
- 1PCL点云处理之主成分分析(PCA)拟合圆柱参数(C++详细介绍)(二百二十六)_圆柱体pca
- 2小和问题(归并排序解法)_小和问题(sum) 在一个数组中,每一个数左边比当前数小
- 3Android心得4.3--SQLite数据库--execSQL()和rawQuery()方法_android sqlite rawquery
- 4Vue使用ajax(axios)请求后台数据_vue请求后端数据axios
- 5Hi3681 ----- HarmonyOS的程序框架 和 启动流程_ohos_systeminit
- 6鸿蒙开发工具DevEco Studio安装指导_鸿蒙开发工具安装教程
- 7【Keil 5安装教程】_keil5安装
- 8虚拟机中linux能联网,但是远程连接时提示Network error: Connection timed out的解决办法
- 9OpenHarmony 开源电商项目
- 10Python中OpenCV库(二)_python opencv2
Yes, PP-YOLOE!80.73mAP、38.5mAP,旋转框、小目标检测能力双SOTA!
赞
踩

上个月,百度飞桨团队开源了其最新SOTA通用检测模型——PP-YOLOE+,COCO数据集精度达54.7mAP,其l版本相比YOLOv7精度提升1.9%,V100端到端(包含前后处理)推理速度达42.2FPS,文章回顾请戳:
较YOLOv7精度提升1.9%,54.7mAP的PP-YOLOE+强势登场!
通用检测算法在工业质检、遥感图像场景下会表现出误报、低召回等现象。核心问题在于目标小、密集排布且存在旋转角度。为此,飞桨团队基于PP-YOLOE+推出了旋转框检测算法PP-YOLOE-R(Rotate)以及小目标检测方案PP-YOLOE-SOD(Small Object Detection),前者在DOTA1.0数据集上精度达到80.73 mAP,后者在VisDrone-DET数据集上单模型精度达到38.5mAP,均达到了SOTA性能!
PP-YOLOE-R paper链接如下
https://arxiv.org/abs/2211.02386
开源代码链接如下
https://github.com/PaddlePaddle/PaddleDetection
接下来,本文会详细地为大家介绍这两部分的工作,同时,两位模型的作者将直播详解改造思路及细节,欢迎扫码预约并加入技术交流群:

温馨提示:全文约4141个字,阅读时间约5分钟,整体分为旋转框检测、小目标检测、彩蛋三部分,大家可以按需选读
Part 1
PP-YOLOE-R:一个高效的单阶段Anchor-free旋转框检测模型
背景介绍
旋转框是具有一定角度的矩形框。由于物体本身与图像坐标轴具有大小不一的倾斜角,使用旋转框描述物体相比于使用水平框描述物体包含更少的背景,定位更加精细。旋转框检测常用于遥感影像分析、机器人抓取、自动驾驶、场景文字检测等场景当中。
旋转框检测算法大多从水平框检测算法中改进得到。类似地,旋转框检测算法也可分为一阶段和两阶段的算法以及Anchor-based和Anchor-free的算法。当前的旋转框检测算法多为Anchor-based的方法,且多使用插值和DCN来对齐卷积特征图和旋转物体,为模型的部署带来了不便。
针对此情况,我们从先进的水平框检测算法PP-YOLOE+入手,对其进行了改进,以极少的参数量和计算量取得了极佳的效果。
算法思路
PP-YOLOE-R是一个高效的单阶段Anchor-free旋转框检测模型,基于PP-YOLOE+引入了一系列改进策略来提升检测精度。根据不同的硬件对精度和速度的要求,PP-YOLOE-R包含s/m/l/x四个尺寸的模型。
在DOTA 1.0数据集上,PP-YOLOE-R-l和PP-YOLOE-R-x在单尺度训练和测试的情况下分别达到了78.14mAP和78.28 mAP,这在单尺度评估下超越了几乎所有的旋转框检测模型。
通过多尺度训练和测试,PP-YOLOE-R-l和PP-YOLOE-R-x的检测精度进一步提升至80.02mAP和80.73 mAP,超越了所有的Anchor-free方法并且和最先进的Anchor-based的两阶段模型精度几乎相当。
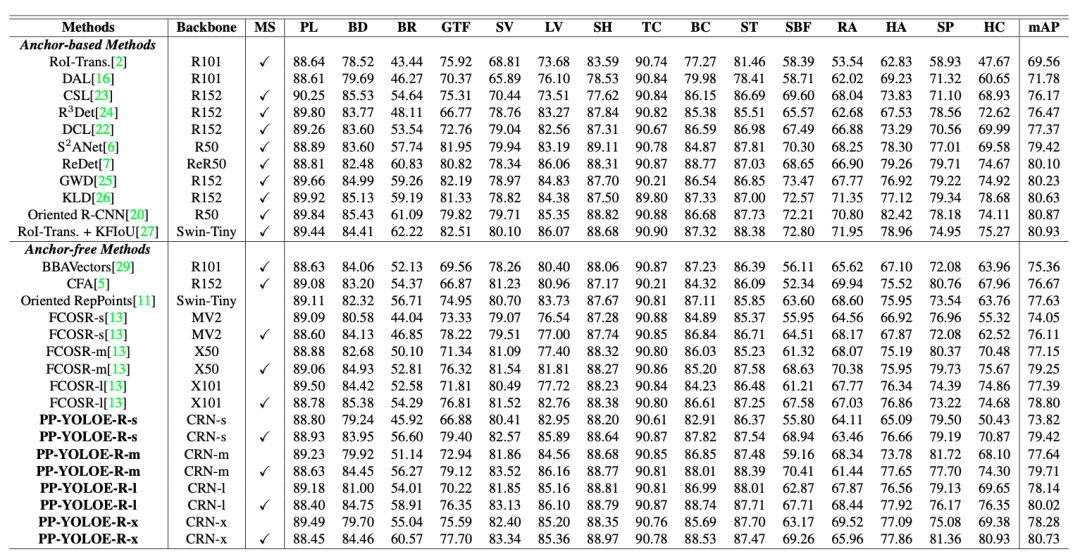
在保持高精度的同时,PP-YOLOE-R避免使用特殊的算子,例如Deformable Convolution或Rotated RoI Align,使其能轻松地部署在多种多样的硬件上。
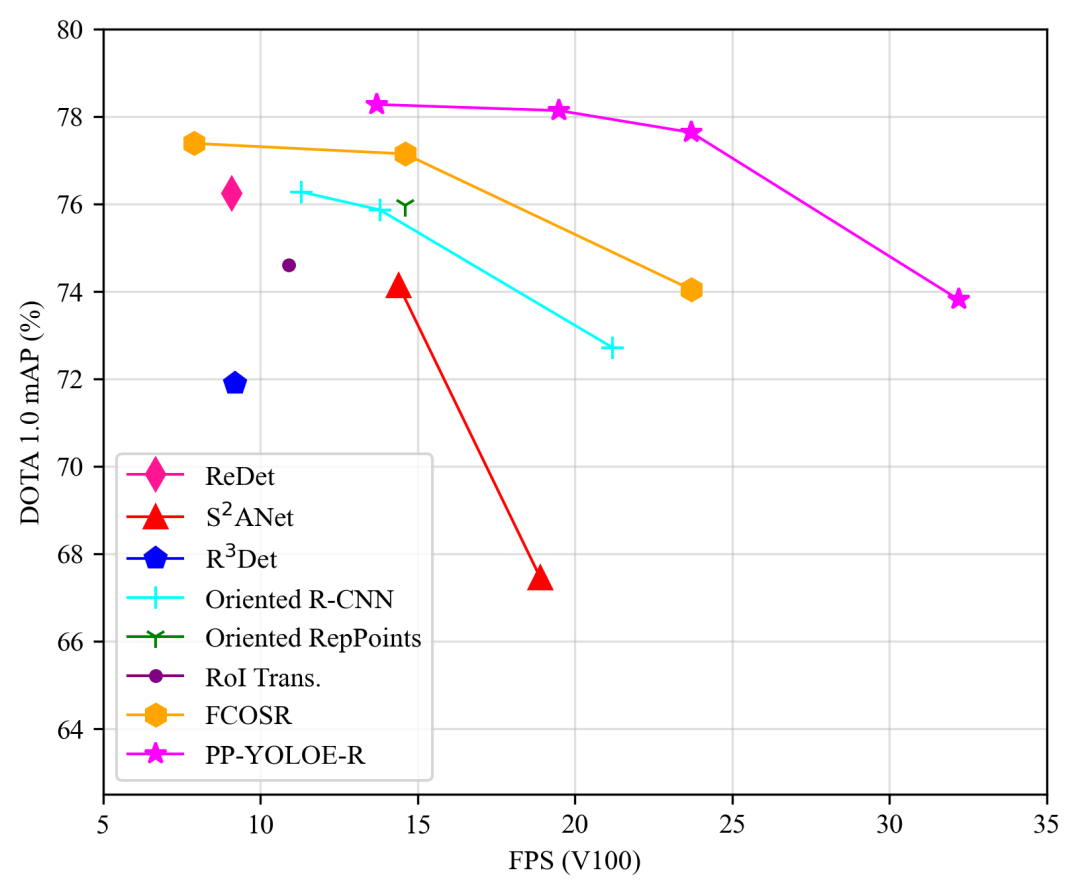
从下图可以看到PP-YOLOE-R相对于其他模型在精度和速度的均衡上均具有明显的优势。
模型结构
PP-YOLOE-R和PP-YOLOE+的对比
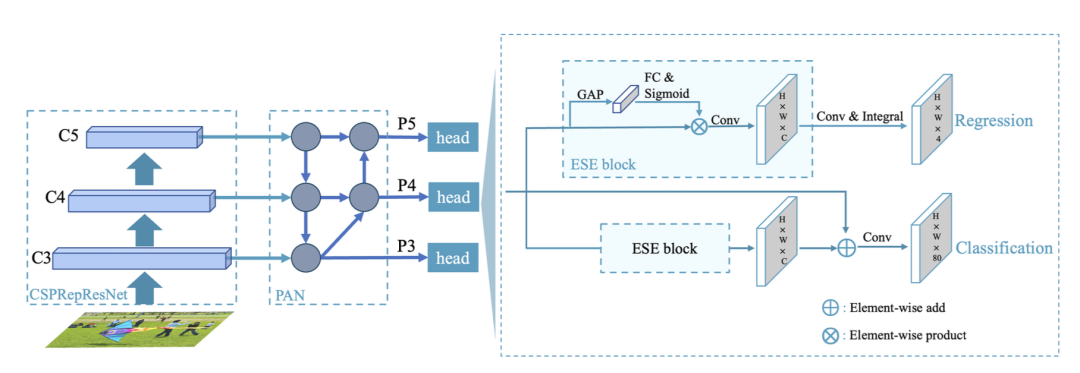
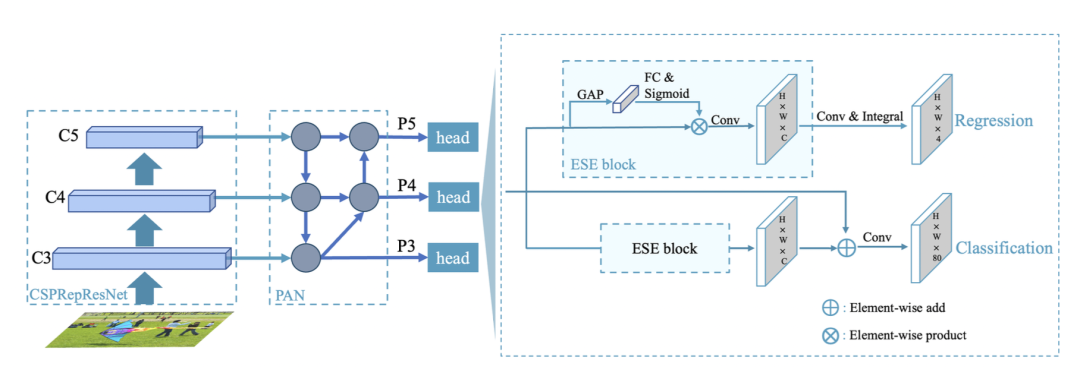
PP-YOLOE-R和PP-YOLOE+整体结构对比如下所示:
PP-YOLOE+结构图
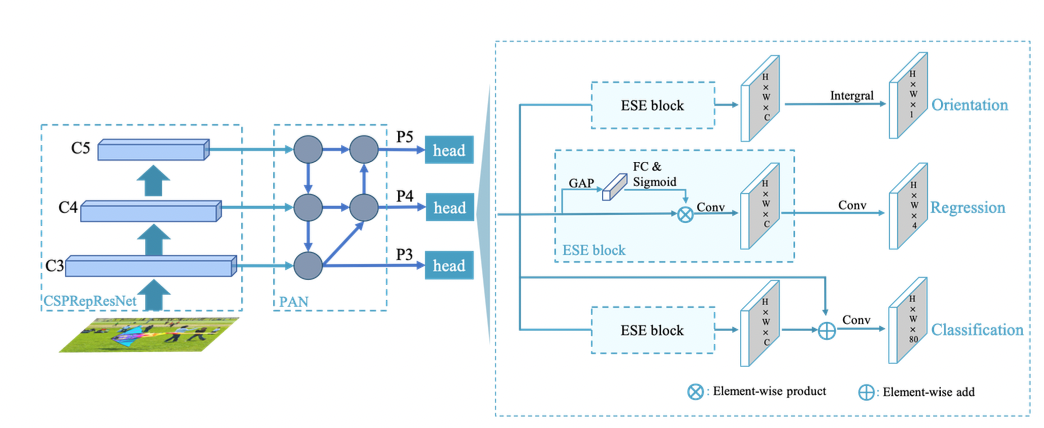
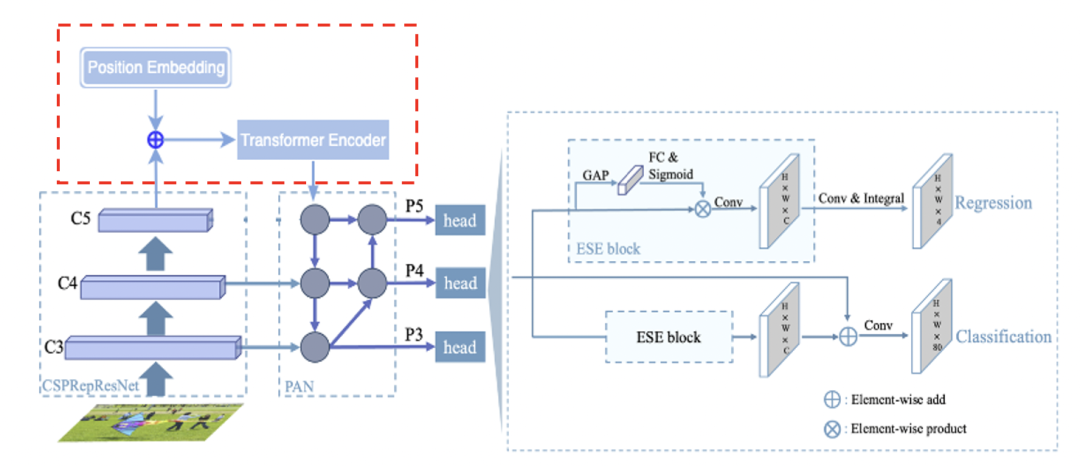
PP-YOLOE-R结构图
从图中可以看出,PP-YOLOE-R与PP-YOLOE的总体结构基本一致,以CSPRepResNet作为backbone,以CSPPAN作为neck,引出P3、P4和P5三个特征图做检测。与之不同的是,PP-YOLOE-R引入了一个解耦的角度预测头。
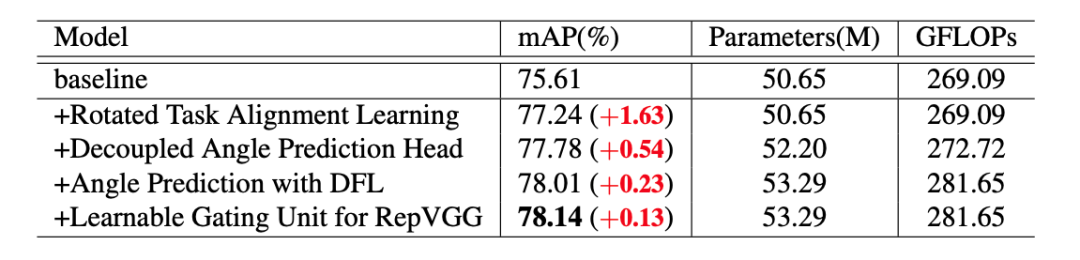
下表为PP-YOLOE-R-l在DOTA 1.0数据集上单尺度训练和测试的消融实验列表,其显示了每一个改进点的精度,参数量和计算量的变化。接下来我们将逐条详细讲解每一个改进点。
Baseline
借鉴了FCOSR[1]的做法,将Assigner和ProbIoU损失函数引入到了PP-YOLOE-l中作为baseline。backbone和neck均保持不变,回归分支被修改为直接预测(x, y, w, h,θ)。
Rotated Task Alignment Learning
TAL(Task Alignment Learning)是在PP-YOLOE中使用的动态匹配算法,为了将其应用到旋转框中,我们对TAL做出了两个简单的适配,得到了Rotated TAL。
首先,我们利用点与旋转矩形框的几何性质判断点是否在矩形框内部,来筛选Anchor Points。其次,我们计算了预测的旋转矩形框与GT框的旋转IoU,加入metric的计算中。
解耦的角度预测头
目前大多数的旋转框检测模型直接在一个回归分支中预测(x, y, w, h, θ)。然而,我们认为(x, y, w, h)和θ需要不同的特征,因此我们将其进行解耦,设计了一个独立的轻量级角度预测分支,仅包含一个ESE(Effective Squeeze and Extraction)注意力模块和一层卷积层。
使用DFL(Distribution Focal Loss)
进行角度预测
ProbIoU等损失函数将旋转矩形框建模成高斯矩形框,然后利用两个高斯矩形框之间的距离等度量作为回归损失。然而,对于接近方形的旋转框,将其转变成高斯矩形框后,角度信息将丢失,导致对于接近方形的旋转框的角度预测不准。
为了解决这一问题,我们使用了DFL的方式预测角度。不同于L1或者L2损失函数,DFL直接学习角度的通用分布。将 [0, π/2) 的角度区间分成90份,每一份的区间大小为 π/180。我们通过DFL学习角度落在每一个区间的概率,然后利用积分得到预测的角度值。
可学习的门控单元
RepVGG提出了一个多分支的卷积结构,包含一个3x3的卷积和1x1的卷积以及一个残差连接。
在推理阶段,RepVGG可以被重参数化为一个3x3卷积。虽然RepVGG等价于一个卷积,但是在训练时使用RepVGG模型收敛的更好。我们将这一结果归功于RepVGG引入了有用的先验知识。受此启发,我们设计了一个可学习的门控单元来控制来自不同层的信息。
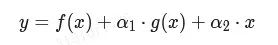
其中,α1和α2均为可学习的参数。由于我们提出的RepResBlock中不使用残差连接,因此我们只需为每一个RepResBlock引入一个可学习的参数。
在推理时,我们可以将其与卷积层一起重参数化,因此推理时的参数量和计算量都不变。
ProbIoU损失函数
将旋转矩形框建模成高斯框已经成为一个流行的做法。GWD、KLD和KFIoU等损失函数也相继被提出,并展现出不错的效果。为了验证ProbIoU损失函数的有效性,我们挑选了KLD进行了对比实验。这是因为KLD具有尺度不变性且适用于Anchor-free的方法。将ProbIoU损失函数替换成KLD损失函数,模型的精度明显降低,从78.14 mAP降至76.03 mAP。这表明ProbIoU更加适用于我们的设计。
部署
由于PP-YOLOE-R避免了特殊算子的使用,我们可以借助Paddle Inference将其轻易地部署在各种各样的硬件上。同时在支持TensorRT的设备上,我们可以借助Paddle-TRT进行部署。
部署代码
首先需要导出模型:
python tools/export_model.py -c configs/rotate/ppyoloe_r/ppyoloe_r_crn_l_3x_dota.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_r_crn_l_3x_dota.pdparams trt=True --output_dir inference使用`deploy/python/infer.py`的部署示例代码预测图像
Python deploy/python/infer.py --image_file demo/test.png --model_dir=inference/ppyoloe_r_crn_l_3x_dota --run_mode=trt_fp16 --device=gpu详细部署请参考
https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/rotate
推理结果

Part 2
PP-YOLOE-SOD:更高效更鲁棒的小目标检测方案
背景介绍
小目标检测在视频监控、自动驾驶、无人机航拍、遥感图像检测等方面有着广泛的应用价值和重要的研究意义。针对小目标的定义,目前主要有两种方式:
基于相对尺度的定义
目标边界框的宽高与图像的宽高比例小于一定值
目标边界框面积与图像面积的比值开方小于一定值
基于绝对尺度的定义
分辨率小于32*32像素的目标。如MS-COCO数据集
像素值范围在[10,50]之间的目标。如DOTA/WIDER FACE数据集
我们从数据集整体层面提出了如下定义:
目标边界框的宽高与图像的宽高比例的中位数小于0.04时,判定该数据集为小目标数据集。

目前,小目标检测主要有以下几个难点:
覆盖面积小,有效特征少
小目标下采样后丢失问题,边界框难以回归,模型难以收敛
同类小目标密集,NMS(非极大值抑制)操作将大量正确预测的边界框过滤
小目标检测的数据集少
针对上述问题,飞桨团队基于PP-YOLOE+通用检测模型,从流程和算法上进行了改进,提出了一套小目标专属检测器PP-YOLOE-SOD(Small Object Detection)。
方案解析
PP-YOLOE-SOD针对小目标检测提出了两种检测方案,分别是基于切图拼图流程优化的小目标检测方案以及基于原图模型算法优化的小目标检测方案。
同时提供了数据集自动分析脚本,只需输入数据集标注文件,便可得到数据集统计结果,辅助判断数据集是否是小目标数据集以及是否需要采用切图策略,同时给出网络超参数参考值。
PP-YOLOE-SOD
基于切图的小目标检测方案
在图像分辨率大,样本中小目标居多的情况下,如果reshape成小图再送进网络训练的话,目标会变得非常小,识别难度大。直接大图训练,GPU显存又顶不住,同时也会极度拖慢训练时间,而且推理速度会很慢。因此提出了切片的想法:
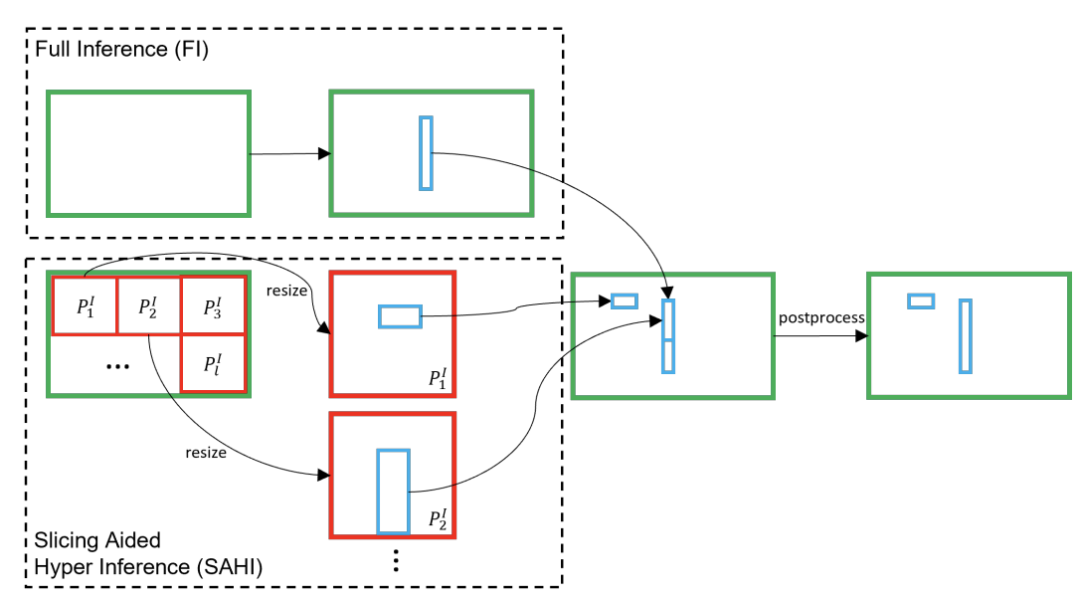
如上图所示,和滑动窗口的思想类似,先将图像分割成多个重叠的切片slices,这样就使得输入网络的图像的小目标占比较高。
在推理过程中,也使用切片的方法。首先将原始图 I 切片为
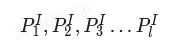
然后在保持横纵比的前提下进行resize,对每个patches进行单独的前向推理。原始图像的推理可以用来检测较大的目标。
最后使用NMS将两者(两个虚线框)的结果合并回原始的大小。

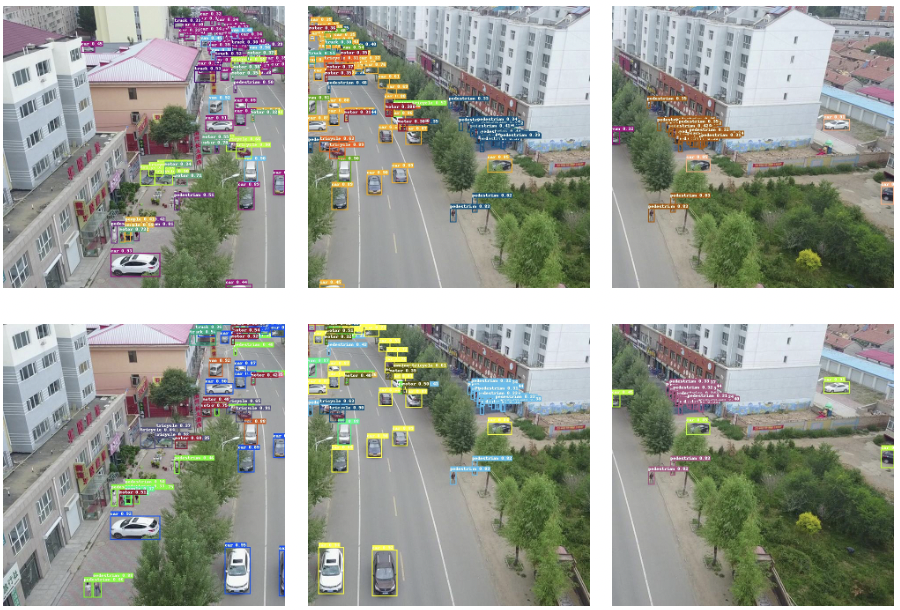
为此,我们集成SAHI(Slicing Aided Hyper Inference,切片辅助超推理)框架到PaddleDetection,并创新性地将它应用到训练推理全流程,只需要设置子图边长和子图重叠率,即可针对超大分辨率图片进行切图训练,并在预测部署阶段自动进行切图和拼图,将各个子图的结果全面融合,流程简单直接。如下图为切图检测方案结果展示。
原图预测漏检误检
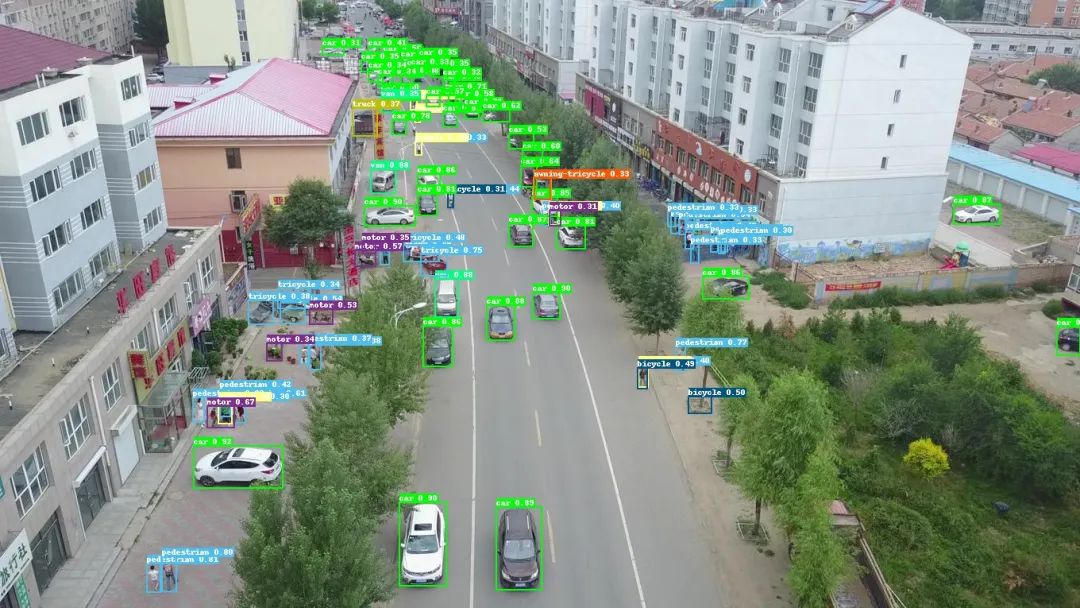
切图进行子图预测结果分散
将子图预测结果进行拼图之后存在冗余信息
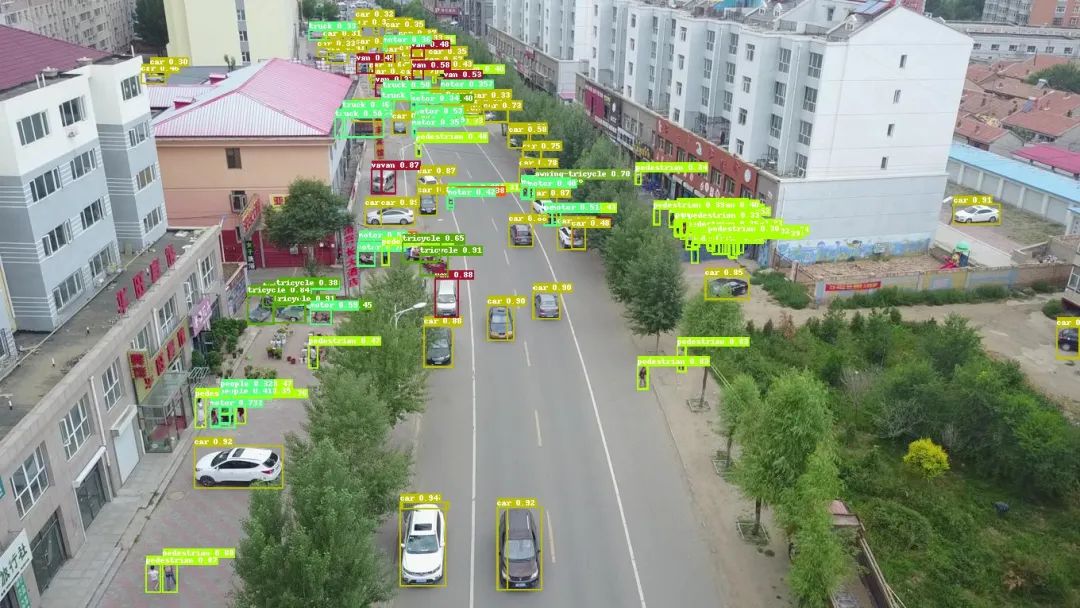
对拼接结果进行NMS之后,最终实现高精度小目标检测

【精度】
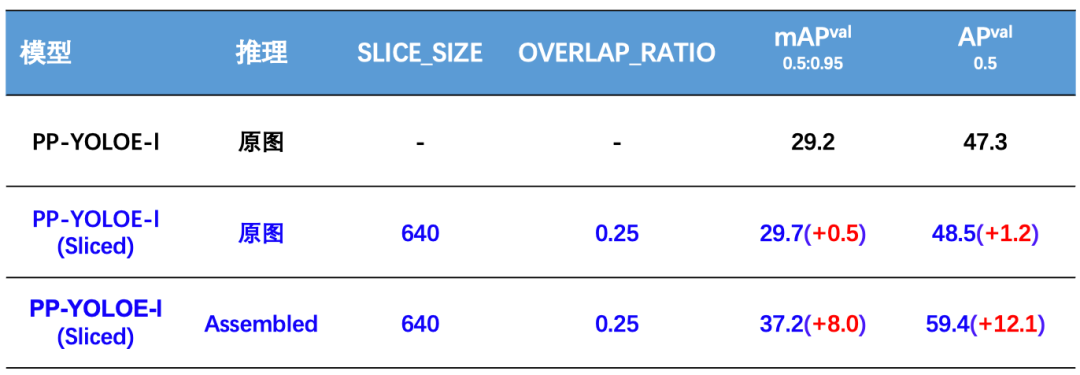
PP-YOLOE-SOD
基于原图的小目标检测方案
相比PP-YOLOE模型,PP-YOLOE-SOD改进点主要包括在neck中引入Transformer全局注意力机制以及在回归分支中使用基于向量的DFL。
引入Transformer全局注意力机制
Transformer在CV中的应用是目前研究较为火热的一个方向。最早的ViT直接将图像分为多个Patch并加入位置Embedding送入Transformer Encoder中,加上相应的分类或者检测头即可实现较好的效果。
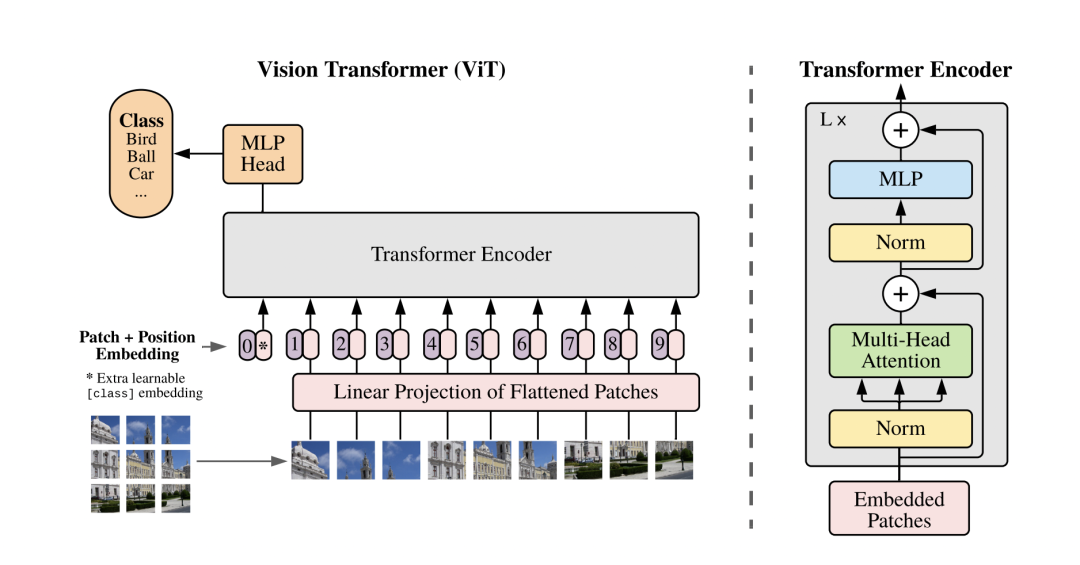
我们这里类似,主要加入了Position Embedding和Encoder两个模块,不同的是输入是最后一层特征图。
PP-YOLOE+结构图
PP-YOLOE-SOD结构图
基于向量的DFL回归算法
PP-YOLOE将回归看作是一个分布预测任务,并在回归分支中使用DFL。解决边界框不确定性问题,让网络快速地聚焦到目标位置的邻近区域的分布中去。
现有的DFL 把回归范围划分成n等份,预测结果落在每个小位置的概率,对结果求期望作为最终回归的box坐标。在回归距离时,用softmax将网络输出转换为概率,计算在[0, ... , reg_max]上的概率和,表示在当前特征图上中心点到目标框四边距离,其最大值应为reg_max,结果乘以步长就可以映射回输入图尺寸上。
但是该方法将reg_max视为标量,针对目标分布不同的数据集采用的回归范围是固定的,这就导致无法兼顾大目标和小目标的检测精度。由于小目标的box框相对较小,会出现小目标框内没有检测到相应目标但是附近点可能满足需求的情况。
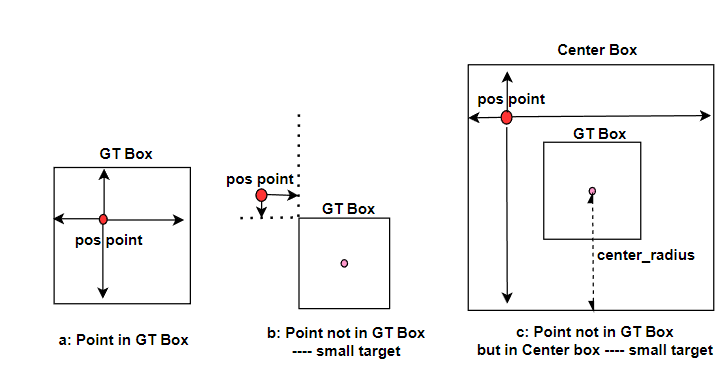
因此,如上图,我们将DFL回归范围向量化,引入回归负半轴,根据不同数据集调整回归上限,减少回归小目标时的噪声,同时用半径为center_radius,以gt框的中心点为中心的先验框来辅助回归小目标检测框,通过gt框与先验框的并集来匹配目标,当目标中心点在box框外部但在先验框内部时,则可以用先验框进行回归,提高了对小目标的预测效果。
【精度】
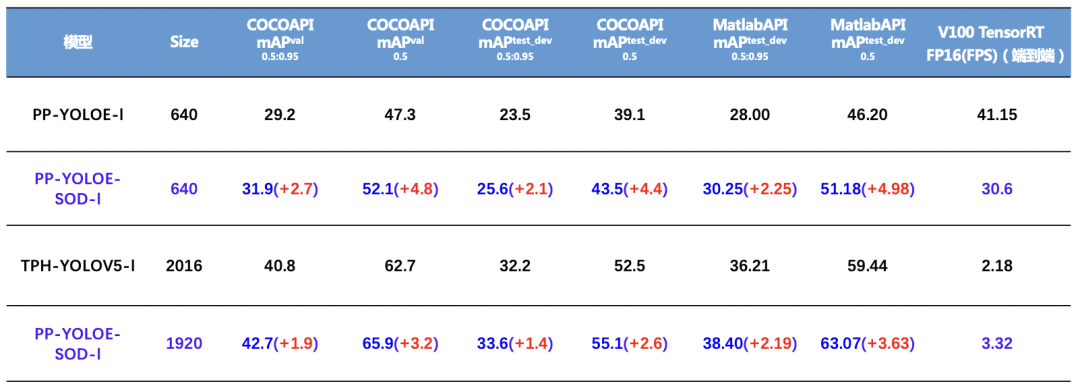
部署
部署代码
导出模型
python tools/export_model.py -c configs/smalldet/ppyoloe_crn_l_80e_sliced_visdrone_640_025.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_80e_sliced_visdrone_640_025.pdparams使用原图或子图直接推理
与评估流程基本相同,可以在提前切好并存下来的子图上预测,也可以对原图预测,如:
python deploy/python/infer.py --model_dir=output_inference/ppyoloe_crn_l_80e_sliced_visdrone_640_025 --image_file=demo.jpg --device=GPU --save_images --threshold=0.25使用原图自动切图并拼图重组结果来推理
python deploy/python/infer.py --model_dir=output_inference/ppyoloe_crn_l_80e_sliced_visdrone_640_025 --image_file=demo.jpg --device=GPU --save_images --threshold=0.25 --slice_infer --slice_size 640 640 --overlap_ratio 0.25 0.25 --combine_method=nms --match_threshold=0.6 --match_metric=ios详细部署请参考
https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/smalldet
结果

同时,我们提供了PP-YOLOE-SOD的实操教程,欢迎大家在线体验!
链接如下
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/330600
以上就是本次PP-YOLOE-R以及PP-YOLOE-SOD的内容。
【One More Thing】
想必大家对PP-YOLOE用于旋转框、小目标检测的方法有了一定的了解,此外我们还提供了将PP-YOLOE用于其他方向的榜单,发起了Call For Contributors活动,希望大家可以参与到PP-YOLOE的生态共建中,将PP-YOLOE用于其他任务方向,欢迎大家来揭榜!
链接如下
https://github.com/PaddlePaddle/PaddleDetection
参考文献
[1] Li Z , Hou B , Wu Z , et al. FCOSR: A Simple Anchor-free Rotated Detector for Aerial Object Detection[J]. arXiv e-prints, 2021.
[2] Xia G S, Bai X, Ding J, et al. DOTA: A large-scale dataset for object detection in aerial images[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 3974-3983.
[3] Xu S, Wang X, Lv W, et al. PP-YOLOE: An evolved version of YOLO[J]. arXiv preprint arXiv:2203.16250, 2022.
[4] Li Z, Hou B, Wu Z, et al. Fcosr: A simple anchor-free rotated detector for aerial object detection[J]. arXiv preprint arXiv:2111.10780, 2021.
[5] Llerena J M, Zeni L F, Kristen L N, et al. Gaussian Bounding Boxes and Probabilistic Intersection-over-Union for Object Detection[J]. arXiv preprint arXiv:2106.06072, 2021.
[6] Feng C, Zhong Y, Gao Y, et al. Tood: Task-aligned one-stage object detection[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE Computer Society, 2021: 3490-3499.
[7] Li X, Wang W, Wu L, et al. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection[J]. Advances in Neural Information Processing Systems, 2020, 33: 21002-21012.
[8] Ding X, Zhang X, Ma N, et al. Repvgg: Making vgg-style convnets great again[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 13733-13742.
[9] Yang X, Yan J, Ming Q, et al. Rethinking rotated object detection with gaussian wasserstein distance loss[C]//International Conference on Machine Learning. PMLR, 2021: 11830-11841.
[10] Yang X, Yang X, Yang J, et al. Learning high-precision bounding box for rotated object detection via kullback-leibler divergence[J]. Advances in Neural Information Processing Systems, 2021, 34: 18381-18394.
[11] Yang X, Yan J, Ming Q, et al. Rethinking rotated object detection with gaussian wasserstein distance loss[C]//International Conference on Machine Learning. PMLR, 2021: 11830-11841.
WAVE SUMMIT+2022
WAVE SUMMIT+2022将于11月30日在深圳举办,欢迎大家扫码报名!关注飞桨公众号,后台回复关键词「WAVE」进入官网社群了解更多峰会详情!

【WAVE SUMMIT+2022报名入口】

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~