
- 1笔记-软考高项-错题笔记汇总3
- 2鸿蒙Harmony-列表组件(List)详解_鸿蒙精简列表
- 3神经网络可以用来分类吗,神经网络用什么软件做_spss神经网络可以用来干什么
- 4python最全画地图,可视化数据
- 5pb90代码如何连接sql2008r2_如何创建Raspberry Pi灯光秀
- 6【毕业设计】疲劳驾驶行为检测系统 - python opencv cnn 深度学习_基于python和opencv的疲劳驾驶检测系统源码+全部数据(毕业设计).zip
- 7深蓝激光slam理论与实践-第一节笔记_slam的静态环境的这个静态环境到底是啥意思
- 8android自动计时器,Android中定时器Timer的使用
- 9【分享】免费的AI绘画网站(5个)_免费ai绘画网站入口
- 10VFF复现_voxel field fusion for 3d object detection
自然语言处理NLP——ERNIE-M:基于回译机制的“预训练-微调”多语言模型
赞
踩
目录
系列文章目录
本系列博客重点在自然语言处理NLP的概念原理与代码实践,不包含繁琐的数学推导(有问题欢迎在评论区讨论指出,或直接私信联系我)。
第一章 自然语言处理NLP——GSDMM用于短文本聚类_@李忆如的博客-CSDN博客
第二章 自然语言处理NLP——图神经网络与图注意力模型(GNN、GCN、GAT)
第三章 自然语言处理NLP——ERNIE-M:基于回译机制的“预训练-微调”多语言模型
梗概
本篇博客主要介绍一种基于回译机制的预训练-微调多语言模型——ERNIE-M,首先介绍了多语言任务及相关难题,提出了多语言模型的动机与ERNIE-M的动机与论文贡献及成就。然后在相关部分引入了多语言模型的底层原理及几种经典且与ERNIE-M相关的多语言模型进行分析与比较。在方法论部分详解了ERNIE-M的技术原理与模型,包括交叉注意力屏蔽语言建模(CAMLM)和反向翻译屏蔽语言建模(BTMLM)的构建与损失函数的定义。在实验部分,首先对论文对比模型、数据集、评估方法等做了总计,而后对论文五个自然语言处理下游任务做了简介与实验结果的分析,并对论文中的消融实验做了介绍。在新数据集实验部分,先是介绍了复现论文实验的4种不同方法,再在开源的3个任务上进行了论文数据集实验复现与对比。在查阅资料与相关论文后,选取了新的数据集进行ERNIE-M的实际任务,同时在新的应用场景下也对其模型进行了实践,并在不同维度下对结果进行了评估与分析。另外,本人自己增加了“优化”与“拓展”部分,前者针对ERINE-M模型与原理方面的一些问题,利用2021-2022的新结论与经典方法在数据、预训练、微调三个部分均提出了几种优化思路。后者针对ERINE-M的一些相关知识进行了补充,并对百度ERNIE的体系框架进行了介绍并进行了应用展示,在最后总结了本次参考的论文。
主要论文:【2021 EMNLP】Ouyang X, Wang S, Pang C, et al. ERNIE-M: Enhanced multilingual representation by aligning cross-lingual semantics with monolingual corpora[J]. arXiv preprint arXiv:2012.15674, 2020.
一、背景介绍
1.多语言任务
1.1 多语言任务定义
多语言任务即在不同语言下完成阅读理解、情绪识别、自然语言推断(逻辑判断)等自然语言处理中的实际下游任务,样例如图1所示:

图1 多语言任务样例
分析:根据图1,不难发现样例1中是中文的提问,样例2是英文情绪识别,样例3是法语中的自然语言推断。
1.2 多语言任务难题

图2 多语言任务难题样例
如图2所示,对于大多数人不熟悉的语言,在解决问题甚至判断问题的过程中均存在多种难题,给解决多语言任务带来很大困难,因此需要多语言模型。
2.多语言模型
2.1 多语言模型定义与原理
为解决多语言任务中的难题,提高多语言任务的精度与效率,多种多语言模型被提出。多语言模型一般通过语言间的词向量对齐实现语义对齐,或使用大数据框架进行预训练+微调,从而利用富资源语言的数据提升模型在低资源语言上的效果。语义对齐原理如图3所示,多语言模型一般流程如图4所示:
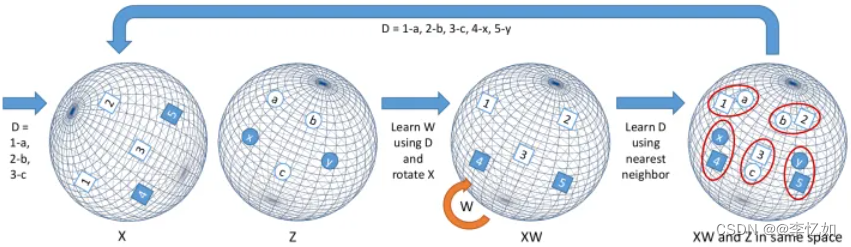
图3 不同语言的词向量映射关系
图4 多语言模型一般流程
2.2 多语言模型困难
随着研究的深入,多种多语言模型被提出,但在数据与工程应用的角度均仍受限于多种因素,多语言模型仍存在以下几个主要难题,模型的精度仍有待优化。
(1)语言多但可用的语料少,导致模型训练困难
全球有超过6000种语言,但常用的仅15种。无监督数据方面,大多语言的语料资源都不足10GB,如图5所示;有监督数据方面,大多数公司在中/英上有一定业务数据的沉淀,但在新语言上的积累基本为零。
此外,为小语种招募数据标注人员也存在一定难度,间接限制了有监督数据的获得。数据的匮乏使得在中小语种上训练一个有效的单语言模型变得困难。
 图5 不同语言语料资源数据汇总
图5 不同语言语料资源数据汇总
分析:如图5所示,除了头部的几个富资源语言(中、英等),其他语言的资源都仅有几GB、几百MB,在需要大数据的模型训练上有大大局限。
(2)语言的繁多增加了维护难度、减缓了扩展速度
一方面,模型上线后,不同语言对应的模型需要单独优化、处理bad case;另一方面,倘若没有良好的复用机制,支持一个新语言的周期会比较长,难以适应快速扩展的业务需求。
(3)算法工程师不懂目标语言,翻译工具质量不高,减缓了开发、调试速度
工程中,模型优化的大多收益来自数据的制作与清洗,但这一流程在多语言的设定下变得困难,工程师不懂目标语言使得该过程几乎无法进行。外部翻译软件仅能在一定程度上缓解这个问题,其在小语种上的效果并不可靠,且翻译这一动作本身就极大影响效率。
3.论文简介
3.1 背景与开发动机
根据1与2中的分析,对于多语言任务及其数据与工程应用中存在的困难,会导致多语言模型在自然语言处理中多种实际任务中表现不佳。对于多语言模型训练,往往需要大量有标签数据,而小语种语言中的有标签数据十分稀缺,因而搭建相关模型(完成多语言任务)十分困难。现有的多语言预训练模型方法往往受到平行语料(语义对齐的不同语言数据库)规模的限制,特别是对于低资源语言,效果不佳。
因此,百度与他们的框架ERNIE-M:基于回译机制的多语言预训练模型应运而生。
3.2 论文梗概
在论文中,作者提出了ERNIE-M,一种面向多语言建模的预训练-微调框架。基于回译机制,模型从单语语料库中学习语义对齐,以克服平行语料库大小对模型性能的限制。
实验结果表明,ERNIE-M优于现有的跨语言模型,显著提升包括跨语言自然语言推断、语义检索、语义相似度、命名实体识别、阅读理解在内的 5 种典型跨语言理解任务效果,在各种跨语言的下游任务中提供了新的SoTA(最先进)的结果。
3.3 论文贡献与成就
在贡献方面,ERNIE-M显著提升了各种典型跨语言理解任务效果,取得SoTA结果,为多语言任务提供了新工具与研究新思路。且ENIRE-M被嵌入百度的物联网产品,在搜索引擎、智能客服、智能音箱等人工智能系统泛化上做了优化,不断给人们带来更好的体验。
在成就方面,论文收录于EMNLP2021。且ERNIE-M框架2021年在权威跨语言理解榜单XTREME上也登顶榜首,超越微软、谷歌、Facebook等机构提出的多语言模型。
二、相关工作
1.预训练方法
1.1 预训练方法定义
由论文梗概可知,ENINE-M是一种预训练-微调框架。预训练的方法最初是在图像领域提出的,达到了良好的效果,后来被应用到自然语言处理。预训练一般分为两步,首先用某个较大的数据集训练好模型(这种模型往往比较大,训练需要大量的内存资源),使模型训练到一个良好的状态,然后下一步根据不同的任务,改造预训练模型,用这个任务的数据集在预训练模型上进行微调。
这种做法的好处是训练代价很小,预训练的模型参数可以让新的模型达到更快的收敛速度,并且能够有效地提高模型性能,尤其是对一些训练数据比较稀缺的任务,在神经网络参数十分庞大的情况下,仅仅依靠任务自身的训练数据可能无法训练充分,预训练方法可以认为是让模型基于一个更好的初始状态进行学习,从而能够达到更好的性能。
1.2 预训练方法发展历程
预训练方法大致经历了基于词嵌入的预训练方法、基于语言模型的预训练方法两个发展阶段,解析如下:
1.2.1 基于词嵌入的预训练方法
预训练词嵌入是在一个任务中学习到的词嵌入,它可以用于解决另一个任务,如图6所示。2003年,Bengio等人提出了神经语言模型,在训练过程中,神经语言模型不仅学习预测下一个词的概率分布,同时也得到一个副产品:词嵌入表示。相比随机初始化的词嵌入,模型训练完成后的词嵌入已经包含了词汇之间的信息。2013年,Mikolov等人提出了word2vec工具,其中包含了CBOW模型和Skip-gram模型,该工具仅仅利用海量的单语数据,通过无监督的方法训练得到词嵌入,两个预训练方法核心架构如图7所示:

图6 预训练词嵌入样例
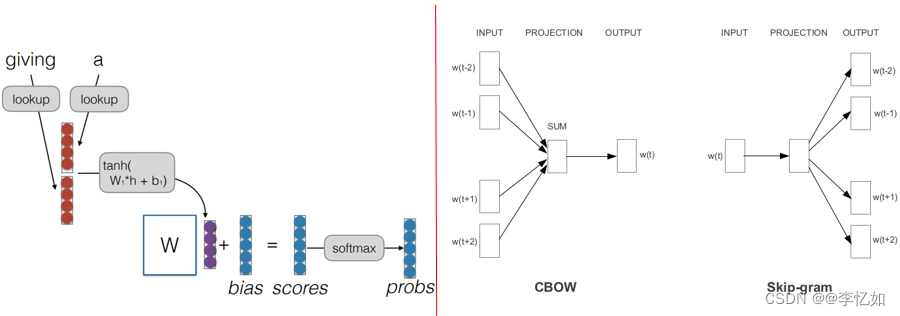
图7 基于词嵌入的预训练方法经典方法核心架构
1.2.2 基于语言模型的预训练方法
词嵌入本身具有局限性,最主要的缺点是无法解决一词多义问题,不同的词在不同的上下文中会有不同的意思,而词嵌入对模型中的每个词都分配了一个固定的表示。针对上述问题,Peters等人提出了ELMo,即使用语言模型来获取深层的上下文表示。ELMo的具体做法是,基于每个词所在的上下文,利用双向LSTM的语言模型来获取这个词的表示。ELMo的方法能够提取丰富的特征给下游任务使用,但是ELMo仅仅进行特征提取而没有预训练整个网络,远远没有发挥预训练的潜力,另外一个不足之处是,LSTM相比自注意力机制的Transformer模型结构无法更有效地捕获长距离依赖,难以对句子中信息进行更充分的建模。
针对上述两个问题,Radford等人提出了 GPT (Generative Pre-Training),即生成式的预训练。GPT将LSTM换成了Transformer,获得了更高的成绩,但是由于使用的是单向模型,只能通过前面词预测后面的词,可能会遗漏信息。Devlin等人提出了BERT,即基于Transformer的双向编码器表示。BERT和GPT的结构和方法十分相似,最主要的不同之处在于GPT模型使用的是单向语言模型,可以认为是基于Transformer的解码器表示,而BERT使用的基于Transformer的编码器能够对来自过去和未来的信息进行建模,能够提取更丰富的信息。三个预训练模型的核心架构如图8所示:

图8 基于语言模型的经典预训练方法核心架构
1.3 多语言模型与预训练方法的关系
由1.1中预训练方法的定义与1.2中预训练方法的发展历程不难发现,相关研究逐渐趋于利用预训练方法开发多语言模型,在模型效果与实际任务中均达到了更优的效果。以经典的BERT为例,目前绝大多数的预训练模型都是在BERT上改造而来,总结如图9所示:
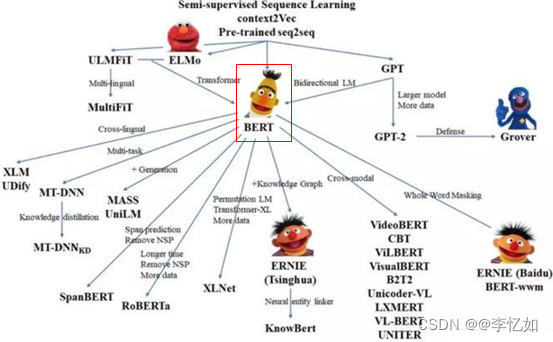
图9 基于BERT的多语言预训练模型
2.多语言模型
在ERNIE-M前,也有大量基于不同原理与流程的多语言模型被提出,在ERNIE-M的方法论与实验中也有进行相关工作的对比与优化,在本部分针对几种经典的多语言模型进行分析,详情如下:
2.1 BERT
多种多语言模型基于BERT开发,故在此对其原理、模型先做引入与解析。
2.1.1 BERT简介
BERT 来自 Google ,是“Bidirectional Encoder Representations from Transformers”的首字母缩写,整体是一个自编码语言模型(Autoencoder LM),基于Transformer中的Encoder加上双向的结构,并且设计了两个任务来预训练该模型。
第一个任务是采用 MaskLM 的方式来训练语言模型,通俗地说就是在输入一句话的时候,随机地选一些要预测的词,然后用一个特殊的符号[MASK]来代替它们,之后让模型根据所给的标签去学习这些地方该填的词。
第二个任务在双向语言模型的基础上额外增加了一个句子级别的连续性预测任务,即预测输入 BERT 的两段文本是否为连续的文本,引入这个任务可以更好地让模型学到连续的文本片段之间的关系。
最后的实验表明 BERT 模型的有效性,并在 11 项 NLP 任务中夺得 SOTA 结果。
BERT 相较于原来的 RNN、LSTM 可以做到并发执行,同时提取词在句子中的关系特征,并且能在多个不同层次提取关系特征,进而更全面反映句子语义。相较于 word2vec,其又能根据句子上下文获取词义,从而避免歧义出现。同时缺点也是显而易见的,模型参数太多,而且模型太大,少量数据训练时,容易过拟合。
2.1.2 Attention机制
由BERT简介可知,其模型基于Transformer 的 Encoder(编码器) 模块,而对于Transformer,最关键机制为Attention,故在此先对Attention机制做一定引入与解析。
Attention机制的中文名叫“注意力机制”,它的主要作用是让神经网络把“注意力”放在一部分输入上,即:区分输入的不同部分对输出的影响。这里,我们从增强字/词的语义表示这一角度来理解一下Attention机制。
我们知道,一个字/词在一篇文本中表达的意思通常与它的上下文有关。比如:光看“鹄”字,我们可能会觉得很陌生(甚至连读音是什么都不记得吧),而看到它的上下文“鸿鹄之志”后,就对它立马熟悉了起来。因此,字/词的上下文信息有助于增强其语义表示。同时,上下文中的不同字/词对增强语义表示所起的作用往往不同。比如在上面这个例子中,“鸿”字对理解“鹄”字的作用最大,而“之”字的作用则相对较小。为了有区分地利用上下文字信息增强目标字的语义表示,就可以用到Attention机制。
Attention机制主要涉及到三个概念:Query、Key和Value。在上面增强字的语义表示这个应用场景中,目标字及其上下文的字都有各自的原始Value,Attention机制将目标字作为Query、其上下文的各个字作为Key,并将Query与各个Key的相似性作为权重,把上下文各个字的Value融入目标字的原始Value中。
如图10所示,Attention机制将目标字和上下文各个字的语义向量表示作为输入,首先通过线性变换获得目标字的Query向量表示、上下文各个字的Key向量表示以及目标字与上下文各个字的原始Value表示,然后计算Query向量与各个Key向量的相似度作为权重,加权融合目标字的Value向量和各个上下文字的Value向量,作为Attention的输出,即:目标字的增强语义向量表示。

图10 Attention机制架构样例
除了基础的Attention机制,还有Self-Attention与Multi-head Attention两种机制。简介如下:
Self-Attention:对于输入文本,我们需要对其中的每个字分别增强语义向量表示,因此,我们分别将每个字作为Query,加权融合文本中所有字的语义信息,得到各个字的增强语义向量。在这种情况下,Query、Key和Value的向量表示均来自于同一输入文本,因此,该Attention机制也叫Self-Attention。
Multi-head Self-Attention:为了增强Attention的多样性,文章作者进一步利用不同的Self-Attention模块获得文本中每个字在不同语义空间下的增强语义向量,并将每个字的多个增强语义向量进行线性组合,从而获得一个最终的与原始字向量长度相同的增强语义向量。
两种改进的Attention架构如图11所示:

图11 Self-Attention与Multi-head Attention的架构样例
2.1.3 Transformer
由BERT简介可知,其模型基于Transformer 的 Encoder(编码器) 模块,首先引入Transformer整体架构如图12所示:

图12 Transformer整体架构
在2.1.2中引入了Attention机制及其改进,在Multi-headSelf-Attention的基础上再添加一些“佐料”,就构成了大名鼎鼎的Transformer Encoder。图13展示了Transformer Encoder的内部结构:

图13 Transformer Encoder内部结构
由图13可以看到,Transformer Encoder在Multi-head Self-Attention之上又添加了三种关键操作:
(1)残差连接(ResidualConnection)
将模块的输入与输出直接相加,作为最后的输出。这种操作背后的一个基本考虑是:修改输入比重构整个输出更容易(“锦上添花”比“雪中送炭”容易多了!)。这样一来,可以使网络更容易训练。
(2)Layer Normalization
对某一层神经网络节点作0均值1方差的标准化。
(3)线性转换
对每个字的增强语义向量再做两次线性变换,以增强整个模型的表达能力。这里,变换后的向量与原向量保持长度相同。
补充:由图13可以看到,Transformer Encoder的输入和输出在形式上还是完全相同,因此,Transformer Encoder同样可以表示为将输入文本中各个字的语义向量转换为相同长度的增强语义向量的一个黑盒。
2.1.4 BERT与Transformer
在引入Attention机制与Transformer后,可基于其介绍BERT原理。BART 使用标准的 Transformer 模型,不过做了以下四个改变改变:
(1)同 GPT 一样,将 ReLU 激活函数改为 GeLU,并且参数初始化服从正态分布。
(2)BART base 模型的 Encoder 和 Decoder 各有 6 层,large 模型增加到了 12 层。
(3)BART 解码器的各层对编码器最终隐藏层额外执行 cross-attention。
(4)BERT 在词预测之前使用了额外的 Feed Forward Layer,而 BART 没有。
BERT整体预训练和微调程序架构如图14所示:
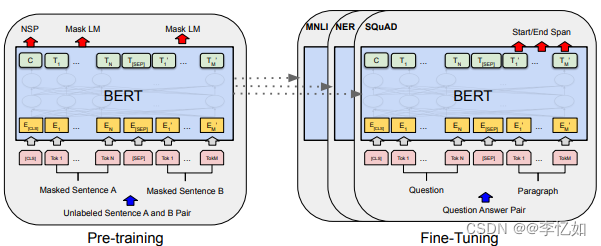
图14 BERT整体预训练和微调架构
2.1.5 BERT模型
在BERT中,作者分别用 12 层和 24 层 Transformer Encoder 组装了两套 BERT 模型,如图15所示,模型架构如图16所示:

图15 BERT两种模型
Tips:其中层的数量(即,Transformer Encoder 块的数量)为L ,隐藏层的维度为H ,自注意头的个数为A 。在所有例子中,我们将前馈/过滤器(Transformer Encoder 端的 feed-forward 层)的维度设置为4H ,即当 H=768 时是3072 ;当 H=1024 是 4096。

图16 BERT模型架构
2.2 mBERT
这个世界上有很多很多种语言,不需要为每一种语言准备一个BERT,而是用Multilingual BERT(mBERT),将所有语言的训练数据放在一起,去训练BERT,只要有足够大的Token set。下面就是用Mask来无监督的训练英文和中文的例子,如图17所示:
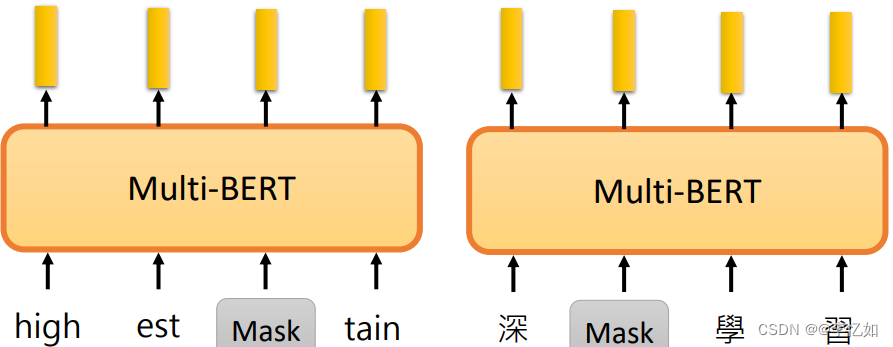
图17 mBERT训练样例
2.2.1 跨语言对齐
跨语言对齐即模型在看不同语言的词语的时候,会把相同意思的词语embedding到一起。由于跨语言对齐的存在,mBERT可以做多语言任务,如图18所示:

图18 跨语言对齐样例
2.2.2 语言类型识别
对于不同语言是存在差异的,故在模型中要进行语言类型识别。mBERT的做法是将语言的信息隐藏在了embedding之中,将多个语言通过mBERT后得到的embedding按照语言进行分类平均,然后投影在二维平面上,结果如图19所示:

图19 mBERT语言类型投影
如图19所示,可以看到每个语言之间还有有明显的不同,故mBERT可以将不同语言较好地分开,将语言类型识别(Reconstruction任务)模块加入模型,最终模型如图20所示:

图20 mBERT核心架构
Tips:蓝色块为带权重的embedding。
2.3 XLM
最初BERT出现时只适用于英语,对于多任务处理是不便的,故Facebook在BERT推断基础上发展出适应Cross-Lingual版本的多语言模型XLM,论文有两个核心创新点:一个是用BERT训练多语言文本分类、另一个是用BERT初始化机器翻译模型。
2.3.1 开发动机
对于经典BERT,尽管其训练语料超过100种语言,它的模型本身并没有针对多语言进行优化——大多数词汇没有在语言间共享,因此能学到的跨语言知识是很有限的。
2.3.2 XLM原理
针对这一点,XLM模型在以下方面修正了BERT:
首先,XLM的模型输入用了字节对编码(BPE)而不是用字符或词语。BPE把输入按所有语言中最常见的词片段进行切分,以此来增加跨语言共享的词汇。
其次,XLM以下面两个方式升级了BERT的模型结构:
(1)XLM的每个训练样本包含含义相同语言不同的两条句子,而不是像BERT中一条样本仅来自同一语言。BERT的目标是预测被遮住的token。XLM模型中,我们可以对每组句子,用一个语言的上下文信息去预测另一个语言被遮住的token。因为句子对中不同的随机词语会被遮住,模型可以利用翻译信息去预测token。
(2)模型也接受语言ID和不同语言token的顺序信息,也就是位置编码。这些新的元数据能帮模型学习到不同语言的token间关系。
2.3.3 模型架构
升级版的BERT模型被称作翻译语言模型(TLM),普通BERT模型+BPE输入被称作有掩码语言模型(MLM)。ERNIE-M重点对比的方法也为TLM与MLMM,原理与缺陷总结在表1中,,核心架构如图21所示:
表1 MLMM与TLM的模型解析
| 名称 | 核心 | 缺陷 |
| MLMM | 对每种单语语料使用MLM | 泛化性能差、效率低 |
| TLM | 使用大量平行语料,让不同语言embedding共享空间 | 平行语料数据少、效果有限制 |
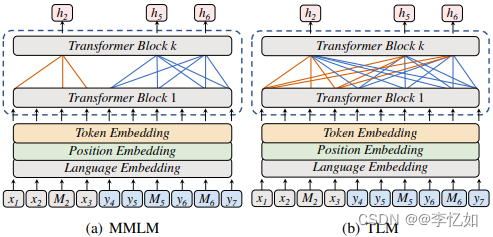
图21 MMLM与TLM的核心架构
完整的XLM模型同时训练了MLM和TLM,并且在两者之间进行交替训练,为了保证语料平衡,句子的采样的概率如式1,核心架构如图22所示:

式1 XLM句子采样概率
Tips: 其中α=0.5。使用这种概率函数进行抽样,可以提高训练语料较少的语言出现的频率,同时可以避免小语种在BPE的过程中直接被切割成单个字符。

图22 XLM核心架构
文章提出3个预训练任务,其中2个仅需要单语种数据集(无监督方式),另一个需要平行语料(有监督方式)。跨语言预训练模型XLM还可由CLM(传统语言模型的训练方式,基于Transformer)与MLM结合的模型组成,对于这种组合,文本训练模型的过程中,每个batch包含64个句子流,每个句子流由256个token组成。每次迭代,一个batch来自于同一语种的句子,句子的采样概率与sub-word vocabulary采样的概率函数设计方式一样,只不过其中的α变为0.7。
2.3.4 XLM模型分析
针对XLM的实现与流程进行分析,总结其模型优势与不足于表2:
表2 XLM模型分析总结
| 优势 | 不足 |
| 优化了BERT,引入BPE,优化了模型结构 | 泛化性能差、效率低 |
| 提供了多语言预训练的思路,预训练任务设计与训练巧妙 | 平行语料数据少、效果有限制 |
2.4 XLM-R
2.4.1 RoBRETa简介
部分多语言模型存在R版,即RoBERTa。相较于 BERT 最大的改进有三点:
(1)动态 Masking
静态 Maksing:在数据预处理期间 Mask 矩阵就已生成好,每个样本只会进行一次随机 Mask,每个 Epoch 都是相同的。
修改版静态 Maksing:在预处理的时候将数据拷贝 10 份,每一份拷贝都采用不同的 Mask,也就说,同样的一句话有 10 种不同的 mask 方式,然后每份数据都训练 N/10 个 Epoch。
动态 Masking:每次向模型输入一个序列时,都会生成一种新的 Maks 方式。即不在预处理的时候进行 Mask,而是在向模型提供输入时动态生成 Mask。
在不同数据集下,优化前后Msaking效果对比如图23所示:

图23 优化前后Msaking效果对比
(2)取消 NSP (Next Sentence predict) 任务
RoBERTa 算是比较早的一批质疑 NSP 任务的模型。RoBERTa 实验了 4 种方法:
Ⅰ、SEGMENT-PAIR + NSP:输入包含两部分,每个部分是来自同一文档或者不同文档的 segment (segment 是连续的多个句子),这两个 segment 的 token 总数少于 512 。预训练包含 MLM 任务和 NSP 任务。这是原始 BERT 的做法。
Ⅱ、SENTENCE-PAIR + NSP:输入也是包含两部分,每个部分是来自同一个文档或者不同文档的单个句子,这两个句子的 token 总数少于 512 。由于这些输入明显少于 512 个 tokens,因此增加 batch size 的大小,以使 tokens 总数保持与 SEGMENT-PAIR + NSP 相似。预训练包含 MLM 任务和 NSP 任务。
Ⅲ、FULL-SENTENCES:输入只有一部分(而不是两部分),来自同一个文档或者不同文档的连续多个句子,token 总数不超过 512 。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加标志文档边界的 token 。预训练不包含 NSP 任务。
Ⅳ、DOC-SENTENCES:输入只有一部分(而不是两部分),输入的构造类似于 FULL-SENTENCES,只是不需要跨越文档边界,其输入来自同一个文档的连续句子,token 总数不超过 512 。在文档末尾附近采样的输入可以短于 512 个 tokens, 因此在这些情况下动态增加 batch size 大小以达到与 FULL-SENTENCES 相同的 tokens 总数。预训练不包含 NSP 任务。
在不同数据集下,取消NSP任务前后效果对比如图24所示:
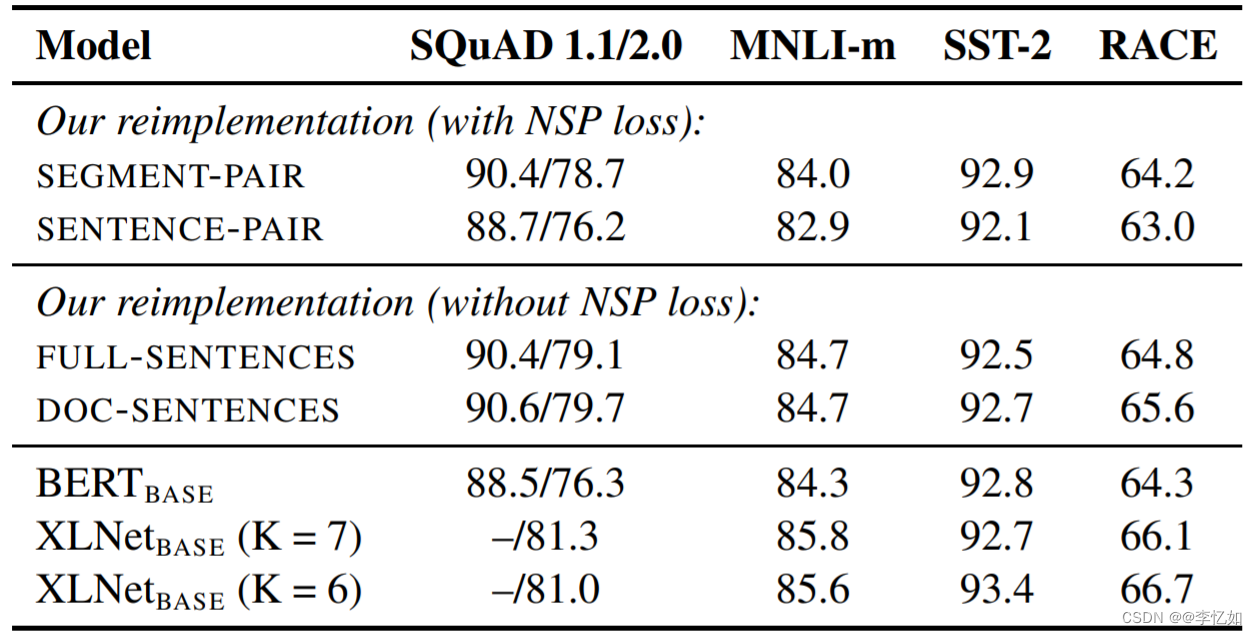
图24 取消NSP任务前后效果对比
(3)扩大 Batch Size
一般来说,降低 batch size 会显著降低实验效果。RoBERTa 论文作者也做过相关实验,采用大的 Batch Size 有助于提高性能。在不同数据集下,扩大前后效果对比如图25所示:
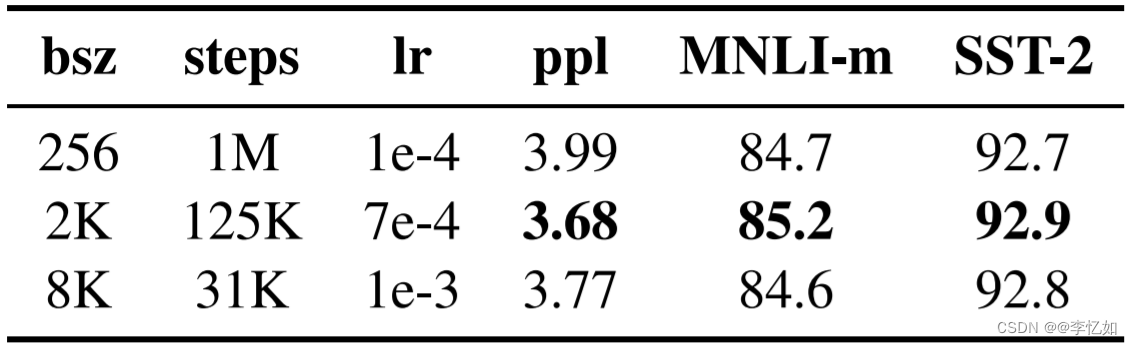
图25 扩大 Batch Size前后对比
Tips:bsz 是 Batch Size;steps 是训练步数(为了保证 bsz*steps 近似相同,所以大 bsz 必定对应小 steps);lr 是学习率;ppl 是困惑度,越小越好;最后两项是不同任务的准确率。
2.4.2 XLM-R简介
以XLM-R为RoBERTa版的例子做介绍。XLM-R基于XLM和RoBERTa,做了如下三个改进:
(1)在XLM和RoBERTa中使用的跨语言方法的基础上,在新模型中增加了语种数量和训练数据集的数量,具体来说使用超过2TB预处理过的CommonCrawl数据集,以自监督的方式训练跨语言表征。
(2)在fine-tuning期间,基于多语言模型的能力来使用多语言的标注数据,以提升下游任务的性能。
(3)调整了模型的参数,以抵消以下不利因素:使用跨语言迁移来将模型扩展到更多的语言时限制了模型理解每种语言的能力。我们的参数更改包括在训练和词汇构建过程中对低资源语言进行上采样,生成更大的共享词汇表,以及将整体模型增加到5.5亿参数量。
XLM-R的模型主体还是Transformer,训练目标是多语种的MLM,基本和XLM一样。作者从每个语种的语料中采样出文本,再预测出被Mask的tokens。从各语种采样的方法与XLM中相同,只是重新设置α=0.3。另一个与XLM不同的是,文本不使用Language Embeddings。本文的词典大小是250k,训练了两个模型,如图26所示:
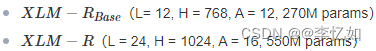
图26 XLM-R的两种模型
3.相关工作总结
与ERNIE-M强相关的方法就是BERT与XLM,在论文实验中还有对比INFOXLM、VECO等方法,在此不做详细叙述与分析,本部分针对上述方法与其他相关工作进行一定总结。
3.1 多语言模型
现有的多语言语言模型可以分为两大类:(1)判别性模型;(2)生成性模型。
在第一类中,使用MMLM对单语语料库进行多语言双向编码器表示(mBERT)的预训练,该模型在多种语言之间学习了一个共享的语言不变量特征空间。评估结果显示,mBERT在下行任务中取得了明显的性能。XLM在mBERT的基础上使用TLM进行了扩展,这使得该模型能够从平行语料库中学习跨语言标记对齐。XLM-R演示了在大规模语料库上训练时的模型效果。它使用了从Common Crawl中提取的2.5T数据,涉及100种语言的MMLM训练。结果表明,大规模的训练语料库可以显著提高跨语言模型的性能。Unicoder通过采用多任务学习框架,用单语和准语料库学习跨语言语义表征,在下游任务上取得了收益。ALM通过使模型学习跨语言的代码转换句子来提高模型的可转移性。INFOXLM为跨语言模型训练增加了一个对比性学习任务。HICTL从多个方面(在词级和句级)学习跨语言语义表达,以提高跨语言模型的性能。VECO提出了一个可变的编码器-解码器框架来统一理解和生成任务,并在这两个下游任务中取得了明显的改善。
第二类包括MASS、mBART、XNLG和mT5。MASS提出了恢复输入句子的训练目标,其中成功的标记片段被屏蔽,这提高了模型的机器翻译性能。与MASS类似,mBART预先训练了一个去噪的序列到序列模型,并使用一个自动渐进的任务来训练该模型。XNLG专注于多语言问题的生成和抽象总结,并通过自动编码和自动回归任务更新编码器和解码器的参数。mT5使用与T5相同的模型结构和预训练方法,并将跨语言模型的参数扩展到13B,大大提升了跨语言下行任务的性能。
3.2 逆向翻译和非自回归神经机器翻译
逆向翻译(BT)是Sennrich等人(2015)提出的一种有效的基于神经网络的机器翻译方法。它可以通过增加平行训练语料库,显著提高有监督和无监督机器翻译的性能。当平行语料库稀少时,BT被发现特别有用。在一个批次中预测目标语言的标记也可以提高非自动回归机器翻译的速度。ERNIE-M的工作受到NAT和BT的启发。分批生成另一种语言的标记,然后在预训练中使用这些标记来帮助句子对齐学习。
三、方法论
1.技术原理与模型综述
1.1 模型概述
ERNIE-M 是面向多语言建模的预训练-微调框架。为了突破双语语料规模对多语言模型的学习效果限制,提升跨语言理解的效果,我们提出基于回译机制,从单语语料中学习语言间的语义对齐关系的预训练模型 ERNIE-M,显著提升包括跨语言自然语言推断、语义检索、语义相似度、命名实体识别、阅读理解在内的 5 种典型跨语言理解任务效果。
1.2 技术原理
ERNIE-M 基于飞桨 PaddlePaddle 框架训练,该模型构建了大小为 25 万的多语言词表,涵盖了 96 种语言的大多数常见词汇,训练语料包含了汉语、英语、法语、南非语、阿尔巴尼亚语、阿姆哈拉语、梵语、阿拉伯语、亚美尼亚语、阿萨姆语、阿塞拜疆语等 96 种语言,约 1.5 万亿字符。 ERNIE-M 的学习过程由两阶段组成。第一阶段从少量的双语语料中学习跨语言理解能力,使模型学到初步的语言对齐关系;第二阶段使用回译的思想,通过大量的单语语料学习,增强模型的跨语言理解能力。
在第一阶段的学习中,ERNIE-M 提出了 Cross-attention Masked Language Modeling(CAMLM)预训练算法。该算法在少量双语语料上捕捉语言间的对齐信息。在 CAMLM 中,将一对双语句子记为<源句子,目标句子>。CAMLM 需要在不利用源句子上下文的情况下,通过目标句子还原被掩盖的词语。例如:输入的句子对是<明天会[MASK][mask]吗,Will it be sunny tomorrow>,模型需要只使用英文句子来推断中文句子中掩盖住的词<天晴>,使模型初步建模了语言间的对齐关系。
在此基础上,ERNIE-M 又提出了 Back-translation Masked Language Modeling(BTMLM)预训练算法。该方法基于回译机制从单语语料中学习语言间的对齐关系。首先,通过第一阶段学习到的 CAMLM 模型生成伪平行句子,然后让模型学习生成的伪平行句子。模型在还原被掩盖的单词时,不仅可以依赖原始输入句子,也可以依赖生成的伪平行句子。例如,输入的单语句子是<我真的很喜欢吃苹果>,模型首先会依据输入的句子<我真的很喜欢吃苹果>生成伪双语平行句子<我真的很喜欢吃苹果,eat apples>。然后再对生成的伪平行句子<我真的很喜欢吃[MASK][mask],eat apples>学习。通过这种方式,ERNIE-M 利用单语语料更好地建模语义对齐关系。
1.3 模型架构对比
将ERNIE-M与不同的多语言模型的原理、架构进行对比,如图27所示:
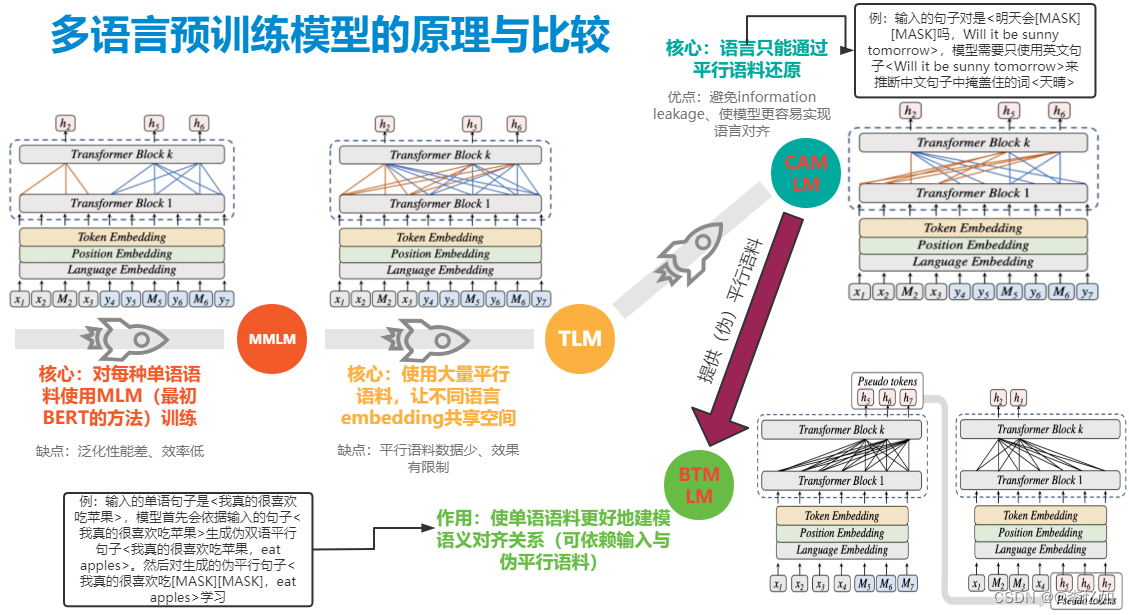
图27 不同多语言预训练模型的原理与比较
2.模型方法的解读
在本部分中,会首先介绍ERNIE-M的一般工作流程,然后介绍模型训练的细节。
2.1 跨语言语义对比
ERNIE-M的关键思想是利用从平行语料库中学到的可转移性来增强模型对大规模单语语料库的学习,从而增强多语语义的表示。基于这一想法,论文中提出了两个预训练目标,即交叉注意力屏蔽语言建模(CAMLM)和反向翻译屏蔽语言建模(BTMLM)。CAMLM是在平行语料上对准跨语言的语义表示。然后,利用从平行语料中学习到的可转移性来增强多语言表征。具体来说,通过使用BTMLM来训练ERNIE-M,使模型能够从单语语料库中对齐多语言的语义,并提高模型的多语言表示。由于Lample和Conneau 2019中显示的强大性能,默认使用MMLM和TLM。然后将MMLM、TLM与CAMLM、BTMLM相结合,训练ERNIE-M。每个目标的细节在后文有详述。
2.2 交叉注意力屏蔽语言建模
为了学习平行语料库中跨语言语义表征的一致性,论文提出了一个新的预训练目标--CAMLM。我们把一个平行句子对表示为<源句子,目标句子>。在CAMLM中,我们通过恢复输入句子中的MASK标记来学习多语言语义表示。当模型在源句中恢复MASK标记时,模型只能依靠目标句的语义,这意味着模型必须学习如何用目标句的语义来表示源语言,从而使多语言的语义保持一致。图28(b)和(c)显示了TLM和CAMLM的区别。
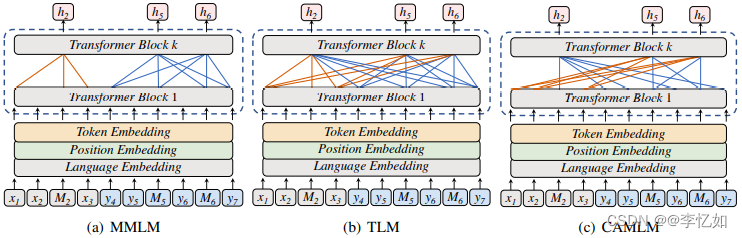
图28 CAMLM及其他方法架构对比
Tips:子图(a)中的输入句子是单语句子;x和y代表不同语言的单语输入句子。子图(b)和(c)中的输入句子是平行句;x和y分别表示平行句的源句和目标句。 h表示模型预测的标记。
TLM通过源句和目标句学习语言间的语义对齐,而CAMLM只依靠句子的一面(不依靠本语言)来恢复MASK标记。CAMLM的优势在于,它避免了模型可以同时关注一对输入句子的信息泄露,这使得学习BTMLM成为可能。图28中的例子的自我注意矩阵如图29所示。对于TLM,MASK标记的预测依赖于输入句子对。当模型学习CAMLM时,模型只能根据其对应的平行句的句子和这个句子的MASK符号来预测MASK标记,这就提供了位置和语言信息。因此,在CAMLM中,MASK标记M2的概率为p(x2|M2, y4, y5, y6, y7),M5为p(y5|x1, x2, x3, M5),M6为p(y6|x1, x2, x3, M6)。

图29 不同预训练目标的Self-Attention掩码矩阵对比
给定双语语料库中的输入Xsrc = {x1, x2,……, xs},及其对应的MASK位置Msrc = {m1, m2,……, mms},目标句是Xtgt = {xs+1, xs+2,……, xs+t},其对应的MASK位置是Mtgt = {mms+1, mms+2,……, mms+mt}。在TLM中,模型可以关注源句和目标句中的标记,因此被遮蔽的标记的概率Πm∈M p(xm|X/M),其中M = Msrc ∪ Mtgt。 X/M表示X中除M中的x以外的所有输入标记,其中X = Xsrc ∪ Xtgt。在CAMLM中,源句中MASK标记的概率为Πm∈Msrc p(xm|X/M∪Xsrc),这意味着在预测源句中的MASK标记时,我们只关注目标句的情况。至于目标句,MASK标记的概率为Πm∈Mtgt p(xm|X/M∪Xtgt),这意味着在预测目标句中的MASK标记时,将只基于源句进行预测。因此,该模型必须学会使用相应的句子来预测和学习跨语言的对齐。CAMLM在源/目标句中的预训练损失如式2所示:
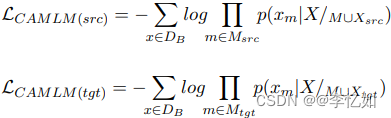
式2 CAMLM在源/目标句中的预训练损失
其中DB是双语训练语料库。CAMLM损失如式3所示:
![]()
式3 CAMLM损失
2.3 逆向翻译屏蔽语言建模
为了克服平行语料库大小对模型性能的制约,论文提出了一个新颖的预训练目标,其灵感来自NAT和BT方法,称为BTMLM,以使跨语言语义与单语语料库保持一致。我们使用BTMLM来训练我们的模型,它建立在通过CAMLM学到的可转移性上,从单语句子中生成伪平行句子(语料),然后将生成的伪平行句子作为模型的输入来对齐跨语言语义,从而增强多语言表示。BTMLM的训练过程如图30所示:

图30 BTMLM训练过程
如图30所示,BTMLM的学习过程分为两个阶段。第一阶段涉及从单语语料库中生成伪平行标记。具体来说,在单语句子的结尾处填入几个占位符MASK,表示我们要生成的位置和语言,并让模型根据原始单语句子和伪标记的相应位置生成其相应的平行语言标记。通过这种方式,我们从单语句子中生成另一种语言的标记,这将用于学习多语言的跨语言语义对齐。
图29中生成的伪Self-Attention掩码矩阵如图31所示:

图31 BTMLM第一阶段生成的Self-Attention掩码矩阵
在伪标记生成过程中,模型只能关注源句和占位的MASK标记,这些标记表示我们想通过语言嵌入和位置嵌入来预测的语言和位置。掩码标记M5的概率为p(y5|x1, x2, x3, x4, M5),M6的概率为p(y6|x1, x2, x3, x4, M6),M7的概率为p(y7|x1, x2, x3, x4, M7)。
第二阶段使用第一阶段生成的伪标记来学习跨语言的语义对齐。阶段2的过程如图30中的右图所示。在第二阶段的训练过程中,模型的输入是单语句子和生成的伪平行标记的串联,学习目标是根据原始句子和生成的伪平行标记来恢复MASK标记。由于该模型在推断MASK to- kens的过程中不仅可以依赖输入的单语句子,还可以依赖生成的伪标记,因此该模型可以明确地从单语句子中学习跨语言语义表征的对齐。
BTMLM的学习过程可以解释如下。给出单语语料库的输入X={x1, x2,……, xs},屏蔽标记的位置M={m1, m2,……, mm}和要预测的伪标记的位置Mpseudo={ms+1, ms+2,……, ms+p},我们首先生成伪标记P={hs+1, hs+2,……, hs+p},如前所述。然后,我们将生成的伪标记与输入的单语句子连接起来,作为一个新的平行句子对,用它来训练我们的模型。因此,BTMLM中被屏蔽的标记的概率为Πm∈M p(xm|X/M, P),其中X/M表示X中除M中的x以外的所有输入标记。BTMLM的预训练损失如式4所示:
![]()
式4 BTMLM预训练损失
2.4 ERNIE-M模型
根据上述模型细节构建模型,核心为MMLM、TLM与CAMLM、BTMLM相结合,目前PaddleNLP支持的ERNIE-M模型对应预训练权重有两种,如图32所示:

图32 ERNIE-M的两种模型
四、论文实验
1.实验简介
1.1 实验任务及设置
对于ERNIE-M的性能探究,论文考虑了自然语言处理中五个实际的下游任务,在不同的评价标准与数据集下进行实验与分析,并与最先进的多语言模型进行效率对比。其中,XNLI用于跨语言自然语言推理,MLQA用于跨语言问题回答,CoNLL用于跨语言命名实体识别,PAWS-X用于跨语言意译识别,Tatoeba用于跨语言检索,实验的简单总结如图33所示。接下来,我们首先描述了数据和预训练的细节,然后将ERNIE-M与现有的最先进的模型进行比较。

图33 ERNIE-M的实验简单总结
补充:如图32,ERNIE-M在两种情况下评测模型效果,分别用Cross-lingual Transfer验证跨语言理解能力,用Multi-language Fine-tuning验证本语言对模型的增强。两种方法详解如下:
1)Cross-lingual Transfer:该方式将英文训练的模型直接在其他语言上测试,验证模型的跨语言理解能力。例如,让模型理解 “这家餐厅环境不错” 是正向情感,模型需要判断 “I am very happy.” 也是正向的情感。在实际应用中,如果缺乏某种语言的标注数据,该技术可以通过其他语言的标注数据对多语言模型训练解决该问题,降低小语种系统的构建难度。
2)Multi-language Fine-tuning:该方式使用所有语言的标注数据对模型进行多任务训练,验证在有本语言标注数据的情况下,模型能否利用其他语言的数据,进一步增强该语言的理解效果。
1.2 数据与模型选择
ERNIE-M是用涉及96种语言的单语和平行语料库训练的。对于单语语料库,我们从CC-100提取。对于双语语料库,我们使用与INFOXLM相同的语料库,包括MultiUN、IIT Bombay、OPUS和WikiMatrix我们使用转化器-编码器作为模型的主干。对于ERNIE-MBASE模型,我们采用12层、768个隐藏单元、12个头的结构。对于ERNIE-MLGE模型,我们采用了24层,1024个隐藏单元,16个头的结构。使用的激活函数是GeLU。我们用XLM-R初始化ERNIE-M的参数。我们使用Adam优化器来训练ERNIE-M;学习率以线性衰减的方式安排,有10K个热身步骤,基础模型的学习率峰值为2e - 4,大模型为1e - 4。我们使用64个Nvidia V100-32GB GPU进行预训练实验,批次大小为2048,最大长度为512。
2.实验与结果评估
本部分将针对ERNIE-M论文中五个任务的设置、数据、实验结果进行解释与对比分析。
2.1 自然语言推断
2.1.1 任务简介
该任务的目标是判断两句话之间的逻辑关系,样例如图34所示。ERNIE-M所使用的多语言数据集「XNLI」数据集包含15种语言,既有英语、法语等常见语言也有斯瓦希里语等小语种语言。

图34 自然语言推断任务样例
2.1.2 实验设置与结果
论文在跨语言转移设置中评估ERNIE-M:用英语训练集微调模型,并评估外语XNLI测试;translatetrain-all设置:在所有其他语言的连接上微调模型,并在每个语言测试集上评估,实验结果如图35所示:

图35 ERNIE-M自然语言推断结果
分析:如图35,结果显示,ERNIE-M在XNLI的两个评估设置上都优于所有基线模型,包括XLM、Unicoder、XLM-R、INFOXLM和VECO。测试集上的最终得分是以不同的随机种子进行的五次运行的平均分。在跨语言转移设置上,ERNIE-M取得了77.3的平均准确率,比INFOXLM高出1.1;ERNIE-M Large取得了82.0的准确率,比INFOXLMLARGE高出0.6。ERNIE-M在低资源语言中也产生了出色的表现,如图36所示。包括斯瓦希里语(sw)的69.5和乌尔都语(ur)的68.8。在翻译-训练-所有的情况下,ERNIE-M提高了性能,达到了80.6的准确率,比INFOXLM高出0.9,ERNIEMLARGE达到了84.2的准确率,是XNLI的新SoTA,比XLM-RLARGE高出0.6。

图36 低资源语言中多语言模型效果对比
2.2 命名物体识别
2.2.1 任务简介
该任务的目标是识别出文章中的人名、地名、时间、机构等信息,样例如图37所示。其可以帮助人们快速地从大量文章中提取出有价值的信息。使用多语言模型可以帮助我们在小语种文章上做信息抽取。ERNIE-M在CoNLL数据集上进行评测。
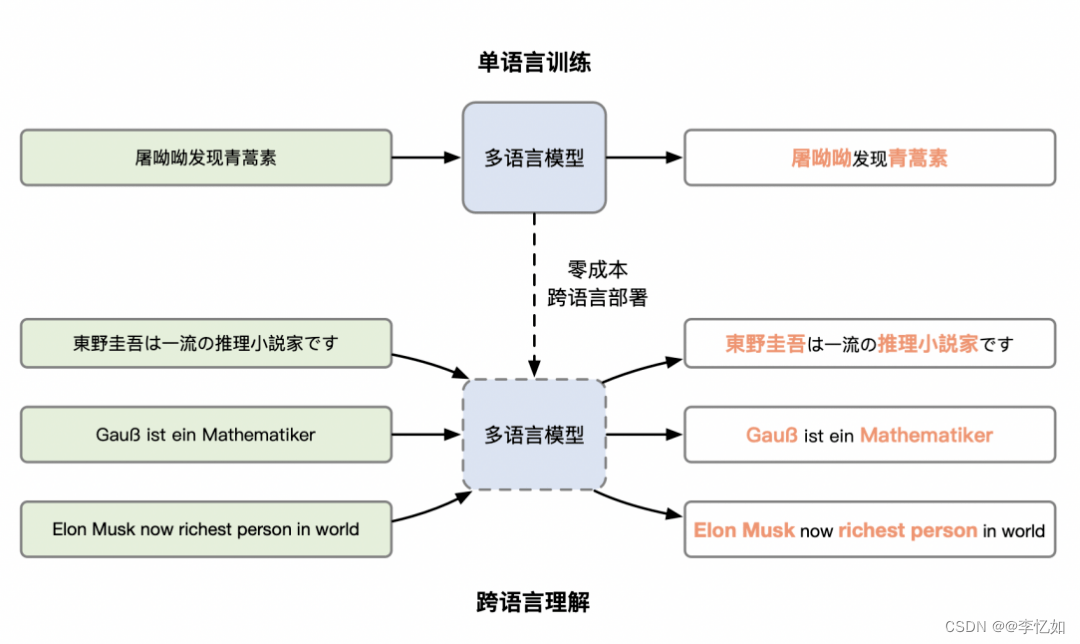
图37 命名物体识别样例
2.2.2 实验设置与结果
对于命名实体识别任务,论文在CoNLL-2002和CoNLL-2003数据集上评估ERNIE-M,这是一个跨语言的命名实体识别任务,包括英语、荷兰语、西班牙语和德语。我们在以下设置中考虑ERNIEM:(1)在英语数据集上进行微调,并在每个跨语言数据集上进行评估,以评估跨语言转移;(2)在所有训练数据集上进行微调,以评估跨语言学习。对于每个设置,我们报告了每种语言的F1得分。实验结果如图38所示:
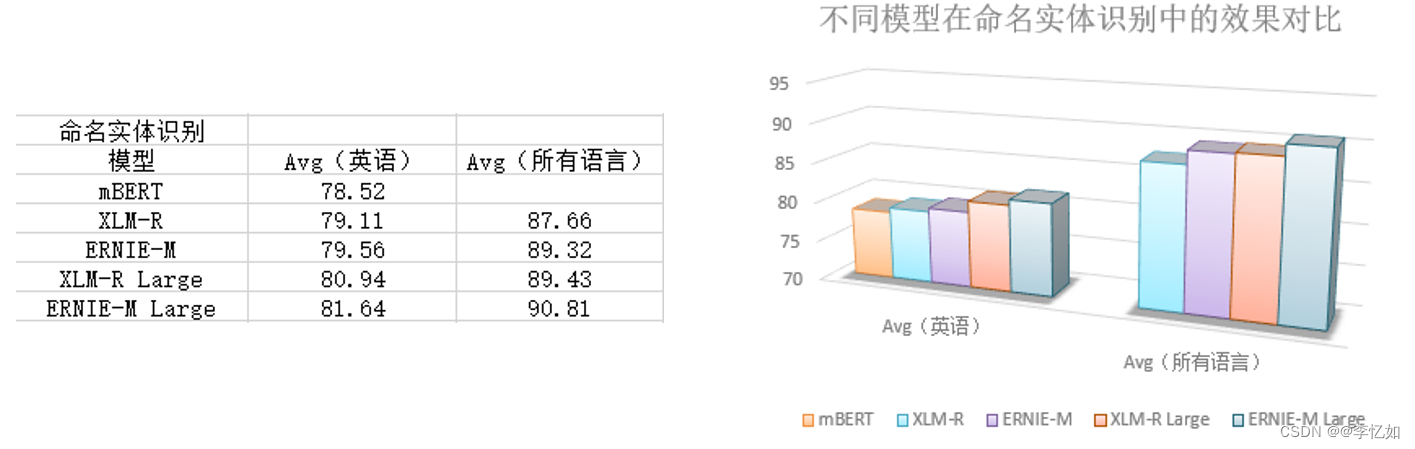
图38 ERNIE-M命名物体识别结果
分析:如图38所示,ERNIE-M模型在两种设置上都产生了SoTA性能,在英语上训练时,比XLM-R高出0.45 F1,在基础模型的所有语言上训练时,高出0.70 F1。与XNLI任务中的表现类似,ERNIE-M在低资源语言上表现出更好的性能。对于大型模型和所有语言的finetune设置,ERNIE-M在荷兰语(nl)中比SoTA高2.21 F1,在德语(de)中比SoTA高1.6 F1。
2.3 阅读理解
2.3.1 任务简介
该任务的目标是根据文章回答指定问题,样例如图39所示。为了评测ERNIE-M在阅读理解任务上的效果,ERNIE-M在Facebook提出的MLQA多语言阅读理解数据集上进行了评测。

图39 阅读理解任务样例
2.3.2 实验设置与结果
对于问题回答(阅读理解)任务,我们使用多语言问题回答(MLQA)数据集来评估ERNIE-M。MLQA与SQuAD v1.1的格式相同,是一个由七种语言组成的多语言问题回答任务。我们通过对英语数据的训练和对七种跨语言数据集的评估对ERNIE-M进行微调。微调方法与Lewis等人的方法相同,将问题-段落对作为输入进行串联。实验结果如图40所示:

图40 ERNIE-M阅读理解结果
分析:如图40所示,报告了基于五次运行的平均值的F1和提取匹配(EM)分数。ERNIE-M在MLQA中的表现明显优于以前的模型,并取得了SoTA的分数。我们在F1中优于INFOXLM 0.8,在EM中优于0.5。
2.4 语义相似度
2.4.1 任务简介
该任务的目标是判断两段文本语义是否相似,为了评测ERNIE-M在语义相似度任务上的效果,ERNIE-M在PAWS-X多语言数据集上进行了评测。
2.4.2 实验设置与结果
对于跨语言的转述识别(语义相似度)任务,论文使用PAWS-X数据集来评估我们的模型。我们在跨语言转移设置和翻译-训练-所有设置上评估ERNIE-M。实验结果如图41所示:

图41 ERNIE-M语义相似度任务
分析:如图41所示,根据五次运行的平均值,报告了每种语言测试集的准确度得分。结果显示,ERNIE-M在大多数语言上的表现优于所有基线模型,并取得了新的SoTA。
2.5 跨语言检索
2.5.1 任务简介
该任务是在双语语料库中检索语义相同的句子,样例如图42所示。ERNIE-M可使得用户只用某一种语言,便可检索到其他语言的结果。该技术使信息跨越不同语言之间的鸿沟,帮助全球的网民搜索到更多有价值的信息。

图42 跨语言检索任务样例
2.5.2 实验设置与结果
对于跨语言检索任务,论文使用Tatoeba数据集的一个子集,其中包含36个语言对来评估ERNIE-M。按照Luo等人,2020年,我们使用最佳XNLI模型中间层的平均表示来评估检索任务。实验结果如图43所示:

图43 ERNIE-M跨语言检索结果
分析:ERNIE-M在Tatoeba数据集中取得了87.9分,超过了VECO 1.0,获得了新的SoTA结果。
为了进一步评估ERNIE-M在跨语言检索任务中的表现,论文使用最硬的负二元交叉熵损失来微调ERNIE-M,在预训练中使用相同的双语语料。图44显示了在Tatoeba的每种语言上的准确率细节。

图44 在Tatoeba的每种语言上的准确率细节
分析:如图44所示,经过微调,ERNIE-M在所有语言上都有明显的改善,所有语言的平均准确率从87.9提高到93.3。
3.消融实验
为了了解在ERNIE-M的训练过程中对齐多种语言的语义表征的效果,论文进行了一项消减实验研究,如图45所示。其中,exp0是直接在XNLI和CoNLL上微调XLM-R模型。论文在单语语料库上只训练了(1)MMLM,exp1的目的是衡量在XLM-R模型的基础上继续训练能取得多大的性能增益,(2)在单语语料库上训练MMLM。(3)在单语语料库上使用MMLM,在双语语料库上使用CAMLM;(4)在单语语料库上使用MMLM和BTMLM,在双语语料库上使用CAMLM;(5)ERNIE-M的完整策略。我们使用基础模型结构进行实验,为了加快实验速度,我们使用XLM-RBASE模型来初始化ERNIE-M的参数,所有的模型都以相同的超参数运行50000步,批次大小为2048,下游任务中报告的分数是五次运行的平均分数。

图45 消融实验设置
分析:比较exp0和exp1,我们可以观察到,通过继续预训练XLM-R模型,跨语言模型的性能没有任何增益。将exp2 exp3 exp4与exp1相比较,我们发现在平行语料库上学习跨语言语义对齐有助于提高模型的性能。使用双语语料库进行训练的实验表明,XNLI有了明显的改善。然而,有一个令人惊讶的结果是,使用TLM目标会损害NER任务的性能,如exp1和exp2所示。对比exp2和exp4,我们发现我们提出的BTMLM和CAMLM训练目标更有利于捕捉跨语言语义的一致性。与使用TLM的训练模型相比,使用CAMLM和BTMLM目标的训练模型在XNLI上有0.3的改进,在CoNLL上有1.3的改进。比较exp3和exp4,我们发现在模型学习了BTMLM之后,在XNLI上有0.5的改进,在CoNLL上有0.1的改进。这表明我们提出的BTMLM可以学习跨语言语义对齐,并提高模型的性能。
为了进一步分析论文策略的效果,我们从头开始训练小规模的ERNIE-M模型。图46显示了XNLI和CoNLL的结果。XNLI和CoNLL的结果都是每种语言的平均值。我们观察到,ERNIE-M Small在XNLI中的表现比XLM-RSMALL高出4.4,在CoNLL中高出6.6。这表明我们的模型可以从对齐跨语言的语义表示中获益。

图46 小规模模型在XNLI和CoNLL上的结果
图47显示了英语和其他语言在下游任务中的差距得分。这个差距分数是英语测试集和其他语言的测试集的平均表现之间的差异。所以,较小的差距分数代表了模型的可转移性较好。我们可以注意到,在XNLI和MLQA任务中,ERNIE-M的差距分数比XLM-R和INFOXLM小,这表明ERNIE-M的可转移性更好。

图47 英语和其他语言在下游任务中的差距得分
为了衡量ERNIEM的计算成本,我们从头开始训练ERNIE-M和XLM-R(MMLM+TLM)。结果显示,与XLM-R相比,ERNIE-M的训练速度是1.075倍,所以与XLM-R相比,ERNIE-M的整体计算量是1.075倍。在相同的计算开销下,ERNIE-M在XNLI中的性能为69.9,在CoNLL中为69.7,而XLM-R在XNLI中的性能为67.3,在CoNLL中为65.6。结果表明,即使在计算开销相同的情况下,ERNIE-M也比XLM-R表现得更好。
此外,我们还探讨了生成的伪平行指标数量对模型收敛的影响。特别是,我们比较了生成5%、10%、15%和20%比例的伪指标时对模型收敛速度的影响。如图48所示:

图48 生成的伪平行指标数量对模型收敛的影响
分析:如图48所示,我们可以发现,模型的困惑度(PPL)随着生成指标比例的增加而减少,这表明生成的伪平行指标对模型收敛有帮助。
五、实验复现
1.论文实验复现方法论
1.1 复现方法简介
ERNIE-M为百度提出的框架,故除了论文外还有平台化的复现方法,在本部分先对论文复现方法论做简述,复现方法总结如图49所示:

图49 ERNIE-M论文实验复现方法总结
Tips:方法1为ERNIE-M全构成项目,包括模型、依赖、函数定义等,方法2kit版为简单版,将任务整合为可执行脚本,复现方便,方法3与4均为百度AI相关平台,可在平台进行ERNIE-M及其它模型的任务实践。
1.2 代码复现实验步骤
使用方法1或2复现论文实验的步骤如图50所示:

图50 代码复现实验步骤
Tips:脚本内置了自然语言推断、命名实体识别、阅读理解三个任务,以及论文中单语言与多语言的训练方法。
1.3 平台复现实验步骤
使用方法3或4复现论文实验的步骤如图51所示:

图51 代码复现实验步骤
2.核心代码解析
2.1 项目依赖与文件
将ERNIE-M导入Pycharm,在requirements.txt查看依赖如图52所示,项目文件如图53所示:
图52 ERNIE-M官方依赖
图53 ERNIE-M项目文件
2.2 数据读取转化代码解析
数据读取、预处理等步骤基本定义在reader目录下,文件如图54所示:

图54 ERNIE-M的reader目录文件
其中,batching.py实现了批量数据的处理,核心是将实例填充到最大序列长度的批次中,并产生相应的位置数据和注意力偏差。Tokenization.py完成了数据的标记化(预处理),如文本的无效字符清理、多余空间删除、词句空间转换等操作。Task_reader.py为数据导入与操作的核心文件,通过不同函数的定义,完成了数据导入、读取、处理等操作,如分类器读取与操作定义在类ClassifyReader中,核心代码如图55所示:
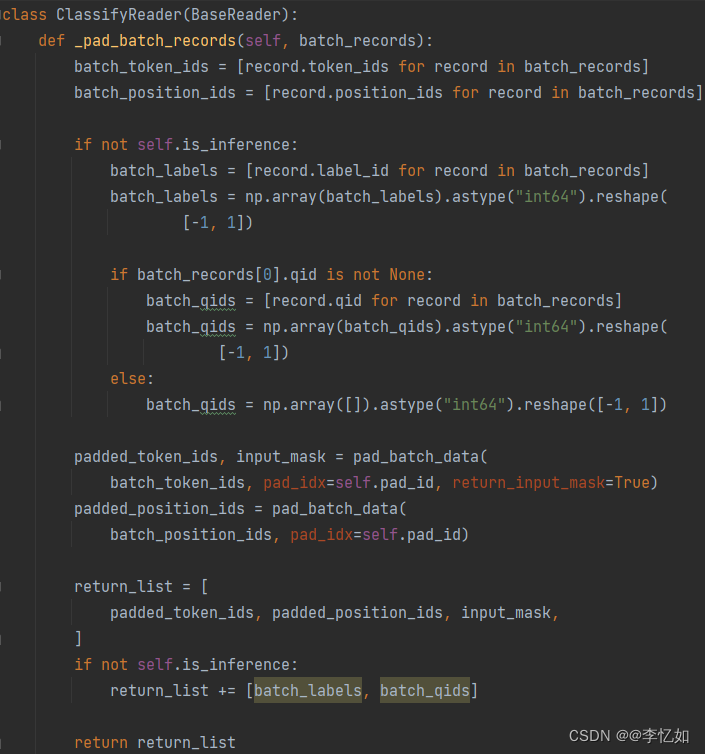
图55 ERNIE-M分类器读取与操作核心代码
2.3 模型代码解析
2.3.1 模型的设置与建立
在二与三中已对ERNIE-M与其他多语言模型的技术原理与模型实现有做详解。由于ERNIE-M基于BERT,所以也有对Transformer_encoder进行优化,并加入了论文提出的CAMLM、BTMLM(项目内集成于ernie.py),并将相关优化(Adam优化器等)定义于optimization.py,model目录文件如图56所示:
图56 ERNIE-M的model目录文件
在ernie.py中,使用ErnieConfig()函数做了相关配置,ErnieModel()函数定义模型,_build_model()函数进行模型的建立,核心代码如图57所示:

图57 model目录下ERNIE-M模型核心代码
Tips:通过截断的正常初始化器初始化所有的重量,所有的偏差,并输出相应特征给分类器。
2.3.2 数据的导入与模型的使用
在encode_vector.py开头将模型所需数据(文本、语料)进行导入、分析、转换,并使用create_model()函数在向量编码中创建并使用对应模型,核心代码如图58所示:
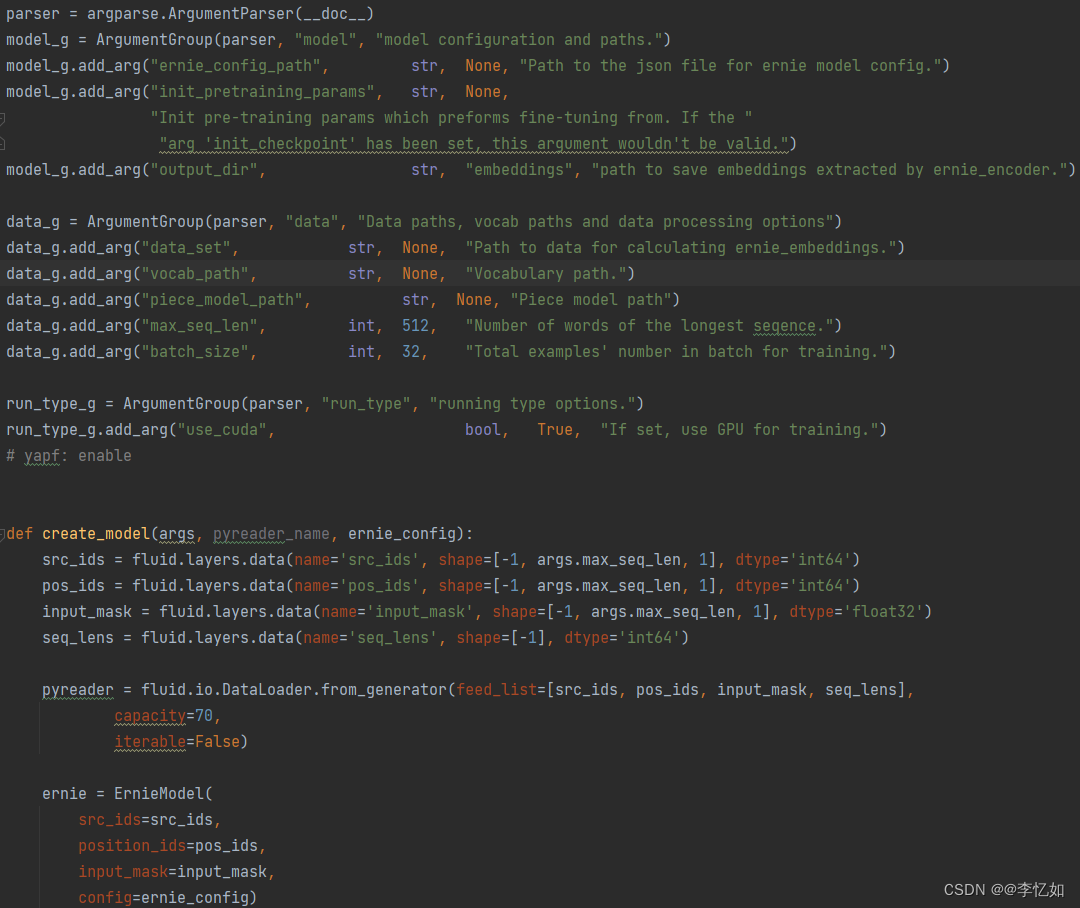
图58 向量编码中的数据导入与模型建立核心代码
2.4 微调框架
由三中ERNIE-M的技术原理介绍可知,ERNIE-M为一种“预训练-微调”的多语言模型框架,故本部分针对项目的微调框架做解析,微调框架代码在finetune目录下,如图59所示。由于ERNIE-M开源了自然语言推断、命名实体识别、阅读理解三个任务,故对应存在三个finetune框架。

图59 ERNIE-M的finetune目录文件
以mrc.py(阅读理解微调框架)为例介绍微调框架,其中,用create_model()函数创建并使用ERNIE-M的模型,compute_loss()函数作为损失函数,write_result()函数用于结果的写入,evaluate()函数作为结果的评估函数,用_get_best_indexes()函数寻找最优参数,核心代码如图60所示:

图60 ERNIE-M阅读理解任务微调框架核心代码
2.5 任务运行代码与脚本
2.5.1 任务运行代码
将数据导入处理、模型建立与使用、预训练、微调等完成,可针对任务(自然语言推断、命名实体识别、阅读理解等)使用相应的run.py进行任务运行,如图61所示:
图61 任务运行代码
2.5.2 可运行脚本
ERNIE-M中集成了可执行脚本于scripits目录中,如图62所示:
图62 ERNIE-M可执行脚本
在Pycharm中对应项目开启终端,使用sh scripts/large/xnli_cross_lingual_transfer.sh或sh scripts/large/xnli_translate-train_all.sh可以执行脚本完成开源的三个任务。
3.论文实验复现
本部分将对ERNIE-M中的实验在论文给定数据集上进行复现,并在新的数据集上进行实践,也会利用相关多维的评价标准对结果进行分析并与论文结论进行对比。
3.1 原数据集复现
由于ERNIE-M开源的任务为自然语言推断、命名实体识别、阅读理解,故在本部分对这三个任务在原数据集上进行复现。论文给定数据集分别为XNLI、CoNLL、MLQA,故将数据集下载到本地再按对应步骤运行ERNIE-M项目或直接使用脚本执行即可,复现结果与论文结果对比如图63所示:
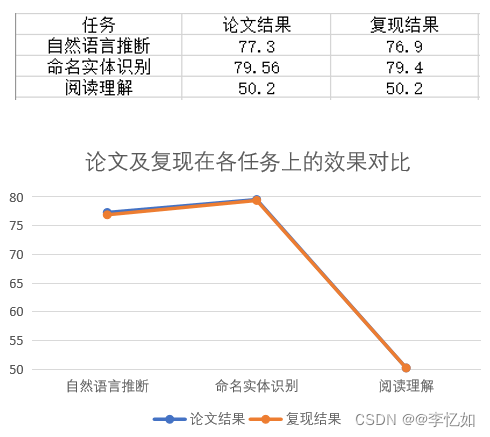
图63 ERNIE-M复现结果与论文结果对比
分析:由图63所示,在论文给定的数据集下,针对自然语言推断、命名实体识别、阅读理解三个自然语言处理实际的下游任务,复现结果评分与论文结果基本一致,两条曲线拟合程度较好,复现成功,验证了ERNIE-M实验结论的正确性与在实际多语言任务上的优越性。
3.2 新数据集实践
Tips:针对跨语言的数据集公开的并不多,故个人尝试完成多语言任务是有一定难度的。
为探究ERNIE-M的可迁移性与效果,我选择了其他数据集进行实践。以阅读理解任务为例,详解如下。
3.2.1 数据集介绍
在新数据集下用ERNIE-M进行阅读理解任务,我选择的新数据集是XQA。基本信息汇总如表3:
表3 XQA数据集基本信息汇总
| 名称 | XQA: 一个跨语言的开放领域问题回答数据集 |
| 来源 | 清华大学 |
| 论文 | XQA: A Cross-lingual Open-domain Question Answering Dataset - ACL Anthology |
| 代码地址 |
XQA是比较优秀且可用于阅读理解任务的数据集,其对于研究OpenQA的意义是重大的。论文构建了一个用于跨语言OpenQA研究的新数据集XQA。它包括英语训练集以及其他八种语言的开发和测试集,样例如图64所示。此外,其还为跨语言OpenQA提供了多种基线系统,包括两种基于机器翻译的方法和一种零距离跨语言方法(多语言BERT)。

图64 XQA数据集示例
3.2.2 评估标准
对于不同的MRC(阅读理解)任务,有不同的评估指标。在评估完形填空题和多项选择题时,最常用的衡量标准是准确率(Accuracy)。在跨度提取方面,使用精确匹配(EM)和F1-score来衡量模型的性能。由于自由回答题的答案不受原语境的限制,故广泛使用ROUGE-L和BLEU来评估。
其中,准确率是指在模型给出的答案中有多大比例的单词在标准答案中出现;召回率是指在标准答案中有多大比例的单词在模型给出的答案中出现。ROUGE-N用来测评N元组的召回率,如式5所示:

式5 BOUGE-N定义
Tips:其中,M为模型答案,counts(A)表示N元组s在标准答案A中出现的次数。ROUGE-N以N元组s在标准答案A中出现的次数和在模型答案M中出现的次数的较小值作为分子。
ROUGE-S和ROUGE-2(N=2)的定义非常类似,只是ROUGE-S中不要求两个词相邻,而是允许二元组中的两个词在答案中最多相隔Skip个词,其中Skip为参数。例如,“我|很|喜欢|晚上|跑步”中,如果Skip=2,则“我|很”,“我|喜欢”,“我|晚上”都是ROUGE-S所考虑的二元组。
ROUGE-L计算标准答案和模型答案的最长公共子序列(Longest CommonSubsequence, LCS)的长度L。这个子序列不一定要在原序列中连续出现。例如,“我|喜欢|这个|学校”和“我|在|这个|学校|时间|很|长”的最长公共子序列是“我|这个|学校”,长度为3。然后,ROUGE-L计算L和标准答案单词个数的比值RLCS、L和模型答案单词个数的比值PLCS,以及它们的调和平均数FLCS。其中FLCS即为ROUGE-L的分值,如式6所示:

式6 ROUGE-L相关定义
Tips:其中,β为ROUGE-L的参数。
3.2.3 实验与结果分析
ERNIE-M论文中,在阅读理解任务里,将ERNIE-M与mBERT、XLM、XLM-R、INFOXLM等模型在两种评估方式(英语评估与全语言评估)下进行对比分析,故在平台下同样使用与论文中一样的模型与评估方式进行新数据集的实践,结果如图65所示:
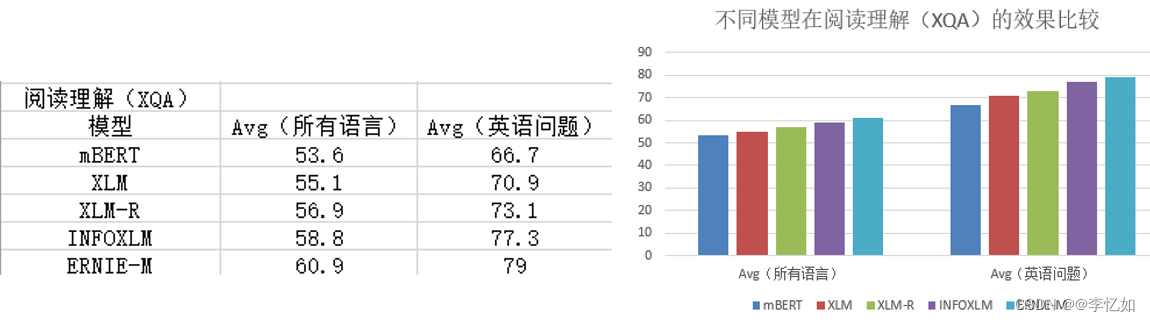
图65 不同模型在阅读理解(XQA)的效果比较
分析:如图65所示,在XQA(新数据集)下,ERNIE-M在两种评估方式下也均取得SoTA结果,新数据集阅读理解任务实践成功,验证了ERNIE-M实验结论的正确性与模型的优越性。
4.新的应用场景实践
除了论文中提到的自然语言推断、命名实体识别、阅读理解、语义相似度、跨语言检索五个任务,ERNIE-M还可以在其他应用场景中进行任务处理。在本部分,将以对话情绪识别为例,探究ERNIE-M在新的应用场景下的效果及其与其他多语言模型对比。
4.1 实验相关介绍
4.1.1 任务介绍
给出一段对话的文字记录,以及每个组成话语的说话者信息,对话情绪识别的任务目标在于从一组定义好的情绪中确定每句话的情绪。样例如图66所示:

图66 对话情绪识别样例
4.1.2 实验设置与数据集选择
实验环境:本次对话情绪识别使用百度开源AI平台实现ERINE-M。
对比模型选择:除了ERNIE-M,本次对比模型选择了BOW、LSTM、Bi-LSTM、CNN、TextCNN、BERT。
数据集选择:本次数据集按类别分为三大数据集,分别为闲聊、客服、微博数据集(来源于百度),同时对应了三种不同的应用场景。
4.2 实验与结果分析
4.2.1 实验流程
在平台上正式进行实验,实验大致流程如图67所示:

图67 对话情绪识别平台实现流程
4.2.2 实验结果及分析
实验结果如图68所示:

图68 不同模型在对话情绪识别中的效果对比
分析:由图68可见,对于对话情绪识别任务,在不同数据集下,ERNIE-M相对其他模型均有着更高的准确率,取得了SoTA的结果,验证了ERNIE-M的可迁移性,以及其在不同应用场景下模型的优越性。
六、模型优化
ERNIE-M在不同的自然语言处理任务中均取得了不错的效果,但对其实现方式与模型构建方法进行剖析,还存在可以优化的部分,基于2021-2022的最新研究成果及经典方法,在本部分提出几种模型优化的思路,详解如下。
1.数据部分改进
数据导入与预处理为多语言模型第一步,ERNIE-M也是如此,在此对数据部分提出几种优化思路。
1.1 双语句对挖掘
方法名称:Language-agnostic bert sentence embedding
对于多语言模型,平行语料的限制是共同的问题,可在模型中添加一种数据增广方式——双语句对挖掘(bi-text mining)。ERNIE-M通过训练一个简单的CDS打分模型,从海量网页中挖掘可能的双语句对,并采样让人类评估,保证优质翻译的占比在80%以上。
1.2 文本分类数据增强
方法名称:AEDA:An Easier Data Augmentation Technique for Text Classification
对于含有文本分类的多语言任务,可以使用AEDA进行数据增强,核心为在原始文本中随机插入一些标点符号,属于增加噪声的一种,主要与EDA论文对标,突出“简单”二字。加入前后效果对比如图69所示:
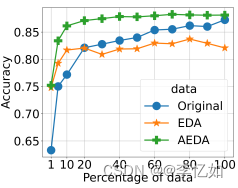
图69 文本分类数据增强效果
2.预训练部分改进
模型预训练为多语言模型第二步,ERNIE-M也是如此,在此对预训练部分提出几种优化思路。
2.1 对比学习
在多语言模型的预训练过程中,对比学习(Constrastive Learning)也是常见的研究角度之一。在HICTL中,作者在不同维面(facet)上做对比学习:句子级别和单词级别。HICTL的输入是句子和它对应的翻译(如果有平行语料)或者扰动后的版本(如果没有平行语料)。在句子层面,HICTL让句子与其对应的翻译句(或扰动句)的向量表达尽可能接近,与同一个batch内的其他句子的向量表达尽可能远。同时作者也提出了一种有趣的插值算法,用于构造困难负例(见论文Figure 2);在单词层面,将句对中出现的单词作为正例向量,其它单词作为负例向量,如图70所示:

图70 HITCL对比学习原理
分析:故在ERNIE-M预训练的损失与评估上可以加入对比学习。
2.2 分阶段预训练
除了目标函数外,训练方式也可以进行改进。如LaBSE中采用了Progressive Stacking的预训练方法:假设需要训练一个L层的模型,则首先训练前L/4,然后训练前L/2,最后训练全部L层。其中每次都使用上一个环节的权重来初始化当前环节的模型,如图71所示:

图71 分阶段预训练Progressive Stacking样例
3.微调部分改进
模型微调为多语言模型第三步,ERNIE-M也是如此,在此以NoisyTune为例,对微调部分提出一种优化思路。
方法名称:NoisyTune: A Little Noise Can Help You Finetune Pretrained Language Models Better
自2018年BERT模型横空出世,预训练语言模型基本上已经成为了自然语言处理领域的标配,「pretrain+finetune」成为了主流方法,下游任务的效果与模型预训练息息相关;然而由于预训练机制以及数据影响,导致预训练语言模型与下游任务存在一定的Gap,导致在finetune过程中,模型可能陷入局部最优。
为了减轻上述问题,提出了NoisyTune方法,即,在finetune前加入给预训练模型的参数增加少量噪音,给原始模型增加一些扰动,从而提高预训练语言模型在下游任务的效果,如图72所示:

图72 NoisyTune改动模型
通过矩阵级扰动(matrix-wise perturbing)方法来增加噪声,定义预训练语言模型参数矩阵为[W1,W2,……,WN],其中,N表示模型中参数矩阵的个数,扰动如式7所示:

式7 矩阵级扰动定义
Tips:其中,U(a,b)表示从a到b范围内均匀分布的噪声;λ表示控制噪声强度的超参数;std表示标准差。
代码实现如图73所示:

图73 NoisyTune代码实现
分析:这种增加噪声的方法,可以应用到各种预训练语言模型中,可插拔且操作简单。故可在ERNIE-M微调前尝试使用NoisyTune。
七、拓展
除了上文提到的ERINE-M的分析、实现、应用、优化等,实际上还有一些相关知识可以拓展。另外,ERNIE-M仅为ERNIE框架中的一个框架,在此对于其他体系框架做简单介绍。
1.XTREME
1.1 XTREME简介
据估计,如今地球上有 6000 多种语言,我们穷其一生也不可能通晓那么多语言。那么,如何理解罕见语言呢?有不少科学家正在研究如何利用人工智能使用这些语言工作,XTREME 便是其中之一(ERNIE-M也使用此标准)。
自然语言处理面临的主要挑战是构建这样一套系统:不仅能用英语,而且也能用世界上所有约 6900 多种语言工作。虽然世界上大多数语言都没有足够的数据来单独训练健壮的模型,但幸运的是,许多语言确实共享了相当多底层结构,因此诞生了许多我们前文详解过的多语言模型。
然而,在实践中,对这些多语言模型方法的评估大多集中在一小部分任务上,并且针对相似的语言。为了鼓励对多语言学习进行更多研究,谷歌发表了论文(XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization)。XTREME 涵盖了 40 种不同类型的语言(跨 12 个语系),包括 9 个任务,这些任务都需要对不同层次的语法或语义进行推理。选择 XTREME 中的语言是为了最大限度地提高语言多样性、现有任务的覆盖率和训练数据的可用性。
在这些语言中,还有许多尚未充分研究的语言,如 达罗毗荼语系(Dravidian languages)泰米尔语(Tamil)(印度南部、斯里兰卡和新加坡语言)、泰卢固语(Telugu)和马拉雅拉姆语(Malayalam)(印度南部语言),以及 尼日尔 - 刚果语系(Niger–Congo languages)斯瓦希里语(Swahili)和约鲁巴语(Yoruba)(非洲语言)。论文提供了代码和数据,包括运行各种基准的示例,可在 GitHub 上获得,地址详见:https://github.com/google-research/xtreme
1.2 XTREME任务和语言
XTREME 中包含的任务涵盖了一系列范式,包括文档分类、结构化预测、文献检索和问答系统,样例如图74所示。因此,为了使模型在 XTREME 基准测试上取得成功,它们必须学习泛化到许多标准跨语言迁移设置的表示法。
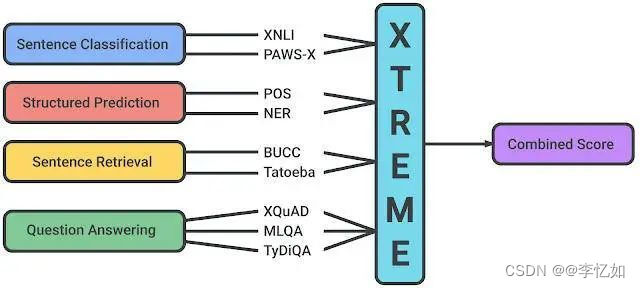
图74 XTREME 基准测试中支持的任务
其中,每个任务都包含 40 种语言的一个子集。为了获得更多用于 XTREME 分析的低资源语言数据,我们将自然语言推理(XNLI)和问答系统(XQuAD)这两个具有代表性任务的测试集从英语自动翻译成其他语言。论文实验表明,在这些任务中使用翻译后的测试集的模型表现出了与使用人类标记的测试集相当的性能。
1.3 零样本评估
要评估使用 XTREME 的性能,首先必须对模型进行多语言文本的预训练,并使用鼓励跨语言学习的目标。然后,对特定任务的英语数据进行微调,因为英语是最有可能提供标签数据的语言。然后,XTREME 评估这些模型的零样本跨语言传输性能,也就是说,在没有特定任务数据的其他语言上对这些模型进行评估。如图75所示,三个步骤的过程,包括从预训练到微调再到零样本迁移。

图75 零样本评估样例
针对给定模型的跨语言迁移学习过程:对多语言文本进行预训练,然后对下游任务进行英语微调,最后使用 XTREME 进行零样本评估。
在实践中,这种零样本设置的好处之一是计算效率:预训练模型只需对每个任务的英语数据进行微调,然后就可以直接在其他语言上进行评估了。不过,对于有其他语言的标签数据的任务,我们也会在语言数据上进行微调对比。最后,论文通过获得所有 9 个 XTREME 任务的零样本得分来提供一个综合得分。
1.4 迁移学习的测试平台
论文使用几种较优的预训练多语言模型进行实验,包括 multilingual BERT,XLM 和 XLM-R,以及大规模多语言机器翻译模型 M4。这些模型有一个共同特点,就是它们已经对来自多语言的大量数据进行了预训练。在我们的实验中,我们选择了这些模型的变体,这些变体在大约 100 种语言上进行了预训练,其中包括基准测试的 40 种语言。
我们发现,尽管模型在大多数现有英语任务上实现了接近人类的表现,但在其他许多语言上的表现却明显低于人类。在所有模型的结构化预测和问答系统任务中,英语的表现与其他语言的表现差距最大,而在结构化预测和文档检索中,不同语言的结果分布最大。
为说明这一点,在图76中,我们按任务和语言的不同,显示了在所有语系中表现最好的模型 XLM-R 在零样本设置中的情况。不同任务之间的得分没有可比性,所以主要关注的应该是不同任务之间语言的相对排名。正如我们所看到的,许多高资源的语言,特别是印欧语系的语言,其排名一直较高。相比之下,该模型在其他语系,如汉藏语系、日本 - 琉球语系、朝鲜语系、尼日尔 - 刚果语系等语言上的表现较差。

图76 迁移学习实验结果
Tips:XTREME 中所有任务和语言在零样本设置下的最佳表现模型 XLM-R 的性能。所报的分数是基于特定任务的度量标准的百分比,在不同任务中并不能直接比较。人类的表现(如果有的话)以红星表示,每种语系的具体示例均以其 ISO 639-1 编码表示。
此外,论文还进行了一些有趣的观察,如下4点:
(1)在零样本设置中,M4 和 mBERT 在大多数任务中都能与 XLM-R 竞争,而在特别有挑战性的问答系统任务中,后者的表现要优于它们。例如,在 XQuAD 上,XLM-R 的得分为 76.6,而 mBERT 和 M4 的得分分别为 64.5 和 64.8,在 MLQA 和 TyDi QA 上也有类似的得分差距。
(2)我们发现,使用机器翻译的基准,无论是翻译训练数据还是测试数据,都非常有竞争力。在 XNLI 任务中,mBERT 在零样本设置中得分为 65.4,而在使用翻译训练数据时得分为 74.0。
(3)我们观察到,少样本设置(即使用有限数量的语言内标记数据,如果可用的话)对于较简单的任务(如命名实体识别)特别有竞争力,但对于较复杂的问答系统任务来说,作用不大。这一点可从 mBERT 的表现中看出,在少样本设置中,mBERT 在命名实体识别任务上的表现提到了 42%,得分从 62.2 提高到 88.3,但对于问答系统任务(TyDi QA),只提高了 25%(得分从 59.7 提高到 74.5)。
(4)总的来说,在所有模式和环境中,英语与其他语言的表现仍存在较大差距,这说明跨语言迁移的研究仍然有很大的潜力。
2.百度在ERNIE体系框架的尝试
ERNIE-M是百度在2021年针对多语言任务提出的预训练-微调框架,但实际上百度自2019年前就在研究ERNIE体系框架并在各种人工智能产品上进行尝试,在论文、产品、平台上均一直不断发展。其ERNIE体系框架发展如图77所示,平台化可用体系框架如图78所示,本部分将会针对其中除ERNIE-M的几个框架做简单介绍。
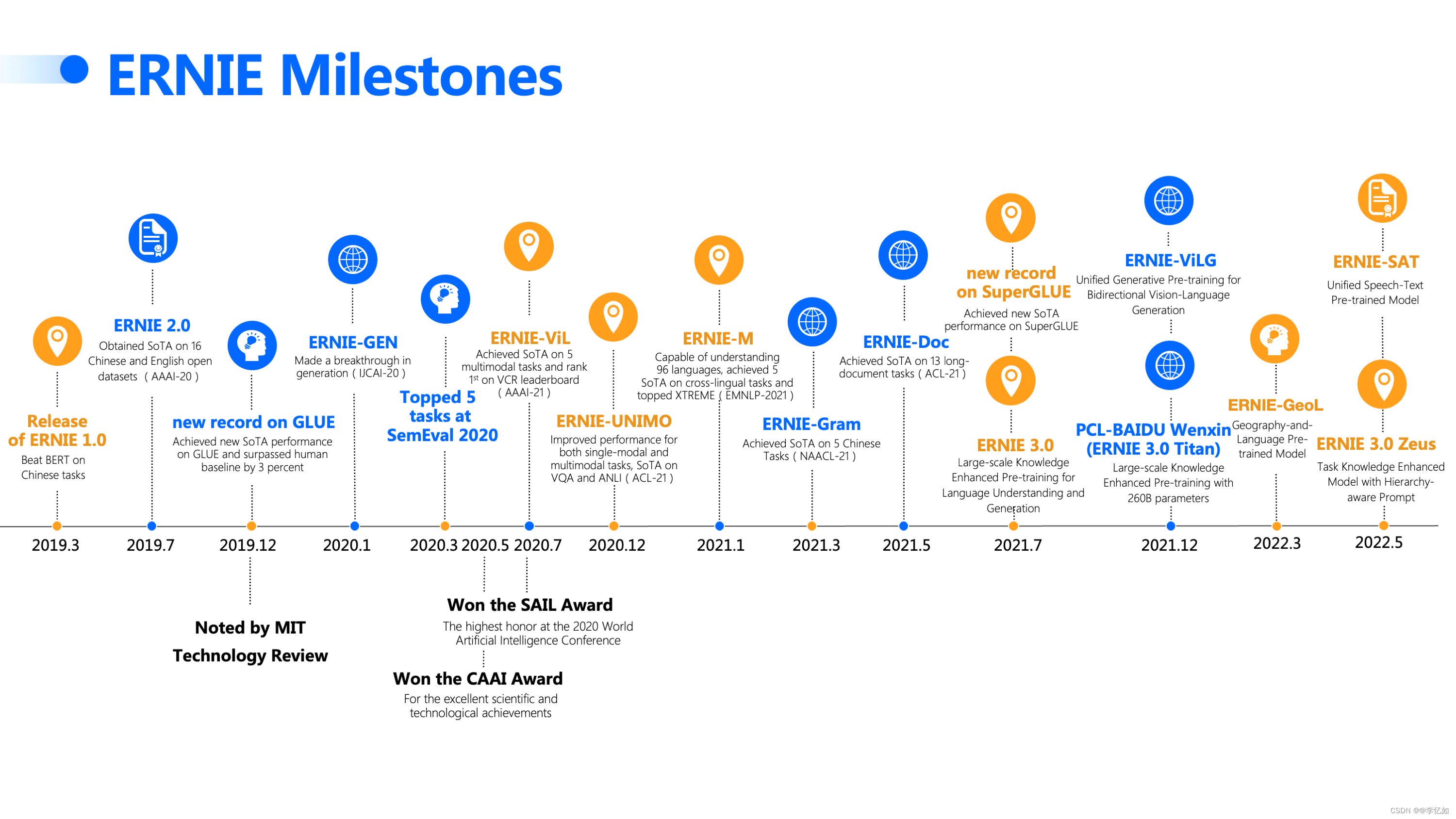
图77 ERNIE体系框架发展历程

图78 平台化ERNIE体系框架
2.1 ERNIE 3.0 Zeus
2.1.1 模型概述
ERNIE 3.0 Zeus 是 ERNIE 3.0 系列模型的最新升级。其除了对无标注数据和知识图谱的学习之外,还通过持续学习对百余种不同形式的任务数据学习。实现了任务知识增强,显著提升了模型的零样本/小样本学习能力。可用于智能创作、摘要生成、问答、语义检索、情感分析、信息抽取、文本匹配、文本纠错等各类自然语言理解和生成任务。
2.1.2 原理介绍
ERNIE 3.0 Zeus 在学习过程中使用统一范式的多任务学习,建模数据中不同粒度的语义信息。为了进一步学习特定任务的相关知识,ERNIE 3.0 Zeus 提出了层次化提示(Prompt)学习技术。在数据构造时通过层次化的 Text Prompt 库将百余种不同的任务统一组织成自然语言的形式,和海量无监督文本以及百度知识图谱联合学习。此外训练过程引入了层次化的 Soft Prompt 建模了不同任务之间的共性与特性,进一步提升了模型对于不同下游任务的建模能力,原理如图79所示:

图79 ERNIE 3.0 Zeus原理
2.1.3 应用样例
百度提供了官方API供用户体验使用,地址如下:文心大模型 - 产业级知识增强大模型 (baidu.com),一个应用样例如图80所示:

图80 ERNIE 3.0 Zeus应用样例
2.2 ERNIE-ViLG
2.2.1 模型概述
ERNIE-ViLG 模型提出统一的跨模态双向生成模型,通过自回归生成模式对图像生成和文本生成任务进行统一建模,更好地捕捉模态间的语义对齐关系,从而同时提升图文双向生成任务的效果。文心 ERNIE-ViLG 在文本生成图像的权威公开数据集 MS-COCO 上,图片质量评估指标 FID(Fréchet Inception Distance)远超 OpenAI 的 DALL-E 等同类模型,并刷新了图像描述多项任务的最好效果。此外,文心 ERNIE-ViLG 还凭借强大的跨模态理解能力,在生成式视觉问答任务上也取得了领先成绩。可应用于艺术创作、虚拟现实、图像编辑、AI辅助设计、虚拟数字人等。
2.2.2 原理介绍
百度文心 ERNIE-ViLG 使用编码器-解码器参数共享的 Transformer 作为自回归生成的主干网络,同时学习文本生成图像、图像生成文本两个任务。
基于图像向量量化技术,文心 ERNIE-ViLG 把图像表示成离散的序列,从而将文本和图像进行统一的序列自回归生成建模。在文本生成图像时, 文心 ERNIE-ViLG 模型的输入是文本 token 序列,输出是图像 token 序列;图像生成文本时则根据输入的图像序列预测文本内容。两个方向的生成任务使用同一个 Transformer 模型。视觉和语言两个模态在相同模型参数下进行相同模式的生成,能够促进模型建立更好的跨模态语义对齐,原理如图81所示:
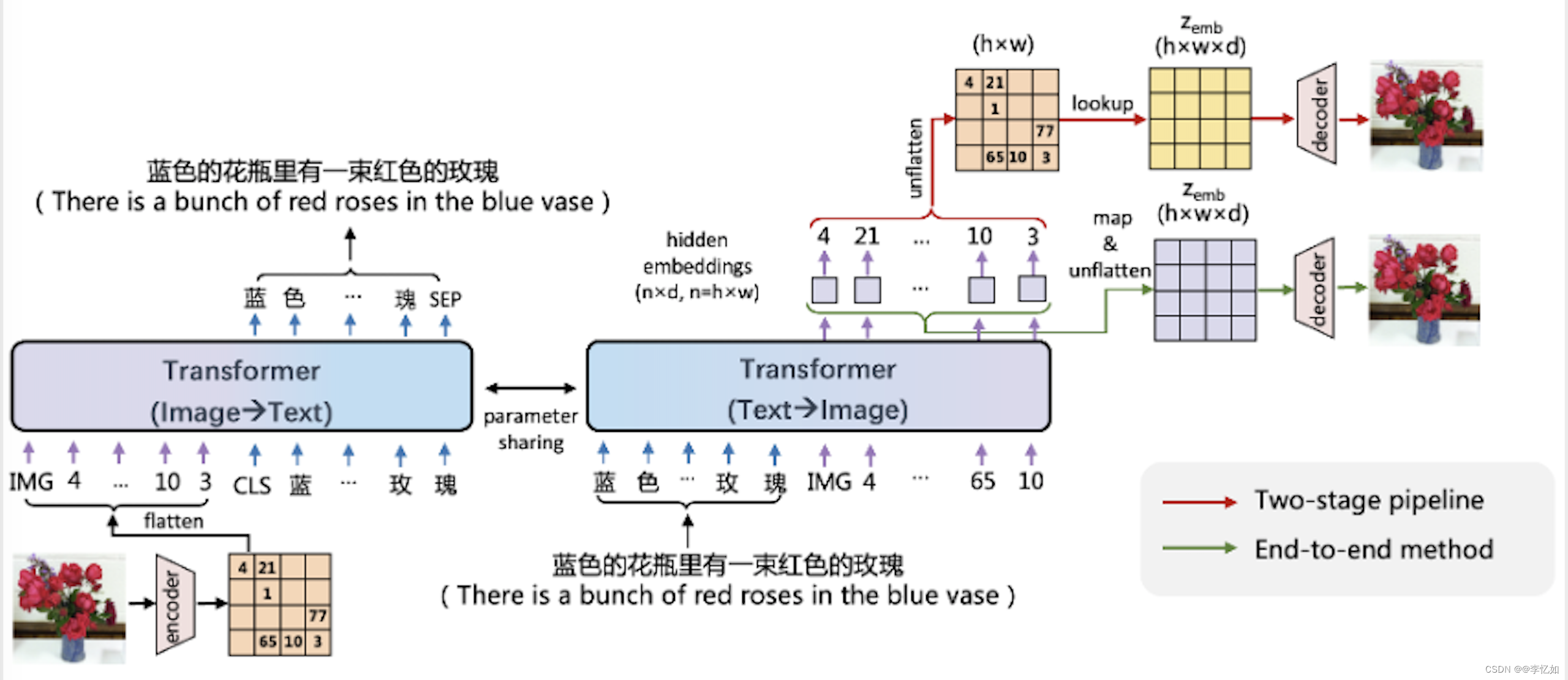
图81 ERNIE-ViLG原理
已有基于图像离散表示的文本生成图像模型主要采用两阶段训练,文本生成视觉序列和根据视觉序列重建图像两个阶段独立训练,文心 ERNIE-ViLG 提出了端到端的训练方法,将序列生成过程中 Transformer 模型输出的隐层图像表示连接到重建模型中进行图像还原,为重建模型提供语义更丰富的特征;对于生成模型,可以同时接收自身的抽象监督信号和来自重建模型的原始监督信号,有助于更好地学习图像表示。
文心 ERNIE-ViLG 构建了包含 1.45 亿高质量中文文本-图像对的大规模跨模态对齐数据集,并基于百度飞桨深度学习平台在该数据集上训练了百亿参数模型,在文本生成图像、图像描述等跨模态生成任务上评估了该模型的效果。
2.2.3 应用样例
百度提供了官方API供用户体验使用,地址如下:文心大模型 - 产业级知识增强大模型 (baidu.com),一个应用样例如图82所示:
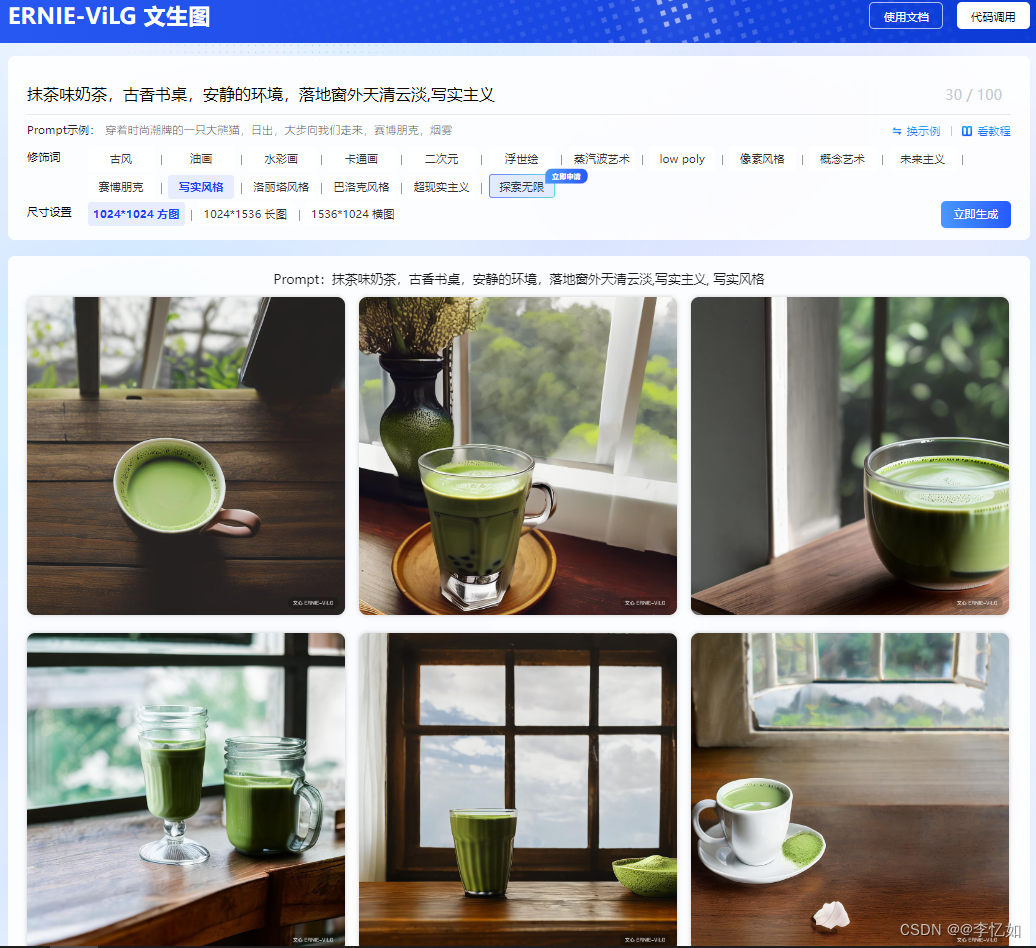
图82 ERNIE-ViLG应用样例
2.3 思考

图83 百度相关信息
如图83,百度公司将“用科技让复杂的世界更简单”作为自己的使命,也确实在产品推出的同时不断潜心研究相关技术。互联网的公司如潮水般涨了又退,但用户真切地从中获得了便利。
八、参考资料
1.参考文献
[1] Ouyang, Xuan, et al. "ERNIE-M: Enhanced multilingual representation by aligning cross-lingual semantics with monolingual corpora." arXiv preprint arXiv:2012.15674 (2020).
[2] Bengio Y, Ducharme R, Vincent P. A neural probabilistic language model[J]. Advances in neural information processing systems, 2000, 13.
[3] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
[4] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[J]. Advances in neural information processing systems, 2013, 26.
[5] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
[6] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[7] Lample G, Conneau A. Cross-lingual language model pretraining[J]. arXiv preprint arXiv:1901.07291, 2019.
[8] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
[9] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[10] Pires T, Schlinger E, Garrette D. How multilingual is multilingual BERT?[J]. arXiv preprint arXiv:1906.01502, 2019.
[11] Liu Y, Ott M, Goyal N, et al. Roberta: A robustly optimized bert pretraining approach[J]. arXiv preprint arXiv:1907.11692, 2019.
[12] Conneau A, Khandelwal K, Goyal N, et al. Unsupervised cross-lingual representation learning at scale[J]. arXiv preprint arXiv:1911.02116, 2019.
[13] Lample G, Conneau A. Cross-lingual language model pretraining[J]. arXiv preprint arXiv:1901.07291, 2019.
[14] Huang H, Liang Y, Duan N, et al. Unicoder: A universal language encoder by pre-training with multiple cross-lingual tasks[J]. arXiv preprint arXiv:1909.00964, 2019.
[15] Chi Z, Dong L, Wei F, et al. InfoXLM: An information-theoretic framework for cross-lingual language model pre-training[J]. arXiv preprint arXiv:2007.07834, 2020.
[16] Luo F, Wang W, Liu J, et al. Veco: Variable encoder-decoder pre-training for cross-lingual understanding and generation[J]. 2020.
[17] Hendrycks D, Gimpel K. A baseline for detecting misclassified and out-of-distribution examples in neural networks[J]. arXiv preprint arXiv:1610.02136, 2016.
[18] Kingma D P, Ba J. Adam: A method for stochastic optimization[J]. arXiv preprint arXiv:1412.6980, 2014.
[19] Rajpurkar P, Zhang J, Lopyrev K, et al. Squad: 100,000+ questions for machine comprehension of text[J]. arXiv preprint arXiv:1606.05250, 2016.
[20] Benjamin E J, Muntner P, Alonso A, et al. Heart disease and stroke statistics—2019 update: a report from the American Heart Association[J]. Circulation, 2019, 139(10): e56-e528.
[21] Liu J, Lin Y, Liu Z, et al. XQA: A cross-lingual open-domain question answering dataset[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 2358-2368.
[22] Hu J, Ruder S, Siddhant A, et al. Xtreme: A massively multilingual multi-task benchmark for evaluating cross-lingual generalisation[C]//International Conference on Machine Learning. PMLR, 2020: 4411-4421.
[23] Feng F, Yang Y, Cer D, et al. Language-agnostic bert sentence embedding[J]. arXiv preprint arXiv:2007.01852, 2020.
[24] Karimi A, Rossi L, Prati A. Aeda: An easier data augmentation technique for text classification[J]. arXiv preprint arXiv:2108.13230, 2021.
[25] Wei X, Weng R, Hu Y, et al. On learning universal representations across languages[J]. arXiv preprint arXiv:2007.15960, 2020.
[26] Wu C, Wu F, Qi T, et al. NoisyTune: A Little Noise Can Help You Finetune Pretrained Language Models Better[J]. arXiv preprint arXiv:2202.12024, 2022.
[27] Hu J, Ruder S, Siddhant A, et al. Xtreme: A massively multilingual multi-task benchmark for evaluating cross-lingual generalisation[C]//International Conference on Machine Learning. PMLR, 2020: 4411-4421.
[28] Zhang H, Yin W, Fang Y, et al. ERNIE-ViLG: Unified generative pre-training for bidirectional vision-language generation[J]. arXiv preprint arXiv:2112.15283, 2021.
2.参考资料
EMNLP2021之AEDA:一种更简单的文本分类数据增强技术 - 知乎 (zhihu.com)
ACL2022 | NoisyTune:微调前加入少量噪音可能会有意想不到的效果 - 知乎 (zhihu.com)
ERNIE 3.0: 用于语言理解和生成的大规模知识强化预训练 - 知乎 (zhihu.com)
飞桨PaddlePaddle-源于产业实践的开源深度学习平台
GitHub - PaddlePaddle/ERNIE at repro
文心大模型 - 产业级知识增强大模型 (baidu.com)
ACM MM'2022 | 首个针对跨语言跨模态检索的噪声鲁棒研究工作 - 知乎 (zhihu.com)
低资源和跨语言NER任务的新进展:词级别数据增强技术_PaperWeekly的博客-CSDN博客
[预训练语言模型专题]跨语种语言模型 - 知乎 (zhihu.com)
谷歌提出XTREME:评估跨语言的大规模多语言多任务基准_AI_Sebastian Ruder_InfoQ精选文章
百度发布预训练模型ERNIE-M,同时掌握96门语言,取得多项世界突破_百度-NLP的博客-CSDN博客
NLP多语言模型调研——一个工程视角 - 知乎 (zhihu.com)
NLP领域预训练模型的现状及分析 - 知乎 (zhihu.com)
RoBERTa概述 - mathor (wmathor.com)

