
- 1医药问答系统(一)python将excel或json数据处理后存入neo4j_excel neo4j
- 2嵌入式软件学习路线(入门)
- 3机器人工程师学习计划(新工科自学方案)------杨硕_怎么自学新工科
- 4Notion AI,又一款强大的内容生成工具?
- 5空投合约代码实现
- 6解决AWS Deep Learning AMI (Ubantu) 中的GPU不可用问题_机器学习算法时gpu不工作
- 7springcloud——registration status: 204_spring cloud 1.5.8 registration status: 204
- 8第十三章:多模态学习与PyTorch
- 9嵌入式|蓝桥杯STM32G431(HAL库开发)——CT117E学习笔记14:PWM捕获_蓝桥杯嵌入式
- 10BERT: 语言理解深度双向转换器的预训练——中文翻译_bert中文预训练
HADOOP HDFS详解_hadoop详细
赞
踩
目录
7.4 SecondayNamenode的工作机制(检查点机制)
第一章 概述
1.1大数据的特征(4V)
Volume: 数据量非常大
Variety:数据类型多样化,组成庞大的数据集的数据,有结构化的,半结构化的非结构化的数据。
Velocity:数据增长的速度非常快
Value: 数据的价值低
1.2 大数据的应用场景
共享单车故障报警
杀熟外卖会员
苹果比安卓贵吗
啤洒和尿不湿
猜你喜欢
贷款要看大数据
.....
1.3大数据的发展前景
大数据本身的价值体现在互联网得到了广泛的应用。
大数据不仅推动了互联网,还有金融、教育、医疗等诸多领域,尤其现有人工智能的发展
大数据形成一个较为完整的产业链,包括数据采集、整理、传输、存储、分析、呈现和应用。
1.4企业大数据的一般处理流程
1.4.1数据源
数据的来源有如下内容: 关系型数据库、日志文件、三方数据
1.4.2数据采集或者同步
常用数据采集导入框架:
sqoop: 用于RDBMS与HDFS之间数据导入与导出
flume: 采集日志文件数据、动态采集日志文件、数据流; flume采集到的数据,一份给HDFS, 用于做离线分析; 一分给Kafka, 实时处理
kafka: 主要用于实时的数据流处理, flume与kafka都有类似消息队列的机制,来缓存大数据环境处理不了的数据。
1.4.3数据存储
常用数据存储框架: HDFS、HBase、ES
1.4.4 数据清洗
对数据进行过滤,得到具有一定格式的数据源: 常用框架(工具): MapReduce, Hive(ETL), SparkCore, sparksql等
1.4.5 数据分析
对经过清洗后的数据进行分析,得到某个指标
常用框架(工具): MapReduce, Hive, SparkSQL, impala(impa:le), kylin
1.4.6数据展示
即将数据分析后的结果展示出来,也可以理解为数据的可视化, 以图或者表具体的形式展示出来。
常用工具: metastor, javaweb, hcharts, echarts
第二章 hadoop介绍
2.1.hadoop 目标
-
数据快速增长超过硬件存储及传输增长的速度
-
因硬件故障造成的数据丢失
-
读取的数据的正确性
2.2 hadoop的介绍
hadoop是Apache基金会旗下一个开源的分布式存储和分析计算平台,使用java语言开发,具有很好的跨平台性,可以运行在商用(谦价)硬件上,用户无需了解分布式底层细节,就可以开发分布式程序,充分使用集群的高速计算和存储。
2.3 hadoop起源
依赖三篇论文
2003年发表的《GFS》: 基于硬盘不够大,数据存储单份的安全隐患问题,提出了分布式文件系统用于存储的理论思想。
解决了如何存储大数据集的问题
2004年发表的《MapReduce》: 基于分布式文件系统的计算分析的编程框架模型,移动计算而非移动数据,分而治之
解决了如何快速分析大数据集的问题
2006年发表的《BigTable》
针对于传统型关系数据库不适合存储非结构化数据的缺点,提出了另一种适合存储大数据集的解决方案。
起源于Apache Nutch项目
2004年,基于《GFS》开始着手NDFS(Nutch的分布式文件系统)
2006年,从Nutch项目移出,开成子项目Hadoop
2008年,打破世界纪录,成为最快排序1TB数据的系统,排序时间为209秒。
2009年,将时间提高到62秒。
2.4 Hadoop版本
Apache hadoop: 原生的
Cloudera Hadoop: CHD版 商业
Hortonworks Hadoop(HDP): 完全开源,安装方便,提供了直观的用户安装界面和配置工具。
官网: Apache Hadoop
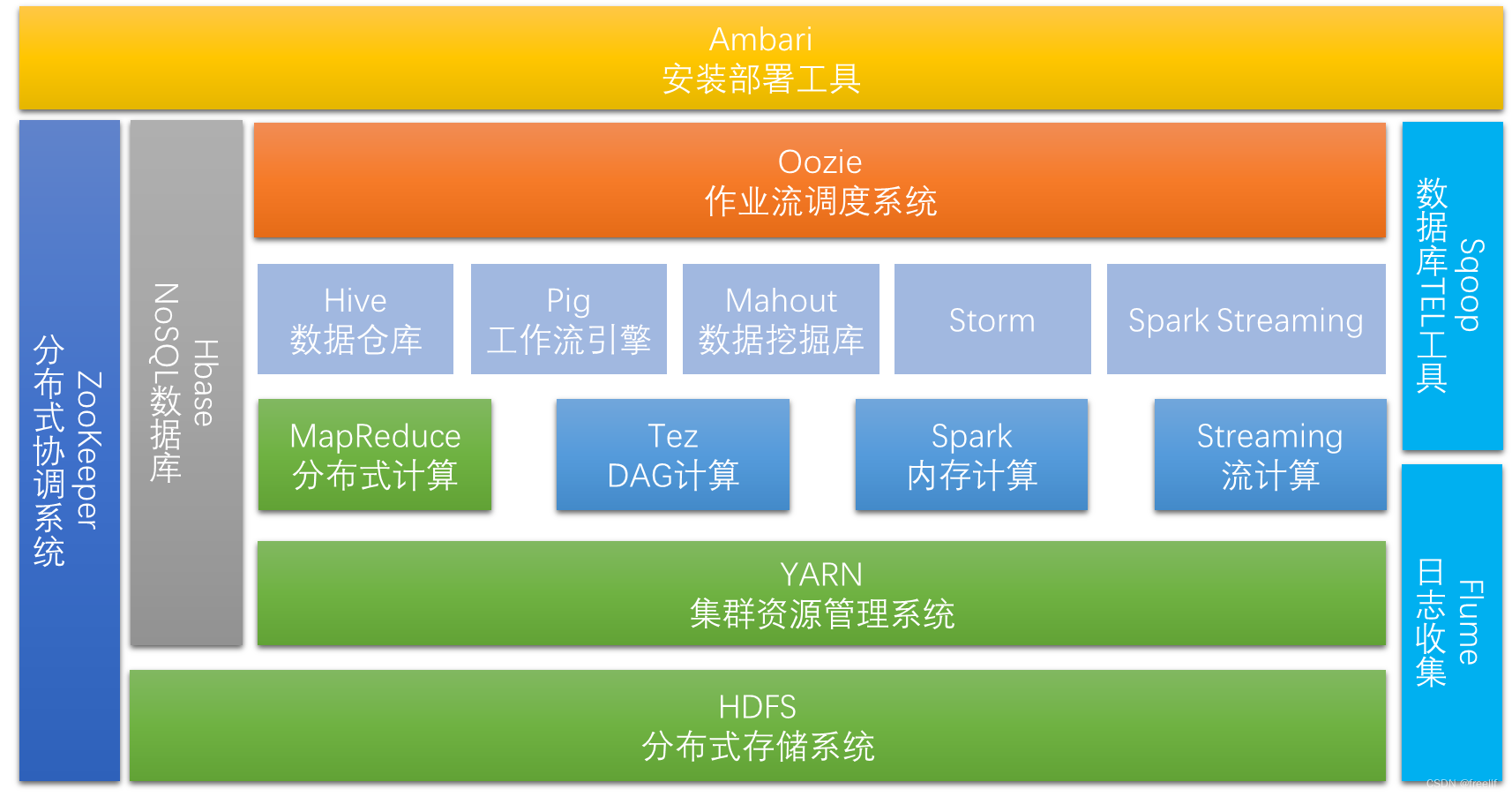
Hadoop生态系统介绍 (Hadoop生态系统介绍-CSDN博客) Hadoop是一个能够对大量数据进行分布式处理的软件框架。具有可靠、高效、可伸缩的特点。 它使我们能用一种简单的编程模型来处理存储于集群上的大数据集。可以应用于企业中的数据存储,日志分析,商业智能,数据挖掘等。
Hadoop的核心是HDFS、MapReduce、YARN。
Hadoop优点:
高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。 高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。 高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。 高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。 低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。 Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。
hadoop的优势主要体现在高可靠性,高扩展性等方面。
高可靠性是指多副本的存储机制和失败作业的重新调度计算。
高扩展性是指资源不够时很容易直接扩展机器。一个集群可以包含数以千计的节点。
其他优势还表现在:hadoop完全可以部署在普通廉价的机器上,成本低。同时它具有成熟的生态圈和开源社区。
狭义hadoop:指一个用于大数据分布式存储(HDFS),分布式计算(MapReduce)和资源调度(YARN)的平台,这三样只能用来做离线批处理,不能用于实时处理,因此才需要生态系统的其他的组件。
广义的hadoop:指的是hadoop的生态系统,即其他各种组件在内的一整套软件。hadoop生态系统是一个很庞大的概念,hadoop只是其中最重要最基础的部分,生态系统的每一个子系统只结局的某一个特定的问题域。不是一个全能系统,而是多个小而精的系统。
HDFS 是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
Block数据块:
基本存储单位,一般为64M(HDFS2.X以后的block默认128M)
减少搜寻时间,一般硬盘传输速度比寻道时间要快,大的块可以减少寻道时间 减少管理块的数据开销,每个块需要在NameNode有对应的记录 对数据块进行读写,减少建立网络的连接成本 一个大文件会被拆分成一个个的块,然后存储于不同的机器。如果一个文件少于block大小,那么实际占用的空间为其文件的大小
基本的读写单位类似于磁盘的页,每次都是读写一个块
每个块都会被复制到多台机器,默认复制三份
NameNode:
存储文件的metadata,运行时所有数据都保存到内存,整个HDFS可存储的文件数受限于NameNode的内存大小
一个block在namenode中对应一条记录(一般一个block占用150字节),如果是大量的小文件,会消耗大量内存。同时map task的数量是由splits来决定的,所以MapReduce处理大量的小文件时,就会产生过多的map task,线程管理开销将会增加作业时间。处理大量小文件的速度远远小于处理同等大小的大文件的速度。因此Hadoop建议存储大文件
数据会定时保存到本地磁盘,但不保存block的位置信息,而是由datanode注册时上报和运行时维护(namenode中与datanode相关的信息并不保存到namenode的文件系统中,而是namenode每次重启后,动态重建)
namenode失效则整个hdfs都失效了,所以要保证namenode的可用性
Secondary NameNode:
定时与NameNode进行同步(定期合并文件系统镜像和编辑日志,然后把合并后的传给namenode,替换其镜像,并清空编辑日志,类似于CheckPoint机制),但NameNode失效后仍需要手工将其设置成主机 DataNode:
保存具体的block数据
负责数据的读写操作和复制操作
datanode启动时会向namenode报告当前存储的数据块信息,后续也会定时报告修改信息
datanode之间会进行通信,复制数据块,保证数据的冗余性
MapReduce MapReduce是一种计算模型,用以进行大数据量的计算。其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。
MapReduce主要是先读取文件数据,然后进行Map处理,接着Reduce处理,最后把处理结果写到文件中
基本流程:

多节点详细流程:

Yarn YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
YARN的基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。这里的应用程序是指传统的MapReduce作业或作业的DAG(有向无环图)。
该框架是hadoop2.x以后对hadoop1.x之前JobTracker和TaskTracker模型的优化,而产生出来的,将JobTracker的资源分配和作业调度及监督分开。该框架主要有ResourceManager,Applicationmatser,nodemanager。其主要工作过程如下:
ResourceManager主要负责所有的应用程序的资源分配, ApplicationMaster主要负责每个作业的任务调度,也就是说每一个作业对应一个ApplicationMaster。 Nodemanager是接收Resourcemanager 和ApplicationMaster的命令来实现资源的分配执行体。 ResourceManager在接收到client的作业提交请求之后,会分配一个Conbiner,这里需要说明一下的是Resoucemanager分配资源是以Conbiner为单位分配的。第一个被分配的Conbiner会启动Applicationmaster,它主要负责作业的调度。Applicationmanager启动之后则会直接跟NodeManager通信。
在YARN中,资源管理由ResourceManager和NodeManager共同完成,其中,ResourceManager中的调度器负责资源的分配,而NodeManager则负责资源的供给和隔离。ResourceManager将某个NodeManager上资源分配给任务(这就是所谓的“资源调度”)后,NodeManager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证,这就是所谓的资源隔离。
在Yarn平台上可以运行多个计算框架,如:MR,Tez,Storm,Spark等计算框架。
Sqoop Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之间传输数据。数据的导入和导出本质上是MapReduce程序,充分利用了MR的并行化和容错性。其中主要利用的是MP中的Map任务来实现并行导入,导出。Sqoop发展到现在已经出现了两个版本,一个是sqoop1.x.x系列,一个是sqoop1.99.X系列。对于sqoop1系列中,主要是通过命令行的方式来操作。
sqoop1 import原理:从传统数据库获取元数据信息(schema、table、field、field type),把导入功能转换为只有Map的Mapreduce作业,在mapreduce中有很多map,每个map读一片数据,进而并行的完成数据的拷贝。 sqoop1 export原理:获取导出表的schema、meta信息,和Hadoop中的字段match;多个map only作业同时运行,完成hdfs中数据导出到关系型数据库中。 Sqoop1.99.x是属于sqoop2的产品,该款产品目前功能还不是很完善,处于一个测试阶段,一般并不会应用于商业化产品当中。 Mahout Mahout起源于2008年,最初是Apache Lucent的子项目,它在极短的时间内取得了长足的发展,现在是Apache的顶级项目。相对于传统的MapReduce编程方式来实现机器学习的算法时,往往需要话费大量的开发时间,并且周期较长,而Mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。
Mahout现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法,Mahout还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB 或Cassandra)集成等数据挖掘支持架构。
ZooKeeper 解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
HBase HBase是Apache的Hadoop项目的子项目,是Hadoop Database的简称。
HBase是建立在Hadoop文件系统(HDFS)之上的一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群,通过利用Hadoop的文件系统提供容错能力。
HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。
Hive Hive是一个在Hadoop中用来处理结构化数据的数据仓库基础工具。它架构在Hadoop之上,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。
Hive特点
它存储架构在一个数据库中并处理数据到HDFS。 它是专为OLAP设计。 它提供SQL类型语言查询叫HiveQL或HQL。 它是低学习成本,快速和可扩展的。 Pig Pig是MapReduce的一个抽象,它是一个工具/平台,用于分析较大的数据集,并将它们表示为数据流。Pig通常与 Hadoop 一起使用;我们可以使用Apache Pig在Hadoop中执行所有的数据处理操作。
要编写数据分析程序,Pig提供了一种称为 Pig Latin 的高级语言。该语言提供了各种操作符,程序员可以利用它们开发自己的用于读取,写入和处理数据的功能。
要使用 Apache Pig 分析数据,程序员需要使用Pig Latin语言编写脚本。所有这些脚本都在内部转换为Map和Reduce任务。Apache Pig有一个名为 Pig Engine 的组件,它接受Pig Latin脚本作为输入,并将这些脚本转换为MapReduce作业。
通常用于进行离线分析。
Flume Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据。它具有基于流数据流的简单灵活的体系结构。它具有可调整的可靠性机制以及许多故障转移和恢复机制,具有强大的功能和容错能力。它使用一个简单的可扩展数据模型,允许在线分析应用程序。
Oozie Oozie是工作流调度用在Hadoop中。它是一个运行相关的作业工作流系统。这里,用户被允许创建DAG工作流程,其可以在并列 Hadoop 并顺序地运行。
提供Hadoop任务的调度和管理,不仅可以管理MapReduce任务,还可以管理pig、hive、sqoop、spark等任务,Oozie就是一个基于hadoop的工作流引擎。
Spark Spark是一个用于实时处理的开源集群计算框架,它建立在Hadoop MapReduce之上,它扩展了MapReduce模型以使用更多类型的计算。它使用内存中缓存和优化的查询执行方式,可针对任何规模的数据进行快速分析查询。它提供使用 Java、Scala、Python 和 R 语言的开发 API,支持跨多个工作负载重用代码—批处理、交互式查询、实时分析、机器学习和图形处理等。
Spark 框架包括:
Spark Core 是该平台的基础
用于交互式查询的 Spark SQL
用于实时分析的 Spark Streaming
用于机器学习的 Spark MLlib
用于图形处理的 Spark GraphX
————————————————
第三章 环境搭建
3.1单机点安装:
3.1.1 jdk安装
| 平台软件 说明 | |
|---|---|
| 宿主机操作系统 windows | |
| 虚拟机操作系统 Centos stream 8 | |
| SSH工具 Windows: MobaXterm | |
| 虚拟机软件 VMWare | |
| 软件包上传路径 /root/softwares | |
| 软件安装路径 /usr/local | |
| JDK X64: jdk-8u321-linux-x64.tar.gz | |
| Hadoop X64: hadoop-3.3.1.tar.gz | |
| 用户 root |
(1)如果之前安装其他jdk,请卸载
- rpm -qa | grep jdk
- rpm -e xxx --nodeps
(2)上传后,解压安装
tar -zxvf jdk-8u321-linux-x64.tar.gz -C /usr/local/(3)配置环境变量
- vim /etc/profile
- 添加以下内容
- #java Environment
- export JAVA_HOME=/usr/local/jdk1.8.0_321/
- export PATH=$JAVA_HOME/bin:$PATH
- export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib
(4)重新引导,使环境变量生效
source /etc/profile(5)验证jdk是否配置成功
java -version3.1.2 安装hadoop
(1) 解压安培
tar -zxvf hadoop-3.3.1.tar.gz -C /usr/local/(2)配置环境变量
- vi /etc/profile
- --添加
- #Hadoop
- export HADOOP_HOME=/usr/local/hadoop-3.3.1
- export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
(3) 使环境变量生效
source /etc/profile(4)验证
hadoop version3.1.3 hadoop安装目录介绍
- bin hadoop的二进制执行命令文件存储目录
- etc 配置文件存储目录
- include 工具脚本存储目录
- lib 资源库存储目录
- libexec
- LICENSE-binary
- licenses-binary
- LICENSE.txt
- NOTICE-binary
- NOTICE.txt
- README.txt
- sbin 集群管理命令存储目录,例如服务启停的命令
- share 共享资源、开发工具和案例存储目录
3.1.4 案例演示测试
wordcount:
(1) 创建目录,存放文本文件
for i in {1..1000}; do cat file1 >> file2; donemkdir ~/input (2) 执行wordcount
cd /usr/local/hadoop-3.3.1/share/hadoop/mapreduce/hadoop jar hadoop-mapreduce-examples-3.3.1.jar wordcount ~/input ~/output(3) 查看结果
cat ~/output/*注意:output不能自己创建,一定要hadoop自己创建
pi (直接计算)
hadoop jar hadoop-mapreduce-examples-3.3.1.jar pi 100 1003.2伪分布式安装:
伪分布式模式也是只需要一台机器,但是与本地模式的不同,伪分布式使用的是分布式的思想,具有完整的分布式文件存储和分布式计算的思想。只不过在进行存储和计算的时候涉及到的相关的守护进程都运行在同一台机器上,都是独立的Java进程,因而称为伪分布式集群。比本地模式多了代码调试功能,允许检查内存使用情况、HDFS输出输出、以及其他的守护进程交互。
3.2.1.jdk及hadoop安装同单机点安装
3.2.2.关闭防火墙
- systemctl stop firewalld
- systemctl disable firewalld
-
- #关闭selinux
- vi /etc/selinux/config
- SELINUX=disabled
3.2.3.修改host映射
- hostnamectl set-hostname --主机名称
- cat >> /etc/hosts << EOF
- 192.168.68.128 hadoopmaster
- EOF
3.2.4.确保ssh对localhost的免密登认证有效
- #1.使用rsa加密技术,生成公钥和私钥
- ssh-keygen -t rsa
- #2.进入~/.ssh目录下,使用ssh-copy-id命令
- ssh-copy-id root@hadoopmaster
3.2.5配置hadoop文档
(1).core-site.xml
- <configuration>
- <!--指定namenode的地址-->
- <!--注意: hadoop1.x默认端口9000 hadoop2.x时代默认端口 9820-->
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://hadoopnode2:9820</value>
- </property>
- <!--用来指定使用hadoop时产生文件的存放目录-->
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/usr/local/hadoop-3.3.1/tmp</value>
- </property>
- <!--用来设置检查点备份日志的最长时间-->
- <name>fs.checkpoint.period</name>
- <value>3600</value>
- </configuration>

(2).hdfs-site.xml
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <!--secondarynamenode守护进程的http地址: 主机名和端口号。参考守护进程布局-->
- <property>
- <name>dfs.namenode.secondary.http-address</name>
- <value>hadoopmaster:9868</value>
- </property>
- <!--namenode守护进程的http地址: 主机名和端口号。参考守护进程布局-->
- <property>
- <name>dfs.namenode.http-address</name>
- <value>hadoopmaster:9870</value>
- </property>
- </configuration>
(3).hadoop-env.sh
- export JAVA_HOME=/usr/local/jdk1.8.0_321
- #hadoop3中,需要添加如下配置,设置启动集群角色的用户是谁
- export HDFS_NAMENODE_USER=root
- export HDFS_DATANODE_USER=root
- export HDFS_SECONDARYNAMENODE_USER=root
注意:如果要使用伪分布式
- vim workers
- 修改 localhost为主机名
(4)格式化集群
在core-site.xml中配置过hadoop.tmp.dir的路径,在集群格式化的时候需要保证这个路径不存在,如果之前存在数据,先将其删除,再进行格式化
hdfs namenode -format(5) 启动集群
start-dfs.sh

(6) WEBUI查看
在浏览器中输入 http://192.168.86.131:9870
(7)验证
hdfs dfs -put input/ / #将本地的数据上传到分布式上集群上hdfs dfs -ls -R / #数据检查手动命令来离开安全模式
hadoop dfsadmin -safemode leave在分布式集群上删除文件
hdfs dfs -rm -r -f /input/file4*执行分布式计算任务
hadoop jar hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output查看结果
hdfs dfs -cat /output/*3.3完全分布式安装
3.3.1 完全分布式介绍
在真实的企业环境中,服务器集群会使用到多台机器,共同配合,来构建一个完整的分布式文件系统,而在这样的分布式文件系统中,HDFS相关的守护进程也会分布在不同的机器上,例如:
NameNode守护进程,尽可能的单独部署在一台硬件性能较好的机器上。
其他的每台机器上都会部署一个DataNode守护进程,一般的硬件环境即可。
SecondaryNameNode守护进程最好不要和NameNode在同一台机器上。
3.3.2守护进程布局

3.3.3集群安装
1.总纲
(1) 三台机器的防火墙必须关闭
(2) 确保三台机器的网络配置畅通(NAT模式,静态IP, 主机名的配置)
(3)确保配置了三台机器的免密登陆认证(克隆会更加方便)
(4)确保/etc/hosts文件配置了ip和hostname的映射关系
(5)确保所有机器时间同步
(6)jdk和hadoop的环境安装配置
2.防火墙关闭、jdk安装、hadoop安装,及环境配置 同伪分布式
3.主机映射
- cat >> /etc/hosts << EOF
- 192.168.68.128 hadoopmaster
- 192.168.68.129 hadoopnode1
- 192.168.68.130 hadoopnode2
- EOF
4.免密登录
- 1. 使用rsa加密技术,生成公钥和私钥,一路回车即哥
- ssh-keygen -t rsa
- 2.使用ssh-copy-id命令
- ssh-copy-id root@hadmaster
- ssh-coyp-id root@hadnode1
- ssh-coyp-id root@hadnode2
- 3.验证
- ssh hadoopmaster
- ssh hadoopnode1
- ssh hadoopnode2
5.时间同步
- #时间同步 -- centOS 7
- yum install ntpdate -y
- ntpdate time.windows.com
-
-
- #设置时间同步 centos 8
- #安装chrony
- yum install -y chrony
-
- #启动 chrony
- systemctl start chronyd
-
- #设为系统自动启动
- systemctl enable chronyd
-
- #编辑配置/etc/chrony.conf
- #注释掉 pool
- #添加 pool ntp.aliyun.com iburst
- 查看服务 chronyc sources
- systemctl status chronyd
设置每分钟同步网络时间
#crontab -e* * * * * /usr/sbin/ntpdate -u ntp.aliyun.com > /varnull 2>&16.安裝jdk, hadoop,及配置/etc/profile,使其生效,同单点安装
7.编辑配置文件(/usr/local/hadoop-3.3.1/etc/hadoop)
(1) core-site.xml
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <!--
- Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License.
- You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software
- distributed under the License is distributed on an "AS IS" BASIS,
- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- See the License for the specific language governing permissions and
- limitations under the License. See accompanying LICENSE file.
- -->
-
- <!-- Put site-specific property overrides in this file. -->
-
- <configuration>
- <!--指定namenode的地址-->
- <!--注意: hadoop1.x默认端口9000 hadoop2.x时代默认端口 9820-->
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://hadoopmaster:9820</value>
- </property>
- <!--用来指定使用hadoop时产生文件的存放目录-->
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/usr/local/hadoop-3.3.1/tmp</value>
- </property>
-
- </configuration>
(2)hdfs-site.xml
- <configuration>
- <property>
- <!-- 块的副本数量 -->
- <name>dfs.replication</name>
- <value>3</value>
- </property>
- <!--secondarynamenode守护进程的http地址: 主机名和端口号。参考守护进程布局-->
- <property>
- <name>dfs.namenode.secondary.http-address</name>
- <value>hadoopnode1:9868</value>
- </property>
- <!--namenode守护进程的http地址: 主机名和端口号。参考守护进程布局-->
- <property>
- <name>dfs.namenode.http-address</name>
- <value>hadoopmaster:9870</value>
- </property>
- </configuration>
(3)hadoop-env.sh
- # server jvm.
- # export HADOOP_REGISTRYDNS_SECURE_EXTRA_OPTS="-jvm server"
- export JAVA_HOME=/usr/local/jdk1.8.0_321
- #hadoop3中,需要添加如下配置,设置启动集群角色的用户是谁
- export HDFS_NAMENODE_USER=root
- export HDFS_DATANODE_USER=root
- export HDFS_SECONDARYNAMENODE_USER=root
(4)works
- hadoopmaster
- hadoopnode1
- hadoopnode2
ps: scp -r 分发
scp -r jdk hadoop hadoopnode1:$PWD8.格式化集群
hdfs namenode -format错误处理
2023-10-25 04:15:56,715 ERROR namenode.NameNode: Failed to start namenode. java.lang.IllegalArgumentException: URI has an authority component

9.启动集群
- start-dfs.sh #启动HDFS所有进程(NameNode, SecondaryNameNode, DataNode)
- stop-dfs.sh #关闭HDFS所有进程(NameNode, SecondaryNameNode, DataNode)
-
- #hdfs --daenon start 单独启动一个进程(当前节点)
- hdfs --daemon start namenode #只开启NameNode
- hdfs --daemon start secondarynamenode #只开启secondaryNameNode
- hdfs --daemon start datanode #只开启DataNode
-
- #hdfs --daemon stop 单独停止一个进程
- hdfs --daemon stop namenode #只停止NameNode
- hdfs --daemon stop secondarynamenode #只停止SecondaryNameNode
- hdfs --daemon stop datanode #只停止DataNode
-
- #hdfs --workers --daemon start 启动所有的指定进程
- hdfs --workers --daemon start datanode #开启所有节点的DataNode
-
- #hdfs --workers --daemon stop 停止所有的指定进程
- hdfs --workers --daemon stop datanode #停止所有节点的DataNode
10.验证
在浏览器栏输入: http://192.168.68.128:9870/
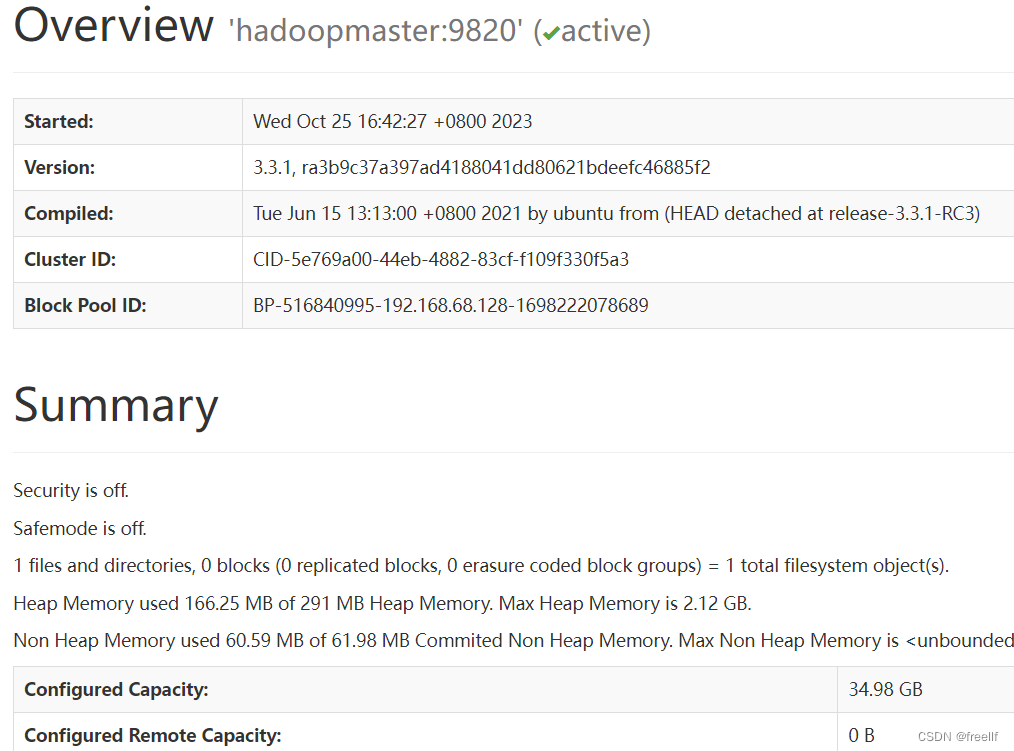
注意:HDFS集群正常启动,但Web页面仅有一个DataNode 主节点的,是因为其他节点中core-site.xml中配置的项fs.defaultFS的值不一样,统一修改成master节点一样,即可解决。
11.进程查看:
jps #单机多机或集群:
mkdir -r /opt/bin/jps-cluster.sh- #! /bin/bash
- HOSTS=(hadoopmaster hadoopnode1 hadoopnode2)
- #遍历每一个节点
- for HOST in ${HOSTS[@]}
- do
- #远程登录到指定节点,执行jps命令
- ssh -T $HOST << TERMINATER
- echo "------------$HOST--------------"
- jps | grep -iv jps
- exit
- TERMINATER
- done
- sudo chmod a+x jps-cluster.sh
- ln -s /opt/bin/jps-cluster.sh /usr/bin/
12 启动日志查看
HDFS的角色有三个,Name Node、SecondaryName、DataNode,启动的时候也会有对应的日志文件生成,如果在启动脚本执行之后, 发现对应的角色没有启动起来,那就可以去查看日志文件,查看错误详情,解决问题。
日志的位置: $HADOOP_HOME/logs
日志的命名:hadoop-username-daemon-host.log
13 常见问题
常见格式集群时,报错原因
-当前用户使用不当 -/etc/hosts里的映射关系填写错误 -免密登录认证错误 -jdk环境变量配置错误 -防火墙没有关闭
namenode进程没有启动的原因
-当前用户使用不当
-重新格式化,忘记删除${hadoop.tmp.dir}目录下的内容
-网络震荡,造成edit日志文件的事务ID序号不连续
datanode出现问题的原因
-/etc/hosts里的映射关系写错误
-免密登录异常
-重新格式化时,忘记删除${hadoop.tmp.dir}目录下的内容,造成datanode的唯一标识符不在新集群中。
上述问题暴力解决,重新格式化.
如果想重新格式化,那么需要先删除每台机器上的${hadoop.tmp.dir}指定路径下的所有内容,然后再格式化,最好也把logs目录下的内容也清空,因为日志内容已经是前一个废弃集群的日志信息,留着也无用。
3.3.4 案例演示 : wordcount
1.准备数据
- mkdir input && cd input
- echo "hello world hadoop Linux hadoop" >> file1
- echo "hadoop Linux hadoop Linux hello" >> file1
- echo "hadoop Linux mysql Linux hadop" >> file1
- echo "hadoop Linux hadoop Linux hello" >> file1
- echo "Linux hadoop good programmer" >> file2
- echo "good programmer studystudydayday good" >>file2
2.上传到集群
- hdfs dfs -put ~/input/ /
- #检查是否已经上传成功
- hdfs dfs -ls -R /
3.执行任务
hadoop jar /$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input/ /output4.查看结果
hdfs dfs -cat /output/*第四章 HDFS的shell操作
HDFS是一个分布式文件系统,可以使用一些命令来操作HDFS集群上的文件
例如: 文件上传、下载、移动、拷贝等操作。
HDFS的shell操作命令都是hdfs dfs,其他的操作直接向后拼接即可。
4.1 创建目录
- [-mkdir [-p] <path> ...] #在分布式文件系统上创建目录,-p, 多层级创建
- 调用格式: hdfs dfs -mkdir /data
- 例如:
- hdfs dfs -mkdir /data
- hdfs dfs -mkdir -p /data/a/b/c
4.2 上传命令
- [-put [-f][-p][-l] <localsrc>...<dst>] #将本地文件系统的文件上传到分布式文件系统
- 调用格式: hdfs dfs -put /本地文件 /分布式文件系统路径
- 注意: 直接写/是省略了文件系统的名称hdfs://ip:port
- 例如:
- hdfs dfs -put /root/a.txt /data
- hdfs dfs -put /root/logs/* /data
- 其他指令:
- [-moveFromLocal <localsrc>...<dst>] #将本地文件系统的文件上传到分布式文件系统
- [-copyFromLocal [-f][-p][-l] <localsrc>...<dst>]
4.3 查看命令
- [-ls [-d] [-h] [-R] [<path> ...]] #查看分布式文件系统的目录里内容
- 调用格式: hdfs dfs -ls /
-
- [-cat [-ignoreCrc] <src> ...] #查看分布式文件系统的文件内容
- 调用格式: hdfs dfs -cat /xxx.txt
-
- [-tail [-f] <file>] #查看分布式文件系统的文件内容
- 调用模式: hdfs dfs -tail /xxx.txt
4.4 下载命令
- [-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
- 注意:本地路径的文件夹可以不存在
- [-get [-p] [-ignoreCrc] [-crc] <src> ... <localhost>]
- 调用模式:同copyToLocal
- hdfs dfs -copyToLocal /input/file1 ~/
4.5 合并下载
- hdfs dfs [generic options] -getmerge [-nl] <src> <localhost>
- 调用格式:hdfs dfs -getmerge hdfs 上面的路径 本地路径
- 实例:hdfs dfs -getmerge /hadoopdata/*.xml /root/test.test
4.6 删除命令
- [-rm [-f] [-r | -R] [-skipTrash] <src> ...]
- 注意:如果删除文件夹时需要加-r
- [-rmdir [--ignore-fail-on-non-empty] <dir> ...]
- 注意:必须是空文件夹,如果非空必须使用rm删除
4.7 拷贝命令
- hdfs dfs [generic options] -cp [-f] [-p | -p[topax]] <src> ... <dst>
- 调用格式:hdfs dfs -cp /hdfs路径_1 /hdfs路径_2
- 实例:hdfs dfs -cp /input /input2
4.8 移动命令
- hdfs dfs [generic options] -mv <src> ... <dst>
- 调用模式:hdfs dfs -mv /hdfs路径_1 /hdfs路径_2
- 实例: hdfs dfs -mv /aaa /bbb
4.9 创建空文件
- hdfs dfs [generic options] -touchz <path> ...
- 调用格式: hdfs dfs touchz /hadooptest.txt
4.10 向文件中追加内容
HDFS的文件系统上的文件,不允许进行文件中的数据插入、删除、修改操作,只支持向文件的末尾追加内容
例如:删除文件的第10行数据,在第11行中插入数据,修改第12行数据等,这些都是不允许的。
- [-appendToFile <localsrc> ... <dst>]
- 调用格式: hdfs dfs -appendToFile 本地文件 hdfs上的文件
- 注意: 不支持在中间随意增删改操作
4.11 修改文件权限
- 跟本地的操作一致,-R是让子目录或文件也进行相应的修改
- [-chgrp [-R] GROUP PATH ...]
- [-chmod [-R] <MODE[, MODE]...| OCTALMODE> PATH ...]
- [-chown [-R] [OWNER][:[GROUP]] PATH ...]
-
- 实例:hdfs dfs -chmod 777 /input
4.12 修改文件副本数量
- [-setrep [-R] [-w] <rep> <path> ...]
- 调用格式:hdfs dfs -setrep 3 / 将hdfs根目录及子目录下的内容设置成3个副本
- 注意:当设置的副本数量与初始化时默认的副本数量不一致时,集群会作出反应,比原来多了会自动进行复制。
4.13 文件测试
- hdfs dfs [generic options] -test -[defsz] <path>
- 参数说明:-e:文件是否存在, 存在返回0, -z:文件是否为空,为空返回0 -d:是否是路径(目录),是返回0
- 调用格式: hdfs dfs -test -d 文件
- 实例: hdfs dfs -test -d /shelldata/111.txt && echo "OK" || echo "no"
- 解释:测试当前的内容是否是文件夹,如果是返回ok,如果不是返回no
4.14 查看文件夹及子文件夹数量
- hdfs dfs [generic options] -count [-q] [-h] <path> ...
- 调用格式:hdfs dfs -count /hadoop
4.15 查看磁盘利用率及文件大小
- [-df [-h] [<path> ... ]] 查看分布式系统的磁盘使用情况
- [-du [-s] [-h] <path> ... ] #查看分布式系统上当前路径下文件的情况, -h:human 以人类可读的方式显示
4.16 查看文件状态
- hdfs dfs [generic options] -stat [format] <path> ...
- 命令的作用:当向hdfs上写文件时,可以通过dfs.blocksize配置项来设置文件的block的大小。这就导致了hdfs上的不同的文件block的大小是不相同的。有时候想知道hdfs上某个文件的block大小,可以预先估算一下计算的task的个数。stat的意义:可以查看文件的一些属性。
- 调用格式:hdfs dfs -stat [format] 文件路径
- format的形式:
- %b: 打印文件的大小(目录大小为0)
- %n: 打印文件名
- %o: 打印block的size
- %r: 打印副本数
- %y: utc时间 yyyy-MM-dd HH:mm:ss
- %Y: 打印自1970年1月1日以来的utc的微秒数
- %F: 目录打印directory, 文件打印regular file
-
- 注意:
- 1)当使用-stat命令但不指定format时,只打印创建时间,相当于%y
- 2)-stat 后面只跟目录, %r, %o 等打印的都是0,只有文件才有副本和大小
- 实例:
- hdfs dfs -stat %b-%n-%o-%r /input/file1
4.17 回收站
-
修改core-site.xml文件
- <!--设置检查点删除的时间间隔,单位是分钟,如果设置为0表示不启用回收站. -->
- <property>
- <name>fs.trash.interval</name>
- <value>1440</value>
- </property>
- <!-- 这是检查点创建的时间间隔,单位是分钟. -->
- <!-- 这个值应该小于或等于fs.trash.interval, 如果设置为0, 则会将这个设置为 fs.trash.interval的值-->
- <property>
- <name>fs.trash.checkpoint.interval</name>
- <value>0</value>
- </property>
-
基本操作
- #删除文件目录, 删除之后会将文件移动到回收站
- hdfs dfs -rm -r /test
- #清空回收站的数据
- hdfs dfs -expunge
- #直接删除文件目录,不进入回收站
- hdfs dfs -rm -r -skipTrash /test2
- #找回文件
- hdfs dfs -mv /user/root/.Trash/Current/test /test
第五章 HDFS的块
5.1 传统型分布式文件系统的缺点
现在想象一下这种情况,有四个文件 0.5TB的file1, 2TB的file2, 50GB的file3, 100GB的file4, 有7个服务器,每个服务器上有10个1TB的硬盘.
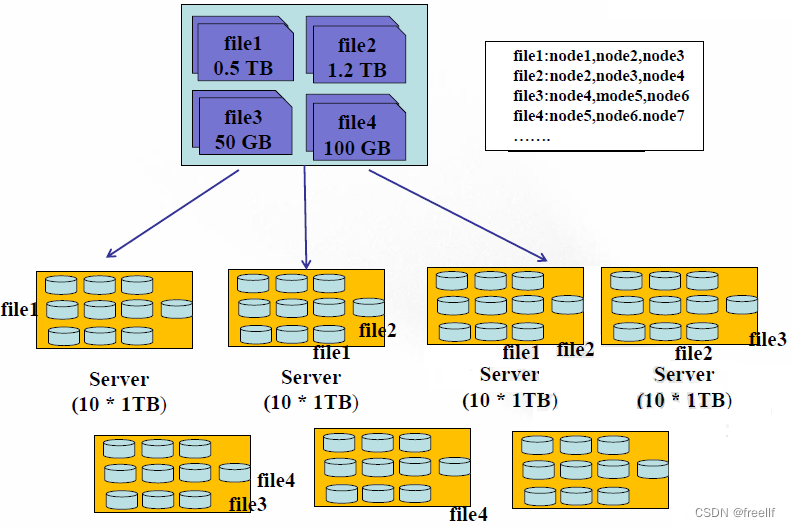
在存储方式上, 我们可以将这四个文件存储在同一个服务器上(当然大于1TB文件需要切分),我们需要将一个文件来记录这种存储的映射关系吧。用户是可以通过这种映射关系来找到节点硬盘相应的文件的。那么缺点也就暴露子出来。
第一、 负载不均衡
因为文件大小不一致,势必会导致有的节点磁盘的利用率高,有的节点磁盘利用率低。
第二、网络瓶颈问题
一个过大的文件存储在一个节点磁盘上,当有并行处理时,每个线程都需要从这个节点磁盘上读取这个文件的内容,那么就会出现网络瓶颈,不利于分布式的数据处理。
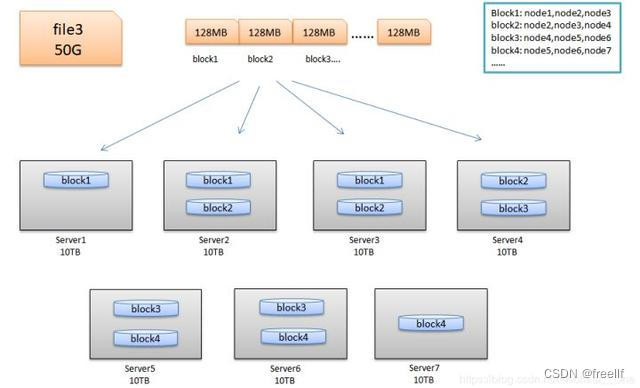
5.2 HDFS的块
HDFS与其他普通文件系统一样,同样引入了块(block)的概念,并且块的大小是固定的,但是不像普通文件系统那样小,而是根据实际需求可以自定义的。块是HDFS系统当中的最小存储单位,在hadoop2.0中默认大小为128MB(Hadoop1.x中的块大小为64M)。在HDFS上的文件会被拆分成多个块,每个块作为独立的单元进行存储。多个块存放在不同的DataNode上,整个过程中HDFS系统会保证一个块存储在一个数据节点上。但值得注意的是,如果某文件大小或者文件的最后一个块没有达到128M,则不会占据整个空间。
我们来看看HDFS的设计思想:以下图为例,来进行解释。
5.3 HDFS的块大小
HDFS上的块大小为什么会远远大于传统文件?
1.目的是为了最小化寻址开销时间。
在I/O开销中, 机械硬盘的寻址时间是最耗时的部分。一旦找到第一条记录,剩下的顺序读取效率是非常高的,因此以块为单位读写数据,可以尽量减少总的磁盘寻道时间。
HDFS寻址开销不仅包括磁盘寻道开销,还包换数据块的定位开销,当客户端需要访问一个文件时,首先从名称节点获取组成这个文件的数据块的位置列表,然后根据位置列表获取实际存储各个数据块的数据节点的位置。最后,数据节点根据数据块信息在本地Linux文件系统中找到对应的文件,并把数据返回给客户端,设计成一个比较大的块,可以减少每个块儿中数据的总的寻址开销,相对降低了单位数据的寻址开销。
磁盘的寻址时间大约在5-15ms之间,平均值为10ms,而最小化寻址开销时间普遍认为点1钞的百分之一是最优的,那么块大小的选择就参考1钞钏的传输速度,比如2010年硬盘的传输速率是100M/s,那么就选择块大小为128M。
2.为了节省内存的使用率
一个块的元数据大约150个字节,1亿个块,不论大小,都会占用20G左右的内存,因此块越大,集群相对存储的数据就越多。所以暴露了HDFS一个缺点,不适合存储小文件。
不适合存储小文件解释:
1.从存储能力出发(固定内存)
因为HDFS的文件是以块为单位存储的,且如果文件大小不到128M的时候,是不会占用整个块的空间的。但是,这个块依然会在内存中占用150个字节的元数据。因此,同样的内存占用的情况下,大量的小文件会导致集群的存储能力不足。
例如:同样是128G的内存,最多可存储9.2亿个块。如果都是小文件,例如1M,则集群存储的数据大小为9.2亿*1M = 877TB的数据。但是如果存储的都是128M的文件,则集群存储的数据大小为109.6P的数据。存储能力大不相同。
2.从内存占用出发(固定存储能力)
同样假设存储1M和128M的文件对比,同样存储1PB的数据, 如果是1M的小文件存储,占用的内存空间为1PB/1MB*150Byte=150G的内存,如果存储的是128M的文件存储,占用的内存空间为1PB/128M*150Byte=1.17G的内存占用。可以看到,同样存储1PB的数据,小文件的存储比起大文件占用更多的内存。
5.4 块的相关参数设置
当然块大小在默认配置文件hdfs-default.xml中有相关配置,我们可以在hdfs-size.xml中进行重置。
- <property>
- <name>dfs.blocksize</name>
- <value>134217728</value>
- <description>默认块大小,以字节为单位。可以使用以下后缀(不区分大小写): k, m, g, t, p, e以重新指定大小(例如128k,512m,1g等)</description>
- </property>
-
- <property>
- <name>dfs.namenode.fs-limits.min-block-size</name>
- <value>1048576</value>
- <description>以字节为单位的最小块大小,由Namenode在创建时强制执行时间,这可以防止意外创建带有小块的文件降低性能。</description>
- </property>
-
- <property>
- <name>dfs.namenode.fs-limits.max-blocks-per-file</name>
- <value>1048576</value>
- <description>每个文件的最大块数,由写入时的Namenode执行,这可以防止创建降低性能的超大文件</description>
- </property>
5.5 块的存储位置
- <!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处 -->
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>file://${hadoop.tmp.dir}/dfs/data</>
- </property>
5.6 HDFS的优点
1.高容错性(硬件故障是常态): 数据自动保存多个副本,副本丢失后,会自动恢复 2.适合大数据集:GB、TB、甚至PB级数组、千万规模以上的文件数量,1000以上节点规模。 3.数据访问:一次性写入,多次读取,保证数据一致性,安全性 4.构建成本低,可以构建在廉价机器上。 5.多种软硬件平台中的可移植性 6.高效性:hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。 7.高可靠性: Hadoop的存储和处理数据的能力值得人们依赖
5.7 HDFS的缺点
1.不适合做低延迟数据访问:
HDFS的设计目标有一点是:处理大型数据集,高吞吐率,这一点势必要以高延迟为代价的。因此HDFS不适合处理用户要求的毫秒级的低延迟应用请示。
2.不适合小文件存取:
一个是大量小文件需要消耗大量的寻址时间,违反了HDFS的尽可能寻址时间比例的设计目标。第二个是内存有限,一个block元数据大内存消耗大约150个字节,存储一亿个block和存储一亿个小文件都会消耗20G内存,因此相对来说,大文件更省内存。
3.不适合并发写入,文件随机修改:
HDFS上的文件只能拥有一个写者,仅仅支持append操作。不支持多用户对同一个文件的写操作,以及在文件任意位置进行修改。
第六章 HDFS的体系结构
6.1 体系结构解析
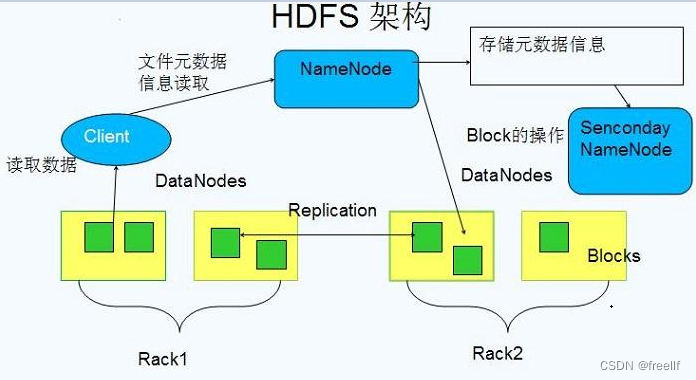
HDFS采用的是master/slaves这种主从的结构模型来管理数据,这种结构模型主要由四个部分组成,分别是Client(客户端)、Namenode(名称节点)、Datanode(数据节点)和SecondaryNameNode。真正的一个HDFS集群包括一个Namenode和若干数目的Datanode.
Namenode是一个中心服务器,负责管理文件系统的命名空间(Namespace),它在内存中维护着命名空间的最新状态,同时并持久性文件(fsimage和edit)进行备份,防止宕机后,数据丢失。namenode还负责管理客户端对文件的访问,比如权限验证等。
集群中的Datanode一般是一个节点支行一个Datanode进行,真正负责管理客户端的读写请求,在Namenode的统一调度下进行数据块的创建、删除和复制等操作。数据块实际上都是保存在Datanode本地的Linux文件系统中的。每个Datanode会定期的向Namenode发送数据,报告自已的状态(我们称之为心跳机制)。没有按时发送心跳信息的Datanode会被Namenode标记为“宕机”,不会再给他分配任何I/O请求。
用户在使用Client进行I/O操作时,仍然可以像使用普通文件系统那样,使用文件名去存储和访问文件,只不过,在HDFS内部,一个文件会被切分成若干个数据块,然后被分布存储在若干个Datanode上。
比如,用户在Client上需要访问一个文件时,HDFS的实际工作流程如此:客户端先把文件名发送给Namenode,Namenode根据文件名找到对应的数据块信息及其每个数据块所在的Datanode位置,然后把这些信息发送给客户端。之后,客户端就直接与这些Datanode进行通信,来获取数据(这个过程,Namenode并不参与数据块的传输)。这种设计方式,实现了并发访问,大大提高了数据的访问速度。
HDFS集群中只有唯一的一个Namenode,负责所有元数据的管理工作。这种方式保证了Datanode不会脱离Namenode的控制,同时,用户数据也永远不会经过Namenode,大大减轻了Namenode的工作负担,使之更方便管理工作。通常在部署集群中,我们要选择一台性能较好的机器来作为Namenode。当然,一台机器上也可以运行多个Datanode,甚至Namenode和Datanode也可以在一台机器上,只不过实际部署中,通常不会这么做的

6.2 HDFS进行之NameNode
- namenode进程只有一个(HA除外) - 管理HDFS的命名空间,并以fsimage和edit进行持久化保存 - 在内存中维护数据块的映射信息 - 实施副本冗余策略 - 处理客户端的访问请求
6.3 HDFS进行之DataNode
- 存储真正的数据(块进行存储) - 执行数据块的读写操作 - 心跳机制(3秒)
6.4 HDFS进程之SecondaryNamenode
- 帮助NameNode合并fsimage和edits文件 - 不能实时同步,不能作为热备份节点
6.5HDFS的Client接口
- HDFS实际上提供了各种语言操作HDFS的接口 - 与NameNode进行交互,获取文件的存储位置(读/取两种操作) - 与DataNode进行交互,读取时分片进行读取
6.6 映像文件fsimage
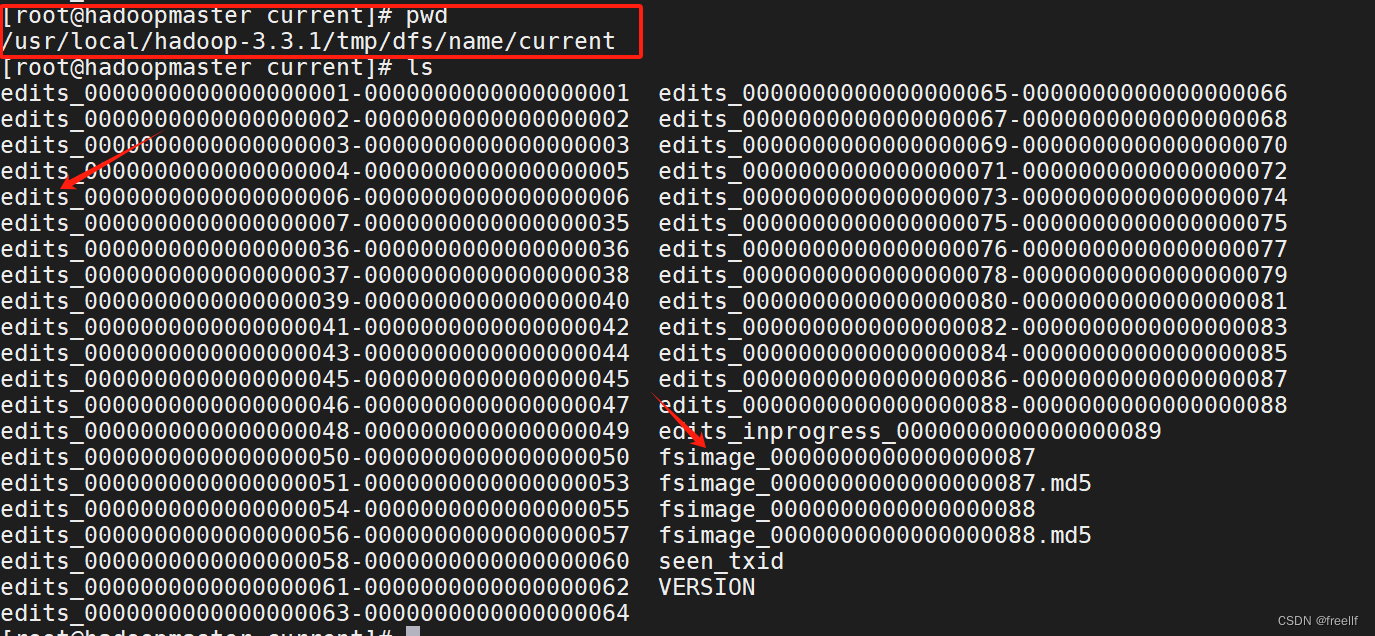
命名空间指的就是文件系统树及整棵树内的所有文件和目录的元数据,每个Namenode只能管理唯一的一命名空间。HDFS暂不支持软链接和硬连接。Namenode会在内存里维护文件系统的元数据,同时还使用fsimage和edit日志两个文件来辅助管理元数据,并持久化到本地磁盘上。
- - fsimage
- 命名空间镜像文件,它是文件系统元数据的一个完整的永久检查点,内部维护的是最近一次检查点的文件系统树和整棵树内部的所有文件和目录的元数据,如修改时间,访问时间,访问权限,副本数据,块大小,文件的块列表信息等等。
- fsimage默认存储两份,是最近的两次检查点。
- - 使用XML格式查看fsimage文件
- hdfs oiv -i [fsimage_xxxxx] -o [目标文件路径] -p XML
- hdfs oiv -i fsimage_0000000052 -o ~/fs52.xml -p XML
6.7 日志文件edit
集群正常运行时,客户端的所有更新操作(如打开、关闭、删除、重命名等)除了在内存中维护外,还会被写到edit日志文件中,而不是直接写入fsimage映像文件。
因为对于分布式文件系统而言,fsimage映像文件通常都很庞大,如果客户端所有的更新操作都直接往fsimage文件中添加,那么系统的性能一定越来越差。相对而言,edit日志文件通常都要远远小于fsimage,一个edit日志文件最大64M,更新操作写入到EditLog是非常高效的。
那么edit日志文件里存储的到底是什么信息呢,我们可以将edit日志文件转成xml文件格式,进行查看
查看editlog文件的方式:
- 查看editlog文件的方式:
- hdfs oev -i [edits_inprogress_xxx] -o [目标文件路径] -p XML
参考xml文件后,我们可以知道日志文件里记录的内容有:
- 行为代码:比如 打开、创建、删除、重命名、关闭
- 事务id
- inodeid
- 副本个数
- 修改时间
- 访问时间
- 块大小
- 客户端信息
- 权限等
- 块id等
第七章 HDFS的工作流程
7.1 开机启动Namenode过程
-
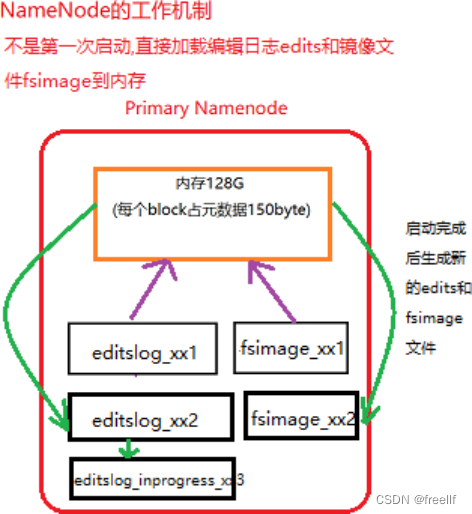
非第一次启动集群的启动流程
我们应该知道,在启动namenode之前,内存里是没有任何元数据的信息的,那么启动集群的过程是怎样的呢?下面来叙述一下:
第一步: Namenode在启动时,会先加载name目录下最近的fsimage文件 将fsimage里保存的元数据加载到内存当中,这样内存里就有了之前检查点里存储的所有元数据。但是还少了从最近一次检查时间点到关闭系统时的部分数据,也就是edit日志文件里存储的数据. 第二步: 加载剩下的edit日志文件 将从最近一次检查点到目前为止的所有的日志文件加载到内存里,重演一次客户端的操作,这样,内存里就是最新的文件系统的所有元数据了。 第三步: 进行检查点设置(满足条件会进行) namenode会终止之前正在使用的edit文件,创建一个空的edit日志文件,然后将所有的未合并过的edit日志文件和fsimage文件进行合并,产生一个新的fsimage。 第四步: 处于安全模式下,等待datanode节点的心跳反馈,当收到99.9%的块的至少一个副本后,退出安全模式,开始转为正常状态。不是第一次启动,直接加载编辑日志和edit文件的情况展示:
-
小知识
(1)滚动编辑日志(前提必须启动集群) 1.可以强制滚动 hdfs dfs admin -rollEdits 2.可以等到edits.inprogress满64m生成edits文件 3.可以等操作数量达到100万次 4.时间到了,默认1小时 注意:在2,3,4时产生滚动,会进行checkpoint (2)镜像文件什么时候产生 可以在namenode启动时加载镜像文件和编辑日志 也可以在secondarynamenode生成的fsimage.chkpoint文件重新替换namenode原来的fsimage文件时。 (3)namenode目录说明
7.2 安全模式介绍
Namenode启动时,首先要加载fsimage文件到内存,并逐条执行editlog文件里的事务操作,在这个期间一但在内存中成功建立文件系统元数据的映像,就会新创建一个fsimage文件(该操作不需要SecondaryNamenode)和一个空的editlog文件。在这个过程中,namenode是运行在安全模式下的,Namenode的文件系统对于客户端来说是只读的,文件修改操作如写,删除,重命名等均会失败。
系统中的数据块的位置并不是由namenode维护的,而是以块列表的形式存储在datanode中。 在系统的正常操作期间,namenode会在内存中保留所有块位置的映射信息。在安全模式下,各个datanode会向namenode发送最新的块列表信息,如果满足"最小副本条件",namenode会在30秒钟之后就退出安全模式,开始高效运行文件系统,所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别(默认值dfs.replication.min=1)。
PS:启动一个刚刚格式化完的集群时,HDFS还没有任何操作呢,因此Namenode不会进入安全模式。
-
系统离开安全模式,需要满足哪些条件?
当namenode收到来自datanode的状态报告后,namenode根据配置确定。 1.可用的block占总数的比例 2.可用的数据节点数量符合要求之后,离开安全模式。 1、2两个条件满足后维持的时间达到配置的要求。 注意:如果有必要,也可以通过命令强制离开安全模式。
-
与安全模式相关的主要配置在hdfs-site.xml文件中,主要有下面几个属性
1.dfs.namenode.replication.min 最小的文件block副本数量,默认为1 2.dfs.namenode.safemode.threshold-pct: 副本数达到最小要求的block占系统总block数的百分比,当实际比例超过该配置后,才能离开安全模式(但是还需要其他条件也满足)。默认为0.999f,也就是说符合最小副本数要求的block占比超过99.9%时,并且其他条件也满足才能离开安全模式。如果为小于等于0,则不会等待任何副本可达到要求即可离开。如果大于1,则永远处于安全模式. 3.dfs.namenode.safemode.min.datanode: 离开安全模式的最小可用(alive)datanode数量要求,默认为0,也就是即使所有datanode都不可用,仍然可以离开安全模式。 4.dfs.namenode.safemode.extension: 当集群可用block比例,可用datanode都达到要求之后,如果在extension配置的时间段之后依然能满足要求,此时集群才离开安全模式。单位为毫秒,默认为1。也就是当满足条件并且能够维持1毫秒之后,离开安全模式。这个配置主要是对集群的稳定程度做进一步的确认。避免达到要求后马上有不符合安全标准。 -
相关命令
-
查看namenode是否处于安全模式
hdfs dfsadmin -safemode get -
管理员可以随时让Namenode进入或开安全模式,这项功能在维护和升级集群时非常关键
- hdfs dfsadmin -safemode enter
- hdfs dfsadmin -safemode leave
-
将大下的属性的值设置为大于1,将永远不会离开安全模式
- <property>
- <name>dfs.namenode.safemode.threshold-pct</name>
- <value>0.999f</value>
- </property>
-
有时,在安全模式下, 用户想要执行某条命令,特别是在脚本中,此时可以先让安全模式进入等待状态。
hdfs dfsadmin -safemode wait
-
7.3 DataNode与NameNode通信(心跳机制)
1.hdfs是master/slave结构,master包括namenode和resourcemanager,slave包括datanode和nodemanager 2.master启动时会开启一个IPC服务,等待slave连接 3.slave启动后,会主动连接IPC服务,并且每隔3秒链接一次,这个时间是可以调整的,设置hearbeat,这个每隔一段时间连接一次的机制,称为心跳机制。slave通过心跳给master汇报自己信息,master通过心跳下达命令。 4.Namenode通过心跳得知datanode状态。Resourcemanager通过心跳得知nodemanager状态 5.当master长时间没有收到slave信息时,就认为slave挂掉了。
注意:超长时间计算结果:默认为10分钟30秒
属性:dfs.namenode.hearbeat.recheck-interval 的默认值为5分钟 #Recheck的时间单位为毫秒 属性:dfs.hearbeat.interval 的默认值时3秒, #heartbeat的时间单位为秒 计算公式:2 * recheck + 10 * heartbeat
7.4 SecondayNamenode的工作机制(检查点机制)
SecondaryNamenode,是HDFS集群中的重要组成部分,它可以辅助Namenode进行editlog的合并工作,减小editlog文件大小,以便缩短下次Namenode的重启时间,能尽快退出安全模式。
两个文件的合并周期,称之为检查点机制(checkpoint),是可以通过hdfs-default.xml配置文件进行修改(hdfs-site.xml)的:
- <property>
- <name>dfs.namenode.checkpoint.period</name>
- <value>3600</value>
- <description>两次检查点间隔的秒数,默认是1个小时</description>
- </property>
- <property>
- <name>dfs.namenode.checkpoint.txns</name>
- <value>1000000</value>
- <description>txid执行的次数达到100w次,也执行checkpoint</description>
- </property>
- <property>
- <name>dfs.namenode.checkpoint.check.period</name>
- <value>60</value>
- <description>60秒一检查txid的执行次数</description>
- </property>
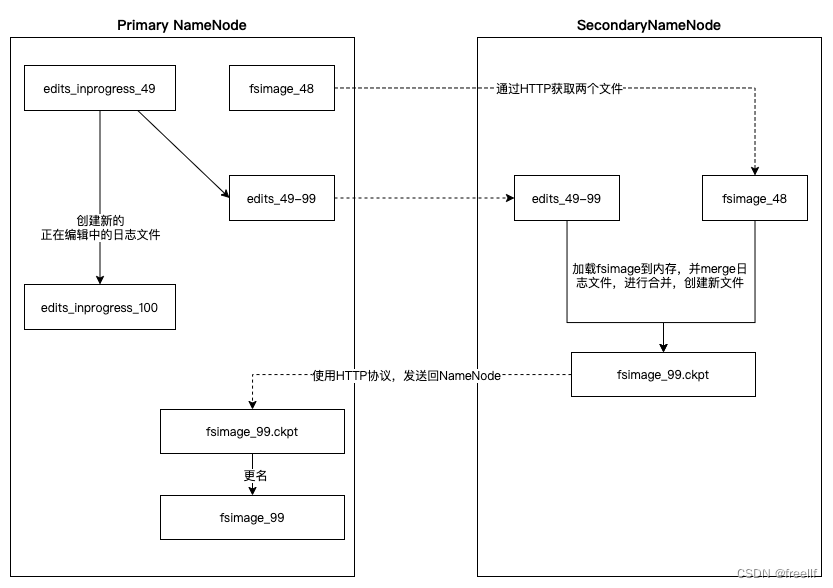
通过上图,可以总结如下:
1. SecondaryNamenode请求Namenode停止使用正在编辑的editlog文件,Namenode会创建新的editlog文件,同时更新seed_txid文件。 2. SecondaryNamenode通过HTTP协议获取Namenode上的fsimage和editlog文件。 3. SecondaryNamenode将fsimage读进内存当中,并逐步分析editlog文件里的数据,进行合并操作,然后写入新文件fsimage_x.ckpt文件中。 4. SecondaryNamenode将新文件fsimage_x.ckpt通过HTTP协议发送回Namenode。 5. Namenode再进行更名操作。
7.5 读流程的详解
- 读操作
- -hdfs dfs -get /file02 ./file02
- -hdfs dfs -copyToLocal /file02 ./file02
- -FSDataInputStream fsis = fs.open("/input/a.txt");
- -fsis.read(byte[] a);
- -fs.copyToLocal(path1, path2);
1.客户端通过调用FileSystem对象的open()方法来打开希望读取的文件,对于HDFS来说,这个对象是DistrbutedFileSystem,它通过使用远程过程调用(RPC)来调用namenode,以确定文件起始块的位置。
2.对于第一个块,Namenode返回存有该副本的DataNode地址,并根据距离客户端的远近来排序。
3.DistributedFileSystem实例会返回一个FSDataInputStream对象(支持文件定位功能)给客户端以便读取数据,接着客户端对这个输入流调用read()方法。
4.FSDataInputStream随即连接距离最近的文件中第一个块所在的DataNode,通过对数据流反复调用read()方法,可以将数据从DataNode传输到客户端。
5.当读取到块的末端时,FSInputStream关闭与该DataNode的连接,然后寻找下一个块的最佳DataNode
6.客户端从流中读取数据时,块是按照打开FSInputStream与DataNode的新建连接的顺序读取的。它也会根据需要询问NameNode来检索下一批数据块的DataNode的位置。一旦客户端完成读取,就对FSInputStream调用close方法。
注意:在读取数据的时候,如果FSInputStream与DataNode通信时遇到错误,会尝试从这个块的最近的DataNode读取数据,并且记住那个故障的DataNode,保证后续不会反复读取该节点上后续的块。FInputStream也会通过校验和确认从DataNode发来的数据是否完整。如果发现有损坏的块,FSInputStream会从其他的块读取副本,并且将损坏的块通知给NameNode。
7.6 写流程的详解
- 写操作
- - hdfs dfs -put ./file02 /file02
- - hdfs dfs -copyFromLocal ./file02 /file02
- - FSDataOutputStream fsout = fs.create(path);
- fsout.write(byte[]);
- - fs.copyFromLocal(path1, path2);
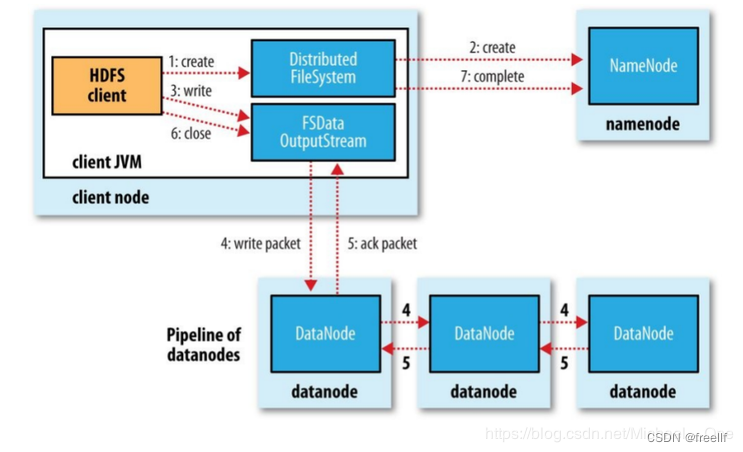 详细图解
详细图解
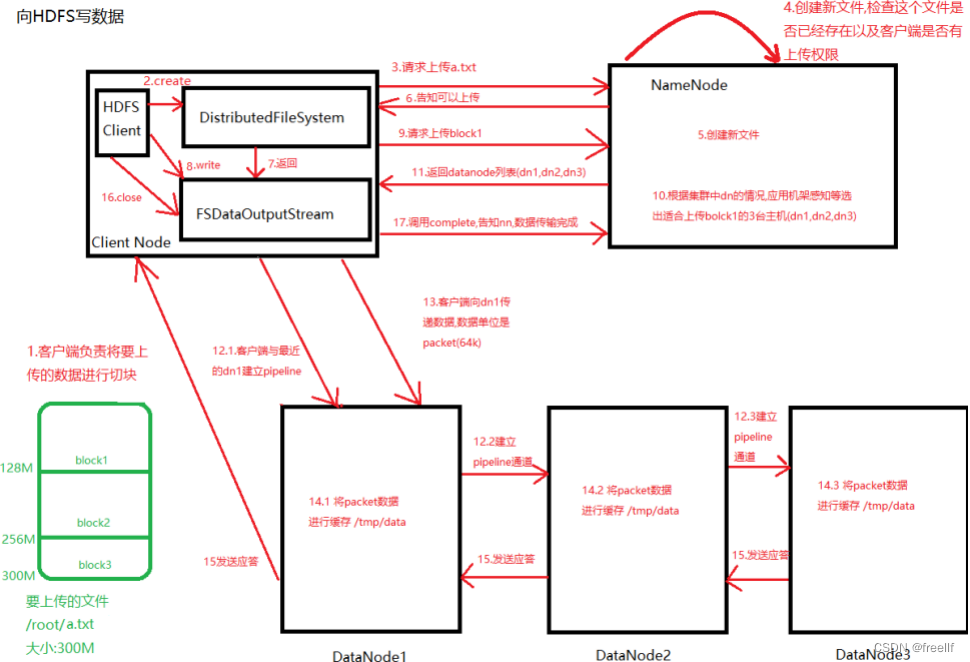 实现过程
实现过程
在图的1和2,客户端(操作者)通过调用DistributedFileSystem对象的create()方法(内部会调用HDFSClient对象的create()方法),实现在namenode上创建新的文件并返回一个FSDataOutputSteam对象. 1)DistributedFileSystem要通过RPC调用namenode去创建一个没有blocks关联的新文件,此时该文件中还没有相应的数据块信息。 2)但是在新文件创建之前,namenode执行各种不同的检查,以确保这个文件不存在以及客户端有新建该文件的权限。如果检查通过,namenode就会为创建新文件记录一条事务记录(否则,文件创建失败并向客户端抛出一个IOException异常)。DistributedFileSystem向客户端返回一个FSDataOutputStream对象。 3)FSDataOutputStream被封装成DFSOutputStream.DFSOutputSteam能够协调namenode和datanode。客户端开始写数据到DFSOutputSteam,DFSOutputStream会把数据分析成一个个的数据包(packet).并写入一个内部队列,这个队列称为"数据对列"(dataqueue); 4)DataStream会去处理接受Data queue,它先询问namenode这个新的block最适合存储的在哪几个datanode里(比方副本数量3,那么就找到3个最适合的datanode),把他们排成一个pipeline,DataStream把packet组成,作用是等待datanode完全接收完数据后接收响应。 5)datanode写入数据成功之后,会为ResponseProcessor线程发送一个写入成功的信息回执,当收到管理中所有的datanode确认信息后,ResponseProcessor线程会将该数据包确认从队列中删除。 6)客户端写完数据后调用 close()方法,关闭写入流。 7)DataStreamer把剩余的包都刷到pipeline里,然后等待ack信息,收到最后一个ack后,客户端通过调用DistributedFileSystem对象的complete()方法来告知namenode数据传输完成。
注意点1:如果任何datanode在写入数据期间发生故障,则执行以下操作:
1.首先关闭管道,把确认队列中的所有数据包都添加回数据队列的最前端,以确保故障节点下游的datanode不会漏掉任何一个数据包。 2.为存储在另一正常datanode的当前数据块制定一个新标识,并将该标识传送给namenode,以便故障datanode在恢复后可以删除存储的部分数据块 3.从管道中删除故障datanode,基于两个正常datanode构建一条新管道,余下数据块写入管道中正常的datanode 4.namenode注意到块副本不足时,会在一个新的Datanode节点上创建一个新的副本。
注意点2:
注意:在一个块被写入期间可能会有多个datanode同时发生故障,但概率非常低,只要写入了dfs.namenode.replication.min的副本数(默认1),写操作就会成功,并且这个块可以在集群中异步复制,直到达到其目标副本数dfs.replication的数量(默认3);
注意点3:
client运行write操作后,写完的block才是可见的,正在见的block对client是不可见的,仅仅有调用sync方法。client才确保该文件的写操作已经全部完毕。当client调用close方法时,会默认调用sync方法。
第八章 IDE远程管理HDFS
布署本地Hadoop环境
8.1本地环境配置
(1) windows系统
1.解压hadoop压缩包到指定路径 注意:hadoop解压的路径不要存在空格。
如:This command was run using /D:/BigData/hadoop-3.3.1/share/hadoop/common/hadoop-common-3.3.1.jar
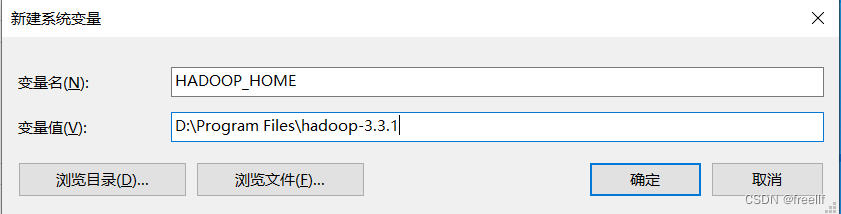
2.新建系统变量 HADOOP_HOME

3. 加入windows支持
Hadoop本身对Windows的支持并不友好,如果需要完整使用,需要将winutils.exe和hadoop.dll两个文件移动到%HADOOP_HOME%\bin目录

4.编辑%HADOOP_HOME%\etc/hadoop\hadoop-env.cmd, 设置JAVA_HOME
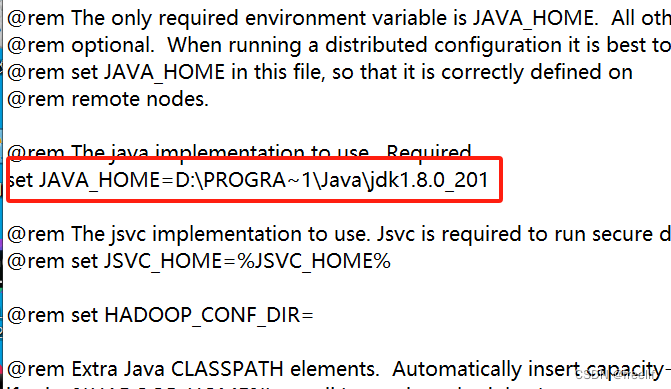
在HADOOP_IDENT_STRING后面加引号

如出现下面问题,注意检查上面的JAVA_HOME的配置路径

验证:
 (2) MacOS环境布署
(2) MacOS环境布署
-
解压包
tar -zxvf hadoop-3.3.1-aarch64 -C /opt/softwares -
配置hadoop-env.sh
export JAVA_HOME=`/usr/libexec/java_home`
-
配置环境变量
- vim ~/.bash_profile
-
- export HADOOP_HOME=/opt/softwares/hadoop-3.3.1
- export PATH+$PATH;$HADOOP_HOME/bin;$HADOOP_HOME/sbin;
-
验证
hadoop version
8.2 创建pom文件
- <dependencies>
- <dependency>
- <groupId>org.apache.hadoop</groupId>
- <artifactId>hadoop-common</artifactId>
- <version>3.3.1</version>
- </dependency>
- <dependency>
- <groupId>org.apache.hadoop</groupId>
- <artifactId>hadoop-client</artifactId>
- <version>3.3.1</version>
- </dependency>
- <dependency>
- <groupId>org.apache.hadoop</groupId>
- <artifactId>hadoop-hdfs</artifactId>
- <version>3.3.1</version>
- </dependency>
- </dependencies>
8.3 创建文件系统对象
- /*
- 文件系统对象的获取
- */
- @Test
- public void getFileSystemTest() throws IOException {
- //创建配置文件对象,加载配置文件上的配置信息
- //默认读取core-default.xml, hdfs-default.xml, mapred-default.xml yarn-default.xml
- //如果项目中有配置文件,则继续读取项目中的配置文件 core-site.xml, hdfa-site.xml, mapred-site.xml yarn-site.xml
- //读取完成之后,也可以自己去配置信息
- //属性优先级: 代码中的设置 > *-site.xml > *-default.xml
- Configuration conf = new Configuration();
-
- //配置属性
- conf.set("fs.defaultFS", "hdfs://192.168.68.128:9820");
- FileSystem fs = FileSystem.get(conf);
- System.out.println(fs.getClass().getName());
- }
8.4 文件的上传与下载、文件夹的创建与删除、重命名与存在
- /**
- * 我们对HDFS进行使嘴使舌,使用的用户都是当前系统登录的用户。
- * 因此,如果使用不正确的用户来进行HDFS的写操作的时候,会出现权限不足的情况。
- * 解决方案:
- * 1. 修改需要操作的路径权限,权限改成777
- * 2. 修改需要操作的路径所属用户
- * 3. 可以设置操作集群的用户是谁
- */
- public class HDFSApi {
-
- private FileSystem fs;
- /*
- 文件系统对象的获取
- */
- @Before
- public void getFileSystemTest() throws IOException {
-
- System.out.println("before...............................................");
- //设置操作HADOOP的用户是谁
- System.setProperty("HADOOP_USER_NAME", "root");
- //创建配置文件对象,加载配置文件上的配置信息
- //默认读取core-default.xml, hdfs-default.xml, mapred-default.xml yarn-default.xml
- //如果项目中有配置文件,则继续读取项目中的配置文件 core-site.xml, hdfa-site.xml, mapred-site.xml yarn-site.xml
- //读取完成之后,也可以自己去配置信息
- //属性优先级: 代码中的设置 > *-site.xml > *-default.xml
- Configuration conf = new Configuration();
-
- //配置属性
- conf.set("fs.defaultFS", "hdfs://192.168.68.128:9820");
- fs = FileSystem.get(conf);
- System.out.println(fs.getClass().getName());
- }
-
- @After
- public void closeFileSystem() throws IOException {
- System.out.println("after..........................................");
- fs.close();
- }
- /**
- * 文件上传
- */
- @Test
- public void uploadTest() throws IOException {
- //需要操作的两个路径,本地源文件的路径和HDFS的路径
- Path src = new Path("F:/p50d/tools/redis-5.0.9.tar.gz");
- Path dst = new Path("/");
- //直接调用方法上传文件即可
- fs.copyFromLocalFile(src, dst);
- }
-
- /**
- * 文件下载
- */
- @Test
- public void downloadTest() throws IOException {
- //需要设置两个路径,HDFS的文件路径和本地存储的文件路径
- Path src = new Path("/redis-5.0.9.tar.gz");
- Path dst = new Path("d:/BigData/redis-5.0.9.tar.gz");
- //直接调用方法下载文件即可
- fs.copyToLocalFile(src, dst);
- }
-
- /**
- * 创建文件夹
- */
- @Test
- public void createDirTest() throws IOException {
- fs.mkdirs(new Path("/apiTest"));
- }
-
- /**
- * 删除文件夹
- */
- @Test
- public void delDirTest() throws IOException {
- boolean delete = fs.delete(new Path("/output"), true);
- }
-
- /**
- * 重命名
- */
- @Test
- public void renameTest() throws IOException {
- fs.rename(new Path("/input"), new Path("/newInput"));
- }
-
- /**
- * 测试存在
- */
- @Test
- public void existsTest() throws IOException {
- boolean isExists = fs.exists(new Path("/input"));
- System.out.println(isExists ? "存在" : "不存在");
- }
- }
8.5 HDFS-IOUtils工具类的使用
- @Test
- public void ioUtilsTest() throws IOException {
- System.setProperty("HADOOP_USER_NAME", "root");
- Configuration configuration = new Configuration();
- configuration.set("fs.defaultFS", "hdfs://192.168.68.128:9820");
- FileSystem fileSystem = FileSystem.get(configuration);
-
- //IOUtils上传
- FileInputStream input = new FileInputStream("D:\\Android\\android-sdk\\build-tools\\32.0.0\\NOTICE.txt");
- FSDataOutputStream output = fileSystem.create(new Path("/NOTICE.txt"));
- IOUtils.copyBytes(input, output, configuration);
- IOUtils.closeStream(input);
- IOUtils.closeStream(output);
-
- //IOUtils下载
- FSDataInputStream downInput = fileSystem.open(new Path("/NOTICE.txt"));
- FileOutputStream downOutput = new FileOutputStream("E:\\360Downloads\\Software\\NOTICE.txt");
- IOUtils.copyBytes(downInput, downOutput, configuration);
- IOUtils.closeStream(input);
- IOUtils.closeStream(output);
- fileSystem.close();
- }
8.6 文件状态查看
- /**
- * 文件状态信息查看
- */
- @Test
- public void listFileStatusTest() throws IOException {
- //获取每一个文件的状态信息列表,迭代器对象
- RemoteIterator<LocatedFileStatus> iterator = fs.listLocatedStatus(new Path("/CentOS-Stream-8-x86_64-20220328-dvd1.iso"));
-
- while(iterator.hasNext())
- {
- //获取当前遍历到的文件
- LocatedFileStatus fileStatus = iterator.next();
- System.out.println("基本信息:" + fileStatus.getBlockLocations());
- //获取所有块的信息
- BlockLocation[] blockLocations = fileStatus.getBlockLocations();
- for(BlockLocation blockLocation : blockLocations)
- {
- System.out.println("当前块的所有副本信息:" + Arrays.toString(blockLocation.getHosts()));
- System.out.println("当前块大小:" + blockLocation.getLength());
- System.out.println("当前块的副本的IP地址:" + Arrays.toString(blockLocation.getNames()));
- }
- System.out.println("系统的块大小:" + fileStatus.getBlockSize());
- System.out.println("当前文件的总大小: " + fileStatus.getLen());
- }
- }
第九章 HDFS的高级操作
9.1 磁盘检测
在HDFS上所有的文件都是以Block的形式存在的,如果在HDFS上存储了海量的数据文件,就会对应有海量的Block的存在,而这些Block难免会因为存在损坏的情况。有什么方法可以去发现哪些块出现了问题呢?可以使用fsck命令。
fsck的选项
| 选项 | 描述 |
|---|---|
| -move | 移动损坏的文件到/lost+found目录下 |
| -delete | 删除损坏的文件 |
| -files | 输出正在被检测的文件 |
| -openforwrite | 输出检测的正在被写入的文件 |
| -includeSnapshots | 检测的文件包括系统snapShot快照目录下的 |
| -list-corruptfileblocks | 输出损坏的块及所属的文件 |
| -blocks | 输出block的详细报告 |
| -locations | 输出block的位置信息 |
| -racks | 输出block的网络拓扑结构 |
| -storagepolicies | 输出block的存储策略 |
| -blockId | 输出指定blockId所属块的信息 |
常见用法:
-
检查文件系统健康状态
hdfs fsck /这个命令会检查整个文件系统的所有文件的健康状态,正常情况下,最后会看到"The filesystem under path '/' is HEALTHY"
-
-files
-files 选项可以列举出来被检查的文件都有谁,以及健康状态信息,例如:
- hdfs fsck /test -files
- /test <dir>
- /test/hadoop-3.3.1.tar.gz 605187279 bytes, replicated: replication=3, 5 block(s): OK
-
-blocks
-blocks 选项可以列举出来被检查的每一个文件的Block信息,例如:
- hdfs fsck /test -files -blocks
- Connecting to namenode via http://hadoopmaster:9870/fsck?ugi=root&files=1&blocks=1&path=%2Ftest
- FSCK started by root (auth:SIMPLE) from /192.168.68.128 for path /test at Tue Jan 23 02:59:52 EST 2024
-
- /test <dir>
- /test/hadoop-3.3.1.tar.gz 605187279 bytes, replicated: replication=3, 5 block(s): OK
- 0. BP-516840995-192.168.68.128-1698222078689:blk_1073742006_1182 len=134217728 Live_repl=3
- 1. BP-516840995-192.168.68.128-1698222078689:blk_1073742007_1183 len=134217728 Live_repl=3
- 2. BP-516840995-192.168.68.128-1698222078689:blk_1073742008_1184 len=134217728 Live_repl=3
- 3. BP-516840995-192.168.68.128-1698222078689:blk_1073742009_1185 len=134217728 Live_repl=3
- 4. BP-516840995-192.168.68.128-1698222078689:blk_1073742010_1186 len=68316367 Live_repl=3
-
-locations
-locations 选项可以列举出来每一个 Block 的位置信息,例如
hdfs fsck /test -files -blocks -locations -
-list-corruptfileblocks
-list-corruptfileblocks 选项可以列举出来损坏的 block 的信息,例如
hdfs fsck /test -list-corruptfileblocks
9.2 动态上线
HDFS支持在廉价硬件上部署分布式文件系统,来存储海量的数据,并且支持扩容。如果已有HDFS的集群容量已经不能满足存储数据的需求,此时可以在原有集群的基础上动态添加新的DataNode节点,来实现对集群的动态扩容。
-
集群规模规划
扩容之前的集群如下:
IP地址 hostname 角色进程 192.168.68.128 hadoop master NameNode DataNode 192.168.68.129 hadoop node1 SecondaryNameNode, DataNode 192.168.68.130 hadoop node2 Datanode 扩容之后的集群如下:
| IP地址 | hostname | 角色进程 |
|---|---|---|
| 192.168.68.128 | hadoop master | NameNode DataNode |
| 192.168.68.129 | hadoop node1 | SecondaryNameNode, DataNode |
| 192.168.68.130 | hadoop node2 | Datanode |
| 192.168.68.131 | hadoop node3 | Datanode |
2. 动态上线过程
2.1 准备一台新的虚拟机,准备职下工作:
- 1. 设置IP地址为192.168.68.131
- 2. 设置hostname为 hadoopnode3 #vi /etc/hostname
- 3. 设置防火墙关闭
- 4. 设置时间同步
- 5. 安装JDK并设置JDK的环境变量(可以直接从已有节点拷贝)
- 6. 安装hadoop并设置Hadoop的环境变量
2.2.在hadoopmaster节点进行修改操作,添加对hadoopnode3的host映射,并同步给每一个节点
- #编辑 hadoopmaster节点上的 /etc/hosts文件,添加映射
- 192.168.68.131 hadoopnode3
-
- #分发给其他的节点
- scp /etc/hosts hadoopnode1:/etc
- scp /etc/hosts hadoopnode2:/etc
- scp /etc/hosts hadoopnode3:/etc
2.3.设置hadoopmaster到hadoopnode3节点的免密登录
- #将hadoopmaster节点生成的公钥拷贝到hadoopnode3节点
- ssh-copy-id hadoopnode3
2.4.修改hadoopmaster节点上的Hadoop配置文件中的workers文件,添加hadoopnode3
- #编辑 workers 文件
- vim /usr/local/hadoop-3.3.1/etc/hadoop/workers
- #添加hadoopnode3
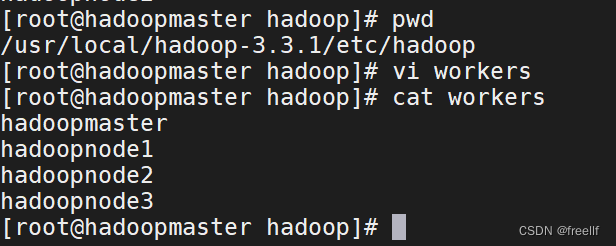
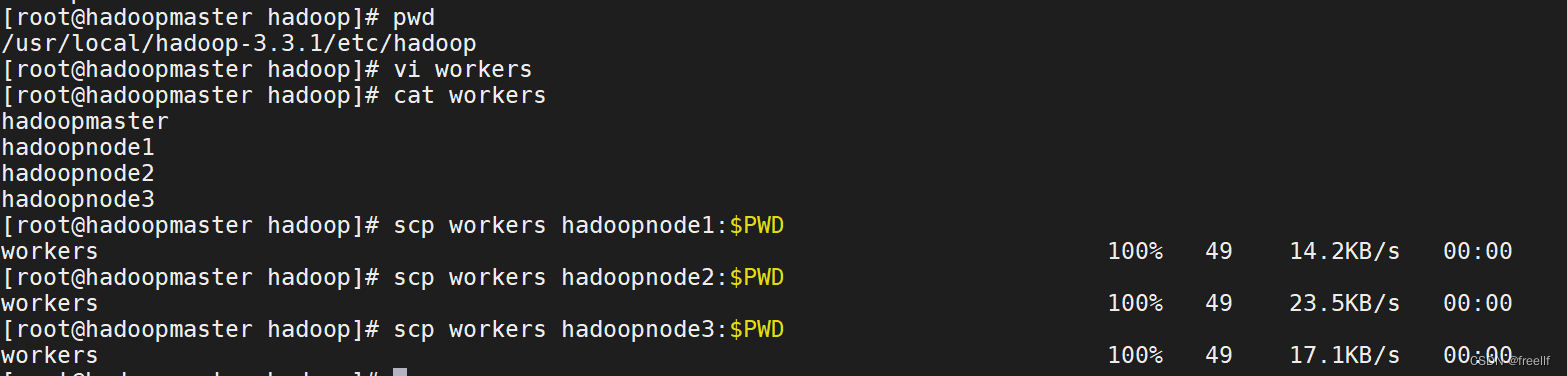
3. 将编辑之后的workers文件分发到hadoopnode1, hadoopnode2, hadoopnode3等节点
4. 将hadoopmaster节点的Hadoop的配置文件直接拷贝到hadoopmaster节点
- cd /usr/Local/hadoop-3.3.1/etc
- scp -r hadoop/ hadoopnode3:$PWD

5. 在hadoopnode3节点启动DataNode
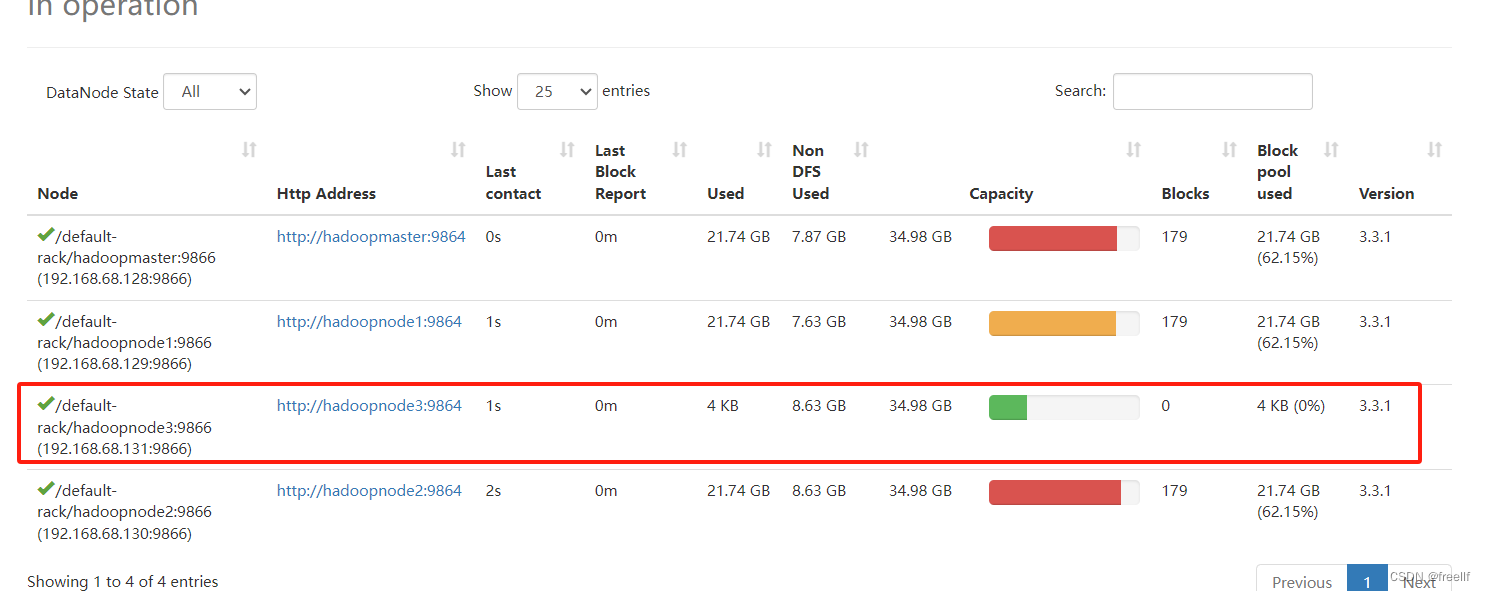
hdfs --daemon start datanode6. 打开WebUI查看DataNodes,发现hadoopnode3节点已经上线
9.3 数据平衡
虽然现在已经上线了hadoopnode3节点,但是我们会发现这个新上线的节点上没有数据存储。可以在WebUI的DataNodes界面查看到这个新的节点上的Blocks的数量为0,这样就使用集群的负载不均衡。因此我们需要对HDFS进行节点之间的数据均衡。
通过balancer可以实现这个效果!在主节点hadoopmaster上执行的balancer命令,实现均衡不同的DataNodes之间的负载。
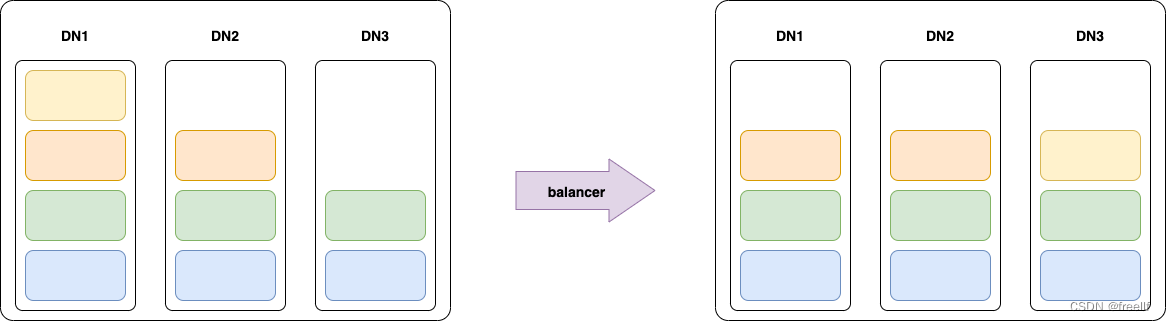
使用balancer的时候需要设置threshold参数,表示均衡的阈值。默认的阈值是10,表示10%的阈值。这个阈值表示balancer在进行数据均衡的时候,将保证每个DataNode上的磁盘使用量与集群的总体使用量的差值不超过这个阈值。
例如: 将阈值设置为10%
那么在做数据平衡的时候,如果集群中所有的DataNode节点总的使用占全部磁盘的40%,那么就确保每一个DataNode的磁盘使用率在30%到40%之间.
为了能够更加方便看到效果,我们可以使用1来设置平衡:
hdfs balancer -threshold 19.4 节点动态下线
节点的动态下线比起动态上线来说,稍微麻烦一些. 因为动态下线的时候需要提前将数据移动到其他节点才可以.Hadoop虽然提供了动态下线的功能,但是有一个前提条件就是需要再在hdfs-site.xml文件中配置属性: dfs.hosts.exclude.这个属性的值需要指向一个文件,也就是需要下线的文件.也就是一个黑名单,在这个文件中的机器,会被NameNode移除集群.
但是这个hdfs-site.xml文件修改之后是需要重启集群才生效的.因此在生产环境中,我们需要提前将这个属性配置好,因为生产环境中的集群是不允许随意的关闭、重启的。在学习阶段,就简单多了,直接修改这个文件,然后重启集群即可。
1.准备工作
1.修改hadoopmaster节点的hdfs-site.xml文件
- <property>
- <name>dfs.hosts.exclude</name>
- <value>/usr/local/hadoop-3.3.1/etc/hadoop/exclude</value>
- </property>
2.创建这个exclude文件
- # 这个文件是一个黑名单文件,为了操作起来方便、合理,我们将它放在Hadoop的配置文件目录中
- touch /usr/local/hadoop-3.3.1/etc/hadoop/exclude
3.重启HDFS集群
- stop-dfs.sh
- start-dfs.sh
2.动态下线过程
1.将需要下线的节点,添加到exclude文件中
echo "hadoopnode3" > /usr/local/hadoop-3.3.1/etc/hadoop/exclude注意事项:下线之后的节点数量,不能少于副本数量,例如副本因子为 3 , 在线的节点数量是小于等于3的,此时是无法下线的。如果需要下线,需要修改副本数这后再下线。
-
刷新节点(需要在NameNode节点操作)
hdfs dfsadmin -refreshNodes -
在WebUI查看节点状态民

-
退役完成,此时我们就可以放心的停止hadoopnode3节点上的服务了

hdfs --daemon stop datanode-
其他节点的数据不果不均衡的话,使用balancer命令平衡一下即可
hdfs balancer注:
如果这个节点下线之后,从此就不再使用,我们可以修改workers文件,从中删除掉这个节点,再修改exclude文件,将其从中删除即可。
9.5 磁盘平衡
HDFS提供了一个balance命令,可以实现DataNode之间的负载均衡。但是一个DataNode节点上可能存在多个磁盘,而banlancer是无法实现单个节点上的磁盘之间的均衡的。
在HDFS中,DataNode是真正负责数据均的存储的,最终数据以Block的形式存储在机器的磁盘上。在写入新的Block的时候,DataNode将根据指定的策略,选择将数据块存储在什么磁盘上:
-
循环策略 round-robin:这种策略会将新的 Block 均匀的分布在可用的磁盘上。默认使用这个策略。
-
可用空间策略 avaliable space: 这种策略会将新的 Block 会按照磁盘占用百分比,写入具有更多可用空间的磁盘上。
如果在长期运行的集群中采用默认的循环策略,可能会出现由于大量的删除操作,或者更换磁盘,而导致数据不均匀的填充在磁盘上。而使用可用空间策略的话,新增的数据块都会往新的磁盘上写,在此期间,其他的磁盘都处于空闲状态。那么这个新的磁盘将会是整个HDFS的瓶颈。
在Hadoop3中新增了一个Disk Balance的工具,这个工具就是用来平衡BataNode中的数据在不同磁盘之间分布的。
-
磁盘平衡实现
前提1:在hadoopnode2节点上挂载一块新的硬盘为例,在hadoopnode2节点挂载了一块新的硬盘,并将其挂载在/mnt/disk目录:
详见:VMware虚拟机添加新硬盘以及对磁盘进行分区挂载 VMware虚拟机添加新硬盘以及对磁盘进行分区挂载_51CTO博客_vmware虚拟机添加硬盘的步骤
查看磁盘情况(新加载磁盘为/dev/sdb):
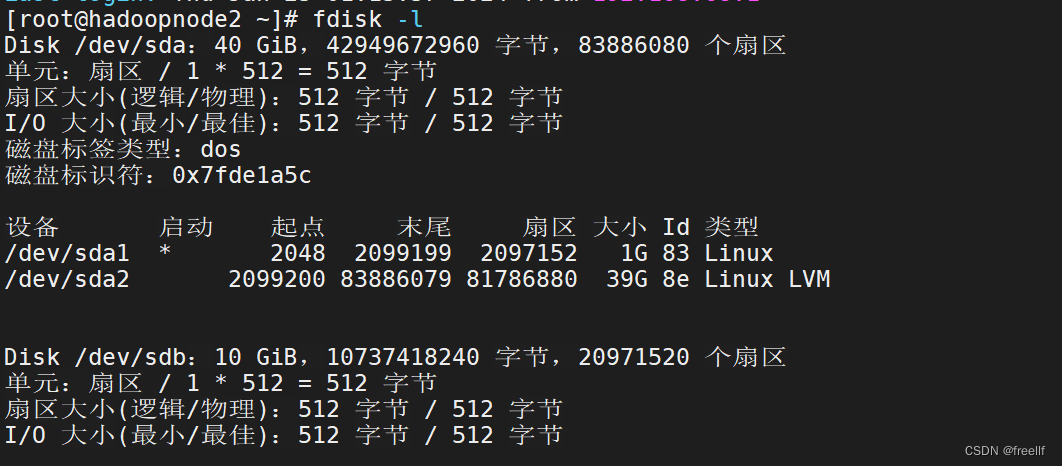
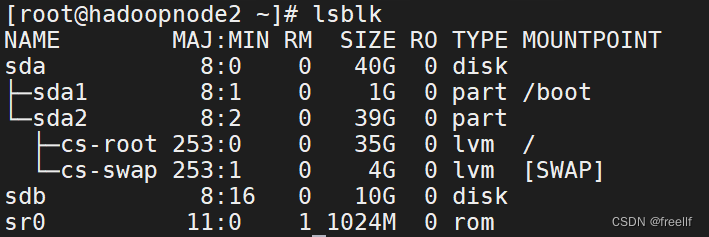
查看分区情况:lsblk
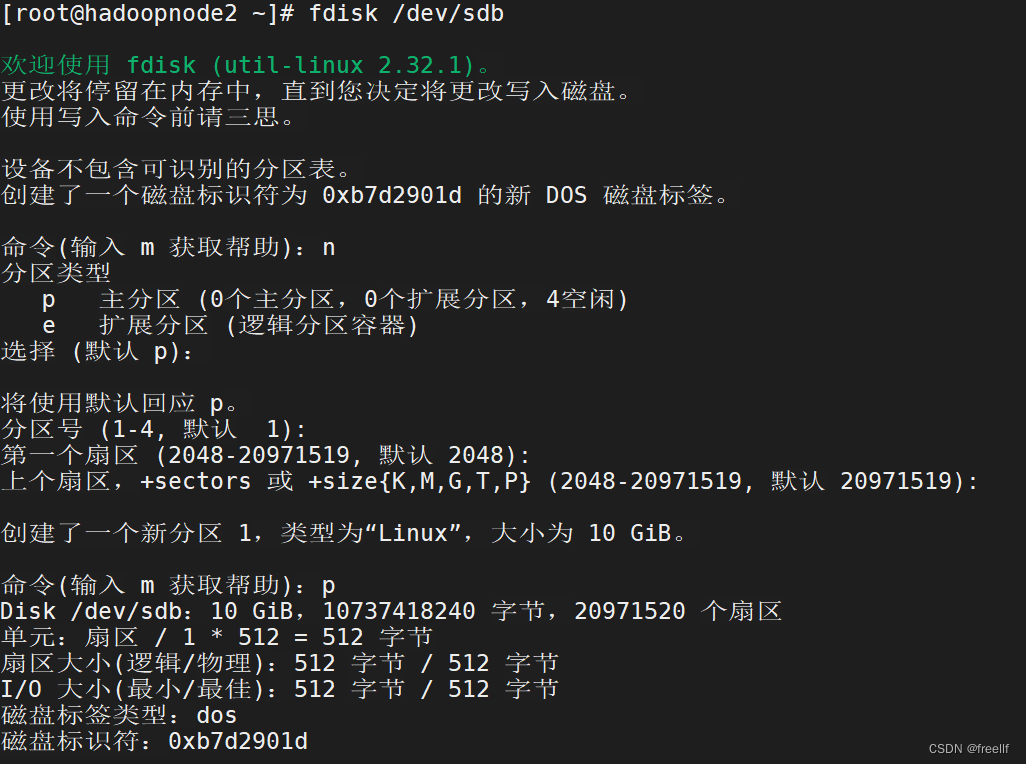
使用命令: fdisk /dev/sdb
n 新建分区
其他默认
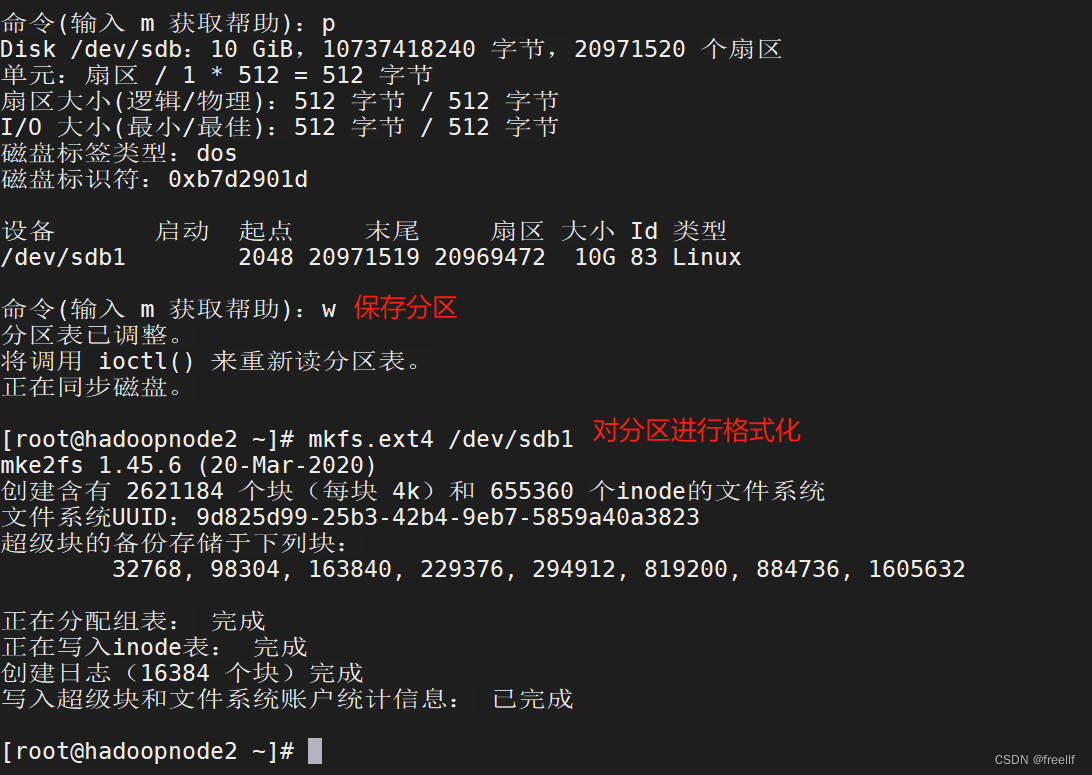
分区挂载
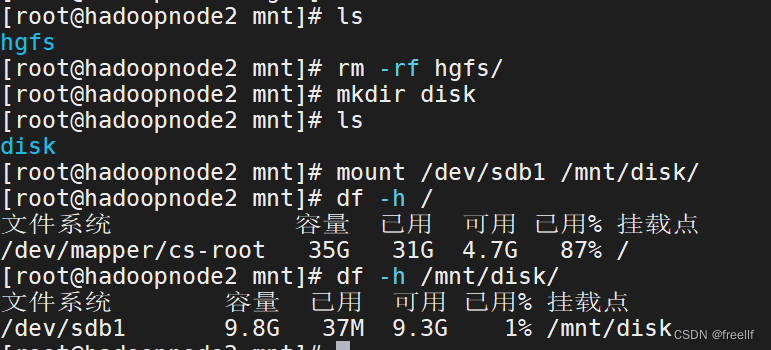
-
修改增加磁盘节点的hdfs-site.xml

-
在 hadoopnode2节点上,现在有两块硬盘,并且两块磁盘的数据并不均衡。此时可以使用磁盘平衡工具,来平衡两块磁盘。磁盘平衡工具 diskbalancer 在使用的时候分为 3 步:
-
生成平衡计划
- # 平衡的时候,默认的阈值是10%,表示平衡之后的磁盘间的数据使用占比差值不会超过10%
- # 这个阈值可以使用 -thresholdPercentage 来设置
- hdfs diskbalancer -plan hadoopnode2
- # 可以从输出的日志中,看到生成了磁盘平衡计划,以 JSON 的形式保存在了 HDFS 的指定目录下
- INFO balancer.NameNodeConnector: getBlocks calls for hdfs://hadoopnode2:9820 will be rate-limited to 20 per second
- INFO planner.GreedyPlanner: Starting plan for Node : hadoopnode2:9867
- INFO planner.GreedyPlanner: Disk Volume set e003df25-b249-4f06-91d9-ef0116ce552e - Type : DISK plan completed.
- INFO planner.GreedyPlanner: Compute Plan for Node : :9867 took 9 ms
- INFO command.Command: Writing plan to:
- INFO command.Command: /system/diskbalancer/2023-三月-02-16-42-00/hadoopnode2.plan.json
- Writing plan to:
- /system/diskbalancer/XXX/qianfeng03.plan.json
-
执行平衡操作
- # 在需要平衡磁盘的节点上执行
- hdfs diskbalancer -execute /system/diskbalancer/XXX/hadoopnode2.plan.json
-
查看平衡结果
- # -execute开始执行平衡操作的时候,HDFS 会启动一个线程来完成这个操作。
- # 我们可以使用 -query 来查看这个进度
- hdfs diskbalancer -query hadoopnode2
-
- # 出现如下的 Result,说明正在执行中,还没有结束
- Plan File: /system/diskbalancer/XXX/hadoopnode2.plan.json
- Plan ID: 63d55420750b6657e608a67db7571ad171dfd5d8
- Result: PLAN_UNDER_PROGRESS
-
- # 出现如下的 Result,说明磁盘平衡结束了
- Plan File: /system/diskbalancer/XXX/hadoopnode2.plan.json
- Plan ID: 63d55420750b6657e608a67db7571ad171dfd5d8
- Result: PLAN_DONE
磁盘平衡结束后,我们可以使用 df -h 来查看各个磁盘的使用情况:
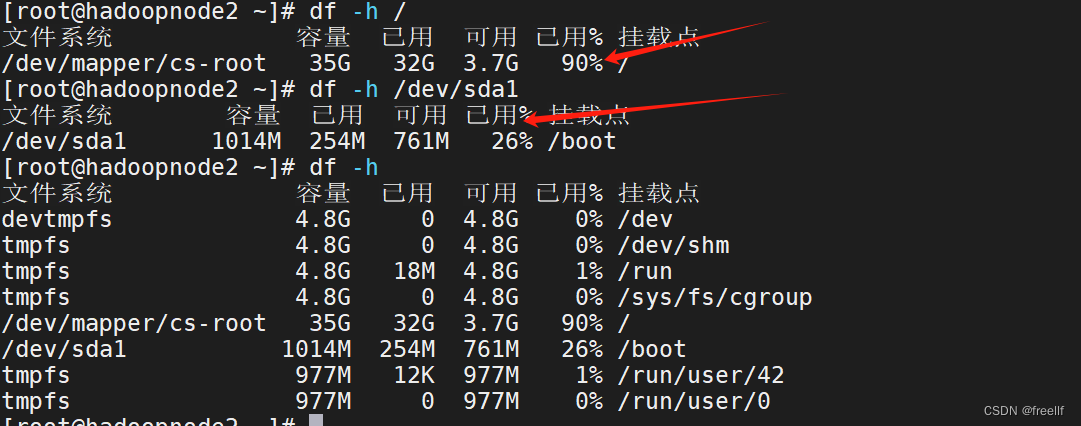
会发现两者之间被平衡到了 10% 的阈值以内,这个也是默认的阈值。磁盘平衡完成!
-
9.6 分布式拷贝(需要调试)
-
distcp的介绍
distcp其实是两个单词的缩写拼接而成的:Distributed Copy. 即分布式拷贝。可以实现将一个分布式集群的数据拷贝到另外的一个分布式集群! distcp命令的拷贝过程本质依然是MapReduce的任务,使用MapReduce实现文件分发,错误处理和恢复,报告生成,以文件或目录的列表作为MapTask的输入,每个MapTask都会拷贝原文件列表中指定路径下的文件。
应用场景:数据迁移、异地容灾等。
使用distcp命令做分布式拷贝有如下优点:
-
可以使用 bandwidth 参数为每一个MapTask限流,控制MapTask并发数量以控制整个个拷贝任务的带宽,防止出现拷贝任务将带宽占满,影响其他的业务。
-
支持多种拷贝模式:
-
overwrite: 覆盖写,无条件覆盖目标文件
-
update: 增量写,如果目标文件的名称和大小与源文件不同,则覆盖;如果目标文件的名称和大小与源文件相同,则路过
-
delete:删除写,删除目标路径存在而原路径中不存在的文件。
-
-
distcp的使用
1.基础使用
distcp最基础的使用,就是直接在两个集群之间进行文件的拷贝。
hadoop distcp hdfs://old:9820/{path} hdfs://new:9820/{path}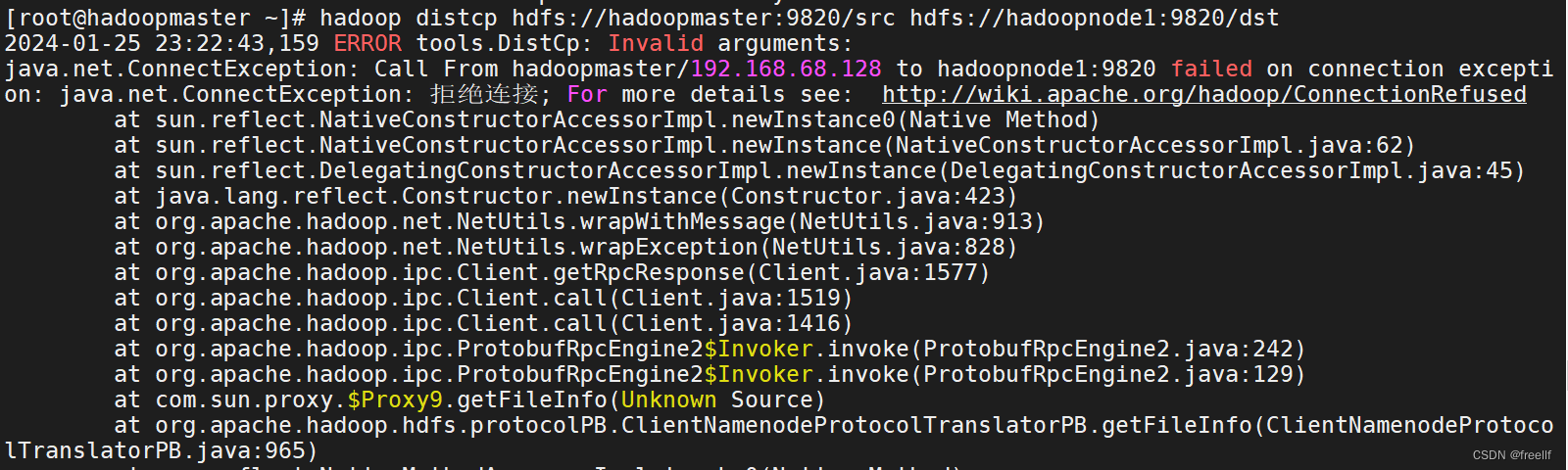
-
多数据源目录
-
在拷贝的时候,也可以指定多个源路径
hadoop distcp hdfs://hadoopmaster:9820/src1 hdfs://hadoopmaster:9820/src2 hdfs://hadoopmaster:9820/dst如果需要拷贝的源路径比较多,不方便直接写到命令中的,也可以将其做成文件
- # 1. 在 HDFS 上创建一个文件,用来存储源路径 # 例如在 hdfs://namenode01:9820/distcp/src 文件中书写 hdfs://hadoopmaster:9820/src1 hdfs://hadoopmaster:9820/src2 hdfs://hadoopmaster:9820/src3
-
- # 2. 执行拷贝操作
- hadoop distcp -f hdfs://old:9820/{path} hdfs://new:9820/{path}
3. 常用选项
| 选项 | 描述 | 备注 |
|---|---|---|
| -i | 忽略错误 | |
| -log <logdir> | 生成日志到logdir目录中 | 这里其实就是 MapTask 的输出 |
| -m <num_maps> | 最大同时拷贝的数量 | 可以确定 MapTask 的数量 |
| -bandwidth | 为每个 MapTask 设置带宽,单位是MB/s | |
| -overwrite | 覆盖目标路径 | 会改变源目录复制到目标目录的路径 |
| -update | 跳过目标路径下的同名、同大小的文件 | 会改变源目录复制到目标目录的路径 |
| -delete | 删除目标路径存在、源路径不存在的文件 |
9.7 归档
-
archives命令介绍
HDFS在使用的时候有一个缺点:不适合小文件存储.因为每一个小文件都会占用一个块来存储,而每一个块也都会有固定的大小的元数据需要保存在NameNode的内存中。如果HDFS中有大量的小文件的话,会带来非常大的内存开销,此时就可以用archives来处理这个问题。
archives就是归档的意思,它可以将HDFS的多个文件归档成为一个扩展名为.har的文件,而且归档之后的文件还可以透明的访问每一个文件,并且可以作为MapReduce任务的输入。
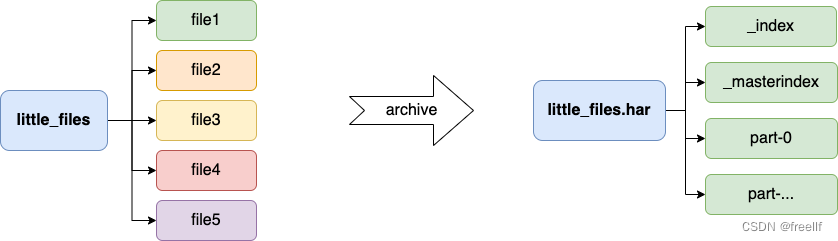
-
创建归档 2.1 创建归档语法
归档的用法:
hadoop archive -archiveName name -p <parent> [-r <replication factor>] <src>* <dest>2.2 创建归档操作
- #1.准备工作: 在HDFS的 /little_files 目录下,上传了若干小文件 file1, file2, file3, file4, file5
- #2.将file1、file2归档到一起,归档文件存放于 /archives
- hadoop archive -archiveName file12.har -p /little_files -r file1 file2 /archives/
- #3.如果需要将某个文件夹下的所有文件都进行归档,可以直接这样做
- hadoop archive -arciveName files.har -p /little_files /archive
创建归档的时候,会生成一个MapReduce的任务,如果已经设置了YARN调度,需要保证YARN是启动的状态。最终会在目标路径下生成归档文件。
归档文件在HDFS的体现形式其实是一个文件夹,其中包含了元数据信息(_index, _masterindex)和数据文件(part_xxx)
注意:创建归档之后,原来的小文件不会被删除!
2.3 查看归档
如果要查看某一个归档文件中都有什么文件,需要通过特定的URI进行查看。在HDFS中,归档文件默认使用的是 har://
hdfs dfs -ls -R har:///archives/files.har2.4 解归档
归档文件在HDFS的映射是一个文件夹,可以透明的访问其中的文件。因此如果我们需要将归档文件中的小文件解出来的话,直接进行拷贝即可,但是需要注意归档文件的URI是har://
- # 1. 在HDFS上创建一个文件夹,用来接收解归档之后的文件
- hdfs dfs -mkdir /unarchive
- # 2. 拷贝归档中的文件到指定目录
- hdfs dfs -cp har:///archives/files.har/file1 har:///archives/files.har/file2 /unarchive
- # 3. 也可以使用分布式拷贝命令实现拷贝
- hadoop distcp har:///archives/files.har/* /unarchive
2.5 归档特性总结
-
-archiveName: 指定归档后文件的名称,需要以.har结尾
-
-p: 指定需要归档的文件的父级路径
-
-r: 指定归档文件的副本因子,默认是 3
-
<src>: 指定所有需要归档的文件
-
<dest>: 指定归档后的文件存放的位置
-
归档文件本身不支持压缩
-
创建归档的时候使用到的小文件和目录都不会自动删除,如果需要删除,需要手动删除
-
归档文件是不可变的,如果想要在归档文件中新增小文件或者删除小文件,需要重新创建归档文件
-
归档文件只是用来减少小文件带来的NameNode过高的内存占用,对于MapReduce来说没有优化,并不会减少分片的数量,也就无法减少MapTask的数量
附1:分布式文件系统(HDFS和FastDFS)
(分布式文件系统(HDFS和FastDFS)-腾讯云开发者社区-腾讯云)
HDFS和FastDFS对比
| 测试项 | HDFS | FastDFS |
|---|---|---|
| 25个小文件上传 | 13599ms | 1949ms |
| 318个图片上传 | 63460ms | 9585ms |
| 3个700m视频上传 | 62092ms | 58137ms |
| 3个2g视频上传 | 171743ms | 131861ms |
| 25个小文件下载 | 13008ms | 1218ms |
| 318个图片下载 | 24942ms | 7051ms |
| 3个700m视频下载 | 69266ms | 36144ms |
| 3个2g视频下载 | 192315ms | 138215ms |
| 25个小文件删除 | 10517ms | 62ms |
| 318个图片删除 | 12828ms | 811ms |
| 3个700m视频删除 | 10286ms | 150ms |
| 3个2g视频删除 | 10594ms | 255ms |
结论
-
FastDFS客户端底层连接服务端使用的是Socket,本身速度就要快很多。
-
HDFS在做删除测试时,明显较慢的地方是在创建到服务端的连接上,实际删除文件的速度很快。由于每次测试都需要先创建到服务端的连接,HDFS在这块消耗较大,在实际场景下,差距应该没有这么大。
-
两者的适用场景确有不同,FastDFS更适合小文件的高效存取,而HDFS更适合超大文件上传后使用Mapreduce去做大数据处理
简介
概要
FastDFS 是一个开源的高性能分布式文件系统(DFS)。 它的主要功能包括:文件存储,文件同步和文件访问,以及高容量和负载平衡。主要解决了海量数据存储问题,特别适合以中小文件(建议范围:4KB < file_size <500MB)为载体的在线服务。
FastDFS 系统有三个角色:跟踪服务器(Tracker Server)、存储服务器(Storage Server)和客户端(Client)。
Tracker Server:跟踪服务器,主要做调度工作,起到均衡的作用;负责管理所有的 storage server和 group,每个 storage 在启动后会连接 Tracker,告知自己所属 group 等信息,并保持周期性心跳。
Storage Server:存储服务器,主要提供容量和备份服务;以 group 为单位,每个 group 内可以有多台 storage server,数据互为备份。
Client:客户端,上传下载数据的服务器,也就是我们自己的项目所部署在的服务器。
FastDFS开源地址:https://github.com/happyfish100
封装的FastDFS Java API:https://github.com/bojiangzhou/lyyzoo-fastdfs-java
文件上传
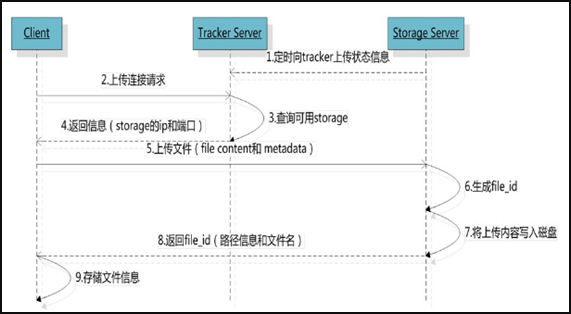
文件同步
写文件时,客户端将文件写至group内一个storage server即认为写文件成功,storage server写完文件后,会由后台线程将文件同步至同group内其他的storage server。
每个storage写文件后,同时会写一份binlog,binlog里不包含文件数据,只包含文件名等元信息,这份binlog用于后台同步,storage会记录向group内其他storage同步的进度,以便重启后能接上次的进度继续同步;进度以时间戳的方式进行记录,所以最好能保证集群内所有server的时钟保持同步。
storage的同步进度会作为元数据的一部分汇报到tracker上,tracke在选择读storage的时候会以同步进度作为参考。
文件下载
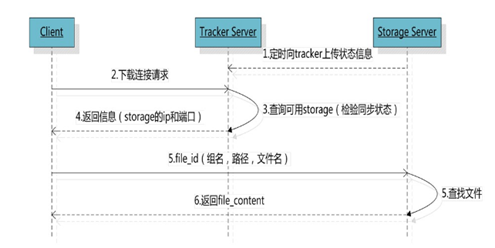
img
安装FastDFS环境
操作环境:CentOS7 X64
我把所有的安装包下载到/softpackages/下,解压到当前目录。
1. 下载安装 libfastcommon
libfastcommon是从 FastDFS 和 FastDHT 中提取出来的公共 C 函数库,基础环境,安装即可 。
① 下载libfastcommon
cd /softpackages wget https://github.com/happyfish100/libfastcommon/archive/V1.0.7.tar.gz
复制
② 解压
tar -zxvf V1.0.7.tar.gz cd libfastcommon-1.0.7
复制
③ 编译、安装
./make.sh ./make.sh install
复制
④ libfastcommon.so 安装到了/usr/lib64/libfastcommon.so,但是FastDFS主程序设置的lib目录是/usr/local/lib,所以需要创建软链接。
ln -s /usr/lib64/libfastcommon.so /usr/local/lib/libfastcommon.so ln -s /usr/lib64/libfastcommon.so /usr/lib/libfastcommon.so ln -s /usr/lib64/libfdfsclient.so /usr/local/lib/libfdfsclient.so ln -s /usr/lib64/libfdfsclient.so /usr/lib/libfdfsclient.so
复制
2. 下载安装FastDFS
① 下载FastDFS
cd /softpackages wget https://github.com/happyfish100/fastdfs/archive/V5.05.tar.gz
复制
② 解压
tar -zxvf V5.05.tar.gz cd fastdfs-5.05
复制
③ 编译、安装
./make.sh ./make.sh install
复制
④ 默认安装方式安装后的相应文件与目录 A、服务脚本:
/etc/init.d/fdfs_storaged /etc/init.d/fdfs_tracker
B、配置文件(这三个是作者给的样例配置文件) :
/etc/fdfs/client.conf.sample /etc/fdfs/storage.conf.sample /etc/fdfs/tracker.conf.sample
C、命令工具在 /usr/bin/ 目录下:
fdfs_appender_test fdfs_appender_test1 fdfs_append_file fdfs_crc32 fdfs_delete_file fdfs_download_file fdfs_file_info fdfs_monitor fdfs_storaged fdfs_test fdfs_test1 fdfs_trackerd fdfs_upload_appender fdfs_upload_file stop.sh restart.sh
⑤ FastDFS 服务脚本设置的 bin 目录是 /usr/local/bin, 但实际命令安装在 /usr/bin/ 下。
建立 /usr/bin 到 /usr/local/bin 的软链接,我是用这种方式。
ln -s /usr/bin/fdfs_trackerd /usr/local/bin ln -s /usr/bin/fdfs_storaged /usr/local/bin ln -s /usr/bin/stop.sh /usr/local/bin ln -s /usr/bin/restart.sh /usr/local/bin
复制
3. 配置FastDFS跟踪器(Tracker)
配置文件详细说明参考:FastDFS 配置文件详解
① 进入 /etc/fdfs,复制 FastDFS 跟踪器样例配置文件 tracker.conf.sample,并重命名为 tracker.conf。
cd /etc/fdfs cp tracker.conf.sample tracker.conf vi tracker.conf
复制
② 编辑tracker.conf ,标红的需要修改下,其它的默认即可。
# 配置文件是否不生效,false 为生效 disabled=false # 提供服务的端口 port=22122 # Tracker 数据和日志目录地址(根目录必须存在,子目录会自动创建) base_path=/data/fastdfs/tracker # HTTP 服务端口 http.server_port=8080
复制
③ 创建tracker基础数据目录,即base_path对应的目录
mkdir -p /data/fastdfs/tracker
复制
④ 防火墙中打开跟踪端口(默认的22122)
vi /etc/sysconfig/iptables
复制
添加如下端口行:
-A INPUT -m state –state NEW -m tcp -p tcp –dport 22122 -j ACCEPT
重启防火墙:
service iptables restart
复制
⑤ 启动Tracker
初次成功启动,会在 /data/fdfsdfs/tracker/ (配置的base_path)下创建 data、logs 两个目录。
# 可以用这种方式启动 /etc/init.d/fdfs_trackerd start # 也可以用这种方式启动,前提是上面创建了软链接,后面都用这种方式 service fdfs_trackerd start
复制
查看 FastDFS Tracker 是否已成功启动 ,22122端口正在被监听,则算是Tracker服务安装成功。
netstat -unltp|grep fdfs
复制
![]()
img
关闭Tracker命令:
service fdfs_trackerd stop
复制
⑥ 设置Tracker开机启动
chkconfig fdfs_trackerd on
复制
或者
vi /etc/rc.d/rc.local
复制
加入配置
/etc/init.d/fdfs_trackerd start
⑦ tracker server 目录及文件结构
Tracker服务启动成功后,会在base_path下创建data、logs两个目录。目录结构如下:
${base_path}
|__data
| |__storage_groups.dat:存储分组信息
| |__storage_servers.dat:存储服务器列表
|__logs
| |__trackerd.log: tracker server 日志文件
复制
4. 配置 FastDFS 存储 (Storage)
① 进入 /etc/fdfs 目录,复制 FastDFS 存储器样例配置文件 storage.conf.sample,并重命名为 storage.conf
cd /etc/fdfs cp storage.conf.sample storage.conf vi storage.conf
复制
② 编辑storage.conf
标红的需要修改,其它的默认即可。
# 配置文件是否不生效,false 为生效 disabled=false # 指定此 storage server 所在 组(卷) group_name=group1 # storage server 服务端口 port=23000 # 心跳间隔时间,单位为秒 (这里是指主动向 tracker server 发送心跳) heart_beat_interval=30 # Storage 数据和日志目录地址(根目录必须存在,子目录会自动生成) base_path=/data/fastdfs/storage # 存放文件时 storage server 支持多个路径。这里配置存放文件的基路径数目,通常只配一个目录。 store_path_count=1 # 逐一配置 store_path_count 个路径,索引号基于 0。 # 如果不配置 store_path0,那它就和 base_path 对应的路径一样。 store_path0=/data/fastdfs/file # FastDFS 存储文件时,采用了两级目录。这里配置存放文件的目录个数。 # 如果本参数只为 N(如: 256),那么 storage server 在初次运行时,会在 store_path 下自动创建 N * N 个存放文件的子目录。 subdir_count_per_path=256 # tracker_server 的列表 ,会主动连接 tracker_server # 有多个 tracker server 时,每个 tracker server 写一行 tracker_server=file.psvmc.cn:22122 # 允许系统同步的时间段 (默认是全天) 。一般用于避免高峰同步产生一些问题而设定。 sync_start_time=00:00 sync_end_time=23:59 # 访问端口 http.server_port=8888
复制
tracker_server不能写127.0.0.1或localhost
③ 创建Storage基础数据目录,对应base_path目录
mkdir -p /data/fastdfs/storage # 这是配置的store_path0路径 mkdir -p /data/fastdfs/file
复制
④ 防火墙中打开存储器端口(默认的 23000)
vi /etc/sysconfig/iptables
复制
添加如下
-A INPUT -m state --state NEW -m tcp -p tcp --dport 23000 -j ACCEPT
复制
重启防火墙:
service iptables restart
复制
![]()
img
⑤ 启动 Storage
启动Storage前确保Tracker是启动的。初次启动成功,会在 /data/fastdfs/storage 目录下创建 data、 logs 两个目录。
# 可以用这种方式启动 /etc/init.d/fdfs_storaged start # 也可以用这种方式,后面都用这种 service fdfs_storaged start
复制
查看 Storage 是否成功启动,23000 端口正在被监听,就算 Storage 启动成功。
netstat -unltp|grep fdfs
复制
img
关闭Storage命令:
service fdfs_storaged stop
复制
查看Storage和Tracker是否在通信:
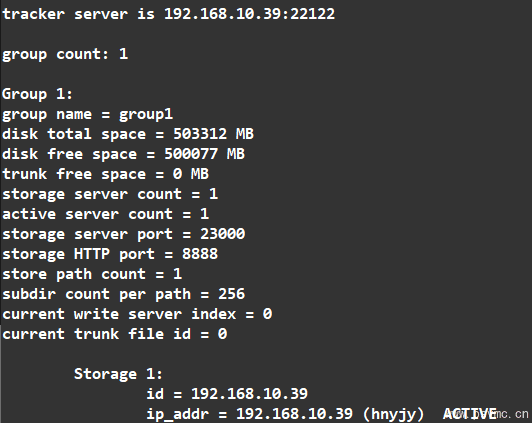
/usr/bin/fdfs_monitor /etc/fdfs/storage.conf
复制
微信截图_20201013170934
⑥ 设置 Storage 开机启动
chkconfig fdfs_storaged on
复制
或者:
vi /etc/rc.d/rc.local
复制
加入配置:
/etc/init.d/fdfs_storaged start
复制
⑦ Storage 目录
同 Tracker,Storage 启动成功后,在base_path 下创建了data、logs目录,记录着 Storage Server 的信息。
在 store_path0 目录下,创建了N*N个子目录:

img
5. 文件上传测试
① 修改 Tracker 服务器中的客户端配置文件
cd /etc/fdfs cp client.conf.sample client.conf vi client.conf
复制
修改如下配置即可,其它默认。
# Client 的数据和日志目录 base_path=/data/fastdfs/client # Tracker端口 tracker_server=file.psvmc.cn:22122
复制
② 上传测试
在linux内部执行如下命令上传 namei.jpeg 图片
/usr/bin/fdfs_upload_file /etc/fdfs/client.conf namei.jpeg
复制
上传成功后返回文件ID号:group1/M00/00/00/wKgz6lnduTeAMdrcAAEoRmXZPp870.jpeg

img
返回的文件ID由group、存储目录、两级子目录、fileid、文件后缀名(由客户端指定,主要用于区分文件类型)拼接而成。

img
安装Nginx
上面将文件上传成功了,但我们无法下载。因此安装Nginx作为服务器以支持Http方式访问文件。同时,后面安装FastDFS的Nginx模块也需要Nginx环境。
Nginx只需要安装到StorageServer所在的服务器即可,用于访问文件。我这里由于是单机,TrackerServer和StorageServer在一台服务器上。
1. 安装Nginx所需环境
① gcc 安装
yum install gcc-c++
复制
② PCRE pcre-devel 安装
yum install -y pcre pcre-devel
复制
③ zlib 安装
yum install -y zlib zlib-devel
复制
④ OpenSSL 安装
yum install -y openssl openssl-devel
复制
2. 安装Nginx
① 下载nginx
cd /softpackages wget -c https://nginx.org/download/nginx-1.12.1.tar.gz
复制
② 解压
tar -zxvf nginx-1.12.1.tar.gz cd nginx-1.12.1
复制
③ 使用默认配置
./configure
复制
④ 编译、安装
make && make install
复制
配置文件路径
vi /usr/local/nginx/conf/nginx.conf
⑤ 启动nginx
cd /usr/local/nginx/sbin/ ./nginx
复制
其它命令
./nginx -s stop ./nginx -s quit ./nginx -s reload
复制
⑥ 设置开机启动
vi /etc/rc.local
复制
添加一行
/usr/local/nginx/sbin/nginx
复制
设置执行权限
chmod 755 /etc/rc.local
复制
⑦ 查看nginx的版本及模块
/usr/local/nginx/sbin/nginx -V
复制
⑧ 防火墙中打开Nginx端口(默认的 80)
添加后就能在本机使用80端口访问了。
vi /etc/sysconfig/iptables
复制
添加如下端口行:
-A INPUT -m state --state NEW -m tcp -p tcp --dport 80 -j ACCEPT
复制
重启防火墙
service iptables restart
复制
3. 访问文件
简单的测试Nginx是否安装成功,下述操作可以跳过,直接配置Nginx的FastDFS模块
① 修改nginx.conf
vi /usr/local/nginx/conf/nginx.conf
复制
添加如下行,将 /group1/M00 映射到 /data/fastdfs/file/data
location /group1/M00 {
alias /data/fastdfs/file/data;
}
复制
重启nginx
/usr/local/nginx/sbin/nginx -s reload
复制
② 在浏览器访问之前上传的图片、成功。
http://file.psvmc.cn/group1/M00/00/00/wKgz6lnduTeAMdrcAAEoRmXZPp870.jpeg
4. 安装配置Nginx模块
① fastdfs-nginx-module 模块说明
FastDFS 通过 Tracker 服务器,将文件放在 Storage 服务器存储, 但是同组存储服务器之间需要进行文件复制, 有同步延迟的问题。
假设 Tracker 服务器将文件上传到了 192.168.51.128,上传成功后文件 ID已经返回给客户端。
此时 FastDFS 存储集群机制会将这个文件同步到同组存储 192.168.51.129,在文件还没有复制完成的情况下,客户端如果用这个文件 ID 在 192.168.51.129 上取文件,就会出现文件无法访问的错误。
而 fastdfs-nginx-module 可以重定向文件链接到源服务器取文件,避免客户端由于复制延迟导致的文件无法访问错误。
② 下载 fastdfs-nginx-module、解压
cd /softpackages # 这里为啥这么长一串呢,因为最新版的master与当前nginx有些版本问题。 wget https://github.com/happyfish100/fastdfs-nginx-module/archive/5e5f3566bbfa57418b5506aaefbe107a42c9fcb1.zip # 解压 unzip 5e5f3566bbfa57418b5506aaefbe107a42c9fcb1.zip # 重命名 mv fastdfs-nginx-module-5e5f3566bbfa57418b5506aaefbe107a42c9fcb1 fastdfs-nginx-module-master
复制
③ 配置Nginx
在nginx中添加模块
# 先停掉nginx服务 /usr/local/nginx/sbin/nginx -s stop # 进入解压包目录 cd /softpackages/nginx-1.12.1/ # 添加模块 ./configure --add-module=../fastdfs-nginx-module-master/src # 重新编译、安装 make && make install
复制
④ 查看Nginx的模块
/usr/local/nginx/sbin/nginx -V
复制
有下面这个就说明添加模块成功

img
⑤ 复制 fastdfs-nginx-module 源码中的配置文件到/etc/fdfs 目录, 并修改
cd /softpackages/fastdfs-nginx-module-master/src cp mod_fastdfs.conf /etc/fdfs/
复制
修改如下配置,其它默认
# 连接超时时间 connect_timeout=10 # Tracker Server tracker_server=file.psvmc.cn:22122 # StorageServer 默认端口 storage_server_port=23000 # 如果文件ID的uri中包含/group**,则要设置为true url_have_group_name = true # Storage 配置的store_path0路径,必须和storage.conf中的一致 store_path0=/data/fastdfs/file
复制
⑥ 复制 FastDFS 的部分配置文件到/etc/fdfs 目录
cd /softpackages/fastdfs-5.05/conf/ cp anti-steal.jpg http.conf mime.types /etc/fdfs/
复制
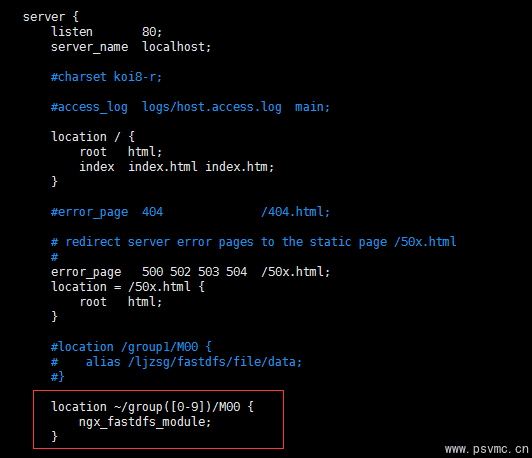
⑦ 配置nginx,修改nginx.conf
vi /usr/local/nginx/conf/nginx.conf
复制
修改配置,其它的默认
在80端口下添加fastdfs-nginx模块
location ~/group([0-9])/M00 {
ngx_fastdfs_module;
}
复制
img
注意:
listen 80 端口值是要与 /etc/fdfs/storage.conf 中的 http.server_port=80 (前面改成80了)相对应。如果改成其它端口,则需要统一,同时在防火墙中打开该端口。
location 的配置,如果有多个group则配置location ~/group([0-9])/M00 ,没有则不用配group。
⑧ 在/data/fastdfs/file 文件存储目录下创建软连接,将其链接到实际存放数据的目录,这一步可以省略。
ln -s /data/fastdfs/file/data/ /data/fastdfs/file/data/M00
复制
⑨ 启动nginx
/usr/local/nginx/sbin/nginx
复制
打印处如下就算配置成功
![]()
img
⑩ 在地址栏访问。
能下载文件就算安装成功。注意和第三点中直接使用nginx路由访问不同的是,这里配置 fastdfs-nginx-module 模块,可以重定向文件链接到源服务器取文件。
http://file.psvmc.cn/group1/M00/00/00/wKgz6lnduTeAMdrcAAEoRmXZPp870.jpeg
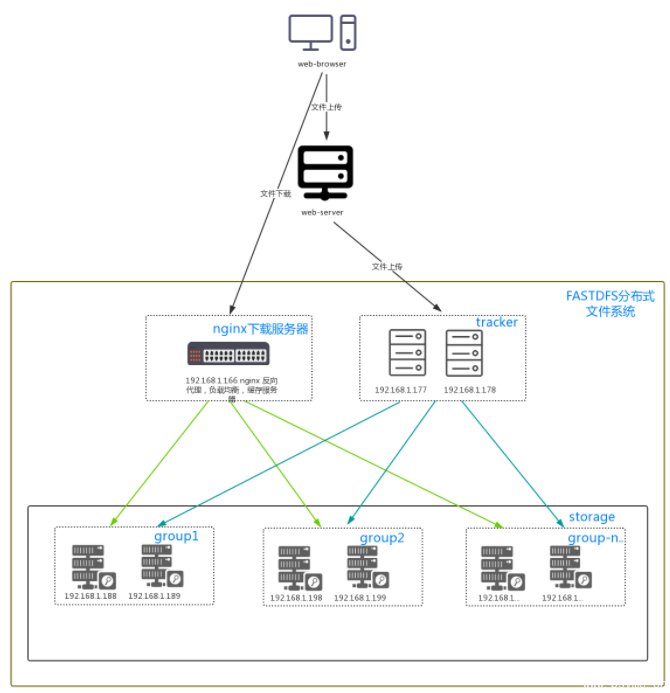
最终部署结构图:可以按照下面的结构搭建环境。
img
Java客户端
前面文件系统平台搭建好了,现在就要写客户端代码在系统中实现上传下载,这里只是简单的测试代码。
1. 搭建Java开发环境
① 项目中使用maven进行依赖管理,可以在pom.xml中引入如下依赖即可:
<dependency> <groupId>net.oschina.zcx7878</groupId> <artifactId>fastdfs-client-java</artifactId> <version>1.27.0.0</version> </dependency>
复制
其它的方式,参考官方文档:https://github.com/happyfish100/fastdfs-client-java
② 引入配置文件
可直接复制包下的 fastdfs-client.properties.sample 或者 fdfs_client.conf.sample,到你的项目中,去掉.sample。
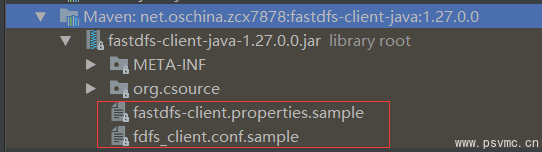
img
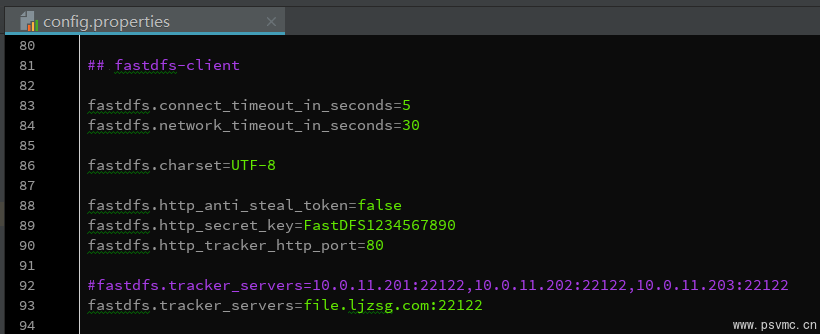
我这里直接复制 fastdfs-client.properties.sample 中的配置到项目配置文件 config.properties 中,修改tracker_servers。只需要加载这个配置文件即可
img
2. 客户端API
个人封装的FastDFS Java API以同步到github:https://github.com/bojiangzhou/lyyzoo-fastdfs-java.git
权限控制
前面使用nginx支持http方式访问文件,但所有人都能直接访问这个文件服务器了,所以做一下权限控制。
FastDFS的权限控制是在服务端开启token验证,客户端根据文件名、当前unix时间戳、秘钥获取token,在地址中带上token参数即可通过http方式访问文件。
① 服务端开启token验证
修改http.conf
vi /etc/fdfs/http.conf
复制
按如下配置
# 设置为true表示开启token验证 http.anti_steal.check_token=true # 设置token失效的时间单位为秒(s) http.anti_steal.token_ttl=1800 # 密钥,跟客户端配置文件的fastdfs.http_secret_key保持一致 http.anti_steal.secret_key=FASTDFS1234567890 # 如果token检查失败,返回的页面 http.anti_steal.token_check_fail=/data/fastdfs/page/403.html
复制
记得重启服务。
② 配置客户端
客户端只需要设置如下两个参数即可,两边的密钥保持一致。
# token 防盗链功能 fastdfs.http_anti_steal_token=true # 密钥 fastdfs.http_secret_key=FASTDFS1234567890
复制
③ 客户端生成token
访问文件需要带上生成的token以及unix时间戳,所以返回的token是token和时间戳的拼接。
之后,将token拼接在地址后即可访问:file.psvmc.cn/group1/M00/00/00/wKgzgFnkaXqAIfXyAAEoRmXZPp878.jpeg?token=078d370098b03e9020b82c829c205e1f&ts=1508141521
/**
* 获取访问服务器的token,拼接到地址后面
*
* @param filepath 文件路径 group1/M00/00/00/wKgzgFnkTPyAIAUGAAEoRmXZPp876.jpeg
* @param httpSecretKey 密钥
* @return 返回token,如: token=078d370098b03e9020b82c829c205e1f&ts=1508141521
*/
public static String getToken(String filepath, String httpSecretKey){
// unix seconds
int ts = (int) Instant.now().getEpochSecond();
// token
String token = "null";
try {
token = ProtoCommon.getToken(getFilename(filepath), ts, httpSecretKey);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
} catch (MyException e) {
e.printStackTrace();
}
StringBuilder sb = new StringBuilder();
sb.append("token=").append(token);
sb.append("&ts=").append(ts);
return sb.toString();
}
复制
④ 注意事项
如果生成的token验证无法通过,请进行如下两项检查: A. 确认调用token生成函数(ProtoCommon.getToken),传递的文件ID中没有包含group name。传递的文件ID格式形如:M00/00/00/wKgzgFnkTPyAIAUGAAEoRmXZPp876.jpeg
B. 确认服务器时间基本是一致的,注意服务器时间不能相差太多,不要相差到分钟级别。
⑤ 对比下发现,如果系统文件隐私性较高,可以直接通过fastdfs-client提供的API去访问即可,不用再配置Nginx走http访问。配置Nginx的主要目的是为了快速访问服务器的文件(如图片),如果还要加权限验证,则需要客户端生成token,其实已经没有多大意义。
附2: 分布式文件系统(Distributed File System,DFS)(分布式文件系统(Distributed File System,DFS)_什么是分布式文件系统-CSDN博客)
分布式文件系统(Distributed File System,DFS)
一、什么是分布式文件系统
1、文件系统的定义: 硬盘是计算机最主要的存储设备,数据按扇区存放在硬盘上。硬盘属于硬件,用户无法直接对其进行操作,由操作系统帮我们管理。文件系统是操作系统用于明确存储设备或分区上的文件的方法和数据结构;即在存储设备上组织文件的方法。操作系统中负责管理和存储文件信息的软件机构称为文件管理系统,简称文件系统。文件系统由三部分组成:文件系统的接口,对对象操纵和管理的软件集合,对象及属性。从系统角度来看,文件系统是对文件存储设备的空间进行组织和分配,负责文件存储并对存入的文件进行保护和检索的系统。通俗地说,文件系统就是一个软件,它负责为用户建立文件,存入、读出、修改、转储文件,控制文件的存取,当用户不再使用时撤销文件等。
2、一般文件系统: 在我们日常生活工作中,自己使用的电脑上都会安装操作系统,比如Windows。我们经常进行的操作如新建文件夹、新建文件、删除文件等等,都是文件系统在帮助我们工作,Windows文件系统有FATFS、VFATFS、NTFS等。除了Windows外,Linux也有ext、vfs等等文件系统,像这种一台计算机,单个存储节点、一个操作系统,一个具体的文件系统的场景称之为一般文件系统。
3、分布式文件系统: 分布式文件系统中的数据存储在多台机器上,这些专门用来存储数据的机器称之为存储节点,由多个节点构成分布式集群,节点上的小的分布式文件系统组合成总的分布式文件系统,由主服务器对总的文件系统进行管理。用户任意访问某一台主机,都能获取到自己想要的目标文件。
4、一般文件系统与分布式文件系统的比较: 一般文件系统 分布式文件系统 存储方式 集中存储在一台机器 分散地存储在多台机器 访问方式 系统总线IO 网络IO 特点 系统级别的文件系统,数据集中存放在一台机器,对数据的访问,修改和删除比较方便快速,存储服务器成为系统性能的瓶颈,伸缩性较差,扩展有限 应用级别的文件系统,分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展 适用场景 小数据量的存储 海量数据的存储 设计目标 高性能、可用性 高性能、可伸缩性、可靠性以及可用性
二、常见的分布式文件系统
常见的分布式文件系统有,GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS等。各自适用于不同的领域。它们都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务。
1、GFS(Google File System) Google GFS文件系统,一个面向大规模数据密集型应用的、可伸缩的分布式文件系统。GFS虽然运行在廉价的普遍硬件设备上,但是它依然了提供灾难冗余的能力,为大量客户机提供了高性能的服务。GFS是一个为Google内部设计的大数据分布式存储框架,由2003年Google发表的论文提出,遗憾的是Google并没有将其开源,但是基于GFS的设计理念,诞生了很多优秀的开源类GFS文件系统。
2、HDFS(Hadoop Distributed File System) HDFS是Hadoop(Apache开源项目)的专用文件系统, Hadoop是一个大数据计算框架,它允许使用简单的编程模型跨计算机集群分布式处理大型数据集,是Google发表的MapReduce算法的实现,HDFS是GFS的开源实现。
3、Ceph Ceph是加州大学Santa Cruz分校的Sage Weil(DreamHost的联合创始人)专为博士论文设计的新一代自由软件分布式文件系统,并使用Ceph完成了他的论文。Ceph的主要目标是设计成基于POSIX的没有单点故障的分布式文件系统,使数据能容错和无缝的复制。与其它分布式文件系统相比,ceph 性能最高,因为其使用C++编写而成。 由于 ceph 使用 btrfs 文件系统, 而btrfs 文件系统需要 Linux 2.6.34 以上的内核才支持。自2007年毕业之后,Sage开始全职投入到Ceph开 发之中,使其能适用于生产环境,经过十几年的发展,Ceph已经趋向于成熟。
4、Lustre Lustre是一个开源、分布式并行文件系统软件平台,具有高可扩展、高性能、高可用等特点。Lustre的构造目标是为大规模计算系统提供一个全局一致的POSIX兼容的命名空间,这些计算系统包括了世界上包含最强大的高性能计算系统。它支持数百PB数据存储空间,支持数百GB/s乃至数TB/s并发聚合带宽。
5、GridFS GridFS 是MongDB的分布式存储系统,用于存储和恢复那些超过16M(BSON文件限制)的文件(如:图片、音频、视频等)。GridFS 也是文件存储的一种方式,但是它是存储在MonoDB的集合中。GridFS 可以更好的存储大于16M的文件。GridFS 会将大文件对象分割成多个小的chunk(文件片段),一般为256k/个,每个chunk将作为MongoDB的一个文档(document)被存储在chunks集合中。GridFS 用两个集合来存储一个文件:fs.files与fs.chunks。每个文件的实际内容被存在chunks(二进制数据)中,和文件有关的meta数据(filename,content_type,还有用户自定义的属性)将会被存在files集合中。
6、MogileFS MogileFS是一个开源的分布式文件存储系统,是由LiveJournal旗下的Danga Interactive公司开发。目前使用MogileFS的公司非常多,如日本排名先前的几个互联公司以及国内的Yupoo(又拍)、digg、豆瓣、大众点评、搜狗等,分别为所在的组织或公司管理着海量的图片。以大众点评为例,用户全部图片均有MogileFS存储,数据量已经达到500TB以上
7、FastDFS(Fast Distributed File System) FastDFS是一个开源的分布式文件系统,由纯C编写,性能很高。她对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
8、TFS(Taobao File System) TFS是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化了文件的访问流程,一定程度上为TFS提供了良好的读写性能。
三、下一代分布式文件系统 1、预想 随着5G、AI、云技术的快速普及和发展,数据的产生呈几何级数增长,必然会带来更大的挑战,势必会催生出下一代分布式文件系统。会在解决最基本的数据存储问题后,我认为分布式文件系统需要解决的问题是如何针对当前系统架构缺点的改进,主要围绕在数据的多元化存储、更灵活的适用场景、系统的性价比提升、更强的适用性和更方便的运维等方面。其实,对大数据的操作有90%是对元数据进行操作,HDFS的元数据存储在内存,虽然性能高,但是内存的容量有限,系统支持的文件数量较少。Ceph将元数据保存在RADOS,IO操作多,路径长,性能不理想。
数据存储在内存,虽然性能高,但是内存的容量有限,系统支持的文件数量较少。Ceph将元数据保存在RADOS,IO操作多,路径长,性能不理想。
人类的智慧是无限的,相信随着时间的发展,在不断地实践和改进后,“数据革命”必然会取得胜利,分布式文件系统也必然会绽放更加绚丽的花!! ———————————————— 版权声明:本文为CSDN博主「爱吃土豆的松鼠」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:分布式文件系统(Distributed File System,DFS)_什么是分布式文件系统-CSDN博客


{kind=link}