
- 1【开题报告】Springboot大学生创新创业项目管理60qsr计算机毕业设计_java项目springboot 大学生创新创业项目论文开题报告
- 2微调Llama2自我认知_self_cognition 数据集
- 3【MATLAB源码-第176期】基于matlab的16QAM调制解调系统频偏估计及补偿算法仿真,对比补偿前后的星座图误码率。
- 4强强联手,丝滑办公新体验!IdeaHub+华为云会议实测_华为idea hub接入
- 5第九层(16):STL终章——常用集合算法
- 6互联网架构演变过程_网络结构演进的过程
- 7图文带你彻底弄懂MySQL事务原子性之UndoLog_mysql undolog 原子性
- 8CVPR-2020笔记 | 文末送书
- 9【腾讯云 TDSQL-C Serverless 产品测评】Serverless集群高可用测评_tdsql-c mysql版 serverless
- 10OpenLayers 开源的Web GIS引擎_openlayers中文官网
【3】自然语言处理
赞
踩
目录
一、自然语言处理概述
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。
二、自然语言处理在大厂的应用
三、NLP核心技术——分词
1.分词的定义:
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
中文自动分词被认为是中文自然语言处理中的一个最基本的环节。
2.术语:
词级别:分词(Seg),词典,词库,语料库,词性标注(POS),命名实体识别(NER),未登录词识别,词向量(word2vec)
隐马尔科夫(HMM),条件随机场(CRF)
3.分词方法
经典算法:隐性马尔科夫(HMM),条件随机场(CRF)
隐马尔可夫模型(Hidden Markov Model)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。
条件随机场(CRF)是判别模型,本质上是隐含变量的马尔科夫链+可观测状态到隐含变量的条件概率。
4.常见分词工具
jieba:https://github.com/fxsjy/jieba
HanLP:pyhanlp: https://github.com/hankcs/pyhanlp
THULAC:https://github.com/thunlp/THULAC-Python
SnowNLP: https://github.com/isnowfy/snownlp
PkuSeg: https://github.com/lancopku/pkuseg-python
LTP:https://github.com/HIT-SCIR/ltp
https://github.com/HIT-SCIR/pyltp
5.分词工具的评价指标
精度(Precision)、召回率(Recall)、F值(F-mesure) 、错误率(ER)
6.分词工具安装
jieba:全自动 半自动 手动 pip install jieba
HanLP:pip install pyhanlp
THULAC:pip install thulac
SnowNLP: pip install snownlp
PkuSeg: pip install pkuseg
7.分词工具概述
(1)Jieba
①“结巴”中文分词:广泛使用的 Python 中文分词组件
支持三种分词模式:
精确模式,试图将句子最精确地切开,适合文本分析;
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合搜索引擎分词。
支持词性标注和返回词语在原文的起止位置
支持繁体分词
支持自定义词典
②Jieba的使用——分词
jieba.cut:精确/全局模式,返回为generator
jieba.cut_for_search:搜索引擎模式,返回为generator
jieba.lcut:精确/全局模式,返回为list
jieba.lcut_for_search :搜索引擎模式,返回为list
jieba.Tokenizer:新建自定义分词器,可用于同时使用不同词典。jieba.dt 为默认分词器
③Jieba的使用——自定义字典
开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率
用法: jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径
(2)Hanlp
①HanLP是一系列模型与算法组成的NLP工具包,由大快搜索主导并完全开源,目标是普及自然语言处理在生产环境中的应用。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。
②安装与配置
通过hanlp serve来启动内置的http服务器,默认本地访问地址为:http://localhost:8765 ;也可以访问官网演示页面:http://hanlp.hankcs.com/
③Hanlp的使用示例
- from pyhanlp import *
-
- print(HanLP.segment('你好,欢迎在Python中调用HanLP的API'))
- for term in HanLP.segment('下雨天地面积水'):
- print('{}\t{}'.format(term.word, term.nature)) # 获取单词与词性
- testCases = [
- "商品和服务",
- "结婚的和尚未结婚的确实在干扰分词啊",
- "买水果然后来世博园最后去世博会",
- "中国的首都是北京",
- "欢迎新老师生前来就餐",
- "工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作",
- "随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这块也不能完全忽略掉。"]
- for sentence in testCases: print(HanLP.segment(sentence))
-
- # 关键词提取
- document = "水利部水资源司司长陈明忠9月29日在国务院新闻办举行的新闻发布会上透露," \
- "根据刚刚完成了水资源管理制度的考核,有部分省接近了红线的指标," \
- "有部分省超过红线的指标。对一些超过红线的地方,陈明忠表示,对一些取用水项目进行区域的限批," \
- "严格地进行水资源论证和取水许可的批准。"
- print(HanLP.extractKeyword(document, 2))
-
- # 自动摘要
- print(HanLP.extractSummary(document, 3))
-
- # 依存句法分析
- print(HanLP.parseDependency("徐先生还具体帮助他确定了把画雄鹰、松鼠和麻雀作为主攻目标。"))
④Hanlp的使用--自定义字典
进入词典目录:
anaconda3/lib/python3.6/site-packages/pyhanlp/static/data/dictionary/custom
编辑mydict.txt
按照 【词语 词性 词频】 的顺序更新词典
四、NLP核心技术——命名实体识别
命名实体识别(NER)是 NLP 里的一项很基础的任务,就是指从文本中识别出命名性指称项,为关系抽取等任务做铺垫。狭义上,是识别出人名、时间、地名和组织机构名这四类命名实体。当然,在特定领域中,会相应地定义领域内的各种实体类型。
1.命名实体识别的方法
基于规则的方法:多采用语言学专家构造规则模板,选用特征包括统计信息、标点符号、关键字、指示词和方向词、位置词、中心词等方法,以模式和字符串相匹配为主要手段,这类系统大多依赖于知识库和词典的建立。
基于统计机器学习的方法主要包括:隐马尔可夫模型、最大熵、支持向量机、条件随机场等。
混合方法:自然语言处理并不完全是一个随机过程,单独使用基于统计的方法使状态搜索空间非常庞大,必须借助规则知识提前进行过滤修剪处理。目前几乎没有单纯使用统计模型而不使用规则知识的命名实体识别系统。

五、词向量模型(word embedding)
词向量技术将自然语言中的词转化为稠密的向量,相似的词会有相似的向量表示,这样的转化方便挖掘文字中词语和句子之间的特征。生成词向量的方法从一开始基于统计学的方法(共现矩阵、SVD分解)到基于不同结构的神经网络的语言模型方法。
经典的语言模型方法:onehot、word2vec、glove、ELMo、BERT。
1.One-hot 编码
最简单
对每个词进行编号,假设词表的长度为n,则对于每一个词的表征向量均为一个n维向量,且只在其对应位置上的值为1,其他位置都是0。
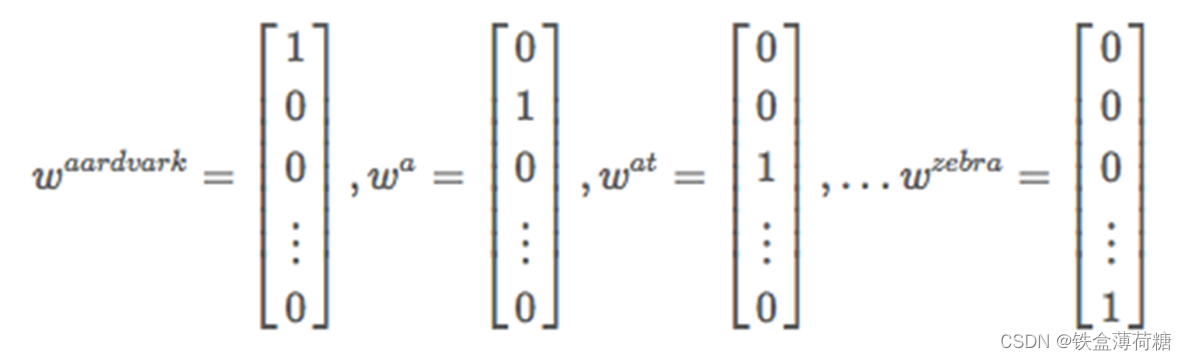
例如:
我:1;喜欢:2;北京:3;爸爸:4;深圳:5;妈妈:6;上海:7
我 ->(1,0,0,0,0,0,0) 喜欢 -> (0,1,0,0,0,0,0) 北京 -> (0,0,1,0,0,0,0) 爸爸 -> (0,0,0,1,0,0,0)妈妈 -> (0,0,0,0,1,0,0) 深圳 -> (0,0,0,0,0,1,0) 上海 -> (0,0,0,0,0,0,1)
然后我们有单个词的one-hot表示可以得到语料库中三句话的特征向量:
我喜欢北京 –> (1,1,1,0,0,0,0)
爸爸喜欢深圳 –> (0,1,0,1,0,1,0)
妈妈喜欢上海 –> (0,1,0,0,1,0,1)
存在问题:
有序性问题:它无法反映文本的有序性。因为语言并不是一个完全无序的随机序列。
语义鸿沟:其无法通过词向量来衡量相关词之间的距离关系
维度灾难:高维情形下将导致数据样本稀疏,距离计算困难,这对下游模型的负担是很重的。
2.word2vec
pword2vec的核心思想是通过词的上下文得到词的向量化表示,
有两种方法:CBOW(通过附近词预测中心词)、Skip-gram(通过中心词预测附近的词)
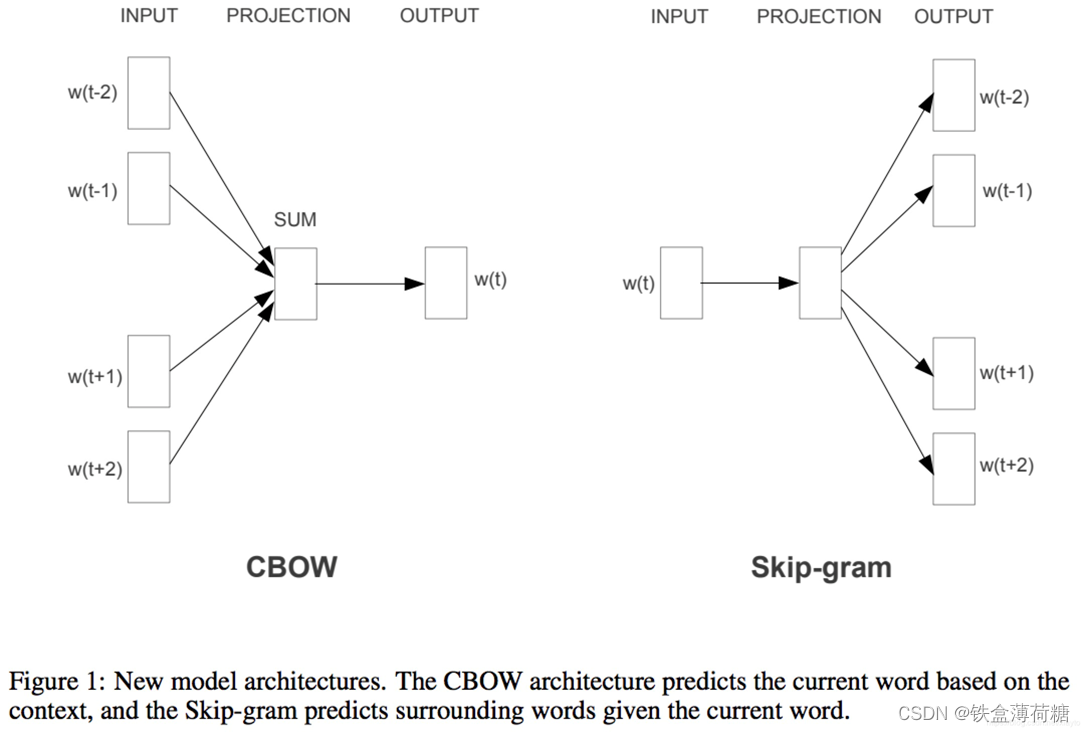
CBOW :通过目标词的上下文的词预测目标词,图中就是取大小为2的窗口,通过目标词前后两个词预测目标词。
具体的做法是,设定词向量的维度d,对所有的词随机初始化为一个d维的向量,然后要对上下文所有的词向量编码得到一个隐藏层的向量,通过这个隐藏层的向量预测目标词,CBOW中的做法是简单的相加,然后做一个softmax的分类,例如词汇表中一个有V个不同的词,就是隐藏层d维的向量乘以一个W矩阵(Rd×VR d×V )转化为一个V维的向量,然后做一个softmax的分类。由于V词汇的数量一般是很大的,每次训练都要更新整个W矩阵计算量会很大,同时这是一个样本不均衡的问题,不同的词的出现次数会有很大的差异,所以论文中采用了两种不同的优化方法多层Softmax和负采样。Skip-gram :跟CBOW的原理相似,它的输入是目标词,先是将目标词映射为一个隐藏层向量,根据这个向量预测目标词上下文两个词,因为词汇表大和样本不均衡,同样也会采用多层softmax或负采样优化

3.GloVe
word2vec只考虑了词的局部信息,没有考虑词与局部窗口外词的联系。Glove相对于Word2Vec,需要提前统计词共现矩阵,并将其整合到代价函数之中,使得训练结果对于该统计是有一定的重建能力的。我们将其称为一种统计模型(count-based model),其目标是优化减小重建损失(reconstruction loss)
Glove综合了频率统计特征、高维隐神经元表征词向量、和Ngram滑动窗口思想,Glove提出了Ngram窗口用词共现矩阵(word-word co-occurrence matrix) 的方式来提取和表征语料的词法和语义。
Glove语言模型的基本假设可以概括为:基于Ngram滑动窗口,彼此相似的词,相比于彼此不相似的词,在窗口中共同出现的概率要更高,语义的相似性可以通过窗口共现概率来体现。
具体可参考这篇博客:
【NLP】GloVe原理详解_nlp glove-CSDN博客
4.ELMo
word2vec和glove存在一个问题,词在不同的语境下其实有不同的含义,而这两个模型词在不同语境下的向量表示是相同的,
Elmo就是针对这一点进行了优化:
优点:1.能够学习到单词用法的复杂特性;2.学习到这些复杂用法在不同上下文的变化
缺点:1.使用LSTM而非transformer; 2.采用双向拼接,无法并行

5.Bert
在语言模型上,BERT使用的是Transformer编码器,并且设计了一个小一点的Base结构和一个更大的Large网络结构。
(1)Bert模型的输入
BERT使用了WordPiece embedding作为词向量,并加入了位置向量和句子切分向量。并在每一个文本输入前加入了一个CLS向量,后面会有这个向量作为具体的分类向量。
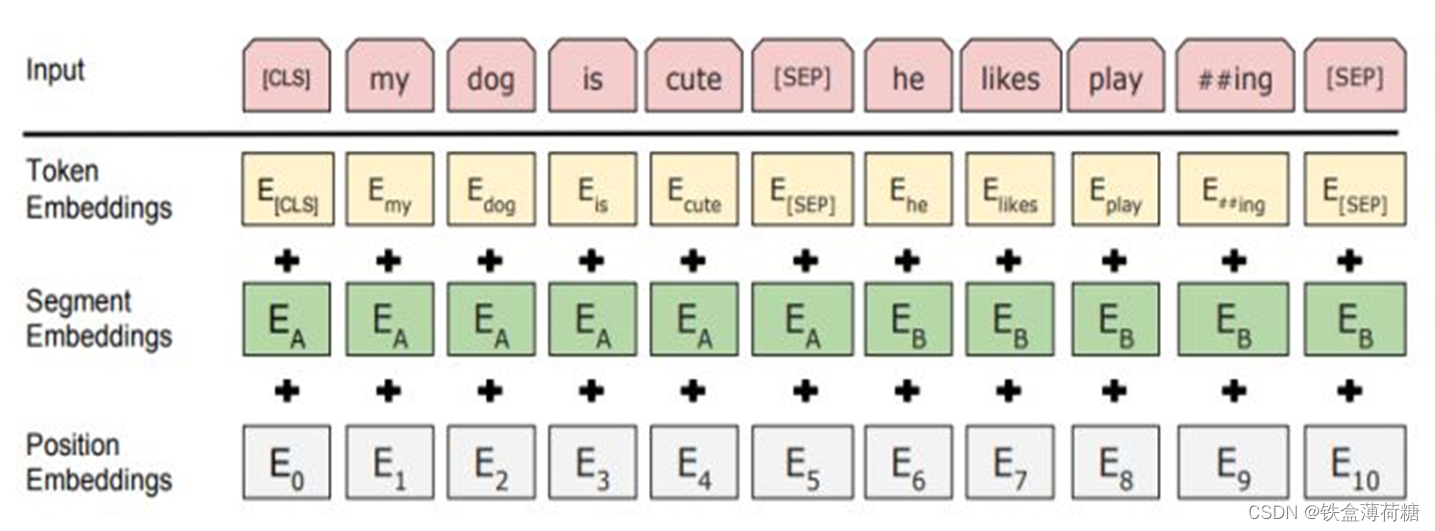
CLS:每个序列的第一个 token 始终是特殊分类嵌入(special classification embedding),即 CLS。对应于该 token 的最终隐藏状态(即,Transformer的输出)被用于分类任务的聚合序列表示。如果没有分类任务的话,这个向量是被忽略的。
SEP:用于分隔一对句子的特殊符号。有两种方法用于分隔句子:第一种是使用特殊符号 SEP;第二种是添加学习句子 A 嵌入到第一个句子的每个 token 中,句子 B 嵌入到第二个句子的每个 token 中。如果是单个输入的话,就只使用句子 A 。
(2)Bert语言模型预训练
BERT是使用Transformer的编码器来作为语言模型,在语言模型预训练的时候,提出了两个新的目标任务:
①遮挡语言模型;
即在输入的词序列中,随机的挡上15%的词,然后任务就是去预测挡上的这些词,可以看到相比传统的语言模型预测目标函数,MLM可以从任何方向去预测这些挡上的词,而不仅仅是单向的。
②预测下一个句子的任务
属于一个二元分类问题,
50%的时间,输入一个句子和下一个句子的拼接,分类标签是正例,而另50%是输入一个句子和非下一个随机句子的拼接,标签为负例。
最后整个预训练的目标函数就是这两个任务的取和求似然。

