
- 1Streamlit自定义组件开发教程_streamlit教程
- 2Android 图片选择器,相机拍摄和图库选择,并进行裁剪_intent.action_pick intent.action_get_content inten
- 3【数据结构】七大排序算法(超详细)_数据结构排序
- 4深度学习 -- 什么是张量 pytorch中张量的几种创建方法_三维张量
- 5Eclipse打开出错:Java wa started but returned exit code=13_javawa
- 6Python 操作 Excel,如何又快又好?
- 7忆本科四年,感谢遇见 - 写在毕业一年后_大学四年遇到了很多人
- 8Java项目:在线服装销售商城系统(java+SpringBoot+Maven+Vue+mysql)_class shoppingcontroller extends basecontroller
- 9numpy 点乘_玩转张量点乘和变形
- 10Hive与Oracle之间利用Sqoop进行数据的导入导出_hive 到 oracle at org.apache.sqoop.manager.oraclema
PostgresSQL HA高可用架构实战
赞
踩
本文由萧少聪在高可用架构群所做的分享整理而来,转载请注明高可用架构公众号:ArchNotes。
萧少聪(花名:铁庵),广东中山人,阿里云RDS for PostgreSQL/PPAS云数据库产品经理。自2006年以来,长期从事RedHat及SuSE Linux的HA集群搭建及PostgreSQL数据库支持工作。2011年开始组建Postgres(数据库)中国用户会。
PostgreSQL背景介绍
有不少同学希望了解PostgreSQL的背景及它与MySQL的对比结果,所以在此啰唆两句,有兴趣的同学可以单独给我发E-Mail,我可以分享详细的介绍及一些对比结果。
2015年是PostgreSQL正式在中国起步的一年,我们看到越来越多的企业选择了PostgreSQL。
中国移动主动使用PostgreSQL实现分布式数据库架构。
金融业方面平安集团明确表示将使用PostgreSQL作为新一代数据库的选型。
华为中兴纷纷加入PostgreSQL内核研究队伍。
阿里云正式提供PostgreSQL服务。
大部分人了解MySQL应该都是从2005年左右开始,那时在互联网带动下LAMP空前繁荣。而你所不知道的是,那时PostgreSQL已发展了近30年,至今已经超过40年。1973年MichaelStonebraker(2014年图灵奖得主)在伯克利分校研发了当前全球最重要的关系型数据库实现:Ingres。此后,陆续改名为Postgres、Postgres95,直到现在的PostgreSQL。PostgreSQL有众多的衍生品牌产品,就如同Linux有RedHat、SUSE、Ubuntu一样,当前,国内多个国产数据库都是基于PostgreSQL进行开发的,同时,国际知名的针对OLAP场景的Greenplum数据库,及EnterpriseDB公司高度兼容Oracle语法的PPAS数据库也是基于PostgreSQL实现。
PostgreSQL与MySQL相比功能更为完善,同时,在进行复杂SQL查询时(特别是多表进行JOIN查询)性能及稳定性也更为优秀,是国外企业首选的应用于核心业务系统的开源OLTP业务关系型数据库引擎。PostgreSQL被誉为全球最先进的开源数据库,支持NoSQL JSON数据类型、地理信息处理PostGIS、丰富的存储过程操作,并可实现基于Tuple(在PostgreSQL中此单位比Block还要小)级别的StreamingReplication数据同步。
与MySQL不同,PostgreSQL不支持多数据引擎。但支持Extension组件扩充,以及通过名为FDW的技术将Oracle、Hadoop、MongoDB、SQLServer、Excel、CSV文件等作为外部表进行读写操作,因此,可以为大数据与关系型数据库提供良好对接。
在PostgreSQL下如何实现数据复制技术的HA高可用集群
业界大多数的数据库的HA实现都是基于共享存储方式的,如下图。在这个方式下,数据库1主1备,使用一个共享存储保存数据。
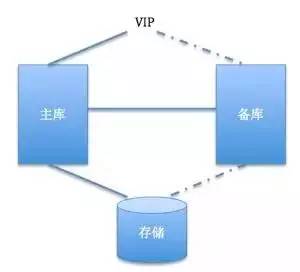
正常情况下主库连接存储及VIP,进行数据业务处理。备库永远处于非运行状态,只有当主库出现故障后,备库才会进行存储及VIP的接管。但传统的企业中,这样的结构比比皆是,在我进入阿里云之前服务过的大多数企业都使用这样的架构(除了Oracle RAC及DB2的并行方案)。而当今,无论Oracle、MySQL、SQLServer,还是今天我们用作说明案例的Postgres,都已经支持基于数据库底层的StreamingReplication模式实现数据复制了,同时支持备库作为只读服务器提供业务服务。因此,备库资源对于企业来说是极大的浪费。
传统的HA方案在实现基于Streaming Replication方式时,往往需要通过大量人为控制的脚本进行判断和控制。2006年到2011年,我为不同的客户及不同的数据库编写了多种特制的脚本,当中的安装配置及维护难度都有点让人望而却步。2011年,我在SUSE系统的HA支持工作中接触到了Corosync +Pacemaker的HA结构。发现了 “Master-Slave模式”。在这个模式下,系统支持promote及demote,以解决数据库基于Streaming Replication主备模式的切换问题。
Corosync + Pacemaker MS 模式介绍
本次讲解主要针对架构及这个模式的处理原理。如果大家想要了解具体的配置方式,可以参考http://clusterlabs.org/wiki/PgSQL_Replicated_Cluster。同时,当前最新的Red Hat Enterprise Linux 7及SUSE Linux Enterprise Server 11/12中的HA组件都基于此架构,你也可以通过厂商的官方文档或官方技术支持得到配置的详细说明。
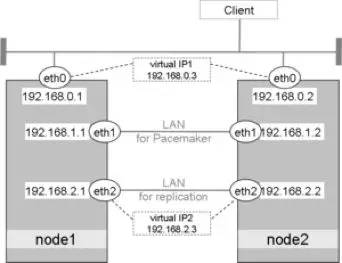
上图有3个网段:0.x网段,用于数据库对外业务;1.X网段,用于Pacemaker心跳通讯;2.X网段,用于数据库的数据复制。同时提供主库读写服务VIP1 192.168.0.3和备库只读服务VIP2 192.168.2.3。用户的主应用程序可以通过VIP1进行读写操作,而只读处理可以通过VIP2实现。
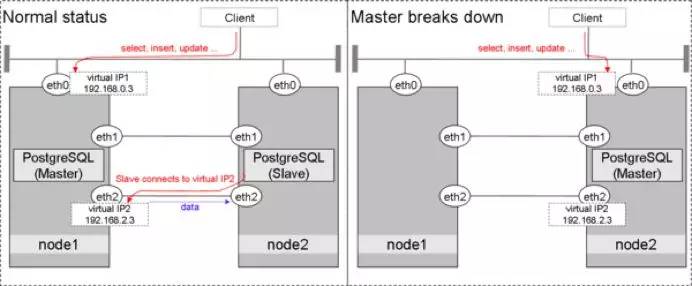
上图中,左边是正常运行的模式:所有读写操作通过VIP1进入到Master节点;Slave节点的会连接到VIP2,通过此IP支持只读操作;Streaming Replication通过eth2进行两节点的数据同步。右边是Master故障时的模式:原Slave会promote成为Master节点;VIP1切换到node2继续提供服务;VIP2切换到node2继续提供服务。
在此处,系统从node1切换到node2有多种可能性。
1. Master节点通过pacemaker控制人为进行Switchover切换。这种情况下主备模式会进行调换,并且过程中可以保证所有Master节点中的数据会复制到Slave后再进行node2上的promote操作。因此,数据库中所有的事务都是完整的,且不会出现任何数据丢失。这种情况大多用于硬件需要进行主动维护时。
2. Master节点意外出现故障时,将进行Failover。由于PostgreSQL在双节点推荐使用的是async模式,因此如果Master节点故障时还有数据没来得及复制到Slave。这些数据将丢失,但由于PostgreSQL的Streaming Replication是以事务为单位的,因此数据库的事务一致性是可以得到保障的,绝对不会出现备库中某个事务只恢复到一半的情况。
当前有一个比较严重的问题,就是如上图所示,切换后node1如果想要重新成为主节点,将需要重新进行全量的数据复制恢复。这是因为Master故障时如果有数据没复制到Slave,Master的最后一个事务时间将比Slave中的事务时间更新(如Master最后一个事务号为1001,但Slave中的事务只恢复到999)。此时Slave节点promote成为新的Master后,所有新的操作将由999号事务的结果为基础。也就是说原Master中的1000及1001事务所处理的数据将不可恢复。由于在当前设计中数据库中已经提交的事务不支持直接回退,所以,如果你的数据库到达TB级别,这将需要6~7小时。
但这个情况很快将会被改善。PostgreSQL9.5将为用户提供pg_rewind功能。当Master节点Failover后,原Master节点可以通过pg_rewind操作实现故障时间线的回退。回退后再从新的主库中获取最新的后续数据。因此,虽然之前没有提交的事务由于ACID原则无法重新使用,但原Master的数据无须进行重新全量初始化就可以继续进行Streaming Replication,并作为新的Slave使用。
Corosync + Pacemaker M/S 环境配置
以下内容中截图来自于http://clusterlabs.org/wiki/PgSQL_Replicated_Cluster。
Corosync + Pacemaker M/S配置环境准备
RA:Resource Agent资源代理,PostgreSQL最新的RA可以通过https://github.com/ClusterLabs/resource-agents/blob/master/heartbeat/pgsql下载。如果你发现这个RA不符合你的需求,也可以自行改写。
操作系统版本:Fedora19及以上、Red Hat Enterprise Linux 7及以上、SUSE Linux Enterprise Server 11 SP3及以上。
数据库要求:PostgreSQL9.1及以上,由于PostgreSQL 9.1以上才支持Streaming Replication,因此,比这个版本低的数据库无法实现此功能。
两台服务器配置相同的NTP时间源及相同的时区。
通过yum、zypper安装pacemaker(主要用于HA资源管理)、corosync(HA心跳同步控制)、pcs3(HA的命令行配置工具)。通过yum、zypper或任何其他方式安装PostgreSQL数据库,安装时务必确认其pg_ctl命令、psql命令、data目录的存放位置,因为配置时要用到。

PostgreSQL Streaming Replication配置
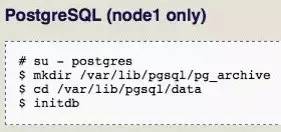
在node1中初始化PostgreSQL数据库。
对其postgresql.conf文件做如下修改。
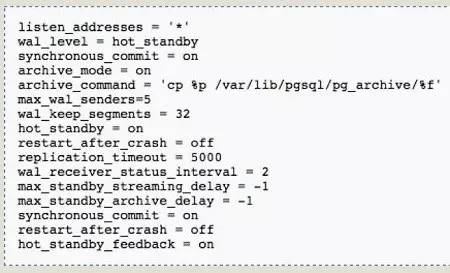
注意:wal_level = hot_standby,使得日志支持Streaming Replication;archive_mode = on,启动归档模式;archive_command = 'xxx',指定归档的保存方法;hot_standby = on,备库启动为standby模式时可实现只读查询;其他参数主要用于性能及延迟的设定。
将data目录下的pg_hba.conf文件做如下修改。

注意:这样配置后,所有192.168.x.x网段的IP都将可以无密码对此数据库进行访问,安全性可能会降低。因此,只作为练习使用,在生产环境中请严格控制IP。如指定只trust某IP可以写成192.168.100.123/32。
配置完成后,启动node1上的PostgreSQL。

在node2进行数据初始化。
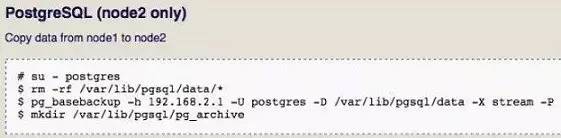
注意:通过pg_basebackup命令将从node1中将所有数据库中的数据都同步到/var/lib/pgsql/data去。
数据basebackup完成后,在node2中的data目录下建立recovery.conf文件并录入以下内容。

注意:primary_conninfo指定了主服务器所在的位置、replicate所使用的用户名。由于我们在pg_hba.conf中使用trust方式,所以在此参数中不需要加入password。
配置完成后,启动node2上的PostgreSQL,准备检查同步效果。
如果在node1中通过psql命令登录数据库后可以得到以下信息,证明数据库端的Replication已运行正常。

自此,PostgreSQL的Streaming Replication配置完成,两个数据库的数据将进行持续复制。
注意:以上两个服务器已经完成Streaming Replication配置,在配置HA前请将两个服务器上的PostgreSQL都停止。因为在HA架构中,所有资源都应该是由HA软件进行管理的,所以与此同时也请确认系统启动时PostgreSQL不会自动启动(你可以通过chkconfig检查)。

Corosync + Pacemaker HA 基础配置
corosync配置文件只有一个,/etc/corosync/corosync.conf。
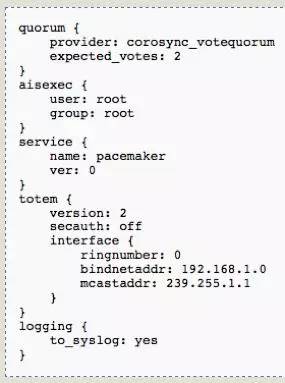
我们可以看到,当前quorum中expected_votes为2,这是因为我们使用2节点。totem中有bindnetaddr:192.168.1.0及mcastaddr: 239.255.1.1,这里说明corosync会使用本服务器上192.168.1.X网段的IP作为心跳。此处注意,不需要写明此IP的详细地址,系统会自动发现。通过scp命令将此文件复制到node2中相同的目录并保证其权限一致。
接下来就可以在两个节点中启动corosync了。以下是系统在Fedora 19、RHEL7、SUSE12后的服务启动命令。如果你使用的是低版本操作系统,请用/etc/init.d/corosync start或service corosync start 。

pacemaker默认情况下是无污染的,但为了保证HA初始状态我们会进行以下操作。此操作会清空所有HA资源的配置。它在另外一些情况下也十分实用,如有时我们会发现两个节点HA启动时资源信息不同步。此时我们可以先择定一个可信的节点,然后将另一节点上的cib文件清空,然后进再启动pacemaker,这样新节点就会自动同步现有节点的所有配置。
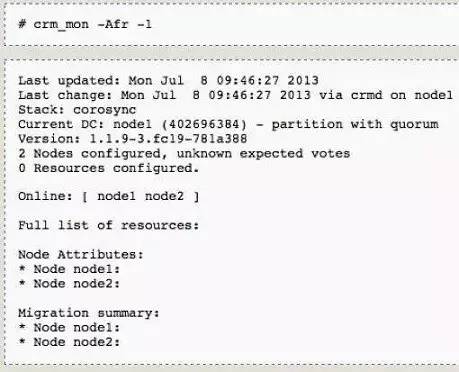
Pacemaker资源配置
通过pcs命令行工具进行HA资源的配置。pcs命令行可以协助生成名为config.pcs的配置脚本,以进行最后的HA配置导入。首先,我们进行一个全局信息的配置,指明由于当前是2节点,所以忽略no-quorum-policy;默认的resource-stickiness为INFINITY,即任何资源默认都是与其他资源可共同运行的;•默认的migration-threshold为1,即任何情况下migration时都会重试一次。

注意:stonith-enabled="false"表示不使用任何电源控制设备,这个情况不建议在生产中使用。熟悉RHEL集群的同学可以认为Stonith等同于Fence设备。
配置VIP1及VIP2,以及pgsql资源。
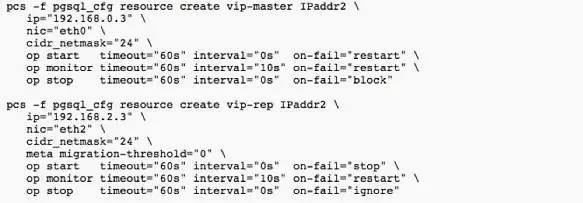
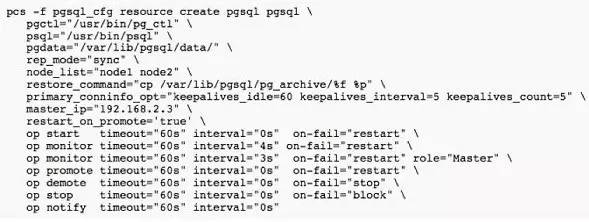
vip-master(VIP1)及vip-rep(VIP2)相对比较好理解。而在pgsql资源中,如果大家有熟悉Linux集群的会发现,一般情况下HA中添加应用资源都会加入一个带有start/stop/status的脚本。而此处是通过一个agent实现,我们只要配置好PostgreSQL的pgctl、psql、pgdata的文件或目录位置即可,处理十分方便。主要因为PostgreSQL RA已经包含start|stop|status|monitor|promote|demote|notify的操作脚本(https://github.com/ClusterLabs/resource-agents/blob/master/heartbeat/pgsql)。感谢开源,感谢贡献者吧,这里头有2070行代码,相比我以前自己写的要精妙得多。
将以上的IP及pgsql资源进行关联,这也是pacemaker最精妙的地方。我们可以看到,首先,有一个“resource master”我们命名为msPostgresql,pgsql属于这个Master模式资源。这个模型的资源,基于clone模型,将会在两个节点同时启动。然后,建立了一个master-group,将vip-master及vip-rep加到这个组中。接下来,constraintcolocation指定了master-group中的资源(vip-master及vip-rep)倾向于与msPostgresql的Master节点运行在一起。最后,orderpromote及order demote负责管理节点的启动顺序。

注意:Master节点会由RA自动识别;msPostgresql进行promote以后才会进行master-group的IP挂接;同时,在进行demote时也是只有等msPostgresql完成停库后才进行master-group的IP断开处理。

此处的config.pcs是由前面的pcs所生成,通过crm_mon你可以看到所有的资源情况。
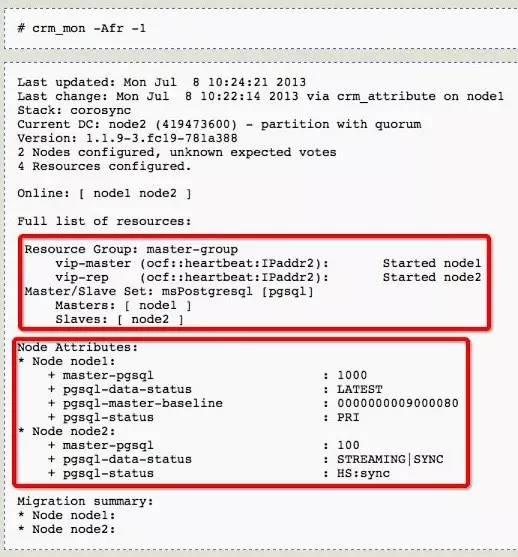
自此所有配置结束,你可以将node1中PostgreSQL的data目录mv到其他地方看看切换的效果,不再赘述。
关于排错,所有HA日志信息会保存在/var/log/message中。如果系统有问题,可以通过此日志进行分析。但有一点很重要,建议大家在配置HA前一定要确认NTP服务是否正常,保障两个服务器时间不要差距太大。不然排错会很麻烦,还会有可能导致集群的其他问题。
过去两年,这样的集群架构已经在很多企业使用,数据量多在20G到1T之间。PG是一个用于OLTP的系统,当前我所实施的企业大多是传统行业。大部份用户主要是从Oracle迁移来的。在大数据及分析方面,会先用Greenplum或Hadoop等进行处理,这时PostgreSQL也可以使用FDW功能进行对接。
PostgreSQL Sync模式当前的问题
前面提到当前PostgreSQL在2节点情况下推荐使用的是async的模式,那sync是不是不支持?不是的,当前PostgreSQL支持sync模式,即使2节点也可以配置,但会有以下问题:
由于sync同步模式要求Master在Slave数据写入成功后才结束事务的Commit操作,因此性能会受到影响。
如果系统运行过程中slave出现故障,主节点也将受到影响使系统出现故障,在HA下这也会Failover。Pacemaker当前最新的PostgreSQLRA也还没有解决此问题。
如果需要使用sync模式的Streaming Replication,我建议搭建1主2备的模型实现,而这个模型下Pacemaker还没有提供3节点的实现方案,尚待改进。
最后简单介绍一下“PostgreSQL中国用户会”,Postgres中国用户会是一个非营利团体,致力于为中国的PostgreSQL用户服务,当前各QQ及微信群已经有超过4000人规模,在过去的2周我们在全国9个城市举办了名为“象行中国 Let'sPostgres”的线下技术沙龙,同时支持了香港及台湾地区的PostgreSQL技术活动。
Q&A
Q1:排除年限,PG相对MySQL和Oracle有啥优势?
A1:PG有很多MySQL没有的功能,就以O2O行业为例,PG直接提供PostGIS,可以有效地在数据库中通过SQL进行复杂的定位查询并与业务直接关联,更多功能欢迎线下交流。
Q2:金融企业中用async复制,怎么应对数据丢失?靠对账么?
A2:首先,金融行业中如果要求100%数据不丢失,应该使用sync而不是async,这个功能PostgreSQL是支持的,只是要用3节点方案。当前在这个方案下进行HA切换也是可以的,只是Corosync+Pacemaker没有直接支持,需要我们对RA进行附加的脚本控制。
Q3:threshold设置为1时,尝试1次,如果再有问题就直接切换了。设置为2时, 2次尝试,这个计数器不会在成功后恢复原值,该测试结果是否正确?
A3:是的,意思就是尝试1次,在Pacemaker这些值都是有限时的,超时就会恢复原值,你可以通过clean操作对这个节点上的计数器进行数值恢复操作。
Q4:MySQL的binlog处理和PG的有什么区别?
A4:MySQL我只用过4及以下版本,对binlog不是十分了解,与公司MySQL大牛讨论中,我感觉这两个方式是很接近的,都是使用日志进行恢复。但PostgreSQL的操作中会以Tuple为单位,这个可能是一个row,甚至就是某个row中被修改过的1个字段的值。有一个讨论结果是PG的StreamingReplication粒库更细。
Q5:3节点方案写成功2个就返回,还是,3个都成功才返回?
A5:3节点情况下,系统中有2个节点是同步,第3个是异步,所以成功2个就返回。
Q6:PG的HA除了今天分享的还有其他方案吗?
A6:PG的HA还可以用LiveKeeper、微软的MSCS等方案,对于HA来讲PG就只是一个服务,所以任何HA软件都可以与PG对接,但如果要进行StreamingReplication的切换就要自己写脚本了。
Q7:我感觉PG这个HA相比MySQL自带的主从没多大亮点。PG有类似mysql-proxy这样的负载均衡中间件及MMA这类解决方案吗?之前听说PG在集群这块不是更好,方案复杂且性能损失大,是不是PG还是更适合单机?
A7:当前PG业界可以通过PGPool实现1个Master进行读写,n个Slave进行只读负载均衡的方案;PG分布式集群当前方案的Postgres-X2,确实复杂,我们这方面也正在努力;单机的这个问题上,我们有很多PG用户会选择通过应用程序自定义进行分库集群模型,毕竟在要求强一致性又没有InfiniBand或更高级的网络的情况下,事务和延迟都不好在传统集群中解决。
Q8:PG有sharding功能吗?能否简单介绍一下。
A8:最近PG出现了一个名为pg_shard的第三方组件,可以对数据库中的一个特定的表进行sharding,可以扩展到64台服务器,但不保证此表的事务,一些分析场景可以考虑尝试。
Q9:能否简单对比一下PG的HA方案?
A9: Corosync + Pacemake,支持Replication模式,在Linux下这是我个为最推荐的方案,共享存储同样也没有问题;原RHEL中的RHCS,配置简单,如果有共享存储,Linux下这个方案最方便,但要注意RHCS是要求付费使用的;LiveKeeper,配置相对复杂一些,如果要支持Replication需要写比较复杂的脚本;微软MSCS,Windows平台必备,中国还真有几个用户是这样用的;VCS,跨Windows及Linux平台但同样只建议在有共享存储情况下使用。
Q10: PG的表分区和MySQL的表分区差别在哪?各自的优点在哪?我印象中PG分区表对外会显示成单独的一个分区表,分区多了很难看。
A10:PG默认的表分区基于对象数据库结构的表集成,通过触发器进行数据调度,表大了以后性能很差,据说在9.6以后(当前9.4)会改善。在此打个广告,分区表性能在阿里云的PPAS中已经得到解决,2~1000个表分区性能表表现恒定,不会因为表分区越来越多导致性能瓶颈。
本文策划启明@迅雷,内容由余长洪@暴走漫画编辑,刘芸@博文视点校对与发布,其他多位志愿者对本文亦有贡献。更多关于架构方面的内容,读者可以通过搜索"ArchNotes"或点击页首的蓝字,关注"高可用架构"公众号,查看更多架构方面内容,获取通往架构师之路的宝贵经验。转载请注明来自"高可用架构(ArchNotes)"微信公众号。


