
- 1简单介绍微信小程序的相关文件类型_1、 微信小程序中一般一个页面由几个文件组成?分别简述这些文件的作用。
- 2Centos下部署开源WAF---ModSecurity_centos waf
- 3js获取指定时间范围内指定间隔天数的所有日期_js通过开始时间和结束时间、间隔时间计算出中间的所有日期
- 4机械臂速成小指南(十四):多项式插值轨迹规划_机械臂三次多项式插值
- 5springboot 最新版本 及特性_springboot最新版本
- 6作为一个回到二线城市程序员,困境下,我的冷思考
- 7springboot+redis+lua脚本进行接口限流,解决高并发计数不准确问题_在高并发下 lua 也不管用
- 8RN环境配置(这里只演示mac版本的android studio的sdk下载失败的解决和ios环境的配置)
- 9C语言文件操作
- 10centos8 执行yum install ntpdate命令,报错未找到匹配的参数: ntpdate_centos8 yum 无法安装ntp
ERNIE快速上手,从一个文本相似度计算任务开始
赞
踩
点击左上方蓝字关注我们


项目背景与相关介绍
PaddleNLP是飞桨生态文本领域核心库,具备易用的文本领域API、中文预训练模型集、多场景的应用示例、高性能分布式训练和预测部署能力,旨在提升开发者文本领域的开发效率,并提供基于飞桨开源框架v2.x的NLP任务最佳实践。
PaddleNLP 链接:
https://github.com/PaddlePaddle/PaddleNLP
本项目主要是NLP 核心技术中的文本匹配 (Text Matching)问题。PaddleNLP为文本匹配任务提供了多种模型,包括SimNet、ernie-matching、Sentence-Transformers等。
SimNet:百度自研的语义匹配框架,使用BOW、CNN、GRU、LSTM等核心网络作为表示层,在百度内搜索、推荐等多个应用场景得到广泛应用。
ernie-matching:基于ERNIE/ERNIE-Gram使用语义匹配数据集LCQMC完成中文句对匹配任务,提供了Pointwise和Pairwise两种类型学习方式。
Sentence-Transformers:基于Siamese双塔网络结构的文本匹配模型,可以使用ERNIE/BERT/RoBERTa等模型获取文本的向量化表示。
ERNIE 链接:
https://github.com/PaddlePaddle/ERNIE
也可调用PaddleNLP的API来加载ERNIE模型,如:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/paddlenlp/transformers/ernie
什么是文本匹配?
文本匹配是自然语言处理中一个重要的基础问题,NLP领域的很多任务都可以抽象为文本匹配任务。例如,信息检索可以归结为查询项和文档的匹配,问答系统可以归结为问题和候选答案的匹配,对话系统可以归结为对话和回复的匹配。语义匹配在搜索优化、推荐系统、快速检索排序、智能客服上都有广泛的应用。如何提升文本匹配的准确度,是自然语言处理领域的一个重要挑战。
信息检索:在信息检索领域的很多应用中,都需要根据原文本来检索与其相似的其他文本,使用场景非常普遍。
新闻推荐:通过用户刚刚浏览过的新闻标题,自动检索出其他的相似新闻,个性化地为用户做推荐,从而增强用户粘性,提升产品体验。
智能客服:用户输入一个问题后,自动为用户检索出相似的问题和答案,节约人工客服的成本,提高效率。
让我们来看一个简单的例子,比较各候选句子哪句和原句语义更相近
- 原句:“车头如何放置车牌”
- 比较句1:“前牌照怎么装”
- 比较句2:“如何办理北京车牌”
- 比较句3:“后牌照怎么装”
(1)比较句1与原句,虽然句式和语序等存在较大差异,但是所表述的含义几乎相同。
(2)比较句2与原句,虽然存在“如何” 、“车牌”等共现词,但是所表述的含义完全不同。
(3)比较句3与原句,二者讨论的都是如何放置车牌的问题,只不过一个是前牌照,另一个是后牌照。二者间存在一定的语义相关性。
所以语义相关性,句1大于句3,句3大于句2,这就是语义匹配。
什么是文本相似度任务?
文本相似度旨在识别两段文本在语义上是否相似。文本相似度在自然语言处理领域是一个重要研究方向,同时在信息检索、新闻推荐、智能客服等领域都发挥重要作用,具有很高的商业价值。
目前学术界的一些公开中文文本相似度数据集,在相关论文的支撑下对现有的公开文本相似度模型进行了较全面的评估,具有较高权威性。因此,本开源项目收集了这些权威的数据集,期望对模型效果进行综合的评价,旨在为研究人员和开发者提供学术和技术交流的平台,进一步提升文本相似度的研究水平,推动文本相似度在自然语言处理领域的应用和发展。
文本相似度任务流程包含如下6个步骤:
数据读取:根据网络接收的数据格式,完成相应的预处理操作,保证模型正常读取;
模型构建:设计基于ERNIE的文本相似度模型,判断两句话是否相似;
训练配置:实例化模型,选择模型计算资源(CPU或GPU),指定模型迭代的优化算法;
模型训练与保存:执行多轮训练不断调整参数,以达到较好的效果,保存模型;
模型评估:训练好的模型在验证集上进行评估;
模型预测:加载训练好的模型,并进行预测;
准备工作
本项目源于课程《百度架构师手把手带你零基础实践深度学习》的课程比赛,比赛项目给出一个数据集压缩包,包含baidu_train.tsv,baidu_dev.tsv,vocab.txt和test_forstu.tsv。其中baidu_train.tsv,baidu_dev.tsv,vocab.txt用来训练模型。最后根据test_forstu.csv测试数据输出预测结果。命名为result.tsv的文件并提交。
数据集格式
- index text_a text_b label
- 1 经济适用房能贷款吗? 经济适用房能贷款吗 1
- 2 兔子有什么颜色 兔子是什么颜色的? 1
- 3 您是要注册支付宝的账户吗 注销成功就可以认证其他的支付宝账户了 0
- 4 建议您在联系卖家看看的哦 满就送彩票业务代发代扣.建议您联系淘宝的客服核实. 0
- 5 支付宝如何解冻? 支付宝怎样提现 1
- 6 怎样让自己快速长高 怎样可以快速长高? 1
- 7 这图片是什么电影? 这是什么电影的图片 1
- 8 红楼梦的主题曲是什么? 红楼梦的主题曲是什么 1
- 9 写合肥春节习俗,短一点的,语言简洁 春节的习俗,短一点的,100字以下的 0
-
本项目基于PaddlePaddle/ERNIE进行模型训练和预测,安装ERNIE代码如下:
!pip install paddle-ernie==0.0.4.dev1
定义数据集,包括数据集路径、tokenizer、batch_size等参数。
- class Classification_Dataset():
- def __init__(self, dataset_dir, max_seq_len=128, batch_size=8):
- self.dataset_dir = dataset_dir
- self.dataset_name = dataset_dir.split('/')[-1]
- self.train_datas = self.loader(os.path.join(dataset_dir, 'data/data90036/baidu_train.tsv'))
- self.dev_datas = self.loader(os.path.join(dataset_dir, 'data/data90036/baidu_dev.tsv'))
- self.test_datas = self.loader(os.path.join(dataset_dir, 'data/data90036/test_forstu.tsv'), True)
- self.tokenizer = ErnieTokenizer.from_pretrained('ernie-1.0')
- self.max_seq_len = max_seq_len
- self.batch_size = batch_size
模型训练
设置模型参数,可以自行尝试对下述参数进行修改调试,提高模型的效果。
- configs = {
- 'batch_size': 128, # 数据批大小
- 'max_seq_len': 128, # 最大文本长度
- 'epoch': 10, # 训练轮数
- 'dataset_dir': './', # 数据集文件夹
- 'warmup_proportion': 0.01, # 模型预热比例设置
- 'max_steps': 5000, # 最大步数
- 'weight_decay': 0.1, # 权重衰减比例
- 'learning_rate': 5e-5, # 学习率
- 'use_gpu': True, # 是否使用GPU训练
- 'log_step': 20, # 打印log间隔
- 'eval_step': 200, # 评估间隔
- 'save_dir': 'save', # 模型保存路径, 包含模型文件和测试集预测输出文件
- 'load_model': 'best_model', # 预测时加载的模型:最佳模型best_model, 最终模型final_model
- }
模型训练代码
- # 导入需要用到的模块,包括ernie中的优化器和模型等
- import paddle.nn as nn
- from ernie.optimization import AdamW, LinearDecay
- from ernie.modeling_ernie import ErnieModel, ErnieModelForSequenceClassification
-
- # 根据模型选择预训练模型进行加载
- model = ErnieModelForSequenceClassification.from_pretrained(
- 'ernie-1.0',
- num_labels=2,
- name='')
-
- # 学习率与优化器设置
- learning_rate = LinearDecay(
- configs['learning_rate'],
- int(configs['warmup_proportion'] * configs['max_steps']),
- configs['max_steps'])
- optimizer = AdamW(
- learning_rate=learning_rate,
- parameter_list=model.parameters(),
- weight_decay=configs['weight_decay'])
-
- # 记录总步数和运行时间
- global_step = 0
- tic_train = time.time()
- # 开始训练
- for epoch in range(configs['epoch']):
- model.train()
- for step, data in enumerate(dataset.get_data('train')):
-
- input_ids, token_type_ids, labels = data
- probs = model(input_ids=input_ids, token_type_ids=token_type_ids)
- loss = criterion(probs, labels)
- correct = metric.compute(probs, labels)
- metric.update(correct)
- acc = metric.accumulate()
-
- global_step += 1
- if global_step % 20 == 0:
- print("global step %d, epoch: %d, batch: %d, loss: %.5f, accu: %.5f, speed: %.2f step/s" % (global_step, epoch, step, loss, acc, 10 / (time.time() - tic_train)))
- tic_train = time.time()
- loss.backward()
- optimizer.step()
- lr_scheduler.step()
- optimizer.clear_grad()
-
- # 每间隔 500 step 在验证集上进行评估
- if global_step % 500 == 0:
- evaluate(model, criterion, metric, dataset.get_data('dev', False))
-
- # 保存模型参数
- save_dir = os.path.join(configs['save_dir'], "model_%d" % global_step)
- os.makedirs(configs['save_dir'])
-
- save_param_path = os.path.join(configs['save_dir'], 'model_state.pdparams')
- paddle.save(model.state_dict(), save_param_path)
- tokenizer.save_pretrained(configs['save_dir'])

模型预测
加载训练完成的模型参数进行预测
- # 模型加载
- model = ErnieModelForSequenceClassification.from_pretrained(
- 'ernie-1.0',
- num_labels=2,
- name='')
-
- # 读取保存的模型参数
- para_state_dict, _ = paddle.load (join(configs['save_dir'], configs['load_model']))
-
- # 设置模型参数
- print('loading the model params...')
- model.set_dict(para_state_dict)
-
- # 模型推理
- model.eval()
- results = []
-
- for step, data in enumerate(dataset.get_data('test', False)):
- input_ids, token_type_ids = data
- input_ids = paddle.to_tensor(input_ids)
- token_type_ids = paddle.to_tensor(token_type_ids)
- batch_prob = model(input_ids=input_ids, token_type_ids=token_type_ids).numpy()
- result = np.argmax (batch_prob, axis=1) \
- results.append(result)
- results = np.concatenate(results, 0)
最后的预测结果都保存在results中,根据results生成提交文件
- import pandas as pd
- import csv
-
- # 读取测试集文件
- test_file = 'data/data90036/test_forstu.tsv'
- data = pd.read_csv(test_file, sep='\t')
- print(data.shape)
-
- # 将预测结果写入输出文件中
- data['label'] = results
- print(data.shape)
- data.to_csv('result.csv',sep='\t')
提交csv内容大致如下:
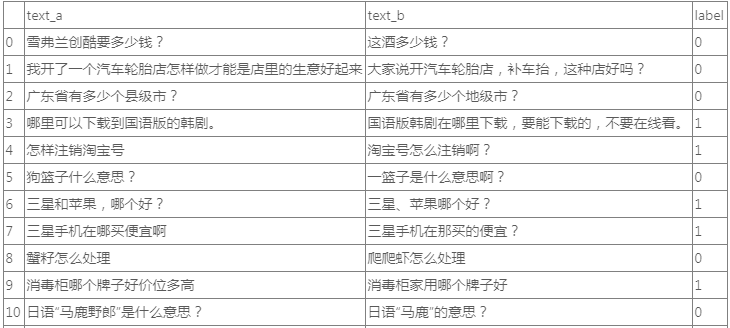
总结
本项目基于ERNIE的文本相似度计算任务还有许多待优化空间,例如,利用同义词替换、随机插入或删除、回译等方法对数据集使用数据增强和扩充,增加训练模型的数据量,提高模型的泛化能力和鲁棒性。在训练模型阶段,可以更换其他预训练模型,包括ERNIE的其他版本、BERT等,调整学习率与优化器配置。另外可以考虑集成学习和模型融合,通过不同的预训练模型对数据集进行学习和预测。
本项目也可以将数据集改为千言数据集:文本相似度的数据集做评测。千言文本相似度数据集包括公开的三个文本相似度数据集,分别为哈尔滨工业大学(深圳)的 LCQMC(A Large-scale Chinese Question Matching Corpus,百度知道领域的中文问题匹配数据集)和 BQ Coupus(Bank Question Corpus,银行金融领域的问题匹配数据),以及谷歌的 PAWS-X(中文)(Paraphrase Adversaries from Word Scrambling)。欢迎同学们参加相关比赛,同时,在课程《基于深度学习的自然语言处理》中也有文本匹配相关内容的介绍。
项目链接:
https://aistudio.baidu.com/aistudio/projectdetail/1962146
千言数据集:文本相似度:
https://aistudio.baidu.com/aistudio/competition/detail/45
《百度架构师手把手带你零基础实践深度学习》:
https://aistudio.baidu.com/aistudio/education/group/info/1297
《基于深度学习的自然语言处理》:
https://aistudio.baidu.com/aistudio/education/group/info/24177
更多有趣项目,可参考飞桨官方repo PaddleNLP,star收藏跟踪最新功能哈:
https://github.com/PaddlePaddle/PaddleNLP
如有飞桨相关技术有问题,欢迎在飞桨论坛中提问交流:
http://discuss.paddlepaddle.org.cn/
欢迎加入官方QQ群获取最新活动资讯:793866180。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
·飞桨官网地址·
https://www.paddlepaddle.org.cn/
·飞桨开源框架项目地址·
GitHub: https://github.com/PaddlePaddle/Paddle
Gitee: https://gitee.com/paddlepaddle/Paddle

????长按上方二维码立即star!????
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END


