
热门标签
热门文章
- 1软考与职称的关系_软考证书和职称的关系原来是这样
- 2react 父组建 调用/获取 子组建函数/参数_react const component =
- 3工作5-8年的外包测试员,平均年薪有多少?_武汉科大讯飞外包测试工资高吗
- 4git clone 指定分支_git clone 指定branch
- 5python目前主流使用的版本,python软件哪个版本好用_现在python 流行哪个版本
- 6【数据结构】——二叉树堆的实现
- 7程序员常用刷题网站分享
- 8亚太数学建模竞赛优秀论文_【竞赛预告】2020年数学建模亚太赛和小美赛,来喽~...
- 9【数据挖掘】实验6:初级绘图
- 10YOLO-World:实时开放词汇对象检测(论文+代码)_yolo world 论文
当前位置: article > 正文
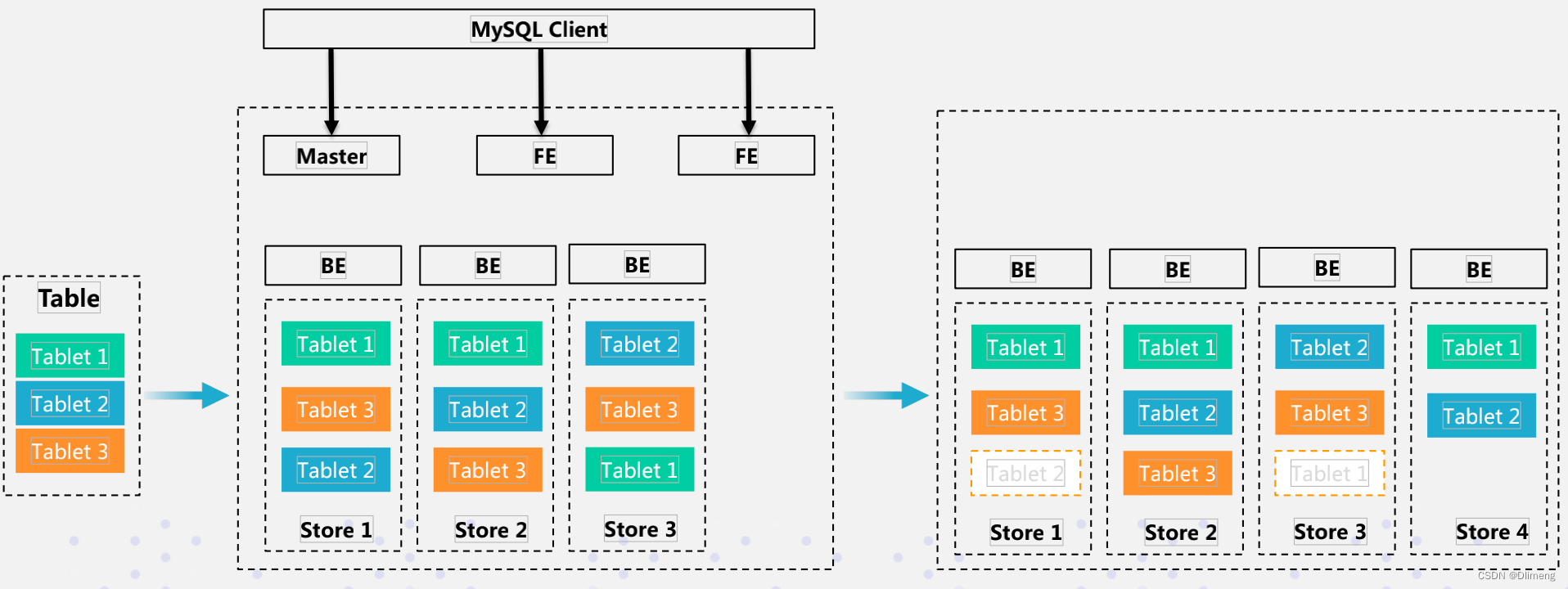
doris 数据库优化_doris unique 查询优化
作者:IT小白 | 2024-04-18 09:28:42
赞
踩
doris unique 查询优化
存储
列示存储
- 数据按列连续存储,按需读取
- 多种编码方式和自适应编码
- 在编码基础上基于Lz4算法进行压缩
- 1:8数据压缩比
存储编码方式

文件格式

多副本存储,自动数据迁移、副本均衡
索引
自动写入的智能索引
- 前缀稀疏索引:快速定位起始行
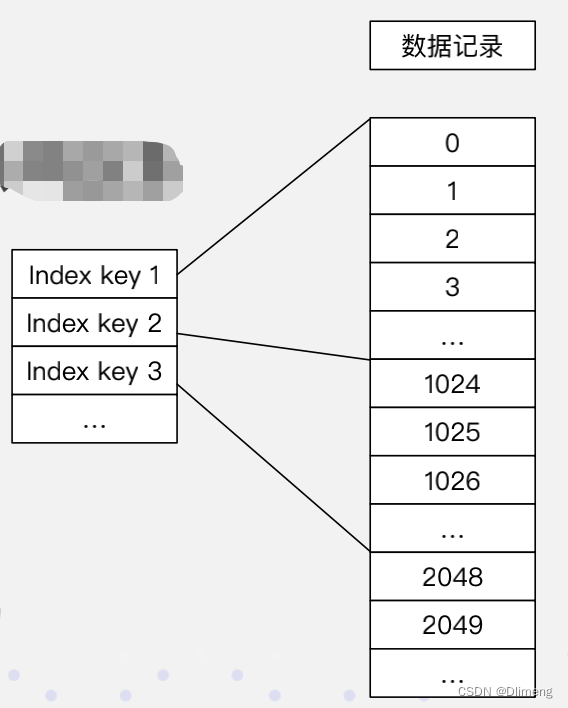
- Min Max 索引:等值/范围查询快速过滤
用户自主选择的二级索引
- Bloom Filter 索引:高基数上实现等值查询
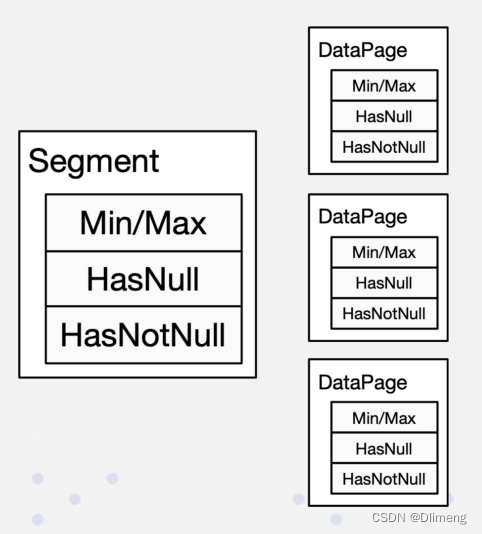
- 倒排索引:基于Bitmap位图快速精确查询
MPP
基于MPP的火山模型

利用多节点间并行数据处理
节点内并行执行,充分利用多CPU资源
算子优化
自适应的两阶段聚合算子,避免阻塞等待。
大量优化Join算子,以Runtime Filter为例
- 为连接列生成过滤结构并下推,减少需要传输和对比的数据量。
- 实现了In/Min Max/Bloom Filter等Filter类型,根据不同场景选择。
- 节点自动穿透,将Filter穿透下推到最底层扫描节点。
*
向量化执行引擎
向量化:一次对一组值进行运算的过程
充分提升CPU执行效率
进一步利用CPU SIMD指令加速计算效率

规则优化RBO
常量折叠:
- 基于常量计算,利于分区分桶裁剪以数据过滤。
子查询改写:
- 将子查询改写成Join,利用Join优化来提升查询效率。
谓词下推:
- 谓词下推至存储引擎,利用索引进行数据过滤。
代价优化CBO
Join Reorder
- 自动调整Join顺序,降低中间数据集大小。
Colocation Join
- 利用数据分布情况在本地完成join,避免数据Shuffle。
Bucket Join
智能判断关联条件和数据分布关系,减少Shuffle数据量。
数据模型
建表
- 定义 Key 维度列和 Value 指标列
- 选择数据模型:Agg /Uniq /Dup
- 选择数据分布方式: Partition 分区和 Bucket 分桶
- 指定副本数量和存储介质

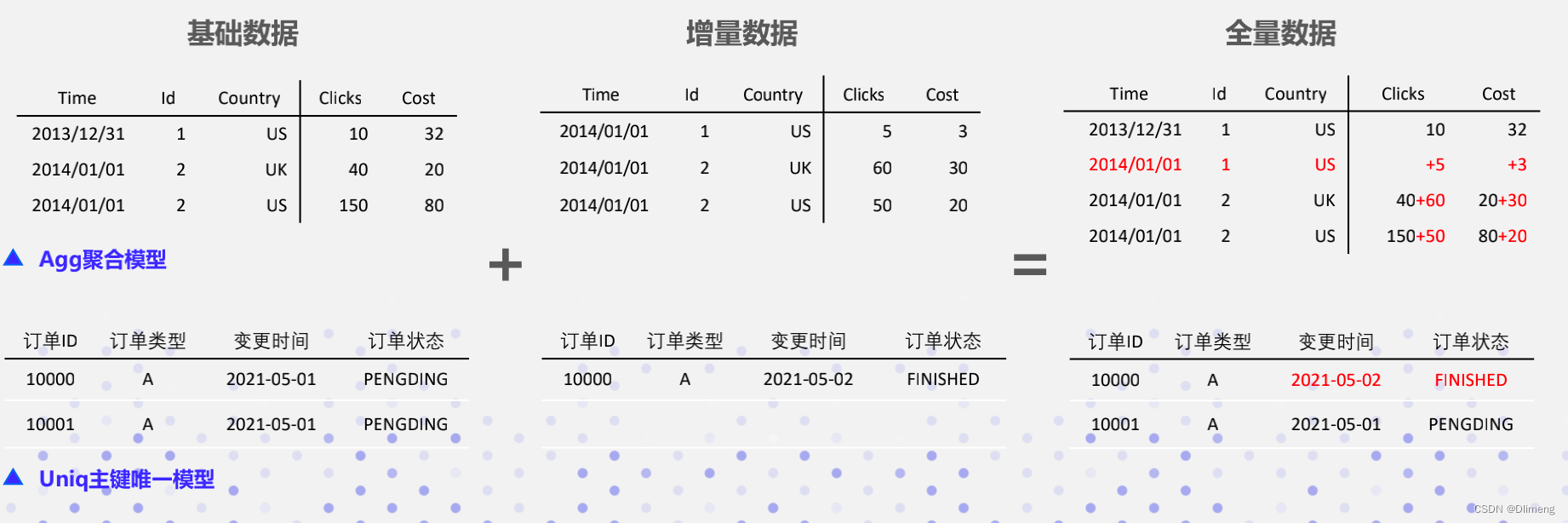
模型
- Unique Key主键唯一模型,Key唯一、不聚合,实现精准去重和行级别数据更新;
- Aggregate聚合模型:相同key列其Value列合并(SUM,MIN,MAX,REPLACE),通过提前聚合显著提升查询性能
- Duplicate Key明细模型,不提前聚合、实现快速排序
- 同时支持星型模型/雪花模型/宽表模型
导入
Broker Load
HDFS或所有支持S3协议的对象存储。
Stream Load
通过 HTTP 协议导入本地文件或数据流中的数据。
Routine Load
生成例行作业,直接订阅Kafka消息队列中的数据。
Binlog Load *
增量同步用户在Mysql数据库的对数据更新操作的CDC。
Flink Connector
在Flink中注册数据源,实现对Doris数据的读写。
Spark Load
通过外部的 Spark 资源实现对导入数据的预处理。
Insert Into
库内数据ETL转换或ODBC外表数据导入。
事务
多版本机制解决读写冲突,写入带版本、查询带版本
两阶段导入保证多表原子生效
- 支持并行导入
- 有冲突时按导入顺序生效,无冲突导入时并行生效

标准sql
- 单表聚合、排序、过滤
- 多表关联、子查询
- 复杂SQL、窗口函数、GroupingSet等高级语法
- UDF、UDAF

- 修改密码
SET PASSWORD FOR ‘root’ = PASSWORD(‘123456’);
高并发
通过分区分桶裁剪,减少查询对系统资源消耗
支持SQL/PartitionCache,降低重复查询对资源的消耗
资源隔离
同时支持节点和查询级别的资源划分
一套集群同时支持在线离线查询,解决资源抢占问题
多用户对集群资源更合理的划分
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/445200
推荐阅读
相关标签

