
- 1mysql数据库now_MySQL NOW() 函数
- 2Chatglm3+langchain智能对话,本地文本库构建问答,图片文本库构建与问答搜索
- 3自动驾驶apollo9.0 Dreamview Debug方法_apollo9.0代码下载
- 4linux下的vim使用教程!从零基础到入门!_linux的vim使用教程
- 5阅读《吴军·硅谷来信》一年的回顾与思考
- 6AttributeError: module ‘pkgutil‘ has no attribute ‘ImpImporter‘. Did you mean: ‘zipimporter‘?_attributeerror: module 'pkgutil' has no attribute
- 7BAT面试算法基础学习笔记_bat 固定长度数列
- 8LeetCode 刷题 [C++] 第3题.无重复字符的最长子串
- 9[uniapp]使用uview组件自定义tabbar_uniapp uview tabbar
- 10HarmonyOS_Dev,DevEco Studio安装HarmonyOS JSSDK报错“Run 'npm install' failed”?
hadoop中的HDFS_hdfs namenode 作用
赞
踩
namenode和datanode的比较:
| namenode | datanode |
| 存储元数据 | 存储文件内容 |
| 元数据保存在内存中 | 文件内容保存在磁盘 |
| 保存文件,block,datanode之间的关系 | 维护了block id到datanode本地文件的映射关系 |
元数据:
除了文件内容之外的数据。
HDFS运行机制:
一个名字节点和多个数据节点
数据的复制(冗余机制)
- - 存放的位置(机架感知策略)
故障检测
-- 数据节点
心跳包(监测是否宕机)
块报告(安全模式下检测)
数据完整性检测(校验和比较)
-- 名字节点(日志文件和镜像文件)
空间回收机制
NameNode主要的功能:
接受客户端的读写程序
NameNode保存metadate信息包括
文件owership和permissions
文件包含那些块
Block保存在哪个DataNode(由datanode启动时上报)
NameNode的metadate信息在启动后会加载到内存
metadata存储到磁盘文件名为"fsimage"
Block的位置信息不会保存到fsimage
edits记录对metadata的操作日志
SecondaryNameNode:
它不是NameNode的备份(但可以作为备份),它的主要功能是帮助NameNode合并edits log,减少NameNode启动的时间。
SecondaryNameNode执行合并时机:
根据配置文件设置的时间间隔fs.checkpoint.period默认3600s,
根据配置文件editd log大小fs.checkpoint.size规定edits文件的最大值默认为64M。
DataNode:
存储数据
启动DataNode线程的时候会向NameNode汇报block信息。
通过向NameNode发送心跳与其联系(3秒一次),如果NameNode10分钟没有收到DataNode的心跳,则认为其已经lost,并copy其上的block到其他的DataNode上。
Block的副本存放的策略“
第一个副本:放置在上传文件的DataNode,如果是集群外提交,则随机挑选一台磁盘不太满,cpu不太忙的节点。
第二个节点:放置在于第一个副本不同的机架的节点上
第三个副本:与第二个副本相同的机架的节点
更多副本:随即节点
HDFS的读写流程图:
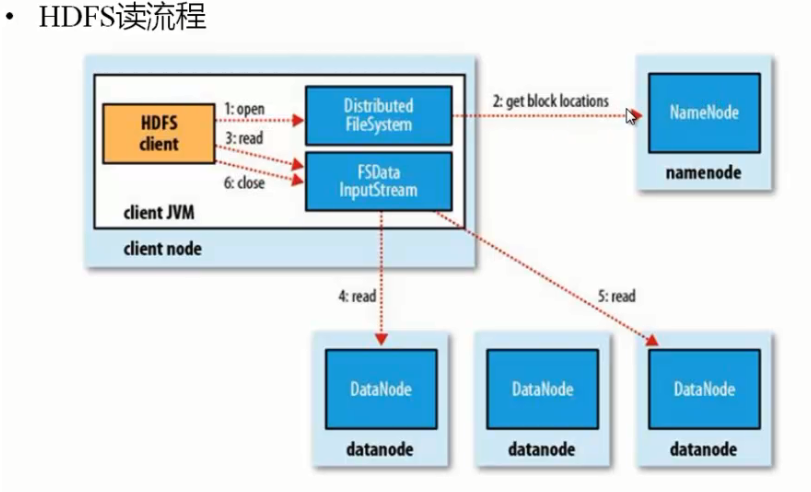
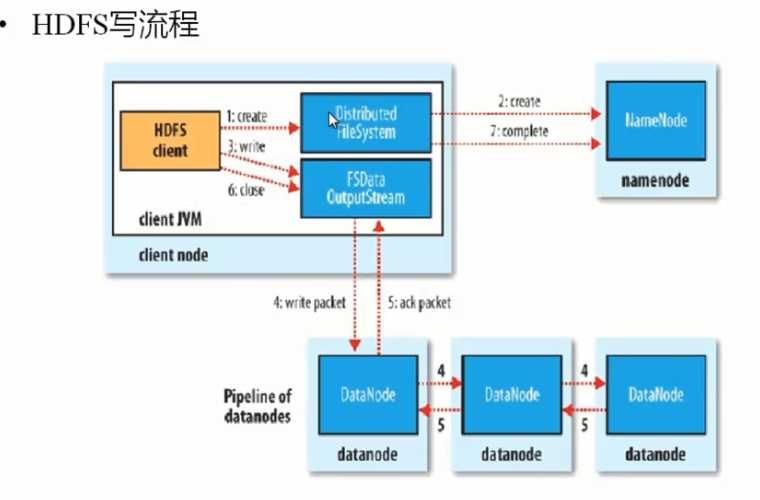
安全模式( 当HDFS启动之后静茹的模式):
namenode启动的时候,首先将映射文件(fsmage)载入内存,并执行编辑日志(edits)中的各项操作,
一旦在内存中成功建立文件系统元数据的映射,则创建一个新的fsimage文件(这个操作不需要SecondayNameNode)和一个空的编辑日志。
此刻namode运行在安全模式。即namenode的文件同对于客户端来说只读(显示目录,文件,写,删除都会失败)
此阶段的namenode收集各个datanode的报告,当数据块达到最小副本数以上时,会被认为是安全的,在一定比例(可设置)的数据块被确定为安全后,再过若干时间,安全模式结束。
当检测到副本数不足的数据块时,该块会被复制直到达到最小副本数,系统中数据块的位置并不是与namenode维护的,而是以块列表的方式存储在datanode
HDFS Hadoop2.x HA
主备NameNode
解决单点故障
主NameNode对外提供服务,备NameNode同步主NameNode元数据以待切换
所有DataNode同时向两个NameNode汇报数据块信息
两种切换选择
手动切换:通过命令实现主备切换,可以使用HDFS升级等场合
自动切换:基于Zookeeper实现
基于Zookeeper自动切换方案
Zookeeper FailoverController:监控namenode健康状态
并向Zookeeper注册NameNode
NameNode挂掉后,ZKFC为NameNode竞争锁,获得ZKFC锁的NameNode变为active。

Hadoop2.x Federation
通过多个namenode/namespace把元数据的存储和管理分散到多个节点中,使到namenode/namespace可以通过增加机器进行水平扩展
能把单个namenode的负载分散到多个节点中,在HDFS数据规模较大的时候不会也降低HDFS的性能。把不同类型的应用的HDFS元数据的存储管理分派到不同的namenode中。
YARN(Yet Another Resource Netgotiator):
hadooop2新引入的资源管理系统,直接从MRv1演化而来。
核心思想:将MRv1中的jobTracker的资源管理和任务调度两个功能分开
ResourceManager:负责将整个集群的资源管理和调度
YARN的引入,使得多个计算框架运行在一个集群中
每个应用程序对应一个applicationMaster
目前多个计算框架可以运行在YARN上,比如MapReduce,Spark,Storm中。
MapReduce On YARN
MapReduce On YARN:MRv2
将MapReduce作业运行在YARN上,而不是由JobTracker和TaskTracker构建的
基本功能模块
YARN:负责资源管理和调度
MRAppMaster:负责任务切分,任务调度,任务监控和容错等
MapTask/ReduceTask:任务驱动引擎,与MRv1一致
每个MapReduce作业对应一个MRAppMaster
MRAppMaster任务调度
YARN将资源分配给MRAppMaster
MRAppMaster进一步把资源分配给内部的任务
MRAppMaster容错:
失败后由YARN重新启动
任务失败后,MRAppMaster重新申请资源。

