
- 1YOLOv8部署,从图像到打标签,再到标签转换,最后机器学习。_yolov8打标签程序
- 2MySQL创建表和约束条件(四)_创建数据表hzb,里面包含以下字段:bh整数字符(此项数据不能为空)并设置为主键约束,
- 3腾讯云GPU云服务器CPU是什么?主频多少?_intel xeon cooper lake 处理器,基频 3.4 ghz,睿频3.8 ghz
- 4动态规划(DP)之入门学习-数字三角形_c语言动态规划数字三角形问题dp最简单的写法
- 5利用数据可视化技术来学习钻石鉴别_diamonds.csv 百度网盘
- 6Django及Flask漏洞合集_django漏洞集合
- 7深入了解Python自然语言处理库NLTK
- 8Android音乐播放器显示startForeground(ONGOING_NOTIFICATION_ID, notification);异常解决方法_android startforeground notification
- 9基于Matlab的Q-learning算法机器人路径规划仿真_matlab qlearn
- 10Win10安装RabbitMQ_rabbitmq的注册表在哪里
卷积神经网络内容概括_卷积神经网络w h是什么
赞
踩
卷积神经网络内容概括
卷积神经网发展历程和基本概念
内容概括

什么是卷积神经网络
以卷积结构为主,搭建起来的深度网络。
将图片作为网络的输入(n(批次),w(宽度),h(长度),c(图的通道数量)),自动提取特征,并且对图像的变形等具有高度不变形。
重要的组成单元

卷积运算的定义
卷积的基本定义
对图像和滤波矩阵(卷积核)做内积(逐个元素相乘在求和)的操作
滤波器:可以理解为卷积,可以通过滤波器来对图像进行降噪等。
例如:均值滤波器[1/3,1/3,1/3]进行内积相乘相加后等于相对应的求均值运算。
另外,每一种卷积对应一种特征
im2col实现卷积运算:可以自己去了解。
卷积的重要参数

卷积核(线性运算)
最常用的为2d卷积核(wh)(当然也有1D以及3D)
权重和偏置项:权值为wx,偏置项:b;
常用的卷积核:11,33,5*5(一般为奇数,这样的卷积具有一个中心点,从而再卷积之后能保护位置信息,同时能在padding时保持对称性)
权值共享和局部连接(局部感受野/局部感知)
卷积运算作用在局部,即为一个感受野
Feature map使用同一个卷积核运算后得到一种特征
多种特征采用多个卷积核。
因此可以得出在一个Feature map种的卷积核的参数时相同的,这就是所谓的全职共享。而输入层和输出层也因此时局部连接的。而全连接即输出层的一个特征点与输入层的所有点都有一定的关系。
从左到右即为全连接到一个卷积核的权值共享的演变,可以发现通过不断地进化,参数量在不断地缩小,从而降低了过拟合的风险。越多的参数两=量也就意味着我们需要更多的样本去训练模型。
卷积核与感受野
卷积核越大等同于感受野越大,也就意味着能获得更多的信息,但也因此,随着卷积核的扩大,也会使参数的大量增加,从而导致过拟合。
例如33需要9个参数,而55则需要25个,到了77甚至到了49个数值。
但如果选择卷积核缩小的方法,又会导致信息的缺少,因此为了解决这个问题,可以采用卷几个堆积的方法,使用小的卷积核来完成大的卷积核,如:
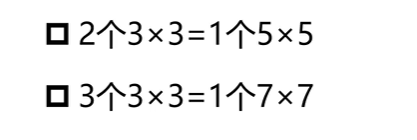

在上图中,对一个55的图像进行卷积运算,如果使用55的卷积进行运算,则只需要一个卷积,则可以得到一个11的feature。然而,如果使用33的卷积核来操作的话,则需要使用两个卷积进行操作从而达到相同的结果。这就是所谓的卷积核堆积,也就是上图中的结论。
计算方法:对于nn的输入图,33的卷积得到的是(n-2)(n-2)的输出图,55的卷积得到的是(n-4)(n-4)的结果,77得到的是(n-6)(n-6)的结果。
通过小卷积的堆积而去代替搭卷积,明显的好处是降低了计算量和参数量,同时又使网络深度加深,从而也可以增加层与层之间的关系。
如何计算卷积参数量
参数量越大,模型越大,对平台的要求越大,占用的存储空间。因此,在保证性能的前提下,我们应该尽量减少参数。也就是w和b

如何计算卷积的计算量
决定平台的功耗以及算法的算力。
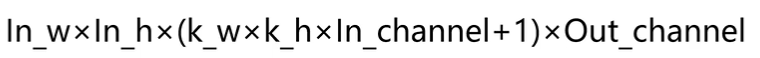
步长
卷积是从上到下,从左到右的滑动,而通过设置步长可以决定滑动的距离。
通过设置设置步长能完成下采样的过程(大于1)。当然也会造成信息的损失(改变了计算量,但是没有改变参数量)
Feature map的大小计算方法:

Pad(填充)
确保Feature map的整数倍变化,对尺度相关的任务尤为重要,取决于步长

不改变参数量,改变计算量。
卷积的定义和使用
caffe

tensorflow

池化层(无参数)
对输入的特征图进行压缩,是特征图变小,简化网络计算复杂度。
进行特征压缩,提取主要特征
增大感受野

激活函数
主要是增加网络的非线性,进而提高网络的表达能力。(卷积是线性的)很多实际任务是非线性的,所以加入激活函数是必要的。

Sigmoid

Tanh

ReLu(最常用的)

BatchNorm层的基本概念
通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正太分布

规范化原因:对于原始的输入数据,每一个层的输入分布不可控,使每一层的数据分布不停变化。
优点:
减少了参数的认为选择,可以取消Dropout和L2正则项参数,或者采取更小的L2正则项约束参数;
减少了对学习率的要求
可以不再使用局部响应归一化,BN本身就是归一化网络(局部响应归一化)
破坏原来的数据分布,一定程度上缓解过拟合
在Caffe中的使用

在Tensorflow中的使用

全连接层
连接所有的特征,将输出层送给分类器(如softmax分类器)
将网络的输出变成一个向量
可以采用卷积代替全连接层:采用一定的卷积可以获得与全连接层一样的结果。
全连接层是尺度敏感的:如果输入数据的大小发生变化,则FC层就会发生参数的变化。
因为全连接带来了大量的参数,所以需要配合使用dropout层
Dropout层
在训练过程中,随机的丢弃一部分输入(变为0),此时丢弃部分对应的参数不会更新。同一层在每次训练时,会随机抛弃一定的元素。
优点:
解决过拟合问题:
取平均的作用
减少神经元之间复杂的共适应关系。

损失层
损失函数:
用来评估模型的预测值和真实值的不一致程度。用来知道模型的学习。利用损失进行反向传播算法。
经验风险最小:
不一致程度,衡量了当前模型的对数据的拟合程度。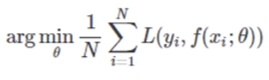
结构风险最小:
对已经拟合好的模型进一步进行约束,如果不进行约束,在模型训练时可能会得到多组解满足经验风险最小,因此,通过结构风险最小来对当前的解空间找到最优解。它定义了模型的复杂程度越低,结构风险越小,意味着模型越简单,越不容易过拟合。(范数约束,也就是正则项(惩罚项))
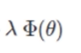
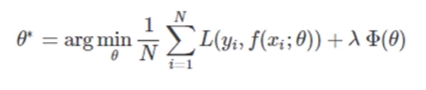
一般形式:
参数:

模型: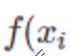
样本标签:
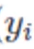
损失函数:
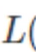
常见的损失函数
经验风险最小:交叉熵损失、softmax loss等
结构风险最小:L0(参数中,为0的个数,稀疏特性),L1(当前参数的绝对值和,稀疏特性),L2(参数的平方和)正则等
损失层
损失层定义了使用的损失函数,通过最小化损失来驱动网络的训练。(反向传播算法)
网络的损失是通过前向操作计算
网络参数相对于损失函数的梯度则铜鼓哦反向操作计算。
分类任务损失:交叉熵损失
回归任务损失:L1损失、L2损失
交叉熵损失
log-likelihood cost
似然:在已知结果的情况下,反推该原因,也就是学习参数。
非负性
当真实输出a与期望输出y接近的时候,代价函数接近于0.
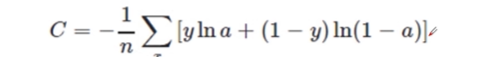
熵
对信息进行量化,定义了事件的不确定程度。不确定性越大,熵越大。
交叉熵损失实现

这两个主要的区别为label
第一个需要出入的值为one-hot编码(有兴趣的可以取查阅),而第二个则不需要。
L1、L2和Smooth L1损失
Smooth L1是L1的变形,用于Faster RCNN、SSD等网络计算损失

两者的区别
L1零点不可导且斜率不变(容易使网络震荡而跳过了最优解,同时在还没达到最优解时,其Loss下降更快),L2则可导且可变(在接近最优解时,损失的变化越来越小,符合现实,更容易找到最优解,避免跳过最优解)。
因此,结合两者优点,提出了Smooth L1。其兼顾了网络收敛速度和网络学习的稳定性。
卷积神经网络发展历程
常见的卷积神经网络

在学术界追求更复杂的网络,追求更高的精准度,而在工业界,则是追求运行速度。
LeNet
麻雀虽小五脏俱全,是由LeCun在1998年提出,用于解决手写数字识别,MNIST

AlexNet
2012年,Hinton的学生Alex Krizhevsky在寝室用GPU死磕出一个DeepLearning模型,一句摘下视觉领域竞赛ILSVRC 2012的桂冠。

当时是通过两个显卡分别训练(目前一个就行)
网络结构:con - relu - pooling - LRN(归一化)
fc - relu - dropout
fc - softmax(进行映射)
参数量60M以上,模型大小>200M
特点:
ReLu非线性激活函数:更快
Dropout层防止过拟合:去掉fc层中的部分参数,主要搭配
数据增强,减少过拟合
标准化层(Local Response Normalization):放大主要单元
意义:

ZFNet
在AlexNet基础上进行细节调整,并且取得2013年ILSVRC的冠军
从可视化的角度出发,解释CNN有非常好的性能的原因。

主要优化为,调整第一层卷积核大小为7*7,
设置卷积参数stride = 2,从而获得更多的信息。
ZFNet与特征可视化

结果:
特征分层次体系结构,每层的特征不同
深层特征更鲁棒,浅层次会受到大的影响,深层次的特征不敏感
深层次更有区分度
深层次特征收敛更慢
同时,随着网络层次更深,也就使模型更加的难以训练
特征:
低层次特征:颜色,纹理
中层次特征:降维,优化学习后
高层次特征:进行抽象之后的到的词组语义特征
VGGNet
由牛津大学计算机视觉和Google Deepmind 共同设计
为了研究网络深度对模型准确度的影响,并采用小卷积堆叠的方式来搭建整个网络结构
参数量:138M
模型大小>500M

特点:
更深的网络结构,结构更加规整、简单;
全部使用44的小型卷积核和22的最大池化层;
每次池化后Feature Map宽高降低一半,通道数量增加一倍;
网络层数更多、结构更深,模型参数量更大。
意义
证明了更深的网络,能够提取更好的特征
成为后续很多网络的backbone
规范化了后续网络设计的思路
GoogLeNet/Inception v1
在设计网络结构时,不仅强调网络的深度,也会考虑网络的宽度,并将这种结构定义为Inception结构(一种网中网的结构,即原来的节点也是一个网络)
14年的比赛冠军的model,这个model证明了一件事:用更多的卷积(宽度,同一层的channel),更深的层次(深度)可以得到更好的结构。(当然,它并没有证明浅的层次不能达到这样的效果)
参数量:6.78M
模型大小:50M


特点:
更深的网络结构
两个LOSS层,降低过拟合风险
考虑网络宽度
巧妙地利用1*1地卷积核来进行通道降维,减小计算量(重点)
Inception v2/v3

巧妙利用感受野,改变卷积大小,降低参数量以及计算量,同时也加深网络层次。
从卷积的角度思考,如何减小网络中的计算量
1.小卷积来对大卷积进行拆分;
2.stride = 2代替pooling层,减小当前的计算量
3.巧妙地利用1*1的卷积来进行特征的降维
ResNet
在2015年,由何凯明团队提出,引入跳连的结构防止梯度小时的问题,进而可以进一步加大网络深度。

跳连结构:将输入层的特征直接传递到输出层,并且与卷积之后的特征进行连接。虽然增加了结构关系,但是没有改变参数量
ResNet的Bottleneck与恒等映射
Bottleneck(包含1*1):跳级结构(Short-Cut)恒等映射(输出等于输入),解决梯度消失问题;

Tensorflow 运用

ResNet中的BatchNorm
每个卷积之后都会配合一个BatchNorm层
对数据scale和 分布进行约束
简单的正则化,提高网络抗拟合能力
设计特点
核心单元简单堆叠
跳连结构解决网络梯度消失问题
Average Pooling 层代替FC层(减少参数量)
BN层加快网络训练速度和收敛时的稳定性
加大网络深度,提高模型特征抽取能力
变种网络

分组卷积:将区域分成多分,使用不同的卷积进行运算。
更多的跳连:引入更多的跳连,增加了密度
Cccacbcbbabacbbaccbccaacbaacbc
卷积神经网络结构对比

轻量型卷积神经网络
1.更少的参数量:减少模型大小,减少占用内存
2.更少的计算量:增强了推理速度
3.移动端,嵌入式平台(减少功耗)
代表性结构
SqueezeNet
ICLR-2017,作者分别来自Berkeley和Stanford
提出Fire Module,由两部分组成:Squeeze层和Expand层
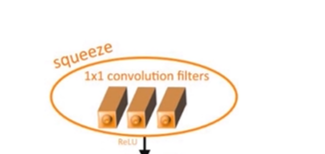
节省计算量
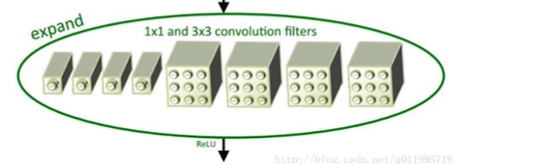
特点
1*1卷积减少计算量
不同size的卷积,类似inception
deep compression技术

MobileNet
由Google团队提出,并发表于CVPR-2017

进行分组,每一组学习一个卷积核,最后进行concat.

如上,将标准的卷积进行分组分成两个组:
Depth-wise Convolution:
分成channel个组,每一组包括一个feature map,学习一个卷积核。
Point-wise Convolution(11卷积):
一个feature map对应一个组,但是channel之间的关系无法实现。通过该方法,对channel之间的信息进行学习,使用11的卷积。
节省的计算量:

MobileNet-v1实验对比

MobileNet v2

红色PW增加channel数量。

ShuffleNet v1
由旷视科技提出的一种轻量型卷积网络
深度卷积来代替标准卷积
分组卷积+通道shuffle

shuffle将通道打乱,并不是随机打乱,将特定的组合理分配到特定的组,如下图
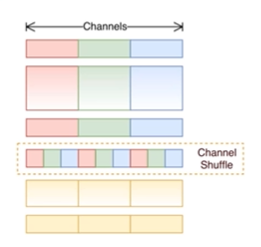
实验效果

ShuffleNet v2
对ShuffleNet v1的优化
ECCV 2018
解释了如何其设计轻量型卷积网络的几个标准和规范
设计标准
相同的通道宽度可最小化访问成本(MAC)
过度的组卷积会增加MAC
网络碎片化(例如GoogLeNet的多路径结构)会降低并行度
元素级运算不可忽视


Xception
由Google提出,arXiv的V1版本于2016年10月公布。
同样借鉴深度卷积的思想,但是又存在查一,具体如下:
Xception先采用11卷积,再进行主通道卷积;
Xception在11卷积后,加入Relu;

多分支卷积神经网络
从结构上的创新
Siamese Net:两支
Triplet Net:三支
Quadruplet Net:四支
多任务网络:多支
Siamese Net(孪生网络)

主要解决度量问题,比如图像检索,人脸识别。输入两个分支,输出为两个图像的关系(常见的为度量相似度),对每一个图像进行特征提取,最后求解特征向量的距离(常用的为欧式是距离)。
度量问题
常规的问题:
分类问题
回归问题
度量问题:除去以上两个问题,即为度量问题。
余弦距离
欧式距离的范围是从0到正无穷的,而余弦距离是从0到1的(符合概率)
余弦距离,也称余弦相似度,是用向量空间中两个向量夹角的于现址作为衡量两个个体间差异的大小的度量。(人脸识别中常用)
余弦距离-扩展loss

Triple Net

输入三个分支Anchor,Negative,Positive.
其中,Anchor与Positive为同类,Anchor与Negative为 不同类,而该网络特点是将同类距离缩小,不同类距离放大。
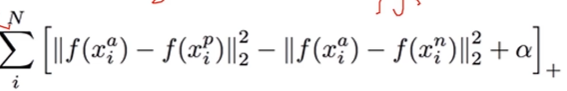
网络结构

特点
提取Embedding Feature
细粒度的识别任务(同类判定)
正负样本比例失衡-难例挖掘(人脸解锁)
Quadruplet Net
相比Triplet Net多加入一张负样本
正度样本之间的绝对距离

多任务网络

两种:
1.多分支->多输出 (参数共享):不同的分支进行不同的任务,常见的为行人人脸识别。
2.单分支->多输出:根据不同的任务拉出不同的输出,常见的为目标检测。
卷积神经网络的Attention机制
人类大脑在接受和处理外界型号时的一种机制

上图中的热力图便是最先Attention的地方。
类似的salience(感兴趣区域).
最后的输出为one-hot或者soft的软分布
实现机制
保留所有分量均做权(soft attention)
在分布中以某种采样策略选区部分分量(hard attention)
如对原图、特征图、空间尺度、通道、特征图上的每个元素、不同历史时刻进行加权。
实现方法


神经网络的压缩方法
学院派(提高精度)VS工程派(提高速度)
方法
模型剪枝
除无意义的权重和激活来减少模型的大小
1.贡献度排序
2.去除小贡献度单元
3.重新fine-tuning

技巧
全连接部分通常会存在大量的参数冗余
对卷积窗口进行剪枝的方式,可以是减少卷积窗口权重,或者直接丢弃卷积窗口的某一维度;
丢弃系数的卷积窗口,但这并不会使模型运行速度有数量级的提升;
首先训练一个较大的神经网络模型,再逐步剪枝得到的小模型
模型量化/定点化
减少数据再内存中的位数操作,可以采用8位类型来表示32位浮点(定点化)或者直接训练低于8位的模型,比如:2bit模型,4bit模型等
特点:
减少内存开销,节省更多的带宽
对于某些定点运算方式,甚至可以消除乘法操作,只剩加法操作,
某些二值模型,直接使用位操作
代价通常使位数越低,精度下降越明显。
方法
再tensorflow中,通常是采用引入量化层的方式来更改计算图,进而达到量化的目的。

知识蒸馏
采用一个大的、复杂的网络模型来指导一个小的、精简的网络模型进行模型训练和学习(教室网络)


