
热门标签
热门文章
- 1【Pytorch学习】-- 模型参数更新-- Loss Function & Optimizer_pytorch多个损失怎么更新
- 2在Linux系统上安装Wine方法教程_linuxxiezaiwine教程
- 3《Python编程从入门到实践》外星人入侵游戏——添加 飞船 图片和外星人 图片,素材_游戏外星人入侵的飞船图片
- 4深度学习中初始学习率设置技巧
- 5第一次参赛获Java B组国二,给蓝桥杯Beginners的6700字保姆级经验分享。_蓝桥杯java组经验贴
- 6【Linux内核链表】的原理及使用方式整理_linux内核链表的使用
- 7使用GPT-4,学渣比学霸更有优势
- 8【游戏开发创新】Unity+人工智能,让小朋友的画成真,六一儿童节一起来画猫猫吧(Unity | 人工智能 | 绘图 | 爬虫 | 猫妖)_unity 粒子绘画
- 9STATUS_STACK_BUFFER_OVERRUN encountered
- 10u-boot spl 学习总结_uboot spl
当前位置: article > 正文
Python爬虫-利用xpath解析爬取58二手房详细信息_xpath爬取58
作者:IT小白 | 2024-03-05 16:26:38
赞
踩
xpath爬取58
前言
简单的Python练习,对页面中的某些部分的文字进行爬取
介绍
xpath解析: 最常用且最便捷高效的一种解析方式。通用型。 -xpath解析原理: - 1. 实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中。 - 1. 调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获。 环境的安装: - pip install lxml -如何实例化一个entree对象:from lxml import etree - 1. 将本地的html文档中的源码数据加载到etree对象中: etree.parse(filePath) - 2. 可以将从互联网上获取的源码数据加载到该对象中 etree.HTML('page_text') -xpath('xpath表达式') -xpath表达式: - /:表示的是从一个根节点开始定位,表示一个层级。 - //:表示的是多个层级,可以从任意位置开始定位。 - 属性定位://div[@class='song'] tag[@attrName='attrValue'] - 索引定位://div[@calss+'song']/p[3] 索引是从1开始的。 - 取文本: - /text() 获取的是标签中的直系文本内容 - //text() 获取的标签中的非直系的文本内容(所有的文本内容) - 取属性: /@attrName ==>img/src

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
代码
import requests from lxml import html etree = html.etree headers ={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.55' } url ='https://shangshui.58.com/ershoufang/?' page_text = requests.get(url=url,headers=headers).text #print(page_text) tree = etree.HTML(page_text) li_list = tree.xpath('//section[@class="list"][1]/div') # print(li_list) fp = open('58.txt','w',encoding='utf-8') for li in li_list: title = li.xpath('./a//div[@class="property-content-detail"]//text()') price= li.xpath('./a//div[@class="property-price"]//text()') # print(price) titles='' prices='' for i in range(len(title)): if title[i]!=', ' and title[i]!=' ': titles += title[i].strip() titles += " " i+=1 for j in range(len(price)): if price[j]!=', ' and price[j]!=' ': prices +=price[j].strip() prices +=" " j+=1 titles_and_prices= titles+prices+'。\n' fp.write(titles_and_prices) print(titles_and_prices)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
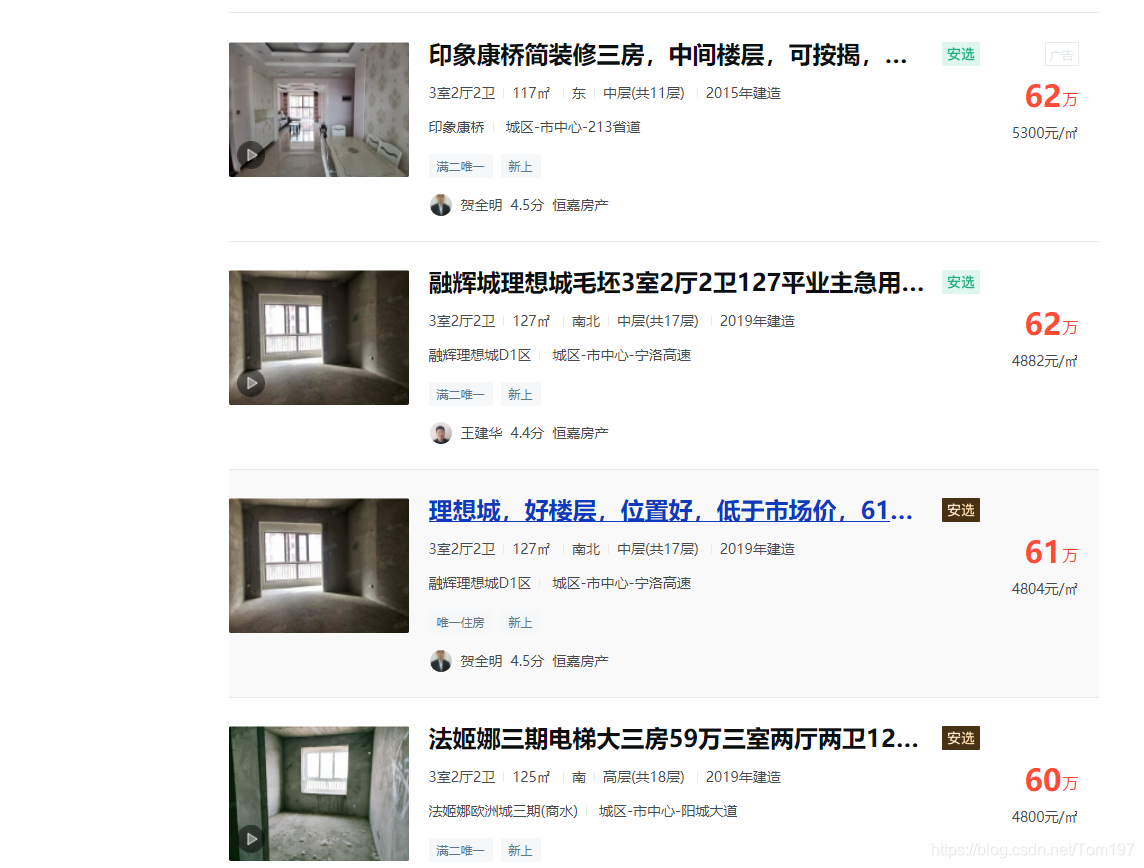
运行结果截图



声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/192339
推荐阅读
相关标签

