
- 1基于Springboot高校学校教室实验室房间预约系统设计与实现 开题报告参考
- 2火遍全网的 ChatGPT,给你的求职新方向_招聘 chatgtp 方向
- 3php 函数(方法)、日期函数、static关键字
- 4vue运用之el-cascader组件
- 5【Android】进程通信IPC——Messenger_fstack ipc message error
- 6白化滤波器 matlab,白化滤波器-matlab-程序.doc
- 7Unity2D更换图片纹理实现动画_unity spine替换纹理
- 8SpringBoot集成RabbitMq 手动ACK_springboot rabbitmq 手动ack
- 9Python:基于Python爬虫技术的抢票程序及其实现_抢票代码
- 10智能家居离线语音识别控制系统设计(SU-03T)_su03t语音模块原理图
基于Keras、DenseNet模型微调、参数冻结、数据增强、模型训练、模型验证全流程记录(模型微调开发全流程记录)_keras densenet 第五 层 输出
赞
踩
基于DeneNet,使用keras搭建模型,用imagenet的权重进行预训练。densenet169的layers数量未595,冻结模型前593,增加一个2分类的dense层,使用图片训练。
本篇仅对模型的训练和调整步骤进行记录。对超参数的调整以及相关问题,请看后续文章。
https://blog.csdn.net/Labiod/article/details/105296184
微调模型、冻结参数
对模型进行微调之前,需要先对模型的整体框架进行一个了解。微调的层数为整个网络框架的最后的全连接层。这里使用plot_model()函数,显示出框架内的整体结构:
- from keras.utils import plot_model
-
- plot_model(model, to_file='../ModelImage/DenseNet169.jpg', show_shapes=True) # 使用Keras的自带库显示框架结构
修改前的模型(只截取末端的几层):

对这个模型做微调。使用基于denseNet在imageNet预训练好的权重。
步骤如下:
选取取消头部全连接层的模型作为基模型 --》 添加新的全连接层并将其与之前层连接起来 --》 冻结相应预训练参数模型 —》对新的模型进行complie
代码如下:
- base_model = DenseNet169(include_top=False, weights='imagenet', input_shape=(IN_WIDTH,INT_HEIGHT, 3))
- # dinclude_top=False 表示取消模型顶部的全连接层
- # weights='imagenet' 表示使用预训练的权重
-
- model = add_new_last_layer(base_model, 2)
- # 设置新的全连接层,并将其与之前的层数连接起来
-
- for layer in model.layers[:595]: # DenseNet169需要冻结前595层
- layer.trainable = False # 冻结模型全连接层之前的参数
-
- model.compile(optimizer=SGD(lr=learning_rate, momentum=0.9), loss=[mycrossentropy()], metrics=['accuracy'])
- # 对模型进行新的编译 ,同时设定优化器、learning rate等参数
连接全连接层与base_model代码add_new_last_layer()如下:
- def add_new_last_layer(base_model, nb_classes, drop_rate=0.):
-
- """Add last layer to the convnet
- Args:
- base_model: keras model excluding top
- nb_classes: # of classes
- Returns:
- new keras model with last layer
- """
- x = base_model.output
- x = Dropout(0.5)(x) # 添加dropout层
- x = GlobalAveragePooling2D()(x) # 添加Pooling层
- predictions = Dense(nb_classes, activation='softmax')(x) # 添加softmax层
- model = Model(inputs=base_model.input, outputs=predictions) # 这一步将微调后模型的卷积层和新的softmax层连接起来
- return model
修改后的模型(仅保存后边几层):
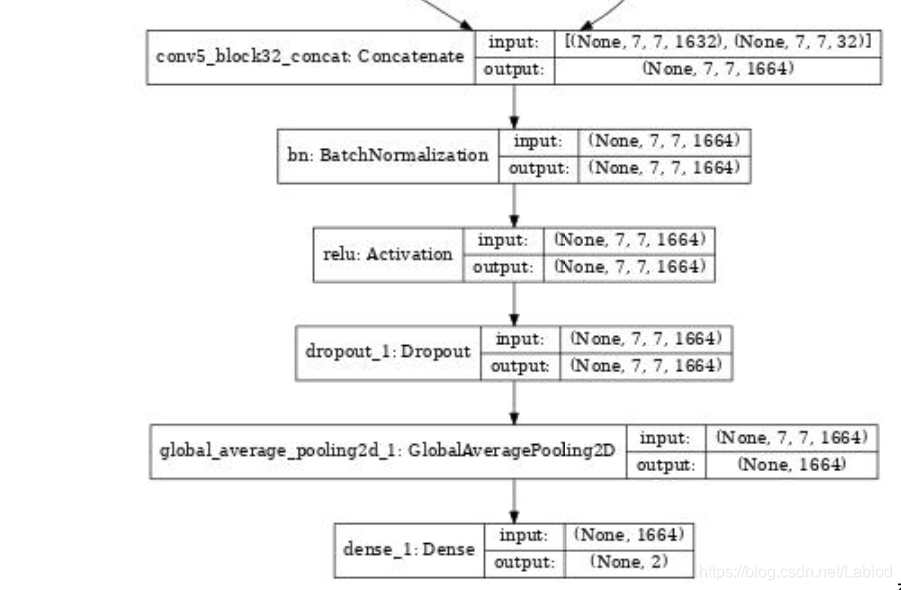
数据增强
微调好的模型,训练数据的数量过少,使用数据增强对数据集进行扩充。
使用keras数据增强:
导入库:
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array设置增强方式:
- datagen = ImageDataGenerator(
- rotation_range=40,
- width_shift_range=0.2,
- height_shift_range = 0.2,
- shear_range=0.2,
- zoom_range=0.2,
- horizontal_flip=True,
- fill_mode="nearst"
- )
对路径下的OK路径下的数据进行增强:
- for img in img_OK:
- img = image.load_img(img)
- x = image.img_to_array(img) # 把PIL图像转换成一个numpy数组,形状为(3, 150, 150)
- x = x.reshape((1,) + x.shape) # 这是一个numpy数组,形状为 (1, 3, 150, 150)
-
- # 下面是生产图片的代码
- # 生产的所有图片保存在 `save_to_dir` 目录下
- i = 0
- for batch in datagen.flow(x, batch_size=32,
- save_to_dir='../data/DataEnhancement/OK', save_prefix='mask', save_format='jpg'):
-
- i += 1
- print("batch_OK: {} is in the {}", img, i)
- if i > 50:
- break # 否则生成器会退出循环
完成数据增强后,就可以得图像在各维度上变换后的数据集了。
训练模型
设置keras训练参数
- #######################################
- # 在训练的时候置为1
- from keras import backend as K
- K.set_learning_phase(1)
- #######################################
使用数据生成器生成训练集和验证集:
这里给出训练集生成器代码,验证集生成器原理类似。
- train_generator = train_datagen.flow_from_directory(
-
- directory = TRAIN_DIR, # 数据路径
- target_size = (IN_WIDTH, INT_HEIGHT), # 图片大小
- batch_size=BATCH_SIZE, # batch_size 一次训练所选取的样本数,
-
- class_mode='categorical',
- seed=2018, # 设置seed的作用可以使随机数据可以预测,即只要seed的值一样,后续生成随机数都是一样的。
-
- interpolation='box', # PIL默认插值下采样的时候会模糊
- # 使用PIL调整图像的大小
- )
使用model.fit_generator()来实现模型训练:
这一步里需要传入之前生成的训练、测试集等条件, 具体参数值,根据自己需要设定。
- model.fit_generator(
- # 当数据集比较难处理,比如,太大而无法放入内存,要求进行增强以对抗过拟合。
- train_generator, # fit_generator必需要传入一个生成器,我们的训练数据也是通过生成器产生的
- steps_per_epoch = 1*(train_generator.samples // BATCH_SIZE + 1),
- # 用BATCH_SIZE将原数据转换为steps_per_epoch。从generator产生的步骤的总数(样本批次总数)。
- # 通常情况下,应该等于数据集的样本数量除以批量的大小。
- epochs = EPOCHS, # 整数,在数据集上迭代的总数
- max_queue_size = 10, # 迭代器最大队列数,默认为10
- workers = 1, # 在使用基于进程的线程时,最多需要启动的进程数量。
- verbose = 1, # 日志显示开关。0代表不输出日志,1代表输出进度条记录,2代表每轮输出一行记录
- validation_data = valid_generator, # 导入验证集数据
- validation_steps = valid_generator.samples // BATCH_SIZE,
- callbacks = callbacks # 回调函数
- )
注意这里还需要使用keras里的回调函数(callbacks)来配置一些其它的训练策略:
使用get_callbackes传递callbacks,具体参数值,根据自己需要设定。
- callbacks = get_callbacks(filepath=save_model_path, patience=3)
- # filepath:保存模型文件的路径
- # patience:停止增长后训练的epoch数
get_callbackes()函数中,调用部分keras的函数方法代码如下。
具体参数值,根据自己需要设定。
- def get_callbacks(filepath, patience=2):
- lr_reduce = ReduceLROnPlateau(monitor='val_accuracy', factor=0.1, epsilon=1e-5, patience=patience, verbose=1, min_lr = 0.00001)
- # 该回调函数检测patience数量,如果没有看到epoch的“patience”数量的改善,那么学习率就会降低。
-
- msave = ModelCheckpoint(filepath, monitor='val_acc', save_best_only=False)
- # 该回调函数将在每个epoch后保存模型到filepath
- # save_best_only:当设置为True时,将只保存在验证集上性能最好的模型
- earlystop = EarlyStopping(monitor='val_accuracy', min_delta=0, patience=patience*3+2, verbose=1, mode='auto')
- # 早停法是一种广泛被使用的降低过拟合的方法
-
- return [lr_reduce, msave, earlystop]
ReduceLROnPlateau()函数,当验证集精度在一定周期里不再上涨时,降低学习率。
ModelCheckpoint()函数,当检测的验证集精度达到最高时,保存模型。
EarlyStopping()函数,当验证集精度在一定周期内不再上涨后,就停止训练,防止过拟合。
最终将各种策略的返回值,传递给callback,由之前的model.fit_generator()机制,实现模型训练过程中的一些小tricks,使训练过程尽量避免泛化不足、过拟和等问题。
验证模型
验证模型代码如下:
- def predict(weights_path, IN_SIZE):
- '''
- 对测试数据进行预测
- '''
-
- IN_WIDTH = IN_SIZE
- INT_HEIGHT = IN_SIZE
- K.set_learning_phase(0)
- # 函数返回值,决定当前模型是在训练模式下,还是测试模式下。变量 1:训练模式, 0: 测试模式
-
- test_pic_root_path = '../data/data2/test'
-
- filename = []
- probability = [] # 可能性
-
- # 1#得到模型
- model = get_model(IN_SIZE) # 这个步骤最终会加载预训练好的DenseNet169
- model.load_weights(weights_path)
-
- # 2#预测
- for parent,_,files in os.walk(test_pic_root_path):
- # os.walk返回遍历的目录地址。不包括子目录
- # parent是指返回这个遍历本身的路径; _ (list),该文件夹中所有目录的名字;files(list),该文件夹中的所有文件
- for line in files:
-
- pic_path = os.path.join(test_pic_root_path, line.strip())
-
- ori_img = cv2.imread(pic_path)
-
- img = load_img(pic_path, target_size=(INT_HEIGHT, IN_WIDTH, 3), interpolation='box')
- img = img_to_array(img)
- # img_to_array()不管是2D shape还是3D shape image,返回都是3D Numpy array.
- img = preprocess_input(img)
- # keras中 preprocess_input() 函数完成数据预处理的工作,数据预处理能够提高算法的运行效果。
- # 常用的预处理包括数据归一化和白化(whitening)。
- img = np.expand_dims(img, axis=0)
- # np.expand_dims(img, axis=0)表示再0位置增加数据
-
- prediction = model.predict(img)[0]
- index = list(prediction).index(np.max(prediction)) # index()函数用于从列表中找出某个值第一个匹配项的索引位置
- pro = list(prediction)[0] # bad对应的概率大小,因为bad是在index为0的位置
- pro = round(pro, 5) # 将数字四舍五入为仅两个小数
- if pro == 0:
- pro = 0.00001
- if pro == 1:
- pro = 0.99999
-
- # 存入list
- filename.append(line.strip()) # Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
- probability.append(pro)
-
- #3#写入csv
- res_path = "../submit/submit_"+datetime.datetime.now().strftime('%Y%m%d_%H%M%S') + ".csv"
- dataframe = pd.DataFrame({'filename': filename, 'probability': probability})
- dataframe.to_csv(res_path, index=False, header=True)

到这一步基本可以完成一个完整的训练过程。源码将在后续进一步整理后更新。在调试过程中出现的一系列问题也将在后续更新。
最终,在main()里,设置好相关路径、调用训练、验证模块,设置好超参数等信息,即可运行代码,完成训练。
训练使用环境
环境: VScode
tensorflow-gpu 2.0.0
keras 2.3.1
cuda 10.1
GPU驱动 Driver Version: 418.87.00

