
- 110.基于STM32C8T6的四旋翼无人机的飞控制作----实践操作5,AD电路板绘制-PCB绘制_基于stm32的无人机pcb设计
- 2解决 jenkins 插件下载失败问题 - 配置 jenkins 插件中心为国内镜像地址_jenkins update site mirror
- 3Mybatis中多对一_mysql多对一 多个学生对应一个老师
- 4Openpcdet 系列 Pointpillar代码逐行解析之检测头(DENSE_HEAD)模块_pointpillar 检测头 18
- 5硬件测试工程师的待遇和前景
- 6数据结构-链表(一)_建立结点的数据结构以及包含若干结点的链表
- 7android 高度模块化,web3j: web3j 是一个轻量级、高度模块化、响应式、类型安全的 Java 和 Android 库,用于与智能合约以及与以太坊网络上的客户端(节点)进行集成: 可以通...
- 8Python爬虫中如何通过post发请求,浏览器控制台抓包教程,有道翻译爬虫程序,通过python伪装翻译(post案例)_爬虫post
- 9echarts柱状图修改背景线为网格线、去掉刻度标签、鼠标悬停在柱条上时变色、柱条圆角弧度
- 10hadoop概述_hadoop是什么开发的
SD好复杂,是不是很糊,一文搞懂Stable Diffusion的各种模型及用户操作界面
赞
踩
这篇文章中对 Stable Diffusion 的各个功能做了详细介绍,今天主要是以一秒内就能生成图片的爆炸性模型 SDXL Turbo的发布为契机,对SD 的各类基础模型:SD 1.x、SD 2.x、SD 1.5、SDXL 1.0和SDXL Turbo,及操作界面:WebUI、ComfyUI和Fooocus进行详细介绍,一文搞懂他们之间的关系,选择不迷路。

一、SD 基础模型介绍
1、SD 1.x:这是Stable Diffusion的早期版本,主要用于图像生成任务。这里的1.x表示1系列的主要版本,x是一个变量,表示具体的子版本。
2、SD 2.x:这是SD 1.x的后续版本,对模型进行了优化和改进,提高了图像生成质量和速度。同样,2.x表示2系列的主要版本,x是一个变量,表示具体的子版本。
3、SD 1.5:这是一个在SD 1.x基础上进行优化的版本,它在文本到图像生成任务上表现尤为出色,能够生成更符合用户需求的图像。
4、SDXL 1.0:这是一个在SD 1.5基础上进一步优化的版本,采用了一种名为“对抗性扩散蒸馏”(Adversarial Diffusion Distillation,简称ADD)的新技术,使得模型能够在保持高采样保真度的同时实现实时图像生成。
5、SDXL Turbo:它是在SDXL 1.0的基础上进行迭代的版本。特点是生成图像的效率非常高,几乎可以做到实时响应。在用户输入完文本提示后,图像就能立即显示。SDXL Turbo不仅速度快,生成的图像质量也非常高,能够精准还原提示文本的描述。得益于其采用的对抗性扩散蒸馏技术,该技术可以在高质量图像下以1-4个步骤对大规模基础图像扩散模型进行采样,同时避免了其他蒸馏方法中常见的失真或模糊问题。存在的局限性:目前它只能生成固定像素的图片,对于一些细节可能表现的不够好,如人的手指、面部表情等,无法完美的展现照片级真实感。目前SDXL Turbo只能用于学术研究,还未开放商业权限。

直接连着游戏,获得了 2fps 的风格迁移画面


一边输入,一边生成
二、以SD 基础模型进行训练和优化的其他模型
以SD 基础模型进行训练和优化的常用模型介绍:
1、majicMIX realistic:专门用于生成唯美的人像图片,目前已更新至第七版。融合了多种模型,能够生成具有吸引力的面部特征,并能有效地处理暗部细节。
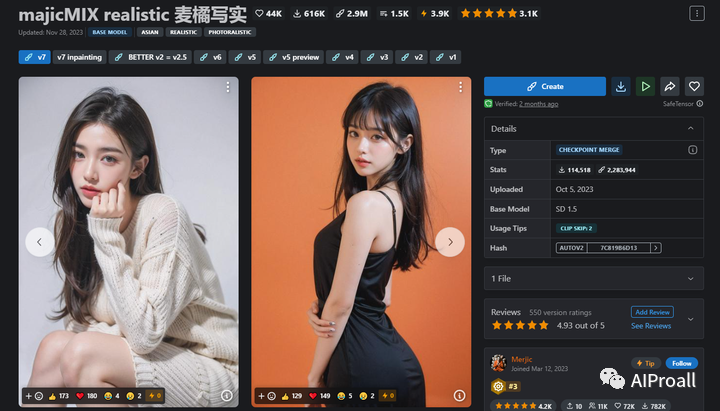
2、ChilloutMix:专为生成逼真的亚洲人物形象而设计。与majicMIX realistic类似,ChilloutMix在生成高质量人物图像方面表现出色。
3、AnythingElse V4:主要生成高质量的二次元和动漫图像。虽然它的风格相对较为单一,但在动漫领域表现出色。

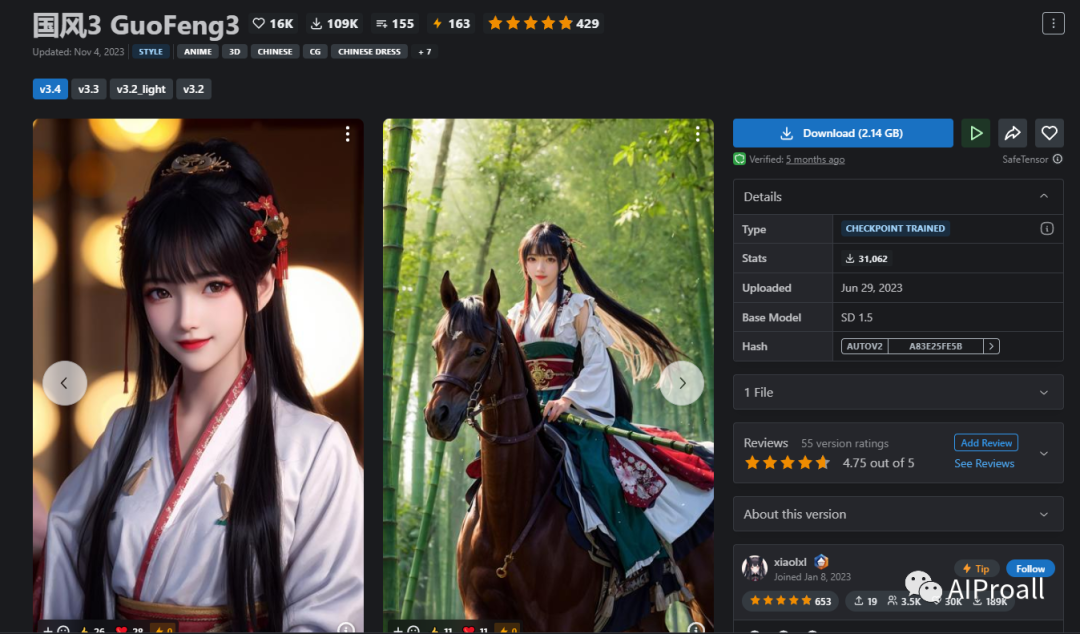
4、GuoFeng3:主要用于生成具有中国华丽古风风格的图像。它在古风游戏角色和场景生成方面具有优势。
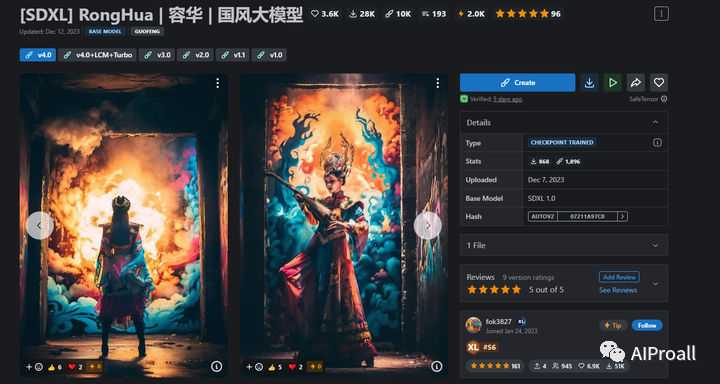
5、RongHua:这是另一个国风系列模型,专注于生成具有中国特色的服装、道具和化妆元素。它在国风创作领域具有较高的评价。
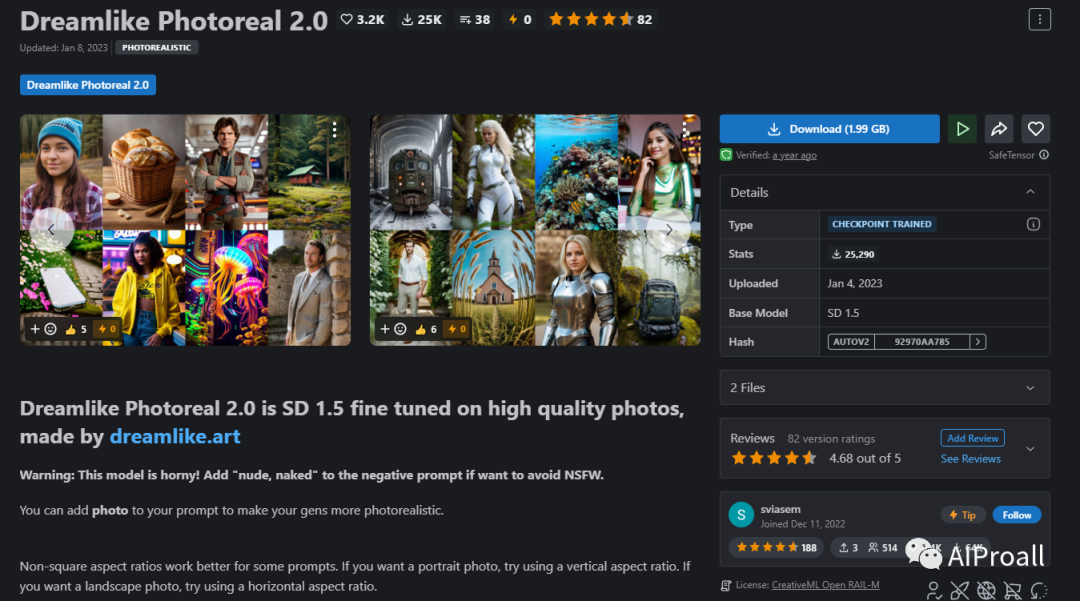
6、Dreamlike-photoreal-2.0:用于生成逼真的场景和物品。它在生成高质量的现实世界图像方面具有优势。
在模型选择时,我们并不直接选择SD 1.x、SD 2.x或是SD 1.5这样的基础模型进行画图,而是选择majicMIX realistic、ChilloutMix等特定优化模型,主要基于以下原因:
1、针对性优化:像majicMIX realistic、ChilloutMix这样的模型是在基础模型的基础上进行了针对性的优化和调整,以满足特定领域或风格的需求。这使得这些模型在生成特定类型图像时的性能更优,例如majicMIX realistic在生成逼真的亚洲人物形象方面,ChilloutMix在生成高质量的二次元和动漫图像方面。
2、更高的专业性和质量:这些特定优化的模型往往在某些方面具有更高的专业性和图像质量。例如,majicMIX realistic在人物形象的逼真度和场景泛化能力上表现出色,而ChilloutMix则在动漫领域的图像生成质量上具有优势。
3、更好的用户体验:这些优化模型通常在易用性和用户体验上进行了改进,使得用户能够更方便地生成所需的图像。例如,一些模型可能会提供更多的控制参数,让用户能够更精细地调整生成结果。
4、更广泛的应用场景:这些特定优化模型往往在某些应用场景中具有更广泛的适用性。例如,GuoFeng3和RongHua等国风系列模型在生成中国古风场景和元素时具有优势,而Dreamlike-photoreal-2.0则在生成逼真的场景和物品方面表现出色。
总之,选择majicMIX realistic、ChilloutMix等优化模型而不是基础模型的主要原因是为了获得更好的性能、更高的专业性、更广泛的应用场景以及更优的用户体验。这些优化模型在特定领域和风格上的表现往往优于基础模型,从而使得用户能够更高效地生成满足需求的图像。
三、以SD 基础模型进行训练和优化的模型的命名规则
通常看到的就两种:safetensors和ckpt,此外还有.pt 或 .pth。
1、safetensors是一种模型文件格式,这种格式是专门为Stable Diffusion模型设计的,具有较小的文件体积和较快的加载速度。safetensors文件只包含模型的权重,而不包含优化器状态或其他信息,通常用于模型的最终版本,当我们只关心模型的性能,而不需要了解训练过程中的详细信息时,这种格式是一个很好的选择。
2、.ckpt:这是一种Checkpoint(检查点)格式的模型文件,用于保存模型的权重和优化器的状态。这种文件格式在训练过程中生成,可以用来恢复训练或调整模型。ckpt模型文件通常较大,因为它们包含了训练过程中的中间状态。
3、.pt 或 .pth:这些文件格式通常用于PyTorch模型,其中.pt表示PyTorch张量(Tensor),而.pth表示PyTorch模型参数。这些文件包含了模型的权重和结构信息,但不包含优化器状态。
在选择模型的存储格式时,需要根据使用场景来决定。例如,如果你需要进行模型微调,或者需要在训练过程中获得详细的信息,Checkpoint格式(.ckpt)可能是更好的选择。而对于那些仅需要快速加载和执行模型的场景,safetensors可能是更好的选择。
四、LCM模型介绍
Latent Consistency Models(潜一致性模型)是一个以生成速度为主要亮点的图像生成架构。和需要多步迭代传统的扩散模型(如Stable Diffusion)不同,LCM仅用1 - 4步即可达到传统模型30步左右的效果。由清华大学交叉信息研究院研究生骆思勉和谭亦钦发明,LCM将文生图生成速度提升了5-10倍。(其刚出来,就被上文提到的SDXL Turbo直接碾压,以后有机会再详细说)。

3分钟快速渲染:AnimateDiff Vid2Vid + LCM
LCM的一个关键特点是它能在非常短的推理时间内生成图像,使其成为需要快速处理的应用场景中的宝贵工具。
LCM与稳定扩散(Stable Diffusion)模型兼容,并能增强其性能。它可以集成到稳定扩散的Web UI中,使用户能够轻松访问LCM功能。当使用稳定扩散生成动画时,这种集成特别有益,因为它提高了扩散过程的速度和稳定性。LCM可以在CPU和GPU上运行,为不同硬件能力的用户提供灵活性。
LCM模型通过将无分类器引导(classifier-free guidance)蒸馏到模型的输入中来工作。这种方法允许使用较少的计算资源并在比传统方法短得多的时间内生成高质量图像。例如,使用A800 GPU,LCM可以在CFG规模为w=8且批量大小为4的情况下生成768 x 768分辨率的图像,展示了其效率和性能。
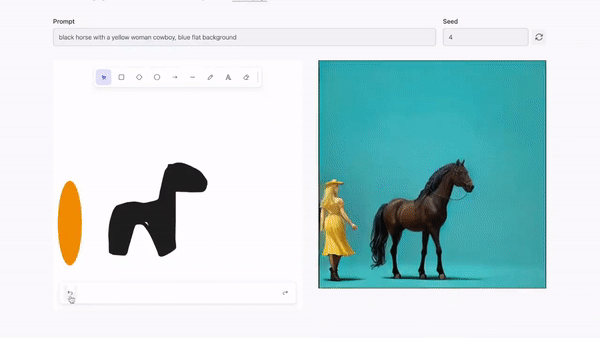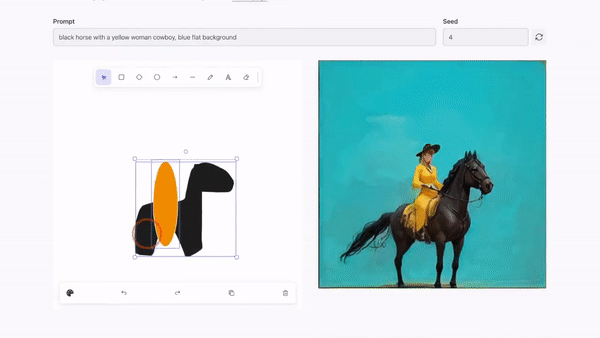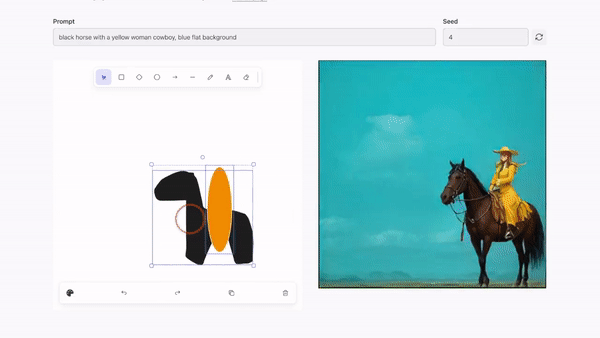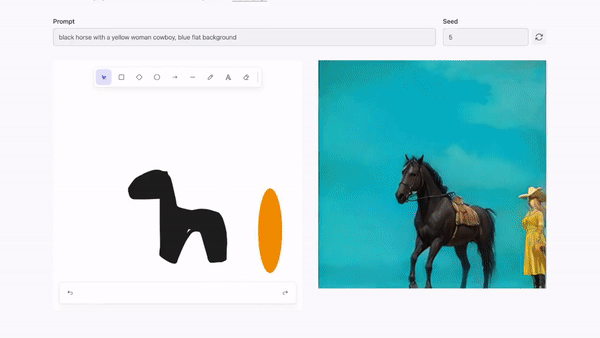
实时图像编辑
此外,LCM已被集成到Diffusers库中,使其对开发者和研究人员更加易于访问。它支持各种功能,如图像到图像和文本到图像的生成,显示了其在不同图像生成背景下的多功能性。
总的来说,LCM在AI图像生成领域代表了一个重大进步,特别是在速度和效率方面。它与稳定扩散模型的集成为实时图像生成和动画制作打开了新的可能性,使其成为各种创意和实际应用中的工具。

Krea.ai实时图像编辑
五、SD 用户界面工具
主要介绍三种:Fooocus、SD WebUI和ComfyUI
1、SD WebUI:
SD WebUI是一个基于Web的界面,用于运行Stable Diffusion模型。它允许用户在浏览器中输入文本提示,然后生成相应的图像。SD WebUI支持多种功能,如调整模型、图像尺寸、采样步数等。用户可以在WebUI中方便地调整这些参数,以获得满意的图像生成效果。SD WebUI的一个优点是其易于使用,用户无需安装任何额外的软件,只需在浏览器中打开WebUI页面即可开始使用。
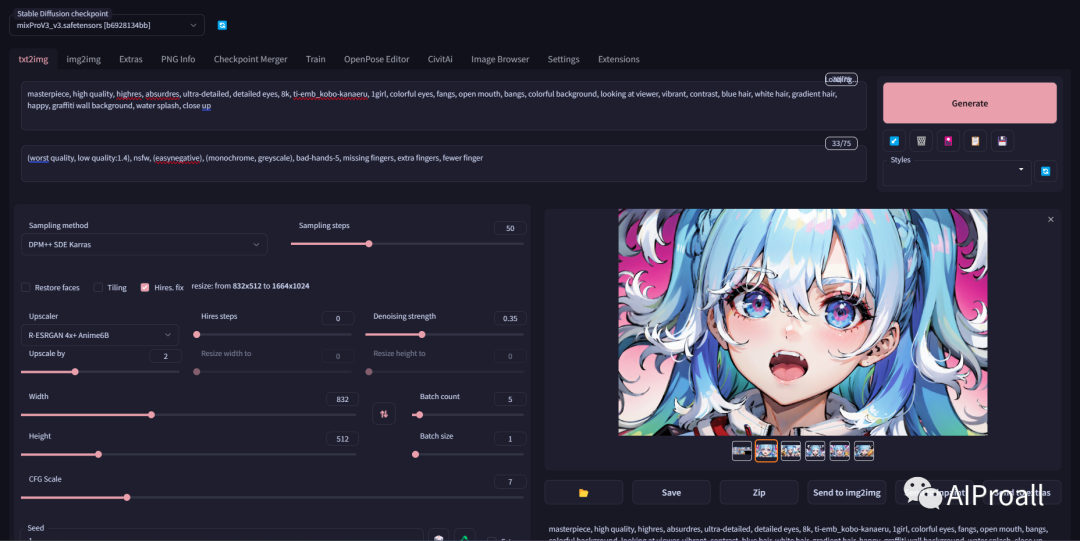
2、ComfyUI:
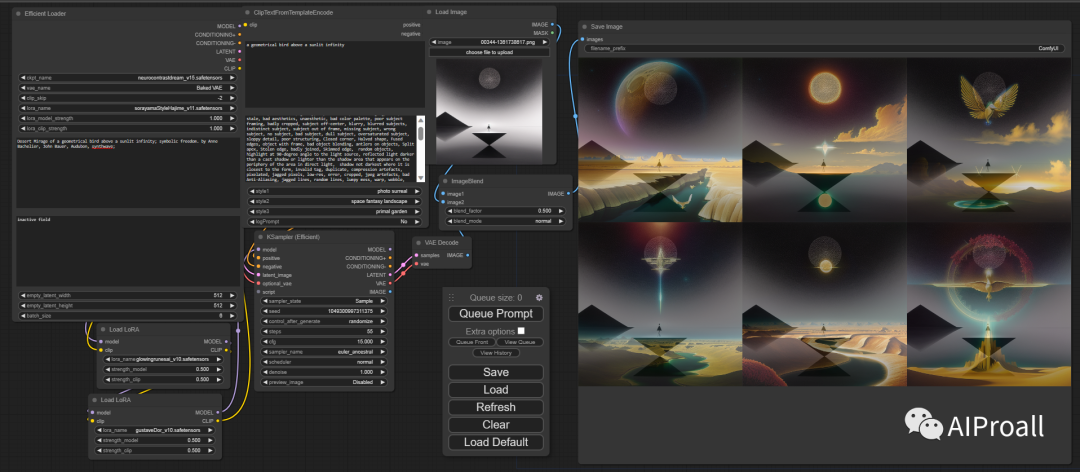
ComfyUI是一个功能强大的节点编辑工具,支持Stable Diffusion模型的双模型计算。与SD WebUI相比,ComfyUI提供了更多的自定义选项和灵活性。用户可以通过连接不同的节点来创建工作流,从而实现对图像生成过程的精细控制。ComfyUI支持多种插件,如ADetailer、Controlnet和AnimateDIFF等,这些插件可以进一步扩展ComfyUI的功能。值得注意的是,ComfyUI可以在MacBook Pro M1的16GB内存上运行双模型计算,这使得它在一定程度上具有竞争优势。
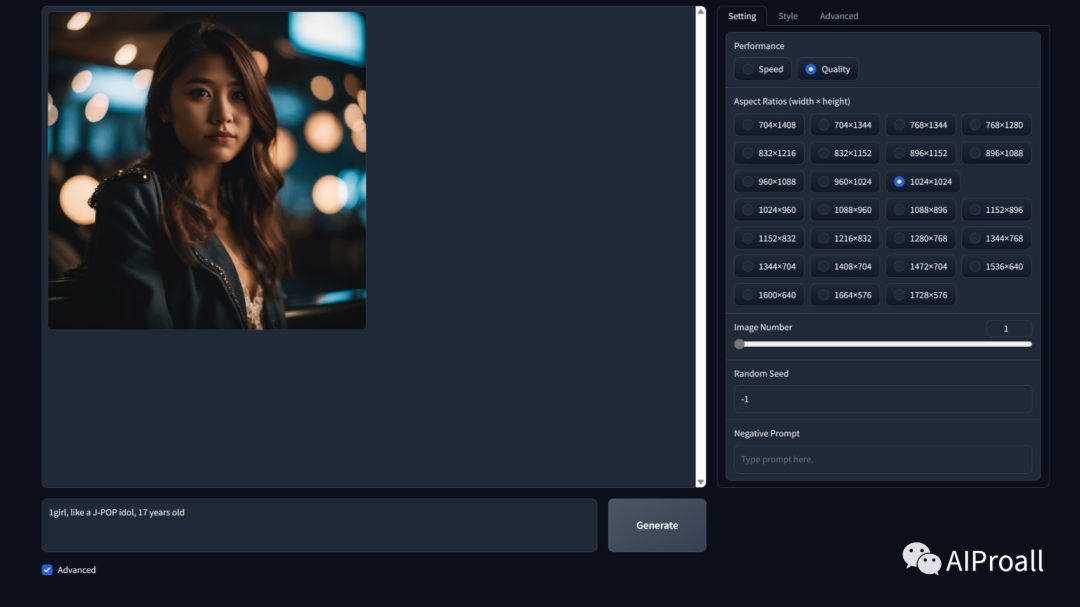
3、Fooocus:Fooocus的主要特点是简单易用,用户只需关注提示词的书写,就可以生成高质量的图片。Fooocus的作者是斯坦福大学博士生张吕敏,他对Fooocus进行了大量的优化,使得用户可以忘记所有那些困难的技术参数,只享受人与计算机之间的交互。
总之,Fooocus、SD WebUI和ComfyUI都是基于Stable Diffusion模型的AI绘画工具,各自具有不同的特点和优势。Fooocus以其简单易用和高质量的图像生成而受到关注,而SD WebUI和ComfyUI则分别以易用性和灵活性而受到欢迎。用户可以根据自己的需求和喜好选择合适的工具。
六、常用模型下载网站
目前比较常见的就是以下三个站点:
1、https://civitai.com/俗称C站,旨在帮助用户更轻松地找到、使用和管理AI和深度学习项目所需的各种工具、数据集和模型。

2、https://huggingface.co/俗称抱脸,可以直接访问,无需注册就可下载模型
3、https://www.liblib.art/这个是国内比较火的模型网站
AI绘画SD整合包、各种模型插件、提示词、GPT人工智能学习资料都已经打包好放在网盘中了,有需要的小伙伴文末扫码自行获取。
写在最后
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除

