 2022.
[33] Carl Doersch, Abhinav Gupta, and Alexei A Efros. Unsupervised visual representation learning by context prediction. In
ICCV, 2015.
[34] Xiaolong Wang and Abhinav Gupta. Unsupervised learning of visual representations using videos. In ICCV, 2015.
[35] Mehdi Noroozi and Paolo Favaro. Unsupervised learning of visual representations by solving jigsaw puzzles. In ECCV, 2016.
[36] Richard Zhang, Phillip Isola, and Alexei A Efros. Colorful image colorization. In ECCV, 2016.
[37] Christoph Feichtenhofer, Haoqi Fan, Yanghao Li, and Kaiming He. Masked autoencoders as spatiotemporal learners. arXiv
preprint arXiv:2205.09113, 2022.
[38] Zhirong Wu, Yuanjun Xiong, Stella X Yu, and Dahua Lin. Unsupervised feature learning via non-parametric instance
discrimination. In CVPR, 2018.
[39] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation
learning. In CVPR, 2020.
[40] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of
visual representations. In ICML, 2020.
[41] Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch,
Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to
self-supervised learning. NeurIPS, 2020.
[42] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In CVPR, 2021.
[43] Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. Generative pretraining
from pixels. In ICML, 2020.
[44] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever.
Zero-shot text-to-image generation. In ICML, 2021.
[45] Rui Wang, Dongdong Chen, Zuxuan Wu, Yinpeng Chen, Xiyang Dai, Mengchen Liu, Yu-Gang Jiang, Luowei Zhou, and
Lu Yuan. Bevt: Bert pretraining of video transformers. In CVPR, 2022.
[46] Antoine Miech, Jean-Baptiste Alayrac, Lucas Smaira, Ivan Laptev, Josef Sivic, and Andrew Zisserman. End-to-end learning
of visual representations from uncurated instructional videos. In CVPR, 2020.
[47] Hu Xu, Gargi Ghosh, Po-Yao Huang, Dmytro Okhonko, Armen Aghajanyan, Florian Metze, Luke Zettlemoyer, and Christoph
Feichtenhofer. Videoclip: Contrastive pre-training for zero-shot video-text understanding. arXiv preprint arXiv:2109.14084,
2021.
[48] Xiaowei Hu, Zhe Gan, Jianfeng Wang, Zhengyuan Yang, Zicheng Liu, Yumao Lu, and Lijuan Wang. Scaling up visionlanguage pre-training for image captioning. In CVPR, 2022.
[49] Zi-Yi Dou, Yichong Xu, Zhe Gan, Jianfeng Wang, Shuohang Wang, Lijuan Wang, Chenguang Zhu, Pengchuan Zhang,
Lu Yuan, Nanyun Peng, et al. An empirical study of training end-to-end vision-and-language transformers. In CVPR, 2022.
[50] Sheng Shen, Liunian Harold Li, Hao Tan, Mohit Bansal, Anna Rohrbach, Kai-Wei Chang, Zhewei Yao, and Kurt Keutzer.
How much can clip benefit vision-and-language tasks? arXiv preprint arXiv:2107.06383, 2021.
[51] Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and
Chunjing Xu. Filip: Fine-grained interactive language-image pre-training. arXiv preprint arXiv:2111.07783, 2021.
[52] Chen Sun, Austin Myers, Carl Vondrick, Kevin P. Murphy, and Cordelia Schmid. Videobert: A joint model for video and
language representation learning. ICCV, 2019.
[53] Linchao Zhu and Yi Yang. Actbert: Learning global-local video-text representations. CVPR, 2020.
[54] Jie Lei, Linjie Li, Luowei Zhou, Zhe Gan, Tamara L Berg, Mohit Bansal, and Jingjing Liu. Less is more: Clipbert for
video-and-language learning via sparse sampling. In CVPR, 2021.
[55] Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to-end
retrieval. In ICCV, 2021.
[56] Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Limin Wang, and Yu Qiao. Uniformerv2: Spatiotemporal learning
by arming image vits with video uniformer. arXiv preprint arXiv:2211.09552, 2022.
[57] Guo Chen, Sen Xing, Zhe Chen, Yi Wang, Kunchang Li, Yizhuo Li, Yi Liu, Jiahao Wang, Yin-Dong Zheng, Bingkun Huang,
et al. Internvideo-ego4d: A pack of champion solutions to ego4d challenges. arXiv preprint arXiv:2211.09529, 2022.
[58] Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Luˇci´c, and Cordelia Schmid. Vivit: A video vision
transformer. In ICCV, 2021.
[59] Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu. Video swin transformer. In CVPR, 2022.
[60] Junnan Li, Ramprasaath Selvaraju, Akhilesh Gotmare, Shafiq Joty, Caiming Xiong, and Steven Chu Hong Hoi. Align before
fuse: Vision and language representation learning with momentum distillation. NeurIPS, 2021.
[61] Tianwei Lin, Xu Zhao, Haisheng Su, Chongjing Wang, and Ming Yang. Bsn: Boundary sensitive network for temporal action
proposal generation. In Proceedings of the European conference on computer vision (ECCV), pages 3–19, 2018.
[62] Tianwei Lin, Xiao Liu, Xin Li, Errui Ding, and Shilei Wen. Bmn: Boundary-matching network for temporal action proposal
generation. In ICCV, 2019.
[63] Elad Hoffer, Tal Ben-Nun, Itay Hubara, Niv Giladi, Torsten Hoefler, and Daniel Soudry. Augment your batch: Improving
generalization through instance repetition. CVPR, 2020.
[64] Kunchang Li, Yali Wang, Gao Peng, Guanglu Song, Yu Liu, Hongsheng Li, and Yu Qiao. Uniformer: Unified transformer for
efficient spatial-temporal representation learning. In ICLR, 2022.
[65] Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment networks:
Towards good practices for deep action recognition. In ECCV, 2016.
[66] Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. Howto100m:
Learning a text-video embedding by watching hundred million narrated video clips. ICCV, 2019.
[67] Chunhui Gu, Chen Sun, David A Ross, Carl Vondrick, Caroline Pantofaru, Yeqing Li, Sudheendra Vijayanarasimhan, George
Toderici, Susanna Ricco, Rahul Sukthankar, et al. Ava: A video dataset of spatio-temporally localized atomic visual actions.
In CVPR, 2018.
[68] Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin
Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The" something something" video database for learning
and evaluating visual common sense. In ICCV, 2017.
[69] Joao Carreira, Eric Noland, Andras Banki-Horvath, Chloe Hillier, and Andrew Zisserman. A short note about kinetics-600.
arXiv preprint arXiv:1808.01340, 2018.
[70] Joao Carreira, Eric Noland, Chloe Hillier, and Andrew Zisserman. A short note on the kinetics-700 human action dataset.
arXiv preprint arXiv:1907.06987, 2019.
[71] Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo
Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv
preprint arXiv:2111.02114, 2021.
[72] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie
Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. arXiv preprint arXiv:2204.14198,
2022.
[73] Yuan Tian, Yichao Yan, Guangtao Zhai, Guodong Guo, and Zhiyong Gao. Ean: event adaptive network for enhanced action
recognition. IJCV, 2022.
[74] Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In ICCV,
2019.
[75] Zhiwu Qing, Haisheng Su, Weihao Gan, Dongliang Wang, Wei Wu, Xiang Wang, Yu Qiao, Junjie Yan, Changxin Gao, and
Nong Sang. Temporal context aggregation network for temporal action proposal refinement. In CVPR, 2021.
[76] Humam Alwassel, Silvio Giancola, and Bernard Ghanem. Tsp: Temporally-sensitive pretraining of video encoders for
localization tasks. In ICCV, 2021.
[77] Junting Pan, Siyu Chen, Mike Zheng Shou, Yu Liu, Jing Shao, and Hongsheng Li. Actor-context-actor relation network for
spatio-temporal action localization. In CVPR, 2021.
[78] Yutong Feng, Jianwen Jiang, Ziyuan Huang, Zhiwu Qing, Xiang Wang, Shiwei Zhang, Mingqian Tang, and Yue Gao. Relation
modeling in spatio-temporal action localization. arXiv preprint arXiv:2106.08061, 2021.
[79] Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video
benchmark for human activity understanding. In CVPR, 2015.
[80] Hang Zhao, Antonio Torralba, Lorenzo Torresani, and Zhicheng Yan. Hacs: Human action clips and segments dataset for
recognition and temporal localization. In ICCV, 2019.
[81] Hildegard Kuehne, Hueihan Jhuang, Estíbaliz Garrote, Tomaso Poggio, and Thomas Serre. Hmdb: a large video database for
human motion recognition. In ICCV, 2011.
[82] Haroon Idrees, Amir R Zamir, Yu-Gang Jiang, Alex Gorban, Ivan Laptev, Rahul Sukthankar, and Mubarak Shah. The thumos
challenge on action recognition for videos “in the wild”. CVIU, 2017.
[83] Yi Liu, Limin Wang, Yali Wang, Xiao Ma, and Yu Qiao. Fineaction: A fine-grained video dataset for temporal action
localization. IEEE Transactions on Image Processing, 2022.
[84] Ang Li, Meghana Thotakuri, David A Ross, João Carreira, Alexander Vostrikov, and Andrew Zisserman. The ava-kinetics
localized human actions video dataset. arXiv preprint arXiv:2005.00214, 2020.
[85] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence
Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014.
[86] Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Girshick. Mask r-cnn. In ICCV, 2017.
[87] Jiajun Tang, Jin Xia, Xinzhi Mu, Bo Pang, and Cewu Lu. Asynchronous interaction aggregation for action detection. In
ECCV, 2020.
[88] Yuqi Liu, Pengfei Xiong, Luhui Xu, Shengming Cao, and Qin Jin. Ts2-net: Token shift and selection transformer for
text-video retrieval. In ECCV, 2022.
[89] Yicong Hong, Zun Wang, Qi Wu, and Stephen Gould. Bridging the gap between learning in discrete and continuous
environments for vision-and-language navigation. In CVPR, 2022.
[90] Dong An, Zun Wang, Yangguang Li, Yi Wang, Yicong Hong, Yan Huang, Liang Wang, and Jing Shao. 1st place solutions for
rxr-habitat vision-and-language navigation competition (cvpr 2022). arXiv preprint arXiv:2206.11610, 2022.
[91] Xing Cheng, Hezheng Lin, Xiangyu Wu, Fan Yang, and Dong Shen. Improving video-text retrieval by multi-stream corpus
alignment and dual softmax loss. arXiv preprint arXiv:2109.04290, 2021.
[92] Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. In
CVPR, 2016.
[93] Zuxuan Wu, Ting Yao, Yanwei Fu, and Yu-Gang Jiang. Deep learning for video classification and captioning. In Frontiers of
Multimedia Research. 2017.
[94] Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. Localizing moments in
video with natural language. In ICCV, 2017.
[95] Anna Rohrbach, Marcus Rohrbach, Niket Tandon, and Bernt Schiele. A dataset for movie description. In CVPR, 2015.
[96] Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan-Fang Wang, and William Yang Wang. Vatex: A large-scale, high-quality
multilingual dataset for video-and-language research. In ICCV, 2019.
[97] David Chen and William B Dolan. Collecting highly parallel data for paraphrase evaluation. In ACL, 2011.
[98] Yuncheng Li, Yale Song, Liangliang Cao, Joel Tetreault, Larry Goldberg, Alejandro Jaimes, and Jiebo Luo. Tgif: A new
dataset and benchmark on animated gif description. In CVPR, 2016.
[99] Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünderhauf, Ian Reid, Stephen Gould, and Anton
Van Den Hengel. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments.
In CVPR, 2018.
[100] Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. Beyond the nav-graph: Vision-and-language
navigation in continuous environments. In ECCV, 2020.
[101] Shizhe Chen, Pierre-Louis Guhur, Cordelia Schmid, and Ivan Laptev. History aware multimodal transformer for vision-andlanguage navigation. NeurIPS, 2021.
[102] Mengmeng Wang, Jiazheng Xing, and Yong Liu. Actionclip: A new paradigm for video action recognition. ArXiv,
abs/2109.08472, 2021.
[103] Mitchell Wortsman, Gabriel Ilharco, Jong Wook Kim, Mike Li, Simon Kornblith, Rebecca Roelofs, Raphael Gontijo Lopes,
Hannaneh Hajishirzi, Ali Farhadi, Hongseok Namkoong, et al. Robust fine-tuning of zero-shot models. In CVPR, 2022.
[104] Youngjae Yu, Jongseok Kim, and Gunhee Kim. A joint sequence fusion model for video question answering and retrieval. In
ECCV, 2018.
[105] Abhijit Bendale and Terrance E Boult. Towards open set deep networks. In CVPR, 2016.
[106] Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning.
In ICML, 2016.
[107] Ranganath Krishnan, Mahesh Subedar, and Omesh Tickoo. Bar: Bayesian activity recognition using variational inference.
arXiv preprint arXiv:1811.03305, 2018.
[108] Guangyao Chen, Limeng Qiao, Yemin Shi, Peixi Peng, Jia Li, Tiejun Huang, Shiliang Pu, and Yonghong Tian. Learning open
set network with discriminative reciprocal points. In ECCV, 2020.
[109] Wentao Bao, Qi Yu, and Yu Kong. Evidential deep learning for open set action recognition. In ICCV, 2021.
[110] Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. A dataset of 101 human action classes from videos in the wild.
Center for Research in Computer Vision, 2012.
[111] Mathew Monfort, Bowen Pan, Kandan Ramakrishnan, Alex Andonian, Barry A McNamara, Alex Lascelles, Quanfu Fan, Dan
Gutfreund, Rogerio Feris, and Aude Oliva. Multi-moments in time: Learning and interpreting models for multi-action video
understanding. TPAMI, 2021.

