
- 1STM32使用HAL库、标准库、LL库和寄存器操作的性能对比_stm32 一般用标准库还是寄存器
- 2GlobalMapper20根据CAD图中的等高线生成GIS用的地形数据_cad等高线导入gis做地形图
- 3Ubuntu 系统如何修改时间_ubuntu设置时间
- 4异步场景加载详解_unity异步加载场景
- 5win10中最常用快捷键大全_ctrl + r 和 ctrl + f5
- 6C++初阶:入门泛型编程(函数模板和类模板)
- 7Python学习笔记(七):元组的使用方法
- 8[Unity]编辑器在没有运行场景的时候就运行脚本_unity executeineditmode自动运行
- 9vue+element+admin实现前后端连接_vue前端和后端怎么连接起来
- 10首次添加iconfont和在已有iconfont文件中新增不同iconfont项目图标_iconfont添加新图标
python随机森林算法——泰坦尼克号幸存预测
赞
踩
hi everybody,
这周开始了对随机森林算法的学习,kaggle网站上有一个关于泰坦尼克号幸存预测的案例很适合用随机森林算法来预测,所以我们本周的算法就以这个数据集开始讲解。
定义问题
本研究是利用泰坦尼克号乘客数据集,运用随机森林算法根据乘客的不同变量参数特征进行学习,最后得出预测是否幸存。
本文运用的编程语言为 python
所需要的包为:sklearn,numpy,matplotlib,seaborn,pandas
泰坦尼克数据集背景解读
1912年3月15号,泰坦尼克号在首航之时就因撞击冰山而沉没,首航之时的2224名旅客及船员中共有1502名死亡。造成伤亡如此惨重的其中一个原因在于船上没有足够的救生船让旅客及船员及时逃离。我们知道在沉船中存活下来需要一些幸运因素,但是有些人对这些人的背景(如性别,舱位,票价,登船地点等)进行调查后发现,幸存与否与这些因素也有一定的关系。
在进行算法演示之前还有一句题外话:我们对船上的人员进行研究与调查,并不是想要去博人眼球消费他们,而是希望让更多的人了解这一个个数字背后不同的人生。
数据展示
数据包含了测试集与训练集两个部分
训练集:

参数分析
我们从训练集中可以看到共有11个输入参数,一个输出参数(survived),现在对输出参数的特征进行解读
1.passangerid:乘客ID号,这个是自动生成的
2.Pclass:乘客的舱位(1-一等舱;2-二等舱;3-三等舱)
3.Name:乘客姓名
4.Sex:乘客性别
5.Age:乘客年龄
6.SibSp:兄弟姐妹,伴侣人数
7.Parch:父母人数
8.Ticket:票号
9.Fare:船票价格
10.Cabin:船舱号
11.Embarked:上船地点
输出量:
survived:是否生还(1-是,0-否)
清洗数据
首先我们要对数据进行清洗,来大致的看一下数据质量
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- import seaborn as sns
- %matplotlib inline
-
- data_train = pd.read_csv(r'D:\飞机ADS-B数据\Python-Machine-Learning-Cookbook-master\titanic\train.csv')
- data_test = pd.read_csv(r'D:\飞机ADS-B数据\Python-Machine-Learning-Cookbook-master\titanic\test.csv')
- data_train.info() #显示数据信息
- 结果演示:
- RangeIndex: 891 entries, 0 to 890
- Data columns (total 12 columns):
- PassengerId 891 non-null int64
- Survived 891 non-null int64
- Pclass 891 non-null int64
- Name 891 non-null object
- Sex 891 non-null object
- Age 714 non-null float64
- SibSp 891 non-null int64
- Parch 891 non-null int64
- Ticket 891 non-null object
- Fare 891 non-null float64
- Cabin 204 non-null object
- Embarked 891 non-null object
结果显示年龄数据值有缺失,可以补充,但是Cabin(舱位)有较多缺失且较难补充,但是我们可以根据Pclass来弥补这个不足,其他的话都是比较正常的。但要注意,Embarked值原始数据是缺少两个的,我们根据计算众数来填充进去。
数据相关性分析(可视化)
数据相关性分析是对我们已有的数据之间关系的一种预判,用来判断哪些数据有可能会影响到我们最终的预测结果。
PassangerId是一个顺序标号,这个肯定对我们预测没有影响,所以忽略
Pclass:船舱等级,这个我们猜想有可能与我们的结果有影响,所以就此进行相关性分析
sns.barplot(x='Pclass',y='Survived',data=data_train)
从图像中可以明显的看到舱位等级越高生存率就越高
其次,我们再看一下性别对幸存结果是否有影响
sns.barplot(x='Sex',y='Survived',data=data_train)
sns.pointplot(x='Pclass',y='Survived',hue='Sex',data=data_train)
从这张图中可以看出,女性生存率远高于男性,但随舱位降低,生存率也随之下降。
结论:
1.舱位对生存结果有较大影响,应保留
2.性别对生存结果有较大影响。应保留
年龄对生存结果的影响:
我们可以分析一下年龄对生存结果的影响
- ageeff = sns.FacetGrid(data_train, col='Survived')
- ageeff.map(plt.hist, 'Age', bins=20)

其实这张图我个人认为他的解释性不强,因为可以看出死亡的多为20-40之间的人,但是生存的也是20-40之间的人多,当然我们也可以解释为船上20-40岁的人占大多数造成了这样的结果,但是我们在分析生存(survived=1)图的时候发现,年龄在0-4岁的小朋友存活率还是蛮大的哦,所以说也可以把它考虑进来。
登船地点对生存结果的影响:
大家也许会认为登船地点对最终结果会有什么影响呢,最开始拿到这份数据的时候,我一度就想直接把这个类给删掉,因为就我自己的感觉来说,登船港口并不能代表着什么,尤其是座位也都已经提前固定的情况下,但是当我进行分析的时候才发现,事情没那么简单的。
sns.barplot(x = 'Embarked',y = 'Survived',hue = 'Sex',data = data_train)

从这张图中我们可以发现,生存率大致是C>Q>S
其实这个是有点奇怪的,也许是因为C地的登船的人数多,也许是C地头等舱的人多,都有可能吧,或许是C地人安排的座位比较好,whatever,反正我们需要把这个考虑进去了。
Ticket和Cabin:
由于Ticket是一个票号,但是他也是一个比如说姓名+性别+舱位+座位+时间 组合的一组数字,但是这个与我们已有的类别高度相同,所以就选择丢弃,同时Cabin由于确实信息过多,而且这个是代表着座位号,所以我们也只能把它删除掉。
其他的比如说姓名,我认为其实是没有用的,但是我看kaggle上的算法大神说可以从这里面找到尊称的称号之类的,比如说什么伯爵夫人啊这种,我不太清楚英美的命名规则所以就删除掉了。但是可以下一次再做的时候把它加进去。
补全缺失值,信息数值化
接下来就是预测前的最后一步了,首先我们要来补全年龄的缺失值
我是通过求性别与舱位这两个类来补全缺少的年龄值
e.g.先计算 舱位1,性别:男 的平均年龄,并对缺失年龄信息的舱位为1,性别:男的人进行补充
但是这需要对性别(男,女)进行数值化处理,我们给定男:1 女:0
- combine = [data_train,data_test]
- for dataset in combine:
- dataset['Sex'] = dataset['Sex'].map({'female':0, 'male':1}).astype(int) #将性别变为数字的格式
- print(dataset.head())
然后我们可以思考因为舱位有三个,性别有两个,所以说是一个(2*3)的矩阵格式,我们对这个矩阵内的值进行计算
- guess_ages = np.zeros((2,3)) #创造矩阵
- for dataset in combine:
- for i in range(0,2):
- for j in range(0,3):
- age_guess = dataset[(dataset['Sex']==i)&(dataset['Pclass']==j+1)]['Age'].dropna() #将非空的年龄数值进行存储
- guess = age_guess.median() #算出该类别下的平均年龄
- guess_ages[i,j] = int(guess/0.5+0.5)*0.5 #这个是为了保证平均年龄更加准确
- for i in range(0,2):
- for j in range(0,3):
- dataset.loc[(dataset.Age.isnull())&(dataset.Sex == i)&(dataset.Pclass == j+1),'Age'] = guess_ages[i,j] #将空白的年龄值按类别补上
-
- dataset['Age'] = dataset['Age'].astype(int)
- data_train.head()

年龄补充完成之后我们希望把年龄分组化,也即是将年龄进行分组处理,并赋予一个新的值 e.g. 1-20岁定义为1,这样的好处在于方便我们进行算法的类别划分,减少过拟合情况出现
-
- data_train['AgeBand'] = pd.cut(data_train['Age'], 5)
- data_train[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True) #先分组再重新定义
- for dataset in combine:
- dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
- dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
- dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
- dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
- dataset.loc[ dataset['Age'] > 64, 'Age']
- data_train.head()

当然你也可以把Fare进行分组化,但是我认为既然已经有Pclass了,那Fare的影响不如Pclass的大,所以我这边就没有分组。然后分完组以后你就可以吧AgeBand给删掉了,删的时候有可能会报错,但是没关系,测试后他的确是已经删掉了
相同的方法把Embarked也进行分类:
- for dataset in combine:
- dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
-
- data_train.head()
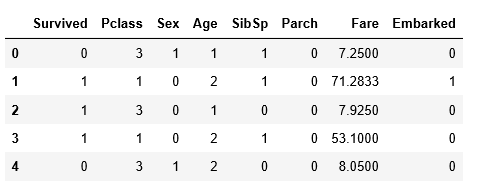
最后的数据处理的结果如上图所示。
机器学习-随机森林算法
最后我们利用sklearn进行随机森林算法实现。
- import pandas as pd
- import numpy as np
- import random as rnd
-
- # visualization
- import seaborn as sns
- import matplotlib.pyplot as plt
- %matplotlib inline
-
- # machine learning
- from sklearn.linear_model import LogisticRegression
- from sklearn.svm import SVC, LinearSVC
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.neighbors import KNeighborsClassifier
- from sklearn.naive_bayes import GaussianNB
- from sklearn.linear_model import Perceptron
- from sklearn.linear_model import SGDClassifier
- from sklearn.tree import DecisionTreeClassifier
- #分测试集与训练集
- X_train = data_train.drop("Survived", axis=1)
- Y_train = data_train["Survived"]
- X_test = data_test.drop("PassengerId", axis=1).copy()
- #进行随机森林算法
- random_forest = RandomForestClassifier(n_estimators=100)
- random_forest.fit(X_train, Y_train)
- Y_pred = random_forest.predict(X_test)
- random_forest.score(X_train, Y_train)
- acc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)
- acc_random_forest #预测准确率

![]()
准确率达到94.05说明模型建立的还不错,
总结与展望
本文只是运用随机森林一种算法进行预测,其实可以加入SVM,regression等方法进行对比。
下一篇文章我将会对随机森林的具体算法以及深度树算法进行分享,thanks for reading!

