
- 1【数据结构】list.h 常用函数实现详解
- 2以 Serverfull 方式运行无服务器服务
- 3随机森林(Random Forest)原理小结_随机森林回归
- 4总结(CFAI,AWB,Denoise2D,Sharpen)_cfaihamiltonadam
- 5[zz]fatal error C1900: Il mismatch between 'P1' version '20080116' and 'P2' version '20070207'
- 6将 Confluence 用于个人的Blog、Wiki平台
- 7基于android的健康管理APP_关于android软件的健康管理app代码
- 8Unity3D——人物对话UI制作_unity 对话框ui展开图
- 9数据库numeric_TCGA数据库:生存分析
- 10iOS 视频播放(AVPlayer)_不需要播放器的av
云端智创 | 基于视频AI原理的音视频智能处理技术_ai视频剪辑原理
赞
踩
本文内容整理自「智能媒体生产」系列课程第二讲:视频AI与智能生产制作,由阿里云智能视频云高级技术专家分享视频AI原理,AI辅助媒体生产,音视频智能化能力和底层原理,以及如何利用阿里云现有资源使用音视频AI能力。课程回放见文末。
01 算法演进:视频AI原理
在媒体生产的全生命周期中,AI算法辅助提升内容生产制作效率,为创作保驾护航。
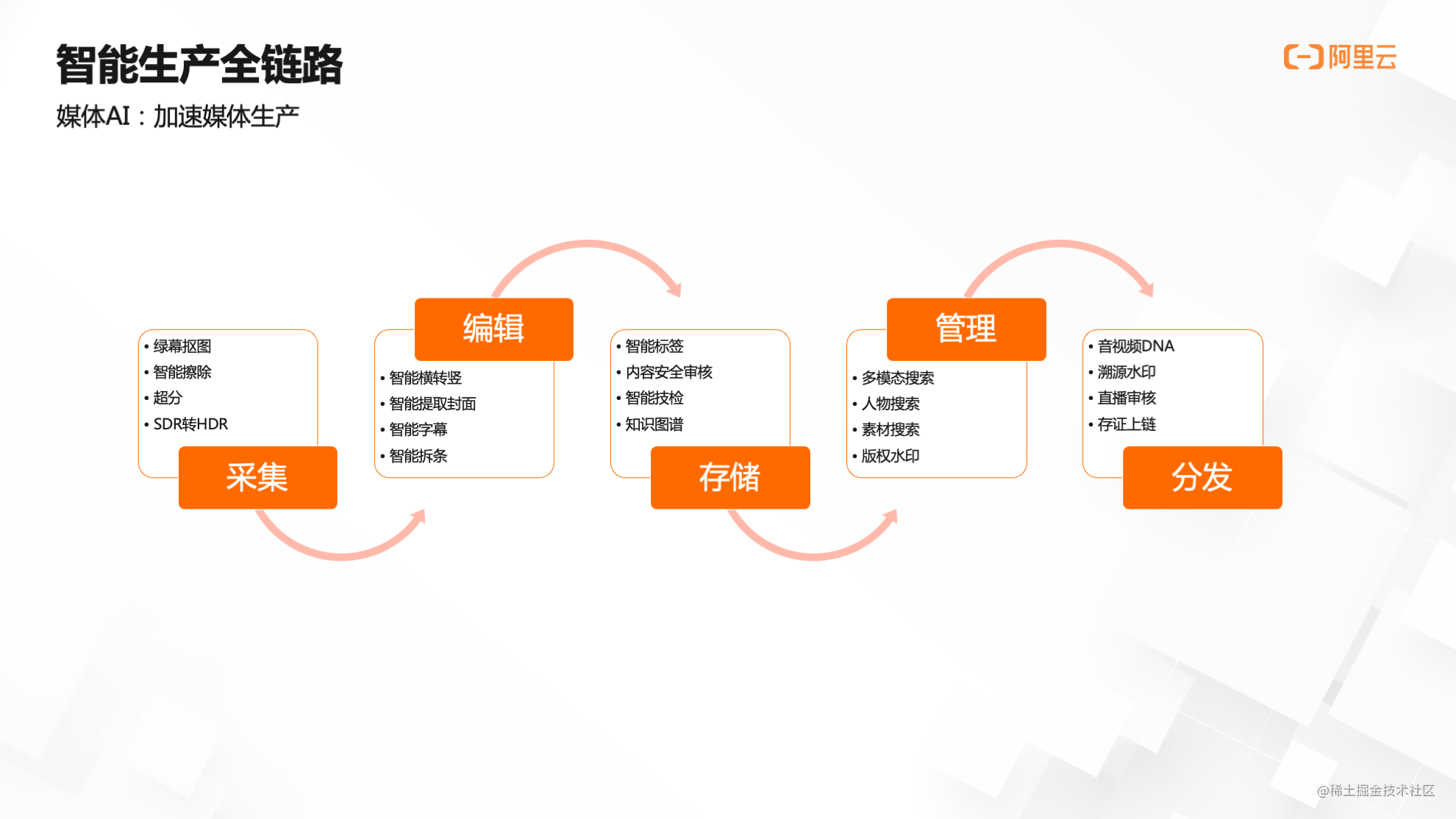
智能生产全链路
智能生产全链路可分为五大部分。传统的媒体生产包含采集、编辑、存储、管理和分发五个流程,随着人工智能技术的兴起,五大流程涉及到越来越多的机器参与,其中最主要的便是AI技术的应用。以下举例说明:
l 采集
在摄像机拍摄时同步进行绿幕抠图,这在演播室或者影视制作场景中是比较常见的。
l 编辑
编辑过程运用到很多技术,比如横转竖、提取封面、叠加字幕等,同时这些字幕还可以通过语音识别的方式提取出来再叠加在画面上。
l 存储
视频在采集和编辑之后,需要存储下来进行结构化分析,像智能标签就是运用在存储场景,从视频中提取出相应的标签,进行结构化的存储,并把视频库中的视频进行结构化关联。
l 管理
存储下来的视频如何管理?如何通过关键词检索到对应的视频?在管理环节,AI可以帮助进行多模态的检索,比如人物搜索等。
l 分发
在存储和管理之后,视频分发也运用到AI技术,比如音视频DNA、溯源水印等版权保护应用。如果通过直播流的方式对广大用户进行直播,那么分发环节还会涉及到直播审核,以免出现直播故障。
基于智能生产全链路,媒体AI全景图应运而生,共分为四个层次:
最上面的层次表达媒体生产的应用场景,包含智能媒资管理、内容智能生产以及视频版权保护。
往下是产品能力,即AI组合达成的能力,比如视频分类、智能封面、智能抠图等。
再往下是AI原子能力,比如语音识别、自然语言处理这些底层的AI能力。
最下是支撑AI能力的基础底座,如编解码和GPU加速等。以上组合起来,生成一张AI运用在智能生产中的全景图。

视频AI原理
视频AI的底层原理究竟是什么?
人工智能发源于机器学习,而机器学习最早只是一种统计手段,像决策树、支持向量机、随机森林等各种数学方法。
随着时代发展,科学家提出一种人工神经网络的计算方法,或者说算法,后来发现人工神经网络可以变得更大、层次变得更深,经过进一步探索发展,在二十多年前提出了深度学习的观点和概念。
所谓深度学习,就是在原先的人工神经网络上,把中间的层次(我们称之为隐含层)扩展成两个层次、三个层次,甚至发展到现在的几十个层次,即可得到更多的输入层和输出层节点。
当神经网络变得更大、更深的时候,机器学习就演化成深度学习,也就是我们现在俗称的AI。
随之而来产生一个问题:如何将AI运用到视频和图像中?
假如有一个1080P的视频,视频大小为1920✖1080,此时一张图像上就存在百万个像素。如果把百万个像素点都放入神经网络中,会产生巨大的计算量,远远超出常规计算机所能达到的上限。
因此,在把图像放入神经网络前需要进行处理,研究人员提出了卷积神经网络,而这也是现在所有图像和视频AI的基础。

在卷积神经网络的标准模型中,图像进入神经网络之前需要进行两步操作:
第一步是卷积层。所谓卷积就是拿一个卷积核(可以简单理解为一个矩阵)和原始图像的每一个卷积核大小的矩阵进行矩阵层的操作,最后得到一个特征图像。由于有多个卷积核,所以一张图片可以提取出多个特征图像。
特征图像直接放入神经网络还是太大,因此,需要进行第二步池化层操作,池化层的作用就是下采样,可采取多种方式,比如把方格中的最大值、平均值或者加权平均值作为最终输出值,形成下采样数据。
在上述例子中,一张图像的大小降低为原先的四分之一,输入到神经网络之后,极大降低了原始数据量,即可进行图像神经网络处理。由此可见,用通俗的话来讲,视频或图像的AI模型必须是由大数据喂出来的。
大数据天然地长在云上,云和AI天然的结合,可以使AI在云上得到较好的发展与运用。
了解视频AI原理之后,如何反过来评价AI的效果?
以典型的分类问题举例,假如有100个视频,需要找出其中出现过人的视频,那么有两个指标可以评价AI模型的好坏:一个是精度,另一个是召回率。
所谓的精度是指,假设AI算法最终找出50个视频,但是检查之后发现,其中只有40个是真正有人的,那么精度计算为40➗50=0.8。
召回率是指,假设这100个视频中真正有人的一共有80个,而AI找出了其中40个,那么召回率计算为0.5。
可以发现,精度和召回率是一对矛盾。假如想提高精度,只要找出来的视频少一点,就可以保证每个找出来的视频都是对的,即精度上升,但此时召回率一定会下降。
现阶段的AI并不完美,也就是说,目前AI还只能辅助视频生产,生产视频的主体还是人。
AI辅助生产
AI辅助生产可以由以下两个示例进行说明。
示例一:通过图片搜索相关图片或视频。Demo显示,输入一张周星驰的图片后,机器虽然不认识这是谁,但是能够从图片中提取此人的外貌特征,然后在视频库里做相应搜索,找出一堆包含周星驰的视频。
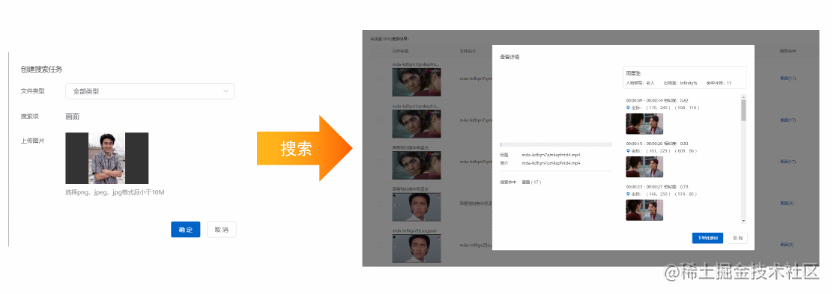
示例二:智能横转竖。传统电影和电视剧均为横屏播放,随着移动互联网兴起,这些电影和电视剧需要在手机端进行投放,由此诞生了智能横转竖这样的AI算法,将大量的横屏视频转换成竖屏视频,帮助横屏视频在手机端分发。

电视剧横转竖效果

新闻横转竖效果
02 智能进阶:视频内容理解
智能标签
智能标签基于AI对于视频内容的理解,自动提取视频中的标签、关键词等信息,分析详情会展示为四部分:
第一部分是视频标签,获取视频的类目,视频出现过哪些人物,人物出现的时间点以及在视频中的位置,人物的相似度等。
第二部分是文本标签,会提炼出一些关键词,包括视频文本中出现过的组织机构,比如央视等。
后面两部分为文字识别和语音识别,分别通过图片OCR技术和语音云识别技术实现。
具体示例可在AI体验馆中进行体验,同时,也提供API接入文档进行参考。
体验中心:https://retina.aliyun.com/#/Label
API接入文档:https://help.aliyun.com/document_detail/163485.html
AI是如何从视频中提取出信息的呢?从视频标签的流程图中可以看到,输入一个视频,分别进行两部分操作:
一部分是对视频做抽帧处理,抽帧得到的图像通过人像识别、场景识别、物体识别、地标识别、OCR等图像AI识别模型,提炼出视频标签。
另一部分是把视频中的音频提取出来,然后通过ASR得到文本结果,最后再经过NLP(自然语言处理),提取出文本标签。

智能审核
视频审核的技术原理与视频标签相同,唯一不同的是,视频标签可以理解为一个正向的视频内容理解,而视频审核是负向的,审核需要识别出一些不合规的、有问题的内容,比如鉴黄、暴恐涉政、违规、二维码、不良场景等信息。

视频检索
视频检索的核心技术点是利用标签结果进行视频的分析和查询。
视频检索架构图显示,媒资系统中的视频通过媒资特征入库模块,导入到智能标签分析中,并得到一系列的标签,包括视频标签、文本标签,原始的ASR、OCR结果等,将这些结果连同视频的元数据信息比如标题、描述等,利用ElasticSearch开源服务进行文本信息的倒排索引和查询。
视频检索过程中会涉及到精排模块,这需要由业务层来实现。如果只是从ES中把符合检索条件的结果提取出来,不一定能满足业务层需求,比方说业务层面对政治新闻场景时,会要求把某些人物的搜索结果更靠前排序,而这就是精排模块所需要做的工作。
检索系统一般都会根据业务层排序,接入业务接口模块,由此一个基本的检索系统搭建完成。但是,现在的检索系统只能按照文本检索视频。如何通过一张图片,检索到相似的图片或视频呢?
这涉及到视频DNA检索技术。所谓的视频DNA,就是把视频里面的关键帧或者某一镜头提炼出关键信息,我们把它称之为DNA,并把这些信息放入向量数据库中进行检索,更多内容可通过体验中心和接入文档进行拓展了解。
体验中心:https://retina.aliyun.com/#/DNA
API接入文档:https://help.aliyun.com/document_detail/93553.html

03 能力升级:音视频智能处理
基于视频内容理解,如何对视频进行智能处理?
绿幕抠图
绿幕抠图是在视频拍摄或者采集时,把背景替换成电脑制作的画面。在演播室场景中,实际拍摄时根据需求,在主持人的背后放置绿幕背景或者蓝幕背景。
影视制作场景同样运用到绿幕抠图,比如科幻片中无法实景拍摄的部分,会在后期进行背景叠加或其他处理工作,通过在人物背后放置绿幕的方式,把人物主体提取出来。
绿幕抠图要求输入的是蓝幕或者绿幕视频,分辨率不超过4K,同时输入一张背景图片,即可输出替换背景后的视频。以下为示例说明:一个人从绿幕前走过,替换背景后,变成此人在背景前走路,整体效果非常自然。

视频链接:https://v.youku.com/v_show/id_XNTk0MDc4Mjc3Mg==.html

视频链接: https://v.youku.com/v_show/id_XNTk0MDc4Mjc5Ng==.html
如何评价绿幕抠图的质量?首先要处理好边缘溢色,比如在头发边缘,由于原始的图像背景是绿幕,头发缝边缘必然会染上一些绿色,技术上需要把这些边缘溢色擦除掉。
此外,如何真实地呈现透明度,并叠加背后的内容,还有运动模糊,地面阴影等,均是绿幕抠图质量好坏的评价点。
横转竖
横转竖是在移动互联网上分发视频的必备处理手段。
传统人工制作横转竖视频的难点在于:一,需要专业的剪辑软件和制作人员,成本高,速度慢;二,在目标移动比较快的场景中,需要逐帧剪裁,工作量巨大;三,剪裁目标区域后,前后帧难以对齐。因此,横转竖视频更适合由机器制作实现。
智能横转竖的算法流程是:首先对视频进行镜头分割,所谓的镜头分割就是在视频制作中,按照不同拍摄机位的转变,识别镜头的切换,并把不同镜头分割开来。

视频链接:https://v.youku.com/v_show/id_XNTk0MDg4MjA0NA==.html
其次是主体选择,在主体选择时,一般选择画面中最醒目的人作为目标,在上述舞蹈场景中,主体就是这个正在跳舞的人。
然后是镜头追踪,每帧图像做好初期选择之后,下一帧都要跟随目标,即框定的图像跟随这个人进行移动。
最后是路径平滑,镜头追踪完成之后,最终生成的竖屏视频必须是平滑的,不能出现翘边等不良效果。更多内容可参见官网:
体验中心:https://retina.aliyun.com/#/H2V
API接入文档:https://help.aliyun.com/document_detail/169896.html
其他视频智能处理能力
目前,阿里云视频云提供的视频智能处理能力,可分为以下四类:
-
ROI提取,即感兴趣区域提取,包括绿幕抠图和横转竖;
-
智能擦除,比如去图标、去字幕;
-
关键信息提炼,比如智能封面,即从视频中提取出最能表现视频的一张图片;视频摘要,提取出视频中最能表现视频的简短视频;
-
结构化分析,比如字幕提取,把嵌入在图像中的字幕自动提取出来;PPT拆条,可以将一个课程视频自动拆成段落。

讲完视频智能处理能力,接下来介绍两项音频智能处理能力:副歌识别和节奏检测。
副歌识别
副歌是指歌曲中的高潮片段。副歌识别有何应用场景?比如,很多音乐APP的试听功能,会直接播放歌曲中的高潮片段,人为进行提取相当麻烦,而副歌识别就能很好地完成任务。
副歌识别的算法流程为:输入歌曲之后,首先进行音乐段落检测,然后提取副歌段落,并进行精调使之更贴合,最后再生成副歌片段。

副歌识别的示例显示,通过调用之后,算法会返回两个结果值,即副歌的开始时间点和结束时间点。

大家可以对返回的结果和音频进行对照,从72秒副歌开始,到102秒副歌结束,副歌识别结果还是非常准确的。
节奏检测
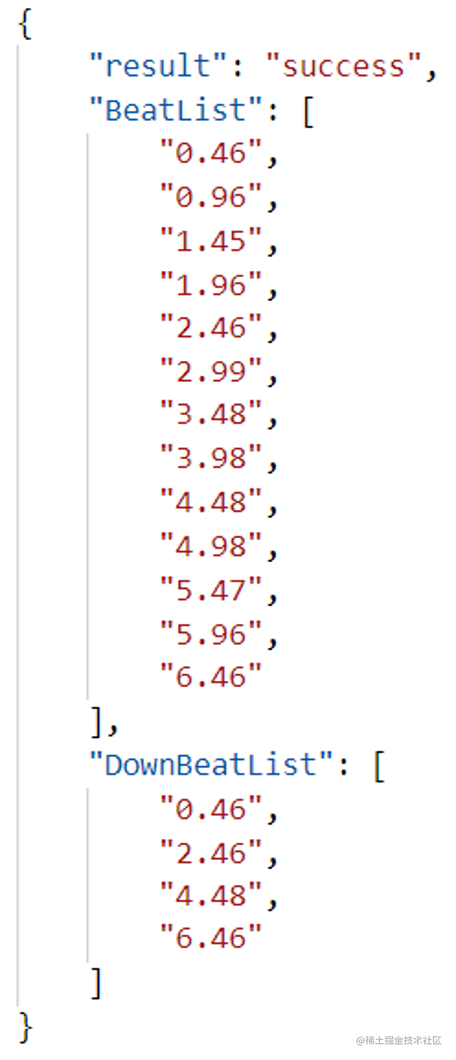
节奏检测即识别音乐中的节奏点,其主要应用场景为视频制作和音乐推荐,比如,通过识别出音乐节奏点,进行鬼畜视频的制作;通过识别音乐的节拍类型,是四三拍还是四四拍,帮助进行音乐分类等。
继续以上述音频示例,节奏检测算法输出两个结果:第一个是节拍时间点,如0.46秒、0.96秒均为节拍时间点;第二个是downbeat时间点,在乐理中解释为重拍,其中0.46秒为第一拍,2.46秒为第五拍,也就是说每四拍为一个小节,每小节的第一拍为重拍,由此检测出该音乐的节奏。
其他音频智能处理能力
此外,视频云还提供其他音频智能处理能力,包括混音,ASR语音识别和TTS语音合成。混音即把两个音乐片段进行叠加,其中涉及到音量增益和自动控制算法。
这些能力进行组合,还可以实现更多玩法,比如歌曲串烧,首先通过副歌识别,把几首歌曲的副歌部分提取出来,然后进行节奏检测,把合适的节拍点合在一起,最终组合成一首完整的歌曲串烧。
04 开箱即用:阿里云媒资服务
基于视频AI原理以及效果,阿里云利用现有资源,提供更方便、更高效的音视频AI使用能力。
MPS服务
MPS是媒体处理的英文简称。阿里云提供针对多媒体的数据处理服务,将媒体处理过程抽象成两种模式:一种是输入音视频等多媒体文件,经过智能化媒体处理,生成一个新的媒体文件,比如之前提到的智能横转竖。
另一种模式是输入一个媒体文件,输出经过媒体处理分析后的一系列结构化数据,比如智能标签或智能审核。
MPS支持多项音视频智能处理能力,此外,MPS的媒体文件类型,既可以输入OSS文件,也支持输入网络URL地址。

MPS接口调用的流程为:
第一步,开通MPS产品,在开通的过程中,控制台会引导进行增加权限等相关操作。
开通MPS产品:https://www.aliyun.com/product/mts
第二步,调用MPS的Open API接口,获得Access Key,包括AK的ID和密钥。所有阿里云的Open API都要通过AK和SK访问。
使用RAM服务获取AccessKey:https://ram.console.aliyun.com/manage/ak
第三步,认真阅读MPS提供的API文档:https://help.aliyun.com/document_detail/29210.html
第四步,针对开发需要,选用不同编程语言,并安装依赖模块:https://help.aliyun.com/document_detail/188024.html
第五步,编写代码。
阿里云MPS服务提供的智能化能力可以分为四个维度:
一是视频内容理解,包含智能标签,智能审核,媒体DNA,媒体DNA是视频检索中的重要组成部分,还有智能封面、视频摘要等。
二是视频智能处理,像横转竖、去图标、去字幕、字幕提取等,从电视剧或电影中抽取出字幕,并输出TXT或者SRT格式,此外,也包括绿幕抠图和PPT拆条等。
三是音频智能处理,包含副歌检测、混音处理、节奏检测和音质检测等。
四是图片智能处理,包含横转竖、去图标和人像风格化。人像风格化可以把一张人像图片风格化成不同的形式,比如把人像进行卡通化,或者进行3D处理。

IMS服务
IMS服务是阿里云近年来新上的服务,全称是智能媒体服务,和MPS服务的区别在于:
IMS服务围绕直播和点播场景,是针对媒体处理的全流程服务,可认为是MPS服务的重大产品迭代和升级。
第一,IMS不仅针对于单个媒体处理过程,而是对于媒体服务全流程、全生产周期的管理和制作;
第二,IMS的集成度更高,不光可以进行单个原子能力的音视频处理,还可以进行媒资管理、工作流触发等,让开发者更方便地使用音视频智能化能力;
第三,IMS更智能,后续所有智能化能力升级后都会集中体现在IMS服务中。

IMS控制台融合了媒资管理,媒资库中的音频视频文件,包括图片、辅助的媒资,都可以通过IMS服务进行展示和管理。
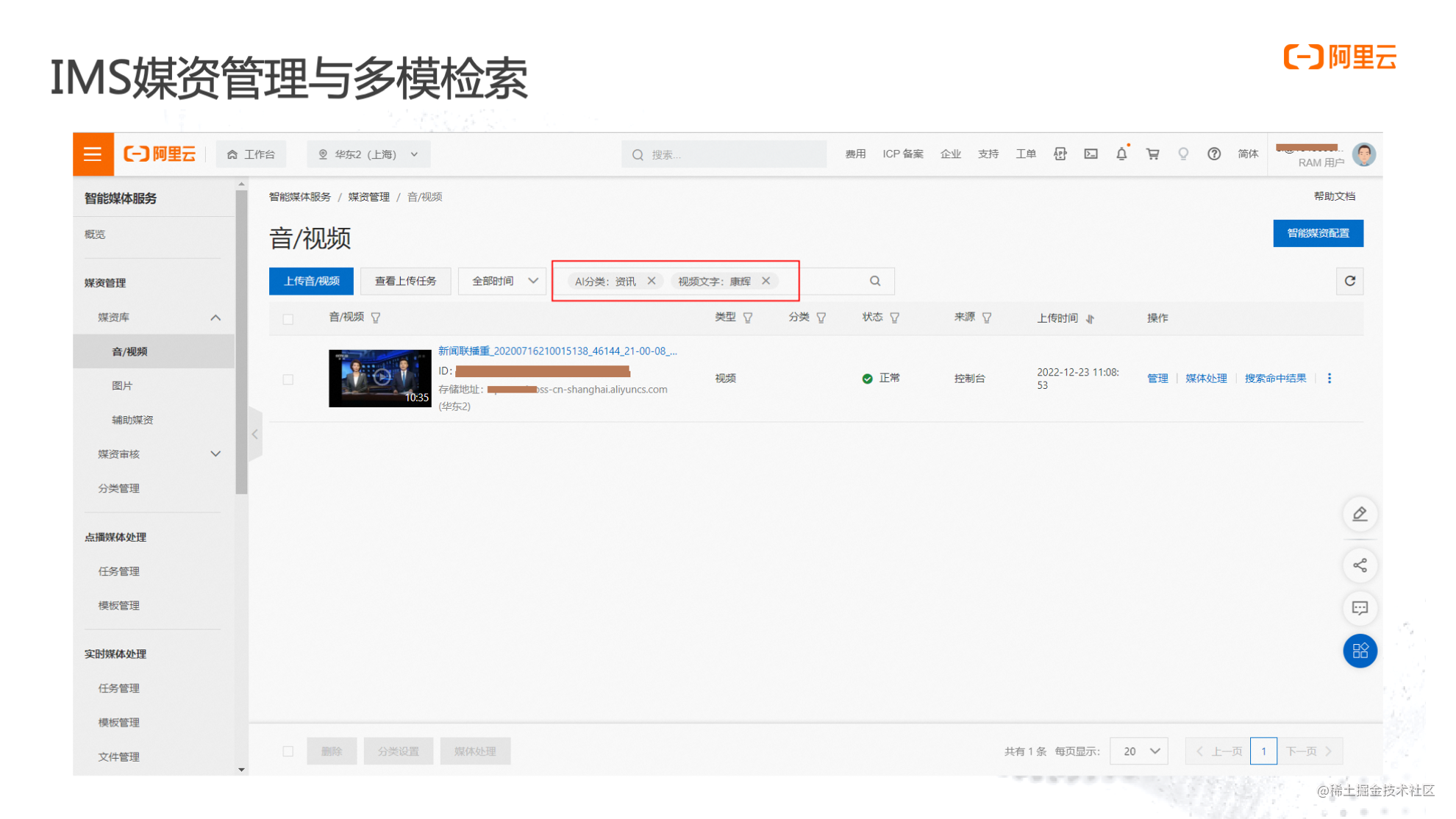
利用多模检索的智能化能力,IMS可以实现多媒体文件的智能化检索。传统的音视频文件检索,只能针对标题或者简介进行,而IMS支持对上传的音视频文件做AI自动分类,并根据分类结果进行搜索,同时,也支持对视频中的文字进行自动识别检索。
比如,新闻联播的画面中出现了“康辉”两个字样,虽然视频文件的标题和简介里都没有出现过“康辉”,但在搜索“康辉”时,AI还是可以搜索识别出此视频文件,这就是多模检索的能力。
Retina多媒体AI体验中心
上述MPS和IMS服务的智能化能力,都需要通过Open API调用或者控制台开通使用,而Retina体验中心可以让大家更方便快捷地进行体验,只需上传视频或图片,就可以直观地得到经过智能化处理后的结果。
例如,在Retina平台,你可以体验人像卡通化的效果,只需上传一张人像图片,经过自动处理,就能获得童话风格的卡通人像图片,更多体验就在:http://retina.aliyun.com/

随着视频与AI技术的发展和演进,AI在媒体生产领域中发挥着越来越重要的作用,以更快的速度、更高的效率完成之前难以实现的事情。
未来,AI将从辅助媒体生产,逐渐转变为直接生产有意义、有价值、有情感的视频,进一步加速媒体生产制作全自动处理进程。
更多完整内容详见课程回放 ⬇️


