
- 1Cassandra介绍与使用
- 2Git镜像网址及其下载安装教程_git镜像地址
- 3Python学习(3)---主成分分析(PCA)的基本原理及其Python实现_python的pca函数怎么分析载荷
- 4Cassandra 数据库操作命令_cassandra 命令操作创建数据库
- 5Vue - 超详细 Element 组件库主题颜色进行 “统一全局“ 替换,将默认的蓝色主题色更换为其他自定义颜色(保姆级教程,简易且标准全局替换主题色)_实现了在 vue3+element plus 项目开发中,统一全局覆盖更换默认主题蓝色,引入一次
- 6unity包体相关的加密解密操作_unityfs解密
- 7元宇宙之问:产业与资本为什么扎堆元宇宙_immersive stream for xr
- 8canvas+audio+range 模拟音乐播放器_zmw77.aqq
- 9【微信小程序开发】使微信小程序中的图片长按保存_wx长按保存dom
- 10Unity Webgl使用GET/POST获取服务器数据,对JSON数据进行解析_unity webgal json
超强满血不收费的AI绘图教程来了(在线Stable Diffusion一键即用)_liblibai教程
赞
踩
超强满血不收费的AI绘图教程来了(在线Stable Diffusion一键即用)
一、简介
1.1 AI绘图
AI绘图就是输入一些描述语句(文生图)或者图片(图生图),AI根据输入信息可以生成创意画作。AI绘图是当下AI最火热的应用领域之一,也是生成式人工智能AIGC的一种。
常见AI绘图软件如下:

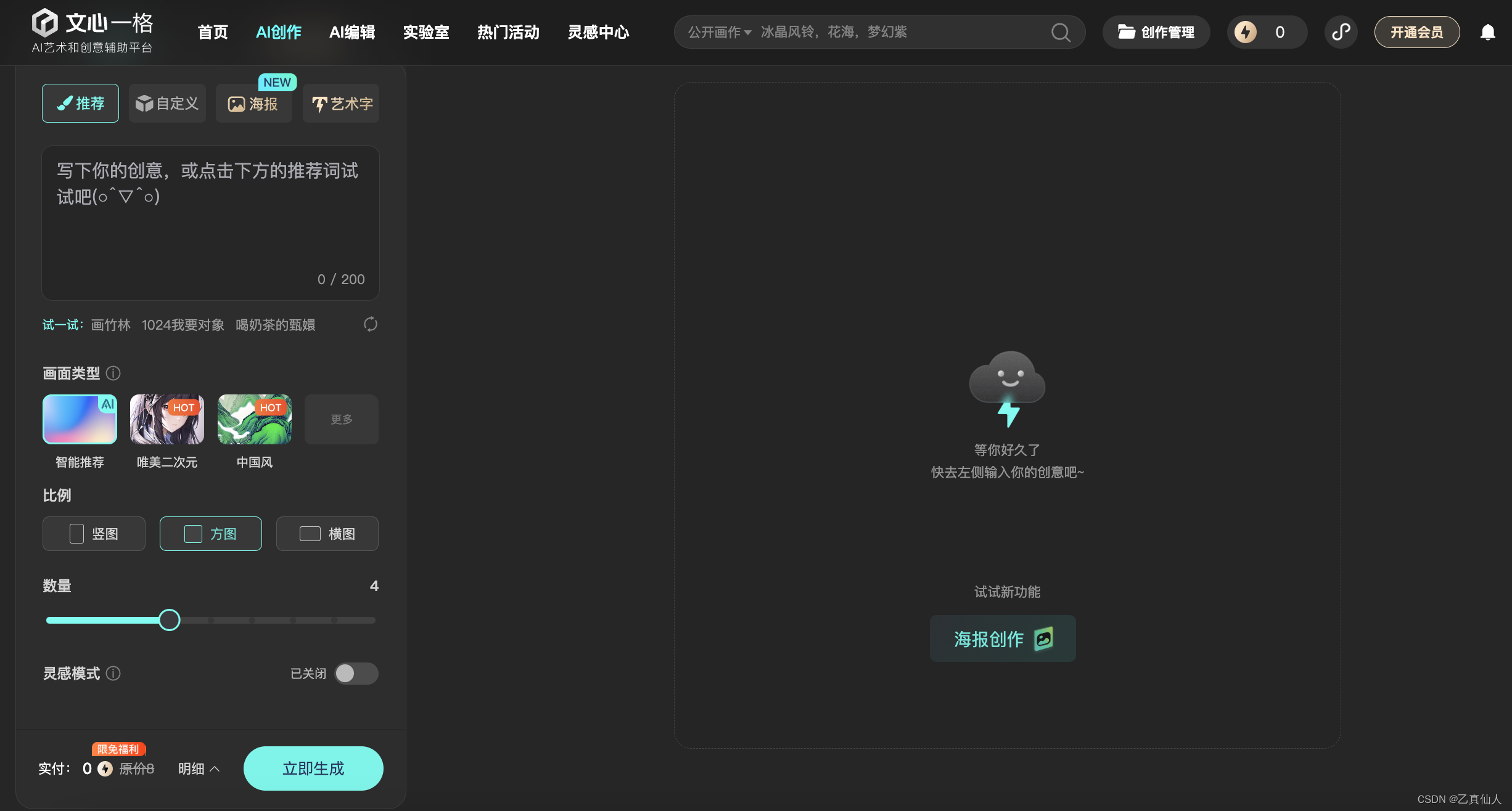
(1)文心一格
文心一格是基于百度飞桨和文心大模型的文生图系统,是一种AI艺术和创意辅助平台。通过文心一格智能生产多样化创意图片,并从中汲取创意灵感,打破创意瓶颈。
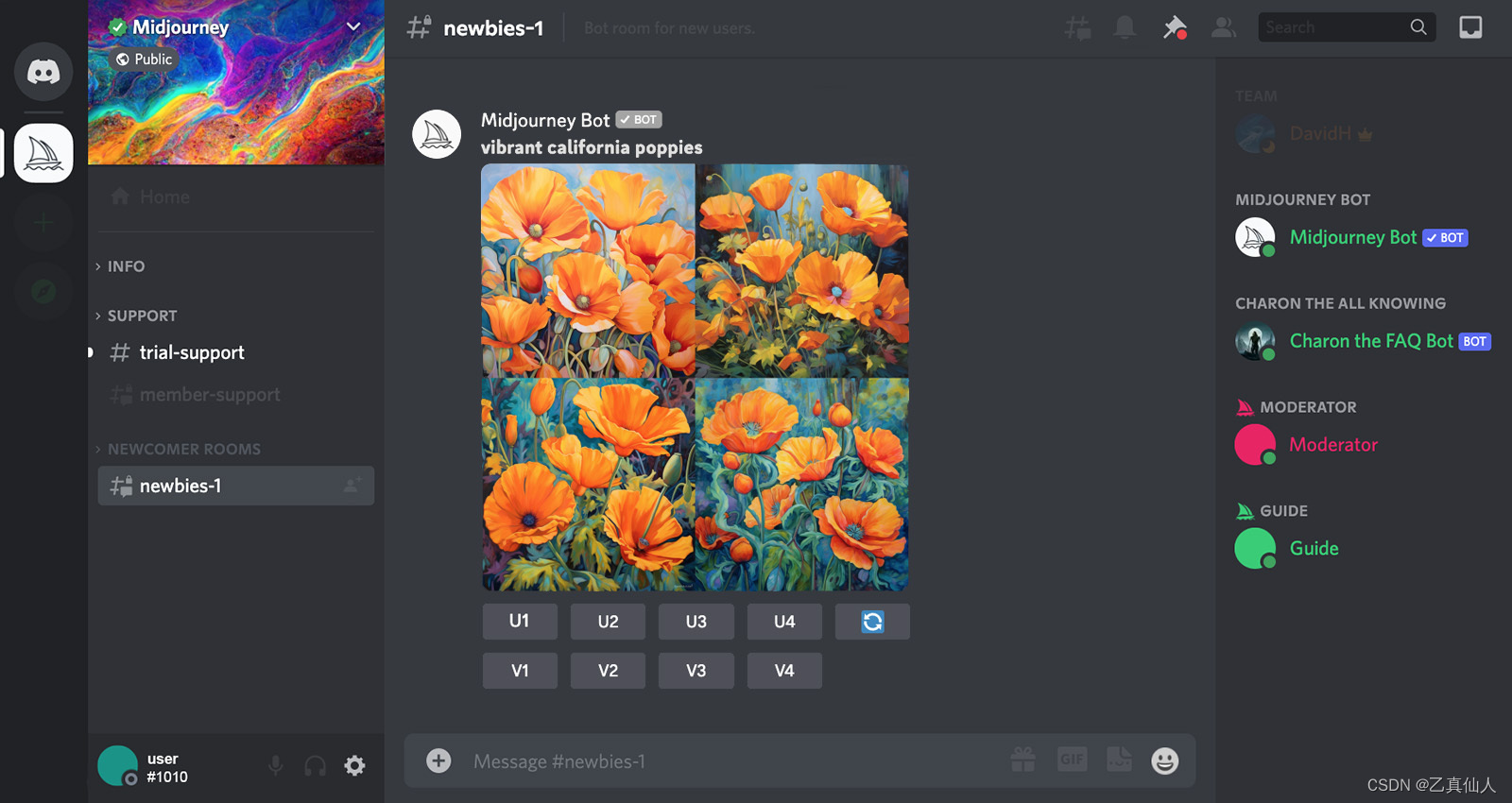
(2)Midjourney
Midjourney可根据文本生成图像,于2022年7月12日进入公开测试阶段,只需要通过输入关键字,就能透过AI算法生成相应的图片,Midjourney里有众多画家的艺术风格,例如达芬奇、达利和毕加索等,还能识别特定镜头或摄影术语。
Midjourney的应用场景非常广泛,可以用于海报、IP设计、广告设计、创意设计、艺术教育、漫画创作等领域。
(3)Adobe Firefly
萤火虫(Firefly),是2023年3月22日Adobe推出的创意生成式AI,使用文字来生成图像、音频、插图、视频和3D图像。Firefly将提供构思、创作和沟通的新方式,同时显著改善创意工作流程。

(4)Stable Diffusion
Stable Diffusion是一种基于潜在扩散模型(Latent Diffusion Models)的文本到图像生成模型,能够跟进任意文本输入生成高质量、高分辨率、高逼真的图像。相对传统的生成模型,Stable Diffusion生成的图像质量更高、速度更快、成本更低。

1.2 Stable Diffusion
本文主要基于Stable Diffusion进行分享,因为↓

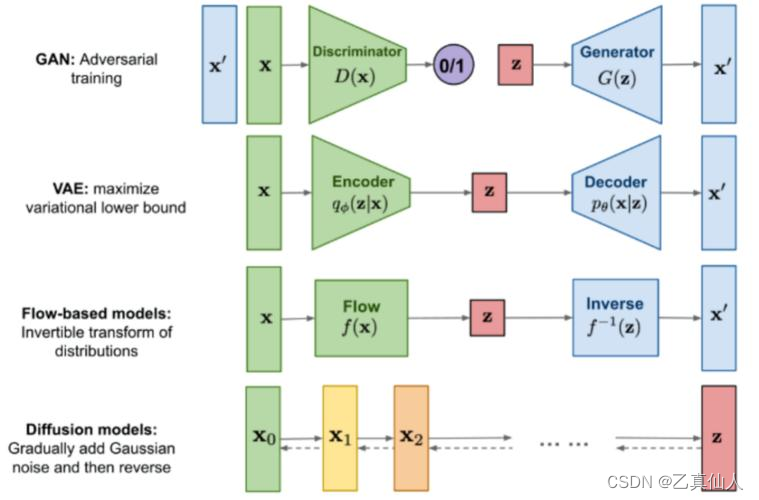
1.2.1 原理简述
从名字Stable Diffusion就可以看出,这个主要采用的是扩散模型(Diffusion Model)。简而言之,扩散模型就是去噪白编码器的连续应用,逐步生成图像的过程。

Diffusion 的含义本质上就是一个迭代过程。扩散是反复在图像中添加小的、随机的噪声,而扩散模型则与这个过程相反,将噪声生成高清图像,训练的神经网络通常为U-net。
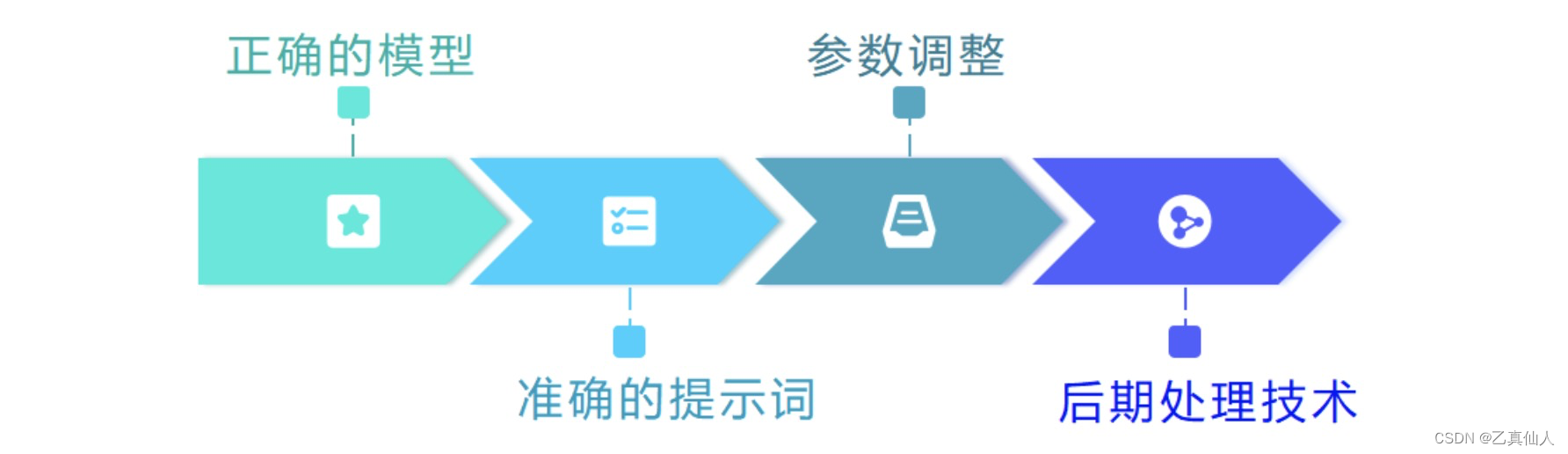
1.2.2 应用流程
流程主要分为4步:
- 选择正确地模型
- 输入准确的提示词
- 参数调整
- 后期处理技术
(1)关于模型
Stable Diffusion模型主要分为大模型和微调模型。常见的大模型为Checkpoint(ckpt)和safetensors两种格式,通常是通过Dreambooth训练得到,特点是出图效果好,但是训练过程较慢且生成的模型文件较大;而微调模型一般需要配合大模型使用,常见包括Lora模型、VAE模型、Embedding模型和Hypernetwork模型。

本文分享主要是基于Lora模型。Lora直译为大语言模型的低阶适应。Lora文件大,保存的信息量大 ,对人物的还原、动作的指定和画风的指定效果比较好。

(2)关于提示词
Stable Diffusion提示词分为正向提示词和反向提示词,一般需要包含【画面质量】+【画面风格】+【画面主体】+【画面场景】+【其它元素】。

二、AI绘图工具
2.1 吐司TusiArt
吐司Tusi.Art是一款基于Stable Diffusion的AI图片生成平台,每天有100算力点、即可生成100张图片,且可以高清下载。

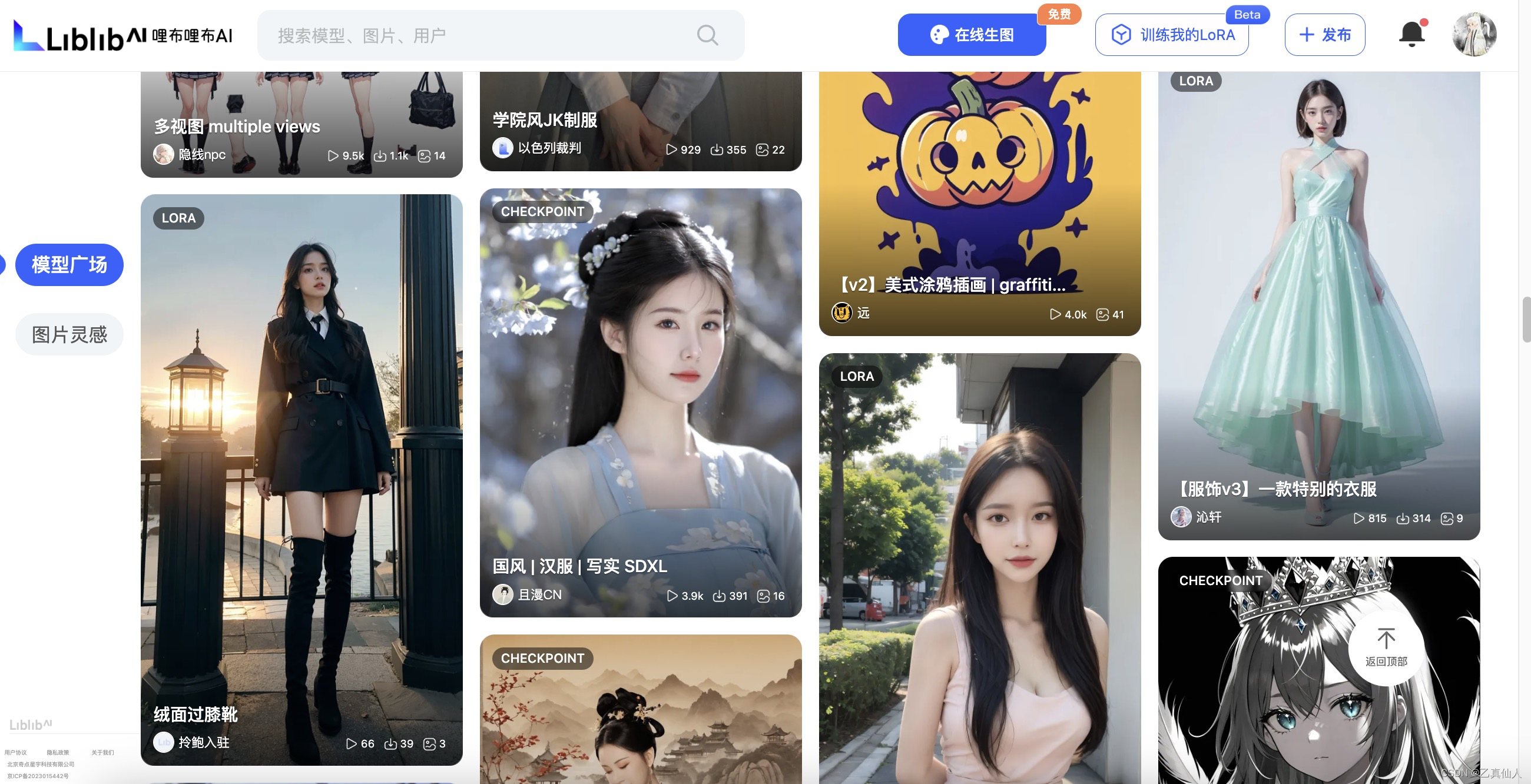
2.2 哩布哩布LibLibAI
LiblibAI基本 1:1 还原了Stable Diffusion跑图界面(有一定阉割),跑图最一目了然、简洁高效的界面,且非常容易上手。另外,LiblibAI每天也可以免费跑100张AI图,后续演示主要基于LiblibAI进行。
2.3 原生部署
本地或云端部署原生Stable Diffusion,例如阿里云云部署↓。
三、一键即用
3.1 开箱尝鲜
注册登录哩布哩布LibLibAI后,直接点击【在线生图】
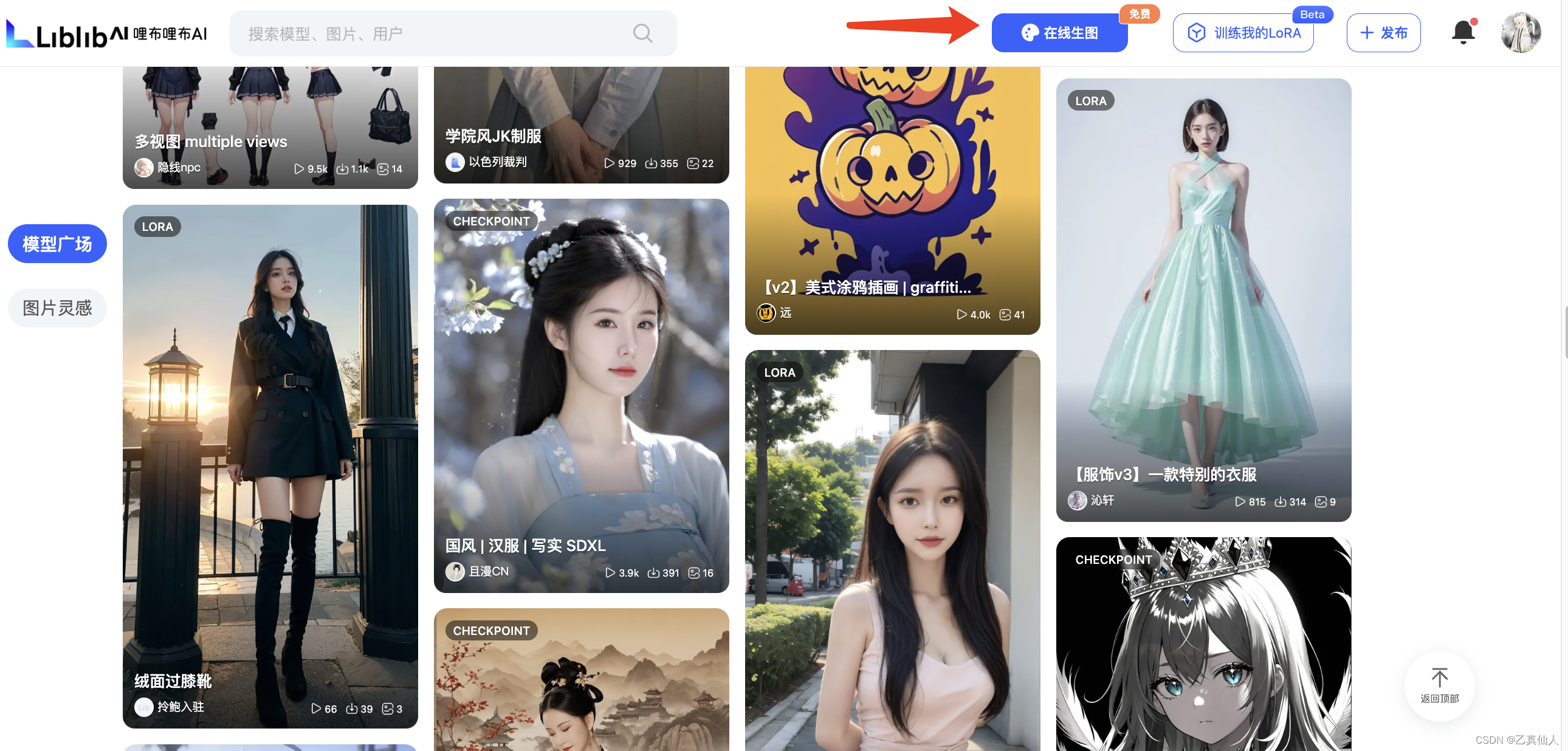
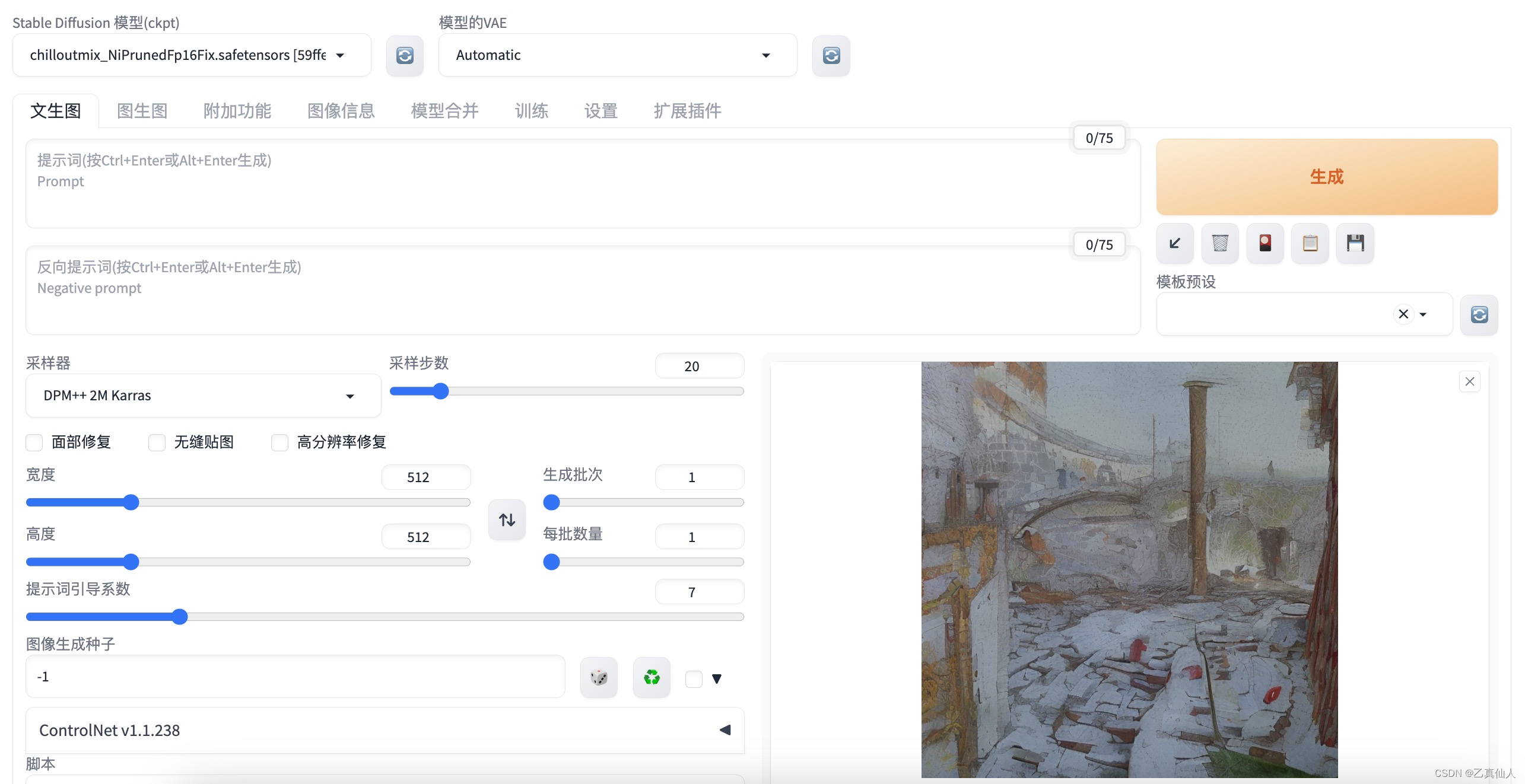
进入到【在线生图】页面后,直接点击【生成图片】,开箱尝鲜。
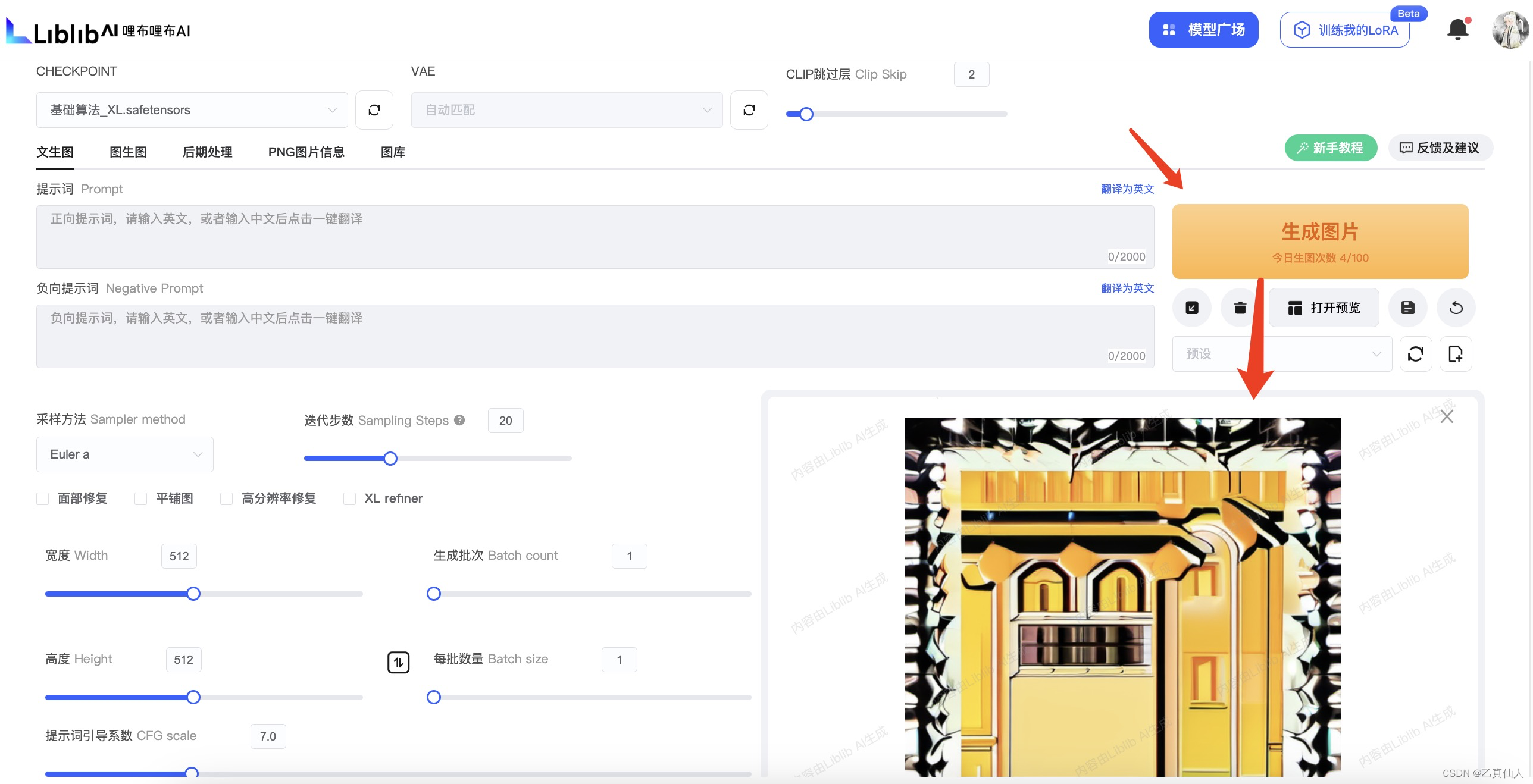
3.2 模型关联
在主页选择一个参照模型,点进去。
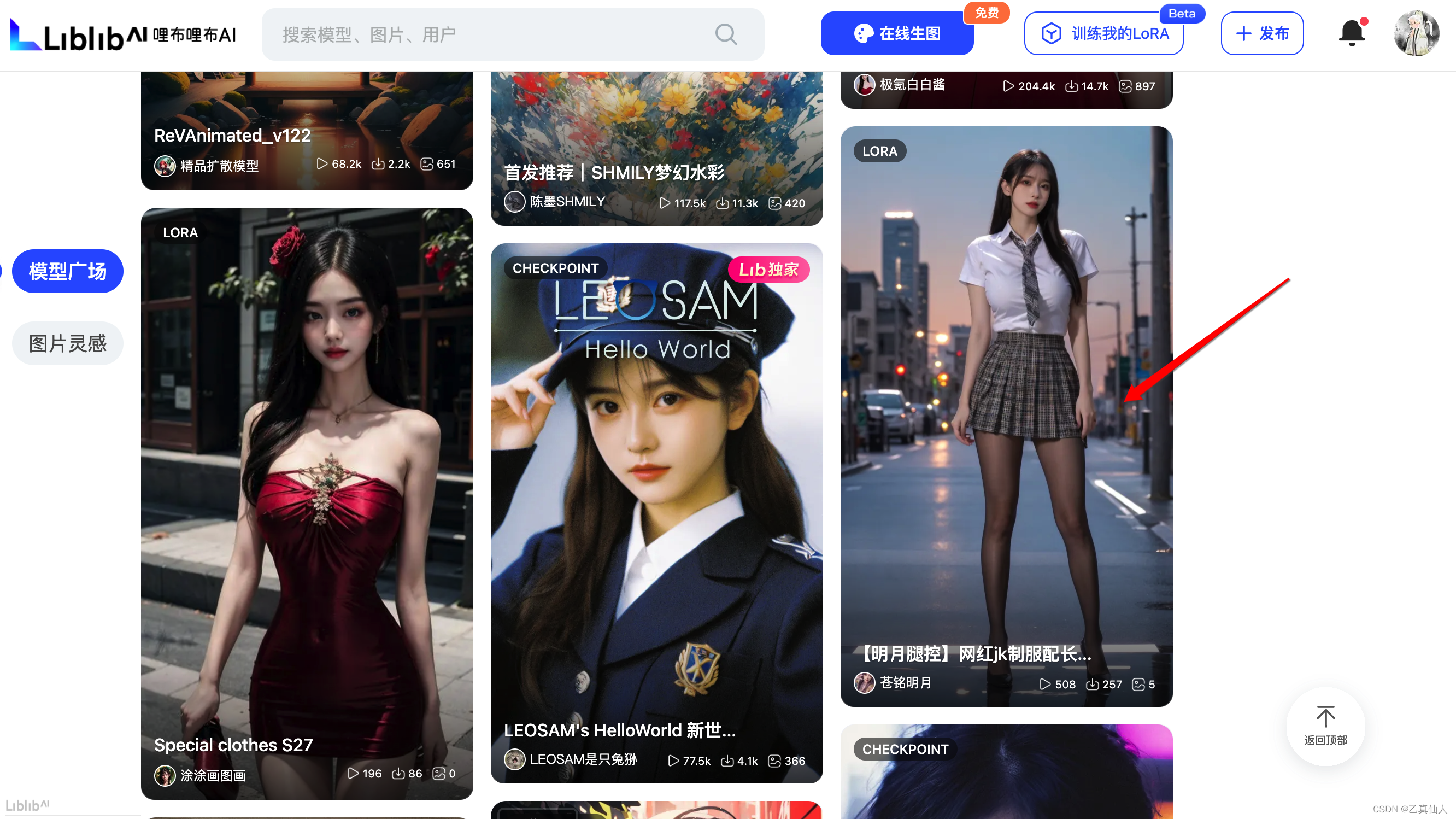
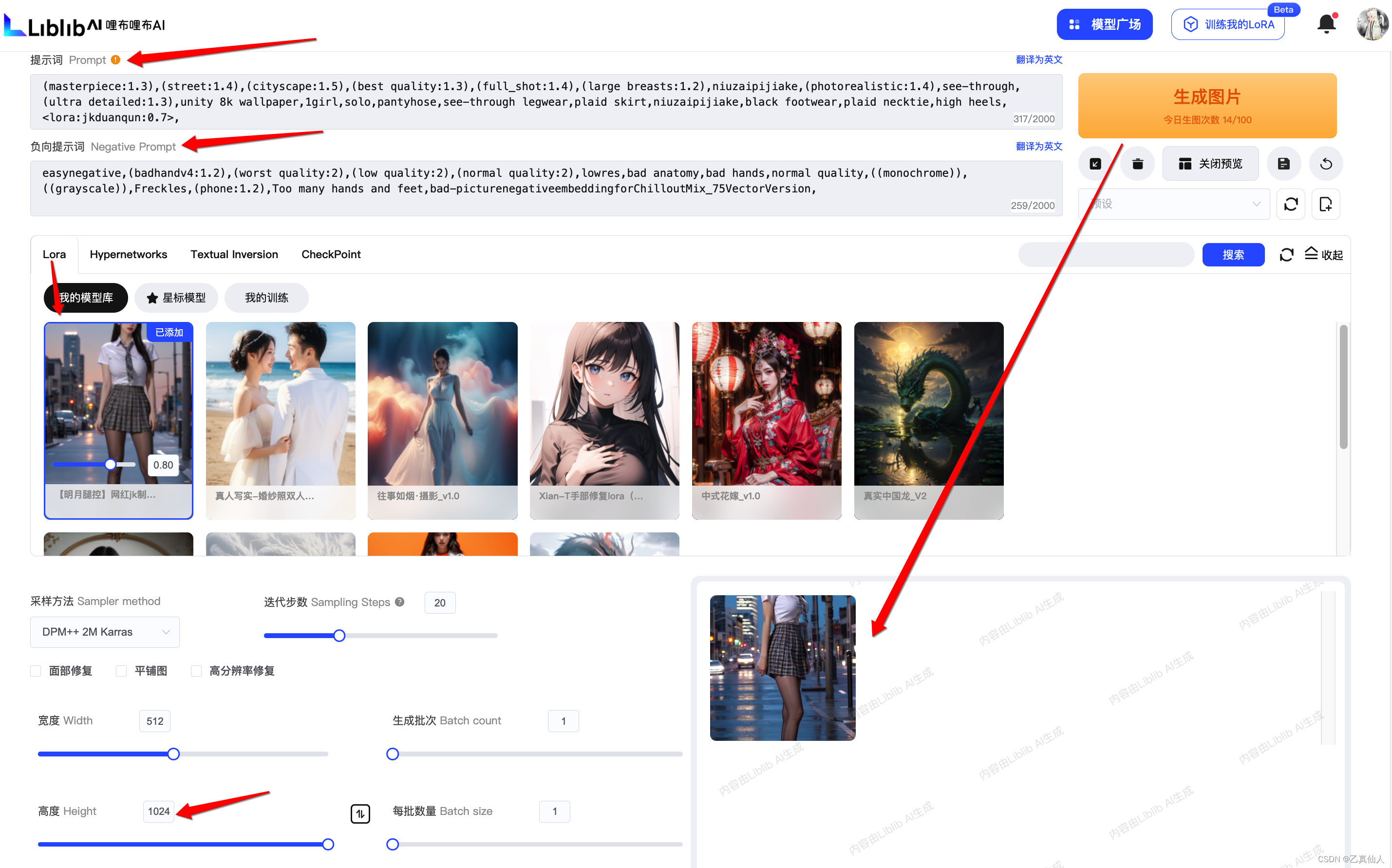
点击【加入模型库】,然后鼠标移动到模型的【生成信息】,复制其中的正向提示词、反向提示词以及采样方式到【在线生图】页面中。

在【在线生图】中,CV好【生成信息】后点击【生成图片】。
如果发现脸变形有崩掉的情况,则需要调大生成图片的的宽度和高度。因为每张图片都有尺寸大小,尺寸不够且需要的元素太多就容易挤在一起导致图片崩坏。
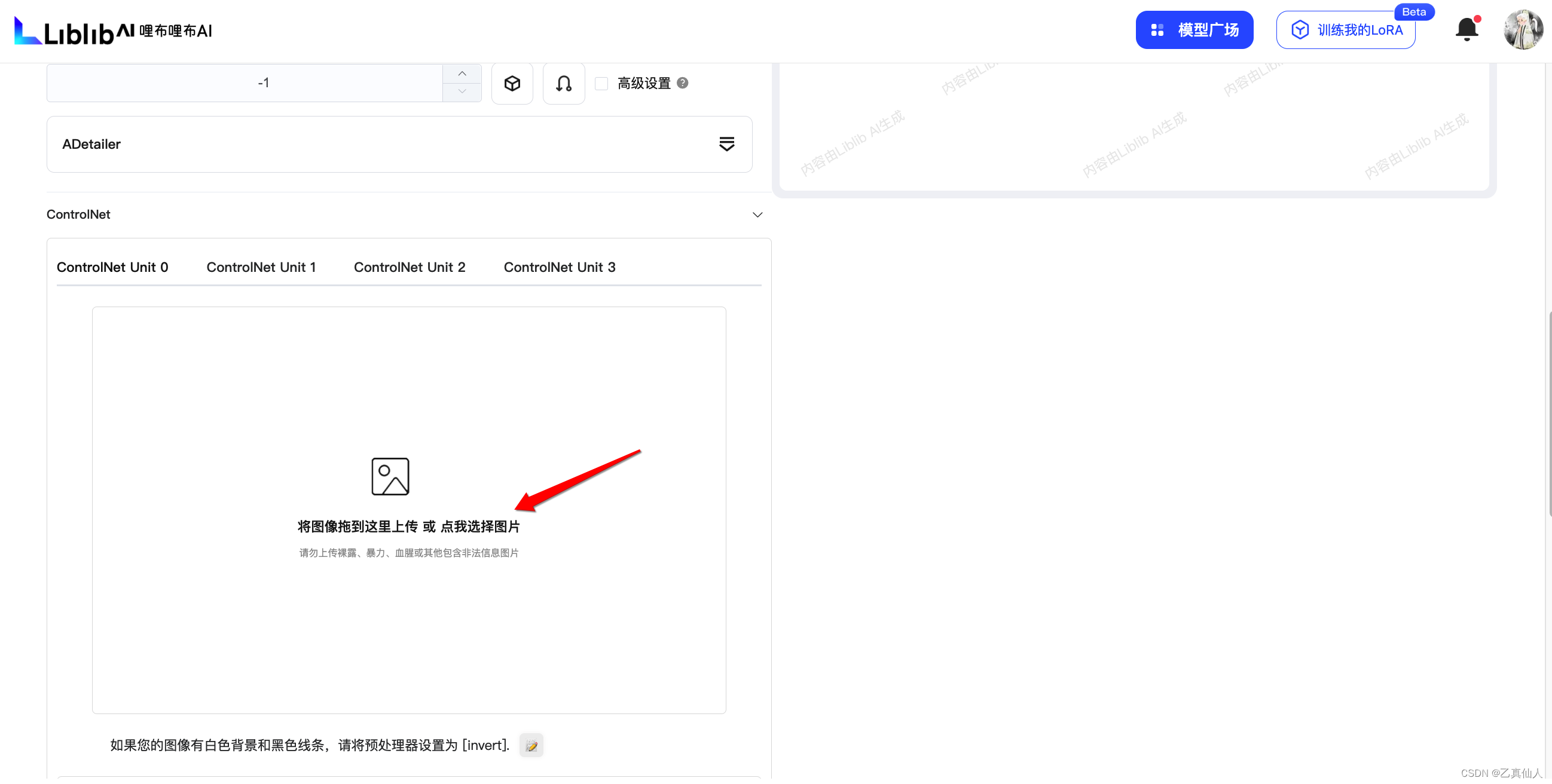
3.3 ControlNet
ControlNet是一种神经网络概念,就是通过额外的输入来控制预训练的大模型。SD中的ControlNet插件可以通过模型精准的控制图像生成,比如:上传线稿让AI控制人物的动作姿态、边缘检测、柔和边缘和涂鸦乱画等等。
如下是一个涂鸦乱画的示例(首先需要上传一张ControlNet参考图):
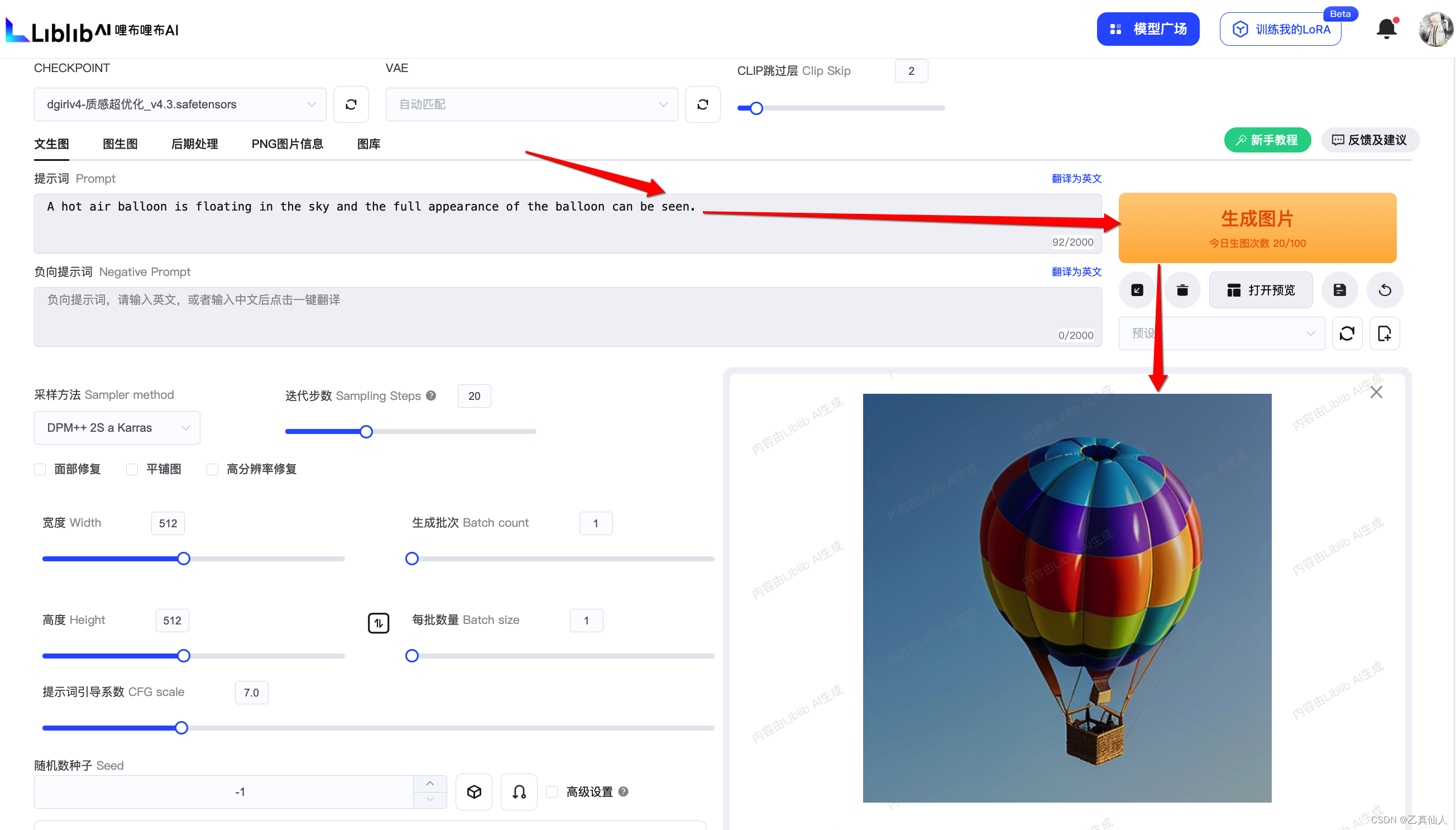
上传后选择 Scribble 的Control Type,然后点击爆炸图标。
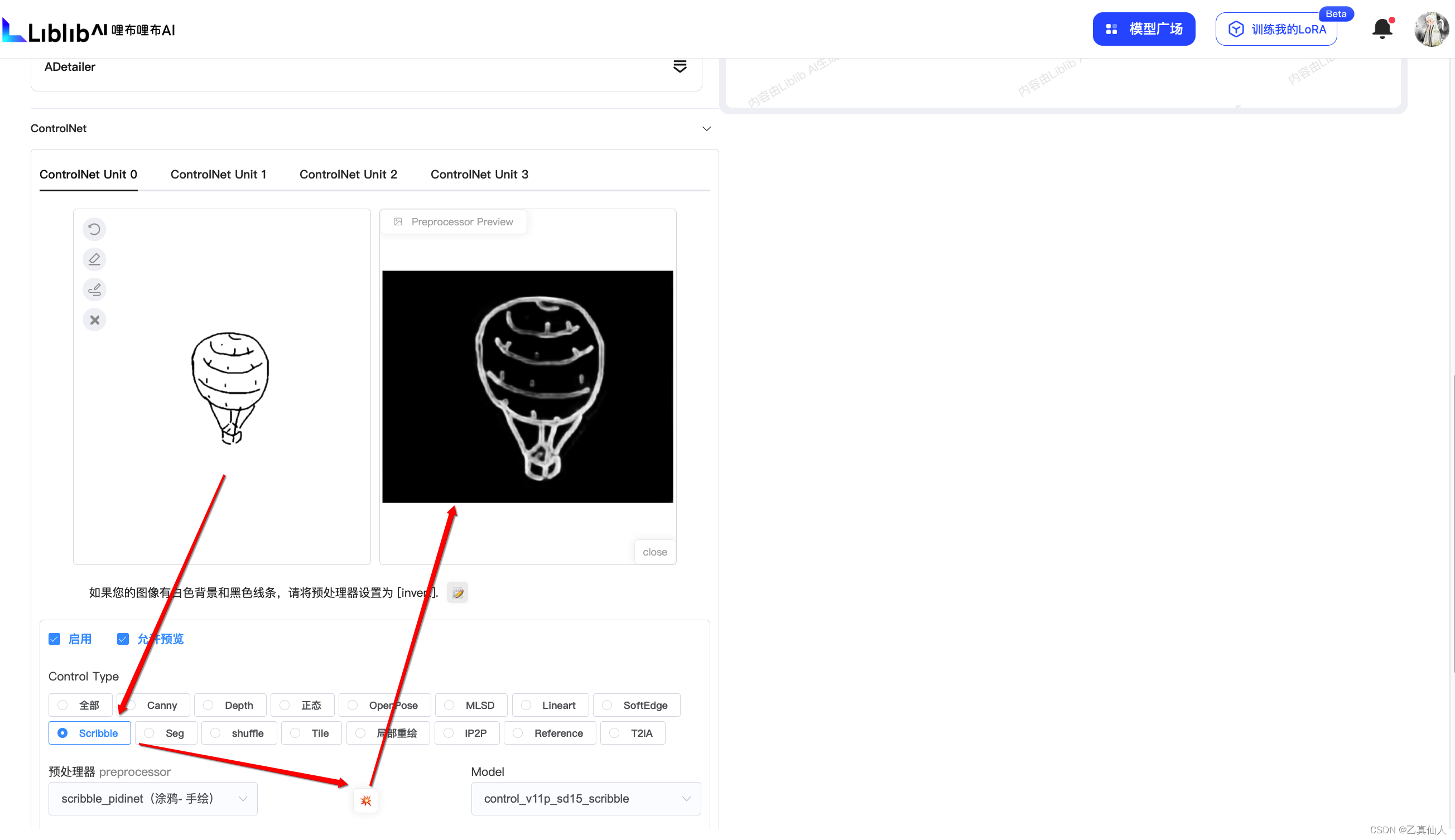
填入提示词(想象力):[A hot air balloon is floating in the sky and the full appearance of the balloon can be seen. ],然后点击【生成图片】
四、总结
至此,超强满血不收费的AI绘图教程来了(在线Stable Diffusion一键即用)介绍完成,后续会陆续输出更多AI绘图相关的篇章;查阅过程中若遇到问题欢迎留言或私信交流。


