
- 1用HttpClient发送HTTPS请求报SSLException: Certificate for <域名> doesn't match any of the subject alternative...
- 2JAVA如何把一个float四舍五入到小数点后2位,4位,或者其它指定位数._java float 四舍五入
- 3使用Python进行文件快速搜索(建立文件搜索索引)_python 建立硬盘索引
- 4STM32F103定时器复用功能映射及其通道_stm32f103定时器映射
- 5The full stack trace of the root cause is available in the server logs.
- 6【深度学习】细粒度图像识别 (fine-grained image recognition)
- 7AI接入微信公众号方法总结_微信公众号 集成ai
- 8RestTemplate如何传递参数源码详解_resttemplate怎么传递requestparam注解标记的参数
- 9ARM-IIC实验
- 10PMP相关管理备考01_需求跟踪矩阵 适用于适应性生命周期
DDSP-SVC-3.0完全指南:一步步教你用AI声音开启音乐之旅
赞
踩
本教程教你怎么使用工具训练数据集推理出你想要转换的声音音频,并且教你处理剪辑伴奏和训练后的音频合并一起,在文章的最后有用我自己声音处理的歌曲,哎哟,还怪不好意思的~,哈哈,快来试试看把!
DDSP-SVC3.0训练推理克隆声音,超物有所值,训练完毕有伴奏处理教程哦
1.使用的工具
要想训练ai声音,首先需要有各种工具,还需要我们提供你需要训练的声音,当然声音需要没有噪音存干声,如果要是歌曲就需要分离歌曲的背景和声音,然后将音频文件切分,切分的目的是为了保证训练不卡,否则音频文件太大,所以你知道我们需要什么工具了把!以下揭晓
Adobe Audition :我主要用这个提取mp4的音频文件,后期可以用这个剪辑将伴奏和音频合起来
UVR5:这个是专门背景与人生分离的软件,一键安装就可以
Audio Slicer(音频切分):这个可以不用专门下软件自己操作了,大神在webui里集成了,按一下自动切分。
DDSP-SVC-3.0:最重要的工具,启动后是个webui界面,然后呢我们需要在里边训练自己的声音,转换声音等操作。
整合包使用b站大佬羽毛布团提供的包-地址: https://pan.baidu.com/s/1DWqVpJ7b6ueoUv6h4yF1-A?pwd=ddsp
处理音频的工具可以去羽毛布团的这个整合包下载,注意不要下载so-svc文件哦: https://pan.baidu.com/s/12u_LDyb5KSOfvjJ9LVwCIQ?pwd=g8n4
2.素材准备
2.1 AU提取音频
将mp4提取音频文件,用AU操作,操作如下:
我是要把我在bilibili录制的视频下载下来的,需要借助bilibili的一些工具才能下载下来视频,我用的是这个在线解析bilibili视频的还是蛮方便的,链接在这里。
然后得到的视频可以拖到如下的位置,
然后点击这个文件右键将音频提取到文件,然后点击新出的音频文件再点击最上面的菜单文件保存或另存为然后就得到音频文件了。

2.2 UVR5提取干声
下面提取说明按需去取。
音频如果比较纯的声音无噪音则直接可以切分音频了,如果不纯的化可以处理下,打开url5,
这个是处理伴奏和人声分离的。

伴奏人声分离以后可以去听听纯声,发现其实会有一些和声和混响的,我们要去去掉这个和声混响,根据下面操作。

如果不是唱歌而是干声去噪也可以使用如下这种方式处理看看效果,我是纯的背景有点噪音,然后用了去和声混响处理的,也是有点效果的。

3.启动DDSP-SVC
声音部分都处理完了,就可以启动webui了,进入DDSP-SVC-3.0目录,双击启动启动WebUI,然后弹出来一个cmd弹框,

复制这个路径打开webui

webui的界面是这样的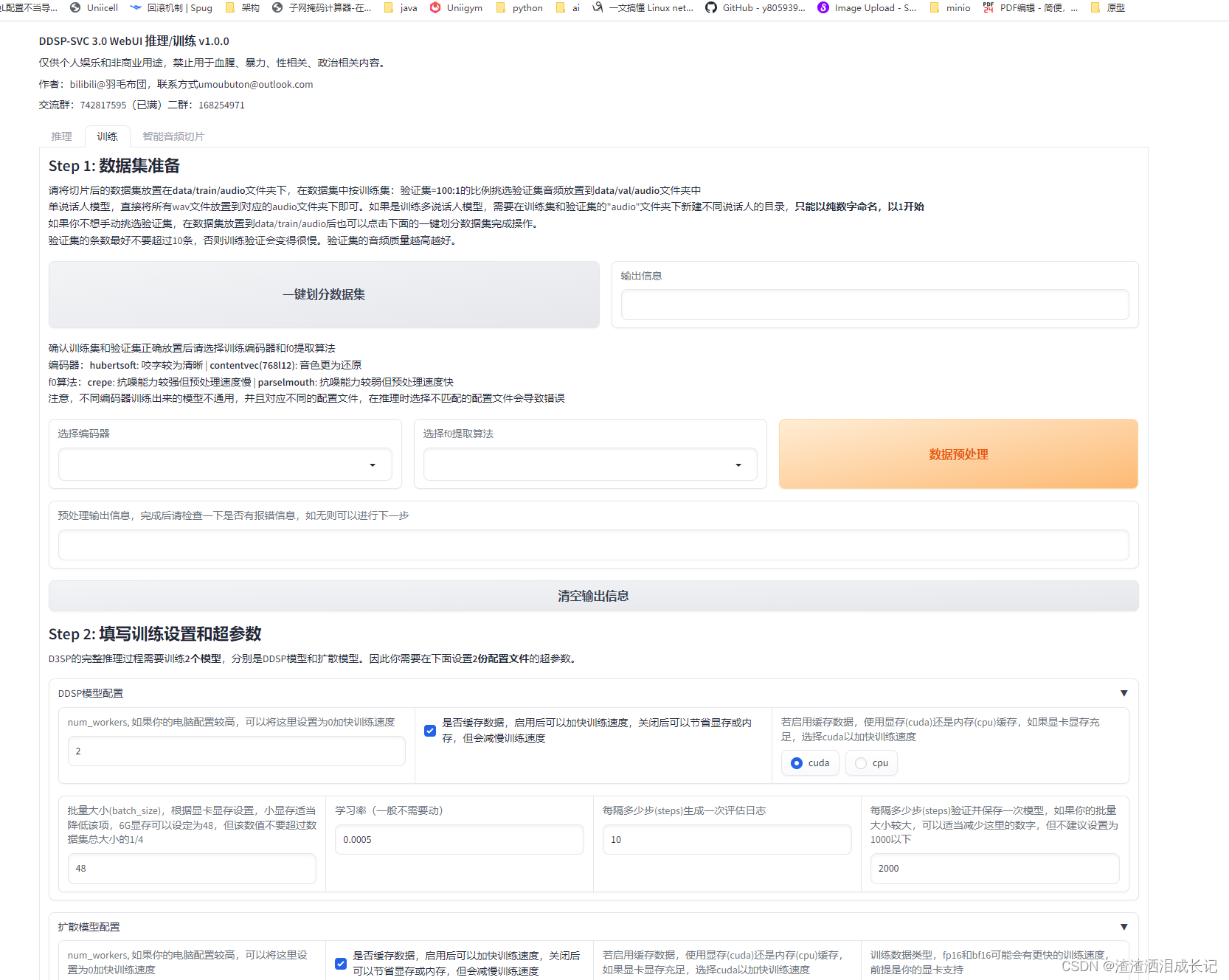
3.1 音频切分
这时就可以音频切分了,按照下面的说明去处理。

切分后的文件。
找到切分后的输出目录然后全部将块音频全部复制到此目录下:DDSP-SVC-3.0\data\train\audio
然后就需要到webui界面下,这时需将DDSP-SVC-3.0\data\train里的音频以100:1的比例放入到此目录下:DDSP-SVC-3.0\data\val\audio,100:1就是100个文件里取一个这样的比例,也可以不用你自己挑,程序帮你挑完自己放入对应的校验集里也就是val目录下,程序操作如下:

3.2 数据预处理
数据预处理,这里也很快,按下面的说明进行填写,填写哪些都有注释,点击数据预处理就可以了。
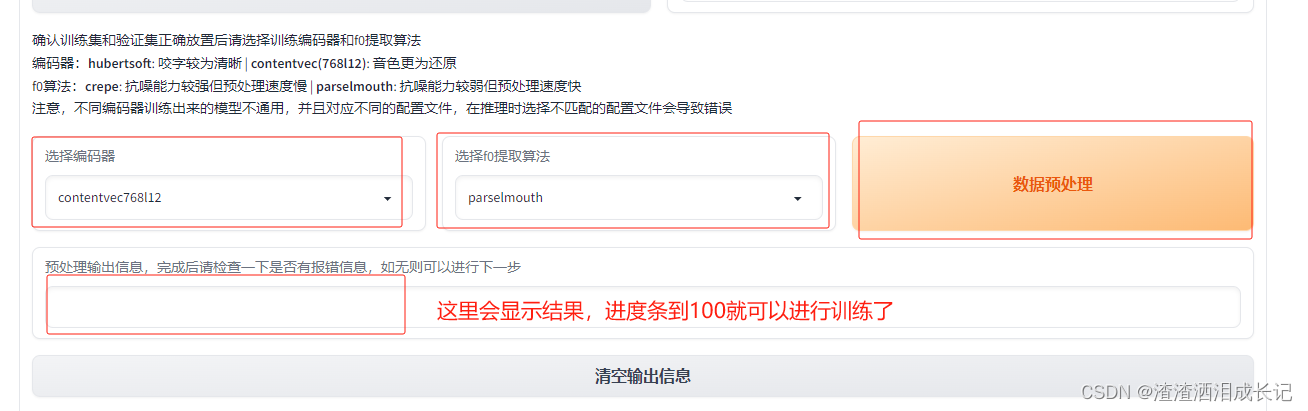
3,3 训练前的参数设置
设置要训练的参数,其实都默认就行,但是配置低的要进行相应的更改,否则训练过程中会失败。然后点击写入配置文件就可以了,此时输出信息说写入配置完成就OK了。

3.4 开始训练
3.4.1 DDSP模型训练
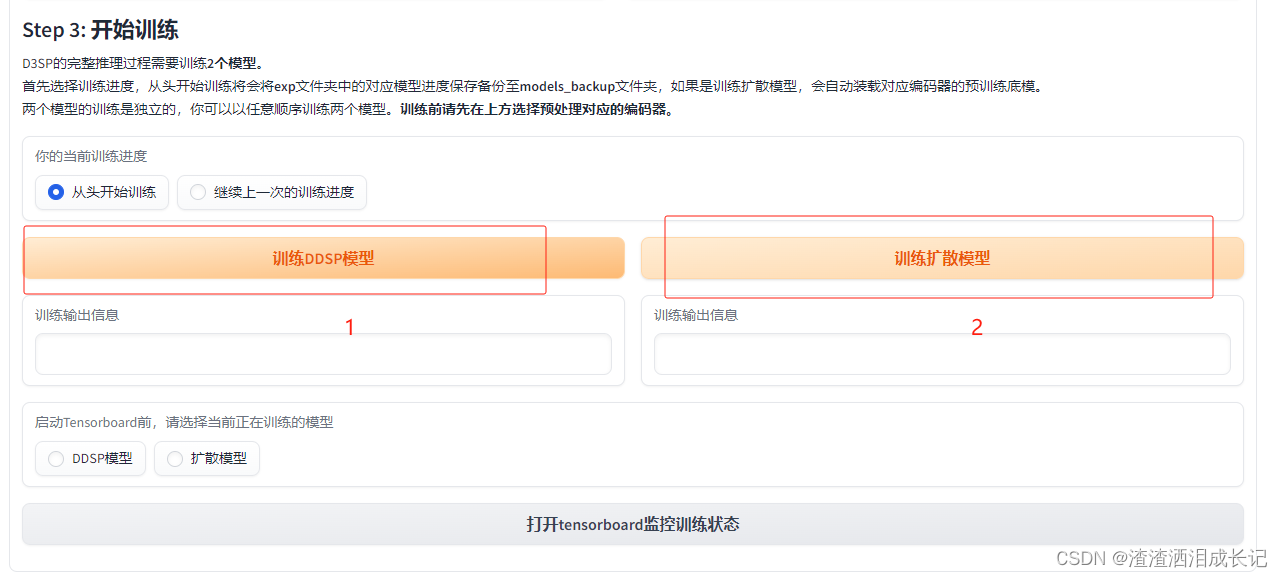
然后就开始训练了, 一般是先训DDSP这个是比较重要的,第一次训练的化需要选择从头开始训练,如果训练过程中取消了,那么想要继续训练就选择继续上一次的训练进度,然后取消模型训练时一定要按照这个倍数取消“每隔多少步(steps)验证并保存一次模型(2000步)”,否则可能没保存上,
然后弹出cmd,一直在迭代步数中,代表训练中

观察loss值,无明显趋势觉得不需要训练就可以按取消了,ctrl+c就会取消训练

训练完了就可以训练扩散模型了,报如下错需要修改fp16需要改成fp32了。
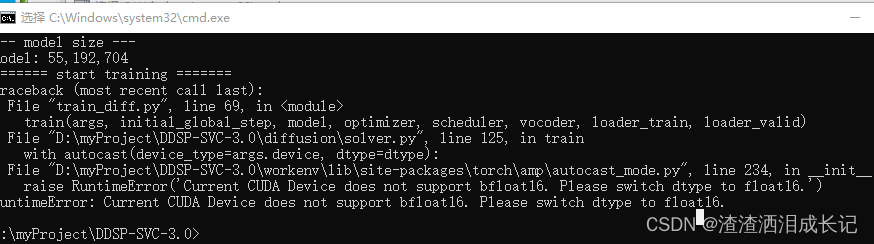
可以看训练趋势图,启动Tensorboard,按下面这个操作就可以了,倒时会告诉你地址。
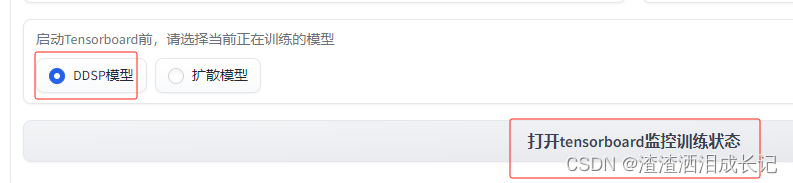
就会出现这样的界面

3.4.2 扩展模型训练
DDSP训练完毕,我们开始训练扩散模型。如下方式这样就可以了,cmd和上面的ddsp是一样的,感觉差不多了就取消训练。都训练完毕了就到推理环节了。

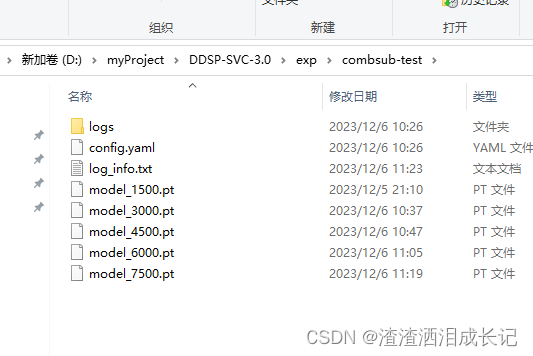
训练好的模型在这里会出现,此目录:DDSP-SVC-3.0\exp
DDSP的在这个目录下,可以看到模型训练的步数
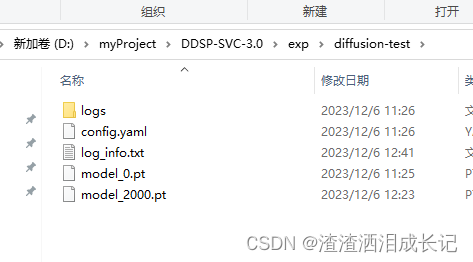
扩散训练的在这个地方
4.模型推理
兄弟们最后一步了,坚持住啊!
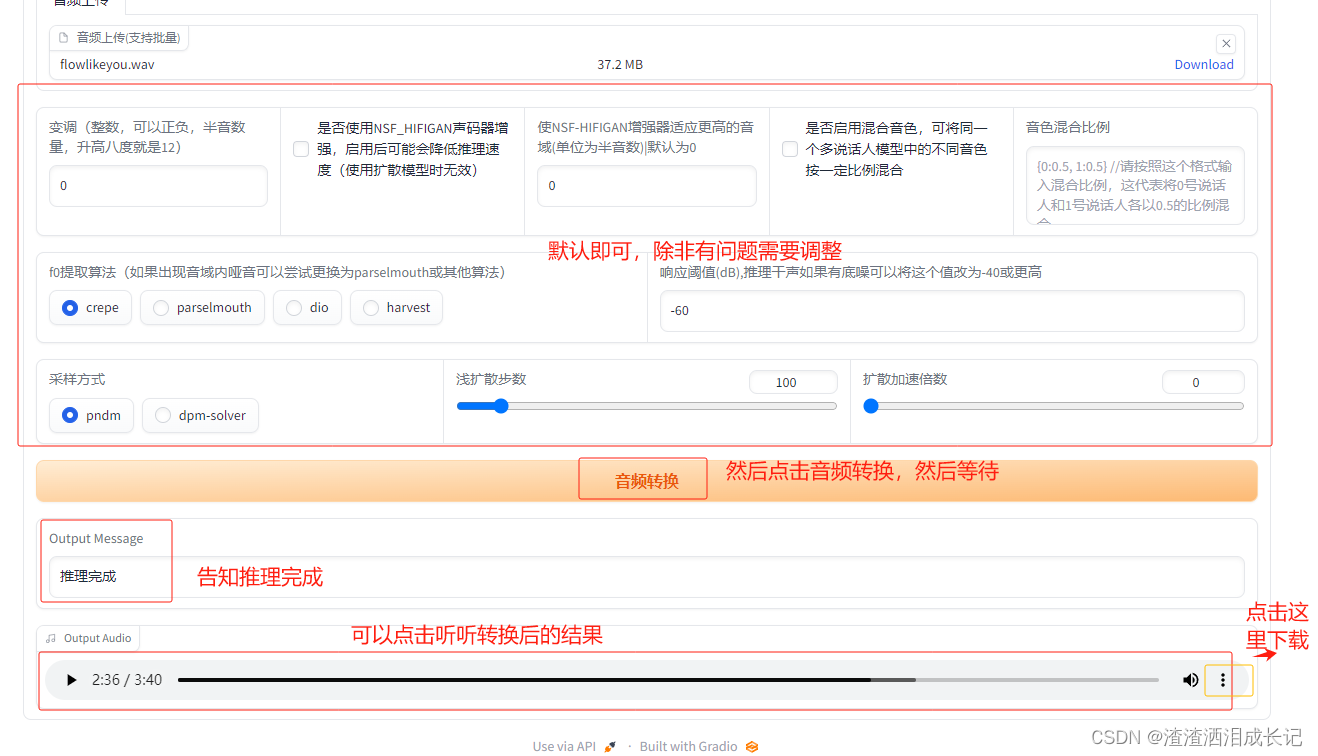
推理就选择我们自己训练的模型,选择音频,按下面的图片的步骤走,按顺序来就行。

4.1 音频转换
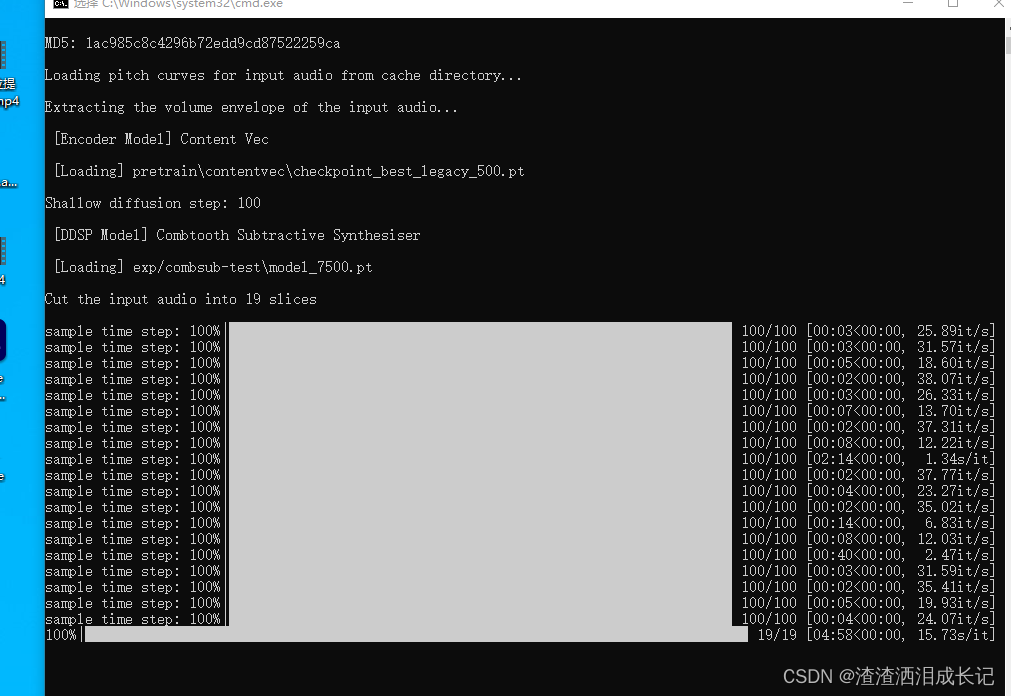
重点来了,开始声音替换 ,我第一次处理时间巨长,也看不到日志后来关掉重启,重试关掉重启几次,突然出现了日志,以及处理过程,然后很快就推理完成了,听了下,效果还行,我的数据集还行,40分钟差不多,训练步数7500步也不多,然后我的声音全部是说话,没有唱歌声音,最后出现的这个效果还行,有一点点感觉到ai的感觉,不知道是不是这个哥以及歌手唱腔的原因。
推理过程。
5.让AI唱歌
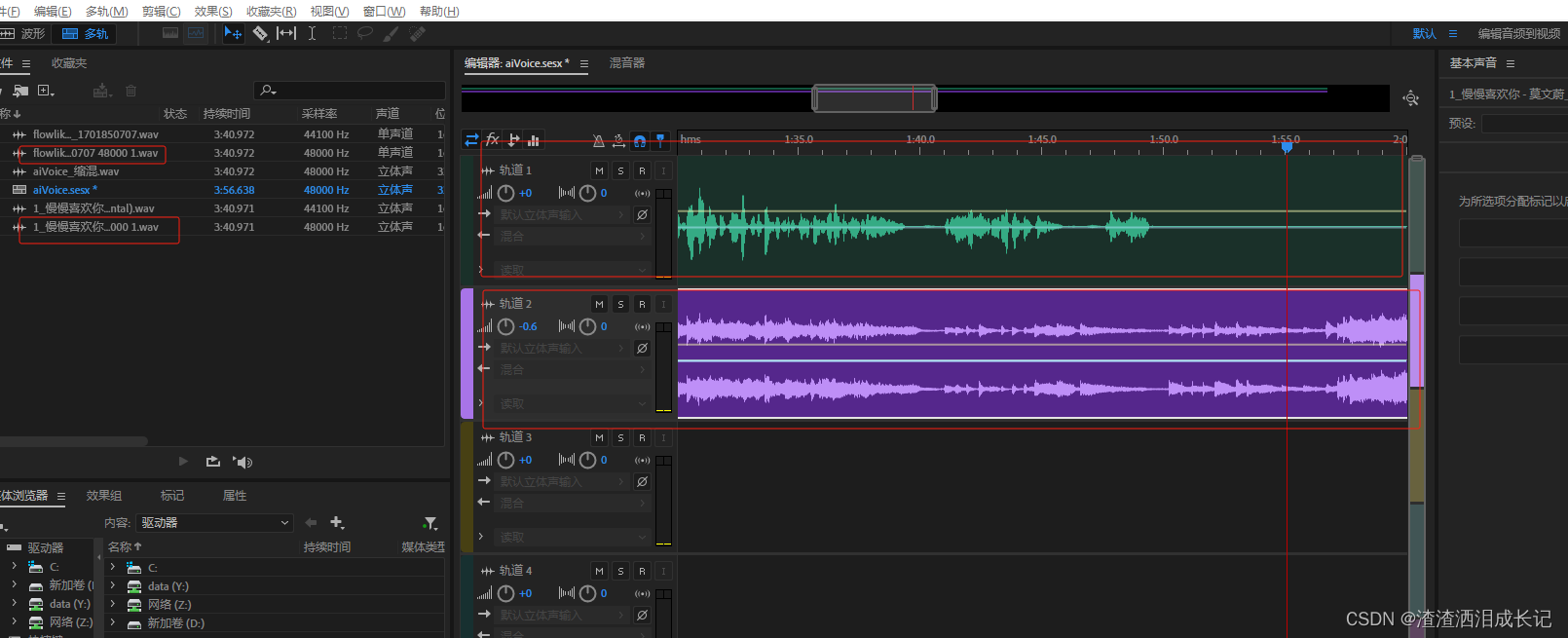
我的音频是《慢慢喜欢你》这首歌的干声,然后把我的声音替换上去,转换了以后《慢慢喜欢你》就是我的声音了,接下来就需要把伴奏和我处理后的声音合在一起,打开AU这个软件就可以了
选择多轨道

然后将伴奏文件和处理好的音频拖入进来,干声放入第一轨道,伴奏放入第二轨道,对齐就好
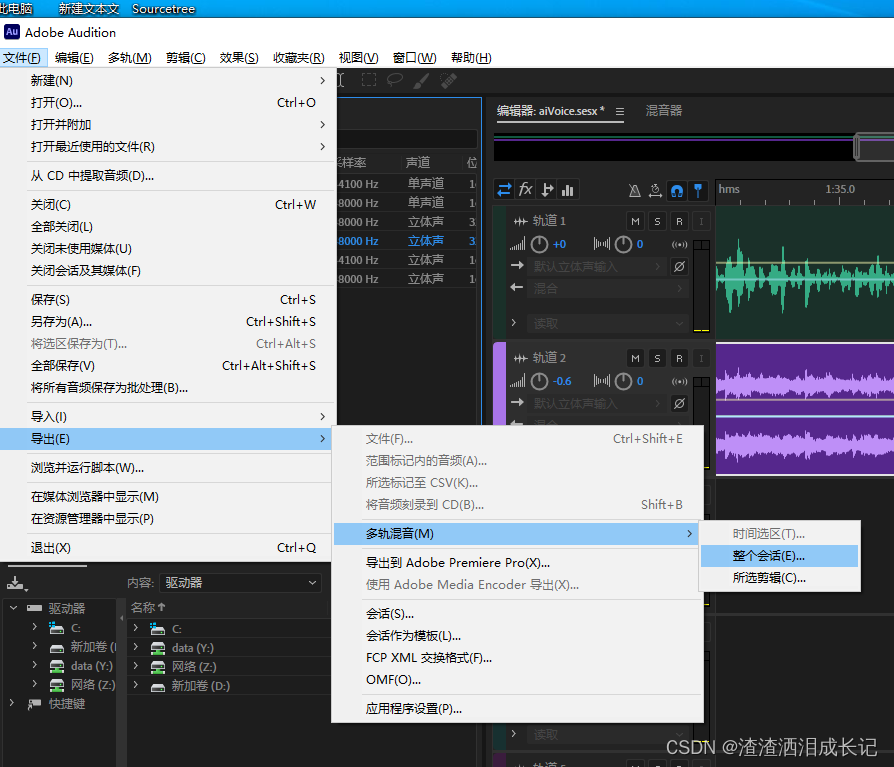
然后点击文件导出-多轨混音-整个会话就可以了。记得自己指定输出目录哦!
来欣赏作品把:
训练22000步的效果:
《漫步人生路》
笑对沧桑,漫步人生路,不问前程几何。
《以渺小爱你》一路前行环保公益曲,最近非常喜欢
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

