
- 1tomcat安装、部署JSPGOU项目、Tomcat多实例
- 2惠氏桥测量电阻_pt1000测量电路
- 3对 Python 代码使用的词语标记化器 tokenize,你懂了吗?【Python|标准库|tokenize】_python tokenize
- 4git-常用命令
- 5阿里通义灵码实测使用,强大,好用!_阿里灵码
- 6用knn算法对鸢尾花数据集进行分类
- 7模拟电路设计(10)--- 运算放大器简介_模拟集成电路中运放的内部结构图
- 8如何使用RxJava 2.x开发Android应用?_反应式编程实战:使用rxjava 2.x开发android应用
- 9人工智能基础部分15-自然语言处理中的数据处理上采样、下采样、负采样是什么?_文本 下采样的区别
- 10编译MOTR的时候,报错:error: cannot call member function ‘void std::basic_string<_CharT, _Traits, _Alloc>::_R_msda.ms_deform_attn_forward
Grounding DINO、TAG2TEXT、RAM、RAM++论文解读_ram论文解读
赞
踩
提示:Grounding DINO、TAG2TEXT、RAM、RAM++论文解读
文章目录
前言
随着SAM模型分割一切大火之后,又有RAM模型识别一切,RAM模型由来可有三篇模型构成,TAG2TEXT为首篇将tag引入VL模型中,由tagging、generation、alignment分支构成,随后才是RAM模型,主要借助CLIP模型辅助与annotation处理trick,由tagging、generation分支构成,最后才是RAM++模型,该模型引入semantic concepts到图像tagging训练框架,RAM++模型能够利用图像-标签-文本三者之间的关系,整合image-text alignment 和 image-tagging 到一个统一的交互框架里。作者也介绍将tag引入Grounding DINO模型,可实现目标定位。为此,本文将介绍这四篇文章。
一、Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
1、摘要
我们提出open-set检测任务方法叫做groindding dino,该方法基于transform的dino预训练模型相结合,可通过类别或相关表述来检测任意目标。该模型解决open-set任务最核心方法是引入语言language,为有效融合语言与视觉模态特征,我们设定三个阶段,并构建feature enhancer、a language-guided query selection与a cross-modality decoder for cross-modality fusion。我们方法与以往研究不一样,以往研究基本是用模型评估开放数据集,我们是通过tag评估开放集数据(我们用tag、以往直接评估),我们方法在三个数据集表现sota

注:文章核心是tag提供语言信息结合到图像中,可使用tag检测定位grounding,即使未学习tag给到图像也有不错表现。
2、背景
Grounding DINO相对于GLIP有以下优势:
1、基于Transformer结构与语言模型接近,易于处理跨模态特征;
2、基于Transformer的检测器有利用大规模数据集的能力;
3、DINO可以端到端优化,无需精细设计模块,比如:NMS
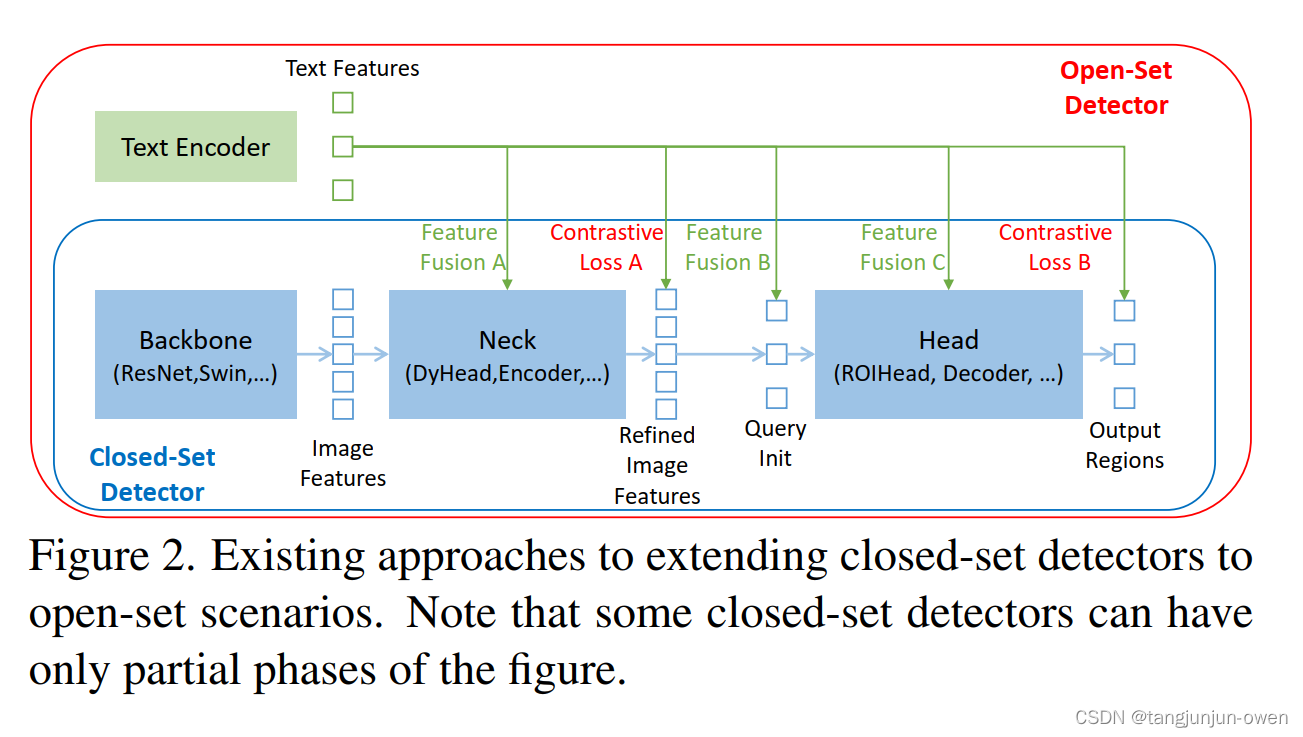
先前研究open-set检测器是由闭集检测器引入语言信息实现,如图2所示,一个封闭集检测器通常有三个重要模块,一个主干网络用于特征提取,一个颈部用于特征增强,以及一个头部用于区域调整(或框预测)。可以通过学习语义意识的区域嵌入来将封闭集检测器推广到检测新对象,以便每个区域可以在语义意识的语义空间中分类为新类别。实现这一目标的关键是在颈部和/或头部输出处使用区域输出和语言特征之间的对比损失。为了帮助模型对齐跨模态信息,一些工作尝试在最终损失阶段之前融合特征。图2显示,特征融合可以在三个阶段进行:颈部(阶段A)、查询初始化(阶段B)和头部(阶段C)。例如,GLIP[26]在颈部模块(阶段A)中执行了早期融合,OV-DETR[56]将语言感知查询用作头部输入(阶段B)。
3、部分文献翻译
检测Transformer。基于定位的DINO建立在类似DETR的模型DINO [58]之上,DINO是一个端到端的基于Transformer的检测器。DETR首先在[2]中提出,然后在过去几年中从许多方面得到改进[4,5,12,17,33,50,64]。DAB-DETR [31]引入了锚框作为DETR查询,以进行更准确的框预测。DN-DETR [24]提出了查询去噪以稳定匹配。DINO [58]进一步开发了几种技术,在COCO物体检测基准测试中刷新了记录。然而,这些检测器主要侧重于封闭集检测,很难推广到新类别,因为预定义类别有限。
开放集物体检测。开放集物体检测使用现有的边界框注释进行训练,目的是检测任意类别的对象,语言泛化提供帮助。OV-DETR [57]使用由CLIP模型编码的图像和文本嵌入作为查询,以在DETR框架中解码类别指定的框。ViLD [13]从CLIP老师模型中蒸馏知识到类似R-CNN的检测器,以便学习到的区域嵌入包含语言的语义。GLIP [11]将物体检测形式化为定位问题,利用额外的定位数据帮助学习短语和区域层面上的语义对齐。它显示这样的表述甚至可以在完全监督的检测基准测试上取得更强的性能。DetCLIP [53]涉及大规模图像字幕数据集,并使用生成的伪标签来扩展知识数据库。生成的伪标签有效帮助扩展检测器的泛化能力。
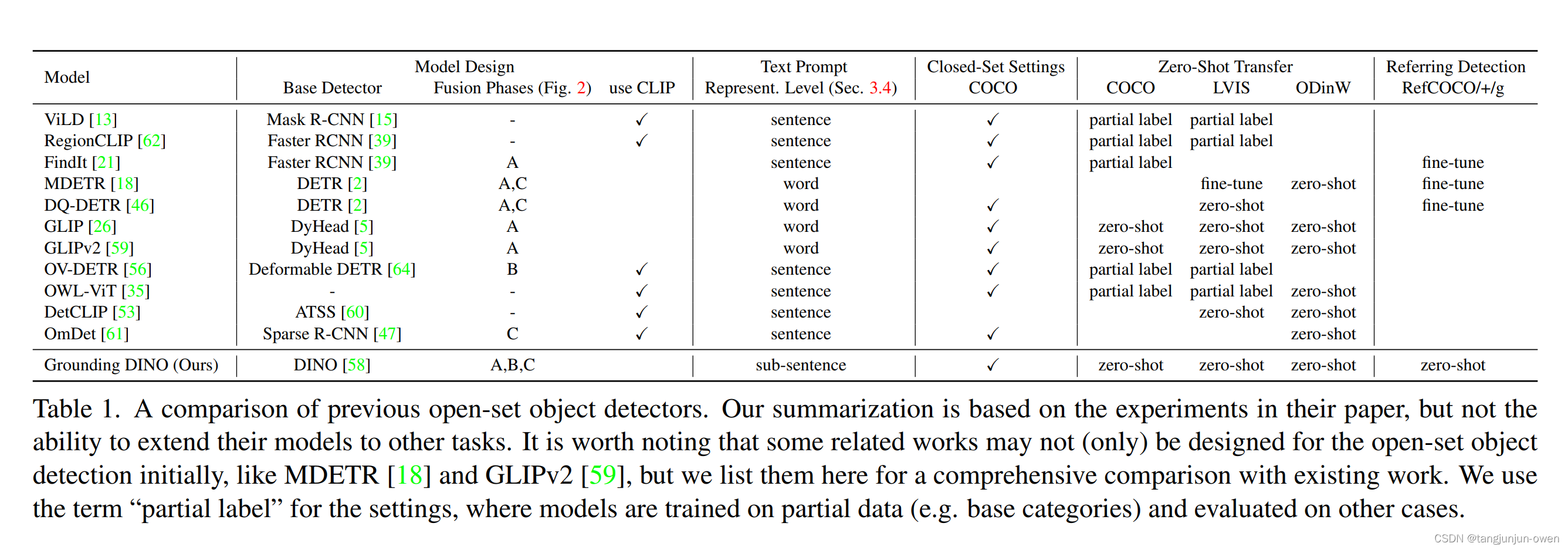
然而,以前的工作只在部分阶段融合多模态信息,这可能会导致次优的语言泛化能力。例如,GLIP仅考虑在特征增强(阶段A)中进行融合,而OV-DETR仅在解码器输入(阶段B)处注入语言信息。此外,REC任务在评估中通常被忽视,这是开放集检测的一个重要场景。我们在表1中比较了我们的模型与其他开放集方法。
4、贡献
- 我们提出了Grounding DINO,它通过在多个阶段执行视觉语言模态融合来扩展封闭集检测器DINO,包括特征增强器、语言指导的查询选择模块和跨模态解码器。 这种深度融合策略有效改进了开放集物体检测。
- 我们提出将开放集物体检测的评估扩展到REC数据集。 它有助于评估模型对自由文本输入的性能。
- 在COCO、LVIS、ODinW和RefCOCO/+/g数据集上的实验表明,Grounding DINO在开放集物体检测任务上的有效性。
5、模型结构解读
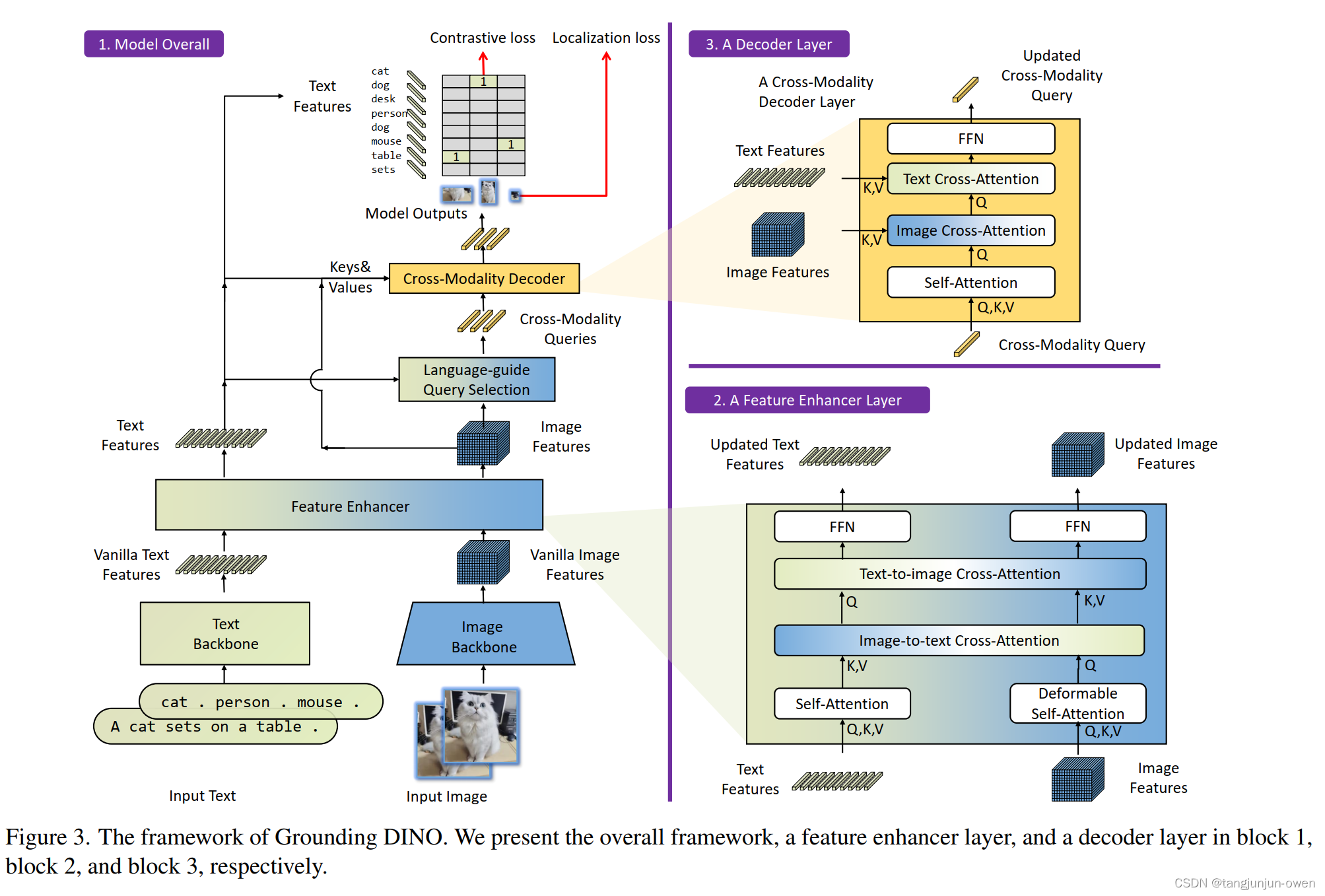
模型整体框架为block1坐标,特征增强层为block2右下角,解码层为block3右上角,我将大概说下这三个block内容。
a.模型整体结构
block1内容:最下面可看出文本tag使用的文本特征提取的backbone,而图像使用图像特征提取的backbone,这2个是独立的;其次中将层feature enhancer为block2我待会再说;然后继续往上,可看到text feature基本结束,类似clip图像特征与最终图像特征做相似度匹配,而中间文本特征还往右图的图像特征做了或引导或KV特征;右边image features向上接受文本特征指引,随后在向上为解码模块block3,我将在下面介绍。
b.特征增强结构
block2内容:特征增强,即特征融合方式,文本与特征分别使用自注意力attention结构,随后图像提供Q在提供KV实现图像特征输出;文本提供KV在提供Q实现文本特征输出。(这里细节建议查看源码,但这里思路可借鉴)
c.解码结构
block3内容:实际是为图像特征解码做后面图像与文本特征匹配与定位任务,首先文本特征驶向图像特征完成文本指导,从图中看是做了cross-Modality,大胆猜测文本为Q、图像为KV的融合,随后再成Q分别再次将图像特征KV进行attention,获得结果再次作为Q对文本特征KV进行attention,最终为图像特征输出。
6、实验有趣说明
有趣的是,在相同设置下,DINO预训练的Grounding DINO优于标准Grounding DINO在LVIS上的性能。结果表明模型训练还有很大的改进空间,这将是我们未来要探索的方向。
二、TAG2TEXT: GUIDING VISION-LANGUAGE MODEL VIA IMAGE TAGGING
1、摘要
本文介绍了 Tag2Text,一种视觉语言预训练 (VLP) 框架,它将图像标记引入视觉语言模型以指导视觉语言特征的学习。与使用手动标记或使用有限检测器自动检测的对象标签的先前工作相比,我们的方法利用从其配对文本解析的标签来学习图像标记器,同时为视觉语言模型提供指导。鉴于此,Tag2Text 可以根据图像文本对使用大规模无注释图像标签,并提供超越对象的更多样化的标签类别。因此,Tag2Text 通过利用细粒度的文本信息实现了卓越的图像标签识别能力。此外,通过利用标记指导,Tag2Text 有效地增强了视觉语言模型在基于生成和基于对齐的任务上的性能。在广泛的下游基准测试中,Tag2Text 以相似的模型大小和数据规模取得了最先进或有竞争力的结果,证明了所提出的标记指南的有效性。

注:文章核心是将tag引入到VL模型且提供tag制作方法。
2、背景
①表示先前研究基于检测器范式将tag引入检测器中,该方法是有效的,②表示提取图像特征,将这些特征送入多模态图像文本交互校准。然这些方法限制了检测模型能力且耗时, 近期研究者使用如何避免这样问题的方法,但结果表明其方法不能有效使用tag信息,③为图像tag指引,使用一个简单tag相关head头将图像tag引入②中detector-free VL模型中且凭借文本解析图像图像对应的tag去监督引入头,而我们完成监督tagging能力模型方法,且有效增强视觉语言任务性能。b图显示我们与基于目标检测范式的内容比较。
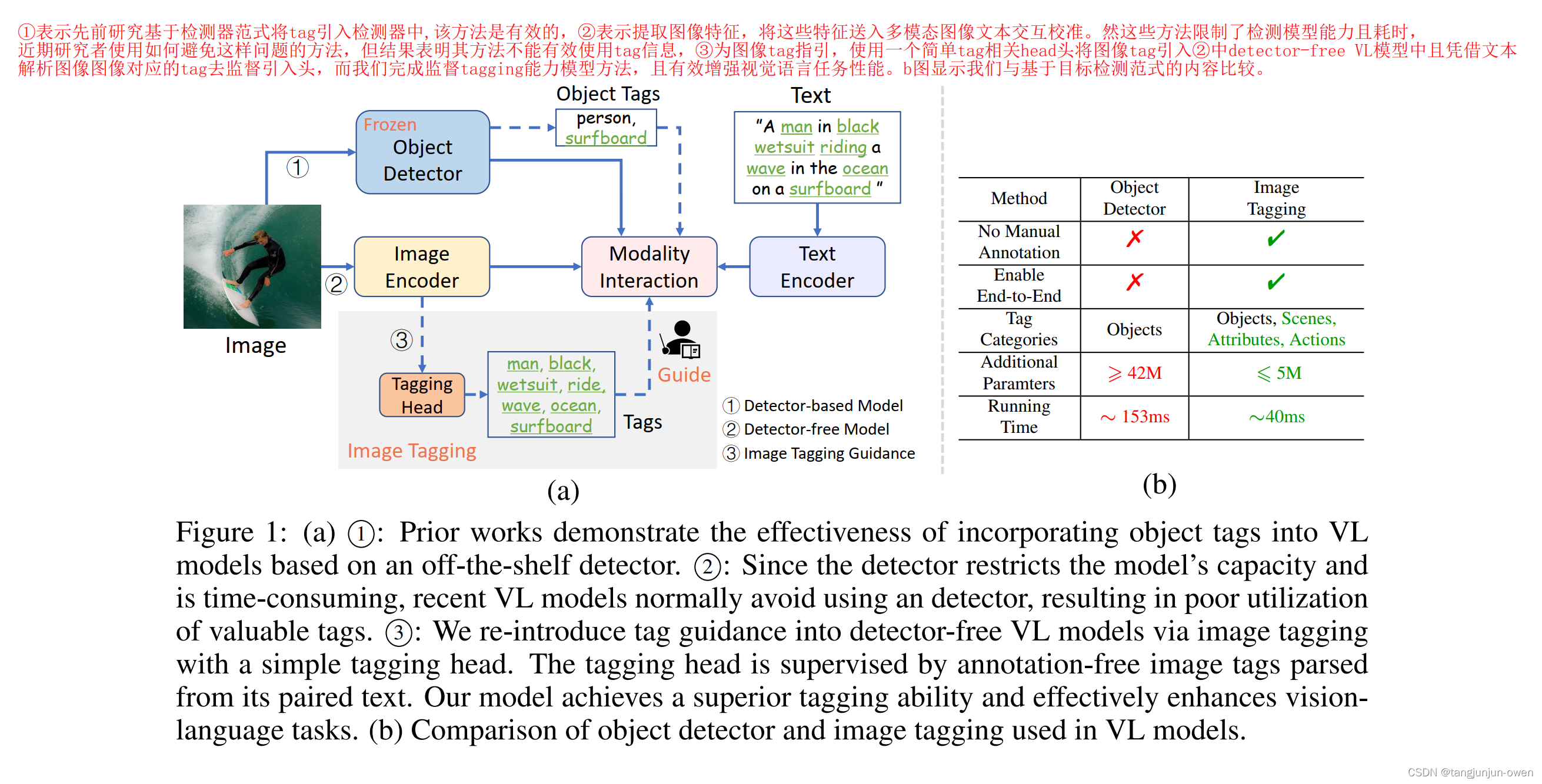
作者提出引入tag作为视觉-文本任务,有两个关键问题:数据和网络结构,其中数据也是本文提出的重点,如何构造图片的tag作为 label训练。实际image-text对数据很丰富,作者使用文本语义解析在text中获取图片对应tags。这样,图像tags能提供了图像和文本之间更好的桥梁,解析的标记类别更加多样化,比目标检测的object更丰富,有例如场景、属性、动作等。这就是数据发挥的重要作用。模型结构我将在下节介绍。
3、贡献
1、首先,证明了tag2text模型利用现成图像文本对解析的tag训练的模型在imge tagging能力,且zero-shot能力与全监督方法相当。
2、tag2text使用tag指导方式通过imamge tagging无缝连接整合现有vlm模型中,有效增强生成任务与校准任务的能力。
3、 一系列下游任务实验等,证明了tagging能力,且说明了tagging 引导信息整合到VLM模型的有效性。

5、模型结构解读
模型结构包含3个分支:Tagging, Generation, Alignment,为不同的任务分支,多标签识别(就是tagging),Image Caption图像解说,Image-Text对齐。其中核心为tagging分支。
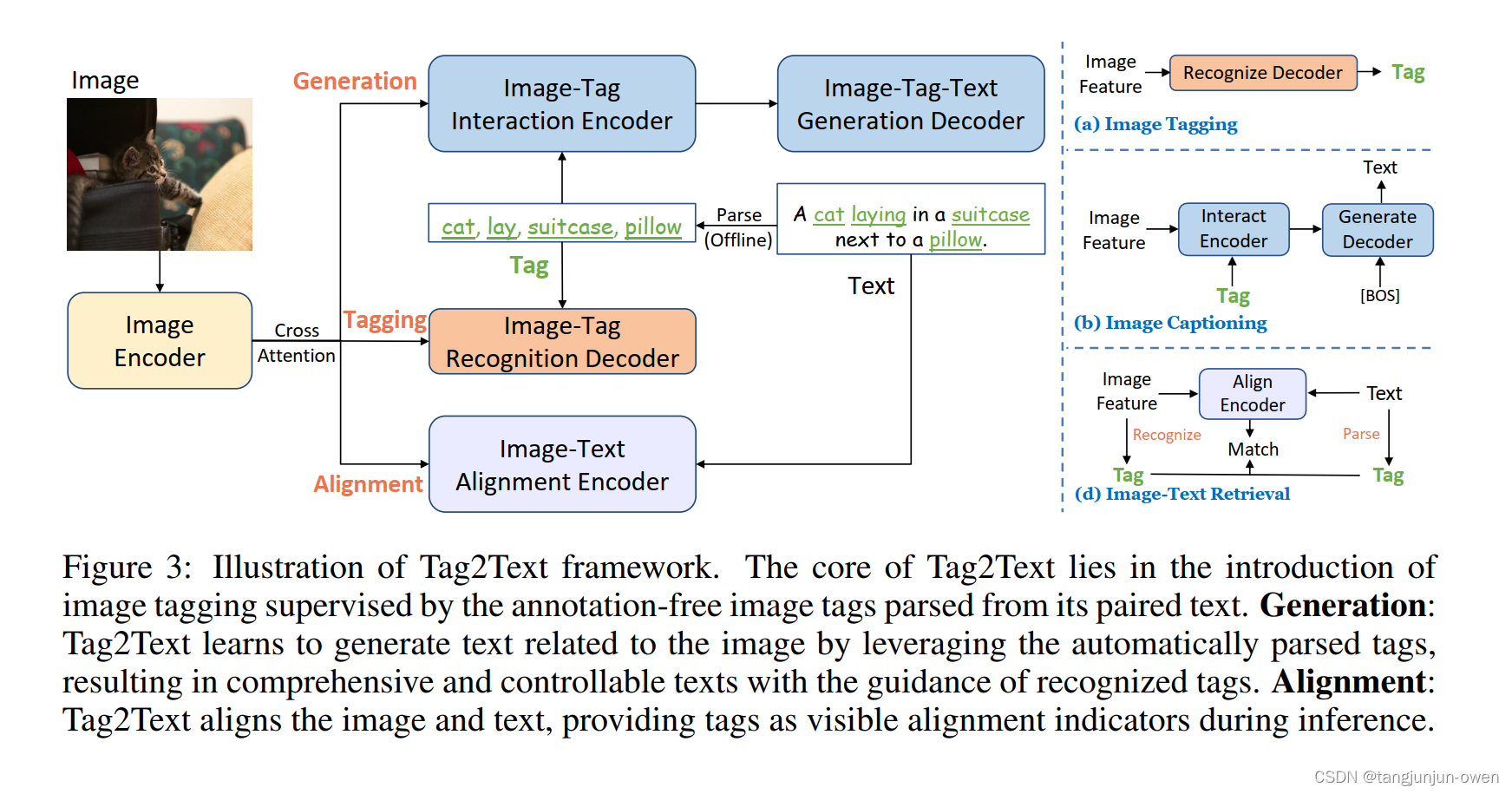
Tagging:用了Query2Label中的多label分类transformer decoder,同时为了避免解析的tags中有某些对应图片tag的缺失、正负样本的不平衡,使用了Asymmetirc Loss。
Generation:用了NLP中标准的transformer的编解码encoder-decoder框架,tags/text 映射为 embeding,然后 tags embeding(随机乱序,防止顺序影响学习)与 image embedding(features) 一起送入 encoder,再经过decoder解码。输出与text embedding进行loss计算,相当于用 tag 指导 image 生成 text。
Image-Text Alignment:用了BLIP中 Encoder 结构,image embedding 与 text embeding送入encoder,用粗粒度的 Image-Text Contrastive(ITC) Loss 和 细粒度的 Image-Text Matching(ITM) Loss 分别进行监督。
三、Recognize Anything: A Strong Image Tagging Model
1、摘要
我们提出了RAM模型,一个image tagging任务的基准模型。ram在计算视觉中迈出一大步,能带有很高精度与zero-shot能力,识别任意类别。ram在image tagging任务中提出了新的范式,利用大量图像-文本对训练,从而替换了人工标注工作。RAM分四个步骤,第一通过自动文本语义解析获得image-text标签;第二训练一个统一描述与标签的初始模型;第三数据引擎用来生成额外注释和清除不对的数据;第四模型通过预训练并使用精度高标注的数据做fitune训练。作者也在多个基准上测试模型,性能已超过CLIP与BLIP能力。

2、背景/引言
LLM因其大数据在NLP领域很火,这些模型展现更好zero-shot能力,且能处理超出训练领域外的任务与数据分布。说到cv领域,SAM模型因大数据训练,已被证明有很强的定位能力。
然而sam模型缺乏输出语义标签能力。多标签图像识别是众所周知的image tagging,目的是通过给定多标签图像识别语义标签。image tagging是一个重要而具有现实意义的视觉任务,多标签可包含目标标签、场景、属性和行为。遗憾的是,存在多标签分类、检测、分割和视觉语言方法在tagging中存在缺陷,为受限范围与精度(与本文ram可识别一切相比),如图1描述,sam定位能力很强但无法识别,与ram相比,ram能给出识别能力且不受scope与accuracy限制(个人理解scope有5000多个类当然scope大了,accuracy因大大数据使其性能好了)。
自然引出网格核心问题,一个是数据制作一个是模型结构。
没有更强识别能力,可突破scope与accuracy限制
3、数据获得
Tag2Text利用 image-text-pair 的 text 进行解析,得到 tags,高频排序筛选前top-5k的标签,频率越高越重要。而RAM进一步扩大了数据量,筛选扩大到top-10k。原文具体做法如下:
标签系统:我们首先建立一个通用和统一的标签系统。我们结合了来自流行学术数据集(分类、检测和分割)以及商业标记产品(谷歌、微软、苹果)的类别。我们的标签系统是通过将所有公共标签与文本中的公共标签合并而获得的,从而覆盖了大多数公共标签,数量适中,为 6,449。剩余的开放词汇标签可以通过开放集识别来识别。
数据集:如何用标签系统自动标注大规模图像是另一个挑战[30]。从 CLIP [22] 和 ALIGN [11] 中汲取灵感,它们大规模利用公开可用的图像文本对来训练强大的视觉模型,我们采用类似的数据集进行图像标记。为了利用这些大规模图像文本数据进行标记,按照[9、10],我们解析文本并通过自动文本语义解析获得图像标签。这个过程使我们能够根据图像文本对获得各种各样的无注释图像标签。
数据引擎:然而,来自网络的图像文本对本质上是嘈杂的,通常包含缺失或不正确的标签。为了提高注释的质量,我们设计了一个标记数据引擎。在解决丢失的标签时,我们利用现有模型生成额外的标签。对于不正确的标签,我们首先定位与图像中不同标签对应的特定区域。随后,我们采用区域聚类技术来识别和消除同一类中的异常值。此外,我们过滤掉在整个图像及其相应区域之间表现出相反预测的标签,确保更清晰和更准确的注释。
4、贡献
1.Strong and general(强大的图片tag能力):实验说明在zero-shot上RAM的tags能力更强;
2.Reproducible and affordable(低成本复现与标注):可需要更少数据work,最强版本需要3天8张A100训练
3.Flexible and versatile(灵活且满足各种应用场景):可以单独使用作为标记系统,应用场景广,通过选择特殊类,ram能直接解决特殊类需要,能进一步和grounding dino结合实现语义分析(tag给grounding dino实现框定位等)
5、模型结构解读
RAM模型架构如图,大量图像对应tags数据通过自动文本语义解析模型从图像文本对中获得(现有数据很多)。在图像、标签、文本三块中,RAM实现图像caption与tagging任务。特别,RAM引入了一个现成的文本编码器,将标签编码器到语义丰富的文本标签查询中,从而在训练阶段实现对未知类别的泛化。
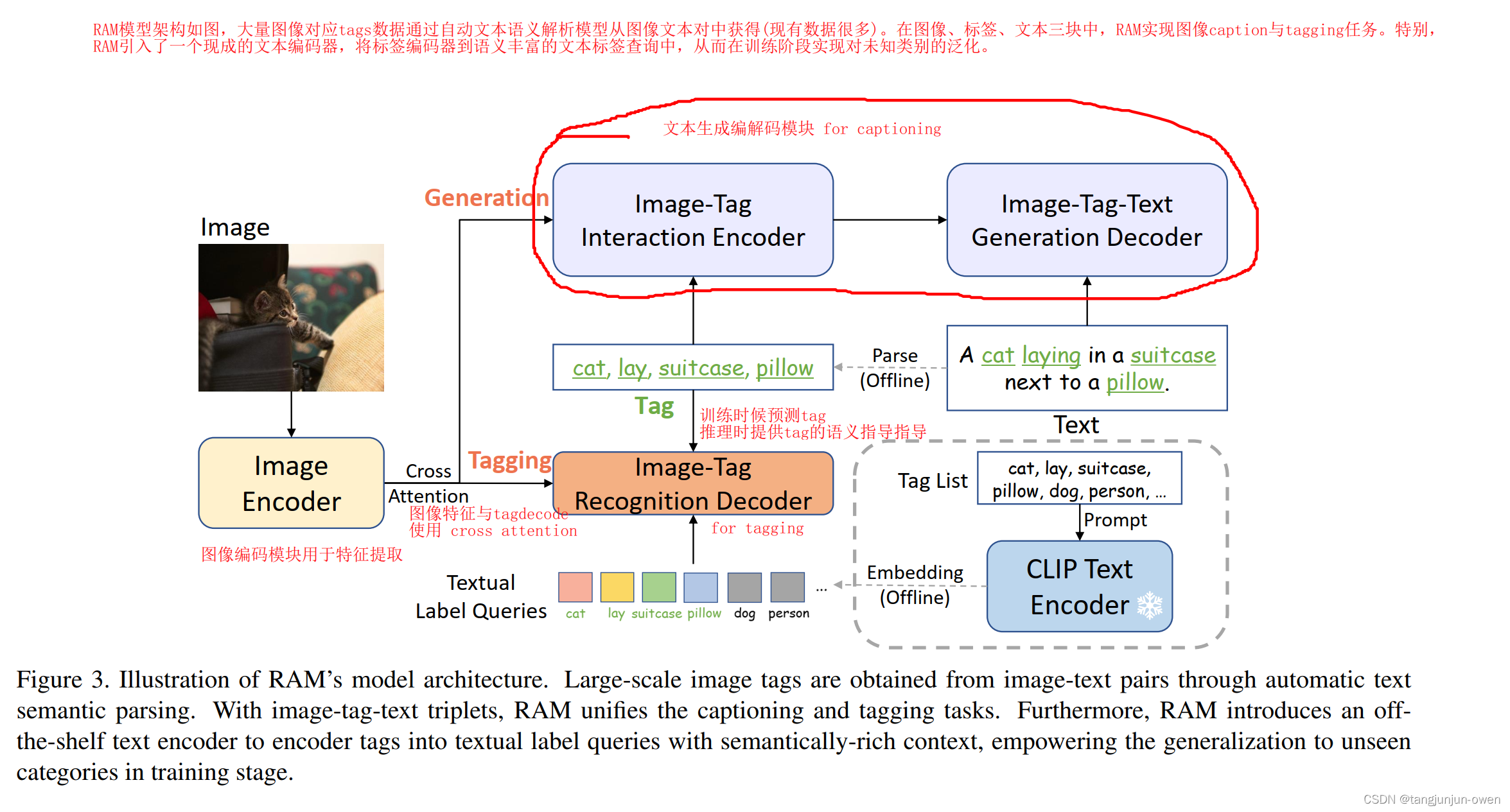
该模型屏蔽了tag2text的alignment分支,只有tagging与generation分支。
Tagging 分支用来多tags推理,完成识别任务;
Generation用来做 image caption任务;
Image Encoder 使用 Swin训练时,Tagging分支和Generation分支都用解析的Tags作为label;
测试时,Tagging会输出Tags,用于Generation的Caption任务生成最终的Text;
这里与tag2text最大不同在与CLIP的使用,作者把每个Tag进行prompt ensembling[22] 扩充,然后送入训好的CLIP Text Encoder得到其对应的文本标签查询(Textual label queries,其实就是 promopt + tag 的 embedding),作者认为这些 queries 比可学习的参数有更强的语义性和上下文信息。然后将这些Label Queris送进Tagging Decoder用image features进行Cross Attention。
引用该篇博客进一步解释:点击这里
1)训练过程没有上图右侧的CLIP Text Encoder。N个类别对应N个textual label queries——也就是可学习的参数,假设论文4585个类,每个类768维度表示,那么就是4585*768。
2)训练输入是三个元素:图片-Tag-文本构成,对应网络的一个输入(图像,文本输入不算,是网络自己的可学习参数)+ 2个输出(文本描述和多标签分类)。损失也就是常见的文本生成损失+多标签ASL损失。
3)image-Tag-interaction encoder 的文本输入是label 解析的Tag,不是模型的输出(推理时是模型的输出)
4)训练过程的某个节点(论文没有详细说)使用了CLIP image encoder 的输出进行蒸馏(distill)RAM 自己的image encoder。(这个我的理解是潜在对齐了CLIP Text encoder ,才更好的实现了后面推理阶段的open set 的识别。)
个人觉得比较重要是CLIP引用的蒸馏方式。
四、Inject Semantic Concepts into Image Tagging for Open-Set Recognition
1、摘要
在这篇论文中,我们引入了RAM++模型,一个在open-set很强能力的图像识别模型,该方法引入semantic concepts到图像tag中去训练的框架。对比先前方法要么是image tagging模块受有限语义制约,要么视觉语言模型浅交互在multi-tag识别中获得次优性能。相比与RAM++模型,该方法基于image-tags-text triplets整合图像文本校准与图像taging为统一细粒度交互框架。这种设计使RAM++能识别定义类,更重要是有识别open-set类的能力。RAM++利用LLMS生成多样可视的tag描述,首创使用LLM知识融合到图像 tagging训练中。在open-set识别中整合视觉藐视concepts进行推理。实验在多个图像识别基准中表明了RAM++图像识别方面取得了SOTA。

2、背景/引言
图像识别已经是研究者长期研究领域,使机器从被给图像中自动识别语义内容输出。随着自然语言过程[3,36]和图像定位[21,26]等领域基础模型的出现,构建图像识别基础模型具有重要意义,一个图像识别基准应该有更强的泛化能力,能在任意视觉概念数据中有效.
image recognition有2种研究方向:
image tagging是大家熟知的多标签识别,该方法主要依赖有标注的数据,而受数据限制,模型结果也都在特定数据与特定类表现很好;
vision-language是视觉语言模型,该方法基于大量图像文本对实现图像文本校准,其代表文章为CLIP,该文章有很强open-set能力,也能在其它领域泛化,如open-set object detection [15], image segmentation [15] and video tasks [32]
尽管CLIP在一图单标签的zero-shot效果显著,但是它的视觉语言交互是粗糙的使用点乘获得相关性,这样方式很困难处理更多现实细粒度image tagging tasks。近期RAM构建自动在图像文本对中获得tag方式,构建了综合的标签系统over 4500类,提取图像tag 标注。基于更细粒度image tagging模型框架,与CLIP对比,ram在识别tag中证明提升很大。
然而,ram缺陷是不能识别超过预定的类别,这就因固定类中限制其ram语义生成能力(只能固定提取),结果也限制RAM模型隐藏更多能力,举个列子,系统标签只有恐龙标签,模型最多只知道子标签霸王龙或三角龙。更多丰富语义如摔倒人等受到挑战。为解决这样限制问题,我们引用语义概念到图像tagging中。具体的,我们将提出2个方法, Image-Text Alignment and LLM-Based Tag Description.
Image-Text Alignment :图像文本对齐,我们设计兼备CLIP与RAM优势,整合到image tagging结构中。这种设计能使模型在训练期间学习超过固定类限制的更广问题语义信息。这个对齐架构是基于细粒度视觉语言特征交互,结合online/offline设置,我们的模型能更好平衡效率与性能。
LLM-Based Tag Description:对于LLM-Based Tag Description,近期研究利用LLM增强识别模型。基于此,我们也将LLM知识整合到image tagging训练。特别地,我们采用LLM为每个tag类自动生成丰富的视觉描述,并与tag合并成embedding去与图像特征对齐。这样方法进一步引入丰富语义信息到模型中,在推理期间合并视觉概念到开放词汇任务。除此之外,我们对tag类别的多视觉描述设计了自动权重re-weighting机制,在没有额外消耗下进一步增强性能。
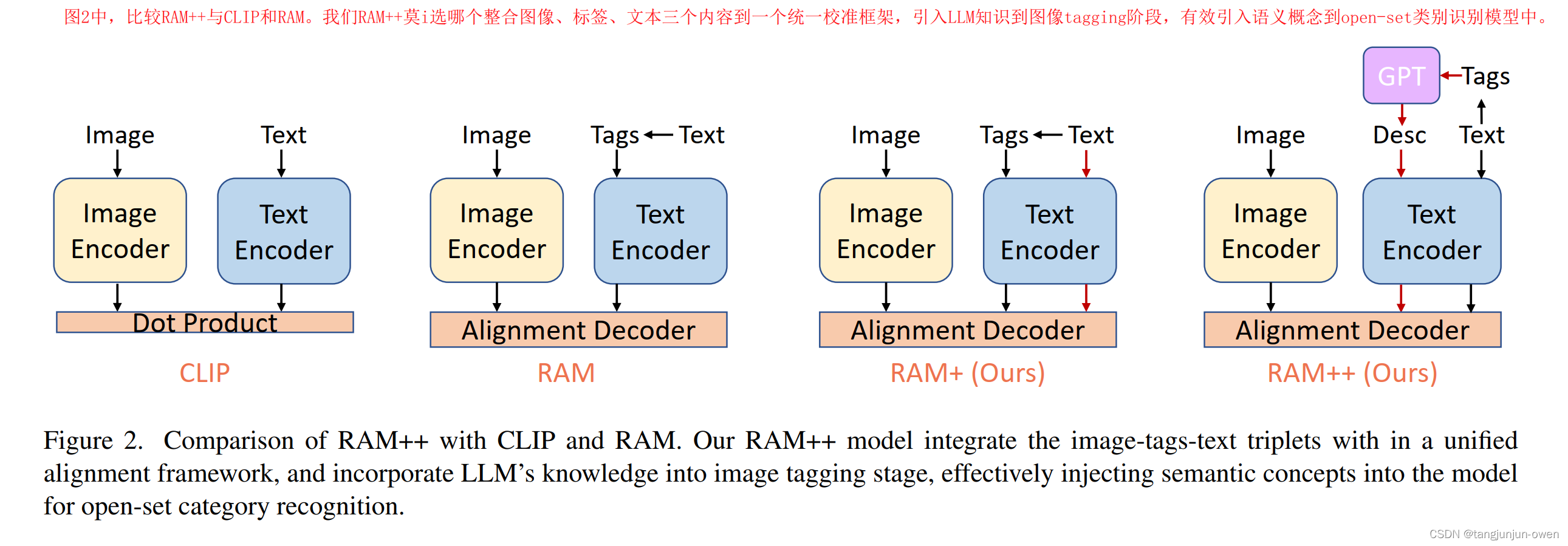
3、CLIP-RAM-RAM++模型结构对比
图2中,比较RAM++与CLIP和RAM。我们RAM++莫i选哪个整合图像、标签、文本三个内容到一个统一校准框架,引入LLM知识到图像tagging阶段,有效引入语义概念到open-set类别识别模型中。
4、贡献
1、我们整合image-tags-texts信息统一到aligment架构中,这种方式不仅在预定义tag类别更好work,还在open-set类别中也work。
2、据我们所知,我们研究是第一个将LLM模型知识整合到image tagging任务中,让模型在推理期间能整合open-set类别识别的视觉描述concept(利用llm获得概念就可在图像中识别未知类)。
3、作者又是一大堆benchmark实验,证明模型有效与sota。
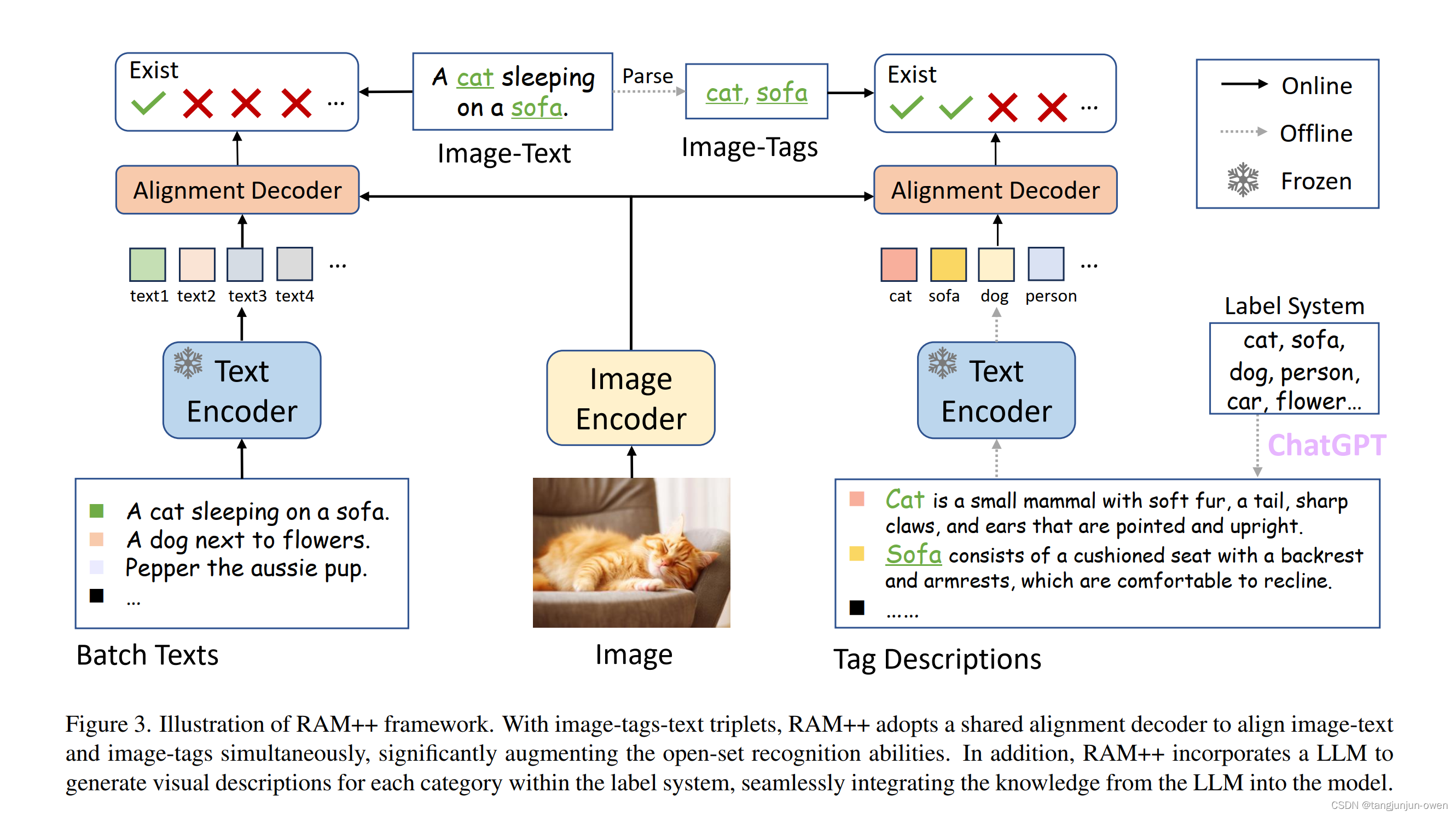
5、模型结构解读
还是三个信息内容图像image、标签tags、文本text内容,RAM++采用共享alignment decode去校准图像文本(左边)与图像标签(右边),这样能显著增强open-set识别能力。除此之外RAM++整合LLM模型为每个类别生成视觉描述,将LLM的知识整合到模型中。而这篇文章最大特点是引入LLM模型,这样就有更多的语义描述信息,具体如下:
总结
第一篇是标签定位内容;
第二篇是tag引入模型;
第三篇是修改模型架构与数据制作方式;
第四篇是在第三篇基础上引入LLM模型与共享align decode结构;

