- 1Android 运行时权限处理解析_android.permission-group.storage
- 2Library <iconv2.4.0> not found 解决方法_library 'iconv.2.4.0' not found
- 3机器学习理论与实战_yaser1.con
- 4漫谈Java加密技术(四)_java p7 数字签名
- 5Helix3DToolkit.Wpf.SharpDX学习(一)_helixtoolkit.wpf.sharpdx
- 6基于Spring Boot的四川火锅文化网站的设计与实现
- 7ChatGLM部署+pytorch安装_chatglm.cpp 源码部署
- 8「python网络编程」查看并修改socket接收和发送缓冲区大小_python socket 通讯大小
- 9Android ContentProvider管理多媒体内容_content providers create digital text, video, audi
- 10cvc-complex-type.2.4.a: Invalid content was found starting with element ‘base-extension‘. One of ‘{l
Oracle中的单行函数-字符函数_oracle upper
赞
踩
目录
在Oracle数据库中,字符函数是用于处理字符串类型的数据的函数。字符函数可以对字符串进行大小写转换、截取、连接、替换等操作,用于对字符串进行处理和运算。
下面解释下常见的字符函数:
1、upper(str)
将字符串转换为大写。例如:
- select UPPER('Hello World')
- from dual;
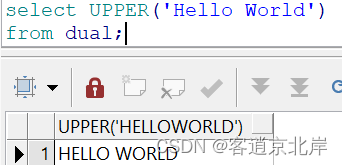
2、lower(str)
将字符串转换为小写转小写。例如:
- select lower('HELLO WORLD')
- from dual;
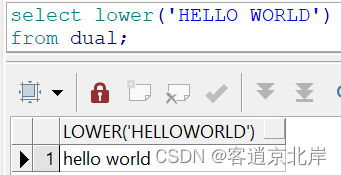
3、initcap(str)
转首字母大写,多个单词都会转首字母大写,英文字母中间有非英文或者标点符号就看做是多个单。例如:
- select initcap('smcvlsmw almlafl号sfl,lamc,jjlk1sf')
- from dual;
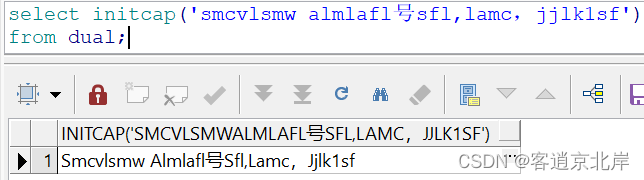
4、length(str)
计算字符的长度,返回的是数值,例如:
- select length('万里长城永不倒'),length('gun gun chang jiang dong shi shui!')
- from dual;

5、lengthb(str)
计算字节的长度,返回的是数值,例如:
- select lengthb('万里长城永不倒'),lengthb('gun gun chang jiang dong shi shui!')
- from dual;

注意:
在Oracle中,一个汉字的长度是1,占用的字节数也是2。这是因为Oracle默认使用UTF-8编码,一个汉字在UTF-8编码下占用2个字节。
要计算一个字符串的长度,可以使用Oracle内置函数LENGTH。
要计算一个字符串占用的字节数,可以使用Oracle内置函数LENGTHB。
换算时,需要注意不同编码方式下一个汉字占用的字节数不同。在UTF-8编码下,一个汉字占用2个字节;在UTF-16编码下,一个汉字占用2个或4个字节;在GB2312编码下,一个汉字占用2个字节。
用下面命令查看数据库参数信息!!!
select * from nls_database_parameters;6、trim([str2 from ]str1)
默认去除两端的空字符,写上[str2 from ]str1则去除str1两端的str2,比如:
- select trim(' a b c '),trim(' !!ename '),trim('a' from 'aabbaa')
- from dual;

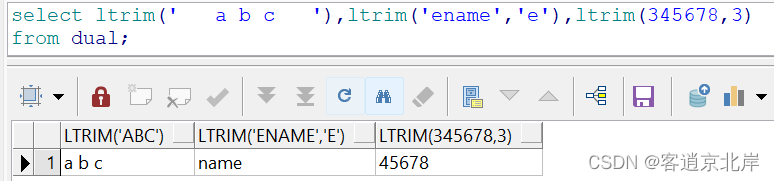
7、ltrim(str1[,str2])
去除字符串左端的字符,例如:
- select ltrim(' a b c '),ltrim('ename','e'),ltrim(345678,3)
- from dual;
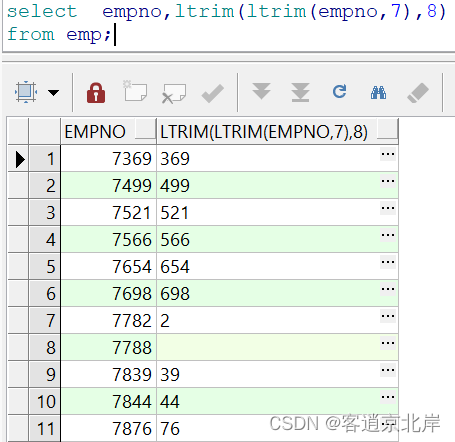
举个栗子:
查询员工编号,去掉左端的7,再去掉左端的8的员工编号
- select empno,ltrim(ltrim(empno,7),8)
- from emp;
8、rtrim(str1[,str2])
去除字符串右端的字符,如果str2不写默认去空格。比如:
- select rtrim(' a b c '),rtrim('ename','e'),rtrim(345678,8)
- from dual;
9、lpad(str1,数,str2)
字符串中向左填充字符
10、rpad(str1,数,str2)
字符串向右填充字符
str1:原字符串;
数:填充之后的长度,如果原字符串位数大于填充之后的长度会被截断(从左到右算长度);
str2:要填充的字符串。
比如:
- --abc的左边填充一颗*
- select lpad('abc',4,'*')
- from dual;
-
- --abc的左右各填充两个*
- 法一:
- select rpad(lpad('abc',5,'*'),7,'*')
- from dual;
-
- 法二:
- select '**'||'abc'||'**'
- from dual;
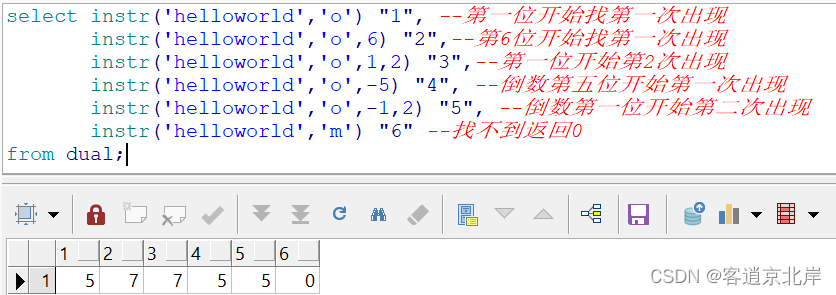
11、instr(str1,str2[,数1[,数2]])
查找出字符串出现的位置,最后返回的结果是数值;
str1:原字符串;
str2:要查找的字符串;
数1:从第几位开始找 ,如果数1和数2都不写,那么就默认是从第一位开始找,即查找第一次出现的位置;
数2:第几次出现,如果数2不写就默认查找第一次出现的位置。
比如:
- select instr('helloworld','o') "1", --第一位开始找第一次出现
- instr('helloworld','o',6) "2",--第6位开始找第一次出现
- instr('helloworld','o',1,2) "3",--第一位开始第2次出现
- instr('helloworld','o',-5) "4", --倒数第五位开始第一次出现
- instr('helloworld','o',-1,2) "5", --倒数第一位开始第二次出现
- instr('helloworld','m') "6" --找不到返回0
- from dual;
举例熟悉运用:
- --查找 helloworld 里o第一次和第二次出现的位置
- select instr('helloworld','o') 第一次,
- instr('helloworld','o',1,2) 第二次
- from dual;
-
- --查找员工姓名和员工姓名中A第1次出现和第二次出现的位置
- select ename,instr(ename,'A') 第一次,
- instr(ename,'A',1,2) 第二次
- from emp
- where instr(ename,'A')!=0;
再举个栗子:
要求查询4月份入职的员工信息。
- SELECT *
- FROM emp
- WHERE hiredate LIKE '%4月%';
- --或
- SELECT *
- FROM emp
- WHERE INSTR(hiredate,'4月')!=0;
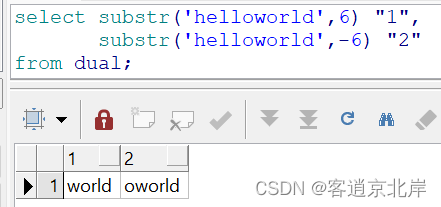
12、substr(str,数1[,数2])
作用是截取字符串
str:原字符串;
数1:从第几位开始 可以是负数 表示倒数第几位;
数2:截取几位 不写默认截取到最后。
比如:
- select substr('helloworld',6) "1",
- substr('helloworld',-6) "2"
- from dual;
举例熟悉运用:
- --从helloworld里截取OWO 截取后三位 截取3-5位 截取出hrld
- select substr('helloworld',5,3) "1",
- substr('helloworld',-3) "2",
- substr('helloworld',3,3) "3",
- substr('helloworld',1,1)||
- substr('helloworld',-3) "4"
- from dual;
-
- --截取员工姓名从字母A开始截,截到最后(名字不包含A的不显示)
- select substr(ename,instr(ename,'A'))
- from emp
- where instr(ename,'A')!=0;
13.replace(str1,str2[,str3])
作用是整体替换字符串
str1:原字符串;
str2:被替换的;
str3:用来替换的,如果不写默认替换成空,把str1里的str2整体替换成str3。
比如:
- select replace('helloworld','owo'),
- replace('helloworld','owo','*')
- from dual;
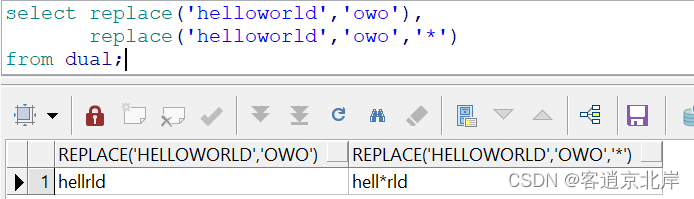
举例熟悉运用:
- --把helloworld 里的l替换成*,o替换成#
- select replace(replace('helloworld','l','*'),'o','#')
- from dual;
-
- --把员工编号中的8替换成7,然后所有的7替换成9
- --在去掉左端的9,显示替换前和替换后的员工编号
- select empno 替换前,
- ltrim(replace(replace(empno,8,7),7,9),9) 替换后
- from emp;
14、translate(str1,str2,str3)
作用是逐一替换字符。把str1里的str2逐一替换成str3,参数2和参数3字符串要一一对应,
当参数2的位数多于参数3,参数2多出来的位数会被替换成空;
当参数3的位数多于参数2,参数3多出来的位数无效;
参数2或者参数3为空时结果为空。
比如:
要求把helloworld里所有的l替换成*,所有的o替换成#。
- select translate('helloworld','lo','*#') a,
- translate('helloworld','lo','*') b,
- translate('helloworld','o','*#') c,
- translate('helloworld','lo','') d,
- translate('helloworld','','*') e
- from dual;
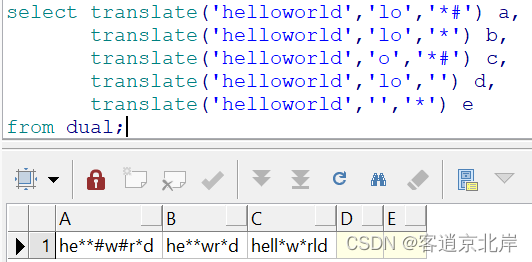
举例熟悉运用:
①把helloworld里的l和o替换成空
- select translate('helloworld',' lo','*') e
- from dual;
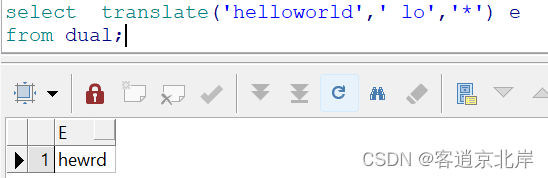
要将字符串中多个字符替换为空,我们可以采用参数2的个数大于参数3的个数方法完成。因为当参数2的位数多于参数3,参数2多出来的位数会被替换成空。
比如要把helloworld里的abcde替换成空 。
- select translate('helloworld',' abcde','q')
- from dual;
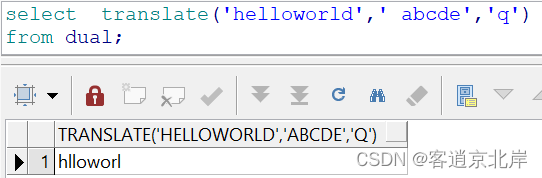
比如把员工姓名中的AMS三个字母替换成空,显示替换前和替换后。
- select ename 替换前,translate(ename,'*AMS','*') 替换后
- from EMP;

在这里会用到一种方法:简称为加星法;在参数2中第一位用*,后面紧跟需要替换为空的字符,然后参数3使用‘*’替换,因为原来的字符串中是没有’*’,所以*在替换字符串只是起到占位。此法只适用于原字符串无*,我们只需要找一个原字符串没有的字符即可,原理是同[参数2的位数多于参数3,参数2多出来的位数会被替换成空。]
②把helloworld里的ll替换成ab
- select translate('helloworld','ll','ab') e
- from dual;
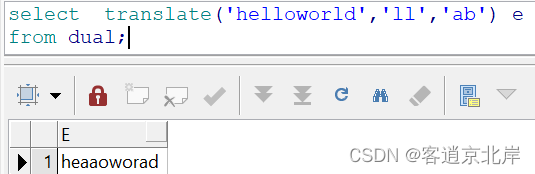
此时会发现字符串中的'l'全部替换为'a',参数2重复的字符在参数3中是只能替换成第一个。这种做法是不可以的,不支持!!!
③把员工姓名中和职位重复的字母替换成*
- select ename,job,translate(ename,job,'*************') 替换后
- from EMP;
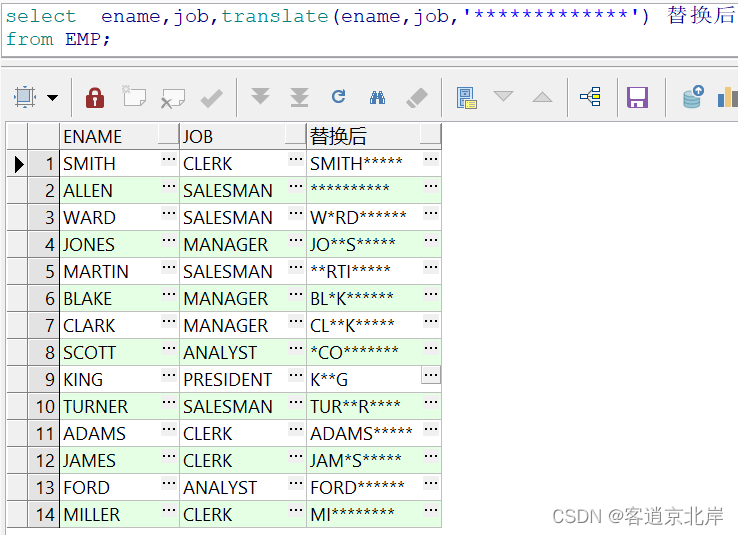
把str1里的str2逐一替换成str3,即把ename里与job相同的字母逐一替换成参数3,一定要注意参数2和参数3的字符串是要一一对应的,即参数2:job字符串的每个字符都对应于*,所以ename和job重复的字符都对应于*,如果没有重复就不会置换;如果参数2字符多于参数3,多出的字符会无效,所以尽可能让参数3的*多一些;因为参数3多于参数2的字符是无效的,所以大可放心参数3的*多一些。
比如:
- select 'abcdefg' ename, 'hgtacfopl' job,
- translate('abcdefg','hgtacfopl','*************') 替换后
- from dual;

④把员工姓名中和职位重复的字母替换成空
- select ename,job,translate(ename,'*'||job,'*') 替换后
- from EMP;
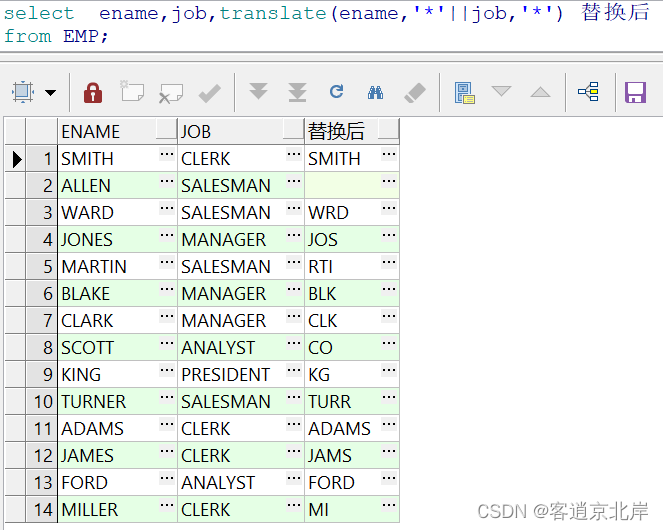
比如:
- select 'abcdefg' ename, 'hgtacfopl' job,
- translate('abcdefg','*'||'hgtacfopl','*') 替换后
- from dual;
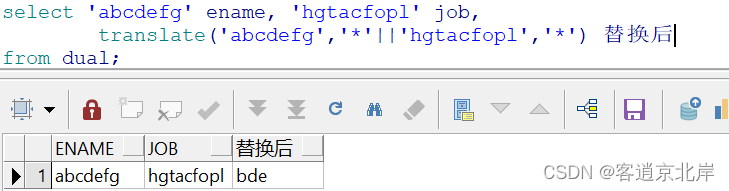
采用加星法解决,原理同当参数2的位数多于参数3,参数2多出来的位数会被替换成空;
举个栗子:
要求查询ename和job包含相同字母的员工姓名和工作
- 法一:加*法
- select ename,job
- from emp
- where translate(ename,'*'||job,'*')<>ename or
- translate(ename,'*'||job,'*') is null;
-
- 法二:
- select ename,job
- from emp
- where translate(ename,job,'**********')<>ename
要求查找ename和job相同的字母。
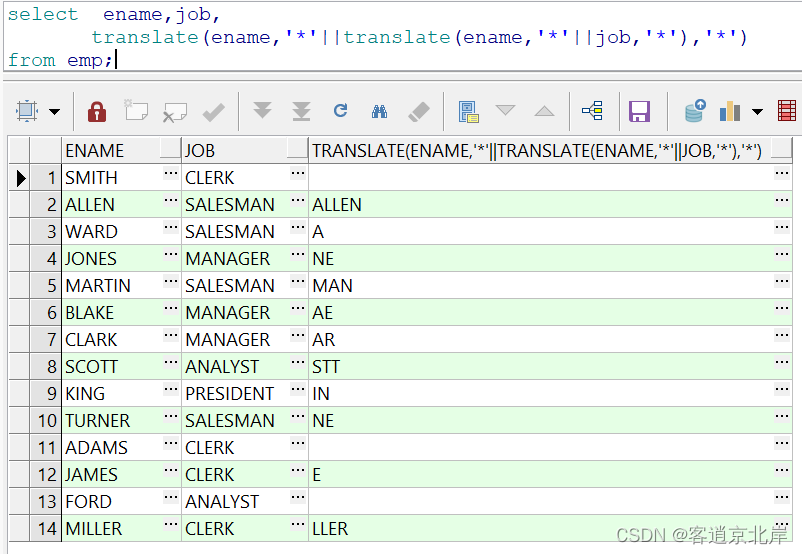
- select ename,job,
- translate(ename,'*'||translate(ename,'*'||job,'*'),'*')
- from emp;
使用加星法拼接字符串更方便解决这种问题哈!!!先将两个字符串的重复字母替换为空,然后将原字符串去除重复字母后的字符串再替换为空,最后剩余的就是重复字母啦!!!
运行结果如下:
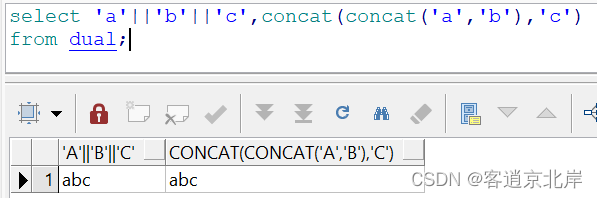
15、concat(str1,str2)
连接字符串,只能是两个参数;如果要连接多个参数需要函数嵌套。
比如:
- select 'a'||'b'||'c',concat(concat('a','b'),'c')
- from dual;
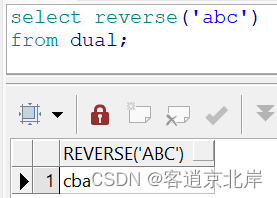
16、reverse(str)
反转字符串。比如:
- select reverse('abc')
- from dual;