
- 1十六进制转十进制JAVA(蓝桥杯练习)_java十六进制转十进制 蓝桥杯
- 2java学习之道 --- 如何学习java?
- 3python-----跳转语句_python怎么跳转到某一句代码
- 4【惊喜福利】Docker容器化部署nextcloud网盘,享受高速稳定的文件共享体验!_nextcloud docker优化速度
- 5pycharm安装pyLDAvis出现错误_pyldavis安装失败
- 6MySQL的redo log 、binlog和undolog_mysql binlog redolog undolog
- 7深入理解Java虚拟机(三)_深入java虚拟机 第3版
- 8Centos7安装Mysql5.7(超详细版)
- 9重装虚拟机后MobaXterm无法连接虚拟机,本机网络适配器中不显示虚拟网卡的解决办法_mobaxterm链接虚拟机
- 10cocos creator android 穿山甲 激励视频 java 调用 js_穿山甲 js
大模型理论基础-模型训练 学习笔记_大模型的基础理论
赞
踩
目标函数
根据上一章节,研究三类模型架构的目标函数,即:
- Decoder-only:计算单向上下文嵌入
- Encoder-only:计算双向上下文嵌入
- Encoer-Decoder:对输入进行编码后解码输出
通过一个映射函数(嵌入模型),可以将token序列映射到上下文嵌入中:
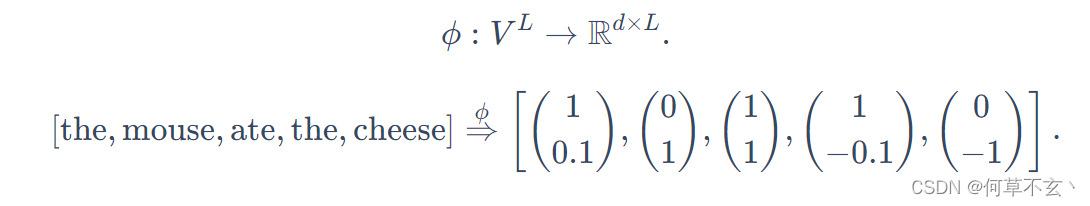
Decoder-only
一般是自回归语言模型,其token的取值概率取决于上一个token的值。

对其前i-1个token计算得分,并得到第i个token的分布
训练目标函数是很常见的最大似然损失函数:

Encoder-only
在不需要生成的情况下,可以用encoder生成更强的双向上下文嵌入
BERT
BERT的目标函数包括两部分,一个是自监督掩码生成目标函数,另一个是下一句预测的目标函数
掩码语言模型

这种掩码技术通过patching的优化已经广泛应用在CV和时间序列领域。
下一句预测
BERT是在拼接好的成对句子上训练的,下一句预测的目标函数是判断第二句是否跟随第一句,利用token首部的[CLS]来做二分类。
数据集
(重要)BERT的数据集是如下构造的:

训练目标
其目标函数就是如上所说的两个目标的损失函数的相加:

RoBERTa
RoBERTa的改进主要包括以下3点:
- 删除了下一句预测的损失部分(无用
- 使用了160G文本训练
- 训练时间更长
Encoder-decoder
主要包括BART和T5
BART
BART (Lewis et al. 2019)是基于Transformer的编码器-解码器模型。
- 使用与RoBERTa相同的编码器架构(12层,隐藏维度1024)
- 使用与RoBERTa相同的数据进行训练(160GB文本)
其包括以下五种任务
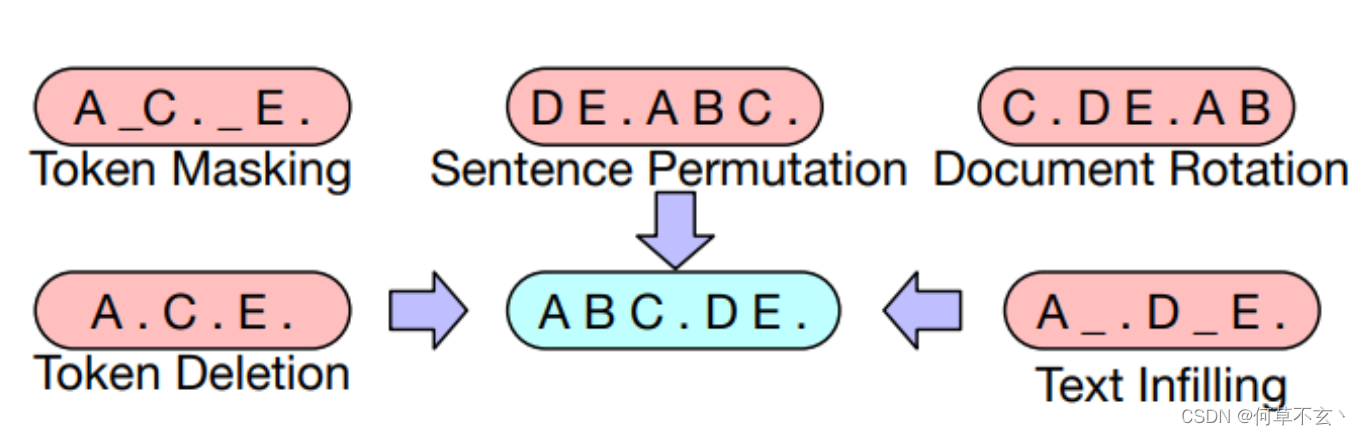
T5
其通过实验发现“i.i.d. noise, replace spans”这一无监督目标效果最好。并实现了text-to-text的各种任务。
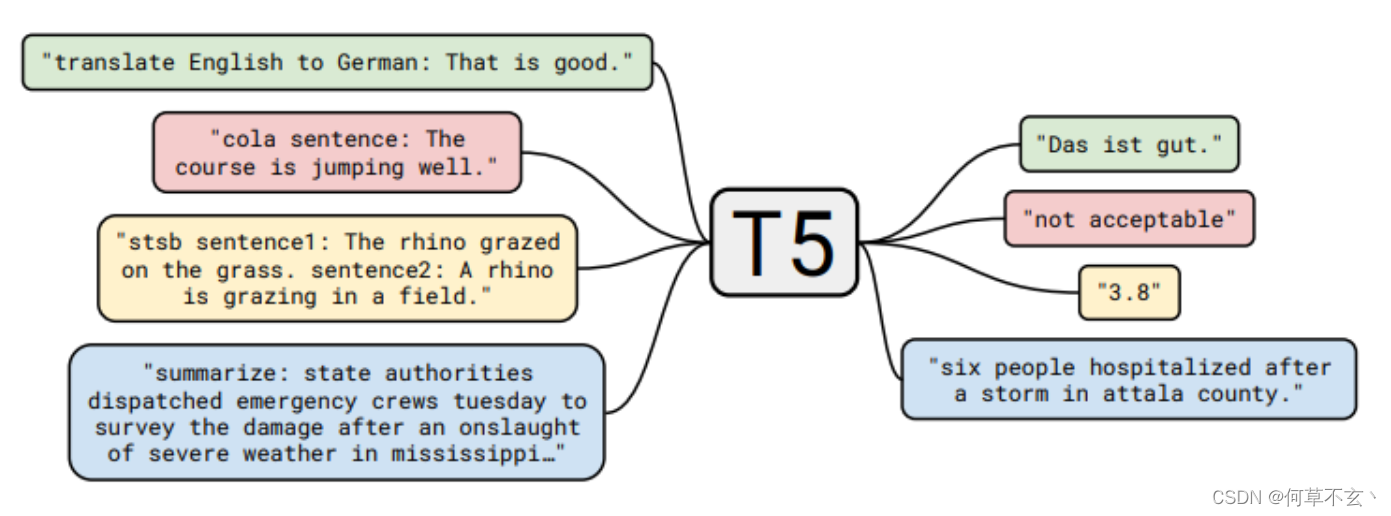
T5,GPT等模型不再利用CLS进行类别预测,转为自然语言生成来完成此类任务。
优化算法
以自回归语言模型为例:
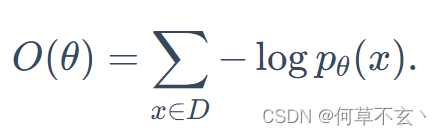
随机梯度下降(SGD)
(没啥好说的,最常用的优化方法

Adam(adaptive moment estimation)
引入动量的梯度下降算法,目前也是最为流行的优化算法
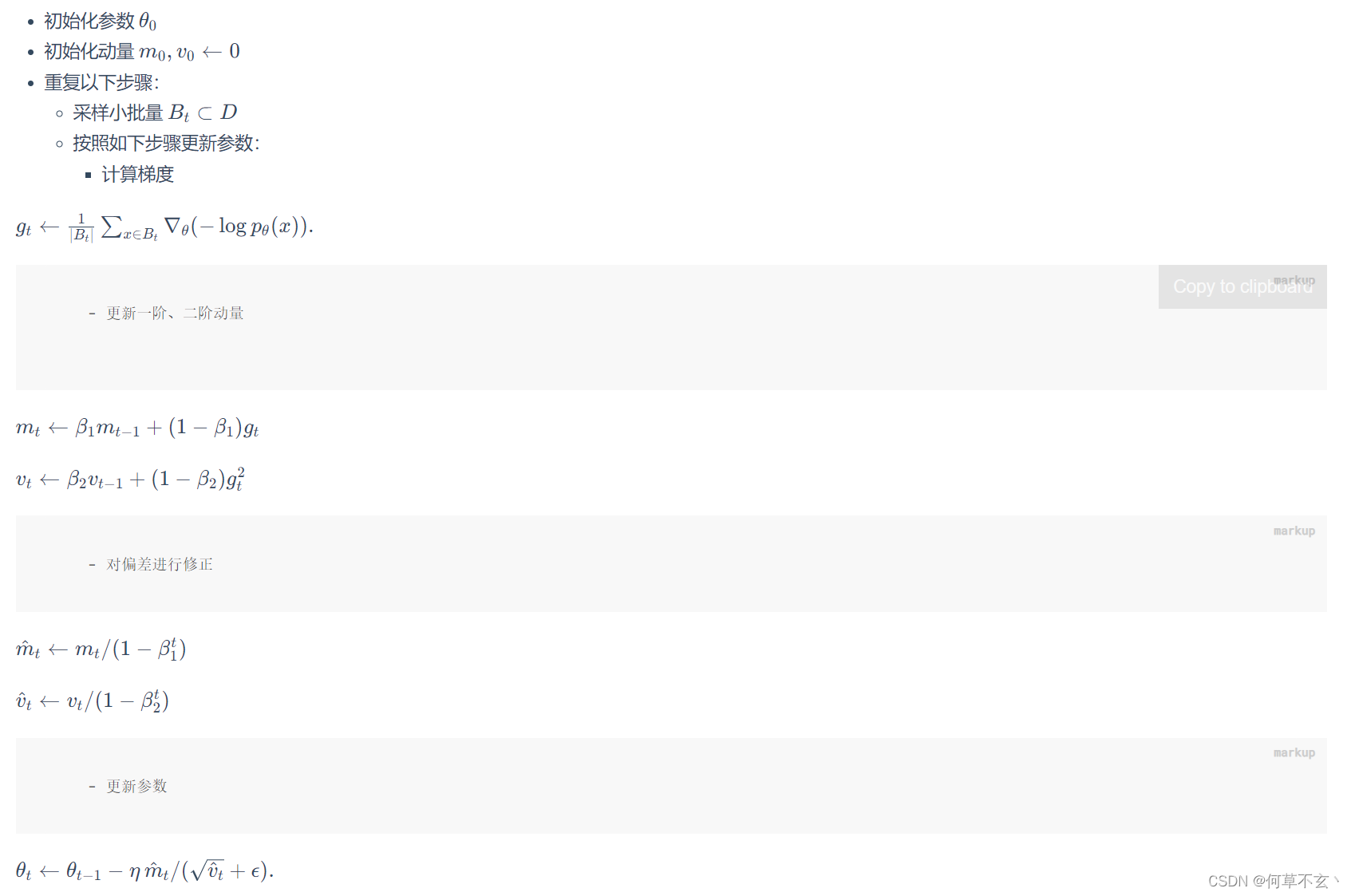
其将内存占用从2倍增加到了4倍(还真没怎么注意过)
AdaFactor
为了减少内存占用而提出的。

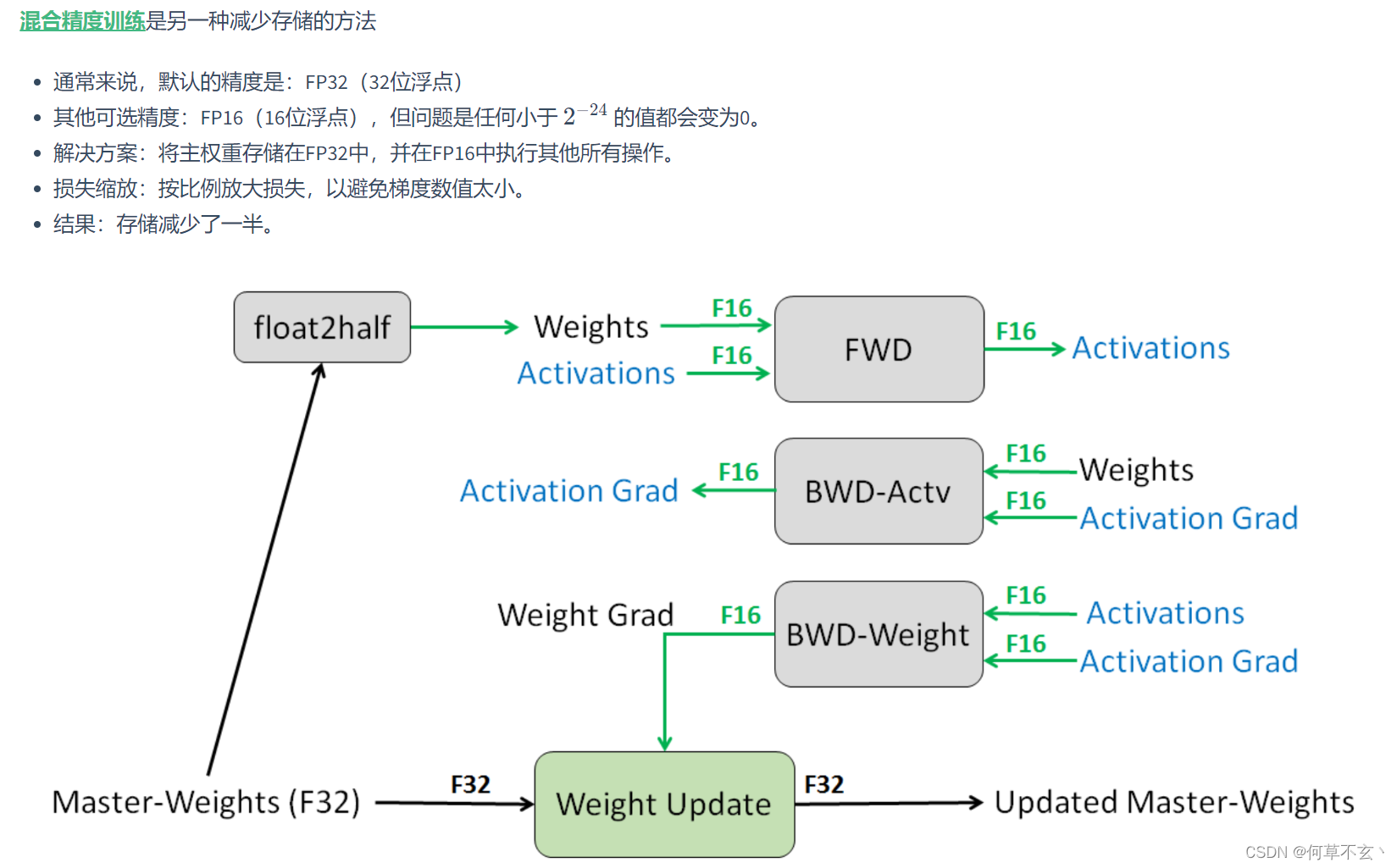
混合精度训练
其目标也是为了减少内存占用。
学习率
一般来说训练时会使用自适应学习率,一开始较大,随后不断衰减,比较常用的算法是warm-up学习率。
初始化

这里介绍了GPT-3所使用的部分参数


