
热门标签
热门文章
- 1【全年汇总】2023年CCF交叉/新兴/综合会议截稿时间汇总(持续更新)_ccf c类会议截稿日期
- 2腾讯发表多模态大模型最新综述,从26个主流大模型看多模态效果提升关键方法_大模型最新技术哪里看
- 3Python创建自己的聊天机器人_python智能客服机器人代码
- 4自然语言处理nltk下载以及nltk_data下载及其所遇问题解决方案_ntlk下载
- 523种设计模式-- 思路分析+代码实现_设计一个类,文字描述设计思路,并转化为代码在主函数中实现
- 6如何使用机器学习进行图像识别|数据标注_图像识别对图片打标签
- 7漫话:如何给女朋友解释为什么计算机从0开始计数,而不是从1开始?
- 8oracle 11.2.0.1 rac 修改asm磁盘组的冗余模式(redundancy mode)为normal【待看】_选择asm磁盘组类型选择nomal还是外部
- 9Linux — 进程控制_linux之进程管理一头歌答案
- 10【医学图像处理】融合 Transformer 和 CNN 进行医学图像分割_cnn-transformer图像分割
当前位置: article > 正文
MySQL索引的数据结构
作者:IT小白 | 2024-03-25 21:09:33
赞
踩
mysql索引的数据结构
索引的数据结构
目标
- 了解索引的数据结构
分析
我们知道索引是帮助MySql高效获取数据的数据结构。但是为什么使用索引后查询效率会有如何大的提升?这就要索引的数据结构有关了,我们来了解一下索引的数据结构
讲解
1. 二叉树
在没有索引的情况下我们执行一条sql语句,那么是MySql进行全表遍历,磁盘寻址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)
为了加快的查找效率,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找快速获取到相应数据。
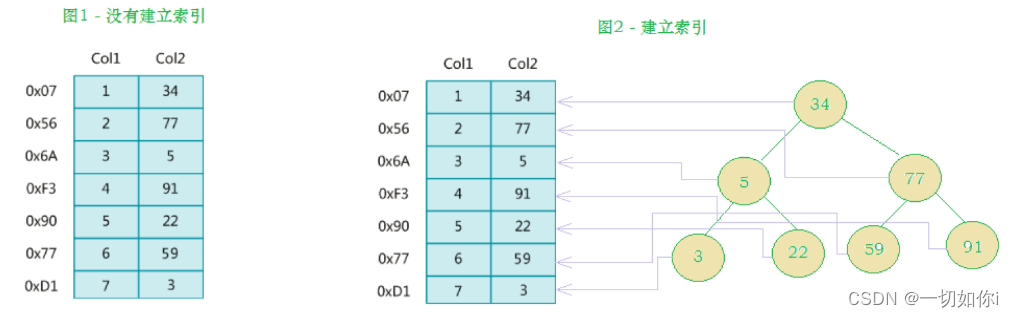
二叉树介绍
每个节点下,只能有两个子节点,并且左边子节点比父节点小,右边子节点比父节点大
二叉树优缺点
- 优点:减少了磁盘IO的次数,加快了查找的速度。
- 缺点:
- 每个节点只能有两个子节点:如果有海量的数据,树的层级会非常深,磁盘IO次数并不会减少特别多
- 极端情况,二叉树可能变成链表,查找数据时就变回了全表扫描,导致性能严重下降
2. 红黑树(平衡二叉树)
平衡二叉树介绍
平衡二叉树是针对二叉树做了增强:会通过左旋、右旋达到一个自平衡,而不会形成链表。
平衡二叉树优缺点
- 优点:任何情况都不会形成链表
- 缺点:
- 每个节点只能有两个子节点:如果有海量数据,树的层级仍然会非常深
- 树的高度无法控制
3. B-Tree(多路平衡搜索树)
B-Tree介绍
- MySql每个索引节点默认16K大小,一个节点上可以存放更多的数据,一个节点可以拥有更多的子节点
- 每个节点上保存的数据既有数据内容,还有索引值和指针值
B-Tree优缺点
- 优点:每个节点可以存储更多数据,树的层级会浅一些,IO次数会减少
- 缺点:不能处理范围查找的性能问题
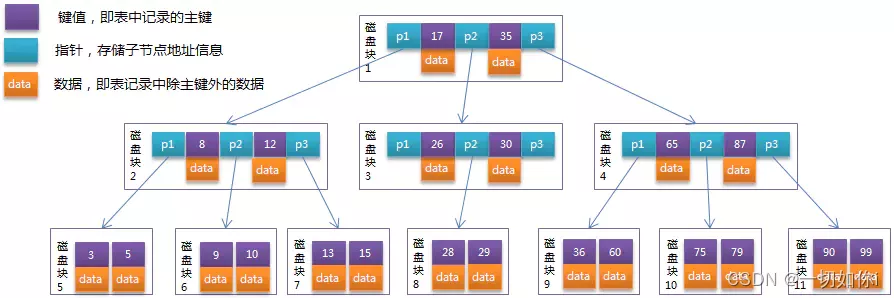
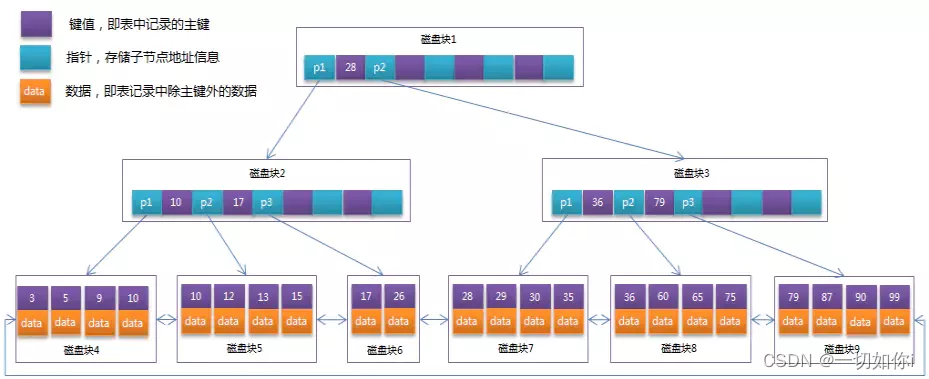
4. B+Tree【MySql使用的这种】
-
B+Tree是对B-Tree的改进版,每个非叶子节点上只保存索引值和指针,只有叶子节点才保存数据。
MySql每个索引节点大小默认是16KB。索引值大小8B、指针值大小6B,那么一个节点可以存储1170个元素;存储1KW数据,只需要3层就可以了。
查看每个节点大小:
show global status like 'innodb_page_size'; -
MySql为了提高性能,会预选把根节点的数据加载到内存中。那么如果是3层的树,只要2次IO就可以找到指定的数据了
-
所有叶子节点,使用链表串起来,大大提升了范围查询的速度
5. hash
redis:性能强,查询速度极快,用来作为缓存,而不是持久化存储的数据库
存取数据的时候,需要先对数据进行哈希运算,得出一个值,此值就是对应的hash桶。hash桶中的数据结构为链表或者红黑树。
- 优点:查询速度快,尤其是单值查询的速度
- 缺点:
- 不能解决范围查询的性能问题
- 不能解决排序的性能问题
jdk8中hashmap桶中的数据结构
- 当桶中的数据超过8的时候就由链表–>红黑树;
- 当数据小于6的时候就会由红黑树–>链表
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/312491
推荐阅读

相关标签

