
- 1IntelliJ IDEA总结(2) -- IntelliJ IDEA中git导入项目不显示maven侧边栏的问题及解决方法_git 显示maven
- 2SD相见恨晚的提示词插件,简直堪称神器!_sd最强提示词插件
- 3小区停车计费管理系统(1)(源码+开题)
- 4JAVA利用websocket实现多人聊天室、私信(附源码)_java实现聊天室框架图 有房间概念
- 5android 超链接是什么意思,Android TextView与HTML结合以及设置超链接
- 6ChatGPT文献综述撰写教程--【数字化转型与企业创新】(附结果数据)_chatgpt写综述
- 7决策树学习笔记整理_采用决策树分类法,预测该客户的拖欠贷款类别
- 8[ 云计算 | AWS 实践 ] Java 应用中使用 Amazon S3 进行存储桶和对象操作完全指南_java amazons3
- 9 Snackbar源码分析
- 10Java集合整理(Arraylist、Vector、Linklist)_arraylsit和linklist和vector
神经网络优化算法(梯度下降)总结与分析_神经网络中梯度下降收敛性分析
赞
踩
梯度下降算法是到目前为止最主流的优化大规模神经网络的算法。近些年来,涌现出了很多基于梯度下降法的优化算法,对推动深度学习的发展起到了重要的作用。本文旨在回顾经典的,当下主流的以及最新出现的梯度下降算法。简单介绍了梯度下降法的三个变种(批梯度下降法、随机梯度下降法以及小批量随机梯度下降法),常见的学习率自适应随机梯度下降算法和其最进的研究进展(带冲量的梯度下降法、Nesterov加速的梯度下降法、AdaGrad、RMSProb、AdaDelta、Adam和Radam)。通过在mnist手写数字数据集上训练全连接神经网络和卷积神经网络进行了测试。读者在阅读过程中若产生任何疑惑,欢迎互相交流。(总结不易,转载请声明,并征得原作者同意)
1 概述
梯度下降算法是到目前为止最主流的优化深度学习的算法。因为通过设置合适的损失函数,我们很容易使神经网络模型变得可微。而对于可微目标函数的优化问题,梯度下降是一个很高效的方法,因为它只需要计算一阶导数,所有的参数都会有相同的计算复杂度。
但是深度学习中优化神经网络模型的问题是高度非凸非线性的。而连续空间中基于梯度的优化算法大多数只适用于凸问题。所以要得到神经网络模型的全局最优,往往要比支持向量机、logistic回归这样的机器学习问题困难很多。在实际应用中,人们常用随机梯度下降法(SGD)来优化神经网络,主要是因为深度学习实际应用中往往数据规模很大,随机算法可以通过减少每次迭代的复杂度进而减少总的复杂度,提升效率。随机梯度下降算法的一个推广就是小批量随机梯度下降。
但是日益增大的数据量以及越来越复杂的神经网络模型,随机梯度下降也显得收敛不够快。近年来,科学家们发现了一类比随机梯度下降法更为复杂并且更加适合训练神经网络的算法。这类算法在更新模型时,不只利用当前的梯度,还会利用历史上的梯度信息或是下一次迭代的信息,并且自适应地调整步长,因而也被称为Ada系列算法。包括带有冲量的随机梯度算法[1]; Nesterov加速的SGD[2];利用历史梯度大小,针对每一维调整步长,进而适用稀疏数据的AdaGrad算法[3], 类似AdaGrad,并且结合了冲量思想的RMSProb算法[4]以及Adadelta[5]和十分流行的Adam算法[6]。这其中以Adam为代表,使用十分广泛。这类算法相较于传统的SGD,在收敛速度上有了大幅的提升,但是遗憾的是在收敛性能上都很难与SGD打成平手。于是人们迫切希望能够找到一种算法,既和Adam等算法一样快,又能收敛到SGD一样好的位置。
自从Reddi et al.[7]在2018年指出了Adam文章中的证明错误之后,自适应地算法研究领域又涌现出了很多优秀算法,如AdaShift[8],NosAdam[9],AdaBound[10],以及最新的Radam[11]。但是大多数算法在收敛性上和SGD还是稍逊一筹。
本文先从SGD算法开始介绍,随后介绍Adam系列算法以及Adam之后的一些Ada算法,并着重介绍Adam算法。
2 梯度下降法
目前主要有三种梯度下降的算法,分别为批梯度下降,随机梯度下降,小批量梯度下降三种。其区别在于使用多少数据对目标函数计算梯度。根据使用数据量的不同会造成我们参数更新得准确性和其使用的时间产生差别。
2.1 批梯度下降法
批梯度下降法又被称为朴素梯度下降法,是最古老的一阶算法,于1847年由Cauchy提出。梯度下降法的基本思想是:最小化目标函数在当前状态的一阶泰勒展开,从而近似地优化目标函数本身。对函数
J
J
J,将其在当前状态
θ
t
\theta_{t}
θt处求解下述问题:
min
θ
J
(
θ
)
=
min
θ
J
(
θ
t
)
+
∇
J
(
θ
t
)
T
(
θ
−
θ
t
)
\min \limits_{\theta} J(\theta)=\min \limits_{\theta} J(\theta_{t})+\nabla J(\theta_{t})^{T}(\theta-\theta_{t})
θminJ(θ)=θminJ(θt)+∇J(θt)T(θ−θt)在机器学习中,是指使用整个训练集的数据来计算目标函数
J
(
θ
)
J(\theta)
J(θ)关于参数
θ
\theta
θ的梯度
∇
θ
J
(
θ
)
\nabla_{\theta}J(\theta)
∇θJ(θ),批梯度下降的参数更新如下:
θ
t
=
θ
t
−
1
−
η
×
∇
θ
J
(
θ
;
x
,
y
)
\theta_{t}=\theta_{t-1}-\eta \times \nabla_{\theta}J(\theta;x,y)
θt=θt−1−η×∇θJ(θ;x,y)
参数更新得伪代码如下:
for i in range(0,epochs):
params_grad = get_gradient(loss,data,params)
params = params-learning_rate * params_grad
- 1
- 2
- 3
批梯度下降法存在以下三点问题:1、参数更新速度慢;2、无法在数据大小超过内存大小时无法使用;3、没法在线上部署。但是批梯度下降的优点在于,如果目标函数是凸函数,那么可以收敛到全局最优。批梯度下降的收敛速度针对不同性质的目标函数是不同的。
2.2 随机梯度下降法
随机梯度下降是使用训练集中的单个元素来计算目标函数
J
(
θ
)
J(\theta)
J(θ)关于参数
θ
\theta
θ的梯度
∇
θ
J
(
θ
)
\nabla_{\theta}J(\theta)
∇θJ(θ),随机梯度下降的参数更新如下:
θ
t
=
θ
t
−
1
−
η
∇
θ
J
(
θ
;
x
(
i
)
,
y
(
i
)
)
\theta_{t}=\theta_{t-1}-\eta \nabla_{\theta}J(\theta;x^{(i)},y^{(i)})
θt=θt−1−η∇θJ(θ;x(i),y(i))这里的
η
\eta
η是学习率。
参数更新得伪代码如下:
for i in range(0,epochs):
np.random.shuffle(data)
for j in data:
params_grad = get_gradient(loss,data[j],params)
params = params-learning_rate * params_grad
- 1
- 2
- 3
- 4
- 5
随机梯度下降用随机采样的数据来计算梯度,是对全部数据来计算梯度的一个无偏估计,如下 E i t ∇ J i t ( θ ) = ∇ θ J ( θ ) \mathbb{E}_{i_{t}}\nabla J_{i_{t}}(\theta)=\nabla_{\theta}J(\theta) Eit∇Jit(θ)=∇θJ(θ)批梯度下降的收敛速度针对不同性质的目标函数是不同的。随机梯度下降每次只随机抽取一个样本,随机梯度中的计算量大大减少。解决了上述批梯度下降存在的一些问题。如果目标函数是凸函数,那么可以收敛到全局最优。但是随机梯度下降法的收敛速度往往比较慢,这是因为随机梯度虽然是全体度的无偏估计,但是这种估计存在一定的方差,会引入不确定性,导致算法收敛速度下降。
2.3 小批量(mini-batch)随机梯度下降法
mini-batch随机梯度下降是对随机梯度下降的一个推广。不同之处在于,SGD的每一次抽样值选取一个样本,而mini-batch SGD每次迭代随机抽取n个样本。
mini-batch随机梯度下降的参数更新如下:
θ
t
=
θ
t
−
1
−
η
×
∇
θ
J
(
θ
;
x
(
i
+
n
)
,
y
(
i
+
n
)
)
\theta_{t}=\theta_{t-1}-\eta \times \nabla_{\theta}J(\theta;x^{(i+n)},y^{(i+n)})
θt=θt−1−η×∇θJ(θ;x(i+n),y(i+n))
参数更新得伪代码如下:
for i in range(0,epochs):
np.random.shuffle(data)
for batch in get_batches(data,batch_size):
params_grad = get_gradient(loss,batch,params)
params = params-learning_rate * params_grad
- 1
- 2
- 3
- 4
- 5
mini-batch随机梯度下降是一种广泛应用在神经网络训练的方法。该方法有效减少了无偏估计的方差,从而提高了收敛速率。
3 自适应随机梯度下降法
自适应随机梯度下降法是一类算法的总称。在模型参数更新时,不只利用当前的梯度,还会用到之前的梯度信息,并且自适应地调整步长。
3.1 Momentum and Nesterov accelerated gradient
带冲量的方法最早于1964年由Polyak提出,被称为传统Classical Momentum(CM)是一种通过累积来梯度进而加速梯度下降的方法。其参数更新方式如下:
v
t
=
μ
v
t
−
1
−
η
∇
J
(
θ
t
−
1
)
v_{t}=\mu v _{t-1}-\eta \nabla J(\theta_{t-1})
vt=μvt−1−η∇J(θt−1)
θ
t
=
θ
t
−
1
+
v
t
\theta_{t}=\theta_{t-1}+v_{t}
θt=θt−1+vt这里的
μ
\mu
μ是冲量系数(mo-
mentum coeffcient)。
Nesterov加速梯度法(NAG)是Nesterov于1983年提出的。和冲量的方法一样,NAG是一个既能保证收敛性并且具有很好的收敛速度的一阶方法。对于一个光滑的凸问题,使用确定性梯度,那么NAG的收敛速率是
O
(
1
/
T
2
)
O(1/T^{2})
O(1/T2)(梯度下降法是
O
(
1
/
T
)
O(1/T)
O(1/T))。NAG的更新方式如下:
v
t
=
μ
v
t
−
1
−
η
∇
J
(
θ
t
−
1
+
μ
v
t
−
1
)
v_{t}=\mu v _{t-1}-\eta \nabla J(\theta_{t-1}+\mu v_{t-1})
vt=μvt−1−η∇J(θt−1+μvt−1)
θ
t
=
θ
t
−
1
+
v
t
\theta_{t}=\theta_{t-1}+v_{t}
θt=θt−1+vt
这两种方法是十分比较相似的,不同之处在于带冲量的随机梯度下降法利用
θ
t
−
1
\theta_{t-1}
θt−1处的梯度进行更新,而NAG是利用
θ
t
−
1
+
μ
v
t
−
1
\theta_{t-1}+\mu v_{t-1}
θt−1+μvt−1处的梯度进行更新。所以从实现上看,后者前者更加简单。
可以通过图1来直观理解两者之间的区别。

其中上面的是冲量加速梯度法,下面的是Nesterov加速梯度法。
3.2 Adagrad
The Adaptive Gradient 算法是John Duch等人于2011年提出[3]。该算法的直觉是,一般梯度比较小的维度对达到最优点也有重要的贡献,但是因为其梯度小,所以更新慢,进而容易到达一个鞍点或者局部最优。所以Adagrad对历史信息(梯度值的平方)进行了累加,并且根据历史梯度逐维度调整步长,使得梯度较小的维度获得更大的步长,其更新公式如下:
g
t
=
g
t
−
1
+
(
∇
J
(
θ
t
−
1
)
2
)
g_{t}=g_{t-1}+(\nabla J(\theta_{t-1})^{2})
gt=gt−1+(∇J(θt−1)2)
θ
t
=
θ
t
−
1
−
η
(
g
t
+
ϵ
)
1
2
∇
J
(
θ
t
−
1
)
\theta_{t}=\theta_{t-1}-\frac{\eta}{(g_{t}+\epsilon)^{\frac{1}{2}}}\nabla J(\theta_{t-1})
θt=θt−1−(gt+ϵ)21η∇J(θt−1)其中的
ϵ
\epsilon
ϵ是一个光滑项,防止分母为零。这个算法更适合优化具有很多局部最优点和鞍点的神经网络模型。而且这种自动调整步长的方法可以使得随机梯度下降法变得更加稳定。
该方法的缺点在于,因为更新公式中的分母项
(
g
t
+
ϵ
)
1
2
(g_{t}+\epsilon)^{\frac{1}{2}}
(gt+ϵ)21随着不断地训练不断变大,所以步长会越来越趋近于零,这一方面会导致最后的收敛速率很低,另一方面会使得无法收敛到足够小的极值。
3.3 RMSProb
RMSProb是Geoff Hinton在他的cs321课程中提出的一个自适应学习率的方法。RMSProb和AdaGrad类似,
区别在于该方法还借鉴了带冲量的随机梯度下降法的思路,对历史信息进行了指数递减平均。其更新公式如下:
E
[
g
t
2
]
=
γ
E
[
g
t
−
1
2
]
+
(
1
−
γ
)
∇
J
(
θ
t
−
1
)
2
\mathbb{E}[g_{t}^{2}]=\gamma \mathbb{E}[g_{t-1}^{2}]+(1-\gamma) \nabla J(\theta_{t-1})^{2}
E[gt2]=γE[gt−12]+(1−γ)∇J(θt−1)2
θ
t
=
θ
t
−
1
−
η
(
E
[
g
t
2
]
+
ϵ
)
1
2
∇
J
(
θ
t
−
1
)
\theta_{t} = \theta_{t-1}-\frac{\eta}{(\mathbb{E}[g_{t}^{2}]+\epsilon)^{\frac{1}{2}}}\nabla J(\theta_{t-1})
θt=θt−1−(E[gt2]+ϵ)21η∇J(θt−1)
从
g
t
g_{t}
gt的更新公式可以看出,RMSProb算法类似于对历史信息
γ
g
t
−
1
\gamma g_{t-1}
γgt−1和当下的梯度信息
∇
J
(
θ
t
−
1
)
2
\nabla J(\theta_{t-1})^{2}
∇J(θt−1)2做了一个加权
平均,减少了历史信息所占的比重,加强了当前梯度的占比,避免了AdaGrad步长随着迭代次数增加逐渐趋于0的问题。
而权重
γ
\gamma
γ推荐设置为0.9。
RMSProb方法之所以这样命名的原因是,我们观察参数迭代公式中的分母项可以发现其刚好是梯度
g
g
g的均方根误差(root mean square error),所以我们将该方法命名为RMSProb。
3.4 AdaDelta
AdaDelta算法于2012年由Zeiler M D等人提出,在RMSProb的基础上进一步对累加的历史信息根据梯度的大小进行调整。在RMSProb中,每一次参数更新得大小是:
Δ
θ
t
=
−
η
(
E
[
g
t
2
]
+
ϵ
)
1
2
∇
J
(
θ
t
−
1
)
=
−
η
R
M
S
[
g
t
2
]
∇
J
(
θ
t
−
1
)
E
[
Δ
θ
t
2
]
=
γ
E
[
Δ
θ
t
−
1
2
]
+
(
1
−
γ
)
(
Δ
θ
t
)
2
3.5 Adam
自适应动量估计法是另一种逐维度调节步长的算法。Adam同时以下两个辅助变量,并且分别按照指数衰减形式来累加梯度和梯度的平方:
m
t
=
β
1
m
t
−
1
+
(
1
−
β
1
)
g
t
m_{t}=\beta_{1}m_{t-1}+(1-\beta_{1})g_{t}
mt=β1mt−1+(1−β1)gt
v
t
=
β
2
v
t
−
1
+
(
1
−
β
2
)
g
t
2
v_{t}=\beta_{2}v_{t-1}+(1-\beta_{2})g_{t}^{2}
vt=β2vt−1+(1−β2)gt2
m
t
m_{t}
mt和
v
t
v_{t}
vt可以看做是对梯度的均值和偏心方差的一个估计,并且作者提出可以通过以下的才做来消除估计的误差:
m
t
^
=
m
t
1
−
β
1
t
\hat{m_{t}}=\frac{m_{t}}{1-\beta_{1}^{t}}
mt^=1−β1tmt
v
t
^
=
v
t
1
−
β
2
t
\hat{v_{t}}=\frac{v_{t}}{1-\beta_{2}^{t}}
vt^=1−β2tvt则参数值的更新就会变为如下:
θ
t
=
θ
t
−
1
−
η
m
t
^
v
^
t
1
2
+
ϵ
\theta_{t}=\theta_{t-1}-\frac{\eta \hat{m_{t}}}{\hat{v}_{t}^{\frac{1}{2}}+\epsilon}
θt=θt−1−v^t21+ϵηmt^作者对于参数
β
1
\beta_{1}
β1,
β
2
\beta_{2}
β2推荐设置为0.9和0.99,
ϵ
\epsilon
ϵ设置为
1
0
−
8
10^{-8}
10−8。
β
1
\beta_{1}
β1和
β
2
\beta_{2}
β2之所以这样设置是因为作者发现在刚开始的时间点,估计有较大偏差,所以要尽快逃出。一般在实践中,Adam是效果最好的。这是因为Adam结合了带冲量的随机梯度下降法、AdaGrad、RMSProb以及AdaDelta等算法中的所有因素:
- 更新方向由历史梯度决定。
- 对步长运用累加梯度的平方值进行修正。
- 信息累加按照指数形式衰减。
但是Radam也不是完美的,在训练的初期因为样本的缺少, Adam中的 v t v_{t} vt方差会非常大。而 v t v_{t} vt起到修正更新方向的作用,因此 Adam 参数的更新量的方差也会很大,进而容易落入一些局部最小值。
3.6 Radam
Radam是2019年由Liyuan Liu提出的,一种能够在训练初始阶段避免方差的方法。该方法直觉上可以看成一种‘预热’。所谓预热,是指训练的学习率在最初保持很小,然后逐渐增加的过程。这是因为在训练初期存在一个较大的方差,为了避免进入局部极值,或者造成‘过拟合’,需要用小一些的学习率,但是随着方差逐渐变小,就可以使得学习率增大。Radam的思路就是先找到一个
V
a
r
(
v
t
)
Var(v_{t})
Var(vt)的函数,随后计算其线性插值权重
r
t
r_{t}
rt,然后根据
r
t
r_{t}
rt对学习率进行修正。作者定义了
ρ
∞
=
2
1
−
β
2
0
−
1
\rho_{\infty}=\frac{2}{1-\beta_{2}^{0}}-1
ρ∞=1−β202−1,参数更新方式如下:
m
t
=
β
1
m
t
−
1
+
(
1
−
β
1
)
g
t
m_{t}=\beta_{1}m_{t-1}+(1-\beta_{1})g_{t}
mt=β1mt−1+(1−β1)gt
v
t
=
β
2
v
t
−
1
+
(
1
−
β
2
)
g
t
2
v_{t}=\beta_{2}v_{t-1}+(1-\beta_{2})g_{t}^{2}
vt=β2vt−1+(1−β2)gt2
m
t
^
=
m
t
1
−
β
1
t
\hat{m_{t}}=\frac{m_{t}}{1-\beta_{1}^{t}}
mt^=1−β1tmt
ρ
t
=
ρ
∞
−
2
t
β
2
t
1
−
β
2
t
\rho_{t}=\rho_{\infty}-\frac{2t\beta_{2}^{t}}{1-\beta_{2}^{t}}
ρt=ρ∞−1−β2t2tβ2t
当方差是可控的时,即
ρ
t
>
4
\rho_{t}>4
ρt>4:
r
t
=
(
(
ρ
t
−
4
)
(
ρ
t
−
2
)
ρ
∞
(
ρ
∞
−
4
)
(
ρ
∞
−
4
)
ρ
t
)
1
2
r_{t}=(\frac{(\rho_{t}-4)(\rho_{t}-2)\rho_{\infty}}{(\rho_{\infty}-4)(\rho_{\infty}-4)\rho_{t}})^{\frac{1}{2}}
rt=((ρ∞−4)(ρ∞−4)ρt(ρt−4)(ρt−2)ρ∞)21
θ
t
=
θ
t
−
1
−
η
r
t
m
t
^
(
1
−
β
2
t
v
t
)
1
2
\theta_{t}=\theta_{t-1}-\eta r_{t}\hat{m_{t}}(\frac{1-\beta_{2}^{t}}{v_{t}})^{\frac{1}{2}}
θt=θt−1−ηrtmt^(vt1−β2t)21
否则直接按照带冲量随机梯度下降法:
θ
t
=
θ
t
−
1
−
η
m
t
^
\theta_{t} = \theta_{t-1}-\eta \hat{m_{t}}
θt=θt−1−ηmt^
该方法在一些应用场景下收敛性可以优于Adam,并且该方法具有很好的稳定性。
4 实验
我们选用了全连接神经网络和卷积神经网络在mnist数据集上对上述的优化器进行了测试。优化器的参数选择按照了推荐的默认值。
4.1 全连接神经网络
全连接神经网络是十分基础却很重要的模型。这是使用的网络结构主要包括两个隐藏层。batch size统一设置为15。测试集的准确度随着不同epoch的变化如图2所示:

左图是整个训练的结果,右图是后50个epoch的结果
测试集的损失函数的值随着不同epoch的变化如图3所示:

通过观察上述结果,最新提出的Radam的方法不论在收敛性还是收敛速度上表现最佳。而adam算法却未曾表现最差,这是因为我们选用的batch size过小,并且选择的学习率较大。这就使得方差较大,进而导致adam优化器进入了局部极小值。观察曲线趋势,可以看到SGD with momentum和NAG表现得十分接近,但是NAG要优于SGD with momentum。RMSProb的收敛速度很快。而AdaGrad和AdaDelta表现得较差,前者可能是因为到最后因为不断累加导致步长较小,而后者可能收敛速度不够,导致还未达到最优点。SGD算法表现出来最慢的收敛速度,直到300个epoch仍然未达到最优点。
4.2 卷积神经网络
这里使用了传统的卷积神经网络对上述的其中优化算法在mnist手写数字数据集上进行了测试。相较于全连接神经网络,结构更加复杂。这里的卷积神经网络使用了两个卷积层加两个全连接层的结构,batch size统一设置为128。测试集的准确度随着不同epoch的变化如图2所示:

测试集的损失函数的值随着不同epoch的变化如图3所示:
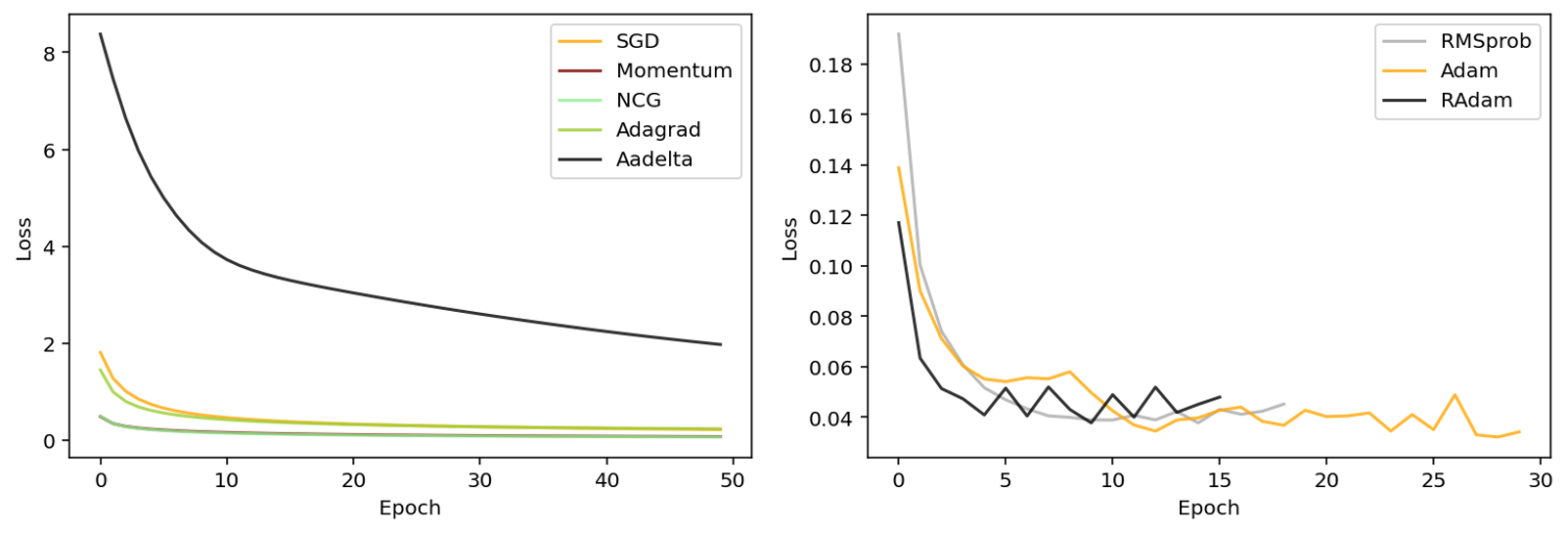
通过观察上述结果,最新提出的Radam的方法在收敛速度上表现得最佳,其次为Adam和RMSProb,这三者在第一梯队。接着是SGD with momentum和NCG,后者的收敛速度略高于前者。随后是SGD和AdaGrad,前者的收敛速度在前期略慢于后者,但到了后期,SGD的收敛速度慢慢超过AdaGrad,这是因为后者的步长随着不断迭代,逐渐趋近于0。Adadelta的收敛速度在这里表现得最慢。就收敛性来看,理论上SGD是最高的,但是由于收敛速度过慢,未达到最优点,所有的方法中只有第一梯队的三种算法达到最优点,表现的基本近似。需要注意的是,在达到最优点的领域内后,由于这三种算法的步长过大,导致其走出点了最优点,并达到了另一个局部最优。
5 总结与展望
大规模神经网络的优化是一个热门并且很有意义的研究方向,目前实际应用中的主流还是Adam家族算法。但是虽然Adam家族算法在收敛速度上表现很好,但是在收敛性上还是很难与SGD打成平手。但是让人欣喜的是,最近涌现出的一些优化算法在某些特定类型任务上展现出很好的效果。目前对Ada算法进行warmup还缺乏理论基础,这是一个比较大的欠缺。另外还是希望能够看到具有颠覆性的算法出现。

