
- 1基于python+django+vue搭建的旅游景区管理系统 - 毕业设计 - 课程设计_毕业设计:基于python+django+vue搭建的旅游景区管理系统.zip
- 2python文本特征提取_机器学习入门之机器学习之路:python 文本特征提取 CountVectorizer, TfidfVectorizer...
- 3语音算法笔记(5)——语音识别应用系统的搭建_tlg 算法理论 工具搭建hclg / tlg
- 4【小白也可做】基于1DCNN的单特征输入的股票预测项目实战(pytorch)(单特征)——仅用于课程和编程学习,不作为任何金融推荐!!!!_1dcnn pytorch
- 5网络训练时使用不同学习率策略(Poly)以及学习率是如何计算_poly learning rate
- 6yolov5 TensorRT 模型转换/量化加速/视频推理_tensorrt加速视频
- 7【深度学习】深度学习框架PyTorch的简单入门了解(未完待更)_pytorch语言二维矩阵第一列是均匀点
- 8使用langchain与你自己的数据对话(二):向量存储与嵌入_langchain chat with your data
- 9论文理解:“Designing and training of a dual CNN for image denoising“
- 10mysql 的字符集、比较规则和服务端、客户端的相关配置_mysql服务端和客户端的编码
AI带火的向量数据库到底是什么?_向量数据库和英伟达合作
赞
踩
大家好,我是风筝,微信搜「古时的风筝」,更多干货
最近有朋友面试的时候被面试官问了有关向量数据库的问题,朋友说啥是向量数据库,咋没听过呢。
最近 ChatGPT 以及类似的 AI 产品大火,不仅带火了英伟达的 GPU 芯片,也带火了向量数据库。
其实向量数据库吧,很早就之前就有了,而且很多公司也在用,只不过最近借着AI的东风,被推到了台前,比如 Pinecone 这家向量数据库公司,估值约为 10 亿美元,刚刚融资 1 亿美元。
再比如,这个…

什么是向量和向量化
向量数据库,顾名思义,存储的内容是向量。
那什么又是向量呢?
我们最早接触向量应该是在数学里面,例如一个二维的向量用(x,y)表示在x轴和y轴的值,用(x,y,z)表是在x轴、y轴和z轴的三维向量。还可以有更多的维度表示多维向量。
向量数据库应用最多的场景就是相似度搜索,就是根据用户的一个输入匹配出几个相似度最高的结果。有点儿像模糊查询或者全文检索的意思,但是原理又不一样,全文检索的核心技术应该是分词+索引 ,而向量数据库是向量化(Embedding)+索引。
索引就不用多说了,只要涉及到存储的,一定会用到索引。
向量化(Embedding)
在 OpenAI 官网上专门有 Embedding 的介绍,并且提供了相关的模型API,叫做 ada,专门将数据 Embedding。
Embedding 是用一个低维稠密向量来表示一个对象,使得这个向量能够表达相应对象的某些特征,同时向量之间的距离能反应对象之间的相似性。
Embedding 是一个多维向量数组,由一系列数字组成,通过相关的算法可以将文本、音频、视频等内容转换为多维向量数组,并最终存储到向量数据库中。
假设 man的向量数组可表示为 [0.1,0.2,0.1],woman的向量数组可表示为[0.3,0.1,0.1]。
下图中可以看到这些多维向量在向量空间中的关系,man和woman之间、king和queen之间,China和Beijing之间。
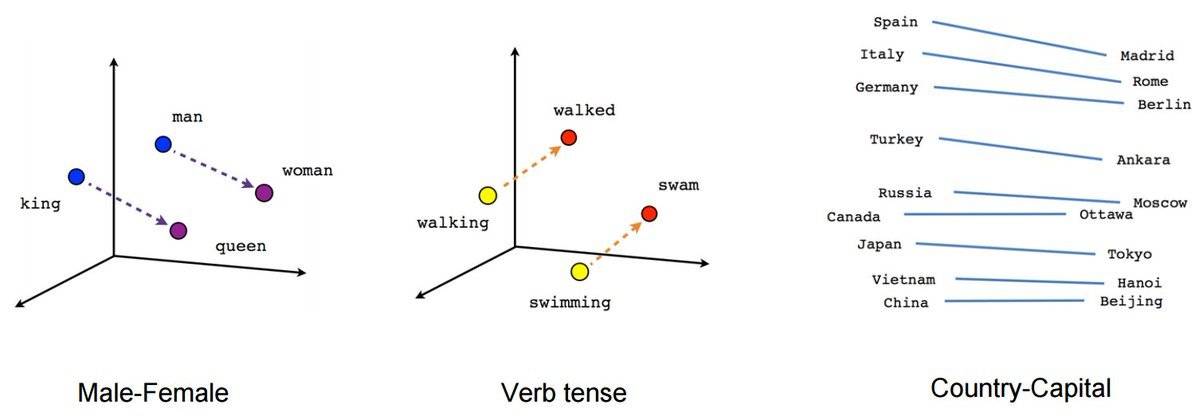
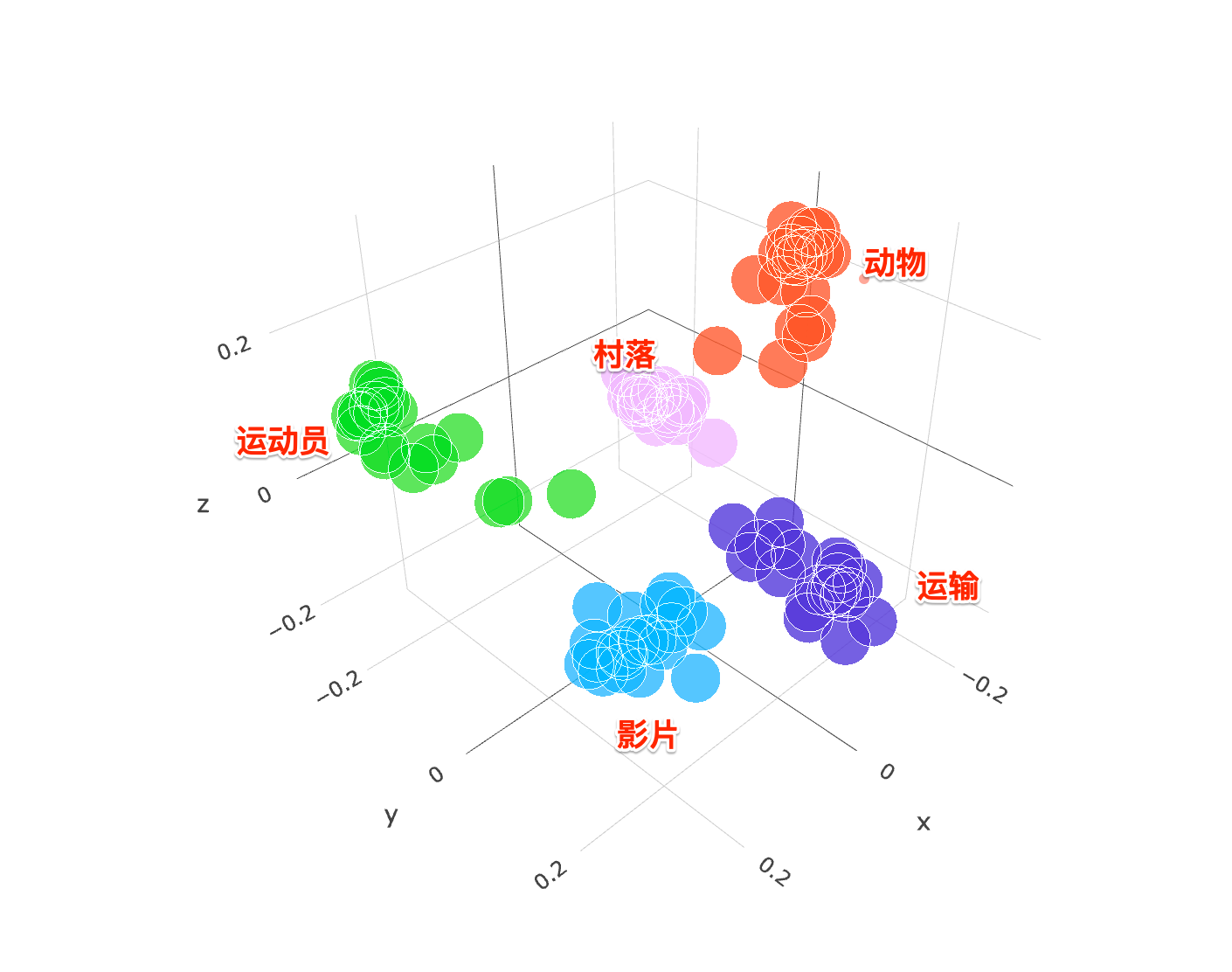
各种各样的内容进行向量化之后,最终在向量空间会形成或近或疏的关系。比如下面这幅图中可以看出,如果你搜索一个动物相关的内容,肯定(大概率)不会匹配到运动员的那一堆数据中。
向量化的过程是一个复杂的过程,通常会用到经过大量训练和优化的大模型以及神经网络等厉害的技术,所以,个人或普通公司只能用大厂提供的付费服务,例如OpenAI 的 Ada 模型。
为什么这么复杂呢,比如基于自然语言处理的方式向量化,不仅要分析文本本身的意思,还会包括情感分析、翻译等工作要处理,例如你搜索英文的 apple,也要能匹配上中文的苹果或其他的语种。还有如果你搜索苹果太难吃了,要不能匹配出苹果太棒了这种结果吧。
目前主流的Embedding 方法主要有如下这三类:
矩阵分解法
矩阵分解法是一种常见的 Embedding 方法,它可以将高维的矩阵映射成两个低维矩阵的乘积,很好地解决了数据稀疏的问题。
基于自然语言处理的方法
自然语言处理(NLP)是一种人工智能技术,它涉及计算机对人类语言的理解和生成。NLP 包括许多任务,如文本分类、情感分析、命名实体识别、机器翻译和自动摘要等。NLP 技术可以帮助计算机处理和分析大量的文本数据,从而使计算机能够更好地理解人类语言并作出更准确的预测和决策。而基于 NLP 的 Embedding 方法的主要思想是将每个单词或短语映射到一个低维向量空间中,使得在这个向量空间中,相似的单词或短语在距离上更加接近,以便于支持语义查找与分析工作。常见的方法包括:
- Word2vec
- GloVe(Global Vectors for Word Representation)
- FastText
基于图的方法
上述方法都是针对序列文本而设计的,而对于诸如社交网络分析、推荐系统、知识图谱等领域中的问题,如下图所示,数据对象之间更多呈现出图结构:
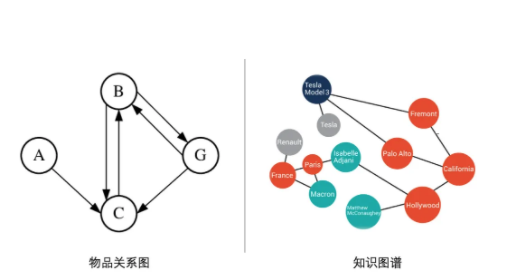
基于图的 Embedding 技术是一种将图数据(通常为高维稠密的矩阵)映射为低微稠密向量的过程,能够很好地解决图数据难以高效输入机器学习算法的问题。Graph Embedding 技术将图中的节点以低维稠密向量的形式进行表达,要求在原始图中相似 (不同的方法对相似的定义不同) 的节点其在低维表达空间也接近。常见的方法包括:
- DeepWalk
- Node2vec
- Metapath2vec
向量数据库的特点
向量数据库的应用场景决定了其大概率需要存储海量的数据,而不是想关系型数据库那样存储确定的多少条数据。
- 向量数据库要具具有高可用、高扩展性的架构;
- 向量数据库是计算密集型应用,需要良好的硬件设备加速;
- 高并发、低延迟
应用场景
向量数据库的核心功能就是相似性匹配,所以,它的应用场景也是围绕着这个功能来的。
- 文本搜索(包含语义的那种),最常见的功能;
- 图片、语音、视频搜索,例如那种以图搜图的功能,当然,与之匹配的向量化的过程也比文字更复杂,例如语音的向量化要包括对语音进行特征化的提取,比如声纹等等。歌曲识别(非歌词的那种)就可以用向量化和向量数据库;
- 推荐系统,根据系统给用户打的标签,给用户推荐相似度最高的商品、服务等;
- 异常检测,相似度过低可以判断为异常,例如人脸识别功能,如果相似度过低,那可能就是非本人;
最近的AI热潮掀起了不少新技术,感觉快要学不过来,不过大多数的内容想学也学不会了,只能学学周边技术,用用人家的API了。
毕竟像OpenAI这种,里面的员工的职位都是xxx科学家,不是xxx工程师了。
但是,该关注还是要关注一下,说不好哪天就用到自己的产品里了。
不如点个赞

推荐阅读

