
热门标签
热门文章
- 1学习网安基础工具:kaili安装及使用、dvwa镜像拉取、靶场搭建、phpstudy下载及使用_kali dvwa镜像拉取不了
- 2华为ensp中高级acl (控制列表) 原理和配置命令 (详解)
- 3什么是CDC?
- 4记录一次Vite打包优化_vite-plugin-spritesmith
- 5带RL的机器人:从类似预测下一个token的伯克利Digit到CMU 18万机器人_on bringing robots home
- 6如何查看键盘上面的键值?_虚拟机window server2012如何查看键值
- 7【自然语言处理】正向最大匹配算法(FMM),反向最大匹配算法(BMM)和双向最大匹配算法(BM)原理及实现
- 8阿里云对象存储oss-文件上传过程详解(两种方式)_oss最新版上传
- 9技术动态 | 去中心化知识图谱协作平台建设实践
- 10AI大模型应用开发实战:10 种架构模式_ai大模型技术架构
当前位置: article > 正文
Hive和Hadoop协作执行任务的工作原理是什么?_下列选项中关于hive和hadoop之间的工作原理说法错误的是用户接口向驱动程序提交执
作者:IT小白 | 2024-04-10 03:02:14
赞
踩
下列选项中关于hive和hadoop之间的工作原理说法错误的是用户接口向驱动程序提交执
Hive是基于Hadoop的一个数据仓库工具,主要用来对数据进行抽取、转换、加载操作。HiveQL可以将结构化的数据文件映射为一张数据表,允许熟悉SQL的用户查询数据,也允许熟悉MapReduce的开发者开发自定义的mapper和reducer来处理内建的mapper和 reducer无法完成的复杂的分析工作,相对于Java代码编写的MapReduce来说,Hive的优势更加明显。Hive利用Hadoop的HDFS存储数据,利用Hadoop的MapReduce执行查询。
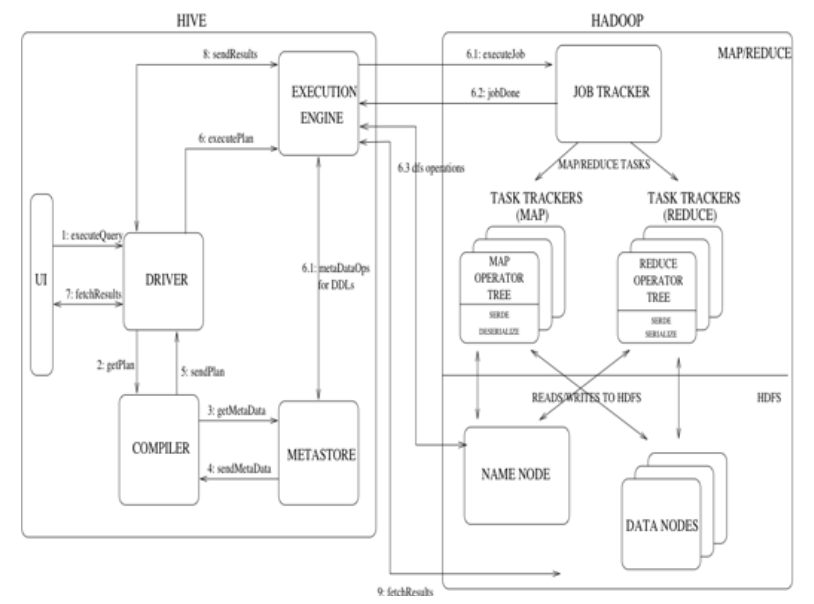
Hive和Hadoop协作执行任务的工作原理
(1) 用户通过用户接口向Driver提交executeQuery。
(2) Driver向Compiler发送获取计划的请求。
(3) Compiler根据用户提交的executeQuery去MetaStore获取需要的元数据信息。
(4) MetaStore向Compiler发送元数据信息。
(5) Compiler得到元数据信息,并向Driver发送计划。
(6) Driver 向EXECUTION ENGINE提交executePlan。
(7) 用户接口向Driver发起获取结果集(fetchResults)的请求。
(8)Driver向EXECUTION ENGINE发起获取结果集的请求。
(9)EXECUTION ENGINE向Driver发送结果集,Driver获取到结果集后返回用户接口。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/396254
推荐阅读
相关标签

