
- 1Communications link failure,The last packet successfully received from the server was 244056 millis_communications link failure the last packet succes
- 2Leetcode 509:斐波那契数_class solution { public: int fib(int n) { int fib[
- 3Webkit 结构简介难点要点和案例源码解析说明_webkit源码分析
- 4Git学习笔记(七)——其他操作_git status查询隐藏文件
- 5深入单例模式 java_深入浅析Java设计模式中的单例模式
- 6Java项目:电影售票系统设计和实现(java+Springboot+ssm+mysql+jsp+maven)_电影票务系统 同类型电影的展示和售票,使用了计数器和排序实现了电影的浏览次数排
- 7【RabbitMQ】Windows下RabbitMQ的安装和部署_windows部署rabbitmq
- 8C++ //练习 17.13 编写一个整型对象,包含真/假测验的正确答案。使用它来为前两题中的数据结构生成测验成绩。
- 9[Errno 14] curl#7 - “Failed to connect to 2a03:2880:f11b:83:face:b00c:0:25de: Network is unreachable_failed to connect to 2a03:2880:f11f:83:face:b00c:0
- 10【2023年】云计算金砖牛刀小试2_2024金砖云计算样题
Prometheus 监控部署教程_prometheus监控部署
赞
踩
一、Prometheus 介绍
1.什么是Prometheus?
Prometheus 是一个开源的报警系统和监控工具包,是由SoundCloud公司开发的开源监控报警系统和时序数据库(TSDB)。Prometheus使用Go语言开发,是Google BorgMon监控系统的开源版本。从 2012 年成立以来,许多公司和组织都采用promethues,并且该项目有着很活跃的社区和开发者;现在是一个开源项目,可以独立于任何公司进行维护;2016年prometheus成为继Kubernetes之后第二个加入Linux基金会旗下的原生云基金会(Cloud Native Computing Foundation)的托管项目。
官网:Prometheus - Monitoring system & time series database 文献:Overview | Prometheus
2.各监控系统对比
| 监控方案 | 数据收集 | 自动发现 | 侧重点 | 数据展示方案 | 贴合云原生 |
| Cacti | SNMP | 插件支持 | 数据展示 | RRDTOOL | 差 |
| Nagios | 各种脚本插件 | 脚本插入 | 状态展示 | 阈值 | 差 |
| Zabbix | zabbix-agent为主 | 主机地址自动发现 | 状态、数据展示 | PHP | 中等 |
| Prometheus | Exporter为主 | 各种模式支持,最为完善 | 以时间序列保存数据 | 通过结合Grafana 进行结合展示 | 优秀 |
grafana:图形展示组件工具
3.Prometheus的特性
-
由 metric 名称和 K/V 键值对标识的时间序列的多维数据模型
-
简单的查询语言 PromQL(TSDB数据库的查询语言)
-
不依赖分布式存储,单个服务节点自动治理
-
通过 http 的 pull 模型获取数据的时序集合
-
支持通过网关 push 时序数据
-
通过服务发现或者静态配置发现目标
-
支持多种图表和仪表盘模式
4.Prometheus架构图和组件介绍
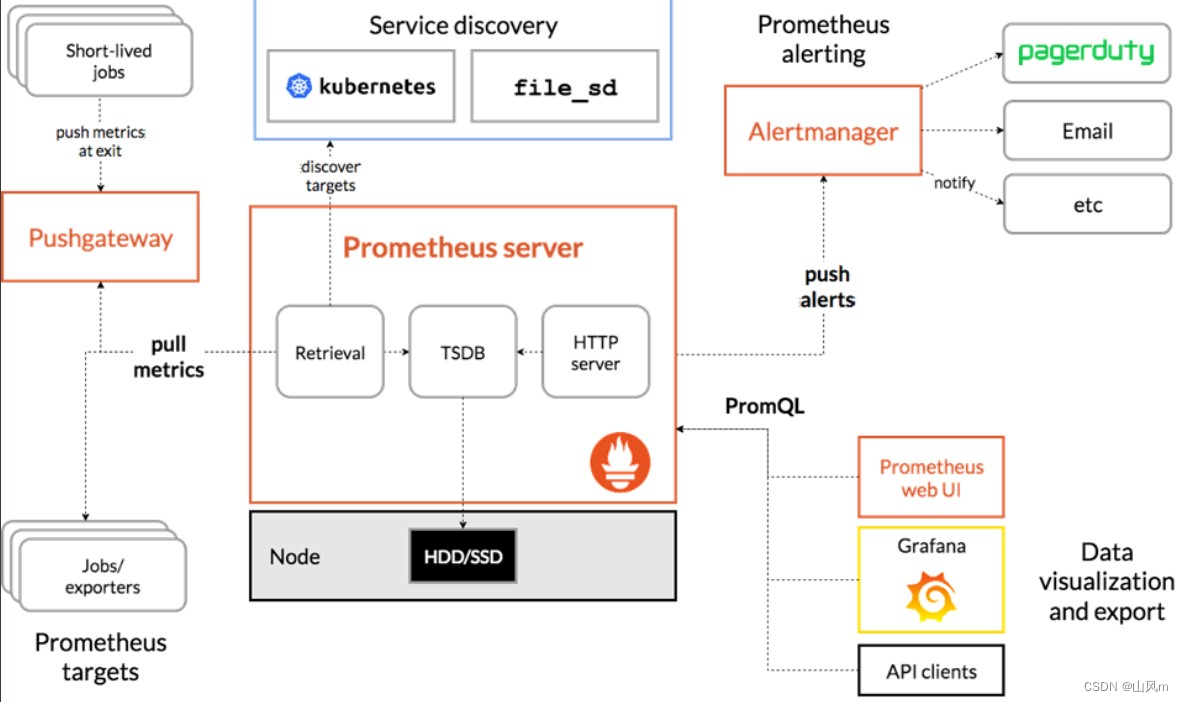
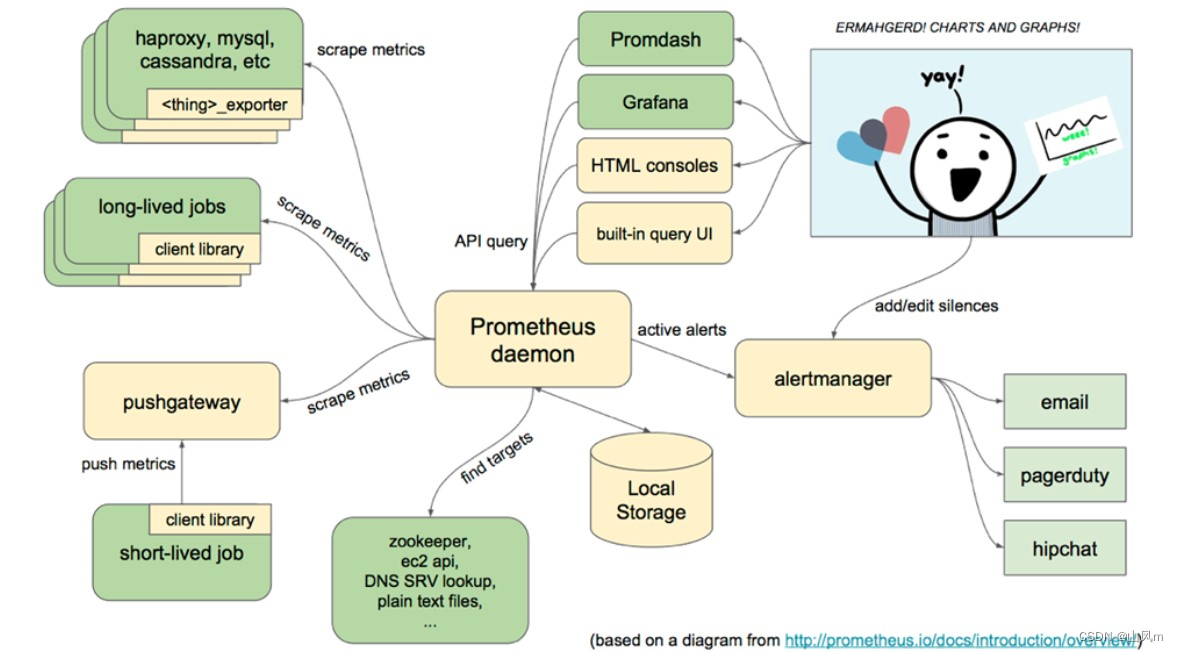
Prometheus Server:负责定时去目标抓取 metrics数据,每个被抓取对象需要开放一个http服务接口;pull下来的数据经过整理后写入到本地的时序数据库(TSDB)中。
Client Library:客户端类库(例如官方提供的:Go,Python,Java等),为需要监控的服务产生相应的 metrics数据并开放一个http服务接口给 Prometheus Server。目前很多软件原生就支持Prometheus,提供了metrics数据,可以直接使用 Prometheus pull。对于像操作系统不提供提供metrics数据的情况,可以使用exporter,或者自己开发exporter来提供metrics数据服务。
Node Exporter:泛指能向Prometheus提供监控数据(metrics数据)的都可以称为一个 exporter,一个 exporter的实例称为 target,exporter来源主要2个方面,一个是社区提供的,一种是用户自定义的。主要用来支持其他数据源的metrics数据导入到 Prometheus,支持数据库、硬件、消息中间件、存储系统、HTTP服务器、jmx等。
PushGateway:主要用于临时性的 short-lived job。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。对此类 jobs 定时将 metrics数据 push 到 pushgateway 上,再由 Prometheus Server 从 Pushgateway 上 pull 到本地。这种方式主要用于服务层面的metrics,对于机器层面的metrices,需要使用node exporter。
Promdash 和 Grafana:Prometheus内置一个简单的Web控制台Promdash,可以查询metrics数据,查看配置信息或者Service Discovery等,实际工作中,查看指标或者创建仪表盘通常使用Grafana,Prometheus作为Grafana的数据源。
alert manager:从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对应的接受方式上,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。
PromQL:是Prometheus TSDB 的查询语言。是结合 Grafana 进行数据展示和告警规则的配置的关键部分。
- prometheus 技术栈
- prometheus server #核心,server服务器端
- TSDB #时序数据库
- *_exporter #监控特定对象的客户端
- alert manager #报警组件
- promdash #图形展示组件
- pushgateway #网关组件
5.Prometheus服务工作过程
-
Prometheus Daemon负责定时去被监控目标上抓取metrics(指标)数据,每个抓取目标需要暴露一个http服务的接口给它定时抓取。Prometheus支持通过配置文件、文本文件、Zookeeper、Consul、DNS SRV Lookup等方式指定抓取目标。Prometheus采用PULL的方式进行监控,即服务器可以直接通过目标PULL数据或者间接地通过中间网关来Push数据。
-
Prometheus 在本地处理抓取到的所有数据,并通过一定规则进行整理数据,并把得到的结果存储到新的时间序列中。
-
Prometheus通过PromQL和其他API可视化地展示收集的数据。Prometheus支持很多方式的图表可视化,例如Grafana、自带的Promdash以及自身提供的模版引擎等等。Prometheus还提供HTTP API的查询方式,自定义所需要的输出。
-
PushGateway支持Client主动推送metrics到 PushGateway,而Prometheus只是定时去Gateway上抓取数据。
-
Alertmanager是独立于Prometheus的一个组件,可以支持Prometheus的查询语句,提供十分灵活的报警方式。
6.实验前准备
- 1.由于使用单机模式部署,所有有些软件的安装或者配置的生效需要连接到互联网(通网)
-
- 2.为了方便识别主机身份,可以给主机设置不同的主机名和域名解析(hosts) #靠ip也可以识别
-
- 3.保证时间同步可以开启ntp服务 systemctl start ntpdate.service
二、Prometheus - Prometheus Server部署
1.下载并安装Prometheus Server服务
- # 上传本地Prometheus及相关软件包
- rz promethues.zip
- unzip promethues.zip
- ls -l promethues/

安装 Prometheus 软件
- # 单独解压缩Prometheus软件,完成安装
- tar -xf prometheus-2.45.0.linux-amd64.tar.gz
- tree prometheus-2.45.0.linux-amd64/
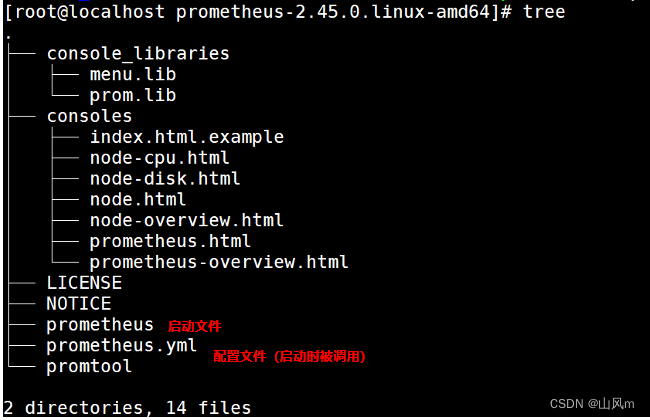
- # Prometheus安装非常简单(类似绿色免安装版本)
- cp -r prometheus-2.45.0.linux-amd64 /usr/local/prometheus
2.编写Prometheus service启动脚本
- cat>/usr/local/prometheus/prometheus.service<<EOF
- [Unit]
- Description=Prometheus
- After=network.target
-
- [Service]
- Type=simple
- User=root
- WorkingDirectory=/usr/local/prometheus
- ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml
-
- Restart=on-failure
- LimitNOFILE=65536
-
- [Install]
- WantedBy=multi-user.target
- EOF

3.添加启动脚本到systemd启动管理中
- ln -s /usr/local/prometheus/prometheus.service /lib/systemd/system/
- systemctl daemon-reload
- systemctl start prometheus
- systemctl enable prometheus
- netstat -antp | grep :9090

4.配置文件讲解
注:Prometheus的配置文件有严格的缩进格式,修改时不要破坏格式! (默认每级标签之间为两个空格)
- # 配置文件(原版未改)
-
- vim /usr/local/prometheus/prometheus.yml
-
- # my global config
- global:
- scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
- evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
- # scrape_timeout is set to the global default (10s).
-
- # Alertmanager configuration
- alerting:
- alertmanagers:
- - static_configs:
- - targets:
- # - alertmanager:9093
-
- # Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
- rule_files:
- # - "first_rules.yml"
- # - "second_rules.yml"
-
- # A scrape configuration containing exactly one endpoint to scrape:
- # Here it's Prometheus itself.
- scrape_configs:
- # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- - job_name: 'prometheus'
-
- # metrics_path defaults to '/metrics'
- # scheme defaults to 'http'.
-
- static_configs:
- - targets: ['localhost:9090']
- -----------------------------------------------------------------------------------------------
- # 配置文件关键词介绍(由于alertmanager、exporter等都未安装,相关配置后面详细讲)
- global: # 全局配置 (如果有内部单独设定,会覆盖这个参数)
- scrape_interval: 15s
- # 全局默认的数据拉取间隔
- evaluation_interval: 15s
- # 全局默认的规则(主要是报警规则)拉取间隔
- scrape_timeout: 10s
- # 全局默认的单次数据拉取超时间,默认不开启,当报context deadline exceeded错误时需要在特定的job下配置该字段,注意:scrape_timeout时间不能大于scrape_interval,否则Prometheus将会报错。
- alerting: # 告警插件定义,这里会设定alertmanager这个报警插件。
- rule_files: # 告警规则,按照设定参数进行扫描加载,用于自定义报警规则(类似触发器trigger),其报警媒介由alertmanager插件实现。
- scrape_configs: # 采集配置,配置数据源,包含分组job_name以及具体target,又分为静态配置和服务发现。
5.通过浏览器访问指标数据和图形化界面(效果见下图)
http://192.168.180.61:9090/metrics

http://192.168.180.61:9090/graph

三、Prometheus - Node Exporter部署
1.解压缩并安装Node Exporter
- tar -xf node_exporter-1.6.0.linux-amd64.tar.gz
- cp -r node_exporter-1.6.0.linux-amd64 /usr/local/node_exporter
2.编写Node Exporter启动脚本
- cat>/usr/local/node_exporter/node_exporter.service<<EOF
- [Unit]
- Description=Node Exporter
- After=network.target
- Wants=network-online.target
-
- [Service]
- Type=simple
- User=root
- ExecStart=/usr/local/node_exporter/node_exporter
-
- Restart=on-failure
- LimitNOFILE=65536
-
- [Install]
- WantedBy=multi-user.target
- EOF
3.添加启动脚本到systemd启动管理中
- ln -s /usr/local/node_exporter/node_exporter.service /lib/systemd/system/
- systemctl daemon-reload
- systemctl start node_exporter
- systemctl enable node_exporter
- netstat -antp | grep LISTEN | grep :9100 # node_exporter 默认端口为 9100

注意:Node Exporter 安装除了在 Prometheus Server 服务器端安装也可以单独安装在其他被监控节点上
4.配置文件修改(修改Prometheus配置文件实现metrics数据获取和监控开启)
- vim /usr/local/prometheus/prometheus.yml
- ---------------------------------------------------------
- # alertmanager 监控区域
- alerting:
- alertmanagers:
- # 指定监控类型为静态配置
- - static_configs:
- - targets: ['127.0.0.1:9093']
- # 指定当前 alertmanager 服务器连接方式
-
- scrape_configs:
- # 当前任务名称
- - job_name: 'prometheus'
- # 当前配置为静态配置,指定 Node_exporter 服务连接方式
- static_configs:
- - targets: ['127.0.0.1:9100','192.168.88.20:9100']
- ---------------------------------------------------------
第一种写法:
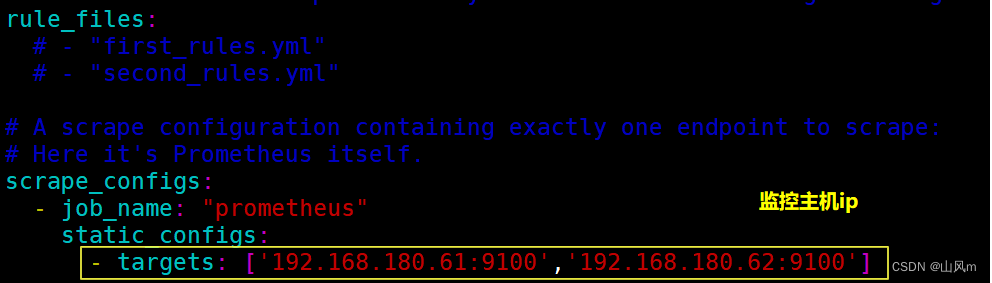
第二种写法:
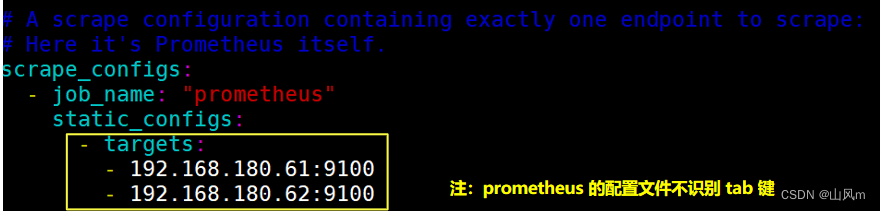
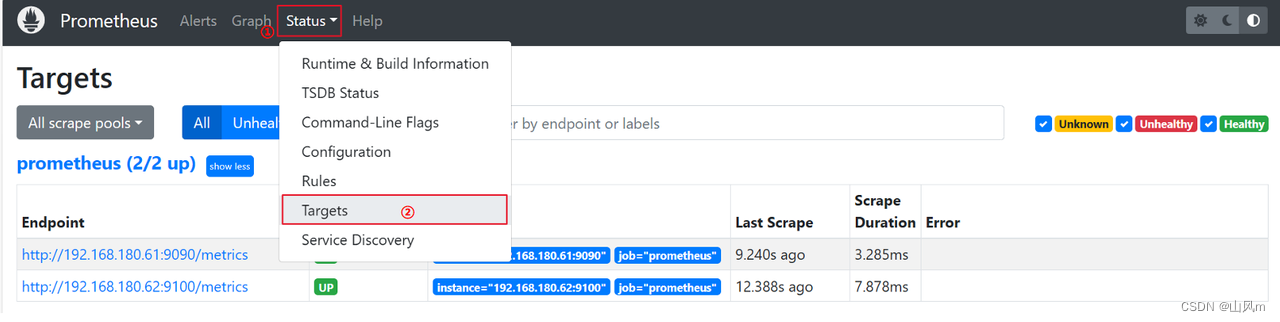
systemctl restart prometheus #重启prometheus,加载最新配置5.效果展示

6.群组分类
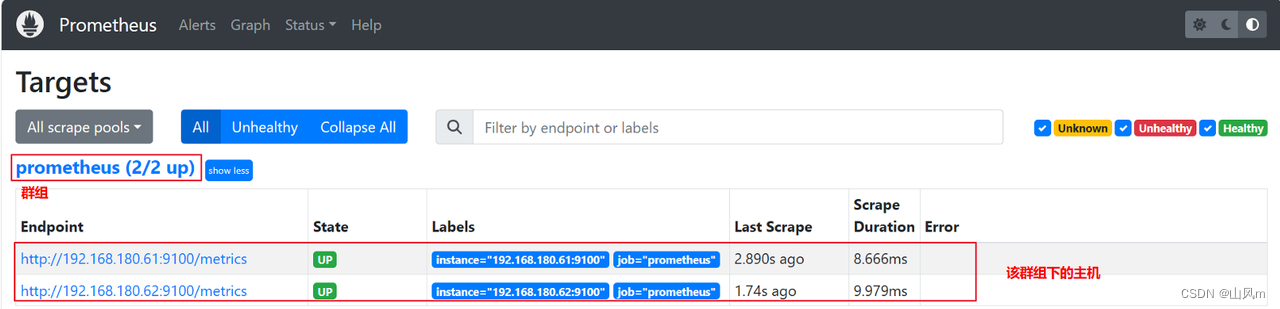
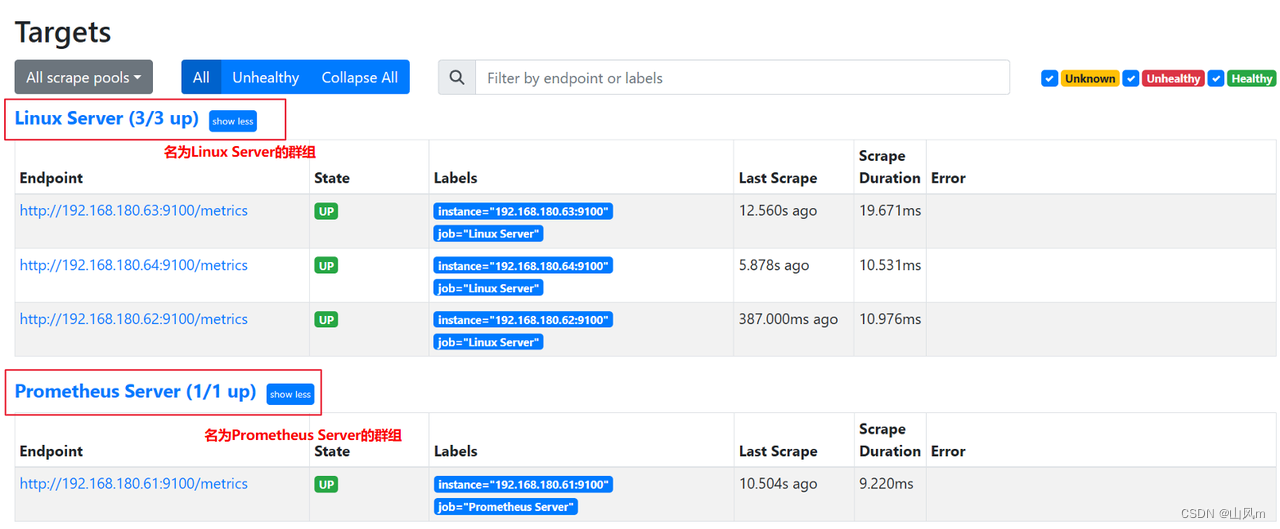
可以在配置文件中新增、改名、删除群组,并可以将具体的监控主机添加到对应群组内
- # 修改 prometheus 的配置文件
- vim /usr/local/prometheus/prometheus.yml
- # 保存退出后重启 prometheus
- systemctl restart prometheus
实际效果:
四、Grafana 部署
Granfana 软件和模板依赖,因为尽量使用新版本的 Granfana 官方网站:Grafana: The open observability platform | Grafana Labs
1.Grafana组件安装
1)下载并安装Prometheus Server服务
- tar -xf grafana-10.2.2.linux-amd64.tar.gz
- cp -r grafana-v10.2.2/ /usr/local/grafana
2)编写Prometheus service启动脚本
- cat>/usr/local/grafana/grafana-server.service<<EOF
- [Unit]
- Description=Grafana Server
- After=network.target
-
- [Service]
- Type=simple
- User=root
- WorkingDirectory=/usr/local/grafana
- ExecStart=/usr/local/grafana/bin/grafana-server
-
- Restart=on-failure
- LimitNOFILE=65536
-
- [Install]
- WantedBy=multi-user.target
- EOF
3)添加启动脚本到systemd启动管理中
- ln -s /usr/local/grafana/grafana-server.service /lib/systemd/system/
- systemctl daemon-reload
- systemctl start grafana-server
2.Grafana组件配置
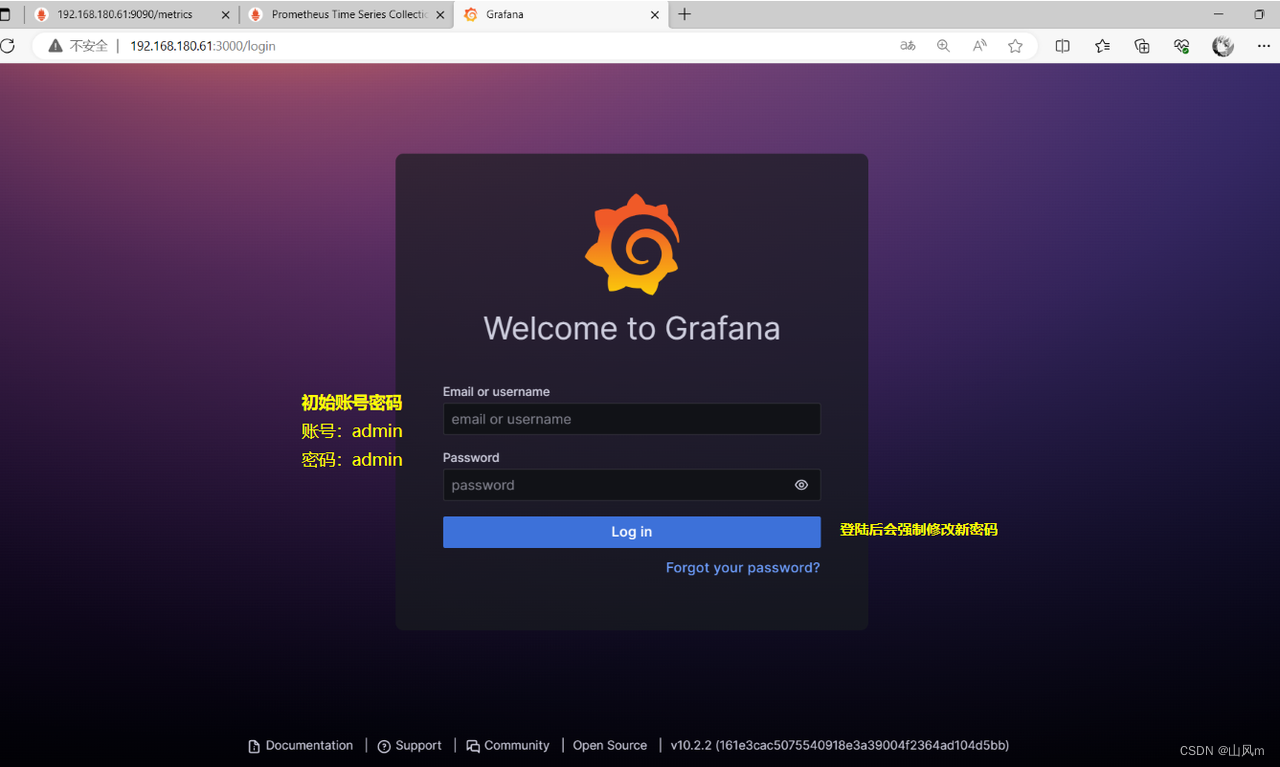
1.web页面访问 grafana
http://192.168.180.61:3000/login
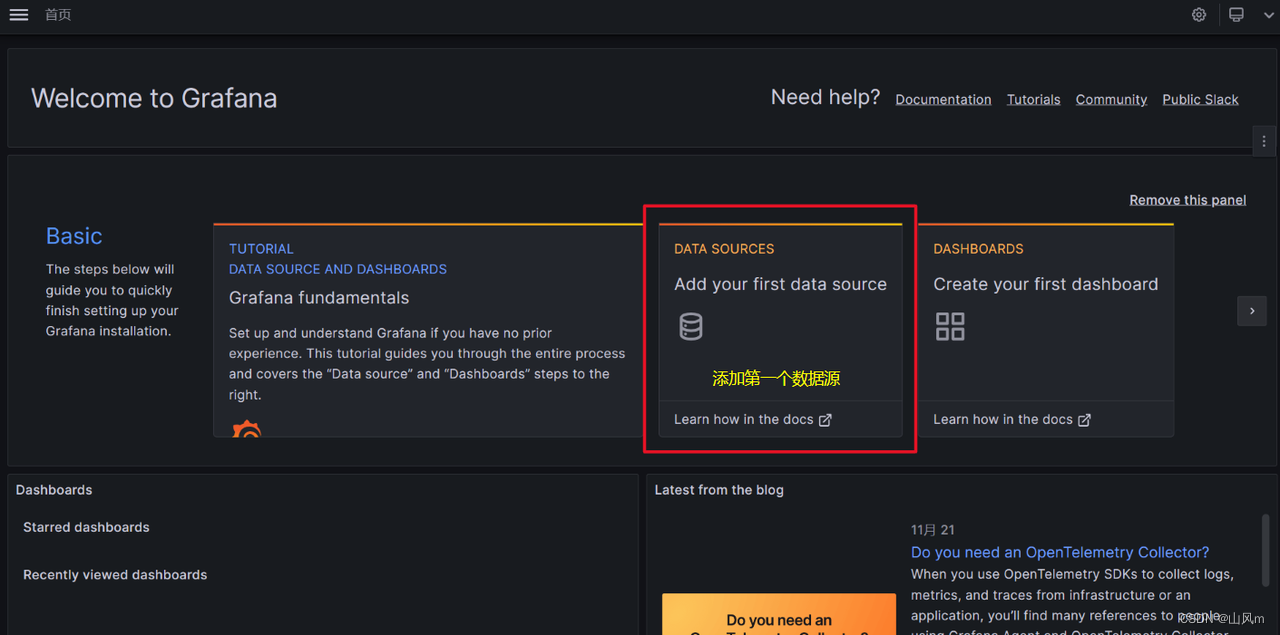
2.安装监控Linux系统资源模板
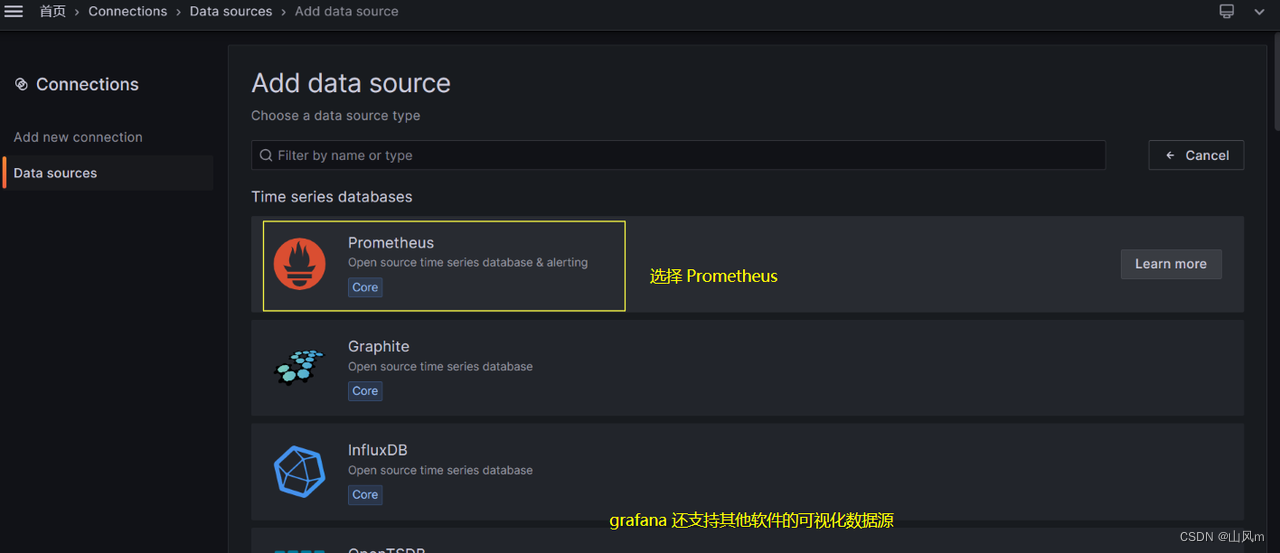
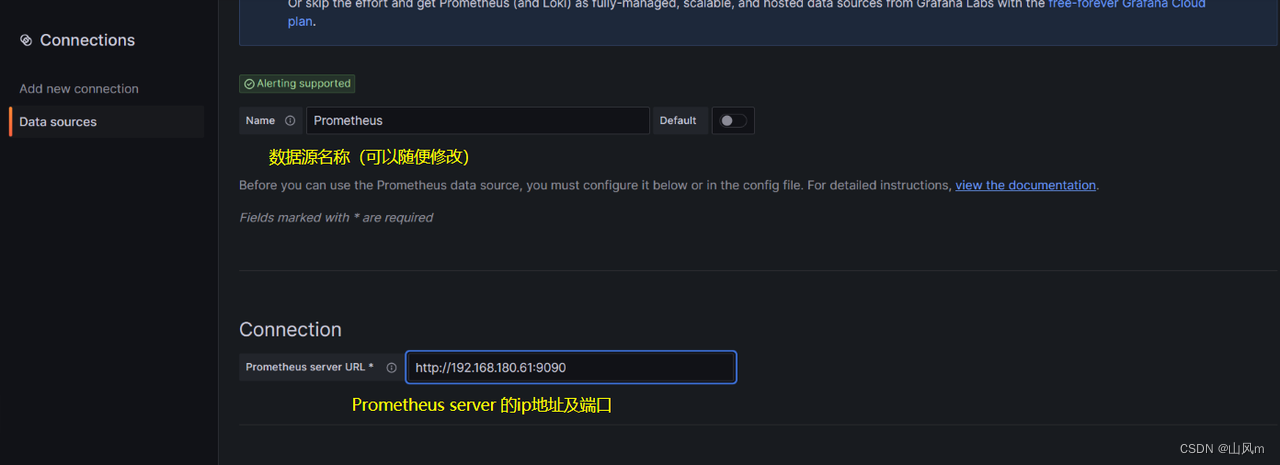
剩余暂时不需要修改,然后点击最下面的 Save & test 即可

模板号:8919,由于图形模板作者会更新版本,软件版本和图形模板由于版本变更导致不兼容,要让软件跟随图形模板进行更新。
也可以去官网 查找适合的模板 复制ID Grafana dashboards | Grafana Labs
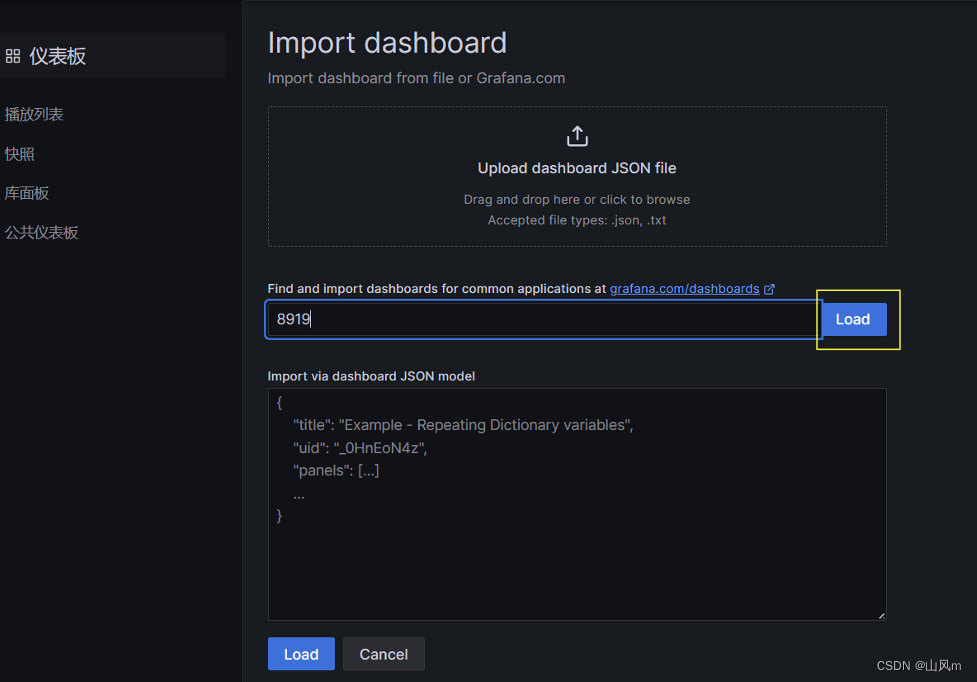
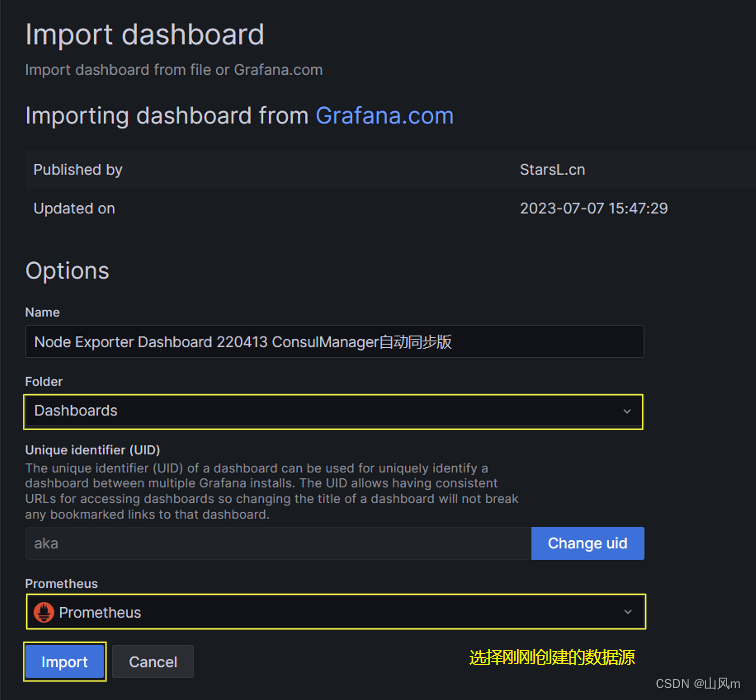
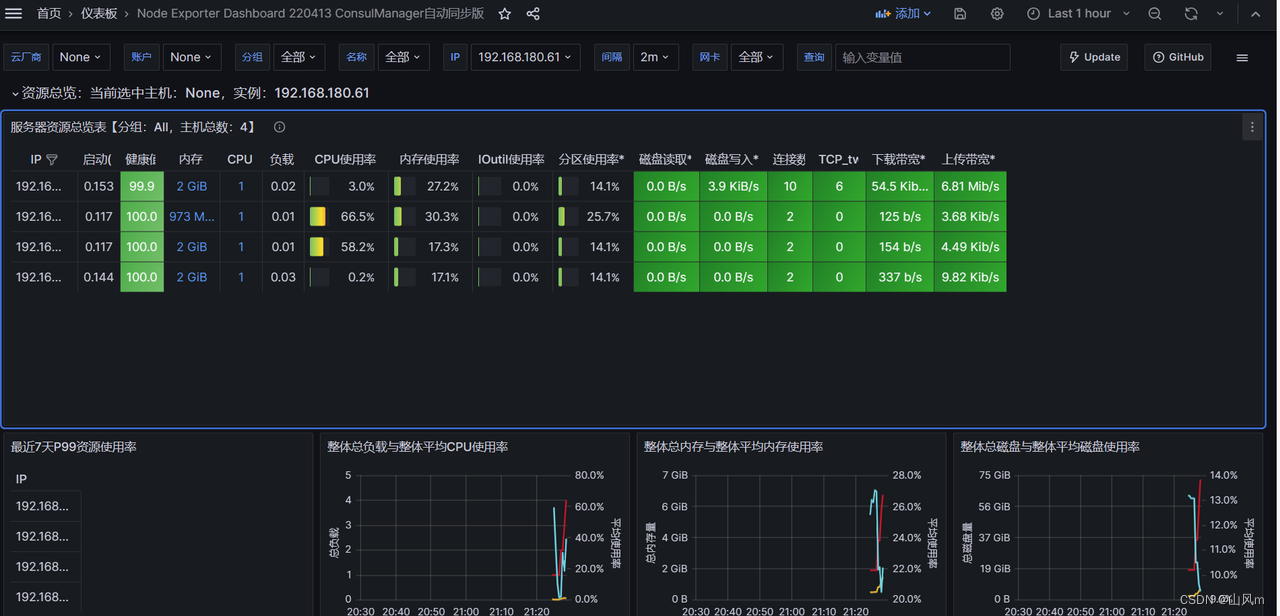
结果展示:
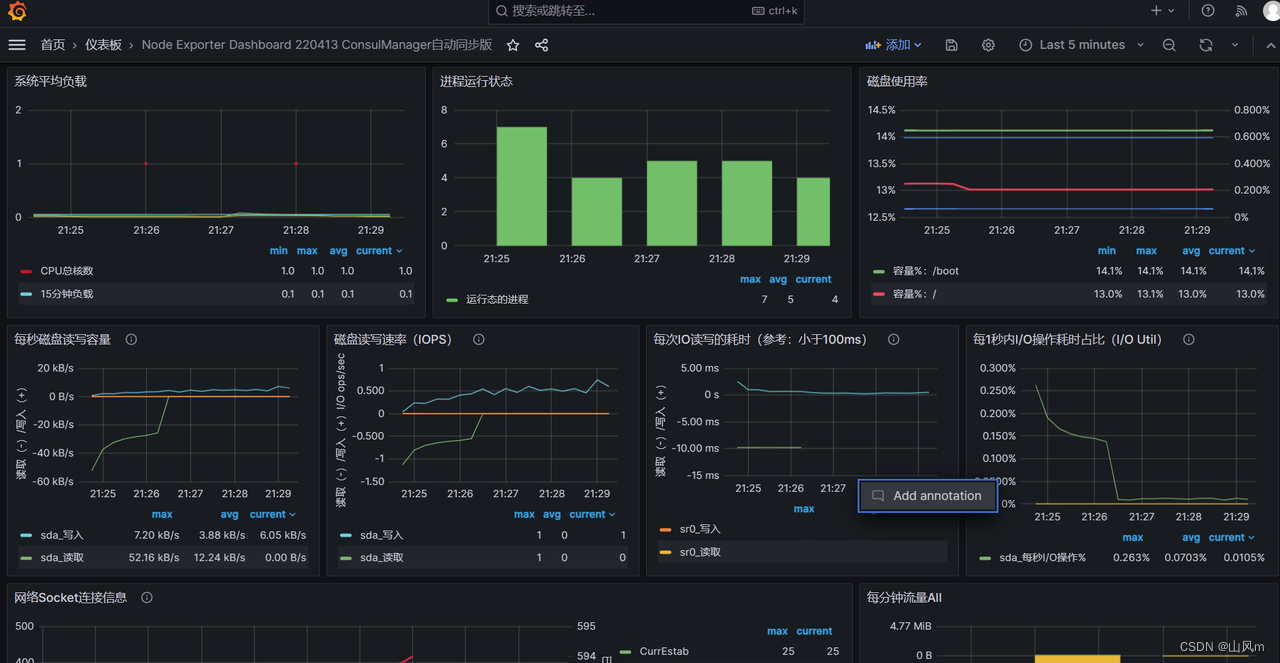
下一期我会出一下prometheus的监控项设置以及自动报警还要prometheus监控K8S集群和MySQL数据库监控项设置,谢谢观看!

