
热门标签
热门文章
- 1Kmeans和谱聚类算法(python实现sklearn)_kmeans python sklearn
- 2颜色的十六进制编码_荧光黄十六进制
- 3HarmonyOS应用开发者高级认证--96分
- 4Vision-Language Models for Vision Tasks: A Survey
- 5分布式关系数据库中间件swiftdb (类似mycat、cobar中间件)_swift中间件
- 635岁程序员的职业分水岭:挑战还是机遇?
- 7机器学习的特征选择方法
- 8谈谈甲方视角下网络安全产品及安全建设_甲方安全产品运营
- 9宝塔快速反代openai官方的API接口,实现国内调用open ai_openai反向代理
- 10数据分析三件客 numpy,pandas,matplotlib的简单介绍-numpy模块_numpy、pandas、matplotlib
当前位置: article > 正文
人工智能基础部分15-自然语言处理中的数据处理上采样、下采样、负采样是什么?_文本 下采样的区别
作者:Gausst松鼠会 | 2024-04-01 13:51:25
赞
踩
文本 下采样的区别
大家好,我是微学AI,今天给大家介绍一下人工智能基础部分15-自然语言处理中的数据处理上采样、下采样、负采样是什么?在自然语言处理中,上采样、下采样、负采样都是用于处理数据不平衡问题的技术,目的是为了优化模型的训练效果和训练速度。
一、负采样(Negative Sampling)
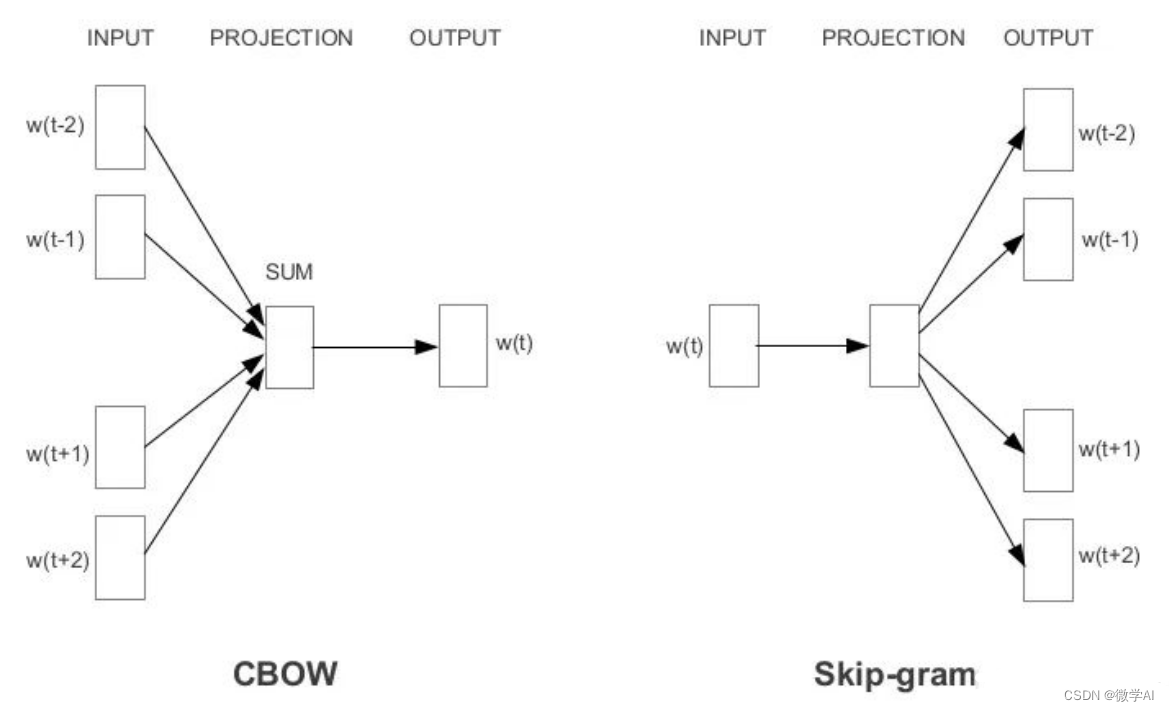
负采样是一种针对skip-gram、CBOW向量模型的优化技术,用于提高训练速度和效果。skip-gram是已知一个词去预测上下文。
Skip-Gram模型:以一个词作为输入,尝试预测上下文的词。
CBOW模型:以一组词(上下文词)作为输入,预测其中一个中心词的出现概率。
在Word2Vec模型中,负采样可以有效地解决softmax计算时的速度问题。负采样的基本思想是对于每个正样本,随机从词典中选择若干个负面样本,使得它们的概率尽可能地小。这样可以加速模型训练过程,同时还可以避免训练过程中出现梯度爆炸和消失的问题。
具体来说,对于每个正样本(即一个单词及其上下文环境),我们从整个词汇表中随机抽取若干个负样本,并将它们作为上下文预测词的负例。这样,我们只需要计算少量的正负样本的概率,就可以更新模型参数。这样既可以减少计算时间,同时也能够使得模型更加关注那些重要的词汇。
二、上采样(Upsampling)
在自然语言处理中&#x
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/349063
推荐阅读
相关标签

