
- 1win11虚拟机如何安装 Windows11虚拟机安装步骤教程
- 2Python配置与测试利器:Hydra + pytest的完美结合_python hydra
- 3为微软键盘添加小鹤双拼——编程学习_微软拼音如何添加小鹤双拼
- 4JavaScript:实现将 base64 字符串转换为字节数组算法(附完整源码)_js 把base转字节集
- 5 SQL 安装问题_找不到 x86\setup\setupsql.exe
- 6使用 Amazon SageMaker 构建高质量 AI 作画模型 Stable Diffusion
- 7数学建模【微分方程传染病预测模型】
- 8Jetson Orin NX 开发指南(8): Pixhawk 6X 飞控固件的烧写与 QGroundControl 参数设置
- 9100 个 Go 错误以及如何避免:1~4_100个go语言典型错误
- 10知乎-怎样算是精通c++_高级c++工程师经验 csdn 知乎
目标检测算法——Fast R-CNN_fastrcnn
赞
踩
1.Fast R-CNN简介
Fast R-CNN
其论文的名字就是 Fast R-CNN,原文链接。Fast R-CNN与R-CNN相同,同样使用VGG16作为网络的backbone,与R-CNN相比训练时间快9倍,测试推理时间快213倍,准确率从62%提升至66%(再Pascal VOC数据集上)。
Fast R-CNN 算法流程可分为3个步骤
- 一张图像生成1K~2K个 候选区域(使用Selective Search方法
- 将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过ROI(Region of Interest) pooling层缩放到 7x7 大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果

2.Fast R-CNN处理过程
1)候选区域的生成
与R-CNN一样,利用Selective Search算法通过图像分割的方法得到一些原始区域,然后使用一些合并策略将这些区域合并,得到一个层次化的区域结构,而这些结构就包含着可能需要的物体。
但是,Fast R-CNN与R-CNN不同的是,这些生成出来的候选区域不需要每一个都丢到卷积神经网络里面提取特征,而且只需要在特征图上映射便可,见下一个步骤。

2)投影特征图获得相应的特征矩阵
Fast-RCNN没有像RCNN一样,其不限制输入的图像的尺寸,其将整张图像送入网络,得到了一个特征图。紧接着从特征图像上提取相应的候选区域。这些候选区域的特征不需要再重复计算,简洁了不少的时间。

但是这其中涉及训练数据正负样本采样的问题。不过Fast R-CNN与Faster R-CNN处理得不同,也可以不用太过的在意。
在Fast R-CNN中,并不适用SS算法提供的所有的候选区域,SS算法会差不多得到2000个候选框,但是训练的过程中其实只需要使用其中的一部分就可以了,Fast R-CNN中好像只挑选了其中的64个。其中还是分为正样本与负样本,正样本指的是在候选框中确实存在所需检测目标的样本;而负样本指的是候选框中没有所需检测的目标,也就是只有背景。
视频up主所理解的一个意思是,当数据不平衡时,数据会有所偏向。如果全部只有正样本,那么网络就会有很大的一个概率认为候选区域是我们需要的一个检测目标,这样就会有问题,所以存在正负样品。
正样本的定义为候选框与真实的目标边界框的iou大于0.5;负样本的定义为候选框与所有真实的目标边界框的iou值最大的区间为0.1-0.5。重点是其实没有完全适应SS算法提供的所以的边界框。
3)ROI层缩放
有了训练样本之后,将训练样本的候选框通过ROI Pooling层缩放到统一的尺寸。
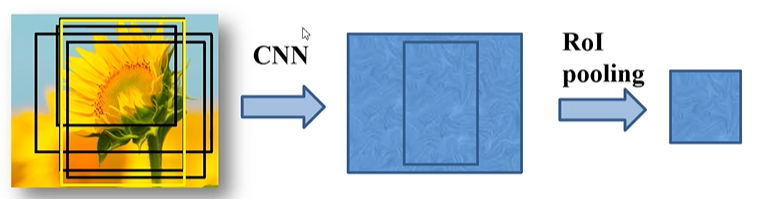
ROI Pooling层的具体做法是,将候选框所框选的训练样本,这是一个比较抽象的特征信息。将其划分为77,也就是49等份。划分之后,对每一个区域做一个最大池化下采样操作,也就是MaxPooling操作。如此对49等分的候选区域操作,便得到了一个77的特征矩阵。

也就是说,无论候选区域的特征矩阵是怎么样的尺寸,都被缩放到一个77的大小,这样就可以不去限制输入图像的尺寸了。因为,作进一步的工作的是输入图像的候选区域,而候选区域总是能被缩放为77的尺寸的,所以也就和输入图像的尺寸无关。
在R-CNN当中,其使用的卷积神经网络要求输入是227*227大小,但是Fast R-CNN就不需要考虑这个因素。
4)展平特征图利用全连接层得到预测结果。
概率分类器
输出N+1个类别的概率(N为检测目标的种类, 1为背景)共N+1个节点。

其中的第0个节点表示的背景的概率。剩下的20个是其他所需检测的类别概率。这个概率是经过softmax处理之后的,是满足一个概率分布的,其和为1.而既然现在是需要预测21个类别的概率,所以目标概率预测的全连接层为21个节点。
边界框回归器
输出对应N+1个类别的候选边界框回归参数(d x , d y , d w , d h )。需要注意,这是每一个类别都有这4个参数。所以共(N+1)x4个节点。

也就是4个4个为一组,一组为一个边界框回归参数。那么如何根据回归参数得到最后的预测边界框?
对应着每个类别的候选边界框回归参数(d x , d y , d w , d h)


Px,Py,Pw,Ph 分别为候选框的中心x,y坐标,以及宽高
Gx,Gy,Gw,Gh 分别为最终预测的边界框中心x,y坐标,以及宽高
3.Fast R-CNN损失函数
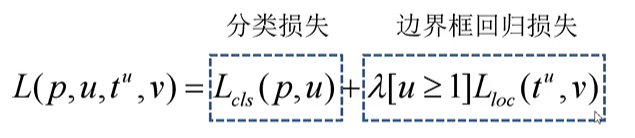
- p是分类器预测的softmax概率分布p = (p0, …, pk)
- u对应目标真实类别标签
- tu对应边界框回归器预测的对应类别u的回归参数(tux,tuy,tuw,tuh)
- v对应真实目标的边界框回归参数(vx,vy,vw,vh)
其中真实目标边界框回归参数的计算公式为:
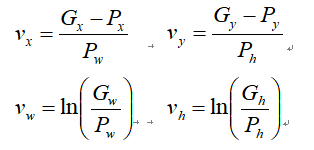
其中对于分类损失:
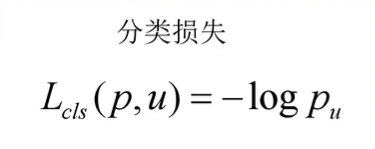
- p是分类器预测的softmax概率分布p = (p0, …, pk)
- u对应目标真实类别标签
其中对于边界框回归损失:
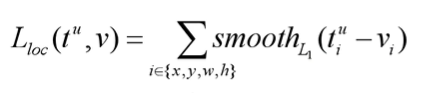
注意,这个损失是由4个部分组成的。分别对应着我们回归参数 x 的smoothL1的回归损失,回归参数 y 的smoothL1的回归损失,回归参数 w 的smoothL1的回归损失与最后的回归参数 h 的smoothL1的回归损失。
- tu对应边界框回归器预测的对应类别u的回归参数(tux,tuy,tuw,tuh)
- v对应真实目标的边界框回归参数(vx,vy,vw,vh)
而具体的smoothL1损失的计算公式为
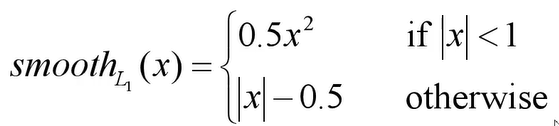
λ 是一个平衡系数,用于平衡分类损失与边界框回归损失。
[u ≥ 1] 是艾佛森括号,也可以理解为一个计算公式。当u满足条件是,公式的值为1;而当u不满足条件时,也就是u<1时,也就是u=0时,(u为类别的标签),此时类别标签为背景,公式的值为0.
u代表了目标的真是标签,u ≥ 1表示候选区域确实属于所需检测的某一个类别当中,也就是对应着正样本。当u=0时,此时候选区域对应着为背景,不属于所需检测的某一个类别当中。那既然是背景,就没有边界框回归损失这一项了。
也就是Fast R-CNN的总损失 = 分类损失 + 边界框回归损失然后对其进行反向传播就可以训练Fast R-CNN网络了。
4.Fast R-CNN总框架
再来看一下Fast R-CNN网络结构的框架

直接将输入的图像输入到神经网络中得到一个特征图,通过ss算法得到的候选区域,根据映射关系找到每一个候选区域的特征矩阵。将特征矩阵通过ROI Pooling层统一缩放到7*7的大小,然后将其展平处理,然后通过两个全连接层,得到ROI feature Vector。在ROI feature Vector的基础上,并联两个全连接层。其中的一个全连接层用于目标概率的预测,另外的一个全连接层用来边界框回归参数的预测。
以上便是整个Fast R-CNN的结构处理流程。
Fast R-CNN框架

Fast R-CNN比R-CNN快了200多倍,选择Fast R-CNN的速度瓶颈就在ss算法上
参考资料:
https://www.bilibili.com/video/BV1af4y1m7iL?p=2

