
- 1【ITRA】 2020 ITRA个人注册 ITRA认领成绩流程_itra官网中国
- 2在内网使用公网域名访问内网群晖NAS网站_局域网内实现域名访问
- 3cdn引入前端插件_antd cdn
- 4华为云幻兽帕鲁服务器搭建教程(Windows平台)_windows2012server 幻兽帕鲁
- 5(附源码)django库存管理系统 毕业设计19144
- 6【数值计算方法(黄明游)】解线性代数方程组的迭代法(一):向量、矩阵范数与谱半径【理论到程序】
- 7自动安装系统-桌面_mdt自动化装机系统
- 8windows计算机遇到错误,Windows 10/8/7重置电脑出错,计算机意外的重新启动或遇到错误...
- 9SMTP地址如何获得?SMTP服务器地址是什么?
- 10Linux-压缩命令_linux 压缩命令
python从入门到高阶(基于黑马程序员python教程)_黑马程序员python学习路线
赞
踩
文章目录
- 0、文章来源
- 1、“学it就来%s%s员”% (name,“程序员”)
- 2、%s:占位字符串、%d:占位整型、%f:占位浮点型
- 3、字符串格式化的精度控制
- 4、字符串格式化的快速写法
- 5、对表达式进行格式化
- 6、 input用法
- 7、使用布尔类型表示真和假(比较运算符就不学了)
- 8、将输入input的输入直接放进判断语句里面,节省用户输入次数(这是个很好的想法,而且代码不用设置多余变量)
- 9、在print中使用end = ‘’使得多个输出之间不换行输出,最后一个print内可以不使用end = ‘’
- 10、使用制表符进行对齐
- 11、使用以上知识,运用while循环打印99乘法表(最后一行的print用于换行,挺重要的)
- 12、当for循环时,想用最后一个临时变量时,可以先在for循环外先定义一个i的值,这个值不在for循环里面,当for循环完可以使用
- 13、python使用continue和break来控制临时跳过和直接退出
- 14、函数定义:是组织好的、可重复使用的、用来实现特定功能的代码段
- 15、形参、实参
- 16、如果函数没有使用return语句返回数据,那么函数有返回值吗?
- 17、None的使用场景
- 18、局部变量和全局变量
- 19、数据容器根据特点的不同,如:
- 20、方法
- 21、列表的操作方法
- 22、元组
- 23、元组的列表元素可以修改
- 24、字符串
- 25、序列操作--切片
- 26、集合
- 27、集合的操作
- 28、字典
- 29、数据容器分类
- 30、数据容器的通用操作
- 31、字符串如何比较大小?
- 32、函数的多返回值
- 33、函数的多种传参方式
- 34、匿名函数
- 35、文件的操作
- 第九章
- 36、异常
- 37、异常的捕获方法
- 38、异常综合案例
- 39、异常的传递
- 40、Python模块
- 41、Python包
- 42、练习案例:自定义工具包
- 43、类
- 44、类的成员方法
- 45、类和对象
- 46、构造方法(使用构造方法对成员变量进行赋值)
- 47、魔术方法(掌握几种常见的类内置方法)
- 48、封装
- 49、继承
- 50、类型注解
- 51、多态
- 52、综合案例(暂时不学)
- ---------------------------------------------------------以下是Python高级编程----------------------------------------------
- 53、闭包
- 54、装饰器
- 55、设计模式
- 56、多线程
- 57、网络编程
- 58、正则表达式
- 59、递归
0、文章来源
在B站:黑马程序员python教程 课程学习产生了这篇文章,同学们可以把视频和文章放在一起学习哈
1、“学it就来%s%s员”% (name,“程序员”)
2、%s:占位字符串、%d:占位整型、%f:占位浮点型
3、字符串格式化的精度控制
“%5d”表示整型的宽度是5
“%7.2f”表示浮点数的宽度为7,保留2位小数,其中小数点也占一个宽度
4、字符串格式化的快速写法
先定义变量name和salary,然后快速定义字符串的格式化
f“{name}程序员年入{salary}”
- 1
这种快速格式化的方法:没有对数据类型进行要求,而且对数据的精度也没有进行控制
5、对表达式进行格式化
表达式:一条具有明确执行结果的代码语句
f"{表达式}"
“%s%d%f”%(表达式,表达式,表达式)
print("1*1的结果是:%d"%(1*1))
print(f"1*1的结果是:{1*2}")
print("字符串在python中的类型名是:%s"%type("某个字符串"))
- 1
- 2
- 3
6、 input用法
user_name = input("请输入用户名:")
user_type = input("请输入您的身份:")
print("您好:%s,您是尊贵的:%s 用户,欢迎您的光临。" \
% (user_name,user_type))
- 1
- 2
- 3
- 4
7、使用布尔类型表示真和假(比较运算符就不学了)
在本质上True是一个数字记作1,False记作0
回忆一下字符串里对的f格式表示
print(f"10>=100的比较结果:{10>=100}")
- 1
8、将输入input的输入直接放进判断语句里面,节省用户输入次数(这是个很好的想法,而且代码不用设置多余变量)
num = 10
if int(input("请猜一下我心中的数字:")) == num:
print("恭喜你猜对了")
elif int(input("猜错了,再猜一遍:")) == num:
print("恭喜你猜对了")
elif int(input("还不对,最后一次机会:")) == num:
print("恭喜你猜对了")
else:
print("抱歉,没有机会了")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
9、在print中使用end = ‘’使得多个输出之间不换行输出,最后一个print内可以不使用end = ‘’
# # 两个print输出内容之间没有换行符
print('---',end = '')
# # print('===',end = '')
print('===')
- 1
- 2
- 3
- 4
输出:
---===
- 1
10、使用制表符进行对齐
# # 使用制表符进行对齐
# print('hello\tworld')
# print('heimait\tbest')
- 1
- 2
- 3
输出:
hello world
heimait best
- 1
- 2
11、使用以上知识,运用while循环打印99乘法表(最后一行的print用于换行,挺重要的)
i = 1
while i < 10:
j = 1
while j <= i:
print(f'{j}*{i}={j*i}\t',end = '')
j = j + 1
i = i + 1
print()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出:
1*1=1
1*2=2 2*2=4
1*3=3 2*3=6 3*3=9
1*4=4 2*4=8 3*4=12 4*4=16
1*5=5 2*5=10 3*5=15 4*5=20 5*5=25
1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36
1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49
1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64
1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
12、当for循环时,想用最后一个临时变量时,可以先在for循环外先定义一个i的值,这个值不在for循环里面,当for循环完可以使用
i = 0
for i in range(1,100):
print(i)
print(i)
# 输出值为100
- 1
- 2
- 3
- 4
- 5
13、python使用continue和break来控制临时跳过和直接退出
continue:直接跳出本次循环,直接进入下一次循环
break:直接斩断该循环,退出的是离break最近的那个for循环或者while循环
for i in range(4):
print("嘿嘿")
continue # 直接跳出本次循环
print("哈哈哈")# 这行代码不会执行
输出:
嘿嘿
嘿嘿
嘿嘿
嘿嘿
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
for j in range(2):
for i in range(4):
print("嘿嘿")
break
print("哈哈哈")
输出:
嘿嘿
嘿嘿
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
14、函数定义:是组织好的、可重复使用的、用来实现特定功能的代码段
为什么要使用函数?
答:为了得到一个针对特定需求、可重复利用的代码段,提高程序的复用性、减少重复性代码、提高开发效率。
15、形参、实参
形参(形式参数):在函数定义中声明要提供的参数
实参(实际参数):在函数调用和执行的时候,函数真正使用的的值
16、如果函数没有使用return语句返回数据,那么函数有返回值吗?
答:有!
python中有一个特殊的字面量:None,其类型是<class ‘NoneType’>
无返回值的函数,实际上就是返回了:None这个字面量
None表示:空的、无实际意义的意思,函数返回的None就表示这个函数没有返回什么有意义的内容,也就是返回了空的意思
17、None的使用场景
17.1 用于函数无返回值
17.2 在if判断中,None等同于False,一般用于在函数中主动返回None,配合if判断做相关处理
17.3 用于声明无内容的变量上,定义变量,但暂时不需要变量有具体值,可以使用None来代替
18、局部变量和全局变量
变量作用域指的是变量的作用范围(变量在哪里可用,在哪里不可用)
局部变量: 定义在函数体内部的变量,即只在函数体内部生效。
全局变量: 在函数体内外都能生效的变量
局部变量的作用: 在函数体内部,临时保存数据,即当函数调用完成以后,则销毁局部变量。
关键字:global: global是设置在函数体内的关键字,位于要设置为全局变量的上方,该关键字可将下方的变量定义为全局变量,即修改了函数体外部同一变量的值。
hei = 9
def funa():
global hei
hei = 10
print(hei)
funa()
hei = 0
print(hei)
输出:
10
0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
19、数据容器根据特点的不同,如:
是否支持重复元素
是否可以修改
是否有序,等
分为5类,分别是:列表、元组、字符串、集合、字典
20、方法
如果将函数定义为类的成员,那么函数将被称为 方法
函数是单独存在的,方法是存在于类中的
21、列表的操作方法
21.1 查询元素下标:list.index(元素)
21.2 修改特定位置的元素值 list[下标]=新值
21.3 插入元素(在指定的下标位置插入指定的元素) list.insert(下标,值)
21.4 追加元素(将指定元素追加到列表的尾部) list.append(元素)
21.5 在列表尾部追加一批数据 list.extend(新的数据容器)
21.6 第一种删除元素 del list[下标]
21.7 第二种删除元素方法 list.pop(下标)
21.8 第三种删除元素方法 list.remove(待移除元素)
21.9 清空列表全部元素 list.clear()
21.10 统计列表中特定元素的个数 list.count(特定元素)
21.22 统计列表中所有元素的个数 len(list) len不是列表的方法
22、元组
为什么需要有元组:列表是可以修改的,如果想要传递的信息不被篡改,列表就不合适了,元组与列表最大不同在于元组一旦定义完成,就不可以被修改。如果当我们需要在程序内部封装数据,又不希望封装的数据被篡改,那么元组就是非常合适的数据结构。
定义一个空元组
a = ()
b = tuple()#定义了一个类对象
- 1
- 2
如果定义了一个只含有一个元素的元组,这个元素后面要加上逗号,不然不加的话数据类型是字符串
元组学习三个方法:索引、计数、统计元组长度(不可修改即增加或删除元素)
索引:tuple.index()
计数:tuple.count(待统计的元素)
统计元组长度:len(tuple)
23、元组的列表元素可以修改
eg:
t = (1,2,3,['nlp','cv','php'])
print(t)
t[-1][2]='ML'
print(t)
- 1
- 2
- 3
- 4
- 5
输出:
(1, 2, 3, ['nlp', 'cv', 'php'])
(1, 2, 3, ['nlp', 'cv', 'ML'])
- 1
- 2
24、字符串
无法修改、移除指定下标的字符,无法追加字符
不然得话就会得到一个新的字符串
索引值:str.index(字符)
替换:str.replace(被替换的字符1,替换的字符2)
分割:str('分割符')
规整:str.strip()、去掉前后指定的字符串:str.strip(‘1234’),字符串的前后只要出现1234中的任何一个数字都会被去除
计数:str.count()
a = '123asdafsa3'
b = a.strip('123')
print(b)
- 1
- 2
- 3
输出:asdafsa
25、序列操作–切片
切片操作不会影响序列本身,而是会得到一个新的序列,因为元组和字符串是不支持修改的
从前到后步长为2 :list[::2]
从前到后步长为-1:list[::-1]
26、集合
不支持元素的重复,但是可以定义一个带有重复元素的集合,在使用的时候集合会自动去重,并且不保证元素的有序性,所以集合不支持下标索引进行访问,但是集合和列表一样是支持修改的
集合:{}
定义空集合:my_set = set()
27、集合的操作
添加元素:set.add("元素")
移除元素:set.remove("待移除元素")
随机取出一个元素:slement = set.pop()
清空集合:set.clear()
取两个集合(set1和set2)的差集(返回一个集合)(set1差set2)(原集合元素不变):set1.difference(set2)
消除两个集合的差集(set1中删除set1和set2的差集)(set1会变化,set2不会变化):set1.difference_update(set2)
合集:set3 = set1.union(set2)
统计集合元素个数:len(set)
集合的遍历:集合不支持下标索引,所以不能使用while循环,可以使用for循环
28、字典
为什么使用字典:因为字典可以提供基于key检索value的场景实现
定义一个空的字典:{}或字典=dict()
字典中的key是不能重复存在的
字典的key和value可以是任意数据类型,key不可以为字典
删除元素:dict.pop(待删除key)
删除的元素的值:score = dict.pop(待删除key)
清空元素(清楚字典中的所有键值对):dict.clear()
遍历字典所有的字典元素:
1、拿到全部的key值:keys = dict.keys()
然后for循环
2、for key in dict:
字典也不支持while循环
统计字典的键值对数量:len(dict)
29、数据容器分类

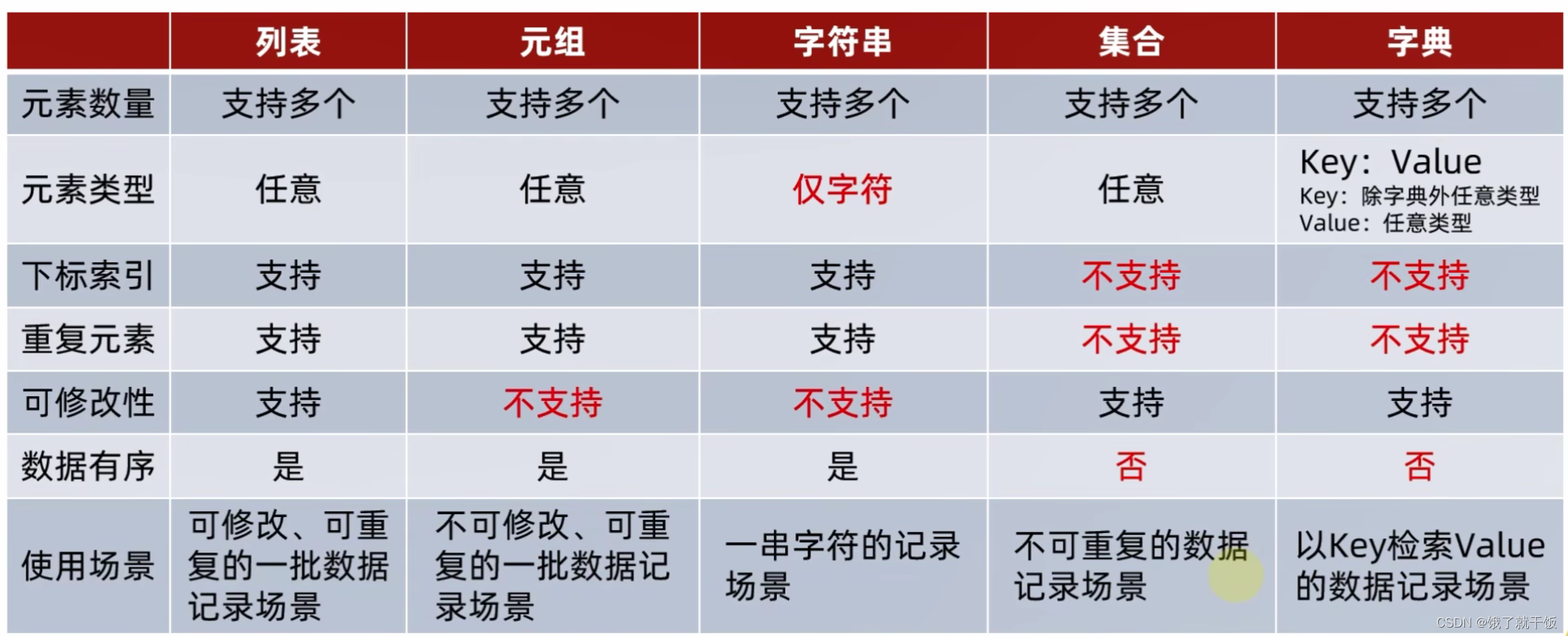
30、数据容器的通用操作
len(容器):计算容器长度
max(容器):计算容器的最大值
min(容器):计算容器的最小值
Alt+Shift+鼠标拖动:可以在pycharm中实现批量修改代码
list(容器):字典和字符串转列表:字符串每个字符是一个元素,字典的每个key是一个元素
str(容器):每种容器都是字符串
tuple(容器):字典和字符串转元组:字符串每个字符是一个元素,字典的每个key是一个元素
dict(容器)
set(容器):元组和列表对应的圆括号和方括号都转为大括号,字符串每个字符是一个元素(元素会无序),字典的每个key是一个元素(元素会无序)
排序功能:sorted(容器,[reverse=True]) sorted函数就是将内容排序完之后将元素放在列表之中
注意:字符串、列表、元组、集合、字典排序的结果都是列表对象
31、字符串如何比较大小?
ASCII表
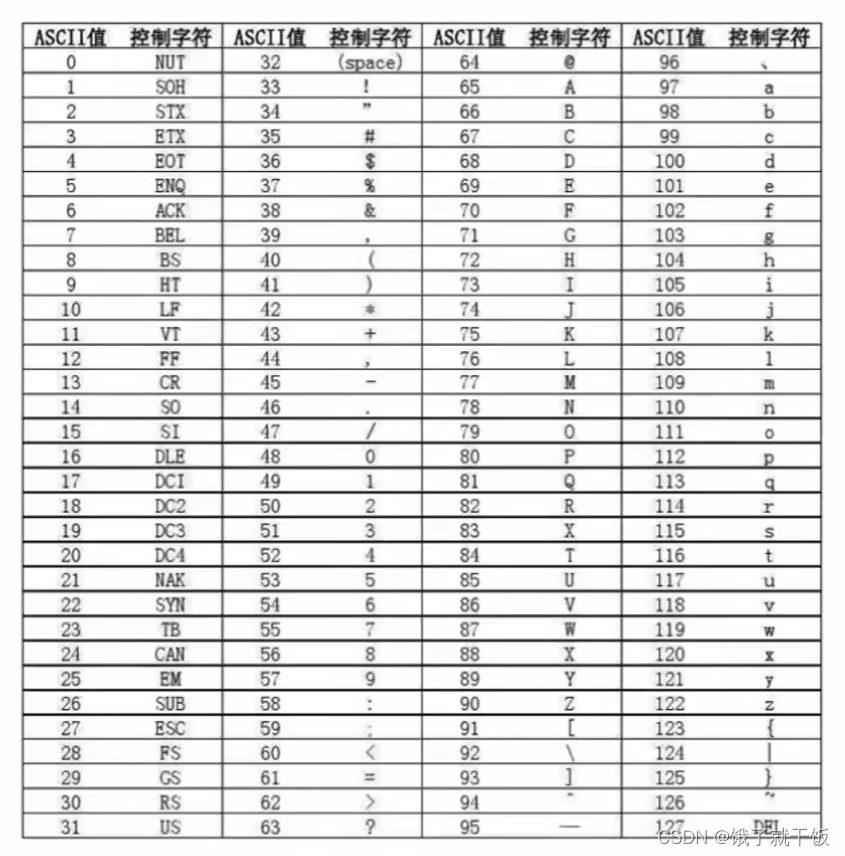

eg:“ab”>“a”(长比短的牛逼),“a”>“A”
32、函数的多返回值
def func():
return 返回值1,返回值2,返回值3
- 1
- 2
定义多个变量接收多个返回值:
x,y,z = func()
- 1
33、函数的多种传参方式
函数常见的参数使用方式:
33.1 位置参数
调用函数的时候根据函数定义的参数位置来传递参数
传递的参数和定义的参数的顺序及个数必须一致
def user_info(age,name,gender):
return age,name,gender
age,name,gender = user_info(28,"Tom","女")
- 1
- 2
- 3
33.2 关键字参数
函数在调用是通过使用键=值的形式来传递参数
作用是可以使函数更加清晰、容易使用,同时也清除了参数的顺序需求
如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存才先后顺序
def user_info(age,name,gender):
return age,name,gender
age,name,gender = user_info(age = 28,name = "Tom",gender = "女")# 顺序无所谓
age,name,gender = user_info(28,name = "Tom",gender = "女")
- 1
- 2
- 3
- 4
33.3 不定长参数
不定长参数也叫可变参数,用于不确定调用的时候会传递多少个参数(不传参也可以)的场景
作用:当调用函数时不确定参数个数时,可以使用不定长参数
不定长参数的类型:
1、位置传递、2关键字传递
33.3.1 位置传递
传进的所有参数都会被args变量收集,他会根据传进参数的位置合并为一个元组,args是元组类型
eg:
def user_info(*args):
print(args)
user_info('Tom')
user_info('Tom',2,3,4)
- 1
- 2
- 3
- 4
- 5
输出:
('Tom',)
('Tom', 2, 3, 4)
- 1
- 2
33.3.2 关键字参数
参数时键=值形式的情况下,所有的键=值都会白kwargs接受,同时会被键=值组成字典
eg:
def user_info(**kwargs):
print(kwargs)
user_info(Tom='婷婷',gender='女')
- 1
- 2
- 3
- 4
输出:
{'Tom': '婷婷', 'gender': '女'}
- 1
33.4 缺省参数
缺省参数也叫默认参数,为参数提供默认值,调用函数时可以不传该默认参数的值,注意:所有位置参数必须出现在默认参数前,包括函数定义和调用。
def user_info(age,name,gender = "男"):
return age,name,gender
age,name,gender = user_info(age = 28,name = "Tom")
age,name,gender = user_info(28,name = "Tom",gender = "女")
- 1
- 2
- 3
- 4
输出:
28 Tom 男
28 Tom 女
- 1
- 2
33.5 函数的多种传参方式总结

34、匿名函数
定义函数:
def定义带有名称函数,lamda 定义无名称的函数
有名称函数可以基于名称重复使用。
无名称的匿名函数只可临时使用一次
34.1 函数作为参数传递
以前学习的函数都是以数据为参数,现在函数的参数是函数名,传递的是执行逻辑。函数本身可以作为参数,传入另一个函数中进行使用,将函数传入的作用在于:传入计算逻辑,而非传入数据。
def func(add):
return add(1,2)
def add(x,y):
return x+y
print(func(add))
- 1
- 2
- 3
- 4
- 5
输出:3
34.2 lamda匿名函数
语法:lamda 传入参数:函数体(一行代码)(适用于只用一次的场景)
eg:
def test_func(add):
return add(1,2,3)
print(test_func(lambda x,y,z:x+y**z))
- 1
- 2
- 3
- 4
输出:9
35、文件的操作
35.1 文件的编码
思考:计算机只能识别0和1,那么丰富的文本文件是如何被计算机识别,并存储在硬盘中呢?
答案:使用编码技术(密码本)将内容翻译成0和1存入
编码技术即:翻译的规则,记录了如何将内容翻译为二进制,以及如何将二进制翻译回可识别内容
计算机中有许多可用编码:UTF-8、GBK、Big5等
UTF-8是全球通用的编码格式
35.2 文件的读取操作
打开、读取、关闭
打开:open(name,mode,encoding),mode是访问模式:只读、写入、追加
读取:read():read中的数字表示读取的字符个数,并且在读同一个文件时,上面读过之后,下面再读会从上次结束的地方继续读取接下来的内容
readlines():每一行数据作为一个元素
readline():一次只读一行内容
关闭:f.close()
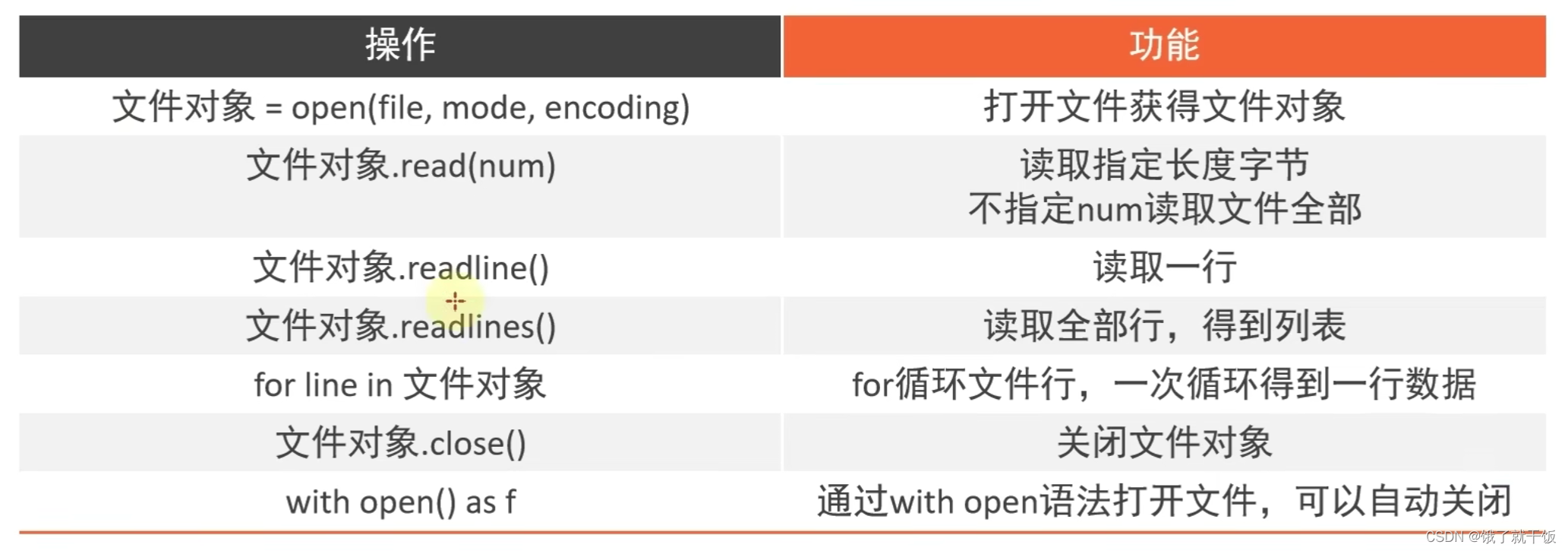
统计长字符串中出现某字符串的次数:str.count(str)
35.3文件的写入:w
文件存在则创建
文件不存在则清空文件的内容

刷新内容:f.flush(),即刷新内容到硬盘中
f.flush()和f.close()只要有一个都会执行写入的操作
35.4 文件的追加操作:a
文件存在则在原有内容之后继续写入
文件不存在则清空文件的内容
f.open("1.txt",a) # 打开文件 通过a模式打开
f.write("hello world")# 文件写入
f.flush()# 内容刷新
- 1
- 2
- 3
第九章
36、异常
当程序检测到一个错误时,python解释器就无法继续执行了,出现了一些错误的提示,这就是异常,也就是BUG
37、异常的捕获方法

38、异常综合案例
语法:
try:
可能发生错误的代码
expect:
如果出现异常执行的代码
- 1
- 2
- 3
- 4
38.1 捕获指定的一个异常
try:
print(a)
expect NameError as e:
print("出现了变量命名的异常")
print(e) # 打印代码错误的具体信息
- 1
- 2
- 3
- 4
- 5
38.2 捕获多个异常
try:
print(a)
expect (NameError,ZeroDivisionError) as e:
print("出现了变量未定义或者除以0的异常")
print(e) # 打印代码错误的具体信息
- 1
- 2
- 3
- 4
- 5
38.3 捕获全部的异常(顶级的捕获异常)
try:
print(a)
expect Exception as e:
print("出现异常了")
print(e) # 打印代码错误的具体信息
- 1
- 2
- 3
- 4
- 5
38.4 else(可以写也可以不写)
else处理:如果没有捕获到异常,执行else语句。
try:
print(1)
except Exception as e:
print(e)
else:
print("嘿嘿")
- 1
- 2
- 3
- 4
- 5
- 6
38.5 finally(可以写也可以不写)
try:
print(1)
except Exception as e:
print(e)
else:
print("嘿嘿")
finally:
print("我是finally,不管是否捕获到异常,最后都会执行的")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
39、异常的传递
def func1():
num = 1 / 0
def func2():
func1()
def main():
try:
func2()
except Exception as e:
print(e)
main()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
40、Python模块

40.1 导入模块
语法:[from 模块名] import [模块 | 类 | 变量 | 函数 | *] [as 别名]
import 模块:import time
from 模块名 import 具体功能名:from time import sleep
from 模块名 import * :from time import * 通过time.就可以使用
40.2 自定义模块
如果导入了两个模块中的两个相同的模块名,那么在使用这个同名功能,那么会覆盖前面一个功能
eg:
from a import c
from b import c
c# 执行的是b.c
- 1
- 2
- 3
40.3 __main__变量
在包里面如果没有
if __name__ == "__main__":
- 1
而只有
执行包中函数
- 1
则在调用这个包的时候就会直接执行这个函数,会让人很懵逼,但是一般py文件都需要有测试实例,所以就发明了以下代码:
if __name__ == "__main__":
执行包中函数
- 1
- 2
这样就可以在调用这个包的时候不执行执行包中函数,而只是使用包的方法,在单独查看包的代码时可以执行以上代码以完成实例的测试
if __name__ == "__main__":表示只有当程序是直接执行的时候才会进入if内部,如果是被导入的,则if无法进入
40.4 __all__变量
如果包中定义了方法1、方法2、方法3、方法4,在包中如果添加了以下代码
# 这行代码一般写在包的第一行
__all__ = ["方法1","方法2","方法3"]
- 1
- 2
那么在调用包时使用
from 包 import *
- 1
将只调用all变量指定的那几个方法
如果手动调用不存在__all__的方法时是可以使用的,如:
from 包 import 功能
- 1
41、Python包
python包从物理上来看是一个文件夹,在该文件夹下包含了一个__init__.py文件,该文件夹可用于包含多个模块文件。python模块从逻辑上来看是一个py文件
一个包包含多个模块文件和一个__init__.py的文件
如果一个文件夹内存在一个__init__.py的文件则这个文件夹就是python包,没有的话就只是文件夹
包的作用:当模块文件越来越多时,包可以帮助管理这些模块,包的作用就是包含多个模块,但包的本质依然是模块
41.1 自定义包
新建package文件夹
文件夹内新建包的py文件
文件夹内新建__init__.py文件
41.2 安装第三方Python包
pycharm中安装 options中加入镜像链接
42、练习案例:自定义工具包

str_util.py文件:
def str_reverse(s):
return s[::-1]
def substr(s, x, y):
return s[x:y]
- 1
- 2
- 3
- 4
- 5
file_util.py文件:
def print_file_info(file_name):
f = None
try:
f = open(file_name, 'r', encoding="utf-8")
print(f.read())
except Exception as e:
print(f"捕获的异常信息:{e}")
finally:
if f: #这一行牛逼Plus
f.close()
def append_to_file(file_name, data):
with open(file_name, 'a', encoding='utf-8') as f:
f.write(data)
if __name__ == '__main__':
print_file_info(r"C:\Users\29617\Desktop\人员招聘.txt")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
测试文件:
hhhhhhhhhhhhhhhhhhhhhhhhhhhhhh
进程已结束,退出代码为 0
- 1
- 2
43、类
43.1 设计类(设计表格)
class Student:
name = None
gender = None
nationality = None
native_place = None #籍贯
age = None
- 1
- 2
- 3
- 4
- 5
- 6
43.2 创建对象(打印表格)
stu1 = Student()
- 1
43.3 对象属性赋值(填写表格)
stu1.name = "林俊杰"
stu1.gender = "男"
stu1.nationality = "中国"
stu1.native_place = "山东省"
stu1.age = 64
- 1
- 2
- 3
- 4
- 5
43.4 查看属性值
print(stu1.age)
print(stu1.name)
print(stu1.nationality)
print(stu1.native_place)
print(stu1.gender)
- 1
- 2
- 3
- 4
- 5
44、类的成员方法
44.1 类的定义和使用语法
class 类名称:
类属性(定义在类中变量即成员变量)
类行为(定义在类中函数即成员方法)
- 1
- 2
- 3
创建类对象的语法
对象 = 类名称()
- 1
即类中只包含两种类型的数据:属性(数据)和行为(函数)
44.2 使用成员方法
class Student:
name = None
gender = None
nationality = None
native_place = None #籍贯
age = None
def say_hi(self):# 在调用的时候需要传参
print(f"hello 我是{self.name}")
def say_hi2(self,xingcan1):#在成员方法中可以不传入参数,在调用的时候也无需传参
print(f"hello 我是{xingcan1}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
成员方法的定义方法:
def 方法名(self,形参1,形参2,...,形参N):
方法体
- 1
- 2
44.3 关键字self的作用(理解)
1.self关键字是成员方法定义的时候必须填写的
2.self表示类对象自身的意思
3.在使用类的方法时,self不用管,只传递形参对应的值即可(self是透明的)
4.在方法内部想要访问类的成员变量时,必须通过self访问
5.在类的方法中调用类的属性值时,使用self.属性,也必须带上self,也正是因为这个必须,所以在该方法中不需要传入类的成员变量,self就代表了类自身,当然也代表了类的属性,所以在定义类的时候只需要填写self即可,其他形参是和属性分开的,slef是self,形参是形参,除去self其他都是形参,形参是和属性不同的
45、类和对象
45.1 掌握使用类描述显示世界事物的思想
现实世界中的事和物都有两大特征:属性和行为
45.2 掌握类和对象的关系
类是程序中的“设计图纸”
对象是基于图纸生产的具体实体
45.3 理解什么是面向对象?
类是程序内的“设计图纸”,需要基于图纸生产实体(对象),才能工作,这种套路,称为面向对象编程
面向对象的核心:设计类、基于类创建对象、由对象做具体的工作,一句话总结:让对象干活
46、构造方法(使用构造方法对成员变量进行赋值)
class Student:
name = None
gender = None
nationality = None
native_place = None #籍贯
age = None
stu1 = Student()
stu1.name = "林俊杰"
stu1.gender = "男"
stu1.nationality = "中国"
stu1.native_place = "山东省"
stu1.age = 18
stu2 = Student()
stu2.name = "刘次新"
stu2.gender = "男"
stu2.nationality = "中国"
stu2.native_place = "甘肃省省"
stu2.age = 64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
以上给成员变量的方法比较繁琐,以下使用简单代码进行代替:
一个想法就是:在构建类对象的时候将参数传递给方法,这个想法可以使用构造方法即__init__()来完成
46.1 构造方法介绍
__init__()称为构造方法,这个方法可以实现以下功能:
1.在创建类对象(构造类)的时候,会自动执行即在未调用的时候也会直接执行(这一句其实我不太懂,但是只要理解了了下面的第二条就已经能理解类的构造原理了,先搁这)
2.在创建类对象(构造类)的时候,将传入参数自动传递给__init__方法使用
看以下代码:
class Student:
name = None
gender = None
nationality = None
native_place = None #籍贯
age = None
def __init__(self, name, gender, age):
self.name = name
self.gender = gender
self.age = age
print("Student类创建了一个新的对象")
student = Student("小张","女","保密")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
执行输出:
Student类创建了一个新的对象
- 1
在以上这段代码中在创建一个学生对象的时候,构造方法是直接运行的,init__就直接运行了,student = Student(“小张”,“女”,“保密”)就直接将参数值直接传给__init,这些参数在__init__方法中通过给self.属性=参数值赋值给了成员变量,此时更新了以上的None值,因此以上这些给成员变量赋初值为None值的代码就显得多余了,因此可以将代码直接简化为以下形式:
class Student:
def __init__(self, name, gender, age):
self.name = name # 这里可以理解为既是定义成员变量(有这个变量)又是给成员变量赋值
self.gender = gender
self.age = age
print("Student类创建了一个新的对象")
student = Student("小张","女","保密")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
注意:在构造方法中因为
47、魔术方法(掌握几种常见的类内置方法)
47.1 __str__
看以下代码:
class Student:
def __init__(self, name, gender, age):
self.name = name
self.gender = gender
self.age = age
student = Student("小张","女","保密")
print(student)
print(str(student))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出:
<__main__.Student object at 0x0000023CB1322FD0>
<__main__.Student object at 0x0000023CB1322FD0>
- 1
- 2
输出内容是类对象所在的内存地址,没多大用处
更改代码(添加魔法函数):
class Student:
def __init__(self, name, gender, age):
self.name = name
self.gender = gender
self.age = age
def __str__(self):
return f"学生信息:性别:{self.name},性别:{self.gender},年龄:{self.age}"
student = Student("小张","女","保密")
print(student)
print(str(student))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
输出:
学生信息:性别:小张,性别:女,年龄:保密
学生信息:性别:小张,性别:女,年龄:保密
- 1
- 2
47.2 __lt__
看以下代码:
class Student:
def __init__(self, name, gender, age):
self.name = name
self.gender = gender
self.age = age
student1 = Student("小张","女","12")
student2 = Student("小张","女","25")
print(student1 < student2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输出:
Traceback (most recent call last):
File "D:/隐藏内容/隐藏内容/测试.py", line 142, in <module>
print(student1 < student2)
TypeError: '<' not supported between instances of 'Student' and 'Student'
- 1
- 2
- 3
- 4
添加__lt__魔法函数
class Student:
def __init__(self, name, gender, age):
self.name = name
self.gender = gender
self.age = age
def __lt__(self,other):
#lt只能判断小于和大于,以下一行代码可以自己任意定义
return self.age < other.age
student1 = Student("小张","女","12")
student2 = Student("小张","女","25")
print(student1 < student2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
输出:True即student1的年龄12小于student的年龄25是True
lt:less than,用于比较类对象中成员变量属性值的魔法函数
other是一个接收另外一个类对象的参数,用于和本类进行比较的
lt只能判断小于和大于
47.3 __le__
le可以判断小于等于、大于等于,唯一不同就是多了一个等于判断,代码:
def __le__(self,other):
return self.age <= other.age
- 1
- 2
47.4 __eq__
如果在类中没有使用__eq__这个魔法方法,也是可以比较两个类对象的属性值的,这时print(student1==student2)默认比较的是两个对象的内存地址,当然会判断他们不同
eq是判断类对象的属性值等不等于的
类比以上代码不同:
def __le__(self,other):
return self.age == other.age
- 1
- 2
还是看一下前后对比吧
class Student:
def __init__(self, name, gender, age):
self.name = name
self.gender = gender
self.age = age
# def __str__(self):
# return f"学生信息:性别:{self.name},性别:{self.gender},年龄:{self.age}"
# def __lt__(self,other):
# return self.age < other.age
student1 = Student("小张","女","12")
student2 = Student("小张","女","25")
print(student1 == student2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
输出:False,即使使用的年龄相同,两个独立的对象所占用的内存地址也不同,判断结果也是False
添加代码:
class Student:
def __init__(self, name, gender, age):
self.name = name
self.gender = gender
self.age = age
# def __str__(self):
# return f"学生信息:性别:{self.name},性别:{self.gender},年龄:{self.age}"
# def __lt__(self,other):
# return self.age < other.age
def __eq__(self, other):
return self.age == other.age
student1 = Student("小张","女","12")
student2 = Student("小张","女","12")
print(student1 == student2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
输出就是:True啦,修改两个对象的age属性值为不同,输出结果就为False了
48、封装
48.1 封装概念
将现实世界的事物在类中描述为属性和方法,即为封装
面向对象包含3大特性:封装、继承、多态
封装表示的是将现实世界的事物所具备的属性和行为描述为类的成员变量和成员方法, 从而完成程序对现实世界事物的描述
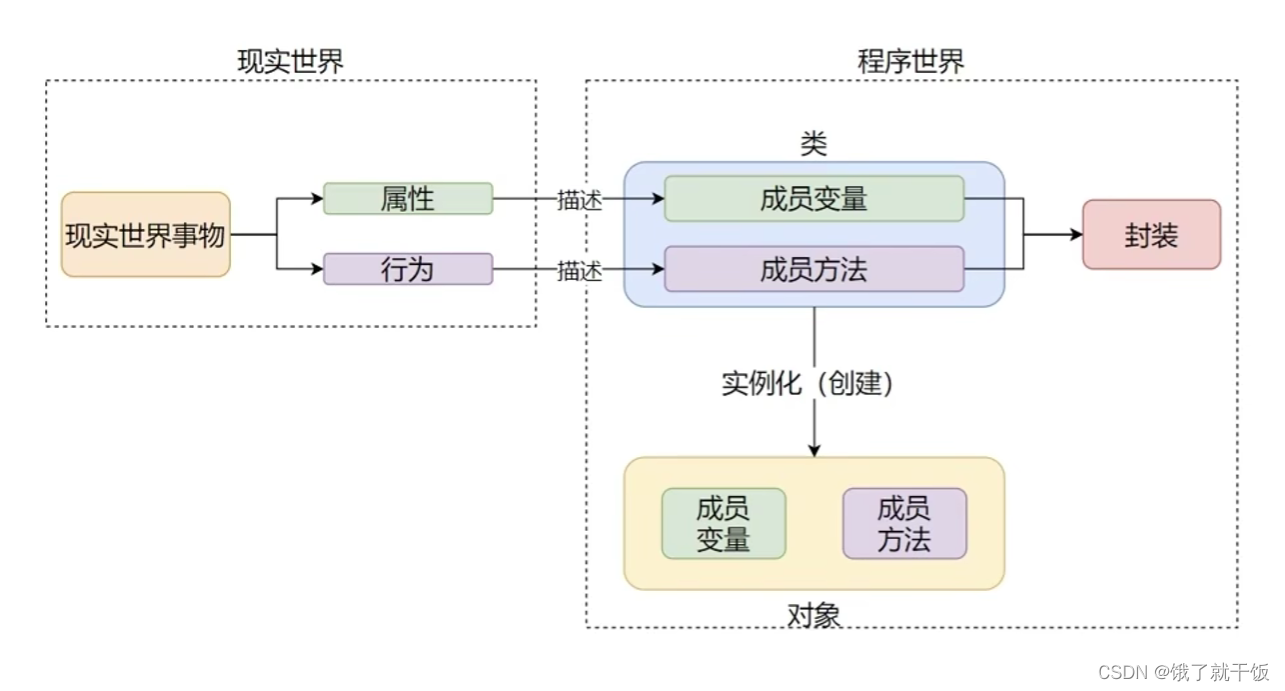
现实世界中的事物,有属性和行为,但是不代表这些属性和行为都是开发给用户使用的,有些是对用户隐藏的属性和行为
因此类也具备私有成员变量和私有成员方法
私有成员变量和私有成员方法定义:只需要变量名和方法名以__开头即可
在类之外不能调用类的私有变量和私有方法
类中其他成员是可以使用这些私有成员的
class Phone():
# 定义私有变量
__voltage = 1
# 定义私有方法
def __keep_single_core(self):
print("CPU以单核模式运行")
def call_5g(self):
if self.__voltage >= 1:
print("5g已经开启")
else:
self.__keep_single_core()
print("电量不足,开启CPU单核运行模式")
iqooNeo3 = Phone()
iqooNeo3.call_5g()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
输出:5g已经开启
class Phone():
# 定义私有变量
__voltage = 0.2
# 定义私有方法
def __keep_single_core(self):
print("CPU以单核模式运行")
def call_5g(self):
if self.__voltage >= 1:
print("5g已经开启")
else:
self.__keep_single_core()
print("电量不足,开启CPU单核运行模式")
iqooNeo3 = Phone()
iqooNeo3.call_5g()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
输出:
CPU以单核模式运行
电量不足,开启CPU单核运行模式
- 1
- 2
总结:
 私有成员有什么意义?
私有成员有什么意义?
答:在类中提供内部使用的属性和方法,而不对外使用
48.2 课后题
设计一个手机类,内部包含:
私有成员变量:__is_5g_enable,类型bool,True表示开启5g,False表示关闭5g
私有成员方法:__check_5g(),会判断私有成员__is_5g_enable的值
若为True,打印输出:5g开启
若为False,打印输出:5g关闭,使用4g网络
公开成员方法: call_by5g(),调用它会执行
调用私有成员方法: __check_5g(),判断5g网络状态
打印输出:正在通话中
运行结果:5g关闭,使用4g网络,正在通话中
通过完成这个类的设计和使用,体会封装中私有成员的作用
对用户公开的,call__by_5g()方法
对用户隐藏的,__is_5g_enable私有变量和__check_5g私有成员
48.3 课后题代码
class Phone():
__is_5g_enable = True # 选择不同的bool值进行测试
def __check_5g(self):
if self.__is_5g_enable is True:
print("5g开启")
else:
print("5g关闭,使用4g网络")
def call__by_5g(self):
self.__check_5g()
print("正在通话中")
iqooNeo3 = Phone()
iqooNeo3.call__by_5g()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
49、继承
继承分为:单继承和多继承
49.1 继承的语法
单继承:
class 类名(父类名):
类内容体
- 1
- 2
多继承:
class 类名(父类1名,父类2名,...,父类N名):
类内容体
- 1
- 2
示例:
49.2 概念
继承表示将从父类那里继承(复制)来成员变量和成员方法(不含私有)
49.3 使用方法
示例:
class Phone():
__is_5g_enable = True
def __check_5g(self):
if self.__is_5g_enable is True:
print("5g开启")
else:
print("5g关闭,使用4g网络")
def call__by_5g(self):
self.__check_5g()
print("正在通话中")
class NFCReader():
nfc_type = "第五代"
producer = "黑马"
def read_card(self):
print("NFC读卡")
def write_card(self):
print("NFC写卡")
class RemoteCotrol():
rc_type = "红外遥控"
def control(self):
print("红外遥控开启了")
class MyPhone(Phone,NFCReader,RemoteCotrol):
pass#这里不想再进一步更新这个新类的功能 就先使用pass填上
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
注意:
1.pass的作用:补充代码的作用
2.在多继承的时候,如果遇到了在父类中如果有重名的成员变量或成员方法,那么按照在子类中的括号中哪个父类写在前面就使用哪个父类的成员变量和成员函数
49.4 总结

复写父类成员的语法:
子类继承父类的成员属性和成员方法之后,如果对其不满意,那么可以进行复写,即在子类中重新定义同名的属性或方法即可
49.5 如何在父类中复写成员变量和成员方法,调用父类成员
# 定义父类
class Phone():
producer = "ITCAST"
def call_by_5g(self):
print("这是5g网络")
# 定义子类
class SubPhone(Phone):
# 复写父类的成员变量
producer = "黑马程序员"
# 复写成员方法
def call_by_5g(self):
#调用父类成员变量和成员方法(方法1:通过父类名调用)
print(f"父类的成员变量为{Phone.producer}")
Phone.call_by_5g(self) # 这里是必须写上self
#调用父类成员变量和成员方法(方法2:通过super())
print(f"父类的成员变量为{super().producer}")
super().call_by_5g()
iqooNeo3 = SubPhone()
iqooNeo3.call_by_5g()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
输出:
父类的成员变量为ITCAST
这是5g网络
父类的成员变量为ITCAST
这是5g网络
- 1
- 2
- 3
- 4
49.6 总结

50、类型注解
为什么使用类型注解?
为什么pycharm可以做到对于在调用一个实例的方法时可以提示可用方法?而对于一个定义一个函数时,对于刚定义的参数,还未声明它是什么类型就不能做到提示可用方法呢?
因为:pycharm不能确定这个对象是什么类型

类型注解语法:变量:类型
50.1 基础数据类型注解
var_1 : int = 10
var_2 : float = 3.13
var_3 : bool = True
var_4 : str = "黑马程序员"
- 1
- 2
- 3
- 4
50.2 类对象类型注解
这里stu是实例的名称,通过冒号和类名,注解以下stu属于Student类
class Student():
pass
stu:Student = Student()
- 1
- 2
- 3
- 4
50.3 基础容器类型简易注解
my_list : list = [1,2,3]
my_tuple : tuple = (1,2,3)
my_set : set = {1,2,3}
my_str : str = "黑马程序员"
my_dict : dict = {"黑马程序员":666}
- 1
- 2
- 3
- 4
- 5
50.4 容器类型详细注解
my_list : list[int] = [1,2,3]
my_tuple : tuple[str,bool,int] = ("诶",True,3)
my_set : set[int] = {1,2,3}
my_str : str = "黑马程序员"
my_dict : dict[str,int] = {"黑马程序员":666}#key和value的类型是啥就写啥
- 1
- 2
- 3
- 4
- 5
注意:
元组类型设置类型详细注释,需要将每一个元素都标记出来
字典类型设置类型详细注释,需要两个类型,第一个是key,第二个是value
alt+回车:自动在文件中生成导入包的语句
50.5 在注释中对数据进行类型注解
my_list = [1, 2, 3] # type: [int]
my_tuple = (1, "2", 3.14) # type: [int, str, float]
my_set = {1, 2, 3} # type: [int]
var1 = random.randint(1, 10) # type: int
var2 = json.loads("{name:张三}") # type: dict[str,str]
def func():
return 2
var3 == func() # type:int
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
一般在无法直接看出变量类型之时会添加变量的类型注解
类型注解仅仅是提示性的,不是决定性的,即使提示错了也不会报错的
50.6 总结

50.7 函数(方法)的类型注解–形参注解
语法:
def 函数方法名(形参名1:类型,形参名2:类型,...):
pass
- 1
- 2
def add(x:int,y:int):
return x+y
def func(data: list):
pass
- 1
- 2
- 3
- 4
Ctrl+p:提示代码函数的形参类型
对函数(方法)的返回值也添加类型注解;
语法:
def 函数方法名(形参名1:类型,形参名2:类型,...) -> 返回值类型:
pass
- 1
- 2
def func(data:list) -> int:
return len(data)
print(func([1,23,4]))
- 1
- 2
- 3
50.8 使用Union进行联合类型注解
语法:
from typing import Union
Union[类型,...,类型]
- 1
- 2
Union表示这个数据的数据类型可以是这个也可以是那个
变量的类型注解:
from typing import Union
my_list: list[Union[str,int]] = [1,23,"嘿嘿","新奇"]
my_dict: dict[str,Union[str,int]] = {"name":"周杰伦","age":12}
- 1
- 2
- 3
函数的类型注解:
def func(data:Union[int,str]) -> Union[int,str]:
pass
- 1
- 2
51、多态
51.1 概念
多态指的是多种状态,即完成某个行为时,使用不同的对象会得到不同的状态
class Animal():
def speak(self):
pass
class Dog(Animal):
def speak(self):
print("汪~汪~")
class Cat(Animal):
def speak(self):
print("瞄~")
def make_noise(animal:Animal):
animal.speak()
dog = Dog()
cat = Cat()
make_noise(dog)
make_noise(cat)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
输出:
汪~汪~
瞄~
- 1
- 2
51.2 抽象类(也可以称为接口)
含有抽象方法的类称其为抽象类
51.3 抽象方法
方法体是空实现的称为抽象方法
51.4 空实现
在类内部成员方法的函数体只有一个pass的方法实现称为空实现
51.5 抽象类(接口)的编程思想
见代码:
# 定义抽象类
class AC:
def cool_wind(self):
"""制冷"""
pass
def hot_wind(self):
"""制热"""
pass
def swing_r(self):
"""左右摆风"""
pass
#定义美的子类
class Midea_AC(AC):
def cool_wind(self):
print("美的空调制冷")
def hot_wind(self):
print("美的空调制热")
def swing_r(self):
print("美的空调左右摆风")
#定义格力子类
class GREE_AC(AC):
def cool_wind(self):
print("格力空调制冷")
def hot_wind(self):
print("格力空调制热")
def swing_r(self):
print("格力空调左右摆风")
def make_cool(ac:AC):
ac.cool_wind()
midea_ac = Midea_AC()
gree_ac = GREE_AC()
make_cool(midea_ac)
make_cool(gree_ac)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
输出:
美的空调制冷
格力空调制冷
- 1
- 2
抽象类是做顶层设计的,不用创建抽象类的实例,只需要创建基于抽象类的子类的实例
51.6 总结

52、综合案例(暂时不学)
---------------------------------------------------------以下是Python高级编程----------------------------------------------
53、闭包
目标使用一个全局变量account_amount来记录余额:
account_amount = 0
def atm(num,deposit = True):
global account_amount
if deposit:
account_amount += num
print(f"存款:+{num},账户余额:{account_amount}")
else:
account_amount -= num
print(f"存款:-{num},账户余额:{account_amount}")
atm(300)
atm(300)
atm(100,False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
以上代码存在问题:
代码在命名空间上(变量定义)不够干净、整洁
全局变量有被修改的风险
将代码改为以下:
def account_create(initial_amount=0):
def atm(num,deposit = True):
if deposit:
initial_amount += num
print(f"存款:+{num},当前余额:{initial_amount}")
else:
initial_amount -= num
print(f"存款:+{num},当前余额:{initial_amount}")
return atm
atm = account_create()
atm(10)
atm(10)
atm(10)
atm(10)
atm(6, deposit=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
这样会报错:
Traceback (most recent call last):
File "D:/0000***/***/测试.py", line 382, in <module>
atm(10)
File "D:/0000***/***/测试.py", line 374, in atm
initial_amount += num
UnboundLocalError: local variable 'initial_amount' referenced before assignment
- 1
- 2
- 3
- 4
- 5
- 6
- 7
得添加nonlocal initial_amount,即:
def account_create(initial_amount=0):
def atm(num,deposit = True):
# nonlocal initial_amount
if deposit:
initial_amount += num
print(f"存款:+{num},当前余额:{initial_amount}")
else:
initial_amount -= num
print(f"存款:+{num},当前余额:{initial_amount}")
return atm
atm = account_create()
atm(10)
atm(72)
atm(26,deposit=False)
atm(4)
atm(6, deposit=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
输出:
存款:+10,当前余额:10
存款:+72,当前余额:82
存款:+26,当前余额:56
存款:+4,当前余额:60
存款:+6,当前余额:54
- 1
- 2
- 3
- 4
- 5
53.1 一个简单的闭包例子
def outer(logo):
def inner(msg):
print(f"<{logo}><{msg}><{logo}>")
return inner
func1 = outer("黑马程序员")
func1("大家好")
func2 = outer("传智教育")
func2("大家好")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出:
<黑马程序员><大家好><黑马程序员>
<传智教育><大家好><传智教育>
- 1
- 2
解释:对于inner函数来说变量logo是外部变量,对于outer函数来说变量logo是临时变量
目标:对于函数inner来说,它依赖的外部变量一直都没有变化,又不想这个外部变量不会被改变
一种想法:在inner中是否可以修改变量logo的值呀?
实现方法:使用nonlocal这个关键字去修饰外部函数的变量才能在内部函数中修改它,即修改外部变量
代码:
def outer(num1):
def inner(num2):
nonlocal num1
num1 += num2
print(num1)
return inner
func1 = outer(10)
func1(10)
func1(10)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出:
20
30
- 1
- 2
53.2 总结

54、装饰器
54.1 案例介绍
def sleep():
import time
import random
print("睡觉中....")
time.sleep(random.randint(1,5))
- 1
- 2
- 3
- 4
- 5
在不改变sleep函数功能以及函数体的前提下为sleep增加新功能
新功能描述:
在睡眠之前先”打印一下要睡觉了“
在睡眠之后“打印一下要起床了”
内包写法:
def outer(func):
def inner():
print("我要睡觉啦")
func()
print("我要起床啦")
return inner
def sleep():
import time
import random
print("睡觉中....")
time.sleep(random.randint(1,5))
inn = outer(sleep)
inn()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
装饰器写法:
def outer(func):
def inner():
print("我要睡觉啦")
func()
print("我要起床啦")
return inner
@outer
def sleep():
import time
import random
print("睡觉中....")
time.sleep(random.randint(1,5))
sleep()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
54.2 装饰器的作用
在不改变目标函数的同时增加额外的功能
54.3 总结

55、设计模式
55.1 单例模式



创建一个tool.py文件
代码:
class Tools():
pass
t1 = Tools()
t2 = Tools()
print(id(t1))
print(id(t2))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出:
D:\Anaconda3\python.exe "D:/0000***/***/tool.py"
2277989643456
2277989508864
进程已结束,退出代码为 0
- 1
- 2
- 3
- 4
- 5
表示这是两个不同的类对象
再创建一个测试.py文件
代码内容:
from tool import t3
t4 = t3
t5 = t3
print(id(t4))
print(id(t5))
- 1
- 2
- 3
- 4
- 5
- 6
输出:
D:\Anaconda3\python.exe "D:/0000***/***/测试.py"
2747203220432
2747203220432
进程已结束,退出代码为 0
- 1
- 2
- 3
- 4
- 5
某些场景下才需要使用单例设计模式,不是所有情况下都是用单例模式
总结:

55.2 工厂模式
什么是工厂模式?

以上是基于原生的创造对象的方法


示例代码:
class Person():
pass
class Worker(Person):
pass
class Student(Person):
pass
class Teacher(Person):
pass
class PersonFactory():
def get_person(self,p_type):
if p_type == "w":
return Worker()
elif p_type == "s":
return Student()
else:
return Teacher()
pf = PersonFactory()
worker = pf.get_person("w")
student = pf.get_person("s")
teacher = pf.get_person("t")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
总结:

前两条好处是重点
56、多线程
了解什么是进程、线程?
了解什么是并行执行?
现代操作系统如Mac OS X,UNIX,Linux,Windows等,都是支持“多任务”的操作系统
56.1 进程
进程就是一个程序,运行在系统之上,那么便称这个程序为一个运行进程,并分配进程ID方便系统管理
56.2 线程
线程就是归属于进程的,一个进程可以开启多个线程,执行不同的的工作,是进程的实际工作单位
类比:
进程好比一家公司,是操作系统对程序进行运行管理的单位
线程好比是公司的员工,进程可以有多个线程(员工),是进程实际的工作者
56.3 多任务运行
操作系统中可以运行多个进程,即多任务运行
56.4 多线程运行
一个进程内可以运行多个线程,即多线程运行
56.5 进程与线程的注意点
进程之间是内存隔离的,即不同的进程拥有各自的内存空间。这就类似于不同的公司拥有不同的办公场所
线程之间是内存共享的,线程是属于进程的,一个进程的多个线程之间是共享这个进程所拥有的内存空间的。这就好比公司员工之间是共享公司的办公场所
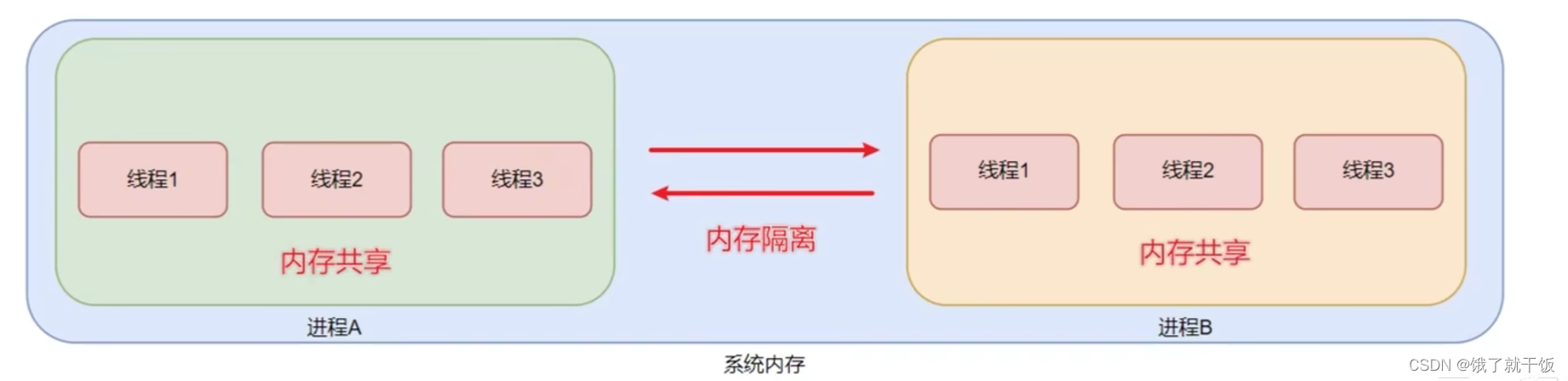
56.6 并行执行
并行执行的意思指的是同一时间做不同的工作
进程之间就是并行执行的,操作系统可以同时运行好多程序,这些程序都是在并行执行
除了进程之外,线程其实也是可以并行执行的,比如一个python程序,完全可以做到:
一个线程在输出:你好
一个线程在输出:hello
像这样一个程序在同一时间做两件乃至多件不同的事情,我们称之为:多线程并行执行
56.7 以上内容总结
见以下图片内容
56.8 多线程编程
目标:掌握使用threading模块完成多线程编程
绝大多数编程语言,都允许多线程编程
单线程编程代码:
import time
def sing():
while True:
print("我在唱歌,啦啦啦...")
time.sleep(1)
def dance():
while True:
print("我在跳舞,嘟嘟嘟...")
time.sleep(1)
if __name__ == '__main__':
sing()
dance()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
输出内容:
我在唱歌,啦啦啦...
我在唱歌,啦啦啦...
我在唱歌,啦啦啦...
我在唱歌,啦啦啦...
...
- 1
- 2
- 3
- 4
- 5
多线程编程:
import time
import threading
def sing():
while True:
print("我在唱歌,啦啦啦...")
time.sleep(1)
def dance():
while True:
print("我在跳舞,嘟嘟嘟...")
time.sleep(1)
if __name__ == '__main__':
# 创建一个唱歌的线程
sing_thread = threading.Thread(target=sing)
# 创建一个跳舞的线程
dance_thread = threading.Thread(target=dance)
#启动多个线程 同时执行
sing_thread.start()
dance_thread.start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
输出:
我在唱歌,啦啦啦...
我在跳舞,嘟嘟嘟...
我在唱歌,啦啦啦...我在跳舞,嘟嘟嘟...
我在跳舞,嘟嘟嘟...我在唱歌,啦啦啦...
我在唱歌,啦啦啦...我在跳舞,嘟嘟嘟...
我在跳舞,嘟嘟嘟...我在唱歌,啦啦啦...
我在跳舞,嘟嘟嘟...我在唱歌,啦啦啦...
等等...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
56.9 在创建多个线程时args和kwargs的传参方式
import time
import threading
def sing(msg):
while True:
print(msg)
time.sleep(1)
def dance(msg):
while True:
print(msg)
time.sleep(1)
if __name__ == '__main__':
# 创建一个唱歌的线程 给sing函数以args元组的方式传参
sing_thread = threading.Thread(target=sing,args=("我在唱歌,啦啦啦",))
# 创建一个跳舞的线程 给dance函数以kwargs字典的方式传参
dance_thread = threading.Thread(target=dance,kwargs={"msg":"我在跳舞,呱呱呱"})
#启动多个线程 同时执行
sing_thread.start()
dance_thread.start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
输出:
我在唱歌,啦啦啦
我在跳舞,呱呱呱
我在跳舞,呱呱呱我在唱歌,啦啦啦
我在跳舞,呱呱呱我在唱歌,啦啦啦
我在唱歌,啦啦啦我在跳舞,呱呱呱
我在唱歌,啦啦啦我在跳舞,呱呱呱
等等...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
59.10 多线程编程总结
1.threading 模块的使用:
# 创建线程对象
tread_obj = threading.Thread(target = func)
# 启动线程执行
thread_obj.start()
- 1
- 2
- 3
- 4
2.如何调参
args和kwargs
57、网络编程
先不学
58、正则表达式
以前学过,就不学这个了
59、递归
递归: 即方法(函数)自己调用自己的一种特殊编程写法
如:
def func():
if ...:
func()
return ...
- 1
- 2
- 3
- 4
函数自己调用自己,即称之为递归调用
递归需要注意:
1、注意退出的条件,否则容易编程无限递归
2、注意返回值的传递,确保从最内层,层层传递到最外层
os模块的3个方法:
os.listdir: 列出指定目录下的内容
os.path.isdir: 判断给定路径是否是文件夹,是返回True,否返回False
os.path.exists: 判断给定路径是否存在,存在返回True,否则返回False
import os
path = "D:\goole下载的内容在此文件夹内"
# 返回指定的文件夹包含的文件或文件夹的名字的列表
print(os.listdir(path))
# 如果指定的路径是现有目录,则返回True,否则返回False
path = "D:\goole下载的内容在此文件夹内"
print(os.path.isdir(path))
# 判断对象是否为一个目录
# os.path.exists()就是判断括号里的文件是否存在的意思,
# 括号内的可以是文件路径。
path = "D:\goole下载的内容在此文件夹内\嘿嘿.txt"
print(os.path.exists(path))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
输出:
['-946787692-姓名-附件 (1).JPG',
'-946787692-姓名-附件 (2).JPG',
'-946787692-姓名-附件 (3).JPG',
'-946787692-姓名-附件 (4).JPG',
'-946787692-姓名-附件 (5).JPG',
'-946787692-姓名-附件 (6).JPG',
'-946787692-姓名-附件.JPG',
'2022年普通招考博士研究生拟录取名单.xls',
'assignment.txt',
'pnas.1512080112 - 副本.docx',
'python组件.md',
'《科幻世界》2016年全年合集-科幻世界.txt',
'神经网络与深度学习-3小时.pptx',
'附件:南方电网公司2022年校园招聘笔试大纲.pdf']
True
False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

