
- 1Android studio版本对用的gradle版本和插件版本(注意事项)_android studio gradle插件版本
- 2BLE连接过程分析及异常断开0x3e错误原因分析
- 3加盐密码哈希:如何正确使用 (密码加密的经典文章)
- 4DevEcoStudio安装与使用_deveco打包程序
- 5Mac电脑可以玩《幻兽帕鲁》吗? 幻兽帕鲁配置要求
- 6ca-bundle.crt文件,用于php发起外部https请求
- 7华为手机怎样才算激活了_为了结婚而结婚会幸福吗 婚后生活怎样才算幸福
- 8LeafletJS-Markers_前端 leaflet marker选中后高亮
- 9Android HIDL 中的函数_hidl generates
- 10chatgpt赋能python:利用Python进行数据预处理
计算机毕业设计:基于python招聘数据分析可视化系统+预测算法+爬虫+Flask框架(建议收藏)_python预测毕设
赞
踩
[毕业设计]2023-2024年最新最全计算机专业毕设选题推荐汇总
2023年 - 2024年 最新计算机毕业设计 本科 选题大全 汇总
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
1、项目介绍
本项目旨在通过使用Python的requests库爬取拉勾网的招聘数据,并对数据进行清洗和持久化保存,以研究市场上招聘信息的趋势和分布情况。使用Flask框架作为后端技术,将数据库中的数据呈现给前端展示,借助基于前端框架Layui的应用,并结合图表展示工具ECharts,将数据以饼图、条形图等形式进行可视化展示。主要展示了招聘信息的数量分布、薪资分布情况以及关键词的分布情况。通过数据分析和可视化展示,得出如下结论:不同城市和行业的招聘信息数量和薪资水平有明显差异,而不同的招聘职位则有不同的职能和技能要求。因此,这些数据和分析结果对于个人求职者和企业招聘者提供了有益的参考。
关键词:requests; Flask框架;ECharts;Mysql;Layui
2、项目界面
(1)招聘企业分析

(2)全国招聘地图

(3)岗位分析词云图

(4)薪资预测模块
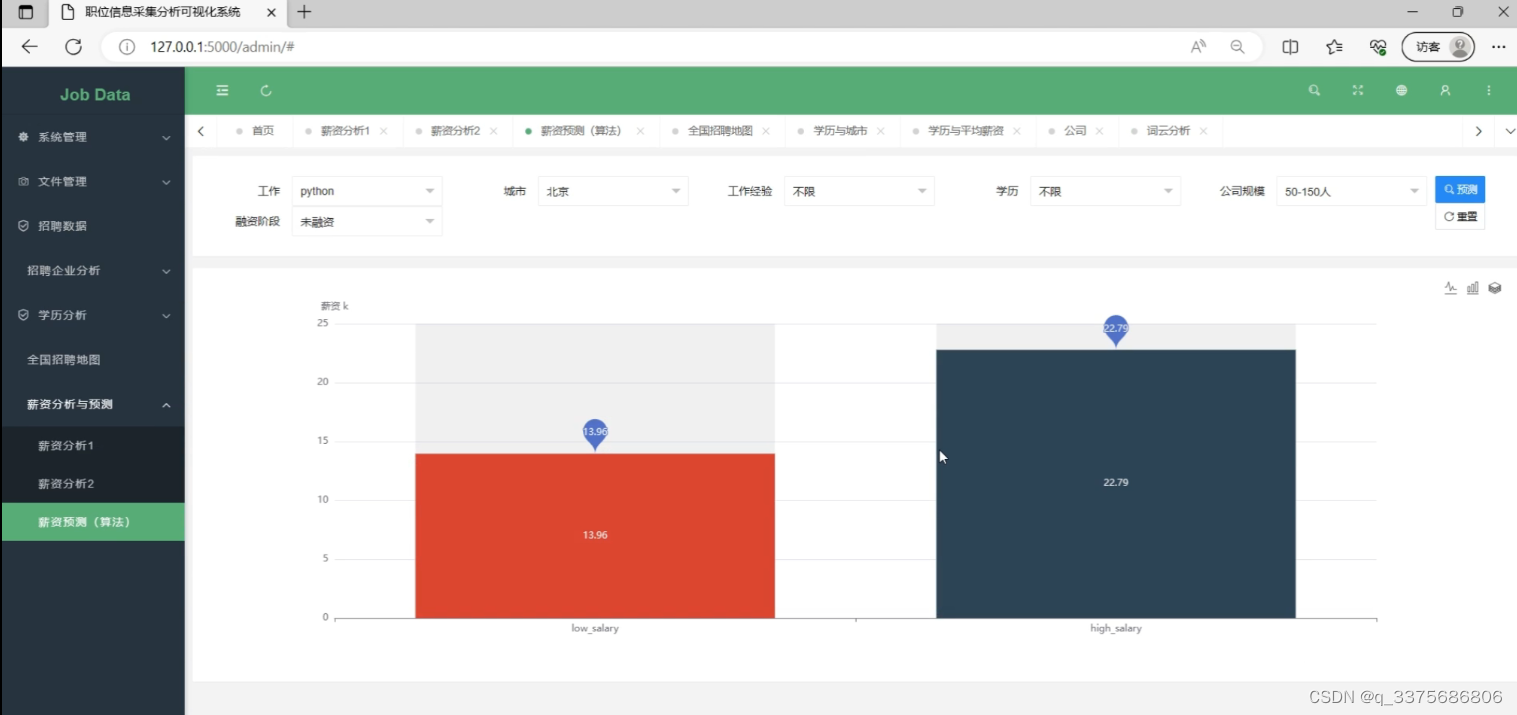
(5)招聘企业分析----融资情况

(6)招聘企业分析----类型

(7)薪资分析

(8)数据采集

3、项目说明
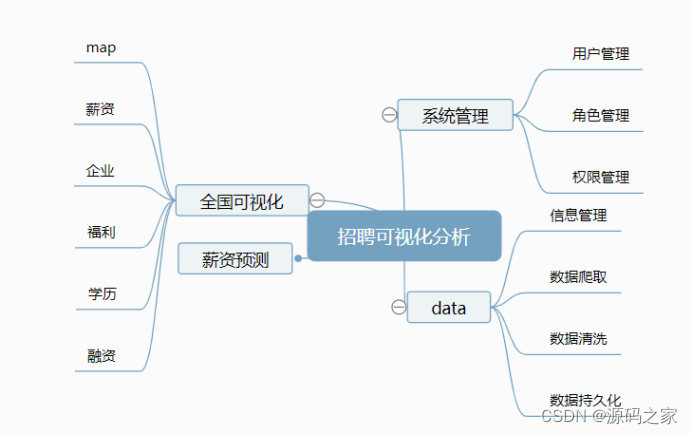
(1)系统功能设计
本系统是使用python进行创作,基于Flask框架实现Web功能,使用MySQL存储系统信息,结合ECharts进行数据可视化分析[11],数据获取通过requests对拉勾网进行爬取,获取的数据进行清洗处理后存储到MySQL数据库中,大致实现数据的爬取,系统管理和数据的可视化等模块[12],系统功能模块如图4-1系统功能模块。
(2)薪资预测模块
可以通过选择职位学历城市工作经验,使用随机森林预测薪资。
特征数据包括
“education”、“city”、“work_year”、"com_size"和"finance_stage"这些列,标签数据包括"low_salary"和"high_salary"这两列。
然后,代码使用RandomForestRegressor类初始化一个随机森林回归模型,并通过调用fit方法对模型进行训练,将特征和标签数据作为参数传入。
接下来,代码创建了一个新的DataFrame对象new_data,其中包含了一个示例的特征数据。然后,通过调用训练好的模型的predict方法,对新的特征数据进行薪资范围的预测。
4、部分代码
(1)预测代码
提取特征和标签
X = df[['education', 'city', 'work_year', 'com_size', 'finance_stage']]
y = df[['low_salary', 'high_salary']]
#训练随机森林模型
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X, y)
#预测薪资范围
new_data = pd.DataFrame({'education': [1], 'city': [1], 'work_year': [1], 'com_size': [1], 'finance_stage': [1]})
prediction = model.predict(new_data)
print(prediction)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
(2)爬虫代码
import os import random import math from time import sleep import json from urllib.parse import quote import requests from fake_useragent import UserAgent # 判断文件是否存在,否则创建新的 def mkdir(path): folder = os.path.exists(path) if not folder: os.makedirs(path) print(path + "文件夹创建成功") else: print("已存在") def my_proxy(): # 隧道域名:端口号 tunnel = "v760.kdltps.com:15818" # 用户名密码方式 username = "t18602188509513" password = "p0z0ogo6" proxies = { "http": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": tunnel}, "https": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": tunnel}, } # proxies = { # # 再例如 # "http": "http://127.0.0.1:7890", # # 再例如 # "https": "http://127.0.0.1:7890", # } return proxies def get_user_agent(): user_agent = UserAgent() return user_agent.chrome def get_headers(job_q): headers = { "User-Agent": get_user_agent(), "Host": "www.lagou.com", "Origin": "https://www.lagou.com", "Referer": f"https://www.lagou.com/jobs/list_{job_q}?labelWords=&fromSearch=true&suginput=", "X-Anit-Forge-Code": "0", "X-Anit-Forge-Token": "None", "X-Requested-With": "XMLHttpRequest", "Cookie": get_cookies(), } return headers def get_cookies(): cookies = def get_page_num(count): """ 计算要抓取的页数,通过在拉勾网输入关键字信息, 可以发现最多显示30页信息,每页最多显示15个职位信息 :param count: :return: """ page_num = math.ceil(count / 15) if page_num > 29: return 2 # return 29 else: return page_num def get_json(job_name, page_num, city): """ 从指定的url中通过requests请求携带 请求头和请求体 获取返回 :param city: :param job_name: 工作 :param page_num: 第几页 :return: """ post_url = f"https://www.lagou.com/jobs/positionAjax.json?px=default&city={quote(city)}&needAddtionalResult=false" # job_q = quote(job_name) url_job = f"https://www.lagou.com/jobs/list_{job_name}?px=default&city={city}#filterBox" headers = get_headers(job_q=quote(job_name)) # 请求体 data = { "first": "true", "pn": page_num, "kd": job_name, } # 代理 # proxy = my_proxy() 注释掉 # proxy = get_proxies(url_job) # s = requests.Session() print("建立session:", s, "\n\n") s.get(url=url_job, headers=headers, timeout=10) # s.get(url=url_job, headers=headers, timeout=10, proxies=proxy) cookie = s.cookies print("获取cookie:", cookie, "\n\n") # 关闭 keep-alive headers['Connection'] = "close" res = requests.post(url=post_url, headers=headers, data=data, cookies=cookie, timeout=10) # res = requests.post(url=post_url, headers=headers, data=data, cookies=cookie, timeout=10, proxies=proxy) print(f"城市{city},工作{job_name}正在爬取第{page_num}页") res.raise_for_status() res.encoding = "utf-8" page_data = res.json() return page_data def spider(job, city): """ 爬虫入口 :param job: :param city: :return: """ # 返回第一页json文件,方便查看有多少页数据,针对中断爬虫,继续爬取 first_page = get_json(job_name=job, page_num=1, city=city) # job 页码数量 num num = get_page_num(first_page["content"]["positionResult"]["totalCount"]) print(f"在城市{city},工作{job}可以爬取{num}页") # 已经爬取的数量 sleep(5) # sleep(10) # 工作保存路径 path_route = f"Data/{job}" mkdir(path_route) # 正式爬取 for page in range(1, num + 1): # 获取每一页的职位的相关职位信息 page_data = get_json(job_name=job, page_num=page, city=city) filename = path_route + "/" + city + job + str(page) + ".json" with open(filename, "w", encoding="utf-8") as f_obj: # 打开模式为可写 json.dump(page_data, f_obj, ensure_ascii=False) # 存储文件 sleep(20) jobs = ["java", "python", "C++", "php", "web", "bi", "go", "ruby", "android", "ios", "算法", "测试", "运维", "数据库", "ai"] cities = ["北京", "上海", "深圳", "广州", "杭州", "成都", "南京", "武汉"] job_num = 0 p_job = jobs[job_num] # 遍历城市 # 从第 n 个开始爬 n = 0 for i in range(n, len(cities)): c = cities[i] spider(job=p_job, city=c) sleep(5) # sleep(10)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
源码获取:
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

