- 1《Improving Backgroud Subtraction using local binary similarity patterns》_lbsp vibe
- 2深度特征提取方法_基于深度学习的文本数据特征提取方法之Word2Vec(一)
- 3使用支持向量机(SVM)进行手写体识别_svm手写体识别代码
- 430分钟读懂Linux进程调度(图文并茂)_linux 0.11 dotimer
- 5灰狼优化算法GWO,优化VMD,适应度函数为最小样本熵或最小包络熵(可自行选择,代码已集成好,很方便修改)包含MATLAB源代码_gwo-vmd
- 6ICLR 2020共计198篇开源代码论文目录!_iclr论文开源代码
- 7【大模型】非常好用的大语言模型推理框架 bigdl-llm,现改名为 ipex-llm
- 8mysql索引概念、定义和使用
- 9GoLang之再谈Gvim/Vim配置——使用Vundle安装vim-go_gvim 配置vim-go
- 10数据可视化redis mysql_开源 5 款超好用的数据库 GUI 带你玩转 MongoDB、Redis、SQL 数据库...
基于 Quivr 搭建个人知识库
赞
踩
目录

今天咱们尝试使用开源的框架Quivr搭建一个自己的知识库。官网自诩Quivr为你的第二个大脑,利用生成人工智能的力量来存储和检索非结构化信息。你可以把它想象成带有人工智能功能黑曜石。看官网的介绍图案也是黑曜石里生长出智慧之树,果然寓意很牛逼。
Quivr介绍
Quivr采用先进的人工智能技术来帮助您生成和检索信息,可以处理几乎所有类型的数据,包括文本、图像、代码片段等。同时,它还专注于速度和效率,确保可以快速访问数据。数据安全由自己掌控,Quivr 支持多个文件格式,包括文本、Markdown、PDF、PowerPoint、Excel、Word、音频、视频等。
Quivr特性
- Universal Data Acceptance:Quivr几乎可以处理你扔给它的任何类型的数据。包括文本、Markdown、PDF、PowerPoint、Excel、Word、音频、视频等等。
- Generative AI:Quivr采用先进的人工智能来帮助你生成和检索信息。
- Fast and Efficient:因为设计是以速度和效率为核心,Quivr确保快速访问数据。
- Secure:任何场景任何时间,你的数据由你自己控制。
- Open Source:开源、免费。
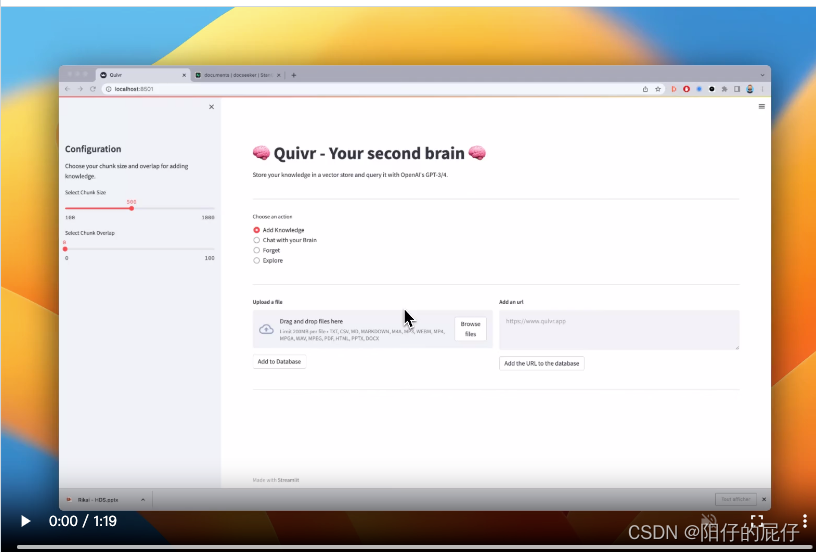
Quivr演示
Demo with GPT3.5:
下面的视频是基于ChatGPT3.5的一个demo演示,其中演示了构建知识库并进行多轮对话问答。https://user-images.githubusercontent.com/19614572/238774100-80721777-2313-468f-b75e-09379f694653.mp4
Demo of the new version:
下面的视频是5月下旬上线的最新的版本的演示视频,新的版本替换了操作UI,接下来我们尝试使用新版搭建自己的知识库。https://user-images.githubusercontent.com/19614572/239713902-a6463b73-76c7-4bc0-978d-70562dca71f5.mp4
Quivr实战
Quiv 使用的主要技术
Quivr 和其他知识库方案一样,本质上都是基于 Prompt 与大模型交互来的,Quivr 用到的主要技术有:
- LLM:GPT3.5 / GPT 4
- Embedding:OpenAI embedding
- 向量知识库:Supabase
- Docker:Docker Compose
Quiv 实践依赖
前面咱们已经提到过Quivr 采用的是Supabase向量数据库,所以在此之前咱们需要先创建一个Supabase的账号,获取到Supabase Project API key、Supabase Project URL,并且生成几个必要的表。
创建Supabase项目
Supabase的官网地址是:Dashboard | Supabase如果有github账号的话可以直接使用GitHub 账号登陆,要是没有的话就用其他的方式注册也可以。创建项目比较简单,创建的时候有付费的和免费的,咱们练习直接白嫖就可以,果断选择免费方式。新建完毕项目之后会出现项目的相关配置,咱们需要的就是第二张图里标记的,如果后面向要重新找这几个信息可以通过这个地址:API Settings | Supabase,或者选择项目进入到设置里查询。


部署Quiv项目
前置环境准备完毕咱们开始部署Quiv项目。
第一步:现在源码
- git clone https://github.com/StanGirard/quivr.git && cd quivr
- # 切换到 v0.0.4分支
- git checkout v0.0.4
- git checkout -b v0.0.4
第二步:设置环境变量
需要修改 frontend、backend两个目录下的环境变量,先拷贝到这里。下面的图里是我本地按照创建的项目里的配置替换的,需要注意的是backend目录下的ANTHROPIC_API_KEY 是选择 Claude 的配置,我们可以删了。
- cp .backend_env.example backend/.env
- cp .frontend_env.example frontend/.env

![]()

第三步:执行sql
配置完完毕,接下来要初始化数据库了。打开 Supabase 面板,按下图点击创建一个sql执行框将下面的sql代码依次执行即可。
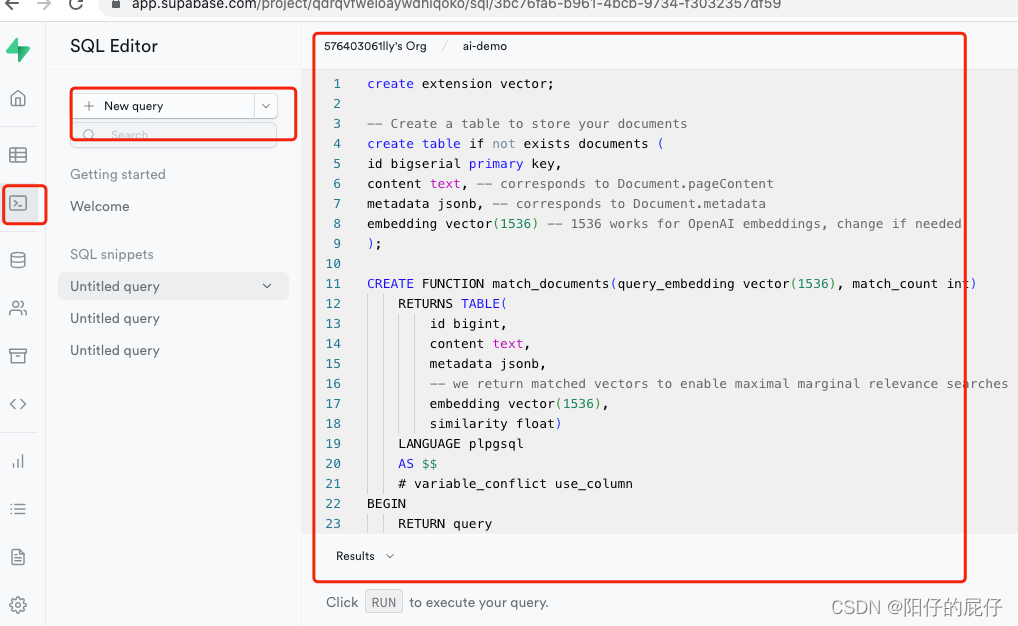

- create extension vector;
-
- -- Create a table to store your documents
- create table if not exists documents (
- id bigserial primary key,
- content text, -- corresponds to Document.pageContent
- metadata jsonb, -- corresponds to Document.metadata
- embedding vector(1536) -- 1536 works for OpenAI embeddings, change if needed
- );
-
- CREATE FUNCTION match_documents(query_embedding vector(1536), match_count int)
- RETURNS TABLE(
- id bigint,
- content text,
- metadata jsonb,
- -- we return matched vectors to enable maximal marginal relevance searches
- embedding vector(1536),
- similarity float)
- LANGUAGE plpgsql
- AS $$
- # variable_conflict use_column
- BEGIN
- RETURN query
- SELECT
- id,
- content,
- metadata,
- embedding,
- 1 -(documents.embedding <=> query_embedding) AS similarity
- FROM
- documents
- ORDER BY
- documents.embedding <=> query_embedding
- LIMIT match_count;
- END;
- $$;

- create table
- stats (
- -- A column called "time" with data type "timestamp"
- time timestamp,
- -- A column called "details" with data type "text"
- chat boolean,
- embedding boolean,
- details text,
- metadata jsonb,
- -- An "integer" primary key column called "id" that is generated always as identity
- id integer primary key generated always as identity
- );
- -- Create a table to store your summaries
- create table if not exists summaries (
- id bigserial primary key,
- document_id bigint references documents(id),
- content text, -- corresponds to the summarized content
- metadata jsonb, -- corresponds to Document.metadata
- embedding vector(1536) -- 1536 works for OpenAI embeddings, change if needed
- );
-
- CREATE OR REPLACE FUNCTION match_summaries(query_embedding vector(1536), match_count int, match_threshold float)
- RETURNS TABLE(
- id bigint,
- document_id bigint,
- content text,
- metadata jsonb,
- -- we return matched vectors to enable maximal marginal relevance searches
- embedding vector(1536),
- similarity float)
- LANGUAGE plpgsql
- AS $$
- # variable_conflict use_column
- BEGIN
- RETURN query
- SELECT
- id,
- document_id,
- content,
- metadata,
- embedding,
- 1 -(summaries.embedding <=> query_embedding) AS similarity
- FROM
- summaries
- WHERE 1 - (summaries.embedding <=> query_embedding) > match_threshold
- ORDER BY
- summaries.embedding <=> query_embedding
- LIMIT match_count;
- END;
- $$;
第四步:启动应用
前面几步的准备工作做完了,现在就可以启动应用了。需要注意的是如果docker的版本过低的话会提示错误,需要更新docker。大家按照自己的时机情况更新到何时的版本即可。这一步启动时间比较长,因为要打包镜像并启动应用。
docker compose build && docker compose up第五步:效果演示
用户登陆:

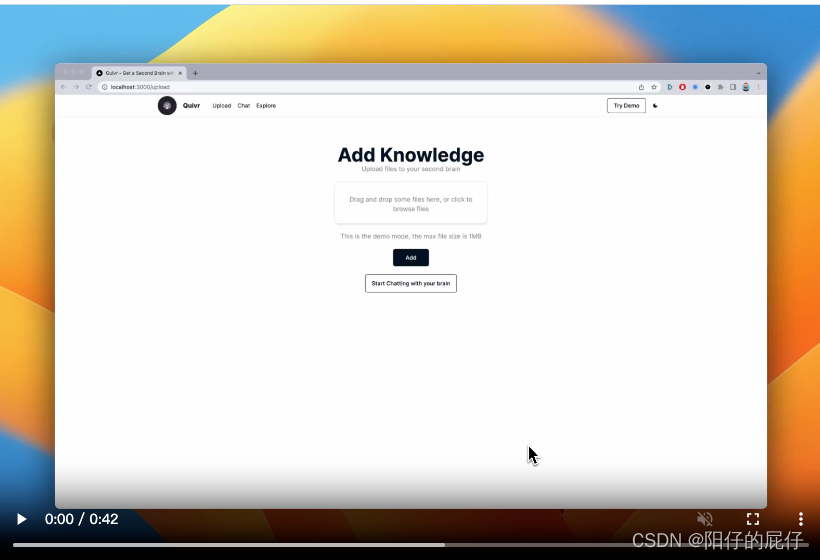
上传知识库:
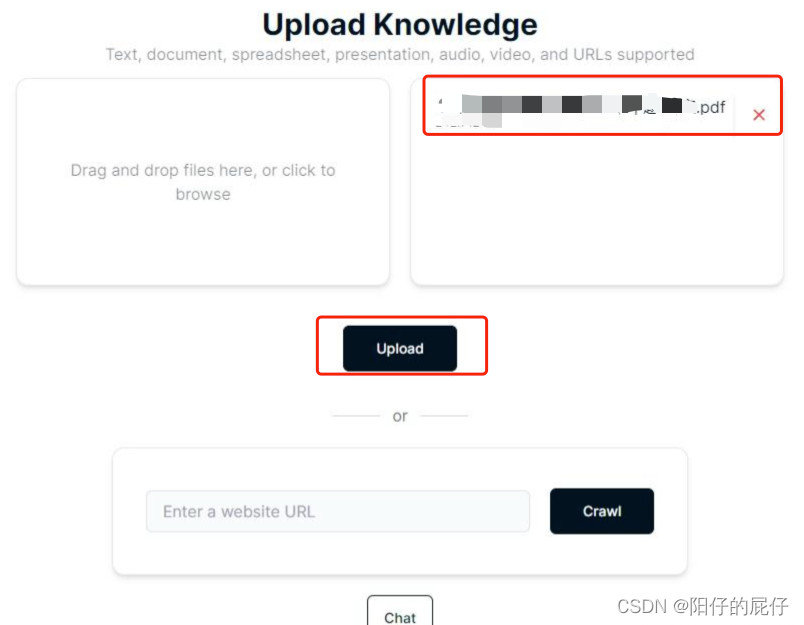
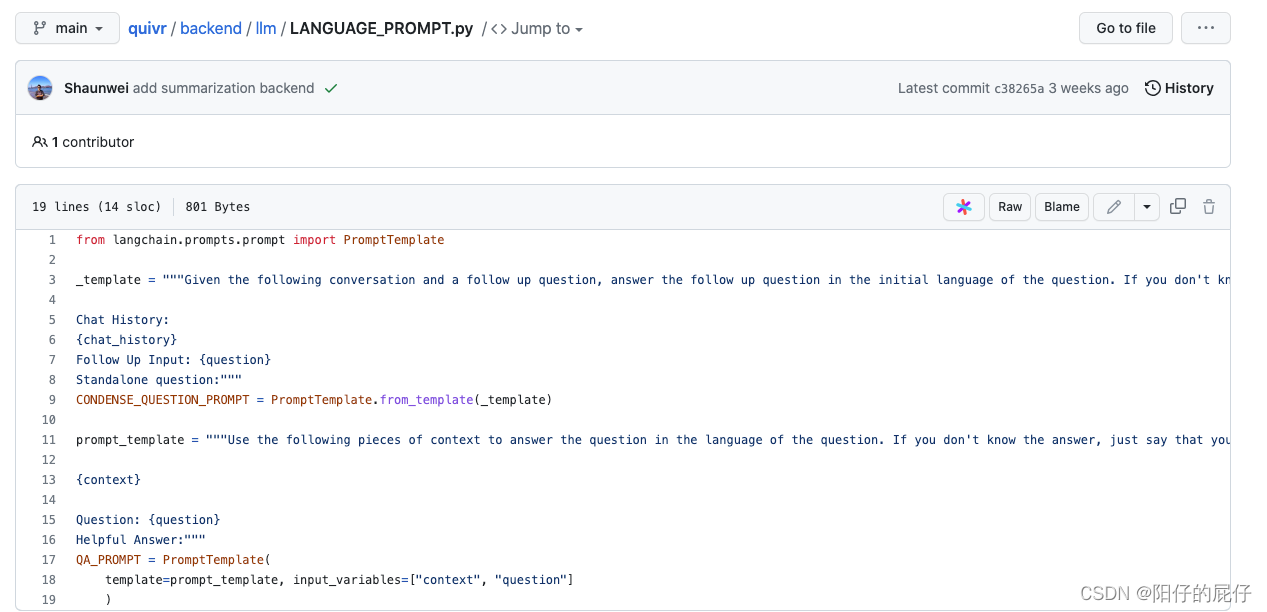
修改问答prompt进行问答
接下来就可以进行知识库的问答了,目前源码还是支持英文的问答,咱们想要使用中文的话修改问答模版即可(作者很有意思为了防止模型胡乱问答模版提示词里特意提醒不要胡编乱造答案,哈哈哈),文件路径如下: