
- 1【华为OD机考 统一考试机试C卷】 机器人仓库搬砖(C++ Java JavaScript Python C语言)_python 二分法 机器人仓库搬砖
- 2Java毕业设计:基于SSM的学生宿舍管理系统的设计与实现_基于ssm框架的学生宿舍管理系统的e-r图
- 3【群晖秘籍】群晖添加第三方套件(套件源),让可用功能更多更好(任性拓展)_群晖第三方套件源推荐 国内
- 4win+r下文件夹创建、删除命令操作_win+r g
- 5FTPClient storeFile返回false,报550-The process cannot access the file because it is being used by anoth_ftpclient.storefile返回false解决方法
- 6IText实现对PDF文档属性的基本设置_stamper.setencryption
- 7python3进阶篇(二)——深析函数装饰器_python3进阶篇(二)——深析函数装饰器
- 8升级 Xcode 15模拟器 iOS 17.0 Simulator(21A328) 下载失败_xcode 下载 simulator 失败
- 9喜讯 雨笋教育优秀学员荣获望城区网络安全攻防演练二等奖
- 10LINUX学习基础篇(八)管道符、命令的别名和快捷键_管道符快捷键
ChatkBQA:一个基于大语言模型的知识库问题生成-检索框架11.13
赞
踩
ChatkBQA:一个基于大语言模型的知识库问题生成-检索框架

摘要
基于知识的问答(KBQA)旨在从大规模知识库(KBs)中获得自然语言问题的答案,通常分为两个研究部分:知识检索和语义分析。然而,三个核心的挑战仍然存在,包括低效的知识检索,检索错误的语义分析产生不利影响,和以前的KBQA方法的复杂性。在大型语言模型(LLM)时代,我们引入了ChatKBQA,这是一种基于Llama-2,ChatGLM 2和Baichuan 2等开源LLM微调的新型生成然后检索KBQA框架。ChatKBQA建议首先使用微调的LLM生成逻辑形式,然后通过无监督检索方法检索和替换实体和关系,这更直接地改进了生成和检索。实验结果表明,ChatKBQA在标准KBQA数据集、WebQSP和ComplexWebQuestions(CWQ)上实现了最新的性能。这项工作还提供了一个新的范例,结合LLM与知识图谱(KG)的可解释性和知识要求的问题回答。
1 引言
基于知识的问答(KBQA)是一种经典的NLP任务,用于基于大规模知识库(KB)上的事实回答自然语言问题,例如Freebase,和DBpedia,其由结构化知识图(KG)组成,所述结构化知识图谱(KG)由包括(头实体、关系、尾实体)的三元组构建。以前的KBQA方法主要集中在解决两个核心问题:知识检索和语义解析。知识检索主要是从知识库中根据问题定位最相关的实体、关系或三元组,缩小了考虑的范围。然后,语义解析本质上将问题从非结构化的自然语言转换成结构化的逻辑形式(诸如S表达式),然后可以将其转换为可执行的图形数据库查询语言(例如SPARQL)以获得精确的答案和可解释的路径。
以前的KBQA工作提出了具有命名实体识别(NER)技术的不同知识检索方法,实体链接或子图检索。然后,他们利用检索到的事实三元组,使用seq2seq模型(如T5)直接得出问题的答案。其他在检索相关三元组之后执行语义解析以生成逻辑形式,然后在KB上执行相应的转换后的SPARQL查询以获取答案。此外,Yu等人将这两种方法结合起来,进一步提高了KBQA任务的准确性。
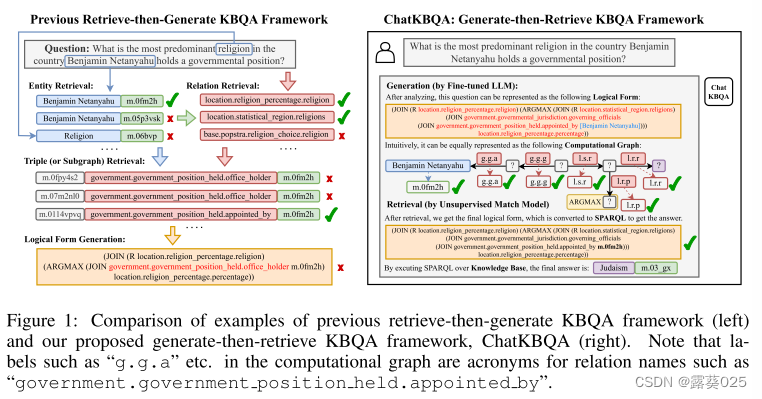
尽管如此,如图1左侧所示,仍然存在三个主要挑战。
- (1)检索效率低。传统的方法首先确定候选实体的跨度,然后进行实体检索和关系检索。由于自然语言问题的结构与知识库事实不同,大多数方法需要训练专用模型来进行低效的提取和链接。
- (2)不正确的检索结果会误导语义分析。先前的方法还利用检索到的三元组作为与原始问题一起沿着到seq2seq模型的引用的输入。然而,由于检索到的三元组并不总是准确的,它们会对语义解析结果产生不利影响。此外,如果有许多检索到的三元组,seq2seq模型需要更长的上下文长度。
- (3)多个处理步骤使KBQA成为一项非常复杂的任务。先前的工作将KBQA任务分解为多个子任务,形成复杂的流水线处理,这使得复制和迁移具有挑战性。在大型语言模型(LLM)正在重构传统的NLP任务,一个更直接的解决方案,利用LLM重新制定传统的KBQA范式是有前途的。
为了克服这些挑战,我们引入了ChatKBQA,这是一种基于微调开源LLM的新型生成然后检索KBQA框架和百川2-7 B。如图1右侧所示,ChatKBQA为KBQA提出了一种直接的方法:
1.首先生成逻辑形式,
2.然后进行实体和关系的检索,旨在避免检索对逻辑形式生成的影响,提高检索效率。
在生成阶段,我们使用指令调优技术微调开源LLM,使他们具备以逻辑形式感知和生成的能力。由于LLM的特殊学习能力,波束搜索结果表明,大约74%的测试问题,一旦转换为逻辑形式,已经匹配基本事实。此外,在实体和关系被屏蔽(骨架)的情况下,超过91%的样本具有与地面事实一致的逻辑形式结构。在检索阶段,我们提出了一种无监督的实体和关系的检索方法,进行短语级语义检索的实体集和关系集的知识库中的实体和关系的逻辑形式,并取代它们在各自的位置。整个ChatKBQA框架简单易用,其中LLM部分可以替换为当前开源的LLM,检索部分可以灵活地与其他语义匹配模型交换,确保了即插即用的出色性能。
为了测试我们提出的框架的性能,我们在两个标准KBQA数据集WebQSP和复杂网络问题(CWQ),使用和不使用黄金实体的设置。实验结果表明,ChatKBQA在KBQA任务中实现了新的最先进的性能。我们还设置了额外的实验,以验证我们的生成,然后检索方法是否提高了生成结果和检索效率。最后,我们还讨论了如何从这个框架的见解使我们设想未来的LLM和KG的组合。
3 准备工作
在本节中,我们定义了我们工作的两个基本概念:知识库和逻辑形式,其次是知识库问答任务的问题陈述。
定义1:知识库(KB)
定义2:逻辑形式
逻辑形式是自然语言问题的结构化表示。以S-表达式为例,一个逻辑形式通常由投影和各种运算符组成。
投影操作表示三元组(s,r,o)在s或o上的单跳查询,其中,(?,r,o)记为(JOIN r o),而(s,r,?)表示为(JOIN(R r)s)。
各种运算符包括
“
A
N
D
”(
A
N
D
E
1
E
2
)
“AND”(AND E_1 E_2)
“AND”(ANDE1E2)表示取
E
1
和
E
2
E_1和E_2
E1和E2的交点,
“
C
O
U
N
T
”(
C
O
U
N
T
E
1
)
“COUNT”(COUNT E_1)
“COUNT”(COUNTE1)表示计数
E
1
E_1
E1,
“
A
R
G
M
A
X
”(
A
R
G
M
A
X
E
1
r
)
“ARGMAX”(ARGMAX E_1 r)
“ARGMAX”(ARGMAXE1r)表示取
E
1
在
r
E_1在r
E1在r关系中投影后获得的最大文字,
“
A
R
G
M
I
N
”(
A
R
G
M
I
N
E
1
r
)表示取
E
1
的
r
“ARGMIN”(ARGMIN E_1 r)表示取E_1的r
“ARGMIN”(ARGMINE1r)表示取E1的r关系的投影之后获得的最小文字,
“
G
T
”(
G
T
E
1
l
)
“GT”(GT E_1 l)
“GT”(GTE1l)表示取
E
1
的大于
l
E_1的大于l
E1的大于l的部分,
“
G
E
”(
G
E
E
1
l
)表示取
E
1
“GE”(GE E_1 l)表示取E_1
“GE”(GEE1l)表示取E1中大于或等于1的部分,
“
L
T
”(
L
T
E
1
l
)表示取
E
1
“LT”(LT E_1 l)表示取E_1
“LT”(LTE1l)表示取E1中小于1的部分,
“
L
E
”(
L
E
E
1
l
)表示取
E
1
“LE”(LE E_1 l)表示取E_1
“LE”(LEE1l)表示取E1中小于或等于
l
l
l的部分,其中
E
1
或
E
2
E_1或E_2
E1或E2表示子层逻辑形式。
问题陈述
对于KBQA任务,给定自然语言问题Q和知识库K,我们需要首先将Q转换为逻辑形式
F
=
S
p
(
Q
)
,其中
S
p
(
.
)
F = Sp(Q),其中Sp(.)
F=Sp(Q),其中Sp(.)是一个语义解析函数。然后将
F
转换为等价的
S
P
A
R
Q
L
查询
q
=
C
o
n
v
e
r
t
(
F
)
F转换为等价的SPARQL查询q = Convert(F)
F转换为等价的SPARQL查询q=Convert(F),其中
C
o
n
v
e
r
t
(
.
)
Convert(.)
Convert(.)是固定的转换函数。最后,最后一组答案
A
=
E
x
e
c
u
t
e
(
q
∣
K
)
A = Execute(q | K)
A=Execute(q∣K)是通过对K执行q而获得的,其中
E
x
e
c
u
t
e
(
.
)
Execute(.)
Execute(.)是查询执行函数。
4 方法
在本节中,我们首先概述ChatKBQA框架,然后介绍对开源大型语言模型(LLM)的有效微调,通过微调LLM生成逻辑形式,实体和关系的无监督检索,以及可解释的查询执行。
4.1 ChatKBQA概述
ChatKBQA是一个生成然后检索的KBQA框架,用于使用微调的开源LLM进行知识库问答(KBQA)。
首先,ChatKBQA框架需要通过指令微调,基于KBQA数据集中的(自然语言问题,逻辑形式)对 有效地微调开源LLM。
然后使用微调的LLM通过语义解析将新的自然语言问题转换为相应的候选逻辑形式。
然后,ChatKBQA在短语级别检索这些逻辑形式中的实体和关系,并搜索转换为SPARQL后可以对KB执行的逻辑形式。
最后,利用转换后得到的SPARQL得到最终的答案集,并获得可解释的和知识所需的自然语言问题的答案。

4.2 在LLMS上进行高效微调
为了构造指令微调训练数据,ChatKBQA首先将KBQA数据集中测试集的自然语言问题对应的SPARQL转换为等价的逻辑形式,然后将实体ID(例如,“m.06w2sn5”)与相应的实体标签(例如,“[ Justin比伯]”),让LLM比无意义的实体ID更好地理解实体标签。然后,我们联合自然语言问题(例如:“贾斯汀比伯兄弟的名字是什么?”)以及处理后的对应逻辑形式(例如“(AND(JOIN [ people,person,gender ] [ Male ])(JOIN(R [ people,sibling relationship,sibling ])(JOIN(R [ people,person,sibling s ])[ Justin比伯])”)分别作为“输入”和“输出”,并添加“指令”为“生成检索与给定问题对应的信息的逻辑形式查询”。构成了开源LLM的指令微调训练数据。
为了降低微调具有大量参数的LLM的成本,ChatKBQA利用参数高效微调(PEFT)的方法来微调仅少量的模型参数,并实现与完全微调相当的性能。其中,LoRA通过使用低秩近似来减少在微调期间具有变化权重的大型语言模型的内存占用。QLoRA通过将梯度反向传播到冻结的4位量化模型中来进一步减少存储器,同时保持完整的16位微调任务的性能。P调谐v2采用前缀调谐方法,该方法在输入之前的每一层处并入可微调参数。Freeze通过仅微调Transformer最后几层的全连接层参数,同时冻结所有其他参数,加快了模型的收敛速度。ChatKBQA可以在所有上述有效的微调方法以及LLM之间切换,例如Llama-2-7B和ChatGLM 2-6B。
4.3 用微调LLMS生成逻辑形式
通过微调,LLM在一定程度上掌握了从自然语言问题转换为逻辑形式的语义解析能力。因此,我们使用微调的LLM对测试集中的新问题进行语义解析,我们发现大约63%的样本已经与地面真值逻辑形式相同。当我们使用波束搜索时,LLM输出的候选逻辑形式C列表包含约74%的具有真实逻辑形式的样本,这表明微调的LLM具有良好的语义解析任务的学习和解析能力。此外,如果我们用“[ ]”替换所生成的候选逻辑形式中的实体和关系(例如,“(AND(JOIN [ ] [ ])(JOIN(R [ ])(JOIN(R [ ])[ ]))“)形成逻辑形式的骨架,则为地面真实逻辑形式的骨架,出现在候选骨架中的样本百分比大于91%。这表明我们只需要将这些逻辑形式中相应位置的实体和关系替换为知识库中已有的实体和关系,就可以进一步提高性能。
4.4 实体和关系的非监督检索
由于微调LLM的良好的生成能力的逻辑形式的骨架,在检索阶段,我们采用了无监督的检索方法,它采取的实体和关系的候选逻辑形式,并通过他们通过短语级语义检索和替换,得到最终的逻辑形式转换为SPARQL可执行的知识库。

具体地,如算法1所示,输入是所生成的候选逻辑形式列表C,并且我们按顺序遍历这些逻辑形式F中的每一个。首先,我们执行实体检索。对于F中的每个实体
e
e
e,我们计算与知识库K实体集合E中的每个实体
e
′
e'
e′的标签的相似度
s
e
←
S
i
m
i
E
n
t
i
t
i
e
s
(
e
,
e
′
)
s_e ← SimiEntities(e,e')
se←SimiEntities(e,e′)。我们根据相似度对检索到的实体进行排序,取最高的
k
e
k_e
ke和大于阈值
t
e
t_e
te的,得到该实体的检索结果
e
l
i
s
t
←
T
o
p
K
w
i
t
h
T
h
r
e
s
h
o
l
d
(
e
l
i
s
t
,
k
e
,
t
e
)
e_{list}← TopKwithThreshold(e_{list},k_e,t_e)
elist←TopKwithThreshold(elist,ke,te)。PermuteByEntity函数对检索到的每个位置的实体进行排列,得到实体检索后的结果
F
l
i
s
t
F_{list}
Flist。根据
F
l
i
s
t
F_{list}
Flist中的概率,取top k1且大于阈值t1,得到一个新的候选逻辑形式列表
C
′
.
a
p
p
e
n
d
(
T
o
p
K
w
i
t
h
T
h
r
e
s
h
o
l
d
(
F
l
i
s
t
,
k
1
,
t
1
)
)
C′.append(TopKwithThreshold(F_{list},k_1,t_1))
C′.append(TopKwithThreshold(Flist,k1,t1))。
然后,我们执行关系检索。与实体检索相似,但不同的是,对于 F ∈ C ′ F ∈ C′ F∈C′中的每个关系 r r r,我们根据逻辑形式EF的实体集的邻域计算与每个候选关系 r ′ r′ r′的相似度 s r ← S i m i R e l a t i o n s ( r , r ′ ) s_r ←SimiRelations(r,r′) sr←SimiRelations(r,r′)。我们还根据相似度对检索到的关系进行排序,取最高的 k r k_r kr和大于阈值的 t r t_r tr,得到检索结果 r l i s t ← T o p K w i t h T h r e s h o l d ( r l i s t , r e , r e ) r_{list}←TopKwithThreshold(r_{list},r_e,r_e) rlist←TopKwithThreshold(rlist,re,re)。通过对每个位置的关系检索结果进行排列,得到关系检索后的结果Flist,然后取top k2且大于阈值t2,得到新的候选逻辑形式列表 C ′ ′ . a p p e n d ( T o p K w i t h T h r e s h o l d ( F l i s t , k 2 , t 2 ) ) C''.append(TopKwithThreshold(F_{list},k_2,t_2)) C′′.append(TopKwithThreshold(Flist,k2,t2))。
给定一个查询,无监督检索方法不需要额外的训练来选择语义上与候选集最相似的前k个作为检索到的答案集。BM 25使用词频和逆文档频率来根据文档与给定查询的相关性对文档进行排名。SimCSE是使用比较学习模型的无监督密集信息检索。ChatKBQA可以在上述所有实体检索和关系检索的无监督检索方法之间切换。
4.5 可解释查询执行
在检索之后,我们得到最终的候选逻辑形式列表 C ′ ′ C'' C′′,我们顺序地通过逻辑形式 F ∈ C ′ ′ F ∈ C'' F∈C′′进行查询,并将其转换为 S P A R Q L 查询 q = C o n v e r t ( F ) SPARQL查询q = Convert(F) SPARQL查询q=Convert(F)的等价形式。当找到第一个可以对KB K执行的q时,我们执行以获得最终答案集 A = E x e c u t e ( q ∣ K ) A = Execute(q | K) A=Execute(q∣K)。通过这种方法,我们也可以得到一个完整的推理路径的自然语言问题的基础上 S P A R Q L SPARQL SPARQL查询具有良好的可解释性。综上所述,ChatKBQA提出了一种思想,既利用LLM进行自然语言语义解析以生成图查询,又调用外部知识库对查询进行解释性推理,我们将其命名为思维图查询(GQoT),这是一种很有前途的LLM+KG组合范式,可以更好地利用外部知识,提高Q&A的可解释性,并避免LLM的幻觉。

