
- 1android——jetpack Compose布局居中,margin,padding,文字居中_android compose margin
- 2PHP原生对接QQ互联/实现QQ登录,SDK2.1版本/超级详细!
- 3数学建模之灰色关联分析(GRA)_灰色关联分析法
- 4android自定义控件Group之上下滑动回弹及快速滑动手势viewgroup_android 自定义viewgroup 左右上下滑动
- 5RabbitMQ 面试八股题整理
- 6【以太网通信】RGMII 接口及其时序规范
- 7Open3D(C++) 点云滤波——均值滤波_点云均值滤波csdn
- 8Linux系统进程输出与统计模块_统计进程数量
- 9【2019.07.29 Python每日一题】—— 水仙花数【菜鸟100例-13】_python中形参为单字符,实参传递一个字符进行统计水仙花数
- 10java shutdown_java.lang.Shutdown | 学步园
Unity性能优化与分析--GPU
赞
踩
每一帧,Unity 都需要确定必须渲染哪些对象,然后创建绘制调用。绘制调用是调用图形 API 来绘制对象(如三角形),而批处理是要一起执行的一组绘制调用。
随着项目变得更加复杂,您需要用管线来优化 GPU 的工作负载。通用渲染管线 (URP) 目前使用单通道前向渲染器将高质量图形传输给移动平台(未来版本中将提供延迟渲染功能)。来自游戏主机和 PC 的、基于物理的光照和材质也可以缩放为适合手机或平板电脑。
1 带宽
1.1 GPU压力与发热/耗能
虽然UWA内部做过一些带宽与发热/耗能关系的定量实现,但芯片底层的情况远比我们想象的复杂。我们从经验和跟芯片厂家的专业硬件工程师沟通后得出的结论是:移动设备上GPU带宽的压力还是比较影响能耗的,特别是在发热这一方面也有不小的影响。但这是定性的说法,目前我们和芯片厂商都没有特别定量的公式来具体说明其影响大小。因此,当一个项目的发热或者能耗较大,带宽是开发者特别需要关注的地方。
UWA工具能够监控游戏测试过程中硬件温度的变化,一般而言长时间维持在55℃以上就是需要警惕的温度了。在UWA进一步的GPU专项服务中,还会更详细的采集和展示GPU和CPU分别的温度。
1.2 GPU压力与帧率
上文中已提到过,GPU压力大会使得CPU等待GPU完成工作的耗时增加,与此同时,也会使得渲染模块CPU端的主要函数耗时上升,从而影响帧率、造成卡顿。
除此之外,由于移动端硬件客观上存在体积较小、散热难的问题,使得GPU发热会物理上显著影响到CPU芯片温度同时上升,严重的即产生降频现象。
除了通过UWA工具监控Gfx.WaitForPresent和渲染模块主函数的耗时数据外,GOT Online Overview模式下还反映了测试中GPU耗时数据,从而直观地监控GPU性能瓶颈;而目前GOT Online还集成了Mali GPU统计带宽的API,使用Mali芯片的测试机提交Overview报告,就可以获得GPU着色和带宽数据。后续也将逐步添加对于高通等硬件的相关功能支持。

在UWA进一步的GPU专项服务中,还会结合带宽数据和Clocks数据,针对高压场景逐DrawCall地分析其占用带宽和GPU耗时过高的原因,4.3开始的部分会讨论一些常见的原因。
1.3 优化带宽
带宽数据是衡量GPU压力的重要参考。以相对高端的小米10机型而言,全分辨率情况下,如果需要跑满30帧并发热情况稳定,则需要将总带宽控制到3000MB/s以下。为此,常见的优化手段有:
(1)压缩格式 在内存的章节中已经或多或少地讨论过,使用合理的压缩格式,能够有效降低纹理带宽。
(2)纹理Mipmap 对于3D场景而言,对其中的物体所用到的纹理开启Mipmap设置,能够用一小部分内存上升作为代价有效降低带宽。当物体离相机越远,引擎就会使用更低层级的Mipmap进行纹理采样。但Mipmap设置也与合理的纹理分辨率挂钩,一个常见的现象是在实际渲染过程中只用到或者绝大部分用了Mipmap的第0层进行采样,从而浪费了内存,所以要考虑降低这类纹理的分辨率。
UWA工具使用不同颜色来表示使用不同Mipmap层级采样的像素以便定位问题;在进一步的服务中,还会根据Mipmap各层级使用率罗列出每个场景中存在上述浪费现象的纹理。

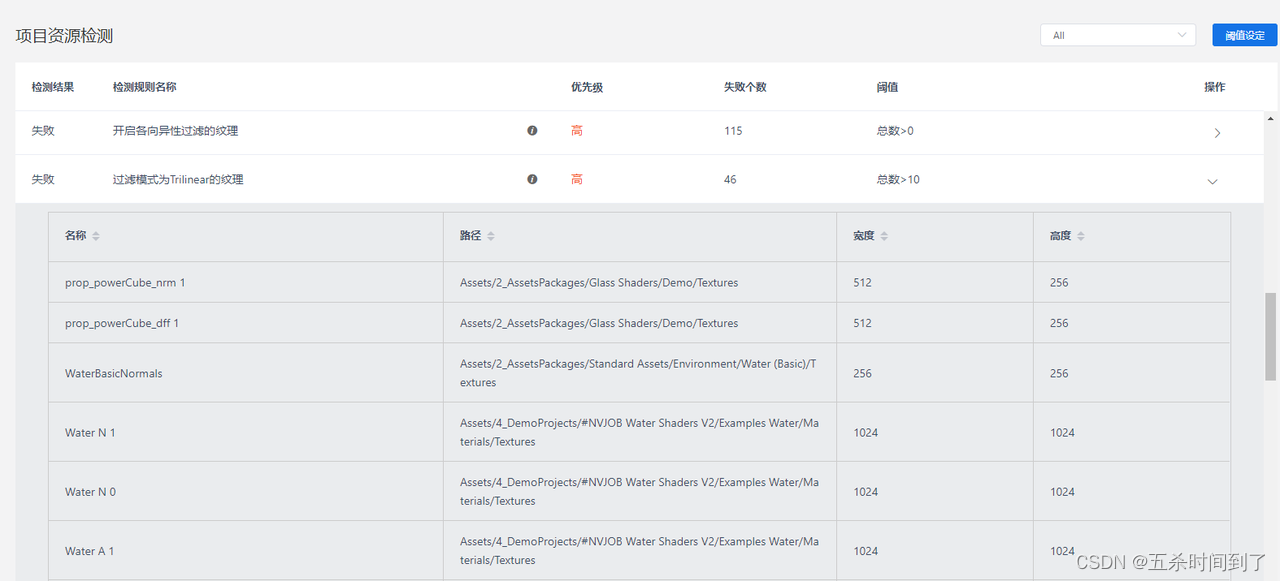
(3)合理的纹理采样方式 除了合理使用Mipmap非0层采样外,还应关注项目中各向异性采样和三线性插值采样。概括来说,纹理压缩采样时会去读缓存里面的东西,如果没读到就会往离GPU更远的地方去读System Memory,因此所花的周期越多。采样点增多的时候,cache miss的概率就会变大,造成带宽上升。各向异性采样次数在Unity中设置有1-16,应尽量设置为1;三线性采样采8个顶点,相对于双线性采样是翻倍的。
UWA的本地资源检测服务能够统计并列出开启各向异性或三线性采样的纹理资源。
(4)修改渲染分辨率 直接修改渲染分辨率为0.9倍乃至更低,减少参与纹理采样的像素,更加有效地降低带宽。
此外,还应注意读顶点的带宽。相比纹理,它的占比一般会比较小。但不同于纹理的是,修改渲染分辨率可以有效降低读纹理的带宽,但读顶点的带宽不会受到影响。所以在上文中针对网格资源和同屏渲染面片数的控制卓有成效后,读顶点的带宽值应该占总带宽的10%-20%较为合理。
2. Overdraw
Overdraw,即多次绘制同一像素造成的GPU开销。在场景中渲染顺序控制合理的理想状况下,不透明物体的Overdraw应控制在1层。所以,造成Overdraw的主要元凶就是半透明物体,也即粒子系统和UI。
2.1 粒子系统
灵活使用UWA的性能分析工具,可以有效定位对GPU压力贡献大的粒子系统。
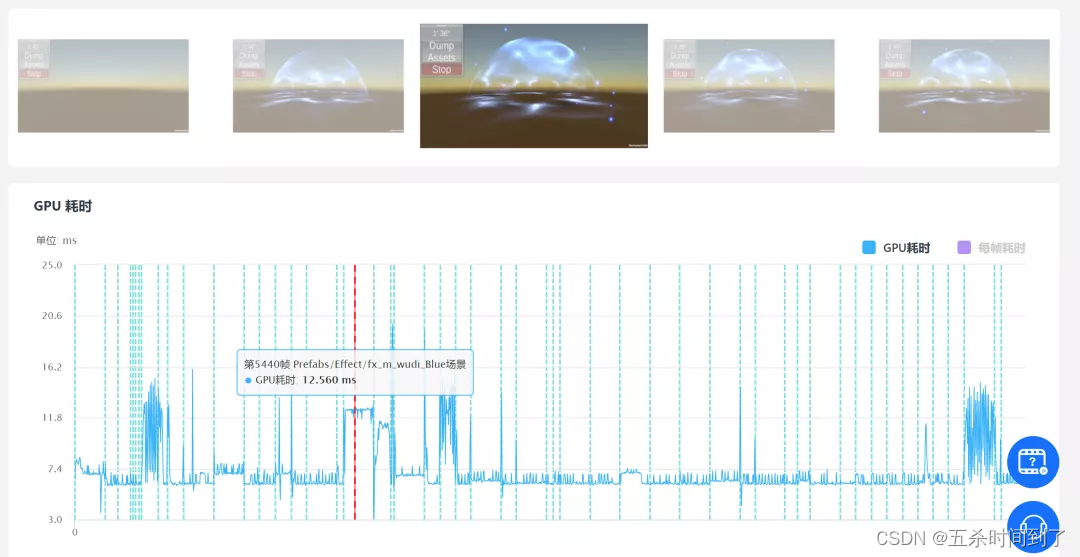
一种做法是,建立一个专门的空的测试场景,在其中顺次播放我们项目中要用到的粒子系统,然后使用UWA SDK进行打包测试提交GOT Online Overview报告,就可以在GPU耗时曲线处,结合测试截图找到播放时GPU耗时较高的粒子系统了。
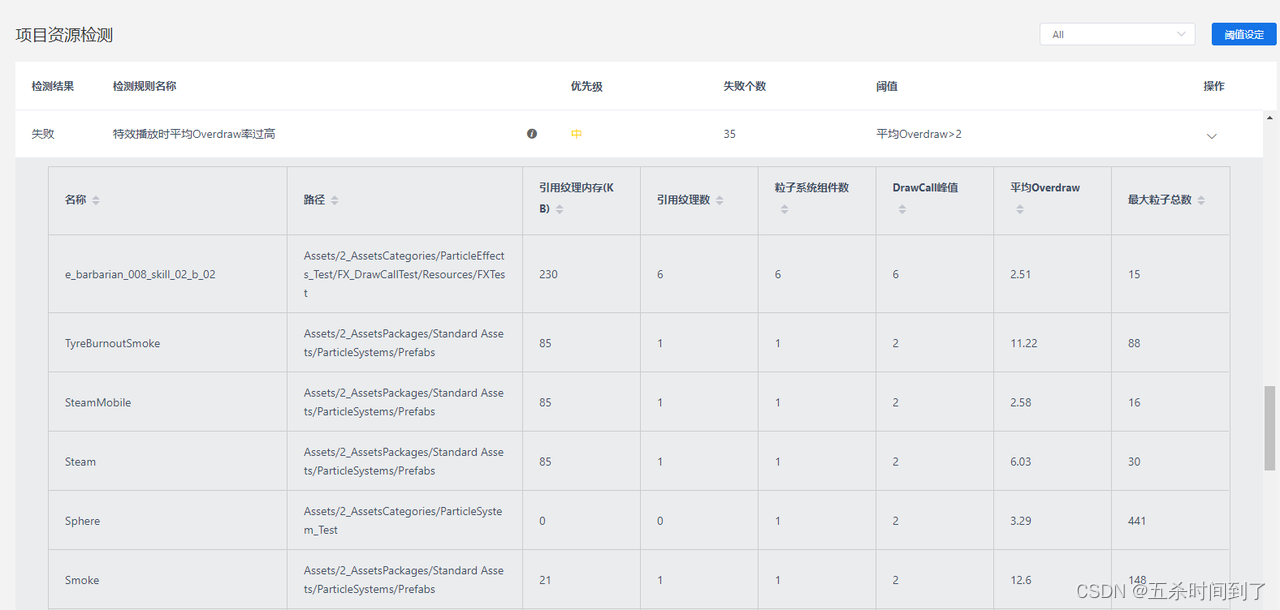
还有一种做法是直接使用UWA本地资源检测报告,可以直接看到造成Overdraw较高的粒子列表作为参考。
在筛选出需要优化的粒子系统后,对于低端设备尽可能降低它们的复杂程度和屏幕覆盖面积,从而降低其渲染方面的开销,提升低端设备的运行流畅性。具体做法如下:
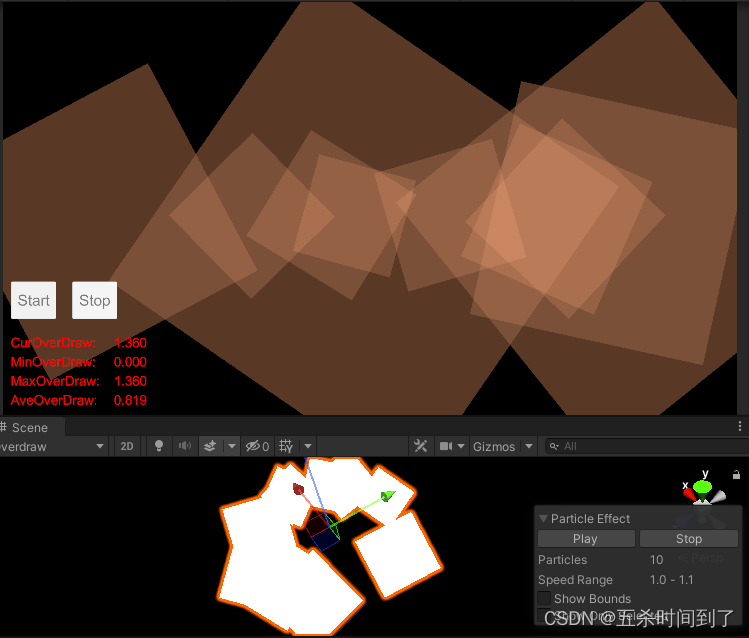
(1)在中低端机型上对粒子系统的Max Particles最大粒子数量进行限制;
修改前:

限制Max Particles为10后:
(2)在中低端机型上只保留“重要的”的粒子系统,比如对于一个火焰燃烧的特效,只保留火焰本身,而关闭掉周边的烟尘效果;
(3)尽可能降低粒子特效在屏幕中的覆盖面积,覆盖面积越大,越容易产生重叠遮盖,从而造成更高的Overdraw。
关于粒子系统的优化,我们曾在UWA DAY 2018中对移动游戏的GPU性能优化中做了些剖析,通过从Fillrate和Shader等几方面出发,结合大量优化过程中的实际案例分析游戏在GPU端的性能瓶颈:《移动游戏的GPU性能优化》。
2.2 UI
(1)当某个全屏UI打开时,可以将被背景遮挡住的其他UI进行关闭。 (2)对于Alpha为0的UI,可以将其Canvas Renderer组件上的CullTransparent Mesh进行勾选,这样既能保证UI事件的响应,又不需要对其进行渲染。 (3)尽可能减少Mask组件的使用,不仅提高绘制的开销,同时会造成DrawCall上升。在Overdraw较高的情况下,可以考虑使用RectMask2D代替。 (4)在URP下需要额外关心是否有没必要的Copy Color或者Copy Depth存在。尤其是在UI和战斗场景中的相机使用同一个RendererPipelineAsset的情况下,容易出现不必要的渲染耗时和带宽浪费,这样会对GPU造成不必要的开销。通常建议UI相机和场景相机使用不同的RendererData。
3. 渲染效果
除了粒子特效外,我们往往还喜欢用一些炫酷的渲染效果来丰富游戏的表现,比如体积雾、体积光、水体、次表面反射等等,然而场景中用到的此类效果越多,Shader越复杂,给GPU带来的压力越是大到远远超出接受范围的程度。
优化和权衡是决定最后留下哪些渲染效果的主要手段。
一方面,从多个方案中对比选取效果和性能较优的,对开源方案根据自身项目需要进行精简优化;另一方面,根据机型分档和当前GPU压力,取重点而舍次要。可以在UWA社区的博客、学堂和开源库中发现一些优化良好、通过实践检验的优秀方案。
4. 后处理
Bloom几乎是最受开发者喜爱、最为常见的后处理效果了。常见的一个问题是,Bloom默认是从1/2渲染分辨率开始进行下采样的。对此,可以考虑在中低端机型上从1/4分辨率开始进行下采样,或减少下采样次数。
各种后处理效果的性能开销和实际使用场景并不相同,在实际项目中遇到的问题也往往各不相同。UWA社区中也有大量后处理相关的文章和资源,比如《屏幕后处理效果系列之常见后处理效果篇》。
5. 渲染策略
5.1 绘制顺序
当场景中存在先画离相机较远的不透明物体,再画离相机较近的物体,而且两者有所重合时,较远物体被较近物体所遮挡部分的像素就有可能被绘制两次,从而造成Overdraw。
这种情况常发生在地形上。本来当不透明物体的Render Queue一致时,引擎会自动判断并优先绘制离相机更近的物体。但对于地形而言往往有的部分比其他物体离相机更近,有的却更远,从而被优先绘制。
所以,需要通过对Render Queue等设置,使得离相机越近的物体(如任务、物体等)越先绘制,而较远的如地形等最后绘制。则在移动平台上,通过Early-Z机制,硬件会在片段着色器之前就进行深度测试,离得较远的物体被遮挡的像素深度检测不通过,从而节省不必要的片元计算。
5.2 无效绘制
存在一些视觉效果不明显可以关闭,或者可以用消耗更低的绘制方案的情况。
比如一种较为常见的情况是,某些绘制背景的DrawCall,本身屏占比较大,开销不小,但在引擎中开关这个DrawCall没有明显的视觉变化,可能是在制作过程中被弃用或者被其他DrawCall完全掩盖了的效果,则可以考虑予以关闭。
还有一种情况是,一些背景是用模型绘制的并带有模糊、雾效等额外的渲染效果。但场景中视角固定、这些背景也几乎不发生变化,则可以考虑用静态图替代这些复杂的绘制作为背景,在低端机上把更多性能留给主要的游戏逻辑和表现效果。
5.3 渲染面积
渲染面积过大造成的性能问题已经在粒子特效中有所反映和讨论了。但事实上对于不透明物体也适用。对于一个DrawCall而言,当它的渲染面积较大、且渲染资源多而复杂时,两者遍呈现出一种乘积的作用,它意味着有更多的像素参与纹理采样,参与Shader计算,给GPU带来更高的压力。
6. Shader复杂度
除了纹理、网格、Render Texture,还有一种对GPU压力贡献极大的渲染资源,也就是Shader。UWA尤其关注Fragment Shader的屏占比、指令数和时钟周期数,渲染的像素越多、复杂度越高,说明该Shader资源越需要予以优化。
其中,使用Mali Offline Compiler工具可以获得Shader的指令数和时钟周期数。UWA的进一步服务中会详细测试项目中所有使用率较高的Shader在不同关键字组合下变体的复杂度,从而定位需要着重优化的Shader资源及其变体。
7 避免使用过多动态光线
与旧版前向渲染器相比,URP 可以减少绘制调用的数量。避免向移动端应用程序添加过多动态光线。考虑采用其他方式,如对动态网格使用自定义着色器效果和光照探针,以及对静态网格使用烘焙光照。
对于 URP 的特定限制以及内置渲染管线实时光照,请参阅此功能对比表。
8 禁用阴影
阴影投射可按 MeshRenderer 和光线禁用。尽可能禁用阴影可以减少绘制调用。
您也可以通过向简单网格应用模糊纹理或在角色下面应用四边形来创建伪阴影。另外,可以使用自定义着色器创建模糊阴影。
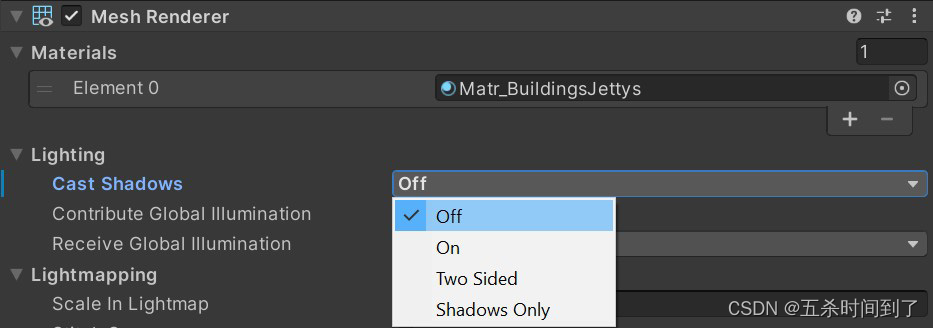
禁用阴影投射可以减少绘制调用。
9 将光照烘焙到光照贴图中
使用全局光照 (GI) 向静态几何体添加动态光照。使用 Contribute GI 标记对象,以便您可以将高质量的光照存储为光照贴图的形式。
这样,烘焙阴影和光照的渲染不会影响运行时性能。渐进式 CPU 和 GPU 光照贴图可以加快全局光照的烘焙。
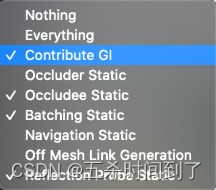
启用 Contribute GI。
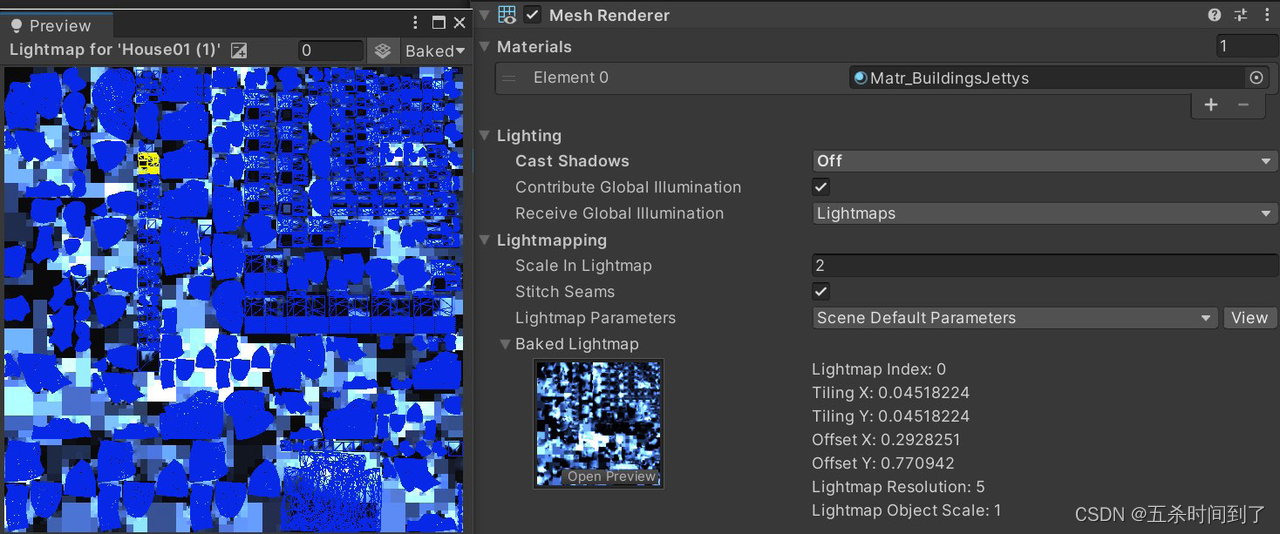
调整 Lightmapping Settings (Windows > Rendering > Lighting Settings) 和 Lightmap 大小,从而限制内存使用量。
请参阅手册指南和有关光照优化的文章了解如何开始在 Unity 中使用光照贴图。
10 使用光源层
对于多光源的复杂场景,将对象分层,然后限定每个光源对特定剔除遮罩 (culling mask) 的影响。
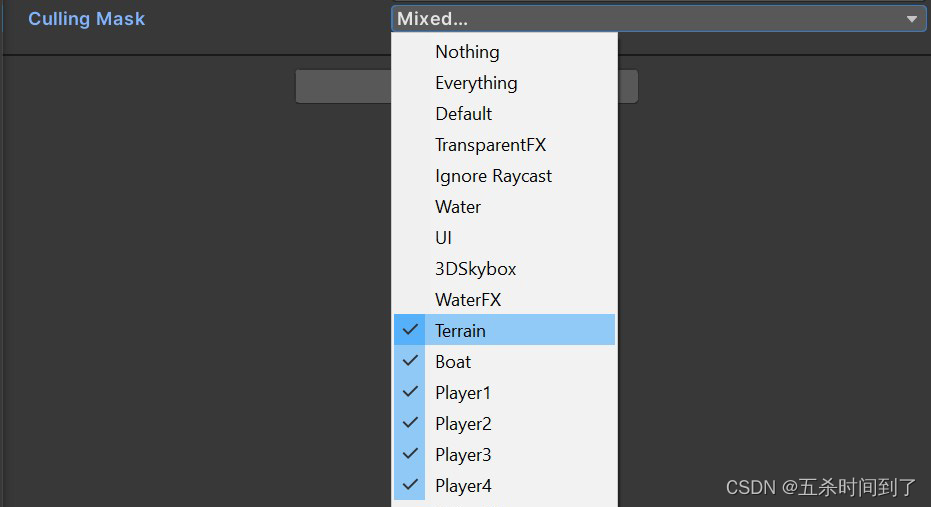
层可以限制光源对特定剔除遮罩的影响。
11 对移动对象使用光照探针
光照探针存储场景中的空白空间的烘焙光照信息并且提供高质量的光照(直接和间接)。它们使用球谐函数,这种函数的计算速度比动态光照快很多。

光照探针照亮背景中的动态对象。
12 使用细节级别 (LOD)
随着对象移向远处,细节级别可以将它们切换为使用更简单的网格,以及更简单的材质和着色器,从而帮助提高 GPU 性能。
请参阅 Unity Learn 上的使用 LOD 级别课程了解更多详细信息。
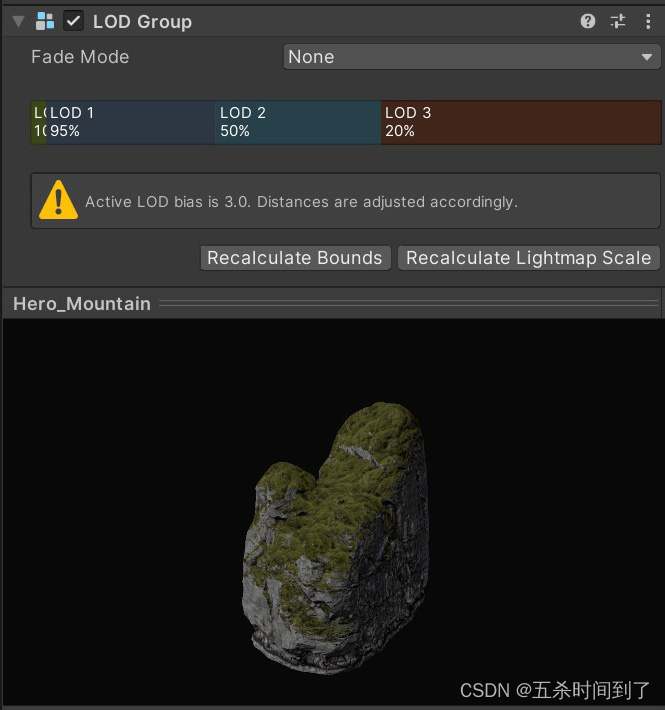
使用 LOD Group 的网格示例。

源网格,以不同分辨率建模。
13 使用遮挡剔除来移除隐藏的对象
隐藏在其他对象之后的对象仍然可能渲染和使用资源。使用遮挡剔除可以将它们丢弃。摄像机之外的视锥体剔除 (frustum culling) 是自动执行的,遮挡剔除 (occlusion culling) 是则要经过烘焙过程。只需将对象标记为静态遮挡物或被遮挡物,然后通过 Window > Rendering > Occlusion Culling 对话框进行烘焙。尽管不是所有场景都适合,剔除在很多情况下都能改善性能。
请参阅使用遮挡剔除教程了解更多信息。
14 避免使用移动端原生分辨率
手机和平板电脑越来越高级,新生代设备往往采用极高的分辨率。
使用 Screen.SetResolution(width, height, false) 可降低输出分辨率,提升一定的性能。配置多个分辨率,在质量和速度之间找到最佳平衡。
15 限制摄像机的使用
每个摄像机都会产生开销,无论它是否在做有意义的工作。只在有必要渲染时才使用摄像机组件。在低端移动平台,每个摄像机最多可以使用 1 ms CPU 时间。
16 保持着色器简单
通用渲染管线包含几个轻量级光照和无光照着色器,它们已针对移动平台进行了优化。让着色器变体的数量尽可能保持较少的状态,这样可以大幅减少运行时内存使用量。如果默认 URP 着色器不满足需要,可以使用 Shader Graph 自定义材质的外观。请参阅此处了解如何使用 Shader Graph 以可视化的方式构建着色器。
使用 Shader Graph 创建自定义着色器。
17 尽可能减少过度绘制和Alpha 混合
避免绘制不必要的透明或半透明图像。这种方式导致的过度绘制和 Alpha 混合会极大影响移动平台。不要重叠几乎看不到的图像或效果。可以使用 RenderDoc 图形调试器检查过度绘制。
18 限制后期处理效果
全屏幕后期处理效果(如发光)会极大降低性能。请在游戏的美术设计中谨慎使用这些效果。
在移动应用程序中使用简单后期处理。
19 小心使用 Renderer.material
在脚本中访问 Renderer.material 会复制材质并返回对新副本的引用。这会破坏任何已包含该材质的现有批次。如果要访问批次中对象的材质,请改用 Renderer.sharedMaterial。
20 优化 SkinnedMeshRenderer
蒙皮网格的渲染开销很大。确保每一个使用 SkinnedMeshRenderer 的对象都是需要它的。如果游戏对象只在某些时候需要动画,请使用 BakeMesh 函数将蒙皮网格冻结在静态姿势中,并在运行时切换为简单的 MeshRenderer。
21 尽可能减少反射探针
反射探针可以创建逼真的反射,但在批处理中,它的开销巨大。使用低分辨率立方体贴图、剔除遮罩和纹理压缩可以改善运行时性能。
参考文献:


