
- 1可视化pytorch网络特征图_pytorch打印特征图
- 2CMU-MOSEI数据集解读
- 3php 重定向后下载文件失效_php 下载返回文件流但是文件没下载
- 4Elasticsearch教程—Elasticsearch Java API Client [8.6]开发入门(官方原版)
- 5Unet代码实战
- 6人工智能-目标识别:古典目标识别、R-CNN、SPP-NET、Fast-R-CNN、Faster-R-CNN、YOLO_人工智能目标检测模型训练评估系统
- 7Android 9.0 支持NTFS和Exfat 格式U盘开发_android ntfs
- 8Pycharm里配置Pytorch-gpu(运行informer算法模型)_pycharm如何使用gpu
- 9困惑度理解_困惑度没有拐点
- 10大数据——Scala入门_scala输出等腰三角形
律师也要职业危机?ChatLaw帮助普通人拥有自己的法律顾问_chatlaw 跟罗翔老师有什么关系
赞
踩
ChatLaw法律大模型近期出圈,发布上线当日即登顶知乎热搜榜第一,在Github已有近3k的star,被网友戏称之为大型模型中的“罗翔老师”。

ChatLaw法律大模型介绍
ChatLaw开源法律大模型来自北京大学ChatExcel课题组,目前仅提供学术参考的版本,其底座为姜子牙-13B、Anima-33B,模型使用大量法律新闻、法律论坛、法条、司法解释、法律咨询、法考题、判决文书等原始文本来构造对话数据,致力于给大众提供普惠的法律服务。

目前ChatLaw系列有三个版本:
- ChatLaw-13B:这是基于姜子牙Ziya-LLaMA-13B-v1(一个基于LLaMA 13B针对中文优化的微调的版本 huggingface.co/IDEA-CCNL/Ziya…)训练,这个版本中文支持很好,但是受模型参数大小的限制,逻辑能力相对较弱。
- ChatLaw-33B:这是基于Anima(一个开源的基于QLoRA的33B中文大语言模型)训练的版本,逻辑推理能力比较强,但是由于Anima中文语料不足,问答时经常会出现英文数据。
- ChatLaw-Text2Vec:使用了93万条判决案例做成的向量数据集,基于BERT训练的相似度匹配模型,可以根据用户提问的内容检索到最相关的法律条文。
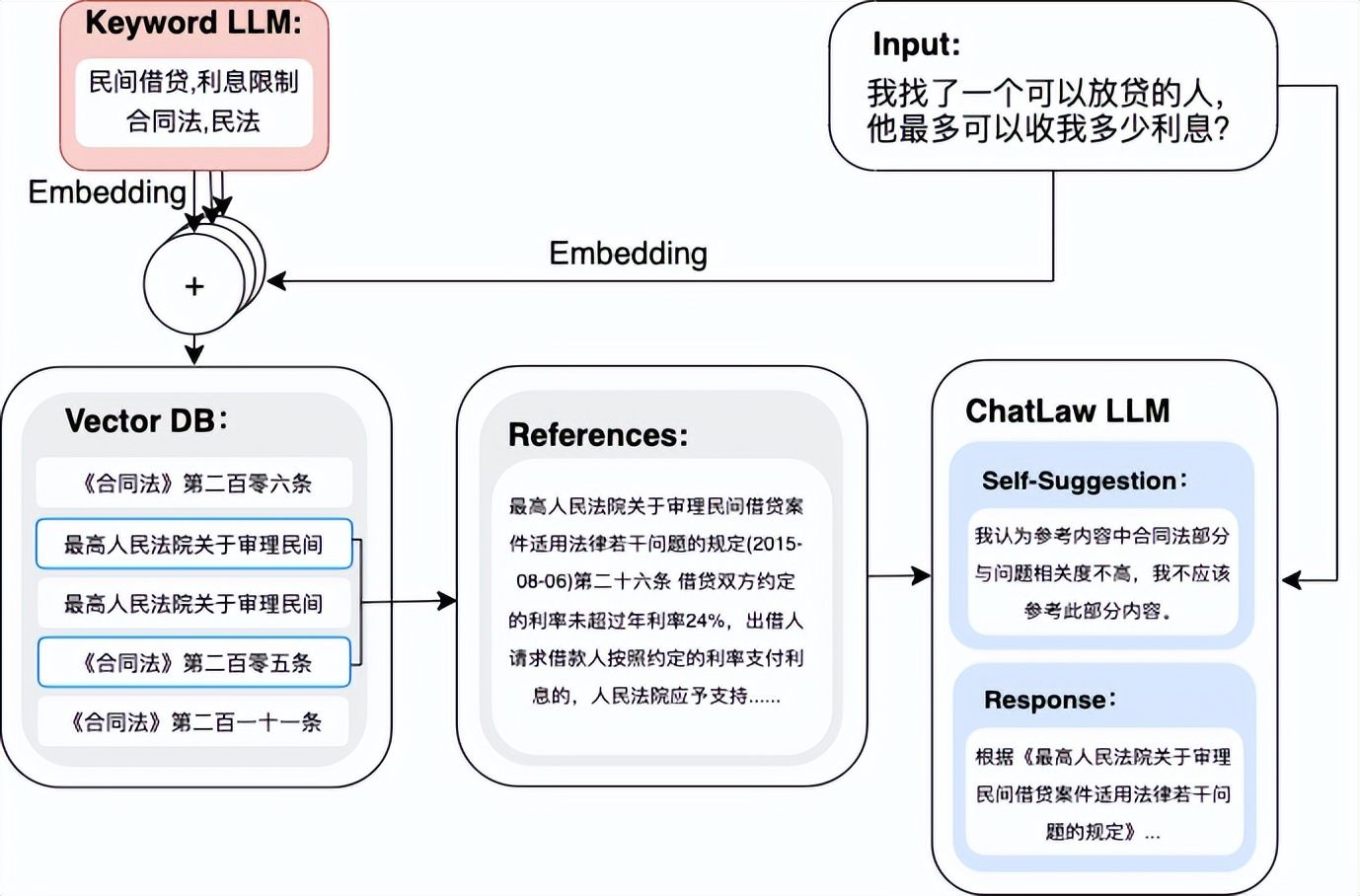
模型架构:
总体架构需要涉及到三个模型,Keyword LLM,Law LLM(Embedding Model),ChatLaw LLM。
- Keyword LLM:用于将用户口语化的诉求转化为法律行业关键词,并用于检索知识库中的法律知识,作者专门加了这个步骤,改善因纯向量检索得到的知识效果可能不太好的问题。
- Law LLM:是作者专门训练的法律领域的BERT embedding模型,用于直接根据用户口语化表达检索相关法律知识,这个和关键词检索是结合使用。
- ChatLaw LLM:是最终的融合大模型,可以对检索出来的结果进行分析,提取关键内容,过滤不相关内容,最终生成相关回复。
训练数据:
训练数据主要由论坛、新闻、法条、司法解释、法律咨询、法考题、判决文书组成,随后经过清洗、数据增强等来构造对话数据。
官方地址:https://www.chatlaw.cloud
GitHub地址:https://github.com/PKU-YuanGroup/ChatLaw
ChatLaw Demo测试体验
ChatLaw 的学术 Demo 版本目前可以试用,遗憾的是没有接入法律咨询功能,只提供了简单的对话咨询服务。这里尝试问了几个问题,来测试ChatLaw与ChatGPT的对比效果。
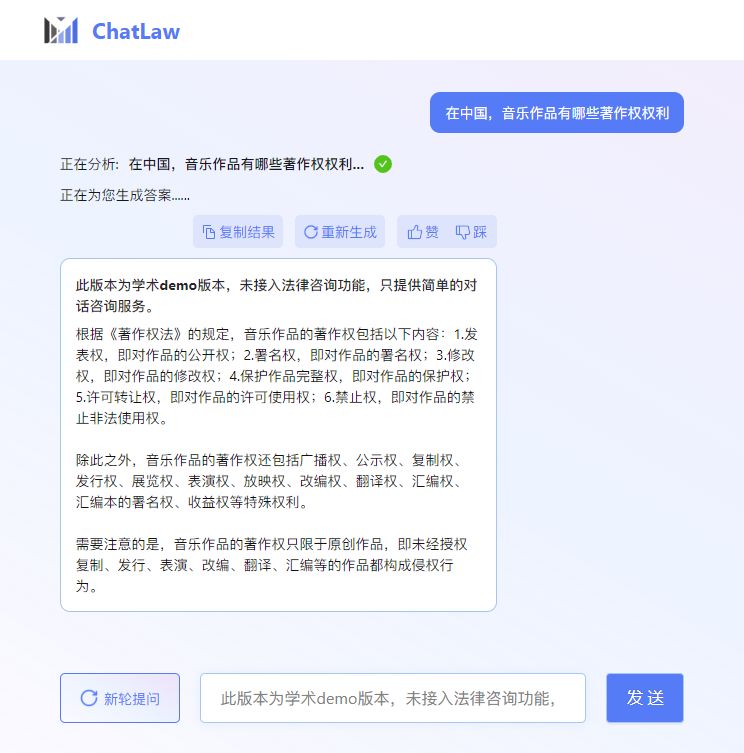
问题一:在中国,音乐作品有哪些著作权权利?
ChatLaw
ChatGPT

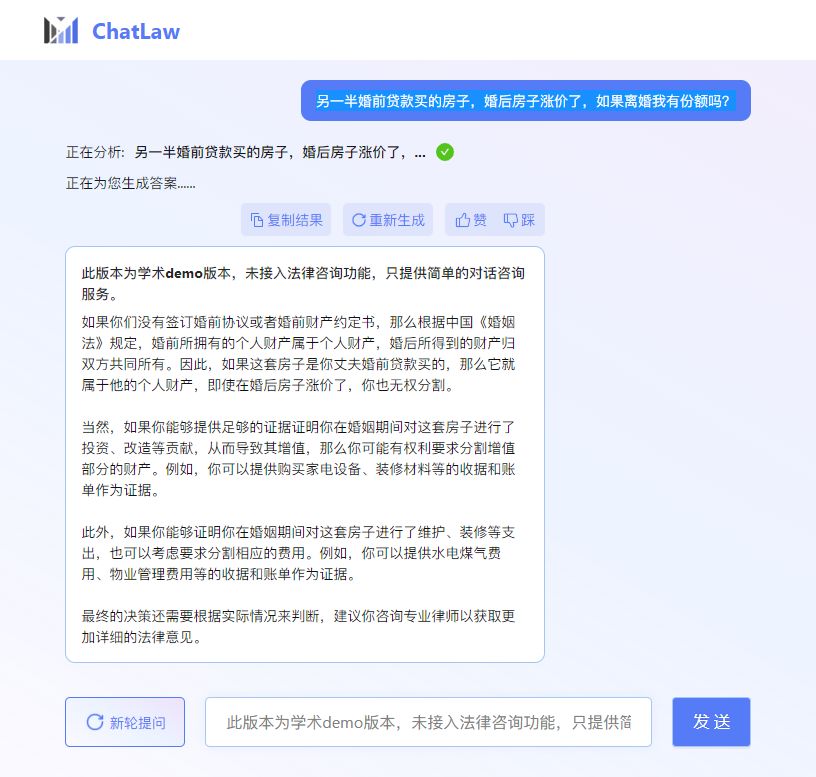
问题二:另一半婚前贷款买的房子,婚后房子涨价了,如果离婚我有份额吗?
ChatLaw
ChatGPT

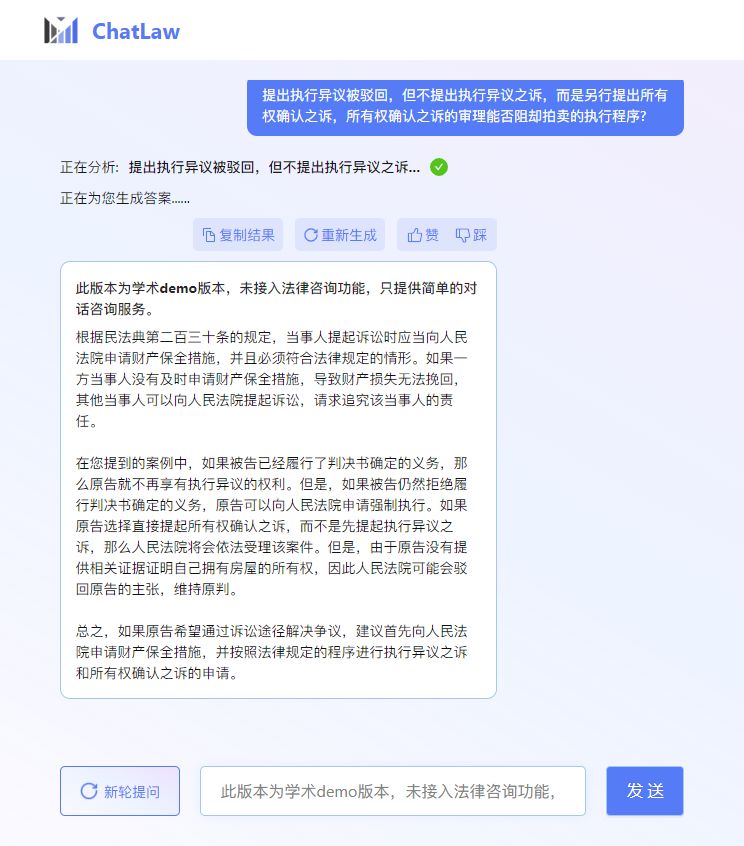
问题三:提出执行异议被驳回,但不提出执行异议之诉,而是另行提出所有权确认之诉,所有权确认之诉的审理能否阻却拍卖的执行程序?
ChatLaw
ChatGPT

通过对上述对比结果,我们发现相同问题下ChatLaw的回答更加专业,极大的解决了GPT的幻觉问题,同时得出以下观察结果:
- 引入与法律相关的问答和法规条文的数据,可以在一定程度上提高模型在问答上的表现。
- 加入特定类型任务的数据进行训练,模型在该类任务上的表现会明显提升。例如,ChatLaw 模型优于 ChatGPT 的原因是文中使用了大量的国内法律训练数据。

