
- 1Zabbix配置监控磁盘空间和配置触发器小于10TB自动告警_zabbix监控硬盘容量mounted filesystem discovery
- 2zzulioj 1000: 从今天开始入坑C语言
- 3报错net/javacrumbs/shedlock/core/LockProvider
- 4C语言实现TCP服务器与客户端通信_c语言设计程序,要求当客户端连接到服务器一端时,服务器会显示连接的提示信息,并反
- 5python中科学计数法怎么表示_python科学计数法转换
- 6xss获取cookie
- 7流媒体-RTP-RTCP协议解析-RTSP流的传输与控制(二)_不在同一网段的rtsp流怎么传输
- 8Java毕业设计 基于Springboot+vue的网上综合超市商城购物网站_网上超市springboot项目
- 9源码开放:基于Pyecharts可视化分析苏州旅游攻略_基于pyecharts的旅游保险数据分析文献
- 10嵌入式C编程中的设计模式之一——单件模式和策略模式_单件模式应用
010 五种序列(列表,元组,字典,集合,字符串)_元组,序列,列表,字典,集合
赞
踩
1. 列表【 】
列表是一个可以包含多种数据类型的对象,列表中的内容是可以改变的,它属于一种动态数据结构,我们可以对它进行添加或删除操作,因此在列表操作的时候离不开索引的使用。
定义列表的方式为:
my_liss = []#定义空列表
my_list = [1,2,3,4,5,6]#定义已有值的列表
my_lizz = ['a','b','c','d']
- 1
- 2
- 3
我们可以把列表当作一种容器,我们用它来存放东西,可以在其中存放相同类型的数据,也可以存放不同类型的数据,但是为了提高程序的可读性,建议在一个列表中存放同一种数据类型。
1.1 列表基础操作
1.1.1创建列表
创建拥有一定数值的列表,而我们又不想手动输入,可以用list()函数嵌套range()函数直接进行创建。
list()函数不止可以进行强制类型转换,把字符串或元组转换为列表,还可以在定义的时候就使用列表方式。
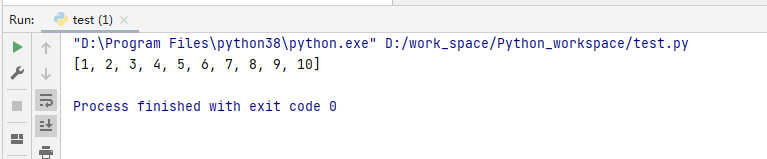
# 创建一个包含1~10的数字的列表
my_list = list(range(1,11))
print(my_list)
- 1
- 2
- 3
1.1.2 删除列表
格式为:
del my_list
- 1
实例:
my_list = [1,2]
print(my_list)
del my_list#删除这个已被创建的列表
print(my_list)#输出一下试试
- 1
- 2
- 3
- 4
- 5

通过报错提示我们可以知道我们创建的列表已经被删除了。
1.1.3 复制列表
我们有时候会需要做一个列表的副本,这时候我们就需要复制列表中的元素,思路:如果先定义一个列表,然后再定义一个列表,让第二个列表等于第一个列表,我们修改了第一个列表中的值之后,第二个列表中的值会变吗?
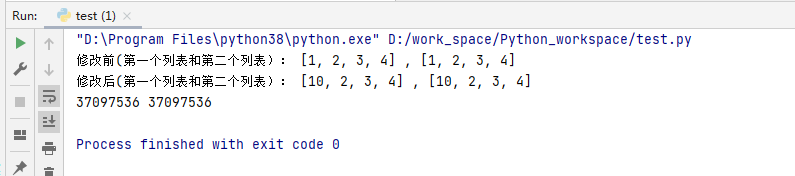
first_list = [1, 2, 3, 4] # 先定义一个列表
second_list = first_list # 复制这个列表
print('修改前(第一个列表和第二个列表):', first_list, ',', second_list) # 输出看一下
first_list[0] = 10
print('修改后(第一个列表和第二个列表):', first_list, ',', second_list) # 再输出看一下
print(id(first_list), id(second_list)) # 通过访问id可以发现此时两个列表地址是相同的
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
可以发现复制的第二个列表在第一个列表中的元素值被修改之后也跟随着修改,说明了他们是使用的同一列表。也就是说着两个变量使用的是内存中的同一列表,无论修改哪个列表中的元素,对应的都是同一列表。
使用相同内容的列表但各自独立的:
first_list = [1,2,3,4]#先定义一个列表
second_list = [] + first_list#使用连接符
print(id(first_list),id(second_list))#通过访问id可以发现此时两个列表是相互独立的
- 1
- 2
- 3

注意:Python的数据结构中最核心的就是列表.
1.2 列表的使用
1.2.1 遍历列表
遍历列表通常采用for循环的方式以及for循环加上enumerate()函数搭配的方式去实现。
1、for循环方式遍历

2、 for循环方式配合enumerate()函数遍历
enumerate函数在序列中提到过一次,它的作用是把序列组合成一个索引序列,我们配合for循环使用的时候,能得到列表中的元素及其索引值。通过这种方式我们能更清楚的看到每个元素在列表中的位置。
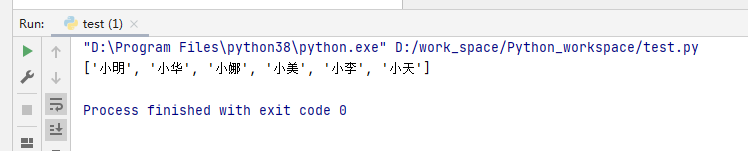
my_list = ['小明','小华','小天','小娜','小美','小李']
for index,element in enumerate(my_list):
print('序号为:',index,'名字为:',element)
- 1
- 2
- 3

1.2.2 查找元素
在查找元素的时候,我们可以使用index()方法,它会返回元素的索引值,如果找不到元素就会报错。
my_list = ['小明','小华','小天','小娜','小美','小李']
print("索引位置:",my_list.index('小天'))
- 1
- 2

1.2.3 增加元素
增加元素相对来说比较简单,使用append()方法进行添加。
my_list = []#创建一个空列表
my_list.append(1)#添加一个元素1
my_list.append(2)#添加一个元素2
print(my_list)#输出
- 1
- 2
- 3
- 4

1.2.4 删除元素
删除元素的时候我们通常采用两种方法,分别是 [根据索引值删除] 和 [根据元素值删除]。
[根据索引值删除] :
my_list = ['小明','小华','小天','小娜','小美','小李']
del my_list[1]#删除索引值为1的元素,对应为‘小华’
print(my_list)
- 1
- 2
- 3

[根据元素值删除]: 根据元素值删除的时候我们会使用到remove()函数进行删除。
my_list = ['小明','小华','小天','小娜','小美','小李','小天']
my_list.remove('小天')#直接找到第一个为‘小天’的元素
print(my_list)
- 1
- 2
- 3
1.2.5 改变元素
直接赋值更改
my_list = ['小明', '小华', '小娜', '小美', '小李', '小天']
print("未修改:",my_list)
my_list [0] = '小明的哥哥'
print("修改后",my_list)
- 1
- 2
- 3
- 4

1.2.6 插入元素
- 当我们想要在列表中某个位置增添一个元素的时候,我们可以采用insert(index,element)方法,index为索引位置,element为插入元素。
- 当元素插入到列表时,列表大小会扩大以容纳新的元素。而之前在指定索引位置上的元素以及其后的所有元素则依次向后移动一个位置。
- 如果你指定了一个无效索引,不会引发异常。
- 如果指定的位置超过了列表末尾,元素会添加到列表未尾。
- 如果你使用负索引指定了一个非法索引,元索会添加到列表开始。
# 在小明和小华之间插入一个元素‘小张’
my_list = ['小明', '小华', '小娜', '小美', '小李', '小天']
print("插入前:",my_list)
my_list.insert(1,'小张')
print("插入后:",my_list)
- 1
- 2
- 3
- 4
- 5
- 6

1.2.7 列表排序
可以采用两种方式,一种使用sorted(list)进行排序,一种是使用list.sort()进行排序
使用方法:
a、 listname.sort(key=None,reverse=False)
listname为目标列表,
key表示指定一个从每个列表元素中提取一个比较的键,
reverse为可选参数,当指定为True时为降序,如果为Flase则为升序。默认为升序。
b、newlist = sorted(listname,key=None,reverse=False)
newlist为新的序列,listname为要排序的列表,key和reverse和1)中一致。
两种方式的区别在于前者等于在原序列上进行直接修改,而后者会生成一个新的序列。
my_list = [2,1,3,5,4,6,8,9,7,10]
print(my_list)
my_list.sort()#这种格式是直接在列表后使用sort()函数
print(my_list) #在原序列上进行直接修改
b = sorted(my_list)#这种方式是定义一个新列表来存放排序过的序列
print(b)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
1.2.8 逆序列表
- 把一个容器中的数据逆序在Python中采用reverse()函数或者reversed().
- reverse()和sort()类似,都是直接在列表后面使用方法就可以了,
- 但reversed需要在前面加上一个存储类型(因为在reversed()作用后,返回一个迭代器,迭代器中的数据是逆序过的,我们使用一种已知的存储结构来存储迭代器中的元素更方便访问,通常会使用列表方法)
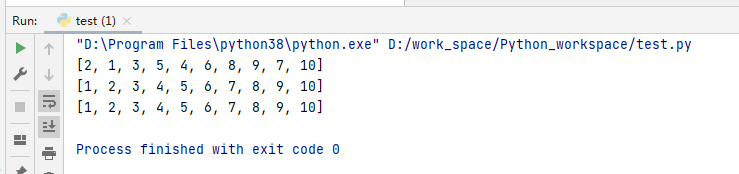
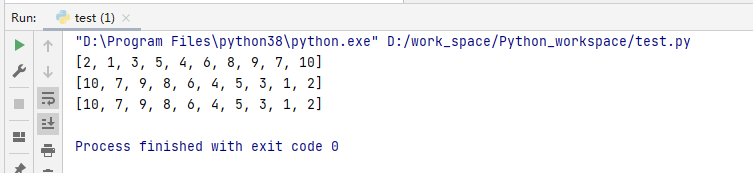
my_list = [2,1,3,5,4,6,8,9,7,10]
print(my_list)
c = list(reversed(my_list)) #使用reversed逆序一定要加上一个存储类型
print(c)#输出
my_list.reverse()#使用reverse逆序
print(my_list)#输出
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
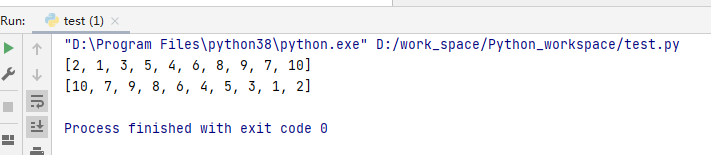
列表逆序的时候还可以使用前面学习过的切片操作,直接进行逆序:
my_list = [2,1,3,5,4,6,8,9,7,10]
print(my_list)
my_list = my_list[::-1]
print(my_list)
- 1
- 2
- 3
- 4
- 5

1.4 列表推导式
- 一种特殊的表达式,名为推导式
- 它的作用是将一种数据结构作为输入,再经过过滤计算等处理,最后输出另一种数据结构。
- 根据数据结构的不同会被分为【列表推导式】、【集合推导式】和字【典推导式】。
这里学习列表推导式,列表推导式的语法格式:
listname = [expression for variable in 对象(if condition)]
- 1
listname:新生成的列表名字
expression:表达式
variable:变量名
(if condition):用于从对象中选择符合要求的列表
1.4.1 规定范围的数值列表
这种方式能简化我们在定义列表时的操作。
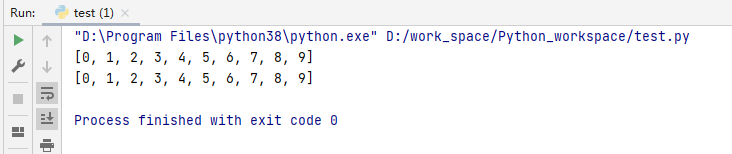
# 生成10个数字并存放列表当中
# 普通方式
listname = []
for i in range(10):
listname.append(i)
print(listname)
# 使用列表推导式
listname = [i for i in range(10)]
print(listname)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
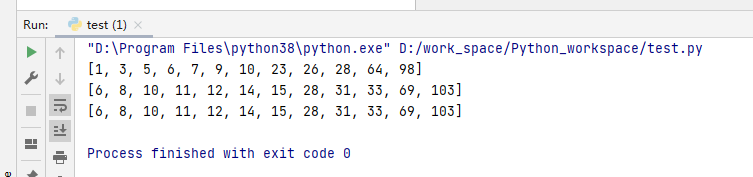
1.4.2 根据规定条件生成列表
# 把列表里面的数全部加5
# 普通方式
listname = [1,3,5,6,7,9,10,23,26,28,64,98]
print(listname)
for i in range(len(listname)):
listname[i] += 5
print(listname)
# 使用列表推导式
listname = [1,3,5,6,7,9,10,23,26,28,64,98]
listname = [ i + 5 for i in listname]
print(listname)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
1.4.3符合条件的元素组成的列表
这种类型的列表推导式要比前两种复杂点,但是能简化更多的代码。
# 找到列表中大于100的数字,然后乘上0.8,最后返回到列表中 # 普通方式 listname = [10,20,30,40,60,120,130,140,160,180,200] print(listname) newlist = []#创建新列表来存储 for i in range(len(listname)):#索引值遍历 if listname[i] >100:#找到大于100的数 listname[i] *= 0.8#乘上0.8 newlist.append(listname[i])#添加到新列表中 print(newlist) # 使用列表推导式 listname = [10,20,30,40,60,120,130,140,160,180,200] newlist = [i*0.8 for i in listname if i > 100] print(newlist)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

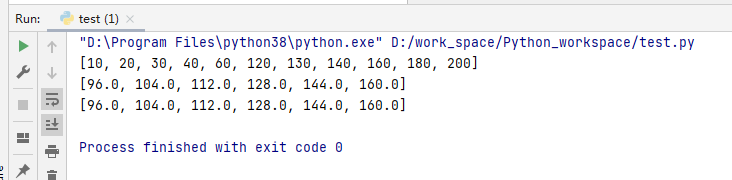
在使用复杂的列表推导式的时候我们可以采用这种方式,可以理解为我们先把符合条件的元素(条件语句)从对象中挑选出来,然后再经过输出表达式的处理,最后存放到了列表当中,形成新的列表。
练习:
# 列表[1,2,13,22,25],请使用使用列表推导式提取出大于10的数,并把每个数平方,最终输出。
# 普通方式
listname = [1,2,13,22,25]
print(listname)
# 使用列表推导式
newlist = [i*i for i in listname if i > 10]
print(newlist)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

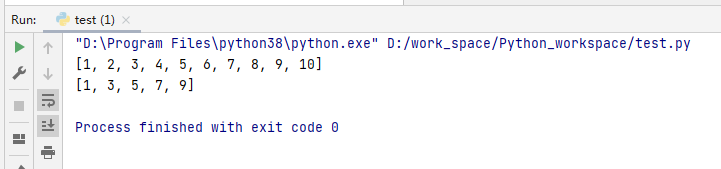
# 求列表所有奇数并构造新列表
# 普通方式
list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(list)
# 使用列表推导式
newlist = [i for i in list if i%2 == 1 ]
print(newlist)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
1.5 二维列表
二维列表是将其他列表当做列表的元素放在一个列表当中,也就是列表的嵌套。
Python中数组存在于第三方库中,因此在不安装第三方插件的前提下我们想要在Python中使用数组方法,就要采用二维列表这个方法。
my_list = [[1,2,3,4,5],'dotcpp',{1,2,3,},('www','dotcpp','com')]
print(my_list)
- 1
- 2

在这个列表中包含了列表,字符串,集合,元组。
当一个列表中的元素全部为列表的时候,是我们最常用的二维列表
1.1 二维列表的创建
使用列表推导式也是可以创建二维列表的,上一节我们刚刚学习过列表推导式,因此我们可以直接使用这种方式来简化我们的代码。
# 创建一个六行六列的二维列表
my_list = [[i for i in range(1,7)] for j in range(1,7)]
print(my_list)
- 1
- 2
- 3
- 4

循环创建了6个列表并赋予了6个值,最后他们是放在了一个列表中构成了二维列表。
2. 元组()
- 元组是一种不可改变的序列,它里面的内容是不可以被改变的。
元组属于序列,它和列表相似,最主要的区别就是元组创建之后就不能再对里面的元素进行增删操作。
元组的一般形式为:
(1,2,3,4,5,6)
- 1
它与列表结构的区别在于它使用小括号‘()’,里面每个元素之间用‘,’隔开,在元组中同样可以存放整数、字符串、列表等类型的内容。
2.1 创建元组
2.1.1 创建空元组
创建空元组和列表方式一样,语法格式为:
my_tuple = ()
- 1
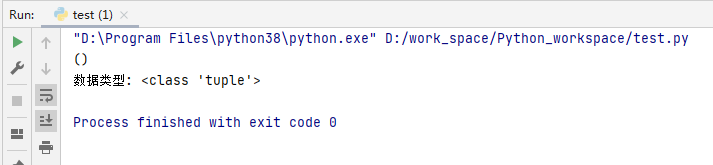
my_tuple = ()#创建空元组
print(my_tuple)#输出
print('数据类型:',type(my_tuple))#看一下它的类型
- 1
- 2
- 3
2.1.2 赋值创建元组
直接赋值的语法格式:
my_tuple = (value1,value2,value3,value4,value5)
- 1
my_tuple为列表名,value1~value5位元组中的各个元素,可以是整数、字符串或者列表
my_tuple = ('www.dotcpp.com','123456',[1,2,3,4,5,6])#创建元组并直接进行赋值
print(my_tuple)#输出
- 1
- 2

2.1.3 使用range()函数创建
使用range()函数我们可以创建具有一定数据规模的元组。
my_tuple = tuple(range(1,100,3))#range(1,100,3)创建了一个1-100之间步长为3的序列,
# 最后使用tuple()强制转换为元组类型
print(my_tuple)#输出
- 1
- 2
- 3

2.2 删除元组
删除元组的方式和列表相同,使用del语句直接进行删除,语法形式为:
del my_tuple
- 1
my_tuple = tuple(range(1,100,3))#range(1,100,3)创建了一个1-100之间步长为3的序列,最后使用tuple()强制转换为元组类型
print(my_tuple)#输出
del my_tuple#删除元祖
print(my_tuple)#这时候再输出就会报错
- 1
- 2
- 3
- 4
- 5

2.3 访问元组
我们在访问元组元素的时候同样是根据索引位置去找到所要访问的元素。
my_tuple = ('a','b','c','d')
print(my_tuple[0],my_tuple[1],my_tuple[2],my_tuple[3])
- 1
- 2


2.4 修改元组
因为元组是不可变的数列,所以我们不可以对其元素进行修改。
my_tuple = ('a','b','c','d')
my_tuple[2] = 6
- 1
- 2
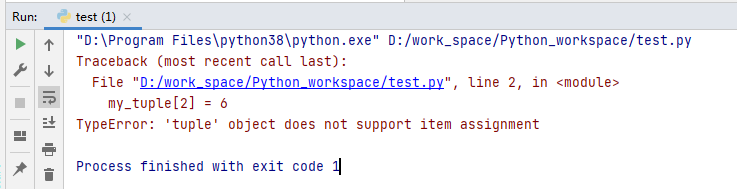
TypeError: ‘tuple’ object does not support item assignment
翻译:'tuple’对象不支持项赋值
如果要修改元组中的元素,通常会采用两种方式,一种是重新赋值法,一种是类型转换法。
2.4.1 重新赋值法
my_tuple = ('a','b','c','d')
my_tuple = ('a','b')
print(my_tuple)
- 1
- 2
- 3
这样的覆盖方式可以很简单的修改了元组中的元素,当然这种方式的使用范围受到限制,因此我们在大多数情况下可以采用第二种。
2.4.2 类型转换法
如果要对元组的第一百元素进行修改,那么采用上面方式就显得十分麻烦,因此可以采用类型转换,先把元组转换成其他数据类型,例如转换为列表,一般情况下我们 都是转成列表进行操作。
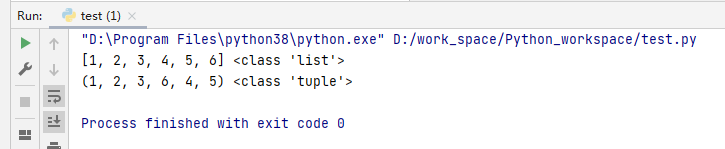
my_tuple = (1,2,3,4,5,6)#先创建一个元组
my_tuple = list(my_tuple)#把元组转换为列表形式
print(my_tuple,type(my_tuple))#输出看一下现在的数据和类型
my_tuple.insert(3,6) #在列表类型下进行元素的插入或更改或删除
my_tuple.pop()#元素的删除,pop()自动删除最后一项,也就是对应的6
my_tuple = tuple(my_tuple)#最后转换为元组形式
print(my_tuple,type(my_tuple))#打印
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
小结:
元组相对于列表缺少了一些功能,但元组也有它的独特之处:
- 首先元组的性能是比较高的,处理元组的速率要快于列表,
- 其次是它非常安全,当数据规模较大的时候,使用元组能保障你的数据不会被修改,确保了安全性,在存储方面是一个很好的选择。
3. 字典{ }
字典和列表和元组不同,字典中存储的是一组数据,也就是说字典中的每个数据都包含了两个部分,一个是“键”,一个是“值”,也就是键值对的形式。
几点字典的特性:
1) 字典是没有顺序的,是任意对象的无序集合。
2) 字典的键是唯一的,不能多次出现,多次出现时取最后一个值。
3) 键是不可变的。
4) 字典中的元素可增删。
5) 因为没有顺序,所以不存在索引。
3.1 字典的使用
3.1.1字典创建
字典每个元素包含2个部分,他们分别是‘键’和‘值’,键和值之间用‘:’隔开,两个元素之间用‘,’隔开。
语法形式为:
my_dict = {‘key’ : ‘value’,’key1’ = ‘value1’....}
- 1
其中my_dict 为我们要创建的字典,key为键,value为键对应的值,他们可以是任何数类型。
字典的形式大致就是这样,每个元素对应两个部分,前面的为‘键’,后面的为‘值’。
- 空字典
my_dict = {}#直接进行创建
print(my_dict)
- 1
- 2
- 非空字典
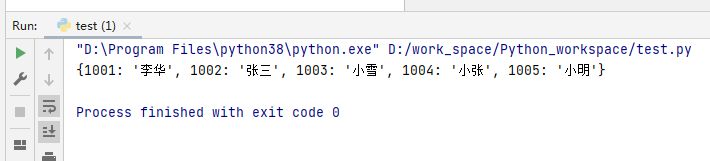
my_dict = {1001:'李华',1002:'张三',1003:'小雪',1004:'小张',1005:'小明'}
print(my_dict)
- 1
- 2
要注意键是不可以修改的,而值是可以变的,因此键要取不可变类型的数据。
3.1.2 字典访问
在字典中访问元素一般是通过访问其键的形式来获取它对应的值。
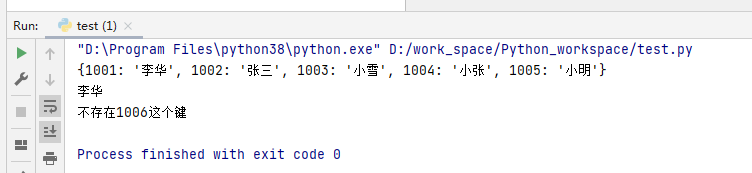
my_dict = {1001:'李华',1002:'张三',1003:'小雪',1004:'小张',1005:'小明'}
print(my_dict)
print(my_dict[1001])
print(my_dict[1006]) # 不存在的键,会报错
- 1
- 2
- 3
- 4
- 5
- 6

3.1.3 判值存否
判别字典中是否存在对应的键。 判断是否存再我们使用的是in和not in。
my_dict = {1001:'李华',1002:'张三',1003:'小雪',1004:'小张',1005:'小明'}
print(my_dict)
if 1001 in my_dict: # 如果my_dict中存在1001这个键就执行下面语句
print(my_dict[1001])
if 1006 not in my_dict:#如果my_dict中吧存在1006这个键就执行下语句
print('不存在1006这个键')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
简单的使用in和not in 可以确保我们在访问的时候减少错误的发生
需要注意在in和not in操作的时候,字符串的比较需要区分大小写。
3.1.4 添加元素
字典是可变的,所以我们可以进行增加删除和修改等操作。
对应的语法形式分别为:
my_dict['newkey'] = 'newvalue'
- 1
增加元素就是直接通过键值对进行添加。
my_dict = {1001:'李华',1002:'张三',1003:'小雪',1004:'小张',1005:'小明'}
print(my_dict)
my_dict [1006] = '小李'#增加键1006,对应值‘小李’
print(my_dict)
- 1
- 2
- 3
- 4
- 5

3.1.5 删除元素
删除元素我们还是通过del语句进行删除,删除的是一整对元素,即包括键和值。
语法格式:
del my_list['key']
- 1
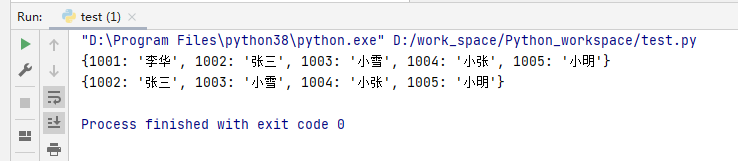
my_dict = {1001:'李华',1002:'张三',1003:'小雪',1004:'小张',1005:'小明'}
print(my_dict)
del my_dict[1001]
print(my_dict)
- 1
- 2
- 3
- 4
- 5
3.1.6 修改元素
修改元素就等于是直接覆盖了现有元素,它的形式和添加元素的格式类似,
格式为:
my_dict[key] = 'newvalue'
- 1
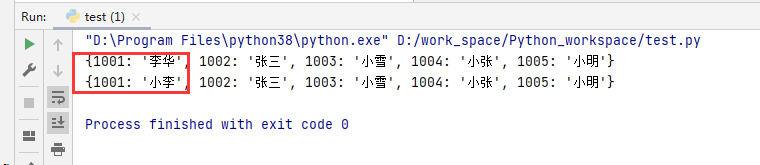
my_dict = {1001:'李华',1002:'张三',1003:'小雪',1004:'小张',1005:'小明'}
print(my_dict)
my_dict[1001] ='小李'
print(my_dict)
- 1
- 2
- 3
- 4
- 5
3.2 字典常用函数

3.2.1 clear()
使用clear()方法会清空字典中的所有元素。
使用方法为:
my_dict.clear()
- 1
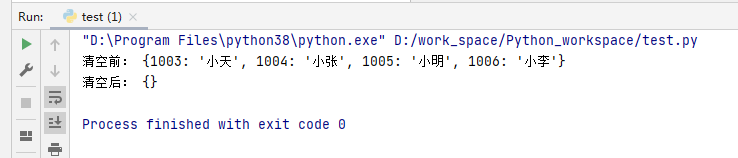
my_dict= {1003: '小天', 1004: '小张', 1005: '小明', 1006: '小李'}
print("清空前:",my_dict)
my_dict.clear()
print("清空后:",my_dict)
- 1
- 2
- 3
- 4
- 5
3.2.2 get()
我们在获取键对应的值的时候,使用get()方法可以避免因未找到相应目标而引发异常的情况。
使用方法为:
my.dict.get(key,default)
- 1
Key为我们要查询的键,default为未找到时的默认返回值,我们可以进行自定义。
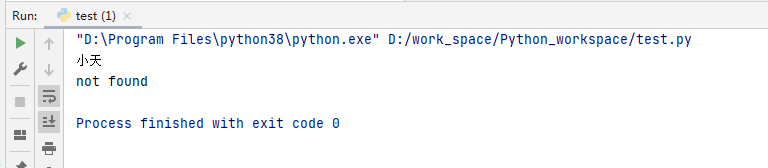
my_dict= {1003: '小天', 1004: '小张', 1005: '小明', 1006: '小李'}
print(my_dict.get(1003,'not found'))
print(my_dict.get(1001,'not found'))
- 1
- 2
- 3
找到key1003对应值,如果找不到就输出’not found’
3.2.3 items()
items方法返回字典中成对的键和值,返回的是一种名叫【字典视图】的特殊序列
其中每个元素都是一个元组。
使用方法:
my_dict.items()
- 1
my_dict = {1001: '小张', 1002: '小华'}
print(my_dict.items())
- 1
- 2
- 3

3.2.4 keys()
它的使用方式和items使用方法类似,keys返回字典中的键。
使用方法:
my_dict.keys()
- 1
my_dict = {1001: '小张', 1002: '小华'}
print(my_dict.keys())
- 1
- 2

3.2.5 values()
vlaues()返回字典中的所有值。
使用方法:
my_dict.keys()
- 1
my_dict = {1001: '小张', 1002: '小华'}
print(my_dict.values())
- 1
- 2
- 3

3.2.6 pop()
pop()方法会删除指定的键,并返回对应键的值,如果没有找到相应键可输出默认值。
使用方法:
my_dict.pop(key,default)
- 1
my_dict = {1001: '小张', 1002: '小华'}
my_dict.pop(1001)
print(my_dict.pop(1003,'not found'))
- 1
- 2
- 3

3.3 混合字典
所谓混合字典,即字典中存储的数据是各种类型混合在一起的,
键需要取不可变的数据类型,但是值是可以取任意类型的对象。
my_dcit = {'小明':['身高:170cm','体重:65kg'],'小李':'爱学习,爱运动','小华':('居住地:苏州','出生地:上海')}
print('访问key=‘小明’->',my_dcit['小明'])
print('访问key=‘小华’->',my_dcit['小李'])
print('访问key=‘小华’->',my_dcit['小华'])
print('itmes()方法:',my_dcit.items()) #整体访问
print('keys()方法:',my_dcit.keys()) #只访问了所有key
print('values()方法:',my_dcit.values()) #只访问了value
print('get()方法:',my_dcit.get('小明')) #get方法来访问指定键
my_dcit.pop('小明') #此步骤为pop()方法,会删除键=‘小明’的成对元素
print('pop()方法后的my_dict:',my_dcit) #查看一下删除后的字典
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

3.4 遍历字典
my_dict ={1001:'小明',1002:'小华',1003:'小张'}
for i in my_dict:
print(i, my_dict[i])#输出key及key对应的值
# 使用items()方法来获取成对的元素。
for i in my_dict.items():
print(i)
# 通过循环的遍历直接获取每一次遍历的键和值。
for i,j in my_dict.items():
print('对应键:',i,'对应值:',j)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

3.5 字典推导式
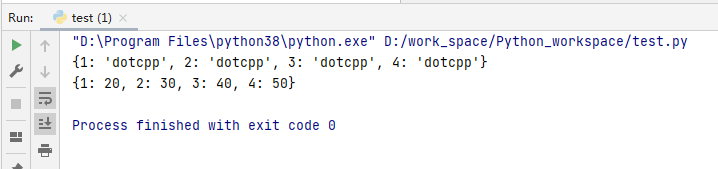
my_dict = {i:'dotcpp' for i in range(1,5)}
print(my_dict)
my_list = [10,20,30,40,50]
my_dict = {i:my_list[i] for i in range(1,5)}
print(my_dict)
- 1
- 2
- 3
- 4
- 5
- 6
- 7

使用字典推导式的时候主要键与值的相匹配问题.
# 要求用户输入总资产,例如: 3000, # 然后显示购物车列表 # 计算购物车商品总金额, # 如果商品总额大于总资产,提示账户余额不足,否则,购买成功。购物车列表如下: carts=[{"name":"床","price":1999,"num":1},{"name":"枕头","price":10, "num":2},{"name":"被子","price":20,"num":1}] m = int(input("输入总资产:")) sum = 0 for i in range(len(carts)): sum = carts[i]['price'] * carts[i]['num'] + sum print(sum) print('-------------------------------') if m >= sum: print('购买成功') else: print('账户余额不足')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

4. 集合{ }
我们在学习数学的时候学过集合这个概念,在Python中同样存在一种名叫集合的数据类型,它也是用来保存不重复的元素,简单的说,集合就是包含了一些唯一存在的元素。
元素有以下几个特性:
1) 无序性,集合中保存的元素是没有顺序的。
2) 多样性,集合中可以保存多种数据类型的元素。
3) 唯一性,集合中的元素都是唯一存在的,不会重复出现。
4.1 集合的使用
4.1.1 创建集合
在创建集合的时候有2种方式,一种是直接使用集合的特征符号‘{}’来创建,一种是使用set()函数强制类型转换来创建。
- 直接创建
首先我们要知道集合和字典的区别,集合是由‘{}’括起来的结构,每个元素之间用‘,’隔开,
集合和字典都是用大括号括起来
但是集合之间不使用冒号。
集合的结构为:
my_set = {元素1,元素2,元素3}
- 1
my_set为要创建的集合名,括号内的为集合中的元素。
my_set = {1,2,3,4,5,6}
print(my_set)
- 1
- 2

2. 使用set()函数强制类型转换创建
使用set()可以直接创建一个空集合,也可以将其他类型的结构直接转换为集合。
格式:
my_set = set(iteration)
- 1
my_set为要创建的集合名,set()函数为强制类型转换,iteration是一个可迭代对象,它可以是元组、列表或range对象。
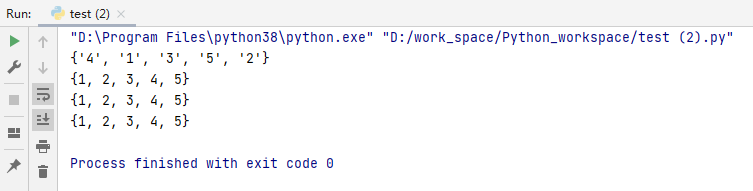
m = set('12345')#强制转换字符串
n = set([1,2,3,4,5])#强制转换列表
k = set(range(1,6))#强制转换range()对象
i = set((1,2,3,4,5))#强制转换元组
print(m)
print(n)
print(k)
print(i)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4.1.1 清空集合
del()方法可以直接删除整个集合,语法格式为:
del my_set
- 1
m = set('12345')#强制转换字符串
print(m)
del m
print(m)
- 1
- 2
- 3
- 4

4.1.1 添加元素
集合是可变序列,因此我们可以对其中的元素进行增删操作。
添加元素使用add()方法,语法格式如下:
my_set.add(x)
- 1
my_set为集合名,x为要插入的元素。
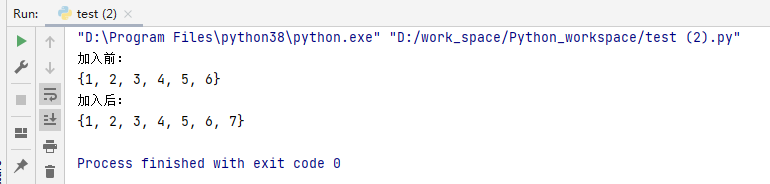
my_set = {1,2,3,4,5,6}
print('加入前:')
print(my_set)
print('加入后:')
my_set.add(7)
print(my_set)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
4.1.1 删除元素
删除元素可以使用集合的pop()方法或者remove()方法去删除一个元素,也可以使用clear()方法去清空集合。
需要注意的是remove()方法是移除指定元素,而pop()方法是直接删除集合中的第一个元素并输出,clear()方法直接清空了集合中的所有元素。
my_set= {1,2}
my_set.pop()#会删除并输出第一个元素1
print(my_set)
my_set = {2, 3, 4, 5, 6, '插入一个新元素x'}
print(my_set)
my_set.remove(6)#直接指定删除6
print(my_set)
my_set.clear()#清空集合
print(my_set)#打印结果显示为一个空集合
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

4.2 集合的运算
4.2.1 交集
求交集的时候可以采用两种方式,一种是使用‘&’运算符进行操作,一种是使用intersection()方法来实现。
- 方法1——使用‘&’运算符
A = {'数学','语文','英语','物理','化学','生物'}
B = {'数学','语文','英语','政治','地理','历史'}
print(A&B)
- 1
- 2
- 3
- 4

- 方法2——使用intersection()方法
A = {'数学','语文','英语','物理','化学','生物'}
B = {'数学','语文','英语','政治','地理','历史'}
C = A.intersection(B)
print(C)
- 1
- 2
- 3
- 4
- 5

4.2.1 并集
使用集合求并集的方式同样也是两种方式,一种是使用‘|’运算符进行操作,一种是使用union()方法来实现。
- 方法1——使用‘|’运算符
A = {'数学','语文','英语','物理','化学','生物'}
B = {'数学','语文','英语','政治','地理','历史'}
C = A | B
print(C)
- 1
- 2
- 3
- 4
- 5

- 方法2——使用union()方法
A = {'数学','语文','英语','物理','化学','生物'}
B = {'数学','语文','英语','政治','地理','历史'}
C = A.union(B)
print(C)
- 1
- 2
- 3
- 4
- 5

4.2.1 差集
使用集合求差集的方式同样也是两种方式,一种是使用‘-’运算符进行操作,一种是使用difference()方法来实现。
- 方法1——使用‘-’运算符
A = {'数学','语文','英语','物理','化学','生物'}
B = {'数学','语文','英语','政治','地理','历史'}
C = A-B
print(C)
C = B-A
print(C)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

- 方法2——使用difference()方法
A = {'数学','语文','英语','物理','化学','生物'}
B = {'数学','语文','英语','政治','地理','历史'}
C = A.difference(B)
print(C)
C =B.difference(A)
print(C)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

在方法2中注意A和B的位置不同的时候是有区别的,
如果是A使用difference()方法,那么是输出A中有而B中没有的元素,
如果是B使用difference()方法,那么是输出B中有而A中没有的元素。
5. 字符串’ ’ " "
5.1 字符串的使用
5.1.1 原始字符串
我们在代码中穿插一些转义符去实现一些代码的换行回车等
我们在数据分析的时候经常要用到原始字符串方法
print('www.dotcpp.com\n','学习乐园')
print(r'www.dotcpp.com\n','学习乐园')
- 1
- 2
- 3

第一行代码中的‘\n’在输出的时候被实现,因此实现了换行操作。
第二行代码输出的字符串前有‘r’,因此在输出的时候只会输出原始字符串,无论字符串中包含什么转义符,都不会被实现。
5.1.2 访问字符串
遇到访问字符串中每个字符的问题,因此我们需要使用循环来访问字符串中的每个字符,我们通常使用for循环和索引来访问。
使用for循环来访问字符串的格式为:
for i in my_str
- 1
my_str = 'www.dotcpp.com'
for i in my_str:
print(i, end=' ')
- 1
- 2
- 3
- 4

我们通过循环的方式访问了字符串中的每一个元素。
字符串同样采用了索引的方式
因此我们在访问字符串的字符的时候同样可以采用索引的方式来访问。
my_str = 'www.dotcpp.com'
for i in range(len(my_str)):
print(my_str[i],end=' ')
- 1
- 2
- 3
- 4

前面介绍过range(len())这个结构,在这里再次解释一下,
range()是一个对象,
而len()是求长度,
len(my_str)求出了字符串的长度,
然后range(len(my_str))的对象就是0到字符串的最大长度减1。
i为我们每次获取的值,从0依次取到字符串长度的最大值减1,然后通过索引值输出my_str[i],
从而获取到了每个元素。
my_str = 'www.dotcpp.com'
print(my_str[5]) # 索引值为5的字符
print(my_str[0]) #索引值为0的字符,也就是第一个字符
print(my_str[len(my_str)-1]) #索引值为最后一位的字符
print(my_str[-1]) #这种方式也是访问最后一个字符
- 1
- 2
- 3
- 4
- 5
- 6

5.1.3 连接字符串
字符串自带连接方法,在连接的时候我们可以使用‘+’直接连接或追加一个字符串到另一个字符串的末尾。
my_str = 'www.dotcpp.com'
his_str = '人生苦短,我用Python'
print(my_str + his_str)
- 1
- 2
- 3
- 4

通过‘+’可以直接进行字符串的连接,连接之后生成的是一个新的字符串,原字符串并没有发生改变。
5.1.4 切片字符串
my_str = 'www.dotcpp.com'
print(my_str[0:2]) #通过切片访问0-1
print(my_str[3:6]) #3-5
print(my_str[7:10]) #7-9
print(my_str[::2]) #步长为2的访问整个字符串
print(my_str[::-1]) #逆置字符串
- 1
- 2
- 3
- 4
- 5
- 6
- 7

5.2 常用方法函数
5.2.1 count()方法
my_str = 'www.dotcpp.com'
num = my_str.count('w')
print(num)
num = my_str.count('.')
print(num)
num = my_str.count('p')
print(num)
num = my_str.count('*')
print(num)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

返回的数字即该字符在字符串中出现的次数,因为‘*’不存在,所以返回值为0。
5.2.1 find()方法
find方法来检索字符串中是否包含指定元素,如果包含该元素则返回该元素第一次出现的索引位置,如果不存在该字符则返回-1
它的语法结构为:
my_str.find(x)
- 1
my_str = 'www.dotcpp.com'
num = my_str.find('w')#寻找字符w
print(num)
num = my_str.find('p')#寻找字符p
print(num)
num = my_str.find('m')#寻找字符m
print(num)
num = my_str.find('*')#寻找字符*,因为*不存在因而返回-1
print(num)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

同样可以采用关键字in来查询指定字符是否存在于指定字符串中,如果字符串中存在指定字符则返回True,如果不存在则返回False。
my_str = 'www.dotcpp.com'
print('p' in my_str)
print('*' in my_str)
- 1
- 2
- 3
- 4

但是这种方式只能知道我们要访问的元素是否存在,而不能获取到它存在的位置.
5.2.1 index()方法
index()方法和find()方法类似,index()方法在检索到指定字符的时候也会返回该字符第一次出现的索引位置,但是如果检索不到就会抛出异常
它的语法格式为:
my_str.index(x)
- 1
my_str为要检索的字符串名,x为要寻找的元素。
my_str = 'www.dotcpp.com'
print(my_str.index('w'))
print( my_str.index('o'))
print(my_str.index('*'))
- 1
- 2
- 3
- 4
- 5

找到存在的元素后会返回其在字符串中的索引位置,最后一个‘*’因为没找到而报错。
5.2.1 标准格式
上面三种方法为他们的省略格式,在标准文档中,他们的格式分别为:
my_str.count(x[,start[,end]])
my_str.find(x[,start[,end]])
my_str.index(x[,start[,end]])
- 1
- 2
- 3
在上面讲解的时候我们没有提到括号中的内容,因为在Python文档中‘‘[]’’表示可以省略部分,因此这一部分是可以省略不写的,但是我们在使用的时候,还是可以使用的,start为索引的起始位置,end为索引的结束位置,但是不包含end。
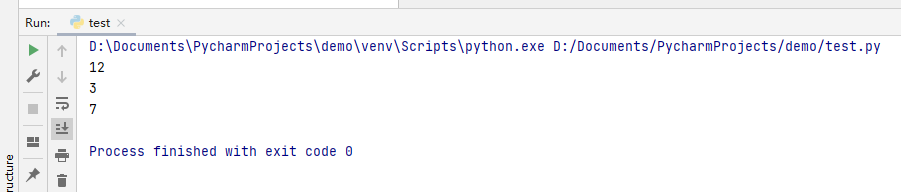
my_str = 'www.dotcpp.com'
print(my_str.index('o',6,13))#在6-12之间寻找o
print( my_str.count('w',0,5))#统计w在0-4之间存在的次数
print(my_str.find('c',3,9)) #在3-8之间寻找7
- 1
- 2
- 3
- 4
- 5
5.3 测试方法
字符串中会包含多种类型的数据,像整数、大小写字母、符号和转义字符。我们要判断字符串中是否包含相应数据类型的字符,就需要借助测试方法。
常用的测试方法有isalnum()、isalpha()、isdigit ()、islower()、isupper()、isspace()。
5.3.1 isalnum()方法
isalnum()方法用来判断字符串中是否只包含字母或数字,并且长度要大于0,满足的话就返回True,否则返回False。
my_str = 'www.dotcpp.com'
print(my_str.isalnum()) # 判断是否只包含字母和数字
s = 'dotcpp123456'
print(s.isalnum())
- 1
- 2
- 3
- 4
- 5

因为my_str中不仅仅包含字母和数字,因此返回Flase
s字符串中只包含字母和数字,因此返回True。
5.3.2 isalpha()方法
isalpha()方法用来判断字符串中是否只包含字母,并且长度大于0,满足的话就返回True,否则返回False。
my_str = 'www.dotcpp.com'
print( my_str.isalpha()) #判断是否只包含字母
s = 'dotcpp'
print(s.isalpha())
- 1
- 2
- 3
- 4
- 5
- 6

5.3.3 isdigit ()方法
isdigit()方法用来判断字符串中是否只包含数字,并且长度大于0,满足的话就返回True,否则返回False。
5.3.4 islower()方法和isupper()方法
判断字符串中是否只包含小写字母和大写字母
my_string= '99+1=100'
print(my_string.isdigit())
s = '1234567'
print(s.isdigit())
- 1
- 2
- 3
- 4
- 5

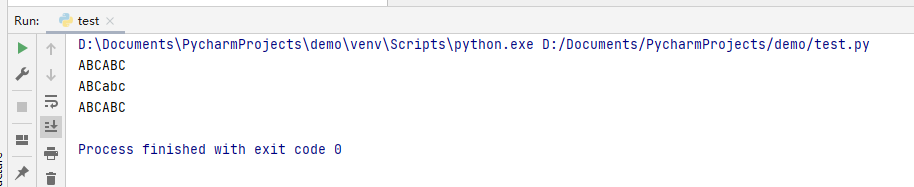
s = 'ABCabc'#字符串s包含大写字母和小写字母
print(s.islower())
print(s.isupper())
print(s.isalpha())
s1 = 'abc'#s字符串只包含小写字母
s2 = 'ABC'#s字符串只包含大写字母
print(s1.islower())
print(s2.isupper())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

5.3.5 isspace()方法
isspace()方法用于判断字符串是否只包含空白字符(空格、换行(\n)和制表符(\t)),
并且长度大于0,满足条件返回True,否则返回False。
my_str = ' \n \t '#其中包含五个字符,三个空格,一个换行,一个制表符
print(len(my_str)) #看一下长度
print(my_str)
print(my_str.isspace()) #判断是否为空白字符
- 1
- 2
- 3
- 4
- 5

小结:
这几个方法的使用比较类似,都是在测试通过之后返回True,而错误则返回False,我们通常会使用if语句结合使用,当if语句成立之后,即判断字符串中所包含内容成立之后再执行相关语句,如果判断为False则执行另外语句。
5.4 字符串修改、搜索和替换方法
5.4.1 lower()方法和upper()方法
前者是返回一个副本,副本中把字符串中所有字符转换为了小写字符,而后者是返回一个副本,副本中把字符串中所有字符转换为了大写字符。
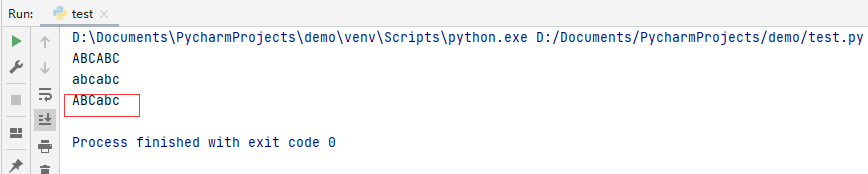
my_str = 'ABCabc'#包含大小写字母的字符串
c= my_str.upper()#将字符串全部大写
print(c)
c= my_str.lower()
print(c)
print(my_str)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
一定要注意的就是返回的是副本,使用了方法,但是原始字符串是没有改变的,
如果我们要获取副本,可以另取名,也可以直接覆盖。
my_str = 'ABCabc'#包含大小写字母的字符串
c= my_str.upper()#将字符串全部大写
print(c)
print(my_str)
my_str = my_str.upper()#直接覆盖
print(my_str)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5.4.2 lstrip()方法、rstrip ()方法和strip()方法
这三种方法的原理类型,他们都是用于处理字符串中的空白字符。
1) lstrip()方法会返回一个副本,副本中的字符串删除所有前导的空白字符。
2) rstrip()方法会返回一个副本,副本中的字符串删除所有后导的空白字符
3) strip()方法会返回一个副本,副本中的字符串删除所有前导和后导的空白字符。
my_str = ' \n\t www.dotcpp.com \t\n '
a = my_str.rstrip()#返回删除后导空白字符的副本
print(a)
b = my_str.lstrip() # 返回删除前导空白字符的副本
print(b)
c = my_str.strip()#返回删除前导后导空白字符的副本
print(c)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

综合代码和上图来理解一下这个例子,通俗的讲,前导返回的副本删除了前面部分,后导返回的副本删除了后面部分,而strip()方法返回的副本把前导后导一并删除。
5.4.3 搜索方法
需要搜索字符串中的元素,除了前面讲过的find()方法和index()方法,我们有时候还需要用到endswith()方法和startswith()方法。
- endswith()方法
它的语法格式为:
my_str.endswith(substring)
- 1
my_str为字符串名,substring参数是一个字符串,如果在该字符串的结尾为substing,那么返回True,反之返回False。
- startswith()方法
它的语法格式为:
my_str.startswith(substring)
- 1
my_str为字符串名,substring参数是一个字符串,如果在该字符串的开头为substing,那么返回True,反之返回False。
my_str = 'www.dotcpp.com'
a = my_str.endswith('.com')
print(a)
b = my_str.startswith('www.')
print(b)
- 1
- 2
- 3
- 4
- 5

5.4.4 替代方法——replace()
replace()方法返回一个副本,副本中将我们需要替代的字符替换掉
它的语法格式为:
my_str.replace(old,new)
- 1
my_str为字符串名,old为要替换掉的字符,new为替换上的字符。
my_str = 'www.dotcpp.com'
a = my_str.replace('w','m')
print(a)
- 1
- 2
- 3

这种方法替换的时候仍然是返回的副本,它会替换掉所有需要替换的字符,保持原字符串是不改变的。
5.5 格式化字符串
格式化字符串就是在先创建一个空间,然后再这个空间留几个位置,然后根据需求填入相应的内容,这里留出的位置相当于占位符,
格式化字符串有两种方式,一种是使用%操作符,一种是使用format()方法。
5.5.1 %操作符
语法结构如下:
'%[+][-][0][.m]格式化字符' %iteration
- 1
1) iteration为我们要填入的内容,第一个%后面为我们要选择的格式。
2) [+]为右对齐‘+’为我们可以填入的参数,数字大小代表对齐宽度。
3) [-]为左对齐‘-’为我们可以填入的参数,数字大小代表对齐宽度。
4) [.m]中的m为可选精度,表示保留小数点后几位小数。
5) 格式化字符为我们需要选定的格式,它的常用类型为字符串%s、十进制整数%d、单字符%c、浮点数%f、十六进制数%x、八进制数%o、字符%%。


my_str =66666.66666
print('保留2位小数格式为:%.2f' % my_str)#保留2位小数格式为: 66666.67
- 1
- 2
格式化部分为‘%.2f’,然后再字符串的最后用%连接相应字符串即直接等同于相应内容。
保留小数的时候会自动进行四舍五入操作
for i in range(5):
print('%-5d'%i,end=' ')#'-':左对齐方式
print('%5d'%i) #'+':右对齐方式
- 1
- 2
- 3

我们采用左右对齐,5是代码对齐的宽度,
第一列为左对齐,宽度为5,然后不换行再次输出i,
第二次输出为右对齐,因此输出入上所示。
5.5.2 format()方法
参考学习
format()方法提供了更多的方法去格式化字符串,它的基本语法是通过‘{}’和‘:’来代替‘%’。它的语法格式为:
str.format()
- 1
namea = '小明'
nameb = '小华'
print('{}是{}的好朋友'.format(namea,nameb))
- 1
- 2
- 3

具体方法, 在占位符里结构可以为:

- index为索引位置,我们可以给他一个数字,用来指定对象在列表中的索引位置(format中的位置),索引值从0开始,如果没有索引值,按从左到右的顺序。像上面的例子,我们如果加了索引值:
namea = '小明'
nameb = '爸爸'
namec = '警察'
print('{0}的{1}是{2}'.format(namea,nameb,namec))
- 1
- 2
- 3
- 4
- 5

那么他们的位置就进行了一个调换。
2) ‘:’为后续内容使用的前提,使用后面操作的时候都要加一个‘:’。
3) fill 可以选择一个参数作为空白填充的字符数。
4) width 是可以选择一个参数来指定长度。
5) align 可以选择一个参数作为对齐方式,参数为‘>’代表右对齐,‘<’为左对齐,‘=’为右对齐,但是符号放在最左侧,‘^’代表居中,这些需要搭配width使用。
my_str = 'dotcpp'
print('{:@>10}'.format(my_str))
- 1
- 2

这个例子里我们选择了右对齐,然后宽度为10,空白字符用符号@代替。
6) ‘#’为进制前缀。
7) .k中的k是可选参数,用来表示小数点后保留的数字。
8) type可选择参数来指定类型,常用的有S来表示字符串、D来表示十进制整数、%来表示百分比、f或者F表示浮点数。
my_str = 'dotcpp'#先定义两个字符串
my_string = 123456.654321
print('my_str:{1:!^20s}\nmystring:{0:$^20.2f}'.format(my_string,my_str))
- 1
- 2
- 3
- 4

对于my_str,‘1‘为它的索引位置,‘!’来替代空白字符,‘^’代表位置居中,20为宽度,‘s’为字符串类型。
对于my_string,‘0’位它的索引位置,‘$’来代替空包字符,‘^’代表位置居中,20位宽度,‘.2’为小数点后保留2位小数,’f‘为浮点类型。


