
- 1Android N Audio: Audio Track play_audio_port_type_t
- 2运动学逆解(四足机器狗)
- 3深入理解Elasticsearch_es原理及实现
- 4【Flutter从入门到实战】 ⑤、Flutter的StatelessWidget案例-列表展示、StatefulWidget 案例 - 加减操作、 Flutter的Widget生命周期_flutter加减控件
- 5服务及进程介绍及使用_fcontext
- 6[附源码]计算机毕业设计Python+uniapp基于小程序制作的剧本杀预约系统j3ast(程序+lw+远程部署)_剧本策划系统软件设计
- 7Python:利用邻接矩阵判断有向图的连通性_根据邻接矩阵判断连通
- 8Ajax之原生请求---XMLHttpRequest对象的使用(超详细)
- 9Conv1d参数与输入数据均无nan,结果出现nan的问题解决_conv1卷积操作出现nan
- 10Android之系统属性(SystemProperties)_android.os.systemproperties
jetson nano(B01)配置pytorch和torchvision环境+tensorrtx模型转换+Deepstream部署yolov5(亲测可用)_nvdsinfer_custom_impl_yolo
赞
踩
jetson nano 配置pytorch和torchvision环境+tensorrt模型转换+Deepstream部署yolov5(亲测可用)
前言
因为一次比赛接触到了jetson nano,需要使用pycharm训练自己的模型加上yolov5进行目标检测,并部署到jetson nano上,直到比赛结束也没有搞出来,后来jetson nano开始吃灰,后来因为大创需要重新开始了我的yolov5部署之路。网上资料断断续续,不是太清晰,也有太多的坑和bug,在环境配置中跌跌撞撞好几天,最后实现了目标检测,因为踩了太多的坑,于是决定写下这篇博客记录我与jetson nano和yolov5的相爱相杀。
此篇文章并不是我的原创,是我结合csdn上许多优秀博主的github上的一些优秀资源写下来的。链接我放在了最后,再次感谢这些博主给予的帮助。
以下是本篇文章正文内容,希望可以帮助大家顺利打开Yolov5的大门。
yolov5是什么?
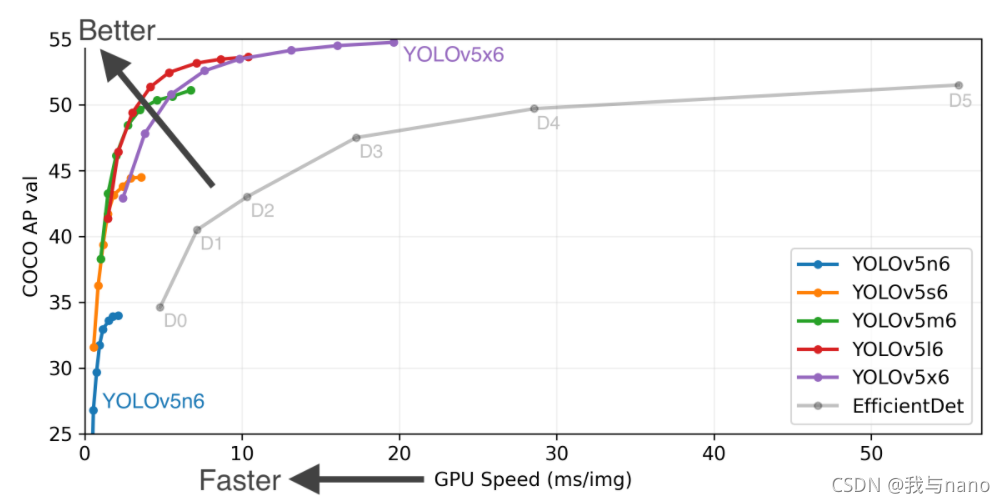
YOLO之父Joseph Redmon在今年年初宣布退出计算机视觉的研究的时候,很多人都以为目标检测神器YOLO系列就此终结。
然而在4月23日,继任者YOLO V4却悄无声息地来了。Alexey Bochkovskiy发表了一篇名为YOLOV4: Optimal Speed and Accuracy of Object Detection的文章。
YOLO V4是YOLO系列一个重大的更新,其在COCO数据集上的平均精度(AP)和帧率精度(FPS)分别提高了10% 和12%,并得到了Joseph Redmon的官方认可,被认为是当前最强的实时对象检测模型之一。
正当计算机视觉的从业者们正在努力研究YOLO V4的时候,万万没想到,有牛人不服。
6月25日,Ultralytics发布了YOLOV5 的第一个正式版本,其性能与YOLO V4不相伯仲,同样也是现今最先进的对象检测技术,并在推理速度上是目前最强。
环境
1.所需硬件
jetson nano B01 4G
USB摄像头
电脑显示屏
2.软件环境
jetson nano下:
Jetpack 4.5.1
Deepstream 5.1
windows
接下来我们进入正文:
**
步骤
一、烧录Jetpack 4.5.1镜像
1.英伟达官网下载地址:
https://developer.nvidia.com/embedded/dlc/jetson-nano-dev-kit-sd-card-image
有些同学下载较慢,在此附上本人百度网盘链接:
链接:https://pan.baidu.com/s/1RNw8x6PCM-WdwNFhfgLRuA
提取码:sml9
2.烧录准备
在漫长的下载等待中,我们首先格式化内存卡,这里我使用的软件是SDFormatter
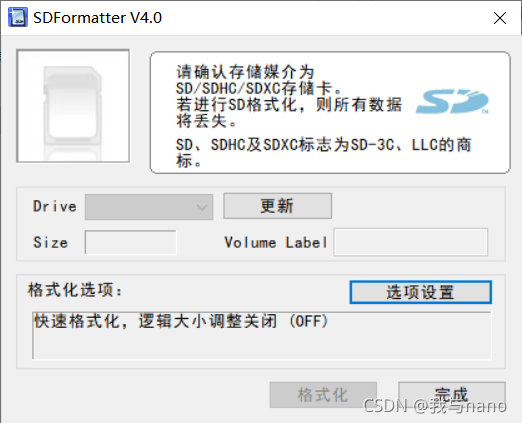
格式化之后一定要弹出U盘,在进行烧录,不要直接烧录(亲自踩坑!!)
烧录软件使用的是win32Disk
在此附上以上两个软件的百度网盘链接:
win32Disk:
链接:https://pan.baidu.com/s/1uG8AnHu4XgOqTLLVulEhpg
提取码:gknk
SDFormatte:
链接:https://pan.baidu.com/s/1irK8jni9cE6E0meXJv_VYg
提取码:rw44
烧录完成后连接显示屏,进行一些基础的配置,配置完成后,开机。
**
二、安装Deepstream 5.1
本人踩了很多坑,Deepstream官网下载非常慢,需要翻墙下载。在此我也附上百度网盘链接:
下载又是一个非常缓慢的过程…
我们先配置安装Deepstream所需要的环境
1.安装环境
$ sudo apt install \
libssl1.0.0 \
libgstreamer1.0-0 \
gstreamer1.0-tools \
gstreamer1.0-plugins-good \
gstreamer1.0-plugins-bad \
gstreamer1.0-plugins-ugly \
gstreamer1.0-libav \
libgstrtspserver-1.0-0 \
libjansson4=2.11-1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.输入以下命令以提取并安装DeepStream SDK:
sudo tar -xvf deepstream_sdk_v5.1.0_jetson.tbz2 -C /
cd /opt/nvidia/deepstream/deepstream-5.1
sudo ./install.sh
sudo ldconfig
- 1
- 2
- 3
- 4
提取时一定要使用如上代码,不要将opt文件放在home目录下(后续许多环境会出错),本人亲自踩坑
**
三、安装torch环境
**
1.安装pytorch1.8.0和torchvision0.9.0(切记不要随意安装版本,版本一定要对应)
安装pytorch
wget https://nvidia.box.com/shared/static/p57jwntv436lfrd78inwl7iml6p13fzh.whl -O torch-1.8.0-cp36-cp36m-linux_aarch64.whl
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
pip3 install Cython
pip3 install numpy torch-1.8.0-cp36-cp36m-linux_aarch64.whl
- 1
- 2
- 3
- 4
安装torchvision0.9.0
sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libavcodec-dev libavformat-dev libswscale-dev
git clone --branch v0.9.0 https://github.com/pytorch/vision torchvision
cd torchvision
export BUILD_VERSION=0.9.0
python3 setup.py install --user
- 1
- 2
- 3
- 4
- 5
**
四、将Pytorch模型转化为wts文件
**
1.克隆yolov5-4.0文件和tensorrtx文件(我这里使用的是yolov5-4.0,其他版本转换模型时可能会出错)
git clone -b yolov5-v4.0 https://github.com/wang-xinyu/tensorrtx.git
git clone -b v4.0 https://github.com/ultralytics/yolov5.git
- 1
- 2
2.下载最新的yolov5s.pt到yolov5目录下
wget https://github.com/ultralytics/yolov5/releases/download/v4.0/yolov5s.pt -P yolov5/weights
- 1
3.将tensorrtx文件下的gen_wts.py文件复制到yolov5文件夹里
cp tensorrtx/yolov5/gen_wts.py yolov5/gen_wts.py
- 1
4.生成yolov5s.wts文件
cd yolov5
python3 gen_wts.py
- 1
- 2
执行完成后在yolov5文件夹下将会有yolov5s.wts文件生成
**
五、将wts文件转换为tensorrt 模型
1.在tensorrt文件下创建build文件夹
cd tensorrtx/yolov5
mkdir build
cd build
cmake ..
make
- 1
- 2
- 3
- 4
- 5
2.将生成的 yolov5s.wts 文件移动到tensorrtx下的yolov5 文件夹中
cp yolov5/yolov5s.wts tensorrtx/yolov5/build/yolov5s.wts
- 1
3.转换为 tensorrt 模型(yolov5s.wts文件将在tensorrt/yolov5/build文件夹中生成)
sudo ./yolov5 -s yolov5s.wts yolov5s.engine s
- 1
执行完成后在build文件夹下将会出现yolov5s.engine文件
4.创建自定义 yolo 文件夹并复制生成的文件(这个yolo文件夹自己创建的)
mkdir /opt/nvidia/deepstream/deepstream-5.1/sources/yolo
cp yolov5s.engine /opt/nvidia/deepstream/deepstream-5.1/sources/yolo/yolov5s.engine
- 1
- 2
如果创建不成功可以使用sudo -i进入root权限创建
**
六、编译nvdsinfer_custom_impl_Yolo文件
1.运行命令
sudo chmod -R 777 /opt/nvidia/deepstream/deepstream-5.1/sources/
- 1
这一步的意思是给文件夹赋予权限
2.将Deepstream-yolo-master下的external文件夹复制到我所创建的yolo文件下(可以使用winscp软件)
在此附上Deepstream-yolo-master的百度网盘链接:
链接:https://pan.baidu.com/s/1XfuIT33GCE3QElYg1cQu3A
提取码:ju2u
同时附上winscp下载链接:
https://winscp.net/eng/index.php
3.进行编译
cd /opt/nvidia/deepstream/deepstream-5.1/sources/yolo
CUDA_VER=10.2 make -C nvdsinfer_custom_impl_Yolo
- 1
- 2
编译成功后,恭喜你完成了所有部署。
**
七、测试模型
模型测试在自己创建的yolo文件夹下
输入
deepstream-app -c deepstream_app_config.txt
- 1
等待几分钟后出现如下图界面(第一次加载时间比较长)

八、调用usb摄像头进行检测
修改deepstream_app_config.txt文件

讲上图中source0替换为

[source0]
enable=1
#Type - 1=CameraV4L2 2=URI 3=MultiURI
type=1
camera-width=640
camera-height=480
camera-fps-n=30
camera-fps-d=1
camera-v4l2-dev-node=0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
运行
deepstream-app -c deepstream_app_config.txt
- 1
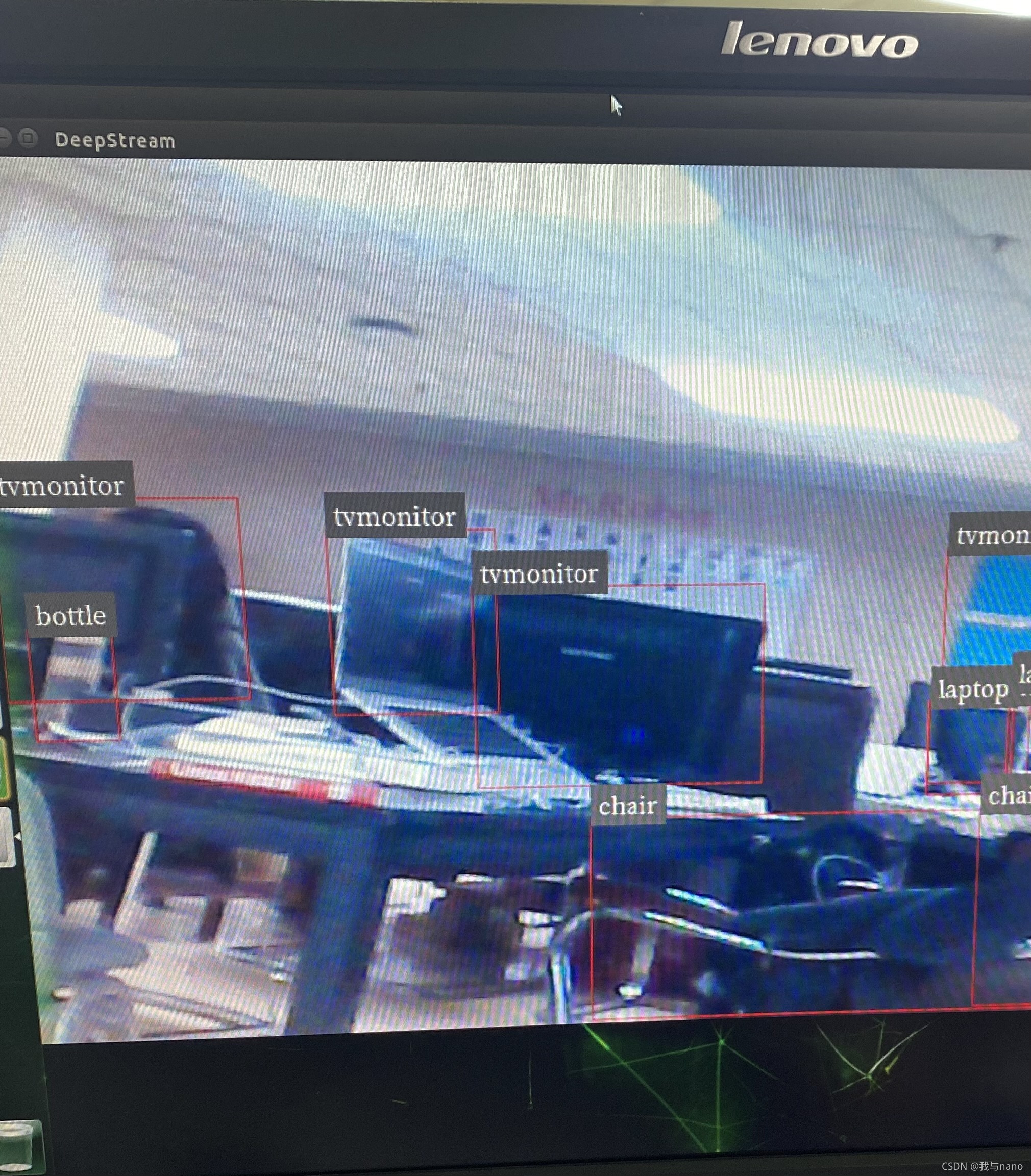
运行帧率大概只有5帧左右,查阅相关资料后发现pytorch模型转换不会优化jetson nano底层转换代码,我使用onnx模型转换做到了25帧左右,基本可以进行实时检测。优化算法稍后我会继续写一篇博客。
总结
现在是凌晨一点钟,我写下这篇博客是为了记录自己部署yolov5的经历与过程,希望在我之后部署yolov5进行目标检测的同学能够更加顺利,同时开启我的博客之路,以后我也会将自己学习到的一些东西写下一篇篇的博客记录下来。
以下附上各位优秀博主的链接,再次感谢你们。
(https://blog.csdn.net/qq_40305597)
(https://blog.csdn.net/IamYZD)

