
- 1编写程序,将给定的n个整数存入数组中,将数组中的这n个数逆序存放,再按顺序输出数组中的元素。_本题要求编写程序,将给定的n个整数存入数组中,将数组中的这n个数逆序存放,再按顺
- 2JAVA新实战1:使用vscode+gradle+openJDK21搭建java springboot3项目开发环境_vscode gradle
- 3[时序波动关联]模型CoFLUX论文要点整理
- 4python 三维数组,numpy中np.shape的理解_python np.shape
- 5Ubuntu16.04.7+Qt15.5.0环境配置(一条龙讲解)_qt ubuntu
- 6基于双层蚂蚁算法和区域优化的机器人导航新算法 翻译+总结_mo-fa
- 7nested exception is java.lang.NoClassDefFoundError: javax/xml/soap/SOAPElement
- 8Flutter 组件化
- 9Android Studio模拟器无法联网网页显示forbidden_android forbidden
- 103D高斯泼溅的崛起
机器学习实战笔记(一)机器学习基础
赞
踩
什么是机器学习?
机器学习能让我们从数据集中受到启发。我们会利用计算机来彰显数据背后的真实含义,这才是机器学习的真实含义。
机器学习就是把无序的数据转换成有用的信息。可以这么说,机器学习对于任何需要解释并操作数据的领域都有所裨益。
机器学习领域的关键术语
下表是用于区分不同鸟类需要使用的四个不同的属性值。
现实中,你可能会想测量更多的值。通常的做法是测量所有可测属性,然后再挑选出重要部分。
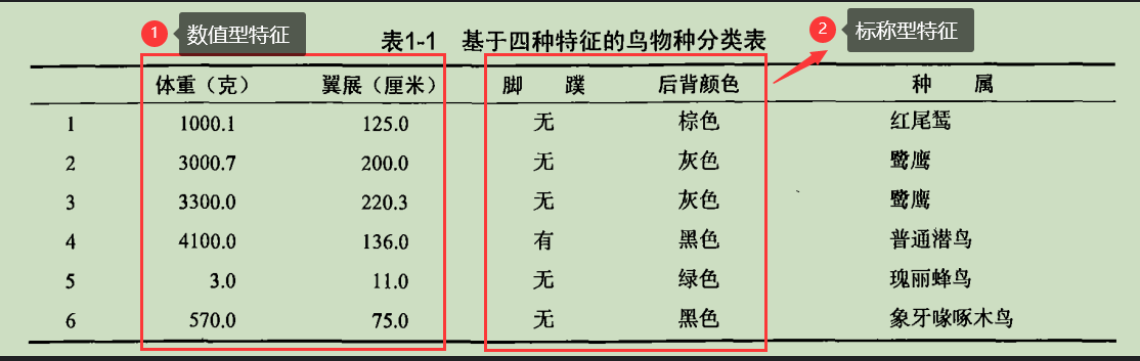
上面测量的这四种值称之为特征,也可叫属性,特征是专业的称呼。表中的每一行都是相关特征的实例。
特征可以分为两类:数值型和**标称型。**标称型的结果只在有限目标集中取值,如真与假、有与无、分类集合{棕色、灰色、黑色}。数值型则可以从无限的数值集合中取值,如0.01、42.0001、125.0等。这两类还可以继续细分。
上表中前两种特征即为数值型特征,后两种为标称型特征。更具体的,第三种是二值型,只可以取0或1、真或假、有与无,第四种是{棕色、灰色、黑色}的枚举类型。
机器学习的主要任务是什么?
分类、回归预测等
机器学习中分类问题的假设
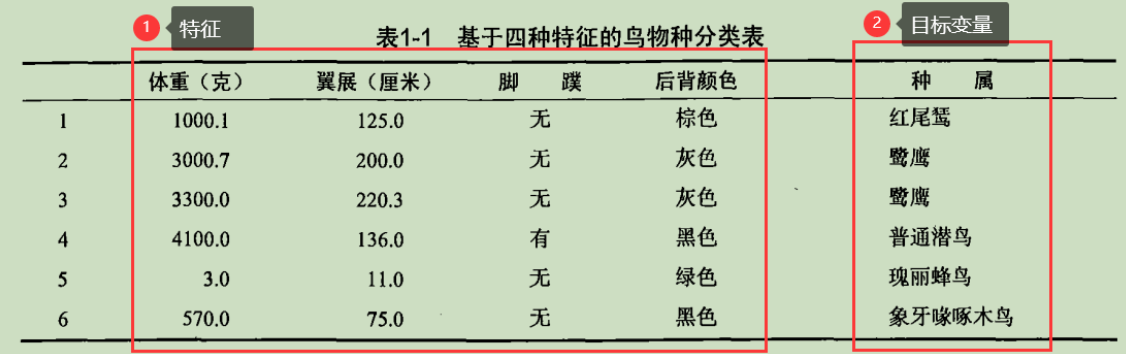
我们通常将分类问题中的目标变量称为类别,并假定分类问题只存在有限个数的类别。
机器学习实现分类任务的步骤有哪些?
-
获取原始数据,进行数据预处理,得到含有所需的全部特征信息和目标变量的数据集。目标变量是机器学习算法的预测结果,在分类算法中目标变量的类型通常是标称型的,而在回归算法中通常是连续型的。
-
划分数据集,通常划分为两套独立的样本集:训练数据和测试数据,或训练集和测试集。训练集是用于训练机器学习算法的数据样本集合。测试集是用于测试模型训练效果的数据样本集合。
-
决定使用某个机器学习算法进行分类。分类机器学习算法有很多:k-近邻算法、决策树、朴素贝叶斯、Logistic回归、支持向量机等。
-
训练模型,为算法输入测试集。训练完成后输入测试集,注意的是测试集不提供目标变量,结果由算法模型进行预测。
-
比较测试样本预测的目标变量值与实际样本类别之间的区别,就可以得出算法的实际精确度。如100个测试集实例,算法预测对了78个,那么精确度就是78%
机器学习的分类
机器学习的另一项任务是回归,它主要用于预测数值型数据。
分类和回归属于监督学习,这类算法必须指导预测什么,即目标变量的分类信息。
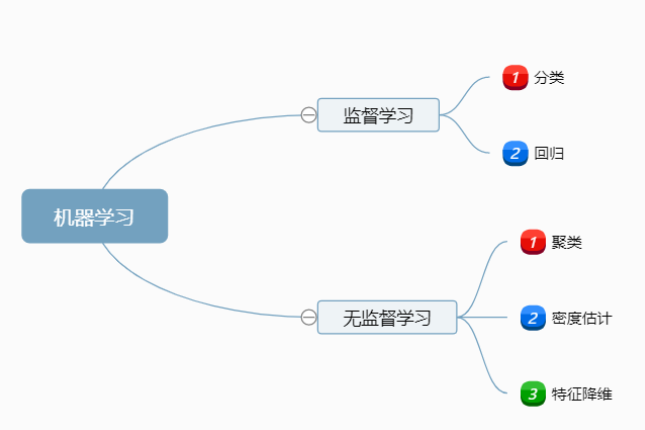
与监督学习相对应的是无监督学习,数据没有类别信息,也不会给定目标值。
在无监督学习中,将数据集合分成由类似的对象组成的多个类的过程被称为聚类;将寻找描述数据统计值的过程称之为密度估计。
此外,无监督学习还可以减少数据特征的维度,以便我们可以使用二维图形或三维图形更加直观地展示数据信息。

开发机器学习应用程序的步骤
- 收集数据,如制作网络爬虫从网站上抽取数据。为了节省时间和精力,可以使用公开可用的数据源。
- 准备输入数据。要确保数据格式符合要求
- 分析输入数据。确保数据集中没有垃圾数据。如空置和极大极小数据实例。
- 训练算法
- 测试算法
- 使用算法
为什么推荐用Python语言开发机器学习应用程序
语法清晰、易于操作纯文本文件、使用广泛,存在大量的开发文档。
Python比较流行,有丰富的模块库可以利用,缩短开发周期:
- SciPy 和 NumPy等科学函数库都实现了向量和矩阵操作。
- Matplotlib库可以绘制2D、3D图形
Python唯一的不足是性能问题,代码跑得慢。Python程序运行的效果不如Java或者C代码高,但是我们可以使用Python调用C编译的


