
- 1Python sklearn模型选择_x = maxabs_scale(x, axis=1)
- 2spring 和spring boot的区别
- 3名帖212 赵孟頫 行书《秋兴赋》_赵孟頫秋兴赋
- 4Code Interpreter - AI助力代码理解
- 5图像编辑之对比度调整(亮度对比度的算法公式)_对比度算法原理
- 6爬虫 - requests + xpath 爬取猫眼电影排行榜 TOP100_爬取猫眼电影top100排行榜,电影名及评分(xpath或bs
- 7vue3简易对话窗口_vue实现一个聊天对话框
- 8聊聊CVE漏洞编号和正式公开那些事_cve reserved后
- 9Jetson Nano之ROS入门 -- YOLO目标检测与定位_jetson nano yolo
- 10科大学长对数学系学弟学妹的忠告_狄多涅现代分析基础
【NLP作业02:课程设计报告】_自然语言处理大作业课程设计
赞
踩
NLP作业02:课程设计报告
| 这个作业属于那个课程 | 自然语言处理 |
|---|---|
| 这个作业要求在哪里 | NLP作业02:课程设计报告: link |
| 我在这个课程的目标是 | 能够综合理解运行我 在这门课程中学到的内容 |
| 这个作业在哪个具体方面帮助我实现目标 | 代码构建,设计理解 |
| 参考文献 | 链接: link |
基于文本内容的垃圾短信识别
1 设计目的
通过课程设计的练习,加深学生对所学自然语言处理的理论知识与操作技能的理解和掌握,使得学生能综合运用所学理论知识和操作技能进行实际工程项目的设计开发,让学生真正体会到自然语言处理算法在实际工程项目中的具体应用方法,为今后能够独立或协助工程师进行人工智能产品的开发设计工作奠定基础。通过综合应用项目的实施,培养学生团队协作沟通能力,培养学生运用现代工具分析和解决复杂工程问题的能力;引导学生深刻理解并自觉实践职业精神和职业规范;培养学生遵纪守法、爱岗敬业、诚实守信、开拓创新的职业品格和行为习惯。
垃圾邮件内容往往是广告或者虚假信息,甚至是电脑病毒、情色、反动等不良信息,大量垃圾邮件的存在不仅会给人们带来困扰,还会造成网络资源的浪费;在机器学习领域,基于文本内容的垃圾短信识别是一个非常重要的应用。它可以应用在手机短信过滤、邮件分类等场景中,为用户提供便利和良好的体验。
2 设计要求
2.1 实验仪器及设备
(1)使用64位Windows操作系统的电脑。
(2)使用3.8.5版本的Python。
(3)使用PyCharm Community Edition编辑器。
(4) 使用 jieba, wordcloud……
2.2 设计要求
课程设计的主要环节包括课程设计作品和课程设计报告的撰写。课程设计作品的完成主要包含方案设计、计算机编程实现、作品测试几个方面。课程设计报告主要是将课程设计的理论设计内容、实现的过程及测试结果进行全面的总结,把实践内容上升到理论高度。
3.设计内容
随着网络手段的普及和盛行,垃圾短信给用户和运营商带来的困扰越来越大,甚至造成大量的经济损失,急需解决。针对这一现状,本次设计完成的项目是基于文本内容的垃圾短信识别模型,该模型将使用朴素贝叶斯和自然语言处理(NLP) 来确定是否为垃圾短信 邮件。具体实现流程下图 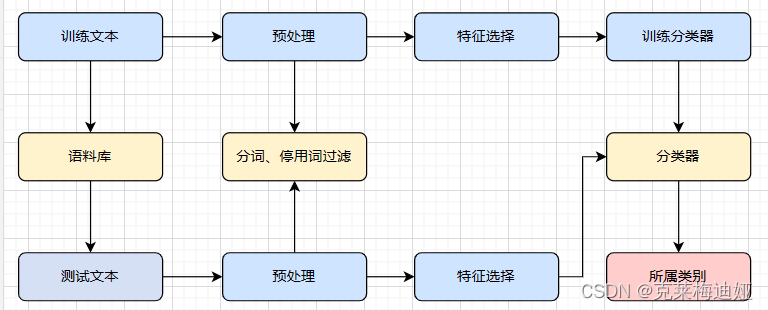
4.设计过程
#4.1.数据准备
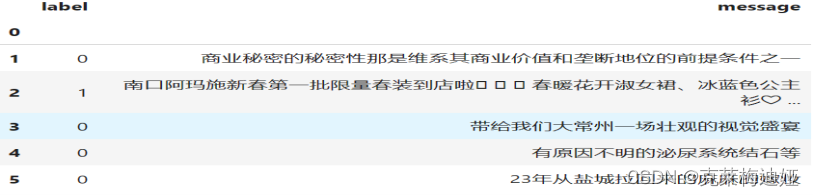
项目模块导入以及数据集导入及处理我们将使用kaggle提供的数据集:数据集
该数据集 包含一组带有标记的短信文本,这些消息被归类为正常短信和垃圾短信。


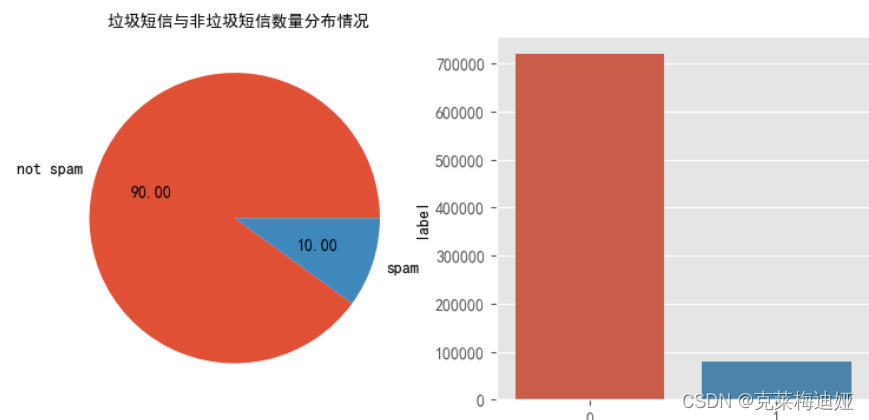
4.2数据预处理
因为短信文本中存在着各种各样的符号、字母、数字等,如果将这些特殊符号也引进分词,在词频统计甚至文本建模中,不仅会消耗计算机内存,还会造成分析结果的偏差所以得对数据进行预处理,清除掉无用的数据。
4.2.1去重
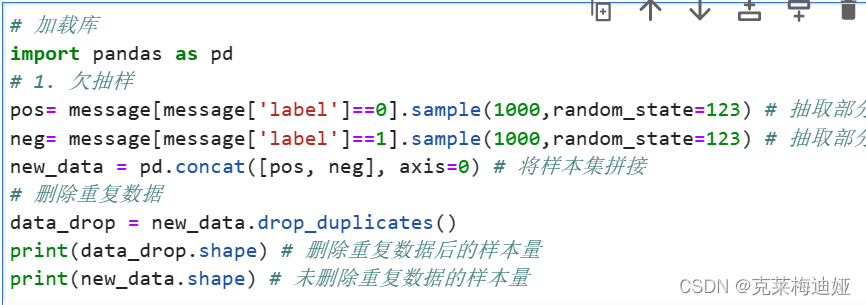


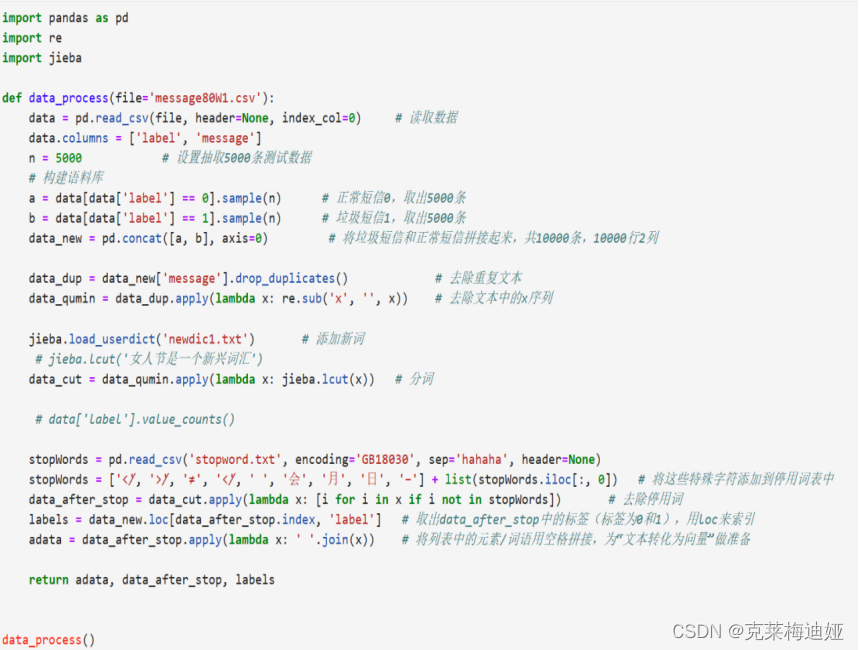
4.2.2 Jieba 中文分词
分词是文本信息处理中非常基础的步骤,它将一个单词序列分割成一个个单独的词汇。分词准确无误可以有效提高计算机对文本信息的识别和理解能力。反之,如果分词错误的话,将会带来很多噪音,干扰计算机的识别和理解能力,并对后续的信息处理工作造成严重影响。本段代码使用jieba库对数据进行中文分词。


4.2.3 去除停用词
经过jieba分词后,句子由一个字符串的形式变为多个由文字或词语组成的字符串的形式,可判断短信句子中词语是否为停用词。根据自定义的停用词库去除评论中的停用词。
4.3显示词云图
词云图是一文本结果展示工具,通过词云图的展示,可以对短信文本数据分词后的高频词予以视觉上的强调和突出效果,从而达到过滤绝大部分的低频词汇文本信息的效果,在对一系列文本数据进行预处理后,对单个词语进行词频统计,然后利用 wordcloud模块的 WordCloud绘制词云,实现垃圾短信和非垃圾短信的可视化。
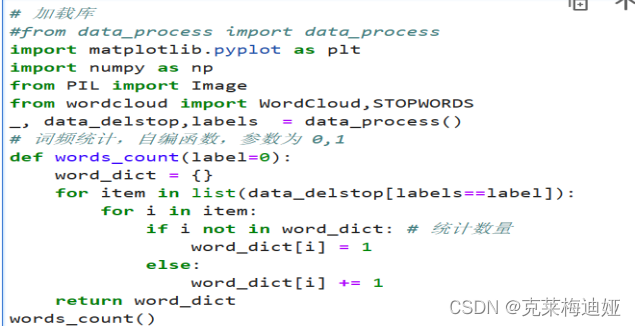

4.4模型构建
4.4.1朴素贝叶斯的介绍
在统计学中,朴素贝叶斯分类器是一系列简单的“概率分类器”,它们基于应用贝叶斯定理和特征之间的(朴素)条件独立假设。它们是最简单的贝叶斯网络模型之一,但与核密度估计相结合,它们可以达到更高的准确度水平。
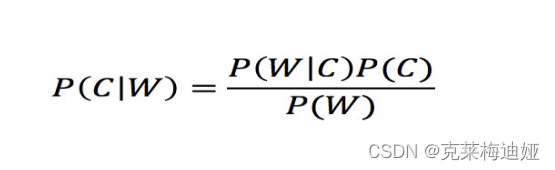



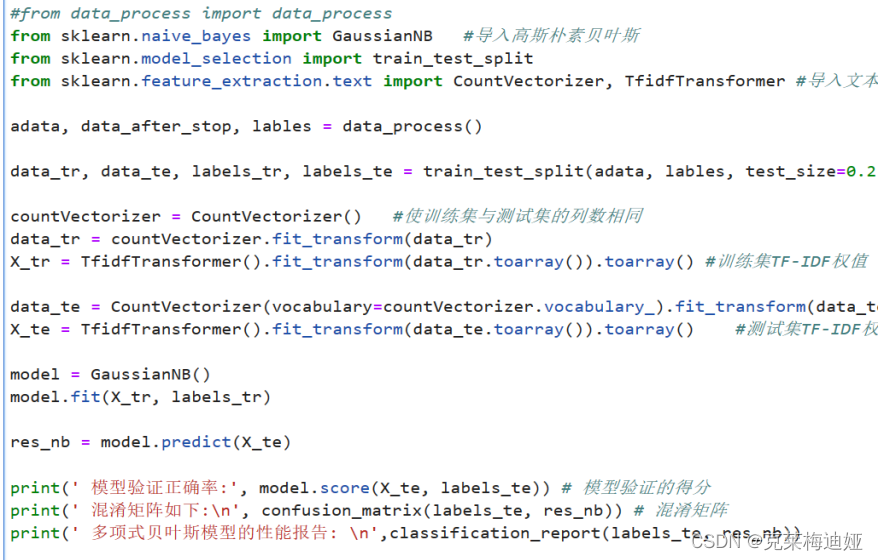
4.4.2贝叶斯分类模型构建
通过sklearn库建立贝叶斯模型,再输出模型评价指标。
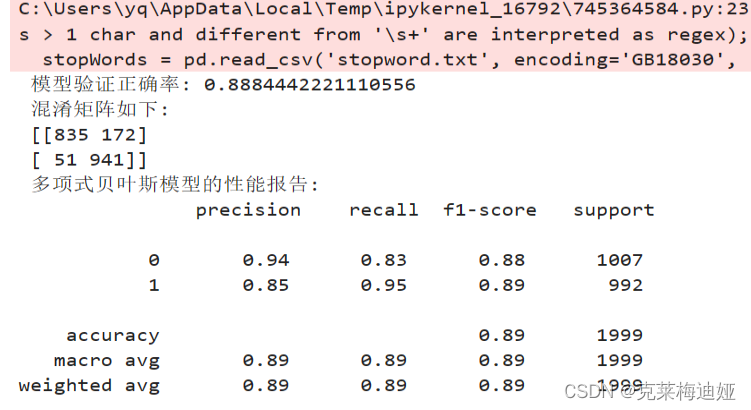
再分别比较三种不同的贝叶斯模型的各个评估指标结果
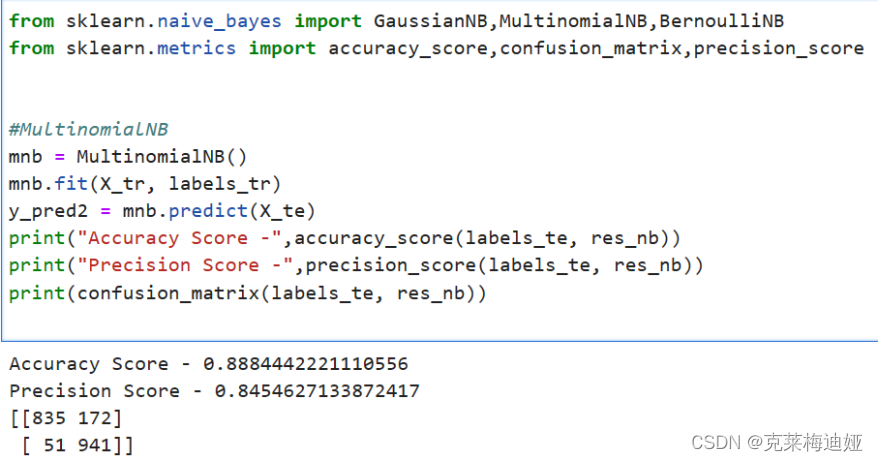
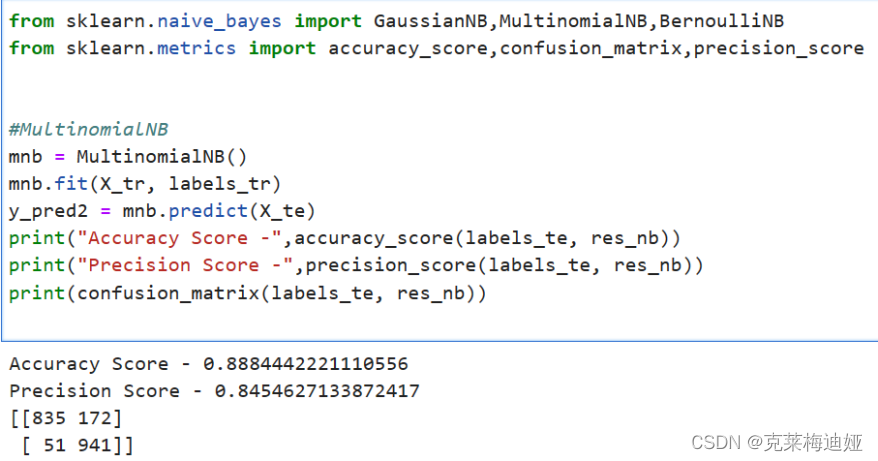
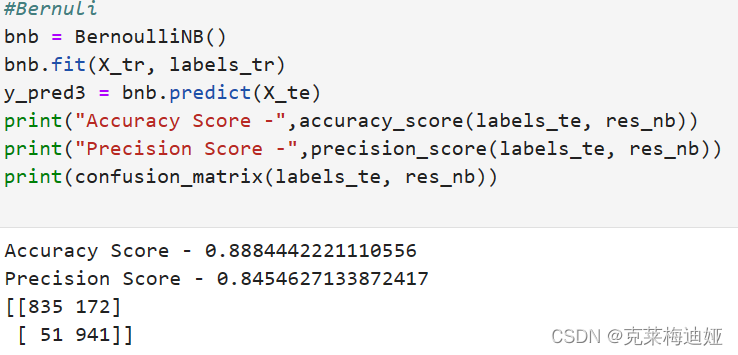
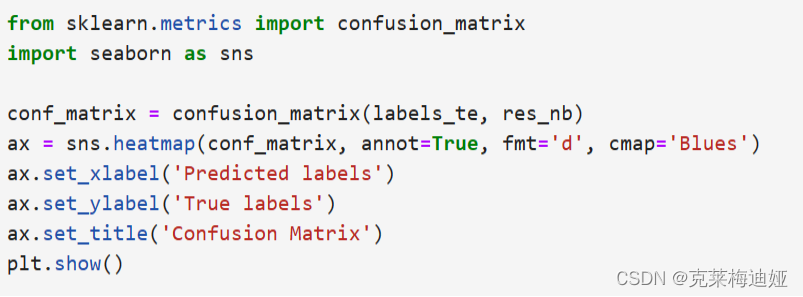
5 设计总结
该模型在测试集上的准确度约为98.3%左右。预训整体来说还是比较好的,当模型参数达到极限时候,调整迭代轮次并没有用。 在不改变模型的情况下,靠参数调整提高精确度的可能性非常局限。因此数据质量就显得尤为重要,通过数据扩增能使得训练的模型提高准确率。若使用数据增强、自定义模型等方式,看看能否取得更好的结果。 针对此次项目运行结果,我有两个改进思路:一是改进算法模型或者结合几种算法一起运行,如改用逻辑回归算法、SVM支持向量机等。二是改用深度学习模型来进行训练,如LSTM算法等。
6 设计体会
在机器学习领域中,基于文本内容的垃圾短信识别是一个非常重要的应用。它可以应用在手机短信过滤、邮件分类等场景中,为用户带来便利和良好的体验。在此过程中,本此项目实现并开发了一个基于文本内容的垃圾短信识别系统,并从中收获了不少体会。
在本次的项目中,我们使用了开源的垃圾短信数据集,但由于数据来源不同,会存在格式和标注不统一的问题。在这种情况下,我们需要先进行数据清理和预处理,标准化数据,使其符合我们模型的输入和输出。并且在这一过程中,需要仔细考虑文本数据中的一些特殊符号和切词的方法,以提高模型的准确性。其次,模型的构建要针对具体场景进行优化。在项目中,我选择了基于卷积神经网络的垃圾短信分类模型,但具体的层数和参数需要根据数据情况和系统的需要进行优化。同时,还要考虑到在线运行和训练的问题,及时调整模型、更新参数,以应对不断变化的垃圾短信形式。最后在机器学习中,评估指标是我们判断模型性能的重要依据。我们可以根据系统特点、用户需求、数据分布等因素来选择适合的评估指标,如准确率、召回率、F1 值等。同时,我们还需注意样本选择的问题,要保证样本的多样性和代表性,以充分测试模型在不同情况下的性能。最后,还需要重视实际应用的评估和迭代。模型在离线测试中的表现可能与在线运行时存在差异,因此需要在实际应用时进行不断的迭代和优化,以提高系统性能。
这次在项目实验过程中我还是犯了很多错误,比如关于文档路径的具体书写要求不规范导致我造成了很大的时间浪费,而且对模型的不熟悉也给我的代码编写带来了很大的困难,但是我也在改正这些错误的过程中,对于模型构架有了更多的理解,也使自己改善了粗心的毛病。
总之,在这次基于文本内容的垃圾短信识别的设计中,我了解到了机器学习应用的具体操作和步骤,并学习到了不少实践技巧和经验。从数据预处理到构建模型,再到评估指标的选择和样本的测试,这些步骤都需要深入思考和慎重设计,才能打造一个准确、高效、可靠的机器学习应用系统。

