
- 1ChatGPT扩展系列之ChatGPT 生成图片_chatgpt生产图片
- 2【Unity Shader】Properties属性定义中bool类型无法使用的替代_unity shader bool
- 3Java 使用正则表达式提取字符串中的时间(年月日时分秒)_java正则找出年月日时分秒的函数
- 4面试 JavaScript 框架八股文十问十答第七期
- 5TResNet: ResNet改进,实现高精度的同时保持高 GPU 利用率_resnet50 stem块
- 6R语言学习笔记——空间自相关:全局Moran’I/局部Moran’I /Geary’c/Moran散点图_r语言 空间自相关
- 7Windows 下后台启动 jar 包,UTF-8 启动 jar 包_windows启动jar
- 8linux日志管理_viovio手机怎么查激活日期
- 9spring mvc整合shiro登录 权限验证_systemauthorizingrealm
- 10点云综述一稿 点云硬件、点云软件、点云处理算法、点云应用以及点云的挑战与展望
残差网络(ResNets)的残差块(Residual block)
赞
踩
来源:Coursera吴恩达深度学习课程
五一假期结束了,听着梁博的《日落大道》,码字中。非常非常深的神经网络是很难训练的,因为存在梯度消失和梯度爆炸问题。跳跃连接(Skip connection)可以从某一层网络层获取激活,然后迅速反馈给另外一层,甚至是神经网络的更深层。利用跳跃连接构建能够训练深度网络的ResNets,有时深度能够超过100层。ResNets是由残差块(Residual block)构建的,首先看一下什么是残差块。

上图是一个两层神经网络。回顾之前的计算过程:
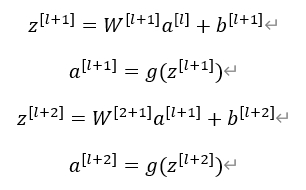
在残差网络中有一点变化:
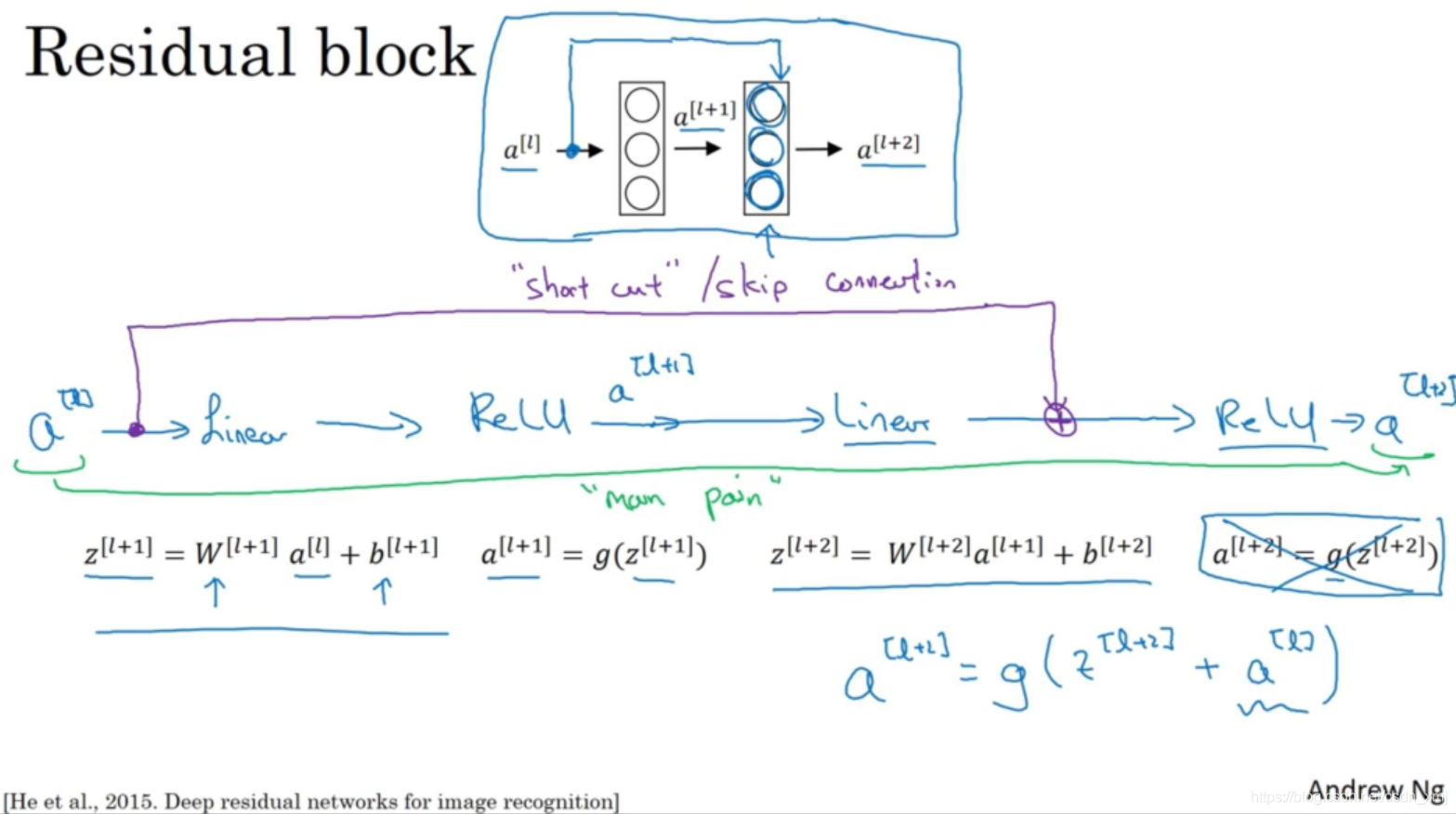
如上图的紫色部分,我们直接将a^[l]向后,到神经网络的深层,在ReLU非线性激活函数前加上a^[l],将激活值a^[l]的信息直接传达到神经网络的深层,不再沿着主路进行,因此a^[l+2]的计算公式为:
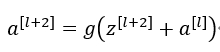
加上a^[l]后产生了一个残差块(residual block)。插入的时机是在线性激活之后,ReLU激活之前。除了捷径(shortcut),你还会听到另一个术语“跳跃连接”(skip connection),就是指a^[l]跳过一层或者好几层,从而将信息传递到神经网络的更深层。
ResNet的发明者是何恺明(Kaiming He)、张翔宇(Xiangyu Zhang)、任少卿(Shaoqing Ren)和孙剑(Jiangxi Sun),他们发现使用残差块能够训练更深的神经网络。所以构建一个ResNet网络就是通过将很多这样的残差块堆积在一起,形成一个很深神经网络。首先回忆一个普通网络(Plain network),这个术语来自ResNet论文。如下图:

变成ResNet的方法是加上所有跳跃连接,每两层增加一个捷径,构成一个残差块。如下图所示,5个残差块连接在一起构成一个残差网络。

假设使用标准优化算法(梯度下降法等)训练一个普通网络,如果没有残差,没有这些捷径或者跳跃连接,凭经验你会发现随着网络深度的加深,训练错误会先减少,然后增多。而理论上,随着网络深度的加深,应该训练得越来越好才对,网络深度越深模型效果越好。但实际上,如果没有残差网络,对于一个普通网络来说,深度越深意味着用优化算法越难训练,随着网络深度的加深,训练错误会越来越多。
但有了ResNets就不一样了,即使网络再深,训练的表现却不错,比如说训练误差减少,就算是训练深达100层的网络也不例外。对x的激活,或者这些中间的激活能够到达网络的更深层。这种方式有助于解决梯度消失和梯度爆炸问题,在训练更深网络的同时,又能保证良好的性能。
说明:记录学习笔记,如果错误欢迎指正!转载请联系我。

