
- 1Android Studio 导入及关联framework源码_androidstudio 打开android framework
- 2交换机进行读写rtl8306.c驱动源码_rtl836 驱动
- 3【Matlab算法】梯度下降法(Gradient Descent)(附MATLAB完整代码)_matlab 梯度下降法
- 4如何用python编辑 一个偶数总能表示为两个素数之和_python偶数拆成两个素数之和
- 5鸿蒙系统(HarmonyOS)理论基础合集(六):创建鸿蒙工程_鸿蒙系统指令代码大全
- 6电话拨键号码(DTMF信号)识别_dtmf拨号判读 csdn
- 7使用Git下载Android源代码_app源码 git下载
- 8vue 监听滚动条行为 | 判断滚动条是向上滚动还是向下滚动_vue 判断滚动条滚动方向
- 9ArcGIS批量裁剪栅格数据(ArcPy方法)
- 10Android中kernel内核模块编译执行_安卓kernel编译
NLP面试题目总结_nlp大模型的面试算法题
赞
踩
文章目录
- 数学基础
- 1. 给定两个矩阵,怎么计算它们之间的相乘?怎么计算一个矩阵的inverse?
- 2. 怎么计算一个向量的 norm? a = (3,1,5,1), |a| = ?
- 3. 什么是 Frobenius norm? 给定 A = [[1,3],[2,5]], 请计算;
- 4. 什么叫矩阵的 determinant? 怎么计算⼀个矩阵的 determinant? A = [[1,3],[2,5]],det(A)=?
- 5. 什么叫 underflow, 什么叫 overflow? 对于很多的 AI 问题,如果出现很多概率的相乘,我们通常都在最前⾯加 log, 为什么? ⽐如 argmax p(x), 通常求解 argmax log p(x).
- 6. 什么叫信息熵? 什么叫互信息? 他们具体的含义是什么?
- 7. 对于softmax 函数,我们去实现的时候怎么避免underflow 或者 overflow?
- 8. 怎么判断一个函数是否是凸函数?比如log x,Ax+b,|Ax-b|^2是凸函数吗?
- 9. 利用chain rule来分解联合概率 p(x1, x2, x3, x4, x5)
- 10. 什么是KL-Divergence,写出它的数学细节,什么时候需要用到它?
- 机器学习基础
- 自然语言处理
- 数据结构与算法相关
数学基础
1. 给定两个矩阵,怎么计算它们之间的相乘?怎么计算一个矩阵的inverse?
。
A
=
[
[
1
,
3
]
,
[
2
,
5
]
]
,
B
[
[
4
,
1
]
,
[
2
,
4
]
]
,
A
∗
B
=
?
A
−
1
=
?
A = [[1,3],[2,5]], B[[4,1],[2,4]],A*B=? A^{-1}=?
A=[[1,3],[2,5]],B[[4,1],[2,4]],A∗B=?A−1=?
两个矩阵的相乘,就是各个位置元素的相乘。
A
∗
B
=
[
[
1
∗
4
,
3
∗
1
]
,
[
2
∗
2
,
5
∗
4
]
]
A*B = [[1*4,3*1],[2*2,5*4]]
A∗B=[[1∗4,3∗1],[2∗2,5∗4]]
2*2的矩阵求逆,假设A=[[a,b],[c,d]]:
- 调换a和d的位置;
- 把负号放在b和c前面;
- 用各个元素除以A矩阵的行列式 (ad-bc);
A − 1 = − 1 ∗ [ [ 5 , − 3 ] , [ − 2 , 1 ] ] = [ [ − 5 , 3 ] , [ 2 , − 1 ] ] A^{-1}=-1*[[5,-3],[-2,1]]=[[-5,3],[2,-1]] A−1=−1∗[[5,−3],[−2,1]]=[[−5,3],[2,−1]]
2. 怎么计算一个向量的 norm? a = (3,1,5,1), |a| = ?
一范式是向量的绝对值之和:3+1+5+1 = 10;
二范式是向量元素的绝对值的平方和再开方:sqrt(9+1+25+1)=6
3. 什么是 Frobenius norm? 给定 A = [[1,3],[2,5]], 请计算;
F-范数:矩阵A各项元素的绝对值平方和开方
向量范数和矩阵范数的区别:
- 首先是向量和矩阵的区别:为了更好的在数学上表达集合的映射关系,这里引入了矩阵。矩阵就是表征空间映射关系,向量是用来表示映射中的集合。一个集合(向量)通过一个映射关系(矩阵),得到另外一个集合(向量);
- 向量的范数:表示原有集合的大小;矩阵的范数:表示这个变化过程大小的一个度量;
4. 什么叫矩阵的 determinant? 怎么计算⼀个矩阵的 determinant? A = [[1,3],[2,5]],det(A)=?
矩阵行列式是指矩阵的全部元素构成的行列式,设
A
=
(
a
i
j
)
A=(a_{ij})
A=(aij)是数域P上的一个n阶矩阵,则所有
A
=
(
a
i
j
)
A=(a_{ij})
A=(aij)中的元素组成的行列式称为矩阵A的行列式,记为|A|或det(A)。
2X2矩阵的行列式det(A)= ad-bc= -1
5. 什么叫 underflow, 什么叫 overflow? 对于很多的 AI 问题,如果出现很多概率的相乘,我们通常都在最前⾯加 log, 为什么? ⽐如 argmax p(x), 通常求解 argmax log p(x).
- 实数在计算机内用二进制表示,所以不是一个精确值,当数值过小的时候,被四舍五入为0,这就是下溢出。此时如果对这个数再做某些运算(例如除以它)就会出问题。反之,当数值过大的时候,被视为(正负)无穷,情况就变成了上溢出;
- 加log是为了将乘除转变为加减运算,一是为了简化运算,二是为了避免出现上下溢出的情况;
6. 什么叫信息熵? 什么叫互信息? 他们具体的含义是什么?
信息熵是信息量的定量描述,是随机变量抽样得到的分布中产生的信息量的平均值:
H
(
x
)
=
−
∑
i
=
1
∞
P
(
x
i
)
l
o
g
P
(
x
)
H(x) = -\sum_{i=1}^{\infty}P(x_i)logP(x)
H(x)=−i=1∑∞P(xi)logP(x)
下面介绍下为什么信息熵要用这样的式子来表示:
- 信息量:信息量可以被看做是在学习x的值时的“惊讶程度”,当一个相当于不可能的事件发生时,信息量(惊讶程度)越大;当一个事情一定会发生时,信息量(惊讶程度)越小;
- 由此将信息内容的度量与概率分布P(x)挂钩,将信息内容的度量依赖于概率分布P(x),信息内容h(x)是概率P(x)的单调递减函数;
- 不相关的事件X、Y,X和Y同时发生的概率为:P(X,Y) = P(X)P(Y),X和Y同时发生的信息量应是:h(X, Y) = h(X)+h(Y),根据这个变乘为加的关系,可以考虑引入log来表示h(X),于是可以有:
h ( x ) = − l o g P ( x ) h(x) = -logP(x) h(x)=−logP(x)或者 h ( x ) = l o g ( 1 P ( x ) ) h(x)=log(\frac {1}{P(x)}) h(x)=log(P(x)1) - 对随机变量抽样所获得的平均信息量,就是关于概率分布P(x)的期望(以第一种表达方式为例):
H ( x ) = − ∑ i = 1 ∞ P ( x i ) l o g P ( x ) H(x) = -\sum_{i=1}^{\infty}P(x_i)logP(x) H(x)=−i=1∑∞P(xi)logP(x)
参考blog链接:https://blog.csdn.net/pipisorry/article/details/51695283
互信息是用来度量 随机变量X 和随机变量 Y 共享的信息:表示已知X时,有多大程度可以确定Y,这个多大程度就是X提供的Y的信息量。是变量间相互依赖性的量度,表示联合分布P(X,Y)和分解的边缘分布的乘积P(X)P(Y)的相似程度。
参考blog:https://www.cnblogs.com/gatherstars/p/6004075.html
7. 对于softmax 函数,我们去实现的时候怎么避免underflow 或者 overflow?
- softmax函数可以表示为: f ( x ) = e x i ∑ j = 1 n e x j , j = 1 , , , n f(x) = \frac {e^{x_i}}{\sum_{j=1}^{n}{e^{x_j}}} ,j=1,,,n f(x)=∑j=1nexjexi,j=1,,,n
- softmax的功能就是将输入的值映射成为(0,1)的值,而映射后的值累加和为1(满足概率的性质),那么我们就可以将映射后的值理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为预测目标。如图:
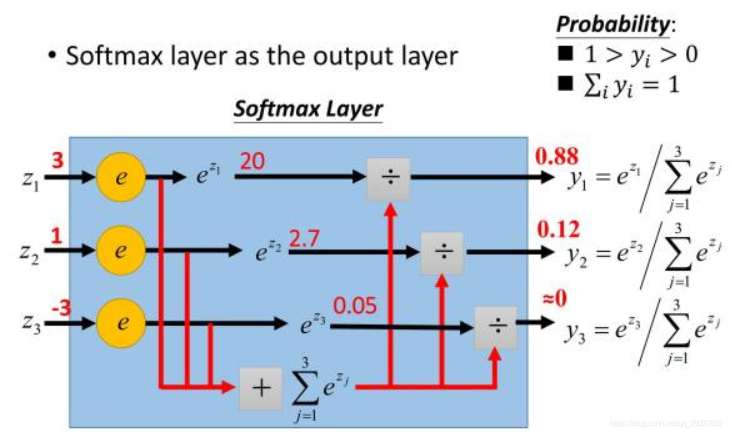
- 当z的值极其大时,分子计算 e x e^x ex时就可能导致上溢出,而当x的值为负数时,分母很大,就容易输出为0,导致下溢出。
- 解决方法一: 将
f
(
x
i
)
f(x_i)
f(xi)变为
f
(
x
i
−
M
)
f(x_i-M)
f(xi−M)
解决方法二:加上log
参考知乎:
https://www.zhihu.com/question/23765351
8. 怎么判断一个函数是否是凸函数?比如log x,Ax+b,|Ax-b|^2是凸函数吗?
凸函数的判断方法有三种:
- 定义法(易画出图形时判断);定义:函数的定义域为凸集,对于定义域里任意x,y,函数满足:
f ( θ x + ( 1 − θ ) y ) ≤ θ f ( x ) + ( 1 − θ ) f ( y ) , θ ∈ [ 0 , 1 ] f(\theta x+(1-\theta )y) \leq \theta f(x)+(1-\theta)f(y), \theta \in[0,1] f(θx+(1−θ)y)≤θf(x)+(1−θ)f(y),θ∈[0,1]
即任意x和y两点的连线上的值大于等于函数上的值,即为凸函数。
这里即可判断log x,Ax+b均为凸函数; - 一阶导数判断(不常用):假设函数在定义域内可导,当且仅当 f ( y ) ≥ f ( x ) + ∇ ( x ) T ( y − x ) f(y) \geq f(x)+\nabla(x)^T(y-x) f(y)≥f(x)+∇(x)T(y−x)
- 二阶判断:假设函数在定义域内二阶可导,则当且仅当:
∇
2
f
(
x
)
≥
0
\nabla ^2f(x) \geq 0
∇2f(x)≥0时,f为凸函数;
如果求二阶导后为一个具体的数,这个数大于等于0即为凸函数;如果求出的是一个矩阵,则矩阵正定的话,即为凸函数;
对于二次函数 ∣ A x − b ∣ 2 |Ax-b|^2 ∣Ax−b∣2来说,求完二阶导等于2|A|,因为|A|大于等于0,故原函数为凸函数。
9. 利用chain rule来分解联合概率 p(x1, x2, x3, x4, x5)
p ( x 1 , x 2 , x 3 , x 4 , x 5 ) = p ( x 5 ∣ x 1 , x 2 , x 3 , x 4 ) ∗ p ( x 4 ∣ x 1 , x 2 , x 3 ) ∗ p ( x 3 ∣ x 1 , x 2 ) ∗ p ( x 2 ∣ x 1 ) ∗ p ( x 1 ) p(x1,x2,x3,x4,x5)=p(x5|x1,x2,x3,x4)*p(x4|x1,x2,x3)*p(x3|x1,x2)*p(x2|x1)*p(x1) p(x1,x2,x3,x4,x5)=p(x5∣x1,x2,x3,x4)∗p(x4∣x1,x2,x3)∗p(x3∣x1,x2)∗p(x2∣x1)∗p(x1)
10. 什么是KL-Divergence,写出它的数学细节,什么时候需要用到它?
机器学习基础
自然语言处理
数据结构与算法相关
1. 快速排序算法
请实现快速排序算法,自行设计测试用例来说明算法的准确性,算法的时间和空间复杂度是多少?最坏的时间复杂度是多少?
快排是每次从当前考虑的数组中选择一个元素,以这个元素为基点,之后把这个元素放在它排好序后应该处的位置上。
比如对数组:[4,6,2,3,1,5,7,8]排序,首先先要把4这个元素放在已经排序好的位置上,此时该元素就都具有了一个性质:即4之前的所有元素都是小于4的,4之后的所有元素都是大于4的。
接下来所做的事情,就是对当前排好序的元 素4之前和之后的部分,继续递归的进行上述过程,直至每个元素都排好序。
那么问题就是两个方面:
1. 如何将遍历的元素放在已经排序好的位置上;
2. 如何定义元素已经排好序;
通常选择第一个元素v作为基准点,索引记作i,之后遍历未访问的元素,在遍历的过程中,逐渐的移动位置,把当前访问的元素记为i, 小于v和大于v的分界点的索引位置叫做j。
当i指的元素比v还要大时,让i++,将其放在大于v的区间中;
当i指的元素比v小时,则将j所指的后一个元素与i指的元素进行交换,再让j++,i ++,进而考察下一个;
2. 归并排序算法
请实现归并排序,自行设计测试用例来说明算法的准确性,算法的时间和空间复杂度是多少?最坏的时间复杂度是多少?

