
- 1华为鸿蒙os手机系统下载,华为鸿蒙2.0还原EMUI11系统
- 2数据本地性如何助力企业在云上实现高效机器学习
- 31+x2022年9月16日单选题答案_在使用命令上传一个glance镜像到openstack平台的时候,需要配置镜像格式为qcow2,使
- 4杰理之定时器【篇】_杰理软件定时器
- 5mysql zerofill_请问mysql 中的ZEROFILL是什么意思
- 6分享一次查找GfxDriver内存暴涨的经历_gfx dev
- 7Android Studio 实现桌面小组件(APPWidget)_android studio不显示组件
- 8Element-ui树形控件添加虚线_element ui tree 虚线
- 9The full stack trace of the root cause is available in the server logs.
- 10mysql种default约束的语句_sql语句大全之SQL DEFAULT 约束
【Batch_size 与 梯度 之间的关系】_batch_size对梯度的影响
赞
踩
chatGPT 回答
梯度更新与批大小(batch size)之间有密切的关系。批大小是指在训练过程中一次迭代所使用的样本数量。
在深度学习中,梯度下降是一种常用的优化算法,用于更新模型参数以最小化损失函数。梯度是损失函数对于模型参数的偏导数,它表示了参数变化对于损失函数的影响方向和程度。在每一次梯度更新中,模型的参数会根据梯度的信息进行调整。
批大小对梯度更新有以下影响:
计算效率:较大的批大小可以利用并行计算的优势,提高计算效率。通过在一个批次中同时计算多个样本的梯度,可以减少梯度计算的总时间。这对于大型数据集和复杂模型特别有用。
梯度估计的准确性:较小的批大小可以提供对梯度的更准确的估计。当批大小较小时,每个批次中的样本更具代表性,更能够反映整个数据集的分布。这有助于更准确地估计梯度,避免局部最优和过拟合。
学习速度和收敛性:较大的批大小可能导致更快的学习速度,但可能陷入较差的局部最优。较小的批大小可能导致更慢的学习速度,但在某些情况下可能有助于更好的收敛性和泛化能力。
需要注意的是,选择合适的批大小是一个权衡问题,取决于数据集的规模、模型的复杂性、计算资源的可用性以及特定任务的需求。通常,研究人员和从业者会通过实验和调整来确定最佳的批大小。常见的批大小取值范围是几十到几百个样本。
知乎链接: 深度学习(1)----Batch_size 对模型训练的影响
总结
batch_size是有一个阙值的,一旦超过这个阙值,模型性能就会退化。通俗解释一下,大的batch_size本质上是对训练数据更优的一种选择,但是同时也会限制模型的探索能力,模型训练的时候极易陷入这种很尖的极小值很难跳脱出来,但是相对小一些的batch_size就很容易能检索到一个非常好的极小值点。
原文阐述
如果要探究batch_size对模型训练的影响,首先要了解一下深度学习的三种梯度下降框架:
- BGD Batch gradient descent 全量梯度下降
- SGD Stochastic gradient descent 随机梯度下降
- MBGD Mini-batch gradient descent 小批量梯度下降
1. BGD
全量梯度下降BGD是最原始的梯度下降算法,每次都使用全部的训练集样本来更新模型参数,公式如下:
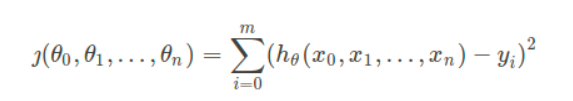
求得loss之后,对所有的参数进行更新:
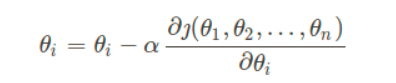
如下格式:
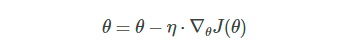
取全量的数据进行梯度更新的方式,每次参数更新都会超着正确的方向进行,对于凸函数来说,可以达到全局最优解,对于非凸函数来说,也可以达到局部最优解。缺点显而易见,全量更新比较缓慢,如果数据集很大,loss的存储和最后全量loss进行的梯度更新回消耗大量的内存。
2. SGD
随机梯度下降SGD每次都会随机选择一个样本梯度更新:
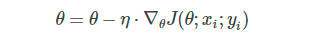
优点是对于非凸函数来说,可能会从当前的局部最小值中跳脱出来,找到更好的极小值点。但是最大的问题是每次更新可能不会按照正确的方向进行,模型训练非常的震荡。
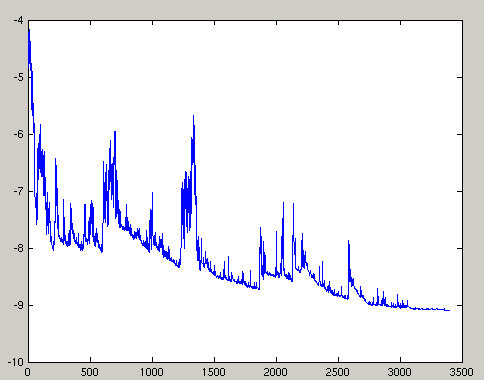
并且实验表明,SGD甚至可能根本不会收敛
3. MBGD
小批量梯度下降法 mini-batch gradient descent,其实就是综合了BGD和SGD,在更新速度和更新次数之间找到一个平衡,每次更新从训练集中随机选择m个样本进行学习:
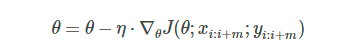
这就是现在一直使用的方法,小批量梯度下降降低了收敛的波动性,即降低了参数更新的方差,更新更加的平缓稳定,并且batch数据可以并行化计算,相当于兼顾了速度和效果。
我们要探究batch_size对模型的影响,从参数更新的公式可以看出,模型性能受学习率的影响是最大的,其次是batch_size的大小。可以归纳的一点是,比较大的batch_size进行梯度更新模型训练会更加平滑,最后模型也相对于小batch_size有更优秀的模型性能。
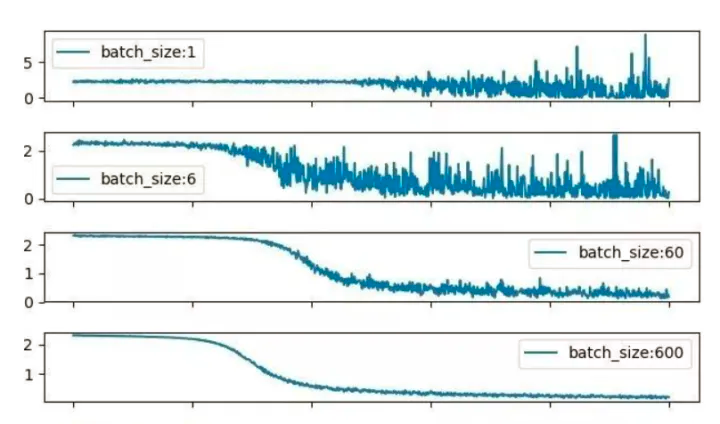
那么是不是batch_size越大越好呢?
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
https://arxiv.org/pdf/1706.02677
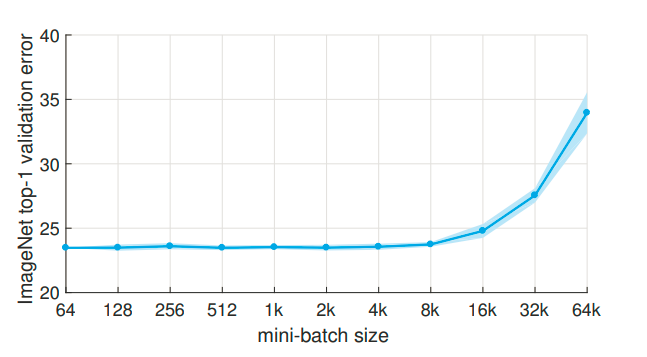
增加batch_size是有利于收敛的稳定性,但是当batch_size特别大的时候,模型的性能会急剧下降,为什么?这其实很反直觉,因为BGD就告诉我们了,batch_size越大,梯度更新的方向也就越准确,性能肯定会提高。
On large-batch training for deep learning: Generalization gap and sharp minima
https://openreview.net/pdf?id=H1oyRlYgg
论文发现,用很大的batch_size训练模型,模型训练和测试会收敛到一个很尖的极小值,相反小的Batch却能够使模型收敛在一个较为平稳的极小值。即大Batch方法训练时候更容易收敛到sharp minima(尖锐极小值),而小Batch的方法则更容易收敛到flat minima(平滑极小值),并且大 Batch 方法不容易从这些 sharp minima (尖锐极小值) 的 basins 中出来。
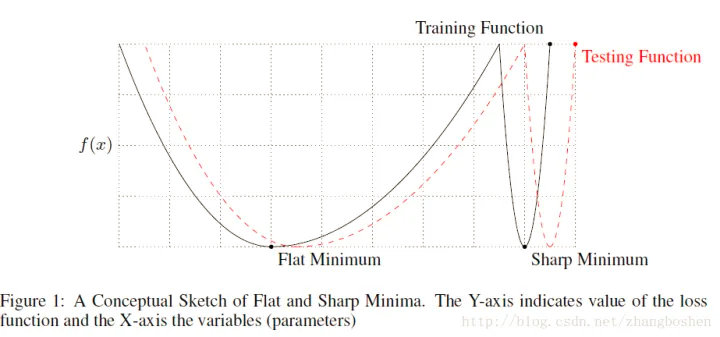
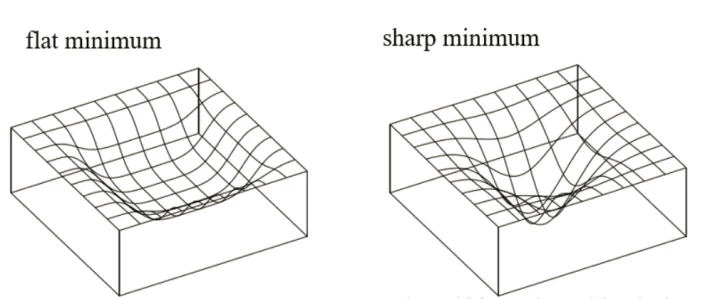
为什么LB(Large batch size)为何不如SB(Small batch size)的原因猜测:
- LB过度拟合模型
- LB更容易陷入鞍点
- LB缺少SB的随机探索性,更依赖于初始值,容易陷入初始点周围的最小值,而SB可以探索到离初始点更远的最小值
- LB和SB收敛到具有不同泛化特性的最小化点
因此,batch_size是有一个阙值的,一旦超过这个阙值,模型性能就会退化。通俗解释一下,大的batch_size本质上是对训练数据更优的一种选择,但是同时也会限制模型的探索能力,模型训练的时候极易陷入这种很尖的极小值很难跳脱出来,但是相对小一些的batch_size就很容易能检索到一个非常好的极小值点。
再继续类比一下,如果要兼顾事业和家庭,就相当于事业、家庭的大量相关数据进行模型训练,让你自己能够更好的拟合这些数据,但是因为数据太多,要尽量拟合这些数据就会让你更倾向于跳到一个比较舒服的局部最优解里面出不来;但是如果你刚开始只是要考虑事业,你可以不断的进行选择找到比较多的局部最优解,因为跳脱出每一个最优解的代价都不会很大,因为batch数据比较少,loss比较小,带来的阻力不会很大。
当然,作者也提出了解决方案:利用SB先训练一定的轮数,让模型远离初始点附近的sharpness点,然后再换成LB接着训练,可以收敛至sharpness较小的点,并且可以提升测试精度。
回到现实,在真实的场景中实际上还是batch_size越大越好,毕竟论文做实验验证使用的batch_size都是几十K的数量级,在实际场景中因为显存的限制,batch_size根本不会达到这么大。
还有一点特别在实际应用中,如果训练样本越不均衡,batch_size越大对分类的结果影响也越大。

