
- 1深度学习故障诊断实战 | 数据预处理之创建Dataloader数据集
- 2白话强化学习(理论+代码)_强化学习代码
- 3LaMDA: Language Models for Dialog Applications
- 4【蓝桥杯】DP和枚举(持续更新~~~)_dp算法和枚举法对比
- 5flutter 用CustomPainter绘制一个三角矩形加圆角_flutter custompainter 画圆角三角形
- 6Flutter ListView保留滚动位置之优化之路_flutter列表更改某一条后页面刷新但保持滚动条位置
- 7计算机网络数据链路层知识总结
- 8Linux 中搭建 主从dns域名解析服务器
- 9python拼写_用 Python 27 行实现拼写纠正
- 10理解Java虚拟机——JVM_java jvm
【数据分析案列】--- 北京某平台二手房可视化数据分析
赞
踩
一、引言
本案列基于北京某平台的二手房数据,通过数据可视化的方式对二手房市场进行分析。通过对获取的数据进行清冼(至关重要),对房屋价格、面积、有无电梯等因素的可视化展示,我们可以深入了解北京二手房市场的特点和趋势,为购房者和投资者提供有价值的信息和参考。
为了实现这个目标,我们将使用Python编程语言及其相关的数据分析库,包括pandas、matplotlib、seaborn和pyecharts。这些库提供了丰富的功能和工具,使我们能够对数据进行处理、分析和可视化。
二、数据探索和清冼
进行数据探索和清冼的目的主要是因为数据来源并不是官方的,数据中往往存在一些异常情况,这些异常的情况会导致我们分析的结果出现大量的偏差,所以我们需要对爬取的北京二手房数据进行探索的清冼,数据集下载地址:https://download.csdn.net/download/qq_38614074/89017277
废话不多说直接上代码:
- 1、导入数据探索清冼需要的库
import pandas as pd
- 1
- 2、导入数据进行数据整体的探索
data = pd.read_csv("二手房数据.csv",encoding = 'gb18030')
#查看数据的维度
data.shape
#打印数据的前5行
data.head()
- 1
- 2
- 3
- 4
- 5
- 6

data.info()
- 1

对数据进行整体的探索,我们发现数据集中"11 Unnamed"列好像都是空值,Id列在后续的分析中也使用不到,故后续需要将这两列进行删除; 并且电梯列中有比较多的缺失值,数据中可以看到电梯有8255条数据缺失记录,后续需要进行清冼;
-
3、数据中字段级别的数据探索
后续的分析主要是对数据中的一些字段进行可视化分析,所以需要查看不同维度的数据中是否存在一些异常情况(不应该出现出现的情况) -
3.1 市区字段分析
data['市区'].value_counts()
- 1
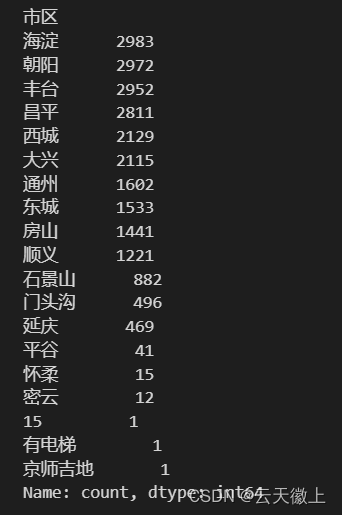
分析: 在市区列中,存在异常值[‘15’, ‘有电梯’, ‘京师吉地’],且量非常少,不影响这个数据分析,后续需要将这些数据所在的行数据进行删除;
- 3.2 户型字段分析
data['户型'].unique()
- 1

分析:通过unique()我们发现,后续的处理中我们需要房间替换成室,保证数据的一致性,并需要将一些非户型类型的描述给删除,这里主要包括[‘叠拼别墅’,‘有电梯’, ‘京师吉地’]等户型列中的异常值;
- 3.3 其它字段的分析
# 小区
len(data['小区'].unique())
#电梯
data['电梯'].value_counts()
#朝向
data['朝向'].unique()
#楼层
data['楼层'].unique()
#装修情况
data['装修情况'].value_counts()
#面积
data['面积(㎡)'].unique()
#年份
data['年份'].unique()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
分析:
1、小区列中的字段数据过多,此次不在处理,此份数据对分析结果无影响;
2、电梯列中缺失值比较多,后续将列中的数据不是’有电梯’ or’无电梯’的情况全部替换成’未知‘;
3、朝向列中将[‘97’,‘有电梯’,‘京师吉地’]异常值所在的行进行删除;
4、楼层列中将[‘490’, ‘房山’, ‘精装’, ‘朝阳’, ‘有电梯’, ‘京师吉地’]异常值所在的行进行删除;
5、装修情况列中将[‘无电梯’,‘2013’,‘丽水嘉园’,‘长阳国际城三区’,‘有电梯’,‘京师吉地’]异常数据所在的行进行删除;
6、年份列中将[‘1.01E+11’,‘其他’,‘精装’, ‘西南’,‘22’,‘有电梯’, ‘京师吉地’]异常数据所在的行进行删除;
7、面积(㎡)列中将包含中文的行进行删除;
8、价格(万元)列中将[‘光明西里’]异常数据所在的行进行删除;
- 4、编写最终的清冼代码
根据上面的分析,编写对应的代码如下
# clean步骤 # 删除指定的列 ['Unnamed: 11', 'Id'] data = data.drop(['Unnamed: 11', 'Id'], axis=1) def remove_outlies(data,col_name='楼层',to_remove = ['490', '房山']): mask = data[col_name].isin(to_remove) data = data[~mask] return data # 市区列中异常值清冼 data = remove_outlies(data,'市区',['15', '有电梯', '京师吉地']) # 电梯列中的数据清冼 data['电梯'] = data['电梯'].apply(lambda x:x if (x=='有电梯' or x=='无电梯') else '未知') # 户型列中的数据清冼 data['户型'] = data['户型'].apply(lambda x:x.replace("房间",'室')) data = remove_outlies(data,'户型',['叠拼别墅','有电梯', '京师吉地']) # 朝向列中的数据清冼 data = remove_outlies(data,'朝向',['97','有电梯','京师吉地']) # 楼层列中的数据清冼 data = remove_outlies(data,'楼层',['490', '房山', '精装', '朝阳', '有电梯', '京师吉地'] ) # 装修情况列中的数据清冼 data = remove_outlies(data,'装修情况',['无电梯','2013','丽水嘉园','长阳国际城三区','有电梯','京师吉地']) # 年份列中的数据清冼 data = remove_outlies(data,'年份',['1.01E+11','其他','精装', '西南','22','有电梯', '京师吉地']) # 面积(㎡)列中的数据清冼 def contains_chinese(s): if isinstance(s, str): return any('\u4e00' <= c <= '\u9fff' for c in s) return False mask = data['面积(㎡)'].apply(contains_chinese) data = data[~mask] data = remove_outlies(data,'价格(万元)',['光明西里'])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 5 将清洗后的数据保存
将清冼后的数据进行保存,方便后续的分析,不用再重新进行数据的清冼;清冼后的数据下载地址:https://download.csdn.net/download/qq_38614074/89017277
data.to_csv(‘clean_data.csv’,index=False,encoding=‘utf-8-sig’)
三、数据分析和可视化
在这一部分,你可以逐步介绍你对数据进行的分析和可视化的过程。你可以展示一些关键的图表和图形,并解释它们背后的含义和发现。
加载绘图需要的库:
import pandas as pd from pyecharts.charts import Map from pyecharts.charts import Bar from pyecharts.charts import Line from pyecharts.charts import Grid from pyecharts.charts import Pie from pyecharts.charts import Scatter from pyecharts import options as opts from pyecharts.globals import ThemeType from pyecharts.charts import Geo import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline from pylab import mpl mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 指定默认字体:解决plot不能显示中文问题 mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
导入清冼后的数据:
data = pd.read_csv(‘clean_data.csv’)
data.describe()
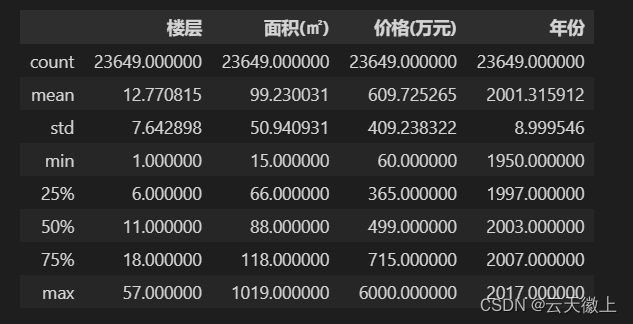
图中显示北京二手房平均平均总价 609万,平均年份2001年,平均楼层 12-13 层,平均房屋面积 99 m²。另还有标准差、最小值、四分之一分位数、二分之一分位数、四分之三分位数、最大值等信息。
下面从几个点上进行数据可视化:
- 1)各区二手房数量条形图 ,获取数据中各区信息和对应区的房屋数量,绘制条形图
region_list = data['市区'].value_counts().index.tolist()
house_count_list = data['市区'].value_counts().values.tolist()
c = Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
c.add_xaxis(region_list)
c.add_yaxis("北京市", house_count_list)
c.set_global_opts(title_opts=opts.TitleOpts(title="北京各区二手房数量柱状图", subtitle=""),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(interval=0)))
# c.render("武汉各区二手房数量柱状图.html")
c.render_notebook()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
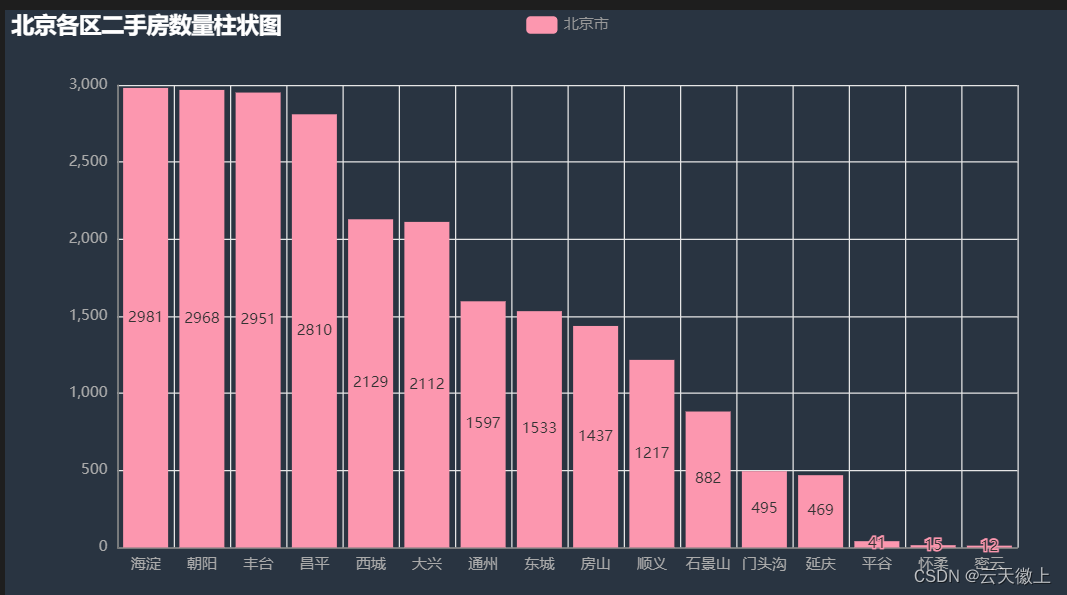
-
- 北京各个城区二手房价格地图分布
zone_median = data.groupby(['市区'])['价格(万元)'].median() c = ( Geo() .add_schema(maptype='北京',itemstyle_opts=opts.ItemStyleOpts(color='#A60B63',border_color='#FFFF22')) .add( "", [list(z) for z in zip(zone_median.keys().tolist(),zone_median.tolist())] ) .set_series_opts( label_opts=opts.LabelOpts(is_show=False)) .set_global_opts( visualmap_opts=opts.VisualMapOpts(min_=280,max_=720), title_opts=opts.TitleOpts(title="北京各个城区二手房平均价格(万元)", subtitle=""), ) ) c.render_notebook()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
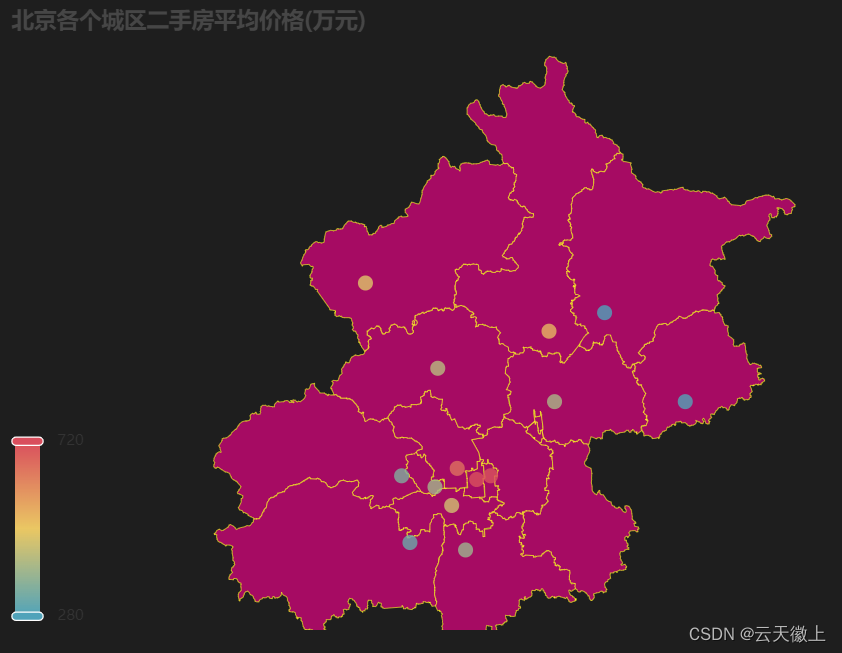
-
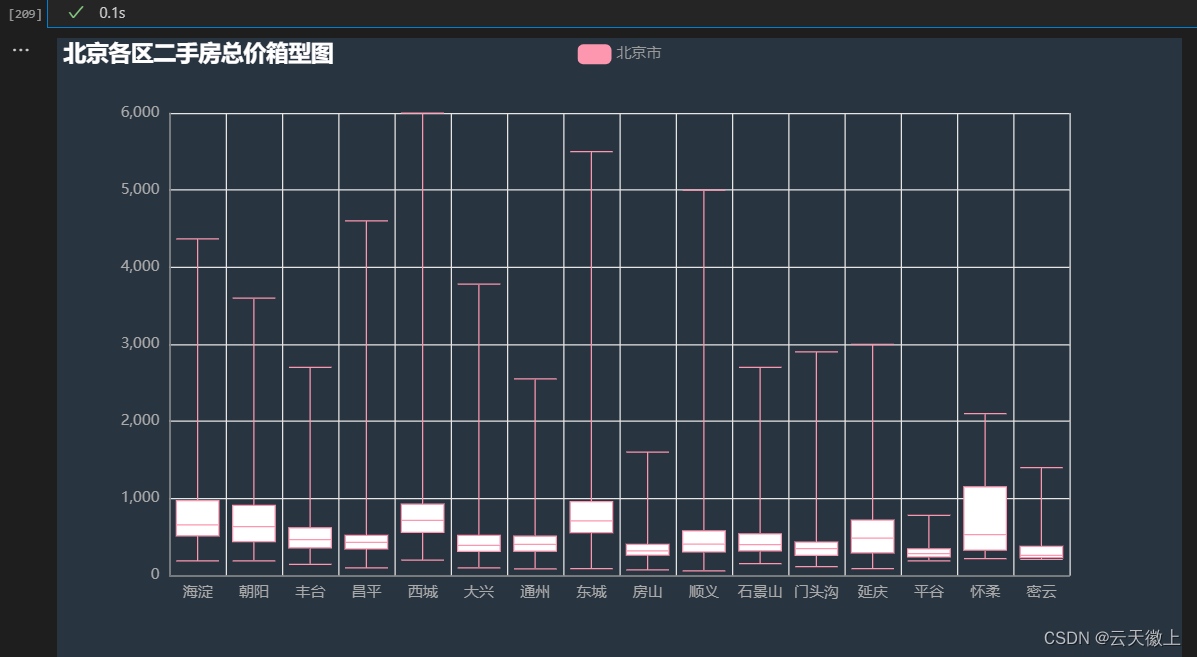
- 各区二手房单价箱型图
统计各区名称信息及对应单价信息,并绘制箱型图。
- 各区二手房单价箱型图
统计各个区二手房单价信息
unit_price_list = []
for region in region_list:
unit_price_list.append(data.loc[data['市区'] == region, '价格(万元)'].values.tolist())
# 绘制箱型图
from pyecharts.charts import Boxplot
c = Boxplot(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
c.add_xaxis(region_list)
c.add_yaxis("北京市", c.prepare_data(unit_price_list))
c.set_global_opts(title_opts=opts.TitleOpts(title="北京各区二手房总价箱型图"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(interval=0)))
# c.render("boxplot_base.html")
c.render_notebook()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
-
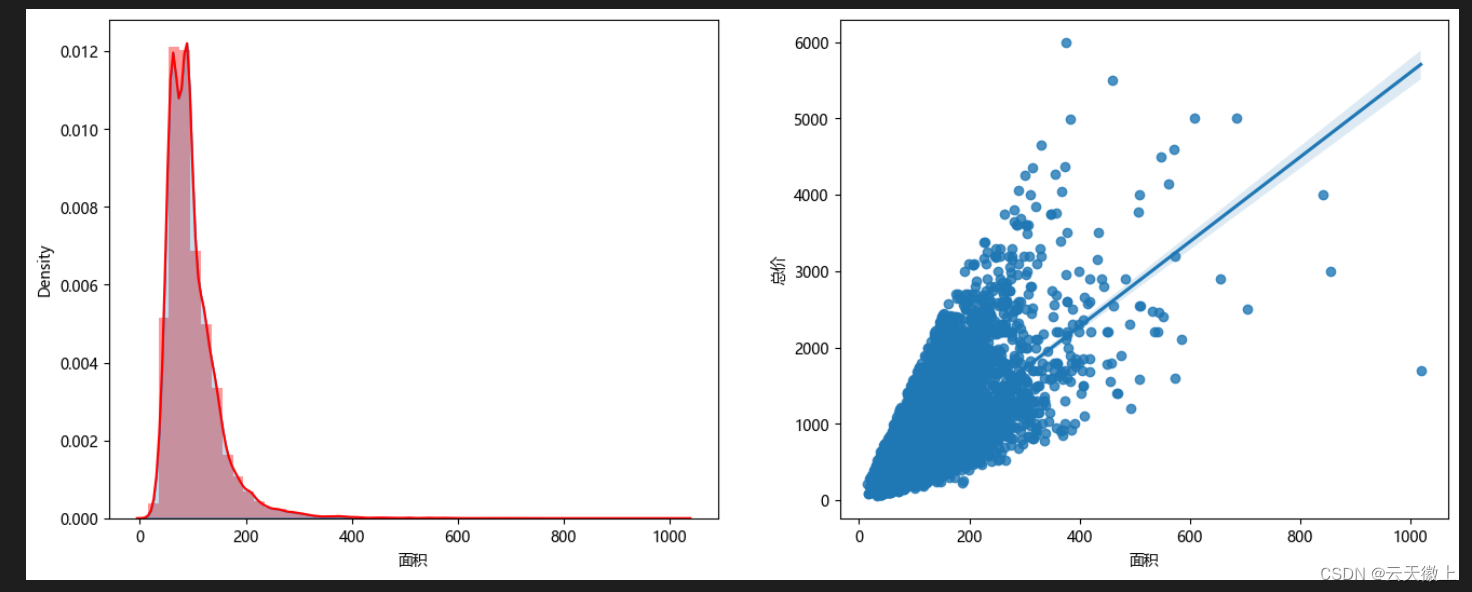
- 二手房面积分布与价格关系图
f, [ax1,ax2] = plt.subplots(1, 2, figsize=(16, 6))
# 房屋面积
sns.distplot(data['面积(㎡)'], ax=ax1, color='r')
sns.kdeplot(data['面积(㎡)'], shade=True, ax=ax1)
ax1.set_xlabel('面积')
# 房屋面积和价格的关系
sns.regplot(x='面积(㎡)', y='价格(万元)', data=data, ax=ax2)
ax2.set_xlabel('面积')
ax2.set_ylabel('总价')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
-
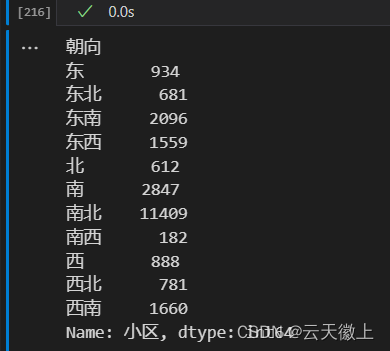
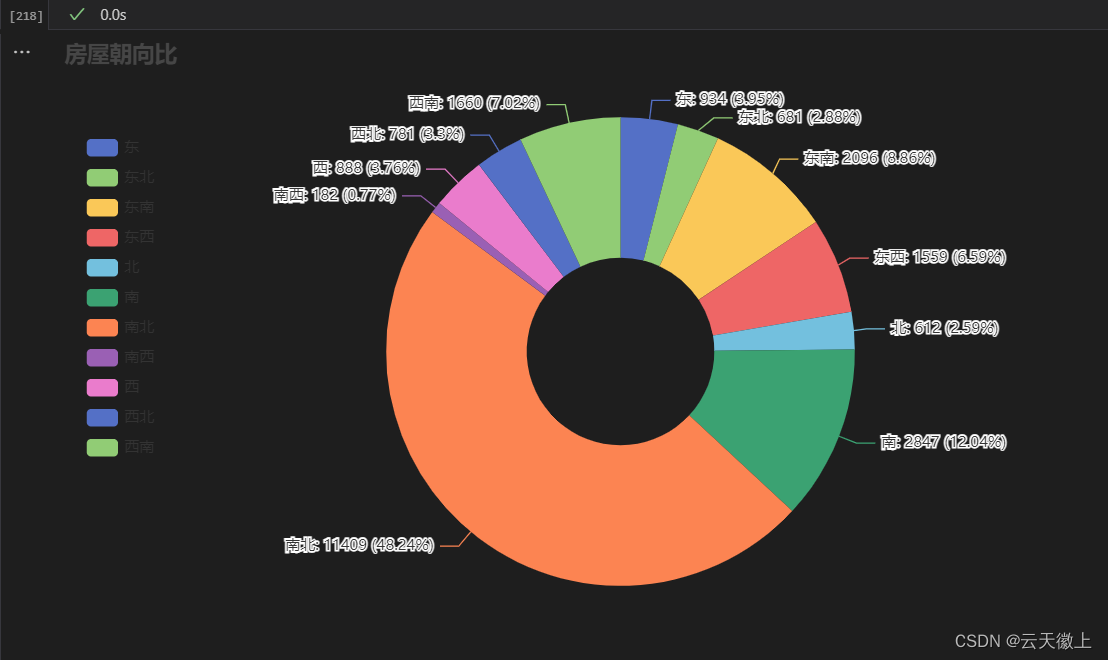
- 房屋朝向饼状图
d = data.groupby('朝向')
direction = d.count()['小区']
direction
- 1
- 2
- 3
from pyecharts.charts import Pie c = ( Pie() .add( "", [list(z) for z in zip(direction.keys().tolist(),direction.values.tolist())], radius=["30%", "75%"], ) .set_global_opts( title_opts=opts.TitleOpts(title="房屋朝向比"), legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"), ) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c} ({d}%)")) ) c.render_notebook()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 6) 各户型横向条形图
series = data['户型'].value_counts()
series.sort_index(ascending=False, inplace=True)
house_type_list = series.index.tolist()
count_list = series.values.tolist()
c = Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
c.add_xaxis(house_type_list)
c.add_yaxis("北京市", count_list)
c.reversal_axis()
c.set_series_opts(label_opts=opts.LabelOpts(position="right"))
c.set_global_opts(title_opts=opts.TitleOpts(title="北京二手房各户型横向条形图"),
datazoom_opts=[opts.DataZoomOpts(yaxis_index=0, type_="slider", orient="vertical")],)
#c.render("北京二手房各户型横向条形图.html")
c.render_notebook()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
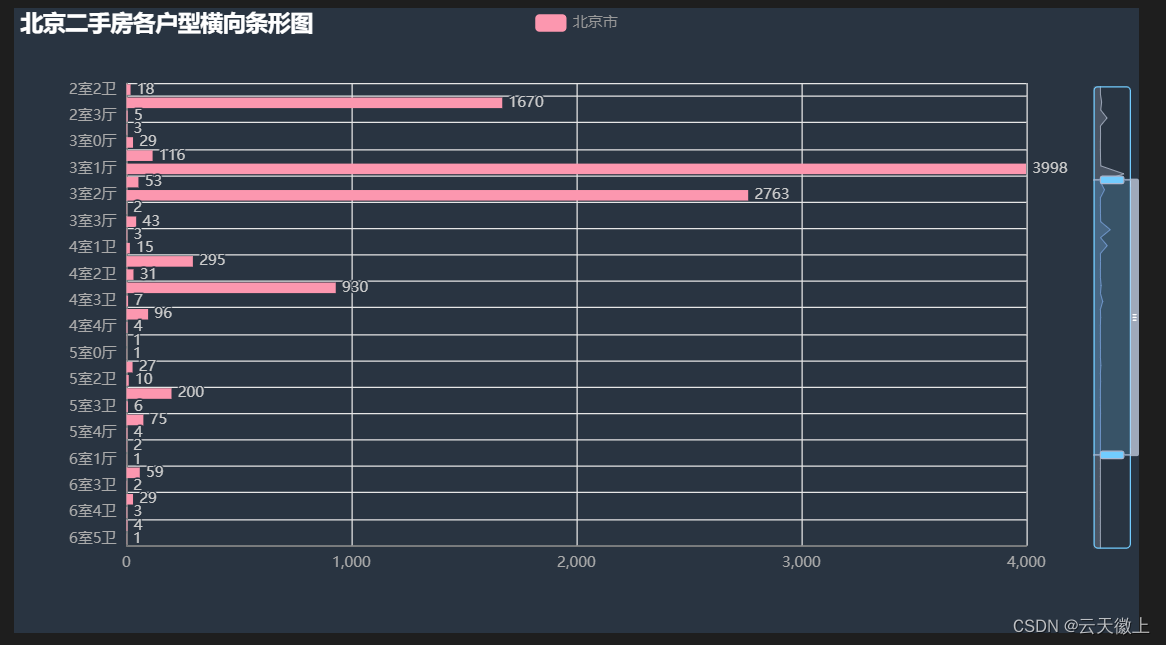
-
- 房屋装修程度饼状图
decoration_list = data['装修情况'].value_counts().index.tolist() count_list = data['装修情况'].value_counts().values.tolist() from pyecharts.charts import Pie c = Pie(init_opts=opts.InitOpts(theme=ThemeType.CHALK)) c.add(series_name="房屋装修", data_pair=[list(z) for z in zip(decoration_list, count_list)], rosetype="radius", radius="55%", center=["50%", "50%"], label_opts=opts.LabelOpts(is_show=False, position="center")) c.set_global_opts(title_opts=opts.TitleOpts( title="北京二手房房屋装修饼状图", pos_left="center", pos_top="20", title_textstyle_opts=opts.TextStyleOpts(color="#fff")), legend_opts=opts.LegendOpts(is_show=False)) c.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"), label_opts=opts.LabelOpts(color="rgba(255, 255, 255, 255)")) # c.render("customized_pie.html") c.render_notebook()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
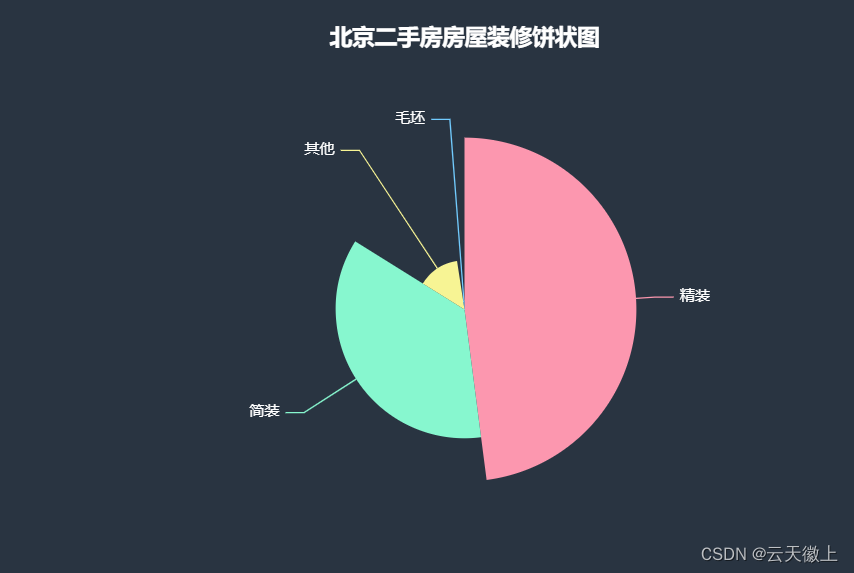
-
- 房屋面积分布柱状图
area_level = [0, 50, 100, 150, 200, 250, 300, 350, 400, 1500]
label_level = ['50-100','100-150','150-200','200-250','250-300','300-350','350-400','400-450']
p1 = pd.cut(data['面积(㎡)'],area_level,label_level)
p2 = p1.value_counts()
p3 = p2.values.tolist()
- 1
- 2
- 3
- 4
- 5
- 6
p3
[13647, 5808, 1675, 1561, 541, 217, 93, 54, 53]
- 1
- 2
c = (
Bar()
.add_xaxis(label_level)
.add_yaxis("面积(㎡)",p3,color="#7944B7")
.reversal_axis()
.set_series_opts(
label_opts=opts.LabelOpts(position='right')
)
.set_global_opts(
title_opts=opts.TitleOpts(title="房屋面积分布柱状图"),
xaxis_opts=opts.AxisOpts(name='数量'),
yaxis_opts=opts.AxisOpts(name='面积(㎡)')
)
)
c.render_notebook()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
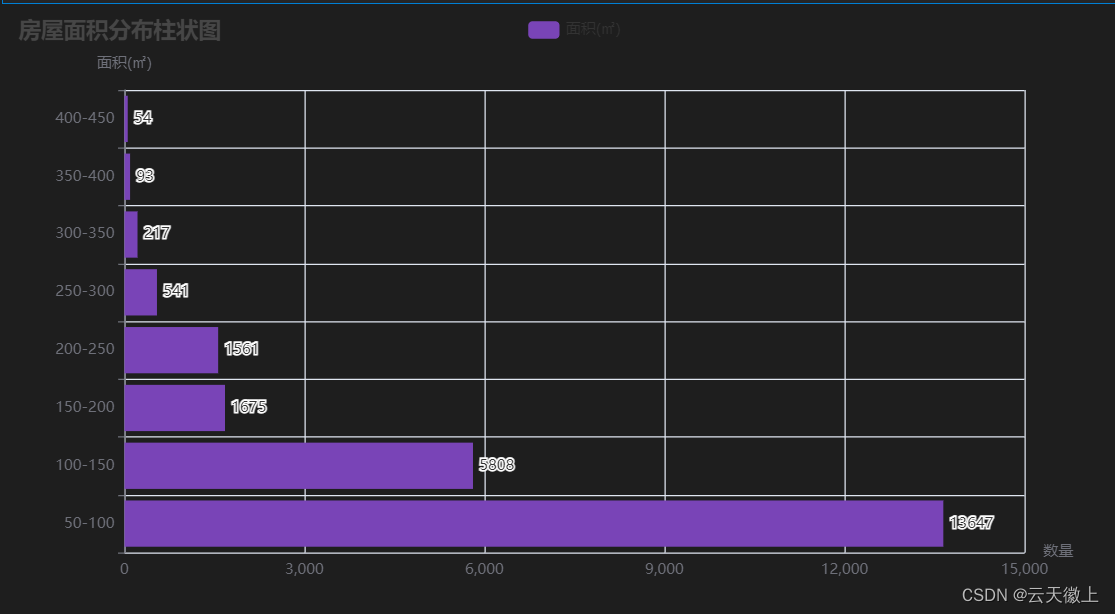
-
- 楼层的分布
sns.distplot(data['楼层'],color='r')
- 1
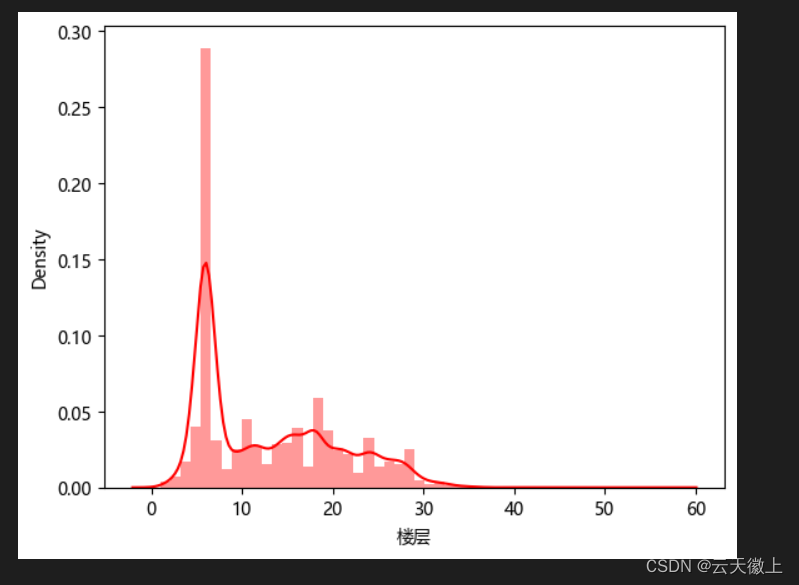
-
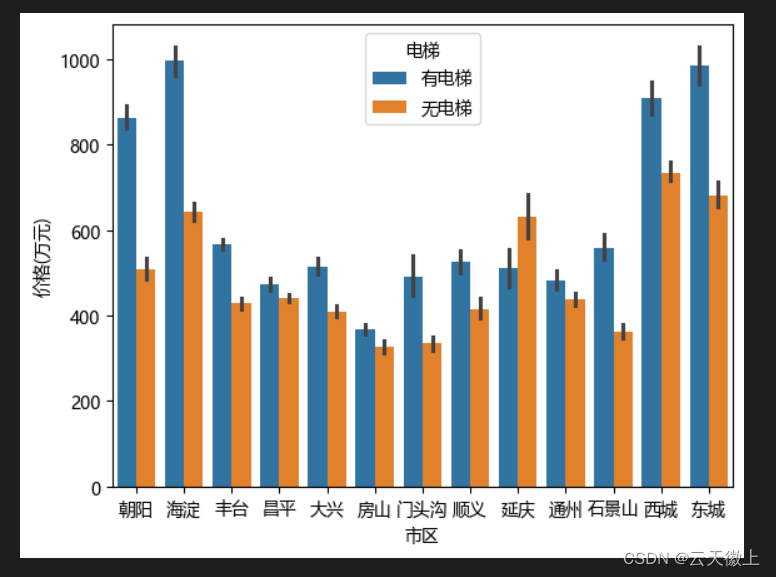
- 北京市二手房有无电梯的关系(柱状图)和有无电梯和房价的关系(折线图)
df = data[data['电梯']!='未知']
sns.barplot(x="市区", y="价格(万元)", hue="电梯", data=df)
- 1
- 2
- 3
sns.lineplot(x=“市区”, y=“价格(万元)”, hue=“电梯”, data=df)
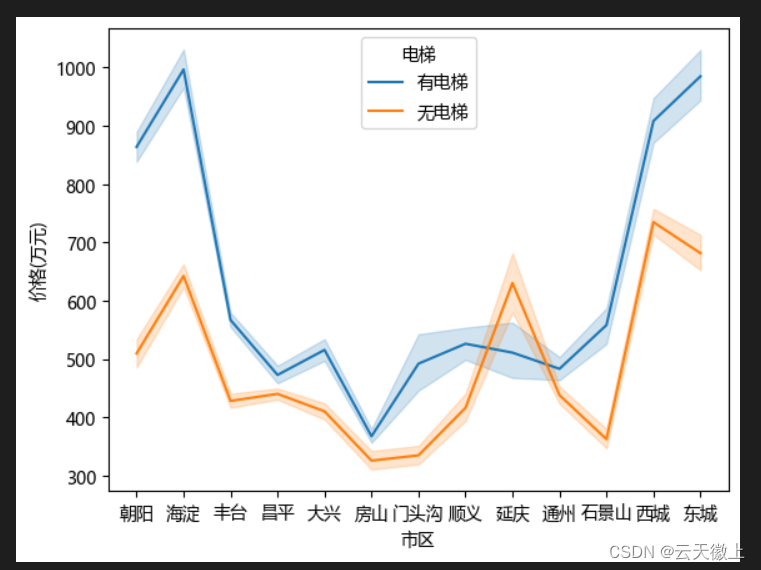
-
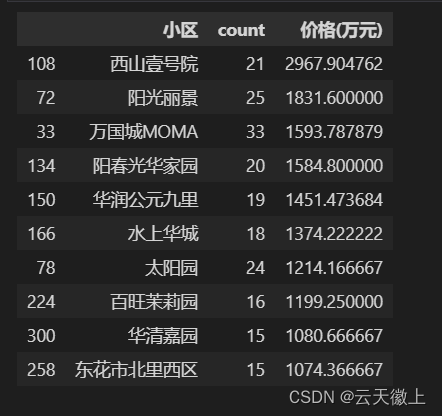
- 出售房数大于15间且房价均值Top10的小区
df = data['小区'].value_counts().reset_index() #data['小区']value_counts的结果转成dataframe
df1 = data.groupby(['小区'])['价格(万元)'].mean().reset_index()
df = df.merge(df1,on=['小区'],how='left')
# 筛选出计数大于15的小区
filtered_counts = df[df['count'] >= 15]
sorted_counts = filtered_counts.sort_values(by='价格(万元)',ascending=False)[:10]
sorted_counts
- 1
- 2
- 3
- 4
- 5
- 6
- 7
sns.barplot(x=‘小区’,y=‘价格(万元)’,data=sorted_counts)
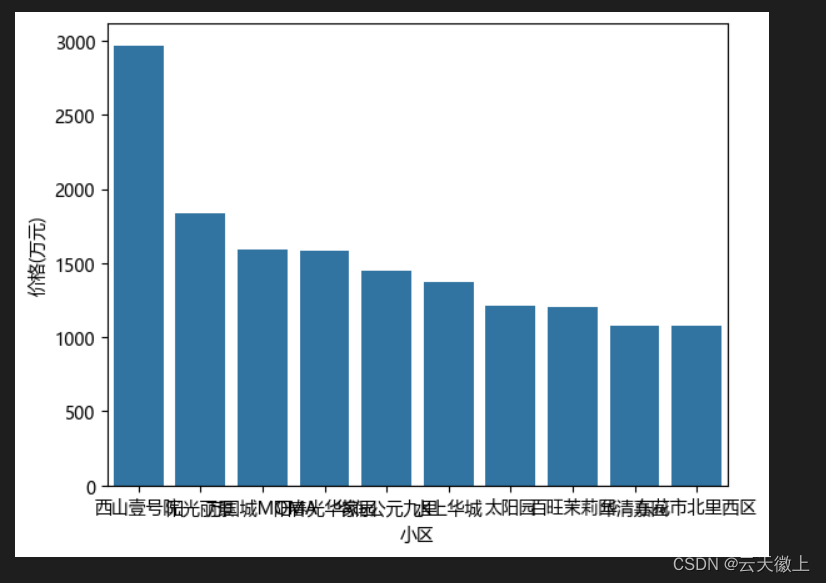
本文完整代码下载地址:https://download.csdn.net/download/qq_38614074/89017277
总结:
通过对北京某平台二手房数据的可视化分析,我们可以得出以下结论:
北京二手房市场的价格呈现出明显的分布特点,不同价格区间的房屋数量和价格水平存在差异。
房屋面积在北京二手房市场中也存在一定的分布特点,不同面积区间的房屋数量和面积大小有所差异。
北京各区域的二手房分布不均,一些热门区域的房源较多,价格也相对较高。
这些分析结果可以为购房者提供有价值的信息和参考,帮助他们更好地了解市场情况,做出明智的购房决策。同时,对于投资者来说,这些数据分析也可以提供市场趋势和投资机会的线索。
需要注意的是,本文仅基于某平台的二手房数据进行分析,可能存在一定的局限性。在实际购房或投资决策中,还应综合考虑其他因素,如房屋质量、交通便利性、配套设施等。
通过数据可视化的方式,我们可以更直观地了解和分析二手房市场的情况,为决策者提供更全面的信息支持。希望本文的分析结果对读者有所启发,并在购房或投资过程中起到一定的指导作用。

