
- 1osg示例解析之osgcamera_osg camera
- 2Django框架之websocket交互_django websocket 页面交互
- 3【超详细教程】云端部署AI换脸开源工具FaceFusion(内附超详细的AI工具使用指南)
- 4(2022|ECCV,图像分割,VQ-SEG,AR Transformer)Make-A-Scene:利用人类先验进行基于场景的文本到图像生成_make-a-scene: scene-based text-to-image generation
- 5今天,纯血鸿蒙开放申请!
- 6Nextcloud激活被锁用户
- 7鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之Swiper容器组件
- 8uniapp的配置文件、入口文件、主组件、页面管理部分
- 9extjs 表格数据重新加载_extjs中Store和grid的刷新问题
- 10基于CentOS 7.6(1810)的OpenStackT版部署教程_centos7 openstack t http
【自然语言处理】大模型高效微调:PEFT 使用案例_peftmodel
赞
踩
一、PEFT介绍
PEFT(Parameter-Efficient Fine-Tuning,参数高效微调),是一个用于在不微调所有模型参数的情况下,高效地将预训练语言模型(PLM)适应到各种下游应用的库。
PEFT方法仅微调少量(额外的)模型参数,显著降低了计算和存储成本,因为对大规模PLM进行完整微调的代价过高。最近的最先进的PEFT技术实现了与完整微调相当的性能。
代码:
https://github.com/huggingface/peft
- 1
文档:
https://huggingface.co/docs/peft/index
- 1
二、PEFT 使用
接下来将展示 PEFT 的主要特点,并帮助在消费设备上通常无法访问的情况下训练大型预训练模型。您将了解如何使用LoRA来训练1.2B参数的bigscience/mt0-large模型,以生成分类标签并进行推理。
2.1 PeftConfig
每个 PEFT 方法由一个PeftConfig类来定义,该类存储了用于构建PeftModel的所有重要参数。
由于您将使用LoRA,您需要加载并创建一个LoraConfig类。在LoraConfig中,指定以下参数:
- task_type,在本例中为序列到序列语言建模
- inference_mode,是否将模型用于推理
- r,低秩矩阵的维度
- lora_alpha,低秩矩阵的缩放因子
- lora_dropout,LoRA层的dropout概率
from peft import LoraConfig, TaskType
peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)
- 1
- 2
- 3
有关您可以调整的其他参数的更多详细信息,请参阅LoraConfig参考。
2.2 PeftModel
使用 get_peft_model() 函数可以创建PeftModel。它需要一个基础模型 - 您可以从 Transformers 库加载 - 以及包含配置特定 PEFT 方法的PeftConfig。
首先加载您要微调的基础模型。
from transformers import AutoModelForSeq2SeqLM
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
- 1
- 2
- 3
- 4
- 5
使用get_peft_model函数将基础模型和peft_config包装起来,以创建PeftModel。要了解您模型中可训练参数的数量,可以使用print_trainable_parameters方法。在这种情况下,您只训练了模型参数的0.19%!
from peft import get_peft_model
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# 输出示例: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282
- 1
- 2
- 3
- 4
- 5
至此,我们已经完成了!现在您可以使用Transformers的Trainer、 Accelerate,或任何自定义的PyTorch训练循环来训练模型。
2.3 保存和加载模型
在模型训练完成后,您可以使用save_pretrained函数将模型保存到目录中。您还可以使用push_to_hub函数将模型保存到Hub(请确保首先登录您的Hugging Face帐户)。
model.save_pretrained("output_dir")
# 如果要推送到Hub
from huggingface_hub import notebook_login
notebook_login()
model.push_to_hub("my_awesome_peft_model")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这只保存了已经训练的增量PEFT权重,这意味着存储、传输和加载都非常高效。例如,这个在RAFT数据集的twitter_complaints子集上使用LoRA训练的bigscience/T0_3B模型只包含两个文件:adapter_config.json和adapter_model.bin,后者仅有19MB!
使用from_pretrained函数轻松加载模型进行推理:
from transformers import AutoModelForSeq2SeqLM
from peft import PeftModel, PeftConfig
peft_model_id = "smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, peft_model_id)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
三、PEFT支持任务
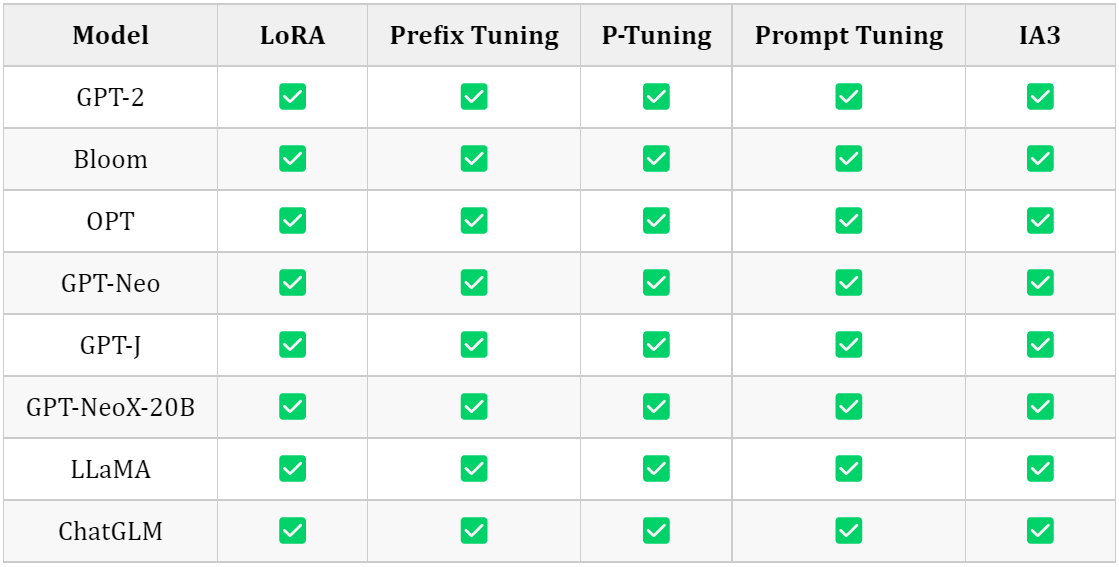
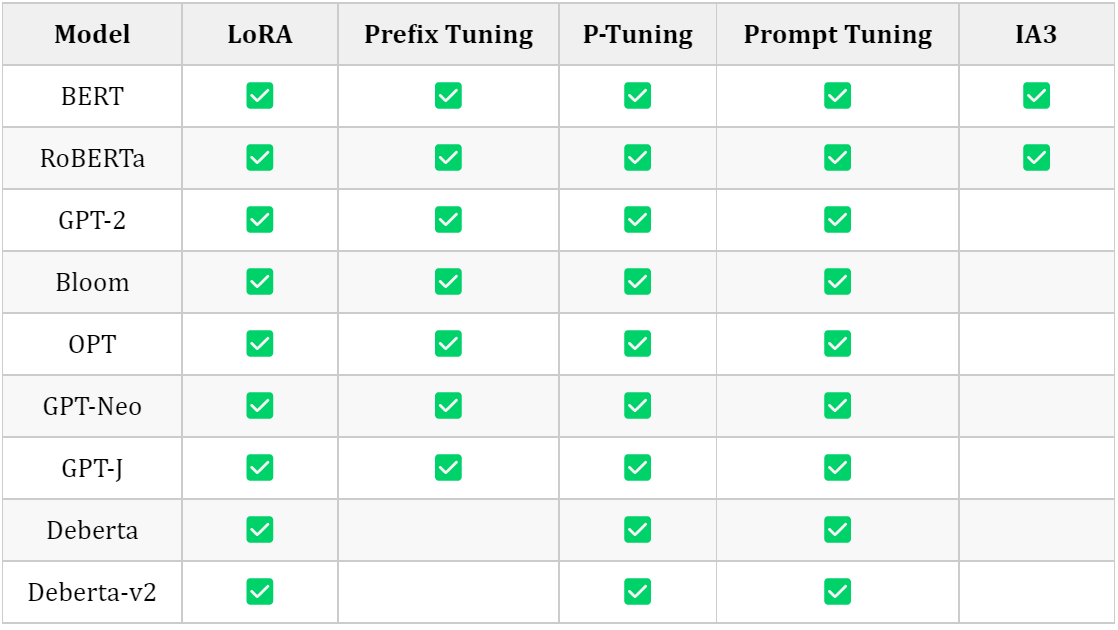
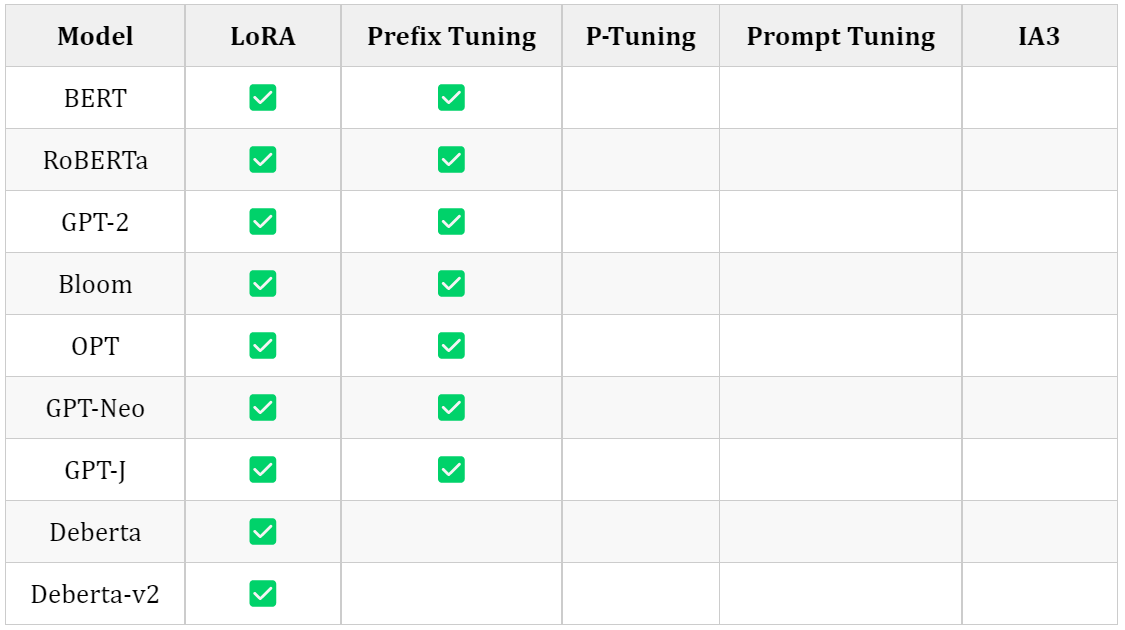
3.1 Models support matrix
3.1.1 Causal Language Modeling
3.1.2 Conditional Generation

3.1.3 Sequence Classification
3.1.4 Token Classification
3.1.5 Text-to-Image Generation

3.1.6 Image Classification

3.1.7 Image to text (Multi-modal models)

四、PEFT原理
4.1 LoRA
LoRA(Low-Rank Adaptation)是一种技术,通过低秩分解将权重更新表示为两个较小的矩阵(称为更新矩阵),从而加速大型模型的微调,并减少内存消耗。
为了使微调更加高效,LoRA的方法是通过低秩分解,使用两个较小的矩阵(称为更新矩阵)来表示权重更新。这些新矩阵可以通过训练适应新数据,同时保持整体变化的数量较少。原始的权重矩阵保持冻结,不再接收任何进一步的调整。为了产生最终结果,同时使用原始和适应后的权重进行合并。
4.2 Prompt tuning
训练大型预训练语言模型是非常耗时且计算密集的。随着模型尺寸的增长,越来越多的人对更高效的训练方法产生了兴趣,例如提示(Prompting)。提示通过包括描述任务的文本提示或甚至演示任务示例的文本提示来为特定的下游任务准备一个冻结的预训练模型。通过使用提示,您可以避免为每个下游任务完全训练单独的模型,而是使用相同的冻结预训练模型。这更加方便,因为您可以将同一模型用于多个不同的任务,而训练和存储一小组提示参数要比训练所有模型参数要高效得多。
提示方法可以分为两类:
- 硬提示(Hard Prompts):手工制作的具有离散输入标记的文本提示;缺点是需要花费很多精力来创建一个好的提示。
- 软提示(Soft Prompts):可与输入嵌入连接并进行优化以适应数据集的可学习张量;缺点是它们不太易读,因为您不是将这些“虚拟标记”与实际单词的嵌入进行匹配。
4.3 IA3
为了使微调更加高效,IA3(通过抑制和放大内部激活来注入适配器)使用学习向量对内部激活进行重新缩放。这些学习向量被注入到典型的基于Transformer架构中的注意力和前馈模块中。这些学习向量是微调过程中唯一可训练的参数,因此原始权重保持冻结。处理学习向量(而不是像LoRA一样对权重矩阵进行学习的低秩更新)可以大大减少可训练参数的数量。
与LoRA类似,IA3具有许多相同的优点:
- IA3通过大大减少可训练参数的数量使微调更加高效(对于T0模型,IA3模型仅具有约0.01%的可训练参数,而即使是LoRA也有超过0.1%)。
- 原始的预训练权重保持冻结,这意味着您可以在其之上构建多个轻量级和便携的IA3模型,用于各种下游任务。
- 使用IA3进行微调的模型性能与完全微调的模型性能相当。
- IA3不会增加任何推理延迟,因为适配器权重可以与基础模型合并。

