
- 1神经网络优化算法(梯度下降)总结与分析_神经网络中梯度下降收敛性分析
- 2案例实战:Python实现逻辑回归(Logistic Regression)与梯度下降策略_logistic regression python
- 3extJs 2.1 学习笔记(Ext.data.HttpProxy篇)_ext.js httpproxy
- 4鸿蒙开发arkTS组件间的数据共享_鸿蒙子组件从父子组件之间双向数据同步
- 5http和socks5代理哪个好?
- 6react-draggable报错:Module parse failed: Unexpected token_./node_modules/react-draggable/build/cjs/draggable
- 7【禅与计算机程序设计艺术】7 大程序设计原则_程序代码设计原则
- 8grub关于linux与initrd、linuxefi与initrdefi、grud.d模板的一些记录_error: cant find command “linux” error: cant find
- 9java数组游戏_带你走进Java数组世界
- 10电视上设置禁止安装不是从Android,海信电视禁止安装第三方软件怎么办?当贝市场教你解决方法!...
ChatGPT也在评审你的顶会投稿,斯坦福新研究捅了马蜂窝,“这下闭环了”
赞
踩
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
尴了个大尬!
人们还在嘲讽有人用ChatGPT写论文忘了删掉“狐狸尾巴”,另一边审稿人也被曝出用ChatGPT写同行评论了。
而且,还是来自ICLR、NeurIPS等顶会的那种。
来自斯坦福的学者对一些顶级AI会议(如ICLR、NeurIPS、CoRL等)中的审稿意见进行了分析,结果发现——
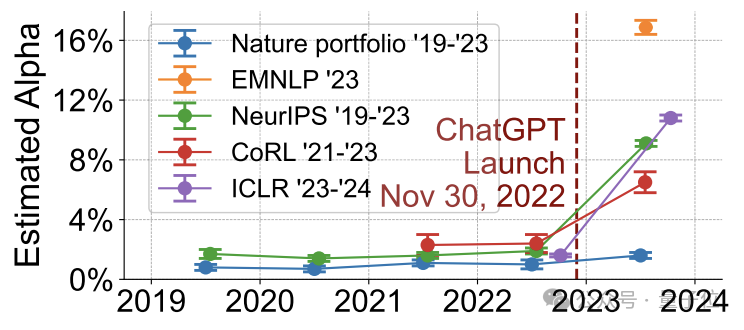
在ChatGPT出现之后,这些同行评论的“AI含量”大增,最多的高达16.9%,而有ChatGPT之前这个比例大约是2%。
证据也很直观,AI常用的词汇出现频率,在ChatGPT发布之后噌的一下就上去了。
消息一出,Reddit的机器学习板块立刻就炸了锅,有网友直呼:闭环了!
在X上,也有人发出了同样的疑问:
既然写论文和审稿都是大模型在干,那科学家去干什么了?

那么,这究竟是怎么一回事呢?
顶会审稿意见AI含量超1/6
来自斯坦福大学多个学院以及加州大学圣芭芭拉分校的研究人员发表了一项研究,主题是关于ChatGPT对AI学术会议同行评审的影响。
研究人员一共分析了ICLR、NeurIPS、CoRL和EMNLP这四个顶会中的同行评审意见,对其“AI含量”进行了计算。
ICLR 2024: 估计α值为10.6%
NeurIPS 2023: 估计α值为9.1%
CoRL 2023: 估计α值为6.5%
EMNLP 2023: 估计α值为16.9%,超过了1/6
α值指在所有内容中疑似由AI生成或“显著修改”的内容所占的比例
而在ChatGPT问世之前,α值的水平大约是在2%,作为对照的Nature系列期刊评审意见的α值则未发生显著变化。
除了得出这些数据,研究人员还发现了“AI含量”较高的评审意见大多具有一些共同特点。
从内容角度上看,“AI含量”高的意见,引用的作者中包括“et al.”的学术内容也较少。
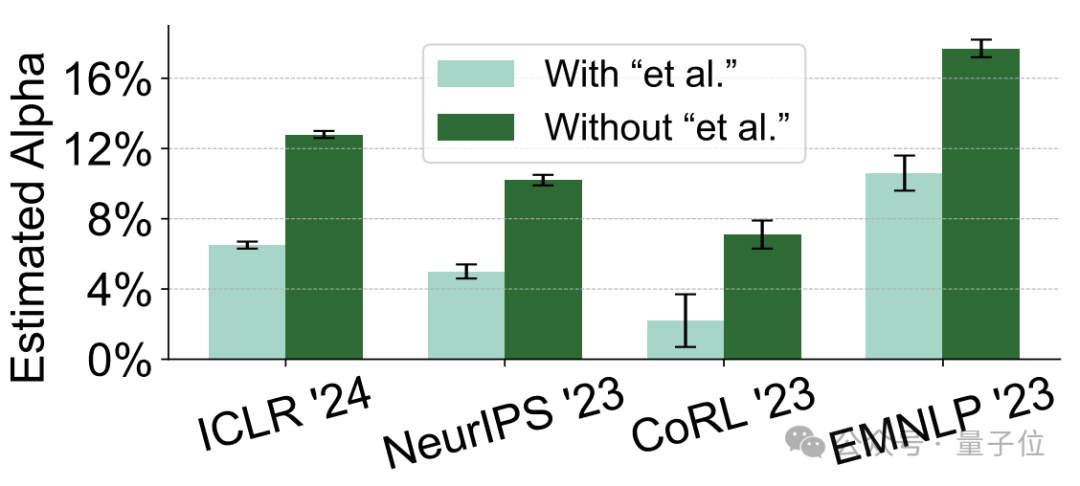
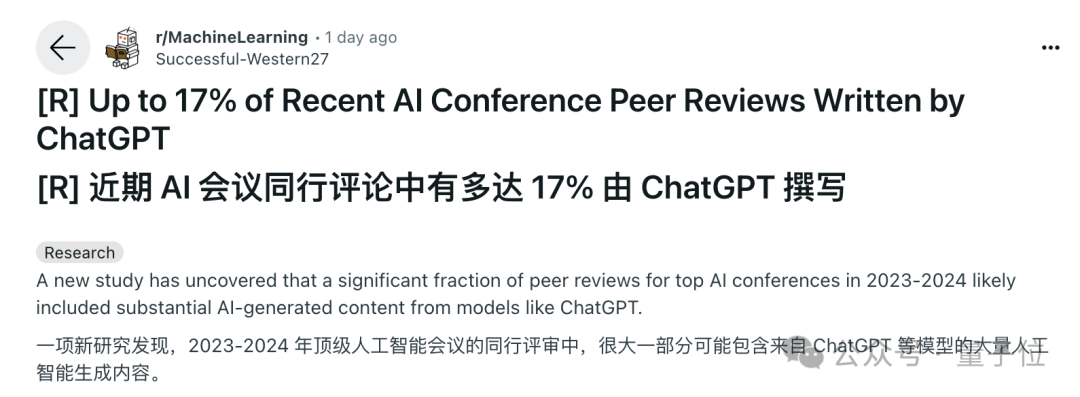
而且,“AI含量”高的内容,在语义上也更加同质化,比如“commendable”(值得称赞的)、“meticulous”(细致的)和“intricate”(复杂的)等形容词大量出现。
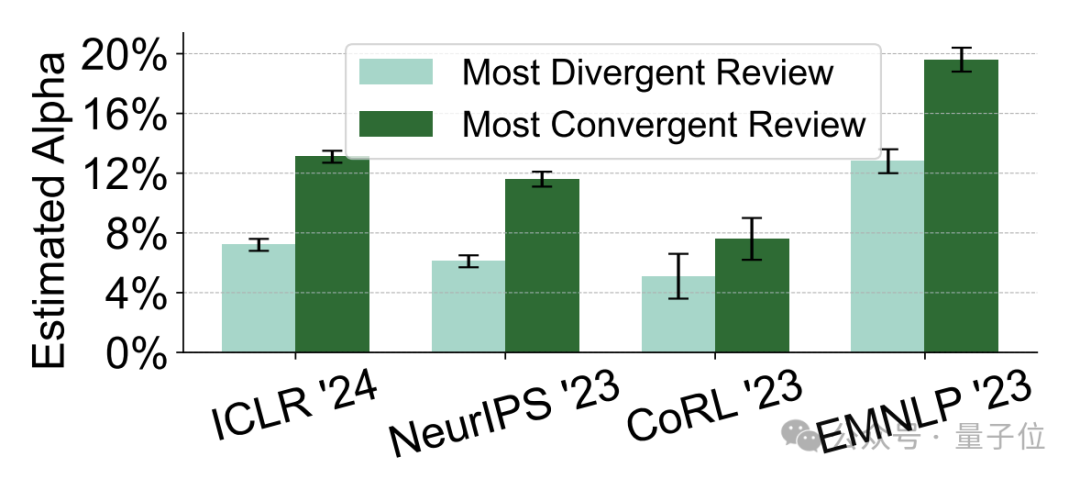
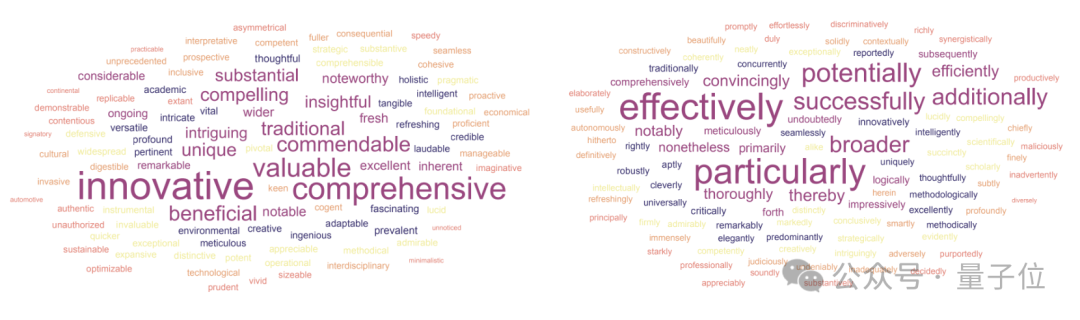
同时作者也展示了在AI生成的内容中出现最频繁的形容词和副词各100个,下图中字号越大代表出现频率越高。
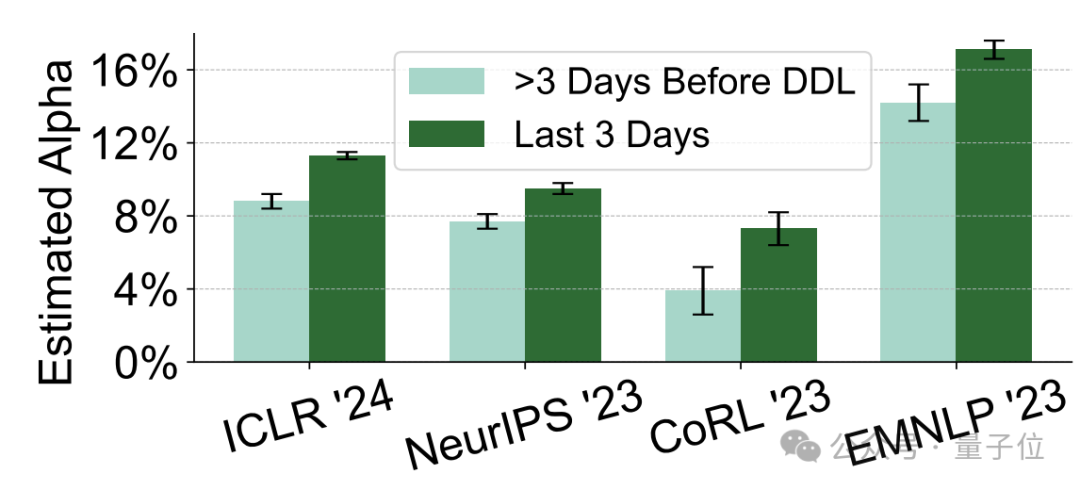
而除了内容本身,高”AI含量“的内容的作者在行为上也表现出了一些共同之处。
一是提交的时间更加接近截止期限,特别是截止前三天提交的意见“AI含量”明显更高。
除了提交时间晚,高“AI含量”意见的作者,普遍对自己提交的内容自信程度也更低。
评审者对自己评审意见信心水平的自我评估(满分5分)结果显示,“AI含量”较高的审稿人,自我评分也更低(不大于2分)。
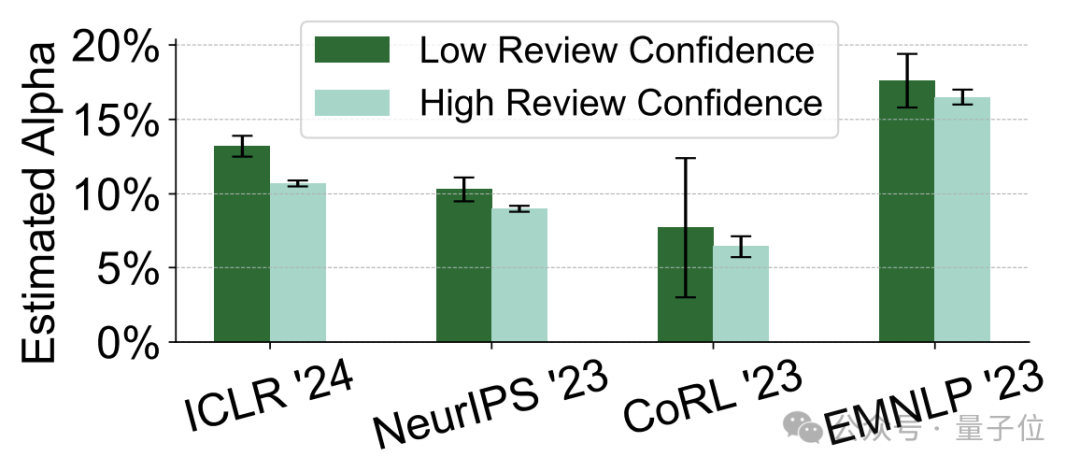
此外,对自己的审稿意见自信程度低的另一个表现是,他们也较少对论文作者反驳做出回应。
在ICLR 2024和NeurIPS 2023上,这类审稿人中有超过12.5%从未对反驳意见做出任何回复,约10%只回复了一次。
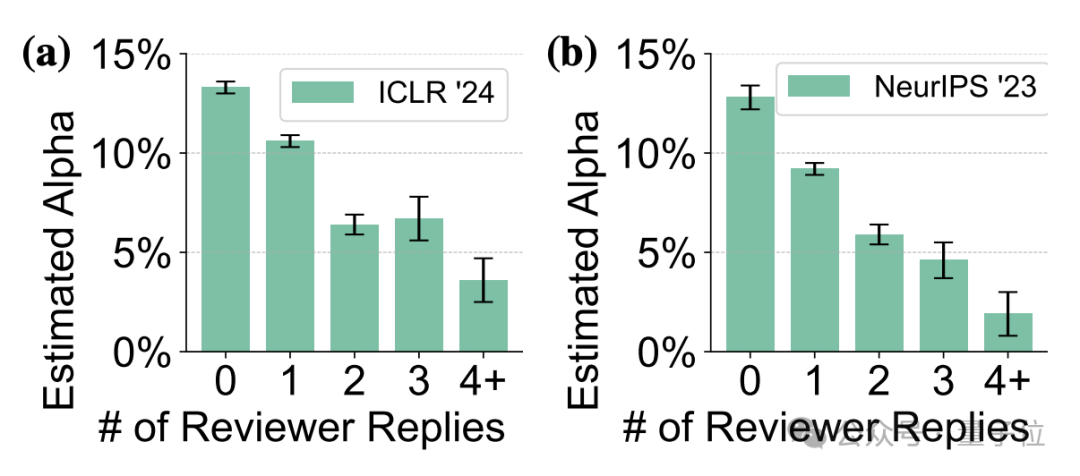
那么,作者又是如何分析出这些审稿意见中的AI含量的呢?
为此,研究人员设计了一种分布式“GPT量化”方法,能够在语料库级别有效估计AI含量,而不必逐篇分析。
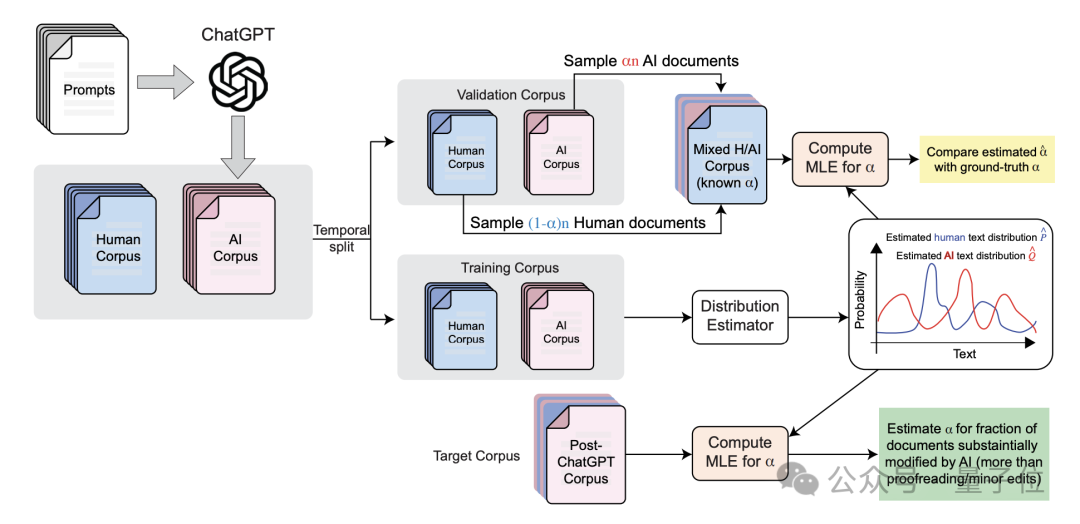
首先,研究人员收集了已知由人类编写(ChatGPT出现前的审稿意见)和AI生成(由研究者直接用ChatGPT编写)的文本的数据集,作为参考分布。
然后,作者估计了人工编写的(P)和AI生成(Q)的内容的token分布,尤其重点关注形容词的出现概率。
最后将这种分布模型拟合到未知成分的目标语料库,假设每个文档都是从人类和人工智能分布的加权组合中,即(1-α)P+αQ,并使用最大似然估计来推断α的值。
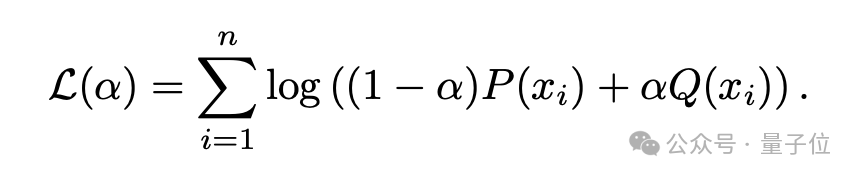
完成方法的构建之后,研究者又合成了多组α值确定的标准数据集,并在此之上对前面提出的方法进行了验证,结果最大误差仅有2.4%。
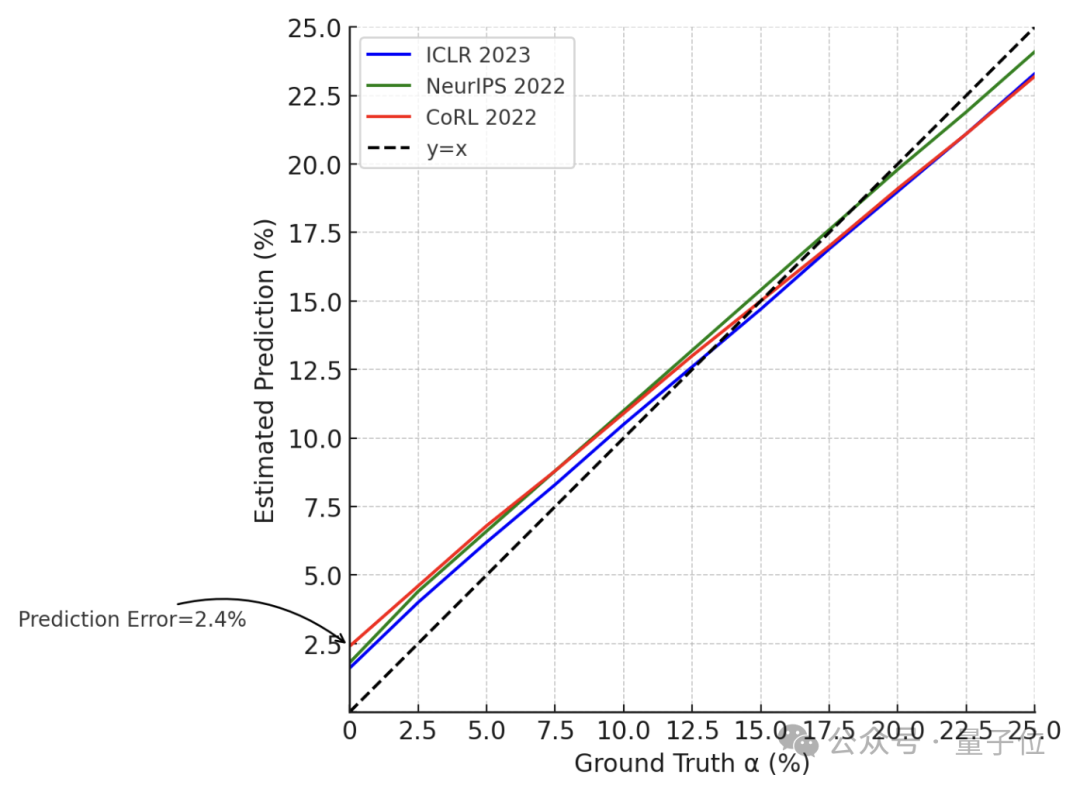
于是,作者使用该方法分析了最近几个会议中的审稿意见,最终得到了前面的结论。
而当这项研究被更多人所得知后,引发了广泛的讨论,其中有不少人对这种现象表达了担忧。
不过,也有人猜测出现这种现象的原因,可能是审稿人母语不是英语,于是用ChatGPT对英文写作进行了调整润色。

基于此,有人提问到,用ChatGPT来改写而不是直接生成评论也是错的吗?

有人给出了半肯定的答复,但理由不是关乎原创性,而是出于对文本质量的担忧,人们还是应该谨慎使用ChatGPT。

当然也有人说,科学写作,本身就是ChatGPT的一种合理用途。

总之对于这件事,担忧也好宽容也罢,这种现象都已然存在了,而按照原作者的观点,这几个问题是人们应该思考的:
是否应该披露AI在同行评审中的使用
在AI极具诱惑力的情况下,应该如何激励好的实践
在人工智能同质化的境地下,人们能否保持“智力多样性”
是否应该重新考虑人类/AI混合知识工作的可信度
当然了,在学术界,ChatGPT生成的内容,还远不只是审稿意见。
论文作者也爱用
除了审稿人被曝用ChatGPT写评论之外,拿它来写论文的人更是屡见不鲜……
在谷歌学术中搜索2023年及以后包含“certainly, here is”这种ChatGPT常用开头的论文,剔除直接包含“ChatGPT”和“LLM”的论文后,结果共有50余篇。
随机翻阅其中的几篇,果然是发现了ChatGPT的使用痕迹,ChatGPT在这些论文中被用做了总结、翻译、制作表格等多种用途。

甚至其中还包括正式出版的论文合集:

而另一个ChatGPT常用句式“As of my Last Knowledge Update”,在相同条件下的搜索结果有114条。

而且出现形式上也更加离谱,“Certainly组”当中至少还有一些只是用ChatGPT做了些辅助工作,“As of my…”这一组干脆直接拿来搞正文内容了。

此外,“As an AI language model, I”也有40多条搜索结果,不过也不排除其中有误伤的情况出现。

当然要论离谱,可能还要属这种把ChatGPT的按钮“Regenerate Response”也一起复制进去的了,而且数量还不算少,有将近一百篇。

露出鸡脚马脚被发现的论文数量尚且如此,删去了这些关键字从而“躲过一劫”的究竟有多少,就更是不得而知了。
当然,并不是说研究者不能使用ChatGPT来辅助论文撰写,包括Elsevier、Springer(Nature出版商)在内的许多知名出版机构都表示并不禁止ChatGPT的使用,只要进行声明即可。
总之,无论是论文本身还是审稿意见,亦或是其他文本写作,如何以更合理的方式运用AI,值得人们继续深入思考。
论文地址:
https://arxiv.org/abs/2403.07183

